
基于Fisher约束和字典对的图像分类
2017-10-13 22:09郭继昌
电子与信息学报 2017年2期
郭继昌 张 帆 王 楠
基于Fisher约束和字典对的图像分类
郭继昌*张 帆 王 楠
(天津大学电子信息工程学院 天津 300072)
基于稀疏表示的分类方法由于其所具有的简单性和有效性获得了研究者的广泛关注,然而如何建立字典原子与类别信息间的联系仍然是一个重要的问题,与此同时大部分稀疏表示分类方法都需要求解受范数约束的优化问题,使得分类任务的计算较复杂。为解决上述问题,该文提出一种新的基于Fisher约束的字典对学习方法。新方法联合学习结构化综合字典和结构化解析字典,然后通过样本在解析字典上的映射直接求解稀疏系数矩阵;同时采用Fisher判别准则编码系数使系数具有一定的判别性。最后将新方法应用到图像分类中,实验结果表明新方法在提高分类准确率的同时还大大降低了计算复杂度,相较于现有方法具有更好的性能。
图像分类;稀疏表示;字典对;Fisher约束
1 引言
在对基于稀疏表示的分类方法进行研究的过程中,研究者们发现字典性能的好坏直接关系到最后的分类结果。字典最早用于解决信号重构的相关问题,它旨在获得一个具有良好表示能力的字典而没有考虑字典的判别性,因此并不利于分类问题[4]。近年来的研究表明判别性字典更加适合用于图像分类任务,此类字典既要被用来对样本进行稀疏编码,又要被用于执行最后的分类判别。判别性字典大致可分为两类:第1类是直接学习具有判别性的字典,文献[5]对不同类别的子字典添加低秩约束来学习一个具有判别性的字典,文献[6]考虑不同类别子字典间的非一致性信息提出了结构不相干字典学习方法,文献[7]提出同时学习一个所有类别的公共字典和多个特定类别的子字典的字典学习方法;第2类是对稀疏系数添加约束项来提升系数的判别性,进而获得具有判别性的字典[8,9],文献[8]在字典学习过程中对系数添加样本的类别信息提出了标签一致K奇异值分解(Label Consistent K-Singular Value Decomposition, LC-KSVD)方法,文献[9]提出了对系数添加Fisher判别约束的字典学习方法。
上述字典学习方法均属于综合型字典学习。综合型字典学习方法一直是研究者关注的热点,因此基于综合模型的字典学习理论相对比较成熟[10],但是综合型字典学习方法的计算量都较大,因此研究者们又提出了解析型字典学习方法[11,12]。解析模型中通过学习到的解析字典来获得样本的稀疏编码,具有较高的编码效率。与综合模型相比,在维数相同时解析模型的子空间数较多,有更灵活和更丰富的表示能力。
本文将解析字典学习模型和综合字典学习模型结合起来,提出一种新的字典学习方法,称之为基于Fisher判别约束的字典对学习方法。新方法一方面联合学习由结构化综合字典和结构化解析字典构成的字典对,并对字典添加判别性约束使得学习到的字典对具有判别性;另一方面通过样本在解析字典上的映射直接求解稀疏系数矩阵,避免了对标准稀疏编码问题的求解,同时采用Fisher判别准则编码系数使系数具有一定的判别性。最后将新模型应用到人脸图像库,目标图像库和场景图像库上进行评估。
2 字典学习模型及字典对模型
2.1 综合型字典学习模型

2.2 解析型字典学习模型
解析型字典学习是综合型字典学习的对偶形式,它的核心思想是通过学习到的解析字典直接获得样本在新映射空间的稀疏表示,解析型字典如图1(b)所示。优化模型可以表示为式(2),为解析型字典,是度量稀疏度的函数。
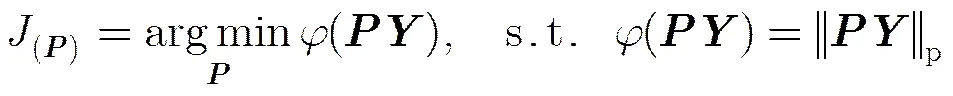
2.3 字典对模型
基于解析型字典学习的稀疏表示研究处于起步阶段,还没有较多地应用到稀疏表示分类问题中。比较有代表性的是文献[13]中提出的字典对学习(Dictionary Pair Learning,DPL) 模型。DPL模型通过样本在解析字典上的映射直接求解稀疏系数矩阵,避免了对受范数约束的标准稀疏编码问题的求解,从而大大减少了分类任务的计算复杂度。设矩阵,本文中用表示将矩阵和按列进行合并,用表示将矩阵和按行进行合并。DPL模型中用表示类训练样本,其中每类训练样本的个数为。求解DPL模型得到综合字典和解析字典。其中是第类样本对应的子字典对。在DPL模型中第类的解析子字典对第类样本的映射集合几乎为空集,即,用字典对表示的最小化重构误差为

3 基于Fisher约束的字典对学习模型
DPL模型利用解析字典大大减少了计算复杂度,但是其并没有充分利用训练样本所具有的类别信息,同时在字典学习模型中也没有考虑不同类别样本对应的字典原子和系数矩阵间的相关性信息。为克服以上缺点,本文提出了一种新的字典学习模型,称之为基于Fisher约束的字典对学习(Fisher constraint Dictionary Pair Learning, FDPL)模型。该模型同时学习结构化综合字典和结构化解析字典,并且在字典学习过程中对解析字典添加判别性约束来衡量解析子字典间存在的相关性信息,同时对系数添加Fisher约束来衡量系数矩阵间的相关性信息。FDPL模型的优化问题可以表示为

3.1 误差项的设计
FDPL模型中对训练样本和字典均采用结构化表示方式。结构化表示方式下解析字典和系数的优化问题以及综合字典和系数的优化问题分别表示为
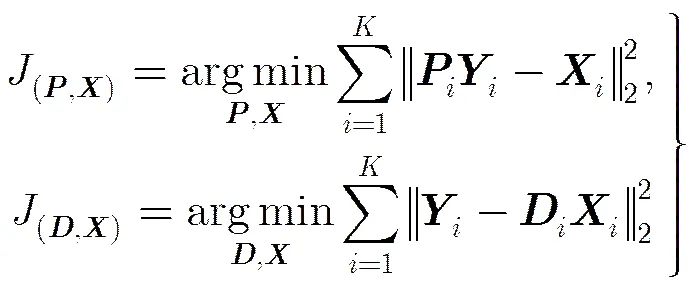
因此FDPL模型的重构误差项和编码误差项为
(6)
3.2 字典判别性约束项的设计
3.3 系数判别性约束项的设计
文献[9]中指出Fisher约束可以用来衡量样本间的相似性信息,具体是通过最小化系数的类内离散度和最大化系数的类间离散度来实现的。设稀疏系数矩阵为,其中为第类样本对应的系数矩阵,表示第类字典对第类样本的编码矩阵。的类内离散度、类间离散度为

(8)

3.4 模型求解
求解FDPL模型可以采用迭代优化的方法,将优化求解分为固定字典对更新系数和固定系数更新字典对两个子问题。
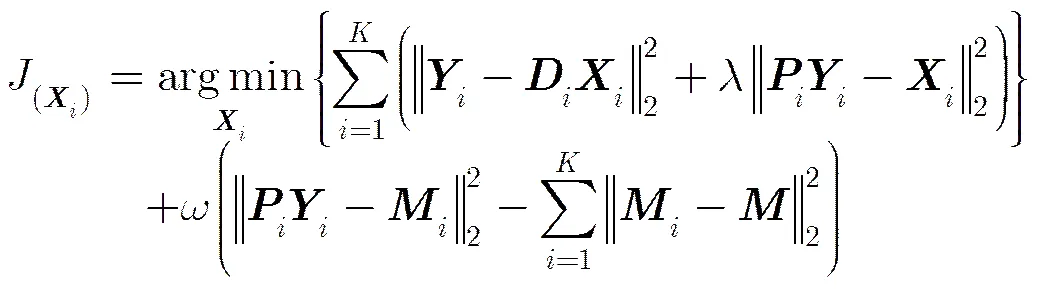
(11)

(13)

(15)

表1 FDPL模型的字典学习过程
3.5 分类准则
本文采用两种分类准则,第1种是将样本的重构误差作为分类准则,在这种分类准则下直接利用训练阶段求得的解析字典来获得测试样本的稀疏编码;第2种是同时考虑样本的重构误差和编码误差进行分类,此时根据训练阶段获得的综合字典通过求解标准稀疏表示问题获得测试样本的稀疏编码,再与解析字典获得的稀疏编码相比较作为编码误差。
(1)根据重构误差进行分类:通过求解FDPL模型得到每个类别对应的字典对,解析型子字典只对与它同类别的样本具有很好的表示能力,同时综合型子字典可以根据编码系数对第类的样本进行重构,此时的重构误差较小,但当时的值较大。因此在测试阶段如果待测试样本属于第类则,显然根据重构误差可以用来确定测试样本的类别:

(17)
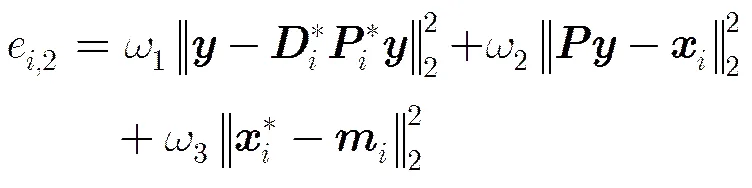
(19)
4 实验及分析
为了验证FDPL算法的性能,本文不仅比较FDPL算法在两种分类准则下的性能,而且将FDPL方法与已有的效果较好的字典学习方法进行比较,例如LC-KSVD[8], Fisher 判别约束字典学习(Fisher Discrimination Dictionary Learning, FDDL)[9]、支持向量引导的字典学习 (Support Vector Guided Dictionary Learning, SVGDL)[15]和DPL[13]。衡量分类模型性能好坏时既要考虑其分类准确率又要考虑其分类效率,因此实验中采用两种衡量指标:一是分类准确率,二是分类复杂度。
4.1 图像库
Extended YaleB图像库包含38人共2414张图像,每人随机选取32张图像作为训练集,其余作为测试集,图像特征采用504维的随机脸。AR图像库包含126人共4000多张图像,选取50个男性和50个女性共计2600张图像来进行实验,每人随机选取20张图像作为训练集其余作为测试集,图像特征采用540维的随机脸。Caltech-101图像库共有102类9144张图像,每类图像个数从31到800不等,每类随机选取30张图像作为训练集其余作为测试集。Scene15图像库共有15类4485张图像,每类图像个数从200到400不等,每类随机选取100张图像作为训练集其余作为测试集。在Caltech-101和Scene15图像库上首先按的图像块、6像素的步长提取图像的原始稠密SIFT特征;然后对原始特征进行空间金字塔最大池化,得到SIFT池化特征;通过K-means方法对池化特征进行稀疏编码,对每幅图像的所有稀疏编码运用空间金字塔最大化池方法;最后通过PCA降维得到3000维的含有空间信息的SIFT特征。
4.2 参数设置

表2 FDPL算法的主要参数
4.3 FDPL方法在不同分类准则下的分类性能对比
3.5节对两种分类准则进行了具体描述,第1种分类准则直接利用解析字典求解稀疏系数,第2种分类准则在求编码误差时仍然需要求解标准稀疏编码问题来获得待测样本在综合字典下的稀疏系数。首先对比表3中的分类准确率可以看出,第2种分类准则下的分类准确率较高但提升不是很明显;然后对比分类用时可以看出,第1种分类准则在分类用时方面具有明显优势。衡量分类模型性能好坏时既要考虑其分类准确率又要考虑其分类效率,综合评定可知第1种分类准则的优势更为明显,也说明了采用样本在解析字典上的投影直接获得稀疏系数矩阵的方法具有高效性和可行性。
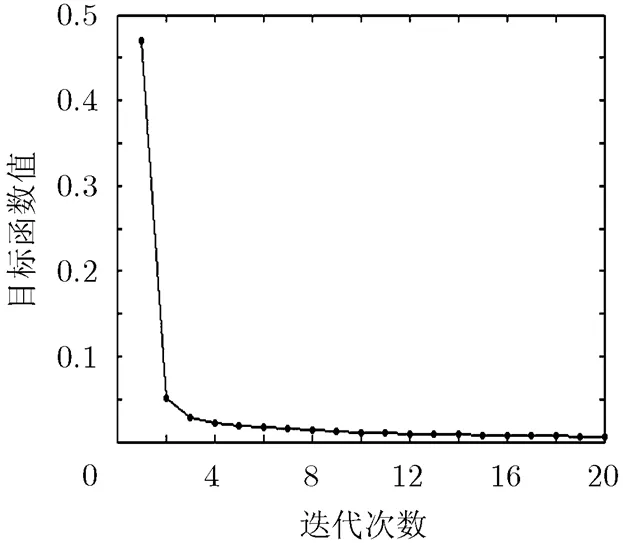
图2 AR图像库上目标函数的收敛性曲线
4.4 字典原子个数不同时分类性能对比
已有研究表明,字典学习过程中每类选取的字典原子个数直接关系到分类性能的好坏,因此将其设置为实验过程中的变量。LC-KSVD和SVGDL算法中限制总的字典原子个数不大于选取的训练样本个数,在AR图像库上每类选取的训练样本个数为20,因此在字典原子个数为30时没有对应的数据。改变字典原子个数时的分类准确率如表4所示,黑体标注为相同字典原子个数下的最高分类准确率。表5是各种方法保持硬件条件一致的情况下的分类用时比较。

表3 FDPL方法在不同分类准则下的分类准确率(%)和分类用时(s)

表4 不同原子个数下的分类准确率(%)
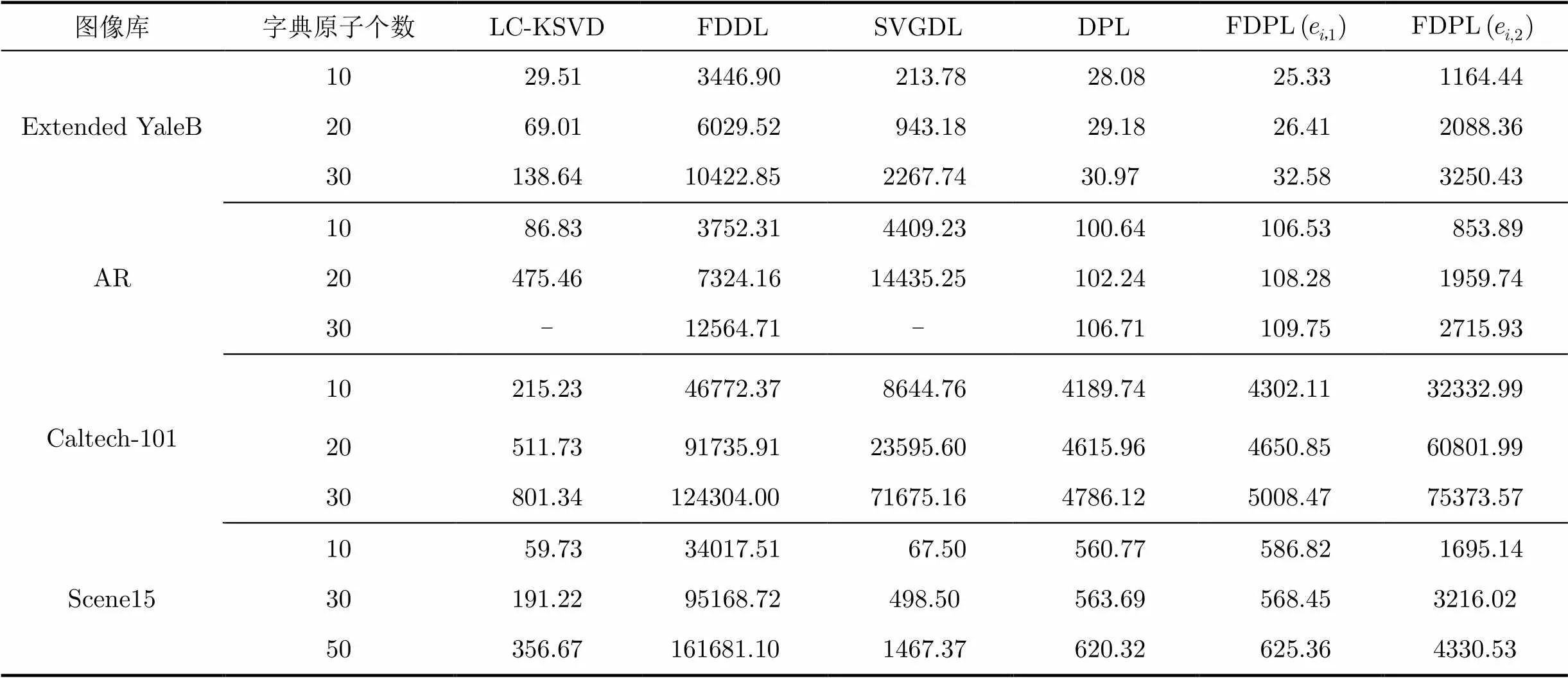
表5 不同原子个数下的分类用时(s)
对比表中每列的数据,为了说明本文算法的有效性首先与LC-KSVD, SVGDL算法进行对比,通过LC-KSVD和SVGDL算法获得的是所有类别公用的综合字典,并且在字典学习过程中没有考虑字典原子间的相关性信息,因此采用LC-KSVD和SVGDL算法获得的字典的判别性能较差,进而造成分类准确率较低。为了进一步论证本文算法的有效性,将与FDDL和DPL算法进行对比,FDDL算法通过对系数添加Fisher约束来获得具有判别性的字典,但该方法没有考虑字典原子间的相关性信息,DPL算法联合学习综合字典和解析字典,但是该方法并没有考虑系数间的相关性信息,因此采用FDDL, DPL算法进行图像分类的效果也较差。通过对比发现FDPL算法具有较高的分类准确率。
4.3节中通过对比FDPL方法在两种分类准则下的分类用时,可知第2种分类准则在时间消耗上并不具有优势,因此在与其它方法进行对比时主要考虑第1种分类准则下的分类用时。与其它方法相比FDPL方法分类用时明显较少并且受字典原子个数的影响较小。分析上述结果原因主要有以下两点:在训练阶段进行迭代更新时FDPL方法需要求解的是标准最小二乘问题,该问题可以通过解析方法求其闭式解,从而避免了处理FDDL, LC-KSVD和SVGDL方法中受范数约束的稀疏编码问题;在分类阶段FDPL方法通过样本在解析字典上的映射直接求解稀疏系数矩阵,也避免了对标准稀疏编码问题的求解,因此用时较短。
然而通过运行时间分析复杂度并不可靠,接下来将从理论上对FDPL方法的计算复杂度进行分析。采用迭代更新的方法更新,,的时间复杂度分别为,,,是采用ADMM方法更新字典时的迭代次数,通常。在实际应用中每类训练样本个数和字典原子个数都远远小于特征维数,因此训练阶段的计算复杂度主要是由更新引起的。第1种分类准则下重构误差项的计算复杂度为,分类阶段总的复杂度为。相较于求解标准稀疏编码问题,FDPL方法具有较小的计算复杂度且受字典原子个数和训练样本个数影响较小。
4.5 稀疏性分析
将实验过程中得到的样本的系数矩阵提取出来进行稀疏性分析,以Extended YaleB为例。图3为在每类字典原子个数为10的情况下的稀疏性分析。
5 结束语
本文提出了基于Fisher约束和字典对学习的图像分类方法,FDPL方法一方面既考虑字典判别性又考虑系数判别性,使得所得字典和系数均具有良好的判别能力;另一方面通过样本在解析字典上的映射直接求解稀疏系数矩阵,避免了对标准稀疏编码问题的求解,减少了计算复杂度。在多个图像库上对FDPL方法进行了实验验证并与现有效果较好的方法进行了比较,实验结果表明FDPL方法克服了当下主流字典学习算法中计算复杂、训练速度慢的缺点,在总体上缩短了图像分类时间,并且具有更高的分类准确率。本文并未考虑图像特征表示这一因素对分类性能的影响,采用了已有的提取图像SIFT特征的方法,因此在未来的研究中将会寻求更好的图像特征表示方法,然后与本文方法相结合。
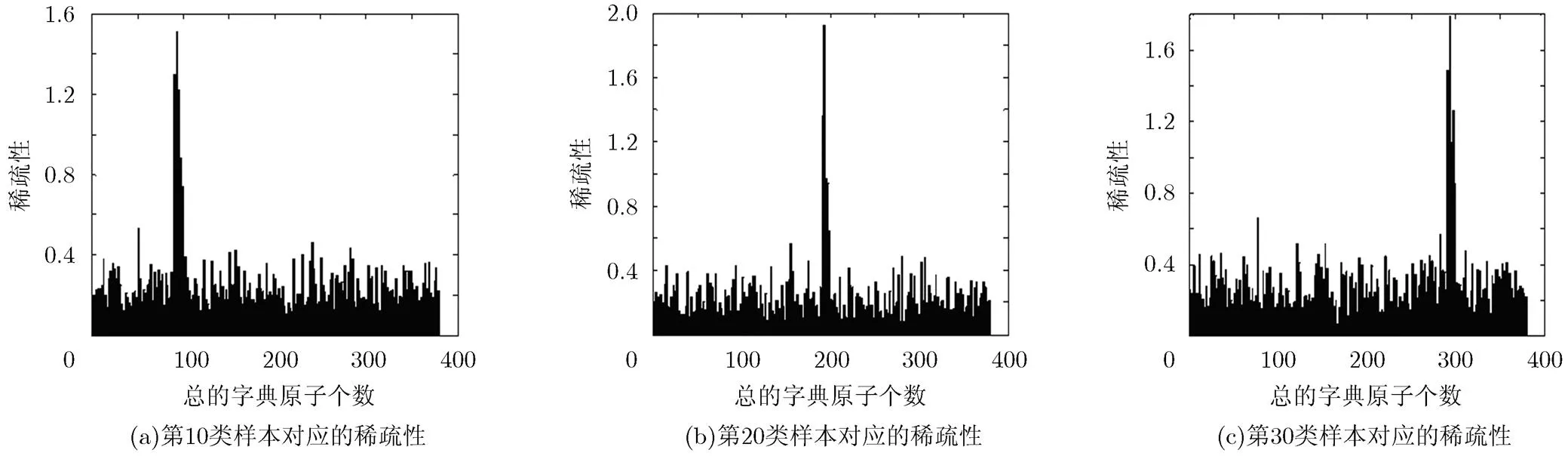
图3 稀疏性分析
[1] RUBINSTEIN R, BRUCKSTEIN A, ELAD M,. Dictionaries for sparse representation modeling[J]., 2010, 98(6): 1045-1057.doi: 10.1109/JPROC.2010.2040551.
[2] GAO Shenghua, TSANG I, and MA Yi. Learning category- specific dictionary and shared dictionary for fine-grained image categorization[J]., 2014, 23(2): 623-634.doi: 10.1109/TIP.2013. 2290593.
[3] 宋相法, 焦李成. 基于稀疏编码和集成学习的多示例多标记图像分类方法[J]. 电子与信息学报, 2013, 35(3): 622-626.doi: 10.3724/SP.J.1146.2012.01218.
SONG Xiangfa and JIAO Licheng. A multi-instance multi-label image classification method based on sparse coding and ensemble learning[J].&, 2013, 35(3): 622-626. doi: 10.3724/ SP.J.1146.2012.01218.
[4] AHARON M, ELAD M, and BRUCKSTEIN A. K-SVD: an algorithm for designing of overcomplete dictionaries for sparse representation[J]., 2006, 54(11): 4311-4322.doi: 10.1109/TSP. 2006.881199.
[5] MA Long, WANG Chunheng, XIAO Baihua,. Sparse representation for face recognition based on discriminative low-rank dictionary learning[C]. IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 2586-2593.
[6] RAMIREZ I, SPRECHMANN P, SAPIRO G,. Classification and clustering via dictionary learning with structured incoherence and shared features[C]. IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 2010: 3501-3508.
[7] NING Zhou and FAN Jianping. Jointly learning visually correlated dictionaries for large-scale visual recognition applications[J]., 2014, 36(4): 715-730.doi: 10.1109/ TPAMI.2013.189.
[8] JIANG Zhuolin, LIN Zhe, LARRY S,. Label consistent K-SVD: Learning a discriminative dictionary for recognition [J]., 2013, 35(11): 2651-2664.doi: 10.1109/TPAMI. 2013.88.
[9] YANG Meng, ZHANG Lei, FENG Xiangchu,. Sparse representation based fisher discrimination dictionary learning for image classication[J]., 2014, 109(3): 209-232. doi: 10.1007/s11263-014- 0722- 8.
[10] 练秋生, 石保顺, 陈书贞. 字典学习模型、算法及其应用研究进展[J]. 自动化学报, 2015, 41(2): 240-260. doi: 10.16383/ j.aas.2015.c140252.
LIAN Qiusheng, SHI Baoshun, and CHEN Shuzhen. Research advances on dictionary learning models, algorithms and applications[J]., 2015, 41(2): 240-260. doi: 10.16383/j.aas.2015.c140252.
[11] RUBINSTEIN R, PELEG T, and ELAD M. Analysis K-SVD: A dictionary-learning algorithm for the analysis sparse model[J]., 2013, 61(3): 661-677. doi: 10.1109/TSP.2012.2226445.
[12] CHEN Yunjin, RANFTL R, and POCK T. Insights into analysis operator learning: From patch-based sparse models to higher order MRFs[J]., 2014, 23(3): 1060-1072.doi: 10.1109/TIP.2014. 2299065.
[13] GU Shuhang, ZHANG Lei, ZUO Wangmeng,.Projective dictionary pair learning for pattern classification[C]. Advances in Neural Information Processing System, Vancouver, BC, Canada, 2014, 1: 793-801.
[14] RAKOTOMAMONJY A.Applying alternating direction method of multipliers for constrained dictionary learning[J]., 2013, 61(3): 126-136. doi: 10.1016/j. neucom.2012.10.024.
[15] CAI Sijia, ZUO Wangmeng, ZHANG Lei,.Support vector guided dictionary learning[C]. European Conference on Computer Vision, Zurich, Switzerland, 2014, 8692: 624-639.
[16] GORSKI J, PFEUFFER F, and KLAMROTH K. Biconvex sets and optimization with biconvex functions: a survey and extensions[J]., 2007, 66(3): 373-407. doi:10.1007/s00186-007-0161-1.
Image Classification Based on Fisher Constraint and Dictionary Pair
GUO Jichang ZHANG Fan WANG Nan
(,,300072,)
Classification method based on sparse representation has won wide attention because of its simplicity and effectiveness, while how to adaptively build the relationship between dictionary atoms and class labels is still an important open question, at the same time most of the sparse representation classification methods need to solve a norm constraint optimization problem, which increases the computational complexity in the classification task. To address this issue, this paper proposes a novel Fisher constraint dictionary pair learning method to jointly learn a structured synthesis dictionary and a structured analysis dictionary, then directly obtains the sparse coefficient matrix by analysis dictionary. In this paper, the Fisher criterion is used to encode the coefficients. Finally the new method is applied to image classification task, the experimental results show that the new method not only improves the accuracy of classification but also greatly reduces the computational complexity. Compared with the existing methods, the new method has better performance.
Image classification; Sparse representation; Dictionary pair; Fisher constraint
TP391
A
1009-5896(2017)02-0270-08
10.11999/JEIT160296
2016-03-31;改回日期:2016-07-25;
2016-10-09
郭继昌 jcguo@tju.edu.cn
国家973计划项目(2014CB 340400),天津市自然科学基金(15JCYBJC15500)
The National 973 Program of China (2014CB340400), The Natural Science Foundation of Tianjin (15JCYBJC15500)
郭继昌: 男,1966年生,教授,研究方向为数字图像处理、语音信号处理等.
张 帆: 女,1993年生,硕士生,研究方向为图像分类.
王 楠: 男,1990年生,硕士生,研究方向为图像分类.
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·高一版(2021年4期)2021-07-19
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学阅读指南·低年级版(2019年11期)2019-07-01
小学生学习指导(低年级)(2018年9期)2018-09-26
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
创新作文(小学版)(2016年19期)2016-08-22
摄影之友(影像视觉)(2016年2期)2016-08-16
