
关联规则在中职学校招生管理系统中的应用
2017-10-13 20:07唐坚胜张晶晶邓珍荣
网络安全技术与应用 2017年3期
◆何 萌 唐坚胜 张晶晶 邓珍荣
关联规则在中职学校招生管理系统中的应用
◆何 萌1唐坚胜2张晶晶1邓珍荣1
(1.桂林电子科技大学计算机与信息安全学院 广西 541004;2.桂林林业学校 广西 541004)
针对中等职业学校招生规模的不断扩大的现象,提高中职生源质量已经成为各培养单位的重点工作。传统的生源质量分析主要是计算考生成绩的均值、方差、区分度等,仅对单个独立的数据进行分析,无法获取数据间的有价值信息。本文将数据挖掘关联规则应用于分析中职学校学生入学成绩、在校生学习成绩、就业状况和生源质量之间的内在关系,找出对影响招生质量有价值的信息,为招生政策的制定提供参考。
数据挖掘;关联规则;生源质量
0 引言
当今大数据时代,数据处理量越来越大,仅仅依靠传统的数据处理方式已经远远不能满足人们现实生活中的需求,数据挖掘技术的发展引起了各行各业的高度关注。近年来,中等职业教育得到国家政策大力扶持,职业学校规模逐渐扩大、自主招生程度不断提高,生源数量已经成为政府和社会评价中等职业学校办学实力的一个重要指标。如何从学校丰富的数据信息中提取出有价值的数据资料,已经成为教学管理中值得探索的问题之一。数据挖掘技术可以为学校科学决策助一臂之力。将数据挖掘技术应用于中等职业学校招生信息系统,搜集各种数据表征的内容及其相互关系,根据学生入学前的信息与在校就读期间的学习成绩等特点,分析中职学校生源质量,可为中职学校制定招生计划、提高生源质量提供有效的参考信息。有助于及时发现教学与管理中的问题,促进教育教学改革,提高教学管理工作的质量和效率。
1 关联规则
1.1 数据挖掘技术概述
从具有随机干扰、噪声、错误、缺失和不完整的大量数据中,将对人们有用的、隐含的、潜在的、未知的信息提取出来的操作,称为数据挖掘。数据挖掘技术在当前形势下应运而生。数据挖掘是一种深层次的数据信息分析方法,是从数据库中知识发现和决策支持的过程,主要基于人工智能、机器学习、统计学等技术,高度自动化地分析原有数据,做出归纳性的推理,从数据中挖掘出潜在的模式,预测分析对象的行为趋势,从而帮助决策或调整策略。数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等,其中最常用的是聚类分析和关联规则分析。数据挖掘技术已成功地应用在许多企业中,对提高企业经济效益和管理效率有显著的影响。
在中等职业教育领域,有很多可以挖掘的信息,如学生入学成绩管理、学生在校成绩管理、学生家庭状况、入学率情况和毕业就业质量等。将数据挖掘技术应用于对中职学校学生成绩的分析,分析生源质量与各种因素之间隐藏的内在联系,这对整个中职院校扩大规模、提高办学质量具有重要的实践意义。
1.2 关联规则概述
数据挖掘中有一类问题,叫做关联规则挖掘或频繁项集挖掘。关联规则是数据挖掘应用最广的一种方法。关联规则挖掘是在海量的数据中发现数据各项之间的关系关联规则的支持度和置信度。它们分别反映了所发现规则的有用性和确定性。通过设定最小支持度阈值和最小置信度阈值,选取有趣的关联规则。当挖掘出的关联规则的支持度和置信度都满足这两个阂值时就认为这个规则是有效的,否则就是无效的,这些阈值一般可由领域专家设定。挖掘关联规则的整个过程主要包括两个方面,一个是发现频繁项集:找出支持度大于等于用户设置的最小支持度的项集;另一方面是生成关联规则:由步骤一发现的频繁项集生成关联规则,并且这些关联规则的置信度不小于用户给定的最小置信度挖掘关联规则的整个过程如图1所示。

图1挖掘关联规则的过程
数据发掘技术中的关联规则挖掘,是利用计算机自动从大量的数据中去分析和发现有关联的规则。计算机本身需要了解所有发生的情况,并依次整理,把相关的事件合并整理在一起,然后对每件事进行扫描分析,以总结出事物的关联性规律。数据挖掘技术对于中职的学生信息管理工作来说,是一种可以化繁琐为简单的技术,对于工作效率的提高以及工作准确度的保证都有很重要的意义,因此在很多中职学校中,数据挖掘技术都被作为了其学生信息管理的研究工作的重点。
2 Apriori算法
Apriori算法是经典的关联规则的挖掘算法,被广泛应用于各种领域。Apriori算法主要用于发现事务数据库中的布尔型关联规则,是一种寻找频繁项集的基本算法,其基本原理是使用一种称作逐层搜索的迭代方法,即用k项集去探索(k +1)项集针对大量的事务数据。从单个项开始逐个遍历所有事务,并与预设的最小支持度阈值相比较,如果支持度小于预设的阈值,则这一项将被删除,进而扩充到所有事务,频繁项集就是最终保留下来的项的集合。关联规则通过子集产生法来生成,与用于预设的最小置信度阈值相比,如果置信度低于这一阈值,则将这一关联规则删除,最终保留下来的关联规则符合用户需要。Apriori 算法可以描述如下:
(1)产生频繁一项集;
(2)产生频繁k(2→end)项集;
(3)产生频繁候选k项集;
①由频繁k-1项集连接成为k项集;
②检测k项集的所有的k-1子集是否为频繁项集,若是该k 项集就成为了频繁候选项集;
(4)扫描事务数据库D对每个候选k项集计数。
(5)达到最少支持度的频繁候选k项成为频繁k项集。
3 关联规则在中职学校管理系统中的应用
3.1 数据分析过程
实验使用的数据为桂林市卫生学校2013、2014、2015级学生的数据,数据分析过程如下图2,从原始数据到发现规则的过程大致要经过数据的准备、预处理、数据挖掘与结果分析四个步骤。
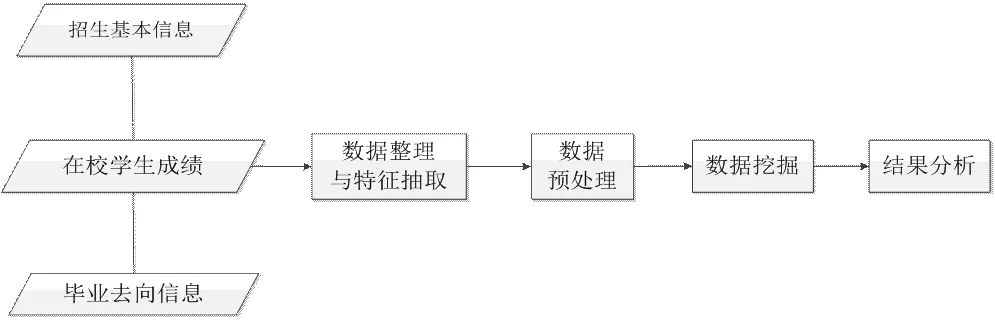
图2数据分析过程
3.2 关联规则挖掘算法在中职招生中应用
在桂林市卫生学校学生数据集合中,既存在布尔型的数据(如学生的性别、家庭住址),又存在数值型的数据(如学生的成绩)。根据数据的特征,选用Apriori作为数据挖掘算法,发现数据集合之间的关联关系。将桂林市卫生学校学生的入学成绩与毕业信息进行数据关联分析,得出有利于选拔优质生源的有用信息。对2010-2012年学生的入学成绩信息、在校成绩信息和毕业信息进行分析,设定支持度=10%,置信度=30%,挖掘出如表 1 所示的参考规则。
表1参考规则

序号参考规则 1初高中学校=重点学校→毕业生质量=优 2初高中学校=重点学校→毕业生质量=良 3入学成绩(平均分)=A或B→毕业生质量=优 4入学成绩(平均分)=A或B→毕业生质量=良 5入学成绩(语文)=A或B→毕业生质量=差 6入学成绩(语文)=C或D→毕业生质量=差 7在校成绩(平均分)=A或B→毕业生质量=优 8在校成绩(政治)=A或B→毕业生质量=差 9在校成绩(政治)=C或D→毕业生质量=优 ……
数据挖掘的结果在实际中不一定存在必然的联系,要结合实际情况对得到的关联规则加以分析,通过设置不同的支持度阀值和置信度阀值,可以得到不同的关联规则。将规则库加以调整,为招生工作提供辅助支持。例如:表1挖掘的规则是学生的生源入学成绩与毕业生是否优秀之间的关联规则,先判断产生的子集是否属于生源特征资料维的,满足这个条件才能挖出规则来。这样可以有效地滤除有意义的关联规则,减少数据的冗余。
参考规则中的规则5和6入学成绩(语文)=A或D→毕业生质量=良,无论学生入学考试语文成绩是高或是低,学生毕业的质量都不是优,此条规则在挑选生源时没有任何实际意义。而规则3和4入学成绩(平均分)=A或D,学生毕业的质量则是可以直观看出,可见可以通过平均分来判断生源质量是否优秀,此信息可以提供给学校作为是否录取该生的条件。
4 结论
通过将关联规则应用到中职学校招生管理系统,可对生源的质量优劣进行初步的分析和评价。关联规则挖掘提供了一个进行合理挖掘的模式和挖掘方向,加快了挖掘速度、减少了数据的冗余度,为该中职专院校招生管理提供了一个方向。
招生阶段是整个学生培养周期的最初阶段,高质量的生源是学生培养质量的有力保证。数据挖掘技术作为中职专院校管理学生信息工作的有力工具,不但可以提高信息管理工作的效率,还对招生工作及相关政策的制定有一定的指导和帮助。数据挖掘技术在中职学生信息分析中可以发挥重要的作用,为制定科学的教育策略提供依据。只要选择合适的分析对象、进行合理的算法选择,数据挖掘技术将在教育领域的其它方面获得更多应用。
[1]王毅鹏.高职院校招生与就业管理信息系统的研究与实现[D].西安电子科技大学,2012.
[2]王晖,王琪,何琼.数据挖掘理论与实例[M].北京:经济科学出版社,2012.
[3]郭涛,张代远.基于关联规则数据挖掘Apriori算法的研究与应用[J].计算机技术与发展,2011.
[4]冯璐妹,赵建宁.基于Apriori的高效关联规则挖掘算法在教育考试系统中的应用研究[J].软件,2013.
[5]Huang Hong-zhi,Cai Yan-rong.Web-based design of the management information system for the chemical laboratory in the university. International Conference on Computer Design and Applications(ICCDA),2010.
桂林市科学研究与技术开发计划项目(2016010406-4)。
猜你喜欢
文教资料(2022年1期)2022-04-08
大众投资指南(2021年35期)2021-02-16
今日农业(2020年15期)2020-12-15
中国交通信息化(2020年1期)2020-07-27
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
中国民政(2016年12期)2016-09-16
中国老区建设(2016年2期)2016-02-28
信息通信技术(2015年6期)2015-12-26
智能系统学报(2013年1期)2013-01-28
