
利用RNNLM面向主题的特征定位方法*
2017-10-12 03:40尹春林熊文军周小煊
计算机与生活 2017年10期
尹春林,王 炜,2+,李 彤,2,何 云,熊文军,周小煊
1.云南大学 软件学院,昆明 650091
2.云南省软件工程重点实验室,昆明 650091
利用RNNLM面向主题的特征定位方法*
尹春林1,王 炜1,2+,李 彤1,2,何 云1,熊文军1,周小煊1
1.云南大学 软件学院,昆明 650091
2.云南省软件工程重点实验室,昆明 650091
Abstract:Software feature location is the guarantee of software evolution.Textual based feature location method is an important part of the current research on feature location.The current feature location method based on text regards the code key words as the independent identically distributed individual,and ignores the context of the code.For this question mentioned above,this paper proposes a source code topic modeling method by using deep learning language model RNNLM(recurrent neural networks language model),and realizes localization features on this basis.The experimental results show that the precision rate is improved by 8.61%and 2.61%compared with the text feature localization based on LDA(latent Dirichlet allocation)and LSI(latent semantic indexing),indicating that the method has better precision.
Key words:software feature location;software evolution;RNNLM;topic modeling
软件特征定位是软件演化活动顺利展开的保证。基于文本的特征定位方法是目前特征定位研究的一个重要组成部分。当前基于文本的特征定位方法将代码关键词视为独立同分布的个体,忽略了代码间的语境。针对上述问题,基于深度学习语言模型RNNLM(recurrent neural networks language model)提出了一种源代码主题建模方法,并在此基础上实现了特征定位。实验结果表明,与基于LDA(latent Dirichlet allocation)和LSI(latent semantic indexing)的文本特征定位相比较,查准率提高8.61%和2.61%,表明该方法具有较优的查准率。
软件特征定位;软件演化;RNNLM;主题建模
1 引言
特征定位(feature location)[1]也被称为概念定位(concept location)[2-3]或者软件侦测(software reconnaissance)[4],是程序理解领域一个重要的组成部分[5-6]。该研究旨在建立特征与源代码之间映射关系,而特征(features)[1]是指可被定义和评估的软件功能属性。
对特征定位的研究最早可以追溯到1992年,Wilde等人提出了最早的特征定位方法——软件侦测(software reconnaissance)[4]。在软件维护/演化领域,没有任何一个维护/演化任务能够脱离特征定位的支持[1,7]。维护/演化活动是在现有系统的约束下实施的受限开发。因此,理解特征与代码之间的映射关系,并据此确定执行维护/演化活动的起始点和范围,是成功实施维护/演化活动的基础。确定维护/演化活动影响范围的过程称为波及效应分析[8-9]。该分析的前提通常是使用特征定位方法确定维护/演化活动的起始点[1]。可追溯性复原[10]试图建立软件实体(代码、需求文档、设计文档等)之间的映射关系。特征定位旨在建立软件功能属性与源代码之间的映射关系,因此可以认为特征定位研究是可追溯性复原研究的一个重要组成部分。建立高效的特征定位方法不仅可以丰富程序理解研究内涵,同时对推动多个研究领域的共同发展具有重要意义。
按分析方式的不同特征定位可以分为静态特征定位、动态特征定位、基于文本的特征定位和混合特征定位。经过实验验证,基于文本的特征定位较静态特征定位和动态特征定位具有较高的查准率,因而受到了业界的广泛重视。
当前基于文本的特征定位方法大致可以分为3类:基于模式识别、基于自然语言处理和基于信息检索的特征定位方法。基于模式识别的特征定位方法是3种方法中最简单的一种,其思想是程序员使用正则表达式描述软件特征,定位算法根据特征描述对代码进行检索,并将检索结果作为特征定位结果进行输出。
基于自然语言处理的特征定位方法试图将自然语言处理在词性标注、分词、组块分析等方面的研究成果嫁接于特征定位问题。而实验证明,基于自然语言处理的特征定位方法较基于模式匹配的特征定位方法在查准率和执行效率方面都有不同程度的提高。
基于信息检索的特征定位方法顾名思义是将信息检索领域成熟的方法应用于特征定位问题。其思想是程序员使用自然语言对特征进行描述,通过度量特征描述与代码之间的语义相似度实现特征定位。基本计算流程如下:
(1)生成语料库。根据不同的粒度,为源代码中每一个实体(类、方法等)建立一个文本文件。文件中保存着代码实体中出现过的关键词。所有文本文件构成语料库。
(2)预处理。包含去除停词(stop words)、分词、词干还原三部分。在去除停词步骤中将删除与特征知识不相关的词,例如代码中出现的冠词、不定冠词等。代码中的变量名经常按照一定的法则由多个实词组合而成(例如驼峰命名法)。分词操作将连续的字符序列按照一定的规则拆分成若干单词,例如tableOpen拆分成为table和open两个词。词干还原将意义相近的同源词和同一个单词的不同形态进行归并,例如inserting还原成为insert。
(3)数值化表示。将经过预处理的语料转换为便于计算的数值化形式。常见的数值化方法是基于“词袋”模式[11]的Document Term Matrix[12]矩阵或TFIDF[13]矩阵。
(4)特征描述数值化表示。将程序员提供的特征描述数值化,使之与经过转换的代码矩阵具有相同的维度。
(5)特征定位。使用信息检索算法对步骤(3)生成的源代码矩阵进行索引、语义分析、主题建模等操作。计算特征描述与信息检索结果之间的相似度。设定阈值,凡大于阈值的代码实体被认为是特征定位结果。
常用的信息检索方法有隐语义索引(latent semantic indexing,LSI)[14]、隐狄利克雷分布(latent Dirichlet allocation,LDA)[15]、向量空间模型(vector space model,VSM)[16]、依赖性语言模型(dependence language model,DLM)[17]。由于代码也是一种特殊的文本,致使信息检索技术应用于特征定位研究并不需要太多的转换,从而定位算法查准率较传统动态、静态定位方法有所提高[1,5],恰当地发挥了信息检索研究成果对特征定位研究的支持。然而,基于信息检索的特征定位方法在实践中也暴露出一些问题。代码的数值化抽象是特征定位的基础,但源代码具有区别于自然语言的构词法则(例如变量的驼峰构词法)、关键词(例如编程语言定义的操作符)、段落标识(自然语言以回车符作为段落标识,而程序则以“}”等符号作为标识)、关键词上下文语义关联性更弱等特点。当前主流的代码数值化方式(LDA、LSI等)均使用“词袋”模型[11],即认为源代码对应的概率分布函数仅与关键词本身有关,与关键词的上下文环境无关,是一种上下文无关模型。该模型的缺陷在于:(1)无法刻画代码上下文对关键词的影响;(2)非平滑性,测试数据中若有一些关键词在训练数据中没有出现,导致整个代码的概率为0;(3)代码向量维度高、稀疏,给后续计算造成了维度灾难(curse of dimension)。
针对当前基于信息检索特征定位方法存在的问题,本文提出了一种基于深度学习语言模型RNNLM(recurrent neural networks language model)的面向主题的特征定位方法。
本文的主要贡献有以下几方面:
(1)利用深度学习语言模型RNNLM获取程序上下文语义,以期支持特征定位。
(2)提出了代码类标定义方法。RNN(recurrent neural network)属于监督学习,需要带标签数据,源代码本身没有标签数据,本文以“类”为粒度,提出了一种代码标签定义方法。
(3)源代码数值化。即词向量的生成,将源代码数值化可以更精准、良好地表达文本上下文语义相似性关系,使得特征定位的基础更牢靠。
本文组织结构如下:第2章给出了利用深度学习算法RNN进行特征定位的基本框架。第3章对实验环节进行描述,设定了基线方法,设计了实验步骤,并定义了实验效果的量化指标。通过对比基线方法与本文方法的实验结果,对有效性进行了分析。第4章对本实验的不足及将来的研究工作进行总结。
2 本文方法
本文方法框架如图1所示,主要分为三部分:生成语料库,代码数值化转换和特征定位。其中,语料库生成使用文本分析方法,利用循环神经网络语言模型生成词向量,最后对给定查询进行相似度计算并输出按相似度降序的结果,也就是特征定位的过程。

Fig.1 Method frame of this paper图1 本文方法框架图
2.1 生成语料库
一个软件系统可以被划分成不同的功能或者不同的模块,一个主题对应于一个功能或者一个模块。基于文本的特征定位方法[18-19]认为源代码中的变量名、函数名、class(类)名、API函数、注释等关键词中蕴含了丰富的主题知识,可以通过它们建立源代码与特征之间的映射关系。基于RNNLM的特征定位方法本质上是先对语料库进行主题知识建模再对查询语句进行分类,精准的主题划分对主题建模结果的好坏具有决定性的作用,不同粒度的主题划分获得的实验效果也不一样。本文进行方法/函数粒度、类粒度、文件夹粒度和包粒度4种划分。函数级的划分粒度过小,可能需要多个函数才能共同表达一个主题知识,为此需要先进行聚类运算;文件夹和包级别的划分粒度偏大,适合大型软件系统的特征定位。结合本文所选源代码系统,认为“类”级的划分对体现本文方法的主题知识更加理想,因此选择在类一级上进行主题知识分析。主题知识的获取如下:
(1)获取语料
源代码中一个class能够体现一个主题。本文使用的源代码系统是一个完整的原始系统,系统中除了包含类文件还包含其他一些无关文档,因此首先需要从源代码系统中将class文件提取出来。将源代码中的所有class文件提取出来后,就获得了一个初始语料库。
(2)语料标注
由于使用的RNN属于监督学习,在训练时需要有标定的数据,而目前的语料还是无标签数据,接下来的工作就是给这些数据贴上标签。本文使用数字作为标签名,标注方式如表1所示。

Table 1 Labelling method表1 贴标签标记方法
表1表示由3个带标签的class组成的一个语料库,其中第一列表示一个从源代码中提取出来的classID,第二列表示该行所对应class的文本内容,第三列表示该行所对应class的标签。
(3)预处理
传统的文本特征定位需要对获得的语料库进行预处理,主要包含分词、词根还原和去除停用词三方面的操作。分词就是将源代码中的复合词拆分,比如一个方法名由ActionSet组成,则将其拆分为Action和Set两个词;词根还原用于将同义词进行归并,以及将一个词的不同形态进行还原;去除停用词将谓词、运算符等不包含主题知识的词汇剔除。
由于本文使用RNNLM进行特征定位,而RNNLM是可以提取复杂的上下文语义关系的。仅将每一个.java文件里的所有内容提取出来作为一个数据,保留文件中各关键词出现的顺序和形式。因此并不需要像传统的文本特征定位那样进行繁琐的预处理,仅需将代码中的部分注释(有一些注释仅仅表达了开源软件使用的开源协议,对表达程序功能语义毫无作用,为了节省运行时间和计算机资源等,需要对这类符号进行一个简单的处理,处理方式是将它删除)删除后就可以作为输入。这样与传统的文本特征定位相比,本文方法更能完整地保留主题知识。
2.2 代码数值化转换
通常的“词袋”语言模型可以抽象为关键词的概率分布函数。形式化地来说,假设源代码SC是由{w1,w2,…,wn}构成的文本序列,则SC对应的概率分布函数如式(1):

其中,条件概率P(w1),P(w2|w1),…,P(wn|w1,w2,…,wn-1)是源代码联合概率模型P(SC)的参数。之前提到这样的模型存在非平滑,向量维度大、稀疏,无法反映关键词上下文语境等问题。如何将以字符串为基础的源代码抽象为对应的数值化形式,解决传统源代码向量维度大、稀疏,无法反映关键词上下文语境等问题决定了特征定位方法的好坏。本文采用可以对更复杂的上下文进行建模的RNNLM对代码进行抽象。
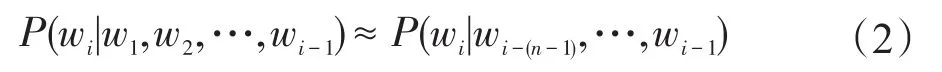
该抽象机制不是像普通的神经网络那样直接对P(wi|wi-(n-1),…,wi-1)进行式(2)这样的近似计算,RNNLM是直接对P(wi|wi-(n-1),…,wi-1)进行建模求解。RNNLM也并不像n-gram model那样对n元近似求解,而是使用迭代的方式对其进行建模求解。RNNLM可以利用所有的上文信息,对当前词进行预测。实验直接利用RNNLM对语料库进行建模,映射出每一个class与其标签的一一对应关系。class与标签名建立对应关系的过程大概如下:
(1)将语料库中每一个class源代码用one-hot表示成词向量。
(2)将第1步生成的词向量进行RNN训练,最终转换成类似于[0.056,-0.267,-0.898,0.111,-0.281,0.567,…]这样的低维实数短向量。
(3)利用第2步获得的词向量通过Softmax建立每个class与其对应类标的映射,即获得RNN隐藏层中的激活函数Softmax的参数θ:

这样的低维实数短向量可以避免传统抽象方法带来的稀疏性,从而可以避免相关或者相似词之间的独立性,两个相似词之间的距离可能就更短了。同时,相似词的词向量之间的距离相近了,这就让基于词向量设计的一些模型自带平滑功能[20-21]。
2.3 特征定位
特征定位是将程序员提供的特征描述与模型中的主题进行匹配的过程,即识别特征描述与哪些程序源代码相关。同样将程序员提交的query(查询语句)经过像2.2节一样的数值化后用RNN进行训练,训练完成后就可以将训练生成的词向量交给2.2节获得的Softmax参数模型进行分类。这一分类过程其实就是计算查询语句的词向量与哪一个class词向量的相似度最高的过程。本质上这也是一个多分类问题。Softmax分类函数如式(3):

Softmax回归其实就相当于多类别情况下的逻辑回归,式(3)中Softmax有k个类,并且函数将(-θ*X)作为指数的系数,因此就有j=1…k项。然后除以它们的累加和,这样做就实现了归一化,使得输出的k个数的和为1。因此Softmax的假设函数输出的是一个k维列向量,每一个维度的值就代表与该维度索引值对应的类出现的概率,比如输出这样一个列向量[0.5,0.3,0.2],0.5就代表第0类出现的概率为0.5。这样计算出每个特征描述与每一个class的概率,然后依次按概率降序排列。为此,获得一个概率相关列表,越在前面的class就是相关度越大的class。本文获得的特征定位的结果就是每个查询语句与每个class的相似度。
3 实验过程及结果分析
为了对实验结果进行客观、有效的评估,将文献[18,23]的方法作为基线方法进行对比论证。
3.1 实验源代码
为了确保实验结果的客观性和正确性,本文使用文献[1]提供的iEdit 4.3[1]基准数据集进行测试。该数据集源代码包含531个类(class),6 400余个方法(method),1.9万行源代码。同时,还有272个通过使用IST(issue tracking system)和SVN(subversion)工具分析获得的特征。每一个特征对应于两个数据文件。
(1)Queries:以“ShortDescription[ID].txt”和“Long-Description[ID].txt”命名的文件,特征的文本描述,该数据主要来源于jEdit版本更新时的改动说明文本。LongDescription是详细描述,ShortDescription是概括性短语描述。在实验中,把ShortDescription作为定位特征时的查询内容。
(2)GoldSet:以“GoldSet[ID].txt”命名的文件,记录了与特征实际相关的源代码,这个数据用于验证定位结果的正确性[22]。
3.2 模型训练
3.2.1 模型挑选
第2章已经介绍了语料库的生成过程,这里就不再做详细介绍。有了语料库,人们就可以对语料库进行建模训练,本文选用RNN语言模型来获取主题知识。对语料库进行简单的预处理后就可以用作实验的输入数据了,但当前的数据还是文本数据,并不能被计算机处理,因此还要将这些数据数值化,即词向量的生成。在RNNLM中词向量的训练生成是伴随着循环神经网络语言模型的训练生成产生的,词向量相当于是以参数的形式存在于RNNLM中。因此本文的词向量与RNN模型是捆绑在一起训练的。
为了能得到一个好的模型,本文设定了一组验证集(实验中因为531个数据没有两个属于同一类,所以验证集同样是531个训练数据中的一小部分),设置验证集的目的是用来选取模型,挑选对验证集预测准确率高的模型来做特征定位。图2是其中训练的两个模型的统计结果,横坐标是训练模型时迭代的次数,纵坐标是验证集准确率。两个模型训练的不同之处是模型1迭代一次训练10个数据,模型2迭代一次训练50个数据,两个模型都迭代了100次。由此可知模型预测的准确率与迭代次数和每次训练的实验数目有关。因为数据集都是不相同的,但又想将每个数据都用于模型的训练,所以验证集就和训练集有交叉,即验证集是训练集的子集。但实验也发现并不是对验证集准确率高的模型特征定位结果的准确率也高。本文选择了模型2这样相对稳定单调的模型来进行下一步的实验。

Fig.2 Comparison of models图2 模型对比
3.2.2 参数设定
本文使用的RNNLM模板并不需要设置太多的参数,其中需要设置的参数有以下几个。
隐藏层(layers)中的Embedding、GatedRecurrent和Dense设置。
(1)Embedding(词向量):size=128;
(2)GatedRecurrent(门机制循环):size=256,激活函数activation=tanh;
(3)Dense(输出设置):size=531,激活函数activation=softmax,训练生成softmax的参数θ,输出531个类。
RNN模型(model)仅有两个参数需要设置。
(1)layers=layers,隐藏层使用上面设置好的layers;
(2)cost=cce,“cce”为以softmax为输出的多分类损失函数。
3.3 实验标准定义
在传统的特征定位中评判实验结果好坏通常使用信息检索中常用的两个指标:查全率(Recall)和查准率(Precision)[22]。
定义1Recall表示查全率,correct代表与特征相关的代码总量,retrieved代表使用特征定位方法检索出来的代码量,则查全率的定义为:

定义2Precision表示查准率,correct代表与特征相关的代码总量,retrieved代表使用特征定位方法检索出来的代码量,则查准率的定义为:

由定义可以看出,查全率和查准率之间存在一定的互逆关系。从定义1可见,特征相关代码总量固定,当增加检索出来的代码量retrieved时会获得较高的查全率,极端情况下检索出所有代码可以获得百分之百的查准率。但从定义2知道,当检索出来的代码量增加也就意味着分母增加,查准率下降。
特征定位的目的是找到特征相关的源代码,并不是很注重查全率的提高,而是更加看重查准率的提升,原因是只有找到一个与特征相关的源代码就可以把接下来的工作交给波及效应分析来处理。传统的基于文本的特征定位方法使用经验阈值α=0.075作为判定文本与特征是否具有相关性的标准[18],但在数据规模较大时,取α=0.075效果并不理想。而文献[22]推荐取相似度最高的10%~15%的源代码作为结果,然而这样的判定方式通常会扩大后续软件演化的范围和降低演化的效率。同时,目前在特征定位中已有很多学者都认为可以通过判定实验检索出代码中第一个与实际特征相关的代码排在第几位来衡量实验方案的好坏。
综上看来,最理想的特征定位应该是只定位出一个相关代码,该代码恰好是与特征相关的代码,接下来的工作交给波及效应分析来进行。传统特征定位在计算查准率时通常取检索结果的前10%~15%(即定义2中的retrieved)来计算,如本实验中有531个class,则取检索出来的高相似度的前10%有53.1个。假设有这样一个例子:在定位特征f时,输入query描述语句,方法检索出来的高相似度的前10%个class为retrieved={r1,r2,…,r50},ri表示检索出来的一个类。假设实际与特征f相关的代码类个数有20个,即correct={c1,c2,…,ci,…,c20},ci表示一个与特征f实际相关的类,假如retrieved中有5个类与correct中的类相同,则查准率约为10%。然而人们并不能确定在retrieved中与correct中相同的这5个类是前5个,最坏的情况可能这5个类在retrieved中是排在最后的5个。在这个例子中用定义2的方法获得的查准率为10%。然而不难发现这种情况下前48个类都不是与特征相关的类,这10%的查准率是虚的,对进行软件维护并没有太大实际意义。因此综合以上几种观点,本实验只检索出一个认为高度与特征实际相关的源代码类来计算查准率,也就是只取前1.9%(1/531)个类进行查准率的计算。此时的查准率计算由定义3进行阐述。
定义3Precision代表查准率,若Ri是实验检索出的与特征i相似度最高的代码,Ri的确与特征i相关,则记Resulti=1,否则Resulti=0,则查准率定义为:
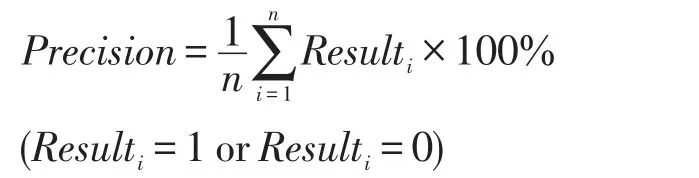
其中,n表示特征的数量。本文对50个特征进行了实验。本实验只检索出一个相似度最高的代码类出来,因此就不做查全率的计算。但认为这不会对实验的评价造成影响。
3.4 实验结果分析
为了验证本文方法的有效性,将文献[18,23]提出的LSI和LDA方法作为基线方法,使用基准数据集进行正面对比实验。本文实验测试了50个数据计算查准率,基线方法仅测试了10个数据。图3是本文方法与两种方法查准率和检索率(即实验检索出来用于计算查准率的代码量与实验代码总量的比值)的对比情况。本文方法获得的平均查准率为11.11%,检索率为1.9%;而基线方法的平均查准率为8.5%和2.5%,检索率却为15.0%和5.0%。
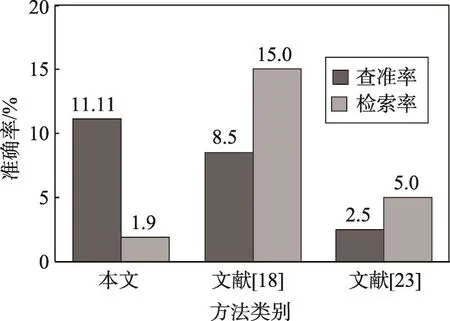
Fig.3 Comparison of experimental result图3 实验结果对比
表2对3种方法的数据进行了对比。从表2中可以看出ArgoUML类个数要比jEdit大,取5%仍然有78个类,jEdit取10%~15%有53~79个类,本文方法测试的数据个数比文献[18,23]都多40个。为了更有效地验证本文方法的有效性和公正性,本文还做了一组自我对照组,同样挑选出了与文献[18]方法相同的10个数据进行了测试,表3是被测试的10个数据,“ID”是每个数据对应的ID号,“GoldSet”是与对应特征实际相关的class数。

Table 2 Test data and retrieve amount表2 测试数据和检索量对比
10个相同数据测试结果如表4。表4中“本文实验1”是测试了50个数据的结果,“本文实验2”是测试了10个实验的结果,然而测试10个数据的查准率为20%,比“本文实验1”测试了50个数据的查准率11.11%和文献[18]方法测试了10个数据的查准率8.5%都要高。这说明在这10个测试中有2个正确地匹配到了相关特征。
通过实验的对比论证可以看出,本文方法较其他方法都有更优的查准率。

Table 3 10 data sets表3 10个数据集

Table 4 10 experimental test results表4 10个实验测试结果
3.5 其他标注方式
使用的RNN是监督学习,监督学习在训练阶段需要有标签数据,而人们常用的基准实验数据集jEdit、muCommander、JabRef和 ArgoUML 等都是无标签数据集,这就需要手动对源代码进行划分。划分的依据是按主题知识进行划分,划分的好坏将会影响分类的结果。作者尝试过不同的划分方式,比如将系统中的同一个文件夹下的所有源代码类划分成一个大类,然而实验发现这样做存在一个问题,数据集jEdit中与实际特征相关的代码是类一级的粒度,那么同一个文件夹下可能有多个类,但这些类都被标注到了同一个类簇中,最后定位出来的就是同一个文件夹下的所有类,这个类簇中包含类的数量多少不一,有的与实际特征相关,有的不相关。这样即使定位出一个文件夹,也不能确定该文件夹下的这些类到底哪一个与特征更相关,即不能够确定该文件夹下的类的相关权重,因此还要进行二次筛选。这就给计算查准率等带来了很大麻烦。
定义4假设S是源代码系统,该系统包含50个文件夹,S={s1,s2,…,si,…,s50},si是该系统中的一个文件夹,该文件夹包含n(n<531)个类,T是S的一个子集T={t1,t2,…,ti},i≤50,其中ti文件夹下至少包含一个源代码类。ti={c1,c2,…,ci},i<531,ci代表一个类。
每一个文件下的类能表达同一个主题知识,于是将系统S按文件夹划分成50个类簇,每个类簇至少包含一个类对象,到此已给系统S贴上标签,接下来用RNN训练,最后进行特征定位。然而按这样的思路定位出来的是一个类簇,而每个类簇的类对象个数多少不一,有的甚至多于源代码总类个数的15%,而有的仅有一个类,这样划分得出的结果难以确定每一个文件夹下哪些类是与相关特征有关。
4 小结及未来研究方向
自从2006年Hinton等人提出深度学习到现在,其在很多领域取得了令人瞩目的成就,特别是在语音、图像识别和自然语言处理等方面。然而基于文本的特征定位大部分工作是与文本打交道,本文提出运用深度学习算法RNN来进行基于文本的特征定位。与传统的软件特征定位不同,深度学习在训练模型前运用了数值化的方式对文本进行预处理,使特征的主题知识得以更完好地保存下来,这就避免了分词、停词、词根还原和使用TF-IDF矩阵来表达主题知识产生的特征表达不好的短板,对后来主题知识的分类打下了很好的基础。同时由于波及效应分析的发展,缩小检索范围对软件演化、软件维护更具有实际意义。目前一些学者认为可以通过评估检索出来的代码中第一个与实际特征一致的代码排在第几个位置来评估实验方案的好坏,本文只是用提取出的代码中相似度最高的一个代码类来做查准率的计算,自然也就去掉了查全率的计算,但是这样评估研究结果的查准率更有助于后续软件演化效率的提高。然而本文利用最低的检索量获得了更高的查准率,从另一方面来说这也是特征定位最理想的状况,也更具有普遍意义和实际意义。
RNN是一个监督学习,需要有标注的数据集,但是通常用在特征定位的数据集都是无标签数据集,并且数据标签标注的标准、粒度及方法等都会影响到领域主题知识的表达。实验中尝试将同一个文件夹下的所有类划分成同一个主题,但并没有取得很好的效果。这也提示人们探索更好的标注方式。
同时,训练RNN需要大量的数据集才能取得良好的效果,而本文实验采用的是jEdit4.3按类级粒度进行划分,划分后仅有531个数据集,这对本文的模型训练增加了一定的难度。因此未来可以将数据集划分粒度减小一些,比如按方法进行划分,或者找一个更大的系统来进行训练,以获得更好的结果。同时希望在目前的基础上增加动态层来提高查准率。
[1]Dit B,Revelle M,Gethers M,et al.Feature location in source code:a taxonomy and survey[J].Journal of Software Maintenance&Evolution Research&Practice,2013,25(1):53-95.
[2]Abebe S L,Alicante A,Corazza A,et al.Supporting concept location through identifier parsing and ontology extraction[J].Journal of Systems and Software,2013,86(11):2919-2938.
[3]Scanniello G,Marcus A,Pascale D.Link analysis algorithms for static concept location:an empirical assessment[J].Empirical Software Engineering,2015,20(6):1666-1720.
[4]Wilde N,Gomez JA,Gust T,et al.Locating user functionality in old code[C]//Proceedings of the 1992 Conference on Software Maintenance,Orlando,USA,Nov 9-12,1992.Piscataway,USA:IEEE,1992:200-205.
[5]Alhindawi N,Alsakran J,Rodan A,et al.A survey of concepts location enhancement for program comprehension and maintenance[J].Journal of Software Engineering and Applications,2014,7:413-421.
[6]Dit B,Revelle M,Poshyvanyk D.Integrating information retrieval,execution and link analysis algorithms to improve feature location in software[J].Empirical Software Engineering,2013,18(2):277-309.
[7]Rajlich V,Gosavi P.Incremental change in object-oriented programming[J].IEEE Software,2004,21(4):62-69.
[8]Li Bixin,Sun Xiaobing,Leung H,et al.A survey of codebased change impact analysis techniques[J].Software Testing,Verification&Reliability,2013,23(8):613-646.
[9]Wang Wei,Li Tong,He Yun,et al.A hybrid analysis method for ripple effect of software evolution activities[J].Journal of Computer Research and Development,2016,53(3):503-516.
[10]Lucia A D,Marcus A,Oliveto R,et al.Information retrieval methods for automated traceability recovery[M]//Software and Systems Traceability.London:Springer,2012:71-98.
[11]Wikipedia.Bag of words model[EB/OL].[2016-07-18].https://en.wikipedia.org/wiki/Bag-of-words_model.
[12]Salton G,Buckley C.Term-weighting approaches in automatic text retrieval[J].Information Processing&Management,1988,24(5):513-523.
[13]Robertson S.Understanding inverse document frequency:on theoretical arguments for IDF[J].Journal of Documentation,2004,60(5):503-520.
[14]Dumais S T,Dumais S T,Landauer T K,et al.Latent semantic analysis[J].Annual Review of Information Science and Technology,2004,38(1):188-230.
[15]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[16]Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[17]Gao Jianfeng,Nie Jianyun,Wu Guangyuan,et al.Dependence language model for information retrieval[C]//Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Sheffield,UK,Jul 25-29,2004.New York:ACM,2004:170-177.
[18]Marcus A,Sergeyev A,Rajlich V,et al.An information retrieval approach to concept location in source code[C]//Proceedings of the 11th Working Conference on Reverse Engineering,Delft,Netherlands,Nov 8-12,2004.Washington:IEEE Computer Society,2004:214-223.
[19]Petrenko M,Rajlich V,Vanciu R.Partial domain comprehension in software evolution and maintenance[C]//Proceedings of the 16th International Conference on Program Comprehension,Amsterdam,Jun 10-13,2008.Washington:IEEE Computer Society,2008:13-22.
[20]Licstar.Deep learning in NLP[EB/OL].[2016-07-18].http://licstar.net/archives/328.
[21]Lai Siwei.Word and document embeddings based on neural network approaches[D].Beijing:University of Chinese Academy of Sciences,2016.
[22]Ju Xiaolin,Jiang Shujuan,Zhang Yanmei,et al.Advances in fault localization techniques[J].Journal of Frontiers of Computer Science and Technology,2012,6(6):481-494.
[23]Han Junming,Wang Wei,Li Tong,et al.Feature locationmethod of evolved software[J].Journal of Frontiers of Computer Science and Technology,2016,10(9):1201-1210.
附中文参考文献:
[9]王炜,李彤,何云,等.一种软件演化活动波及效应混合分析方法[J].计算机研究与发展,2016,53(3):503-516.
[21]来斯惟.基于神经网络的词和文档语义向量表示方法研究[D].北京:中国科学院大学,2016.
[22]鞠小林,姜淑娟,张艳梅,等.软件故障定位技术进展[J].计算机科学与探索,2012,6(6):481-494.
[23]韩俊明,王炜,李彤,等.演化软件的特征定位方法[J].计算机科学与探索,2016,10(9):1201-1210.
Using RNNLM to Conduct Topic Oriented Feature Location Method*
YIN Chunlin1,WANG Wei1,2+,LI Tong1,2,HE Yun1,XIONG Wenjun1,ZHOU Xiaoxuan1
1.College of Software,Yunnan University,Kunming 650091,China
2.Key Laboratory for Software Engineering of Yunnan Province,Kunming 650091,China






A
TP311.5
+Corresponding author:E-mail:wangwei@ynu.edu.cn
YIN Chunlin,WANG Wei,LI Tong,et al.Using RNNLM to conduct topic oriented feature location method.Journal of Frontiers of Computer Science and Technology,2017,11(10):1599-1608.
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2017/11(10)-1599-10
10.3778/j.issn.1673-9418.1609035
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
*The National Natural Science Foundation of China under Grant Nos.61462092,61262024,61379032(国家自然科学基金);the Key Project of Natural Science Foundation of Yunnan Province under Grant No.2015FA014(云南省自然科学基金重点项目);the Natural Science Foundation of Yunnan Province under Grant No.2013FB008(云南省自然科学基金);the Science Research Fund of Yunnan Provincial Department of Education under Grant No.2016YJS007(云南省教育厅科学研究基金).
Received 2016-09,Accepted 2016-11.
CNKI网络优先出版:2016-11-25,http://www.cnki.net/kcms/detail/11.5602.TP.20161125.1530.006.html
YIN Chunlin was born in 1991.He is an M.S.candidate at Yunnan University,and the member of CCF.His research interests include software engineering,software evolution and data mining.
尹春林(1991—),男,云南保山人,云南大学硕士研究生,CCF会员,主要研究领域为软件工程,软件演化,数据挖掘。主持云南省教育厅科学基金研究生项目1项。
WANG Wei was born in 1979.He received the Ph.D.degree in system analysis and integration from Yunnan University in 2009.Now he is an associate professor at Yunnan University,and the member of CCF.His research interests include software engineering,software evolution and data mining.
王炜(1979—),男,云南昆明人,2009年于云南大学系统分析与集成专业获得博士学位,现为云南大学副教授,CCF会员,主要研究领域为软件工程,软件演化,数据挖掘。发表学术论文15篇,出版教材1部,主持省部级项目5项。
LI Tong was born in 1963.He received the Ph.D.degree in software engineering from De Montfort University in 2007.Now he is a professor and Ph.D.supervisor at Yunnan University,and the senior member of CCF.His research interests include software engineering and information security.
李彤(1963—),男,河北石家庄人,2007年于英国De Montfort大学软件工程专业获得博士学位,现为云南大学软件学院院长、教授、博士生导师,CCF高级会员,主要研究领域为软件工程,信息安全。发表学术论文100余篇、专著2部、教材5部,主持国家级项目5项、省部级项目14项、其他项目20余项。
HE Yun was born in 1989.He is a Ph.D.candidate at Yunnan University,and the student member of CCF.His research interests include software engineering,software evolution and data mining.
何云(1989—),男,云南建水人,云南大学博士研究生,CCF学生会员,主要研究领域为软件工程,软件演化,数据挖掘。
XIONG Wenjun was born in 1988.He is an M.S.candidate at Yunnan University.His research interests include software repository mining and software requirement prediction.
熊文军(1988—),男,云南临沧人,云南大学硕士研究生,主要研究领域为软件仓库挖掘,软件需求预测。
ZHOU Xiaoxuan was born in 1993.She is an M.S.candidate at Yunnan University,and the student member of CCF.Her research interests include software engineering,software evolution and data mining.
周小煊(1993—),女,吉林长春人,云南大学硕士研究生,CCF学生会员,主要研究领域为软件工程,软件演化,数据挖掘。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代信息科技(2021年21期)2021-05-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
农家书屋(2016年11期)2016-12-23
世界汽车(2016年9期)2016-09-29
高中生学习·高三版(2016年9期)2016-05-14
