
藏文自动分词系统中虚词识别算法研究
2017-09-23 02:57:24拉巴顿珠赵栋材
计算机应用与软件 2017年9期
拉巴顿珠 欧 珠 赵栋材
1(西藏大学藏文信息技术研究中心 西藏 拉萨 850000)2(西藏民族大学 陕西 咸阳 712082)
藏文自动分词系统中虚词识别算法研究
拉巴顿珠1欧 珠2赵栋材1
1(西藏大学藏文信息技术研究中心 西藏 拉萨 850000)2(西藏民族大学 陕西 咸阳 712082)
在分析现有藏文自动分词方法的基础上,针对藏文分词系统中虚词识别的难点进行深入研究。根据传统藏文文法,描述了藏文虚词在文本中不同的表现形式,用规则和统计相结合的方法,建立了较为全面的虚词知识库和规则库,并给出切分用虚词分块算法,该方法在不同领域的3 200个较典型的藏文句子进行了测试,结果表明,该方法的虚词识别率高达98%以上。
藏文自动分词 藏文信息处理 虚词识别 藏文虚词
0 引 言
藏文自动分词研究是藏文自然语言处理的前提,是藏文信息处理的一项不可缺少的基础性工作,具有广泛的应用前景。藏文自动分词为词性标注、藏文语料库的建设、藏文文本校对、藏文字词频统计、搜索引擎的设计与实现、机器翻译系统的开发、藏文拼写检查以及语句理解等方面的研究奠定良好的研究基础。

1 藏文虚词的解析
1.1 虚词的概述
在语言学中,词分为实词和虚词两大类,实词指的是具有实际意义的词,是藏文自动分词中独立运用而能够表达一定意义的最小分词单位。虚词是与实词相对而言的,在文本或者句子中不能表达任何意义,也不能独立承担句子的主要成分。虚词本身没有实在意义,也没有词性变化,但一个文本或句子中没有虚词就不能形成完整的语句,也不能表达出完整的含义。在自然语言处理中,藏语虚词对词法和句法结构起着至关重要的桥梁纽带作用,虚词的用途广,在句子结构中用法和意义十分复杂,出现的频率相当高。在实现藏文自动分词系统中的主要难点之一,因此,信息处理用藏文虚词识别研究很重要。

1.2 计算机识别藏文虚词的难点


2 虚词识别算法
计算机识别藏文虚词根据虚词本身的特点和难点分析出发,按照一定的先后顺序进行判断,首先通过虚词兼类词典、单字词典、规则的不自由虚词词典库等进行划分,再识别紧缩词并还原,最后结合中嵌否定词、指人后缀来判断藏文虚词,如图1所示。
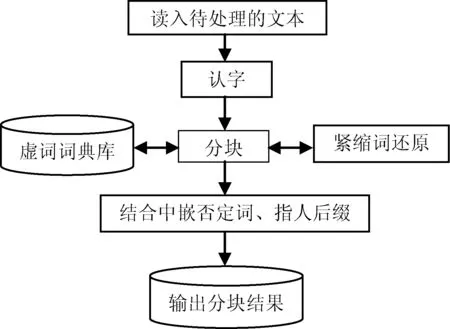
图1 文本中藏文虚词的识别过程
2.1 藏文虚词的识别过程
计算机识别虚词的首要工作就是建立一个相对全面的词典库,为了提高词典库的质量,需要采用规则和统计相结合的方法,并进行大量的人工训练和测试。另一方面,经实验和研究发现,藏文虚词在文本中表现形式相对复杂,单一形式的词典不能满足需求,因此要按照虚词在文本中的不同表现形式,建立几种不同的虚词词典(词典命名为xcself)。


(3) 不自由虚词词典(xcself3):收录需要根据不自由虚词的接续规则识别的藏文虚词,该词典格式为:<虚词—前导字符—后接字符>。
2.2 紧缩词识别及还原
根据紧缩词的变体性及特殊性,分两种情况进行识别,分别是一般紧缩词的识别和特殊紧缩词的识别。
2.3 自由虚词的识别方法
在藏文传统文法中自由虚词没有变体性,而且不受前一个音节后置字的限制,可以自由使用,但自由虚词也并不是不受任何限制而随意使用,在文本中使用自由虚词时也具有一定的接续特点。文中根据自由虚词本身的接续特点和出现歧义的问题,提出了较简单的自由虚词识别方法。
3 测试结果与分析
3.1 测试结果
本文采用的测试语料包含了法律、新闻类、教育类、医学类、诗歌类、文学类等各个领域。从中选择了较典型的3 200句进行测试,同时还考虑了文献的年代、地域等问题。对测试语料进行分词,统计语料中虚词出现的次数并计算准确率(准确率=正确识别的总次数/测试语料中出现的总次数×100%),同时对虚词的兼类性、组合性、结合性、识别紧缩词及还原。实验结果表明,文中提出的方法使虚词的识别率达到98.013 8%。
3.2 结果分析
4 结 语
藏文虚词在文本中出现的频率极高,其应用广泛,表现形式复杂多变。本文基于不同的语境中虚词的识别率和分词的准确度,根据传统的藏文文法,采用统计和规则相结合的方法,对较典型的3 200个语料句子进行了测试。实验结果表明,所提出的方法使得虚词的识别率有一定的提高。
[1] 格桑居冕.实用藏文文法[M].成都:四川民族出版社,1987.
[2] 卓玛吉.藏文虚词自动识别研究[D].青海:青海民族大学,2014.
[3] 高定国,扎西加,赵栋材.计算机识别藏语虚词的方法研究[J].中文信息学报,2014(1):114-117.
[4] 关白.信息处理用藏文分词单位研究[J].中文信息学报,2010(3):124-128.
[5] 赵栋材.基于虚词切分的藏文分词系统的设计与实现[J].西藏大学学报(自然科学版),2012(2):61-65.
[6] 才智杰.藏文自动分词系统中紧缩词的识别[J].中文信息学报,2009(1):35-37.
[7] 索南才让.面向自然语言处理的藏语虚词la格研究[J].西藏大学学报(自然科学版),2013(2):48-52.
[8] 李亚超.基于条件随机场的藏语自动分词方法研究与实现[J].中文信息学报,2013(4):52-58.
[9] 完么扎西.藏语自动分词中的几个关键问题的研究[J].中文信息学报,2014(4):132-139.
[10] 才让三智,多拉.信息处理中藏语虚词“na”和“la”的标注研究[J].电脑知识与技术,2011,7(4):2441-2445.
RESEARCHONFUNCTIONWORDRECOGNITIONALGORITHMINTIBETANAUTO-SEGMENTATIONSYSTEM
Lhakpa Dondrub1Ngodrup2Zhao Dongcai11
(ResearchCenterofTibetanInformationTechnology,TibetUniversity,Lhasa850000,Tibet,China)2(XizangMinzuUniversity,Xianyang712082,Shaanxi,China)
By analyzing a literature review of present Tibetan Auto-Segmentation solutions, we study on the difficult points of Tibetan function words recognition. According to the traditional Tibetan grammar, we described the forms of Tibetan function words in different texts. A holistic function word dictionary and rules set had been created by a rules-statistics-combined method, and the function words segmentation algorithm had been implemented. We tested the algorithm on a sample corpus which contains 3 200 typical Tibetan sentences from different fields. The results show that the correct recognition rate of our system reaches up to 98%.
Tibetan auto-segmentation Tibetan information-processing Function words recognition Tibetan function words
TP391
A
10.3969/j.issn.1000-386x.2017.09.058
2016-11-08。2015年度西藏大学研究生高水平人才培养项目;2016年教育部人文社会科学研究项目(16XZJCZH 001);2016年西藏自治区自然科学基金项目(2016ZR-15-5)。拉巴顿珠,硕士生,主研领域:藏文信息处理。欧珠,教授。赵栋材,副教授。
猜你喜欢
布达拉(2020年3期)2020-04-13 10:00:07
中文信息学报(2019年7期)2019-08-05 02:28:16
中文信息学报(2019年2期)2019-04-02 03:08:28
西夏学(2019年1期)2019-02-10 06:22:34
中文信息学报(2018年2期)2018-04-16 07:53:36
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
文贝:比较文学与比较文化(2016年1期)2016-11-14 05:00:41
新闻传播(2016年17期)2016-07-19 10:12:05
语文教学与研究(2014年8期)2014-02-28 21:54:53
当代修辞学(2011年6期)2011-01-29 02:49:48
