
基于正文和标题文本分类的主题建模
2017-09-23 03:03:44于秀开徐启南
计算机应用与软件 2017年9期
郑 诚 于秀开 徐启南
(安徽大学计算智能与信号处理重点实验室 安徽 合肥 230039) (安徽大学计算机科学与技术学院 安徽 合肥 230601)
基于正文和标题文本分类的主题建模
郑 诚 于秀开 徐启南
(安徽大学计算智能与信号处理重点实验室 安徽 合肥 230039) (安徽大学计算机科学与技术学院 安徽 合肥 230601)
特征稀疏是对传统文本分类的一个巨大的挑战。基于LDA模型,提出一种特征扩展的短文本分类模型。该模型在正文语料的基础上加入标题语料的主题分布,并进行整合,得到每个文本的主题分布。使用SVM分类器进行分类。实验结果表明,与正文语料进行文本分类相比,所提模型对文本分类效果较好。
文本分类 LDA 特征扩展 主题分布 SVM
0 引 言
随着Web的发展,人民群众可以在网上发布言论和意见,政府部门可以答复人民群众反映的问题。所以许多省、市部门单位都在积极努力做好这项工作。安徽省的各个地级市的政府网站都开通了这一项功能,比如合肥市的12345政府服务直通车(http://www.hefei.gov.cn/hdjl/)。在该网站中,人民群众可以向政府相关部门表达自己的意愿,反映自己在生活中遇到的困难,并向政府寻求帮助,也可以对政府不满意的地方,提出意见、建议,甚至举报。在网站中人民群众更愿意表达自己真实的情况和情感,这样政府就可以真正地了解人民群众的所感所想,更有利于为人民服务,例如表1是合肥市民一条反馈信息。通过观察表1的信息,我们可以发现上面的文本主要包括主题(在后文称为标题),信件内容,回复内容。而且文本较短,对于短文本通常它们的信息特征是:信息量少、特征稀疏、语义依赖上下文等情况[1]。而对于短文本处理的难处就是特征非常稀疏,而传统的文本分类算法有Baycs、SVM、KNN等这些直接应用在短文本分类上效果不佳。
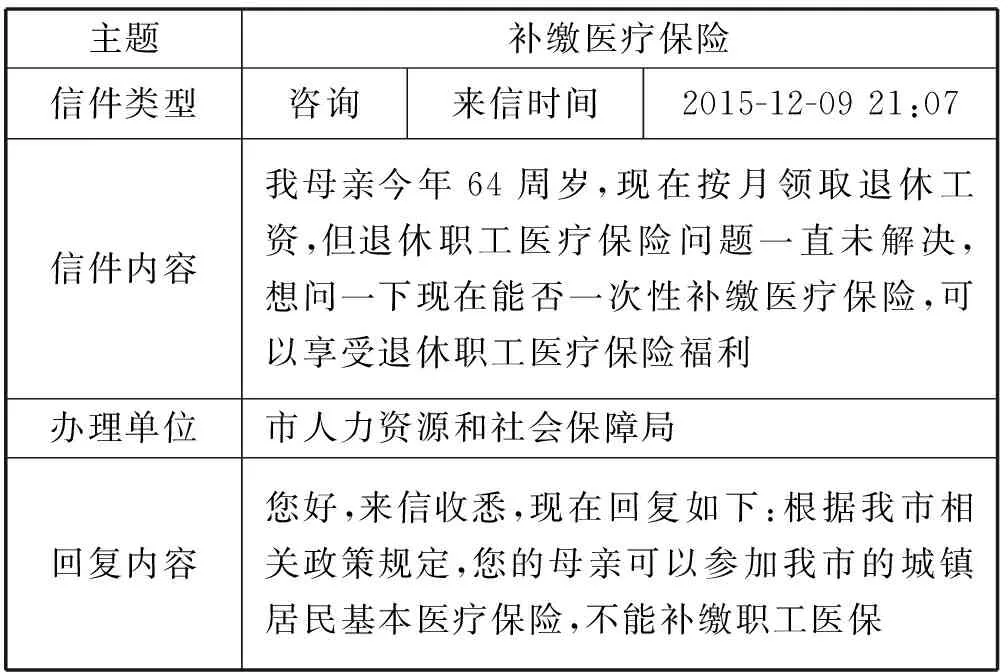
表1 市民反馈信息
1 相关工作
对于短文本的分类处理,主要有两种方法,第一种是增加外部知识域。Wang等[2]在处理短文本分类中,利用一个大的分类知识库,为每个类别建立概念模型,并为每个短文本定义一组概念,通过概念相似性,对短文本进行分类。宁亚辉等[3]提出基于领域词语本体的短文本分类方法,抽取领域高频词作为特征词,借助语义方面将特征词扩展为概念和义元,通过计算不同概念所包含相同义元的信息量来衡量词的相似度,进行文本分类。但是这种借助外部知识域的方法,对于没有在知识域出现的词,效果不佳。另一种是通过为短文本加入更多相关的文本,扩展文本特征进行文本分类。Sriram等[4]为微博文本增加作者的配置文件,提出一种文本分类方法。饶高琦等[5]中通过LDA主题模型获得短文本主题分布,把主题中的词作为短文本的特征,扩充到原短文本中,进行文本分类。Godin等[6]和Mehrotra等[7]利用LDA和微博的标签等特性,进行微博文本分类。基于以上考虑,为了便于本文的描述,文本将正文语料定义为用户的来信内容和回复内容,因为回复内容是政府工作人员回复信息,信息比较充分具体,标题语料定义为用户来信的标题语料。本文将改进LDA主题模型将正文语料和标题语料进行主题整合加权,得到每个文本的主题分布。
2 基于正文和标题短文本分类模型
2.1 命名实体识别
本文是对正文和标题的短文本分类进行建模,实验语料是以合肥政府直通车文本为例,因此在语料中会有大量当地特用的命名实体[8],例如当地市区道路名称、小区名称、公交站名称等。为了提高分词阶段的准确性,因此本文在分词阶段引入了用户词典。从百度地图中获取当地城市特用的命名实体,加入用户词典中,然后基于词典匹配的方法进行分词,以此来提高分词的准确性。见表2是149路公交站的部分命名实体。
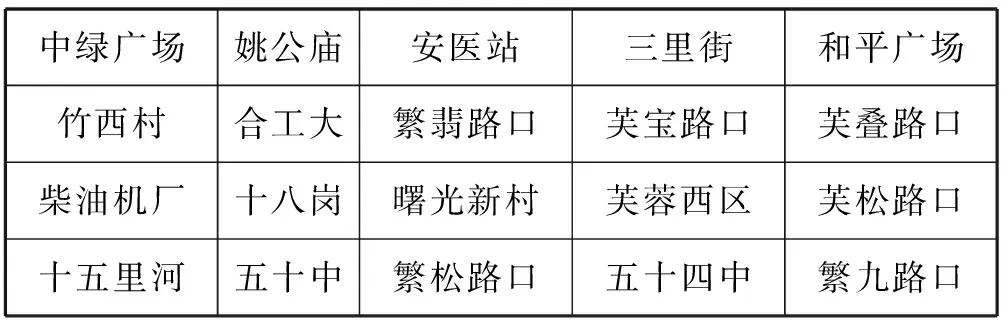
表2 149公交部分命名实体
2.2 LDA主题模型
LDA主题模型[9]是由Blei等提出的,是一个“文本-主题-词”的三层贝叶斯产生式模型,每篇文本表示为主题的混合分布,而每个主题则是词上的概率分布。LDA模型产生一篇文档的过程如下:
(1) 从先验参数α产生一篇文档的主题θ的多项式分布。
(2) 从θ的多项式分布产生一个词的主题Ζ。
(3) 从先验参数β产生词主题φ的多项式分布。
(4) 由词主题分布Ζ和词多项式分布φ产生一篇文档的一个词w。
下面给出LDA生成模型如图1所示。
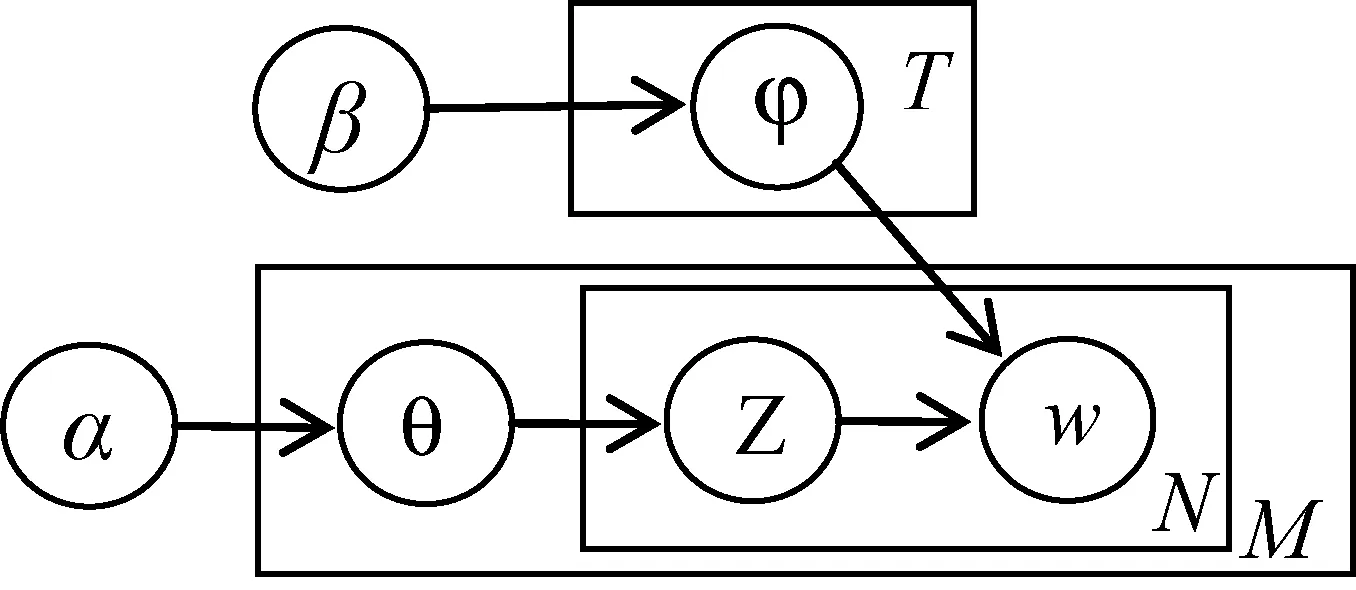
图1 LDA图生成模型
关于LDA的详细介绍和参数请详见文献[9]。
2.3 基于正文和标题短文本分类模型
在各大网站、社团、BBS中,用户在提交自己想法与网友交互时,网站通常要求用户输入问题的标题,为了充分利用标题的信息,本文提出了基于正文和标题的文本分类主题建模。下面给出基于LDA主题扩展的短文本分类的流程图如图2所示。
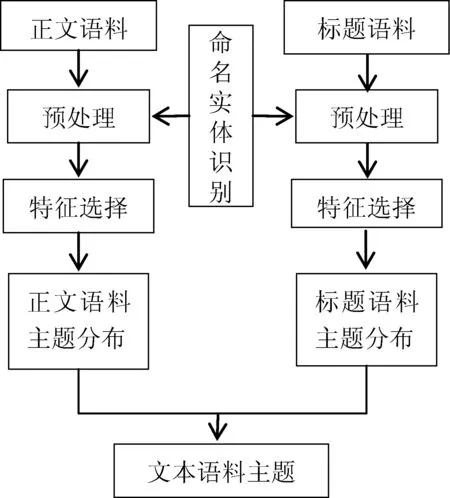
图2 基于LDA主题扩展的短文本分类流程图
2.3.1 预处理
在特征选择之前,本文先要进行文本分词,本文使用的分词工具为张华平博士等开发的ICTCLAS分词工具进行分词。由于本文语料为合肥市政府直通车平台文本,是面向合肥本地人群的意见和建议,所以文本中有大量的合肥当地的命名实体。为了增加分词的准确性,本文加入大量的命名实体作为文本分词的用户词典。在该词典中,加入合肥当地城市的300条主要道路名称,111条公交路线所有公交站名称,150个小区名称等。实验结果如图3所示。本文在最佳主题数35下进行实验,实验中使用命名实体进行分词和未使用命名实体进行分词进行实验。结果表明,在使用命名实体中准确率、召回率和F值都有所提升。
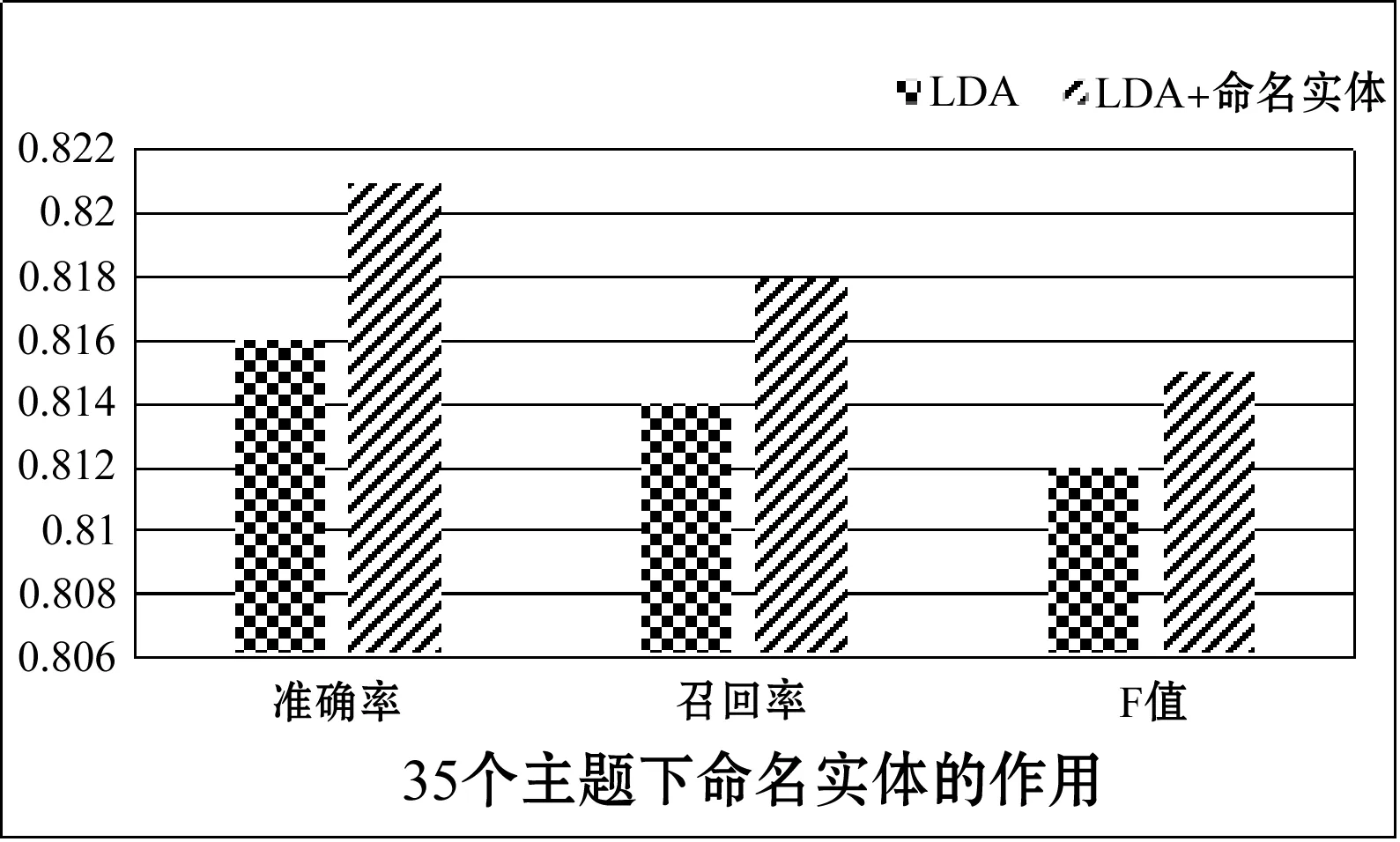
图3 使用命名实体进行分词结果
2.3.2 正文和标题分类模型表示
根据本文文本的特点,包含正文语料和标题语料,文本以直通车文本为例,LDA是基于词袋进行吉布斯采样和训练模型。本文在使用正文语料词袋库进行训练LDA时,引入标题标题语料的词袋库,根据调和参数的不同,即标题信息采样比例不同,获得每篇文本的最佳的主题分布。本文会根据正文语料得到正文语料的主题分布θ1,通过调和参数γ,在LDA中加入标题主题分布θ2,最终获得每一篇文本的最终主题分布θ。解释过程如下:
(1) 从先验参数α产生一篇文档正文文档的主题θ1的多项式分布。
(2) 从先验参数α产生一篇文档标题文档的主题θ2的多项式分布。
(3) 通过γ整合θ1、θ2为θ多项式分布。
(4) 从θ多项式分布产生一个词的主题分布Ζ。
(5) 从先验参数β产生词主题φ的多项式分布。
(6) 由词的主题分布Ζ和词的多项式分布φ产生一篇文档的一个词w。
下面是文本正文和标题模型的表示和表达式,如图4所示。

图4 扩展模型表示
在此给出本模型的参数估计,如图4的概率模型中,M为文档总数,N为一个文档的所有词的个数,α是每个文档主题的狄利克雷的先验参数,β是每个主题下词的狄利克雷的先验参数,Z表示一篇文档中词的主题。θ1是隐含变量表示一篇文档的正文的主题分布,θ2是隐含变量表示一篇文档的标题的主题分布,φ表示一个主题下词的分布。利用调和参数γ,使:
θ=γ×θ1+(1-γ)×θ2γ∈(0,1)
(1)
在语料具有正文和标题的文本中,在对正文语料进行主题建模的过程中,引入标题语料的信息并进行整合,获得整篇文本的主题分布,通过公式推导可以得到新的文本主题分布的Gibbs采样公式,通过对比LDA模型发现,由于引入标题语料的主题因子,文本的主题分布如下:

(2)
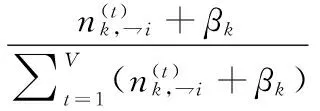
(3)
根据式(2)、式(3),最终得到联合概率分布函数如下式:
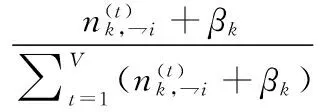
(4)
根据吉布斯采样过程,反复迭代,对标题和正文中词的每个主题进行抽样,直到结果收敛,输出文档下的主题分布θmk和主题下词的分布φkt。
3 实 验
3.1 实验语料
本文基于正文和标题的文本分类建模,以合肥政府直通车文本为例,使用爬虫软件,从合肥政府直通车网站爬取了包含拆迁规划、房产、公积金、公交交通、社保就业、环境卫生、教育、物业、治安、公共事业等10大类语料。其中社保就业2 322条,公积金1 006条,环境卫生2 636条,教育1 632条,拆迁规划400条,房产509条,公共事业793条,治安203条,公交交通1 639条,物业3 301条。
3.2 对比试验、评估方法和分类器
本文的对比实验设置是正文语料的LDA模型,正文语料的BTM模型,BTM主题模型是晏小辉教授在2013年的会议上提出的一个优秀的主题模型[10]。为了评判与其他模型文本分类算法的性能,本文的评估方法为传统文本分类的标准:准确率P、召回率R和F值。
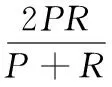
(5)
本文使用的分类器为SVM分类器,验证使用十字交叉法。
3.3 实验结果
文本在确定LDA主题模型的主题数时,设置主题数从10~70(间隔为5)进行实验验证,实验结果如图5所示。从图中可以发现在主题数为35时,LDA、BTM和本文模型的F值都达到了平稳状态,当主题数大于35时,F值波动不大,所以文本的最佳主题数为35。根据经验这里把先验参数α设置为0.5、β设置为0.01,迭代次数为1 000次。
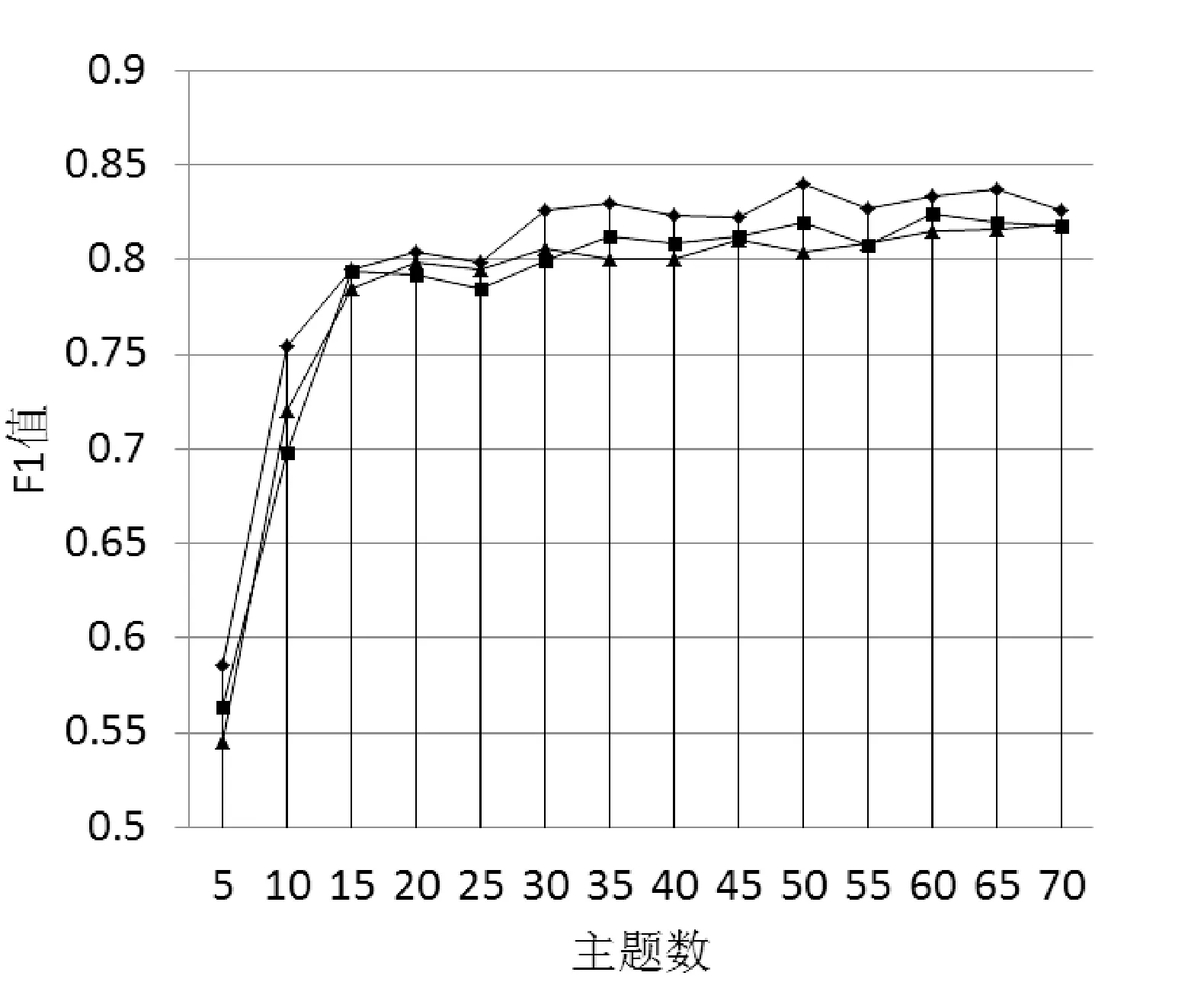
图5 主题参数的确定
本文通过使用调和参数γ将正文语料的主题分布和标题语料的主题分布整合为一篇文档的最终主题分布。为了得到调和参数γ最优解,本文在分类数据集中,根据不同主题,调和参数的变化,得到各个主题下F值,通过F值的变化,确定γ的最优解。实验结果如图6,横坐标表示调和参数,纵坐标表示F值,曲线是每个主题下F值随调和参数的变化曲线,通过实验结果发现,在各个主题下,当调和参数γ=0.7时,F值最佳,所以文本的调和参数设为0.7。
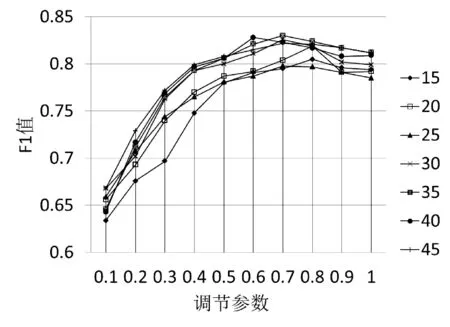
图6 γ参数的确定
为了验证文本模型可以利用标题文本信息的作用,本文使用政府直通车的标题语料和正文语料应用在基于正文和标题文本分类的主题模型中。正文语料上应用LDA模型即只考虑正文的作用,没有利用标题的信息因子,BTM模型使用正文语料。实验结果如表3所示。本文方法在准确率、召回率和F值都优于LDA和BTM模型,证明本文模型可以充分利用标题信息对文本进行分类。
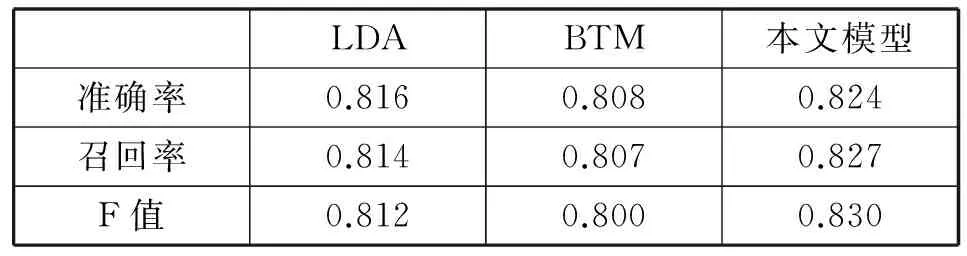
表3 实验对比结果
4 结 语
特征稀疏文本一直是短文本分类的问题,现在文本分类大多基于内容,往往忽略标题信息的作用。为了提高分类的效果,本文利用网站语料的特点,加入了标题语料的主题分布,提出了基于正文和标题的文本分类的主题建模,对文本特征进行扩展。以政府直通车语料为例,实验表明当加入标题语料的信息后,分类效果比只基于正文内容所提升,本文模型对于具有标题和正文的语料分类效果较为明显。另外本文为了解决分词作用的困难,加入了大量的命名实体,增加了分词的正确性。最后本文仅仅是将文本进行分类,下面的工作将引入时间序列因素进一步提高分类效果。
[1] 贺涛,曹先彬,谭辉.基于免疫的中文网络短文本聚类算法[J].自动化学报,2009,35(7):896-902.
[2] Wang F,Wang Z,Li Z,et al.Concept-based short text classification and ranking[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management.ACM,2014:1069-1078.
[3] 宁亚辉,樊兴华,吴渝.基于领域词语本体的短文本分类[J].计算机科学,2009,36(3):142-145.
[4] Sriram B,Fuhry D,Demir E,et al.Short text classification in twitter to improve information filtering[C]//Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval.ACM,2010:841-842.
[5] 饶高琦,于东,荀恩东.基于自然标注信息和隐含主题模型的无监督文本特征抽取[J].中文信息学报,2015,29(6):141-149.
[6] Godin F,Slavkovikj V,De Neve W,et al.Using topic models for twitter hashtag recommendation[C]//Proceedings of the 22nd International Conference on World Wide Web.ACM,2013:593-596.
[7] Mehrotra R,Sanner S,Buntine W,et al.Improving lda topic models for microblogs via tweet pooling and automatic labeling[C]//Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval.ACM,2013:889-892.
[8] 赵军.命名实体识别、排歧和跨语言关联[J].中文信息学报,2009,23(2):3-17.
[9] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[10] Yan X,Guo J,Lan Y,et al.A biterm topic model for shorts texts[C]//Proceedings of the 22nd international conference on World Wide Web.International World Wide Web Conferences Steering Committee,2013:1445-1456.
TOPICMODELINGFORTEXTCLASSIFICATIONBASEDONTEXTANDTITLE
Zheng Cheng Yu Xiukai Xu Qi’nan
(KeyLaboratoryofICSP,MinistryofEducation,AnhuiUniversity,Hefei230039,Anhui,China) (SchoolofComputerScienceandTechnology,AnhuiUniversity,Hefei230601,Anhui,China)
The sparse feature is a huge challenge for the traditional text classification. We propose a short text classification model based on the LDA model. The model integrated the text with the title on the basis of corpus and obtained topic distribution of each text. We used SVM classifier for classification. The test results demonstrate that our model performs better than traditional text classification based on the text.
Text classification LDA Feature extension Topic distribution SVM
TP391.1
A
10.3969/j.issn.1000-386x.2017.09.016
2016-11-17。安徽省高校自然科学基金重点项目(KJ2013A020)。郑诚,副教授,主研领域:信息检索,自然语言处理。于秀开,硕士。徐启南,硕士。
猜你喜欢
传媒论坛(2022年9期)2022-02-17 19:47:54
科学养鱼(2021年6期)2021-11-30 18:02:10
智富时代(2019年6期)2019-07-24 10:33:16
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
中国应用生理学杂志(2013年1期)2013-03-30 02:06:28
