
基于Spark的并行FP-Growth算法优化与实现
2017-09-23 03:04:00江雨燕杜萍萍
计算机应用与软件 2017年9期
陆 可 桂 伟 江雨燕 杜萍萍
(安徽工业大学管理科学与工程学院 安徽 马鞍山 243000)
基于Spark的并行FP-Growth算法优化与实现
陆 可 桂 伟 江雨燕 杜萍萍
(安徽工业大学管理科学与工程学院 安徽 马鞍山 243000)
频繁模式挖掘作为模式识别的重要问题,一直受到研究者的广泛关注。FP-Growth算法因其高效快速的特点,被大量应用于频繁模式的挖掘任务中。然而,该算法依赖于内存运行的特性,使其难以适应大规模数据计算。针对上述问题,围绕大规模数据集下频繁模式挖掘展开研究,基于Spark框架,通过对支持度计数和分组过程的优化改进了FP-Growth算法,并实现了算法的分布式计算和计算资源的动态分配。运算过程中产生的中间结果均保存在内存中,因此有效减少数据的I/O消耗,提高算法的运行效率。实验结果表明,经优化后的算法在面向大规模数据时要优于传统的FP-Growth算法。
频繁模式挖掘 FP-Growth算法 分布式计算 Spark框架
0 引 言
R.Agrawal提出Apriori算法用于解决关联规则的挖掘问题后[1],频繁模式的挖掘就一直受到广泛关注。之后,Han提出的FP-Growth算法由于其自身在计算效率上的优势[2],得到了更为广泛的运用。然而,随着数据规模的不断增大,该算法在实际运用中也存在一些尚待改进的问题。一方面,FP-Growth算法在统计各元素项的支持度计数过程中会消耗大量时间;另一方面,大规模数据集的维度跨越过大,导致算法构建的频繁模式树(FP-Tree)难以存入内存,影响了算法的运行。因此,大规模数据集上如何有效挖掘关联规则成为近年来研究人员关注的重点。
分布式计算是解决大规模数据环境下数据挖掘任务的常用方法,也是一种通过使用低成本的多个硬件达到高性能计算机性能的一种技术。其中,段孝国等在文献[3]中介绍了中间件技术、P2P技术、移动Agent技术、网格技术、云计算和Web Service这几种分布式运算技术的关键技术和国内外应用现状。胡敏等在文献[4]中对上述几种分布式运算技术进行了分析和比较。随着众多学者对分布式运算技术的进一步了解和学习,已有学者将分布式运算技术应用于数据挖掘中。文献[5]中,王轶等提出了一种计算框架并将其应用于分布和并行环境的数据挖掘中,最终建立一种可以应用于分布式并行数据挖掘的框架。王小妮等[6]提出了基于云计算的分布式数据挖掘平台架构,并在此基础上提出了一种新的分布式数据挖掘模式。当前,关于分布式计算的研究集中在分布式系统和分布式环境研究两方面[4]。其中,基于分布式计算环境和计算框架实现数据挖掘应用引起了学者们的广泛关注。Zeng等[7]详细介绍了分布式计算环境的方法和应用程序的最新技术,并对分布式计算环境领域进行了总结。Moteria等[8]将分布式计算环境同高效可扩展的分布式算法相结合并运用于频繁模式的挖掘中,取得了较好的效果。Song等[9]在KNN算法的基础上,结合谷歌提出的Map/Reduce编程模型为大数据的背景下解决基于KNN的实际问题提供了一个指南。Chen等[10]针对分布式数据挖掘中广泛存在着的候选集冗余和频繁模式挖掘低效率的问题,提出了基于Hadoop分布式计算框架的并行算法,在分布式节点中构建和挖掘TPT-Tree,提高了频繁模式数据挖掘的效率。近年来,随着Hadoop分布式计算框架的广泛运用,有学者基于该框架和Map/Reduce编程模型实现了FP-Growth算法的并行化改进[11-13]。文献[14]在Hadoop框架基础上提出了一种基于布尔矩阵和Map/Reduce编程模型的FP-Growth算法BPFP,其执行效率和速率均优于原始算法。上述基于Hadoop平台的方法在一定程度上提高了算法在挖掘大规模数据关联规则的性能。但在Hadoop框架下,Map/Reduce编程模型各步骤的中间结果均存储到硬盘中。这种方法可能在处理大规模数据时会存在着因频繁读取硬盘而造成处理时间大量增加的问题。而Spark[15-16]是典型的基于RDD弹性分布内存的分布式框架。相较于Hadoop,Spark所有的中间结果均存储在内存中,故省去了大量的硬盘I/O操作。薛志云[17]同时搭建了Hadoop和Spark平台,对Hadoop和Spark的性能进行比较,同一组数据集在两个平台上进行Kmeans聚类的时间对比,实验结果表明Spark相较于Hadoop更适用于需大量迭代的机器学习算法,且伴随着数据集的增大Spark的优势愈明显。
故在分而治之的思想基础上,运用Spark分布式框架,利用其自身基于内存进行计算的特点,提高了FP-Growth算法的迭代效率。此外,还对算法的支持度计数统计和数据分组过程进行了优化,提高了算法的运行效率和准确率。
1 相关研究
FP-Growth算法使用特殊的数据结构存储数据集,算法执行过程中不产生候选集,而是采用一种频繁项集不断增长的方式进行挖掘。逻辑上算法分为两个步骤:第一步将数据集以FP树的特殊数据结构存储;第二步就是递归地挖掘FP树[18]。为构建FP树,需对原始数据集扫描两遍,对所有元素项的出现次数进行计数。(1) 第一次遍历数据集,获得每个元素项的出现频率,找出满足最小支持度计数的元素项。同时,将所有元素按照支持度计数降序排列。得到了有一项的频繁项集,记为头指针。(2) 第二次遍历数据集,删除每条事务中不满足最小支持度计数的项,同时,利用头指针中各元素项的排列顺序,对各条事务中的单个元素项进行降序排序。(3) 完成上述操作后,从null开始,不断添加过滤、排序后的事务,如果树中已有现有元素,则增加现有元素的值(即经过该路径),如果不存在,则向树添加分枝,直到所有事务均添加到树中为止。首先,我们得到一组事务数据集,其对应事务ID及事务中的元素项见表1。
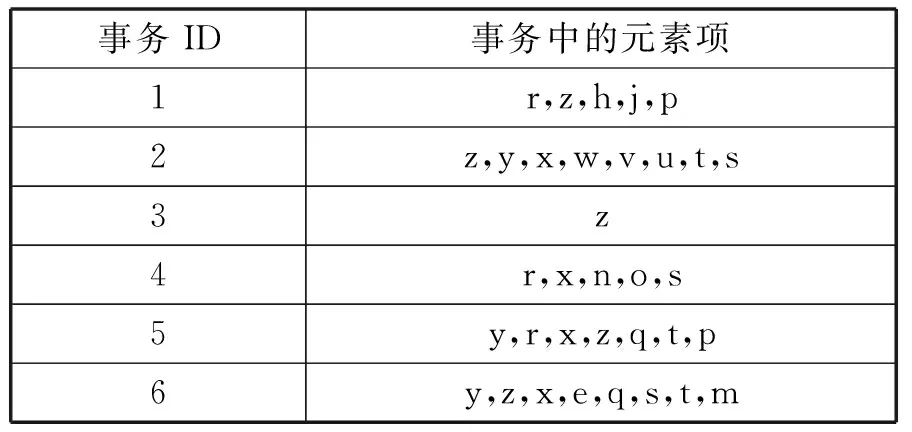
表1 事务数据集
最终通过上述三个步骤经过对事务数据集的反复进行基于最小支持度计数的筛选和排序后,得到构建完成的FP树,如图1所示。

图1 已构建的FP树
近年来,部分学者发现,Spark分布式框架较Hadoop更为适用于这一类递归数据挖掘算法。文献[19]在Spark框架上实现了Apriori算法的并行化改进,取得了较好的效果。
Spark是针对Map/Reduce在处理迭代式算法时效率较低问题时提出的新的内存计算框架,在保留Map/Reduce相关特性的基础上,Spark基于内存的集群方式较Map/Reduce运行速率快100倍[20]。更为重要的是Spark由于其基于内存的特性,能够大量部署在廉价的机器上进而形成一个大规模集群[21]。在实际应用中,Spark框架具有较强的灵活性。
FP-Growth算法作为迭代式算法,在实现并行化的过程中其最大的特点是在多个并行操作中重用数据。这一类算法都用一个函数对同一数据集进行反复的计算,Spark不同于Map/Reduce的是其中间输出结果均保存在内存中,这样就避免了对HDFS进行频繁的读/写操作。因此,Spark更加适用于FP-Growth这一类需要迭代的数据挖掘算法。
2 算法优化
2.1 基于Spark框架的并行算法优化
在Spark上的并行化实现主要分为3个步骤:(1) 计算所有项的支持度计数,这里的思路类似于WordCount过程。WordCount是最基础也是最能体现Map/Reduce编程模型的程序之一,其最终输出的结果为键值对的形式,和FP-Growth算法要求的键值对形式相同。首先,main函数对Map/Reduce Job进行初始化,再遍历每一个事务,累计单个项的支持度计数,在通过reduceByKey算子将待输出数据与一个共用的key结合,最终运用算子中的lamdba函数将所有单个元素项的键值对合成一个结果,保存在内存中。(2) 数据分组,将F_list中的条目分成G个组,就形成了一个Group_list,这其中每一个Group都包含一组item的集合。在这一步中,mapper完成的主要功能是数据集分区,逐个处理数据分区中的事务。将事务分为item,每个item根据Group_list映射到合适的group中去,然后在reduce中并行执行FP-Growth算法。(3) 结果聚合将所有机器上的处理结果聚合,聚合各台机器上得到的频繁项集,并统计支持度。其主要过程如图2所示。其中,原始数据和最终输出结果均保存在HDFS中。

图2 算法实现
下面以伪代码的形式给出在Spark框架下优化后的并行化算法的实现。如算法1所示。
算法1基于Spark框架的并行优化算法
Input:事务数据集D的HDFS链接:HDFS://Hadoop1:9000/ min_sup
Output:频繁项集L(结果以文本的形式存储在HDFS中)
step1: var sc =new SparkContext(conf)
step2: var file = sc.textFile(arg(0)) {
step3: for {Item /*每个事务的项*/
step4: compute(sup);}
step5: var D_list=item.flatMap /*事务分组*/
step6: FP_Growth(D_list) /*并行执行优化后的FP_Growth算法*/
step7: def decare(result){ /*笛卡尔积*/
step8: return L} /*输出最终结果,并保存在HDFS中*/
2.2 支持度计数统计及分组过程优化
本文首先优化了支持度计数统计过程。此外,基于分布式框架优化FP-Growth算法较重要的一个环节是需考虑好数据分组的问题。在并行化运行过程中,整个算法的运行时间取决于最后一个组完成任务的时间,所以对于每一个组的计算量应尽量相等。在Spark框架中,分组的数目决定了整个框架的计算粒度。整个并行计算过程中,每一阶段的分组数目和任务数目均保持一致。一方面要尽量保证每一个子计算区的分组数相等,另一方面要尽量保证每一个分组的计算量保持平衡。在算法的支持度计数统计过程中,加入了reduceByKey算子。当采用reduceByKey时,可以在每个分区移动数据之前将待输出数据与一个共用的key结合。同时运用算子中的lamdba函数将所有单个元素项的键值对合成一个结果。
下面给出了支持度计数统计过程中的伪代码,如算法2所示。
算法2支持度计数统计优化算法伪代码
Input:事务数据集f
Output:各个项的支持度计数sup
/*compute(支持度)之前将重复行合并,并删除事务编号*/
step1: var f = file.map
step2: .drop()
//执行删除操作;去掉多余的事务编号
step3: .toList()
step4: .reduceBykey()
//合并相同的行
/*compute(支持度),并通过cache()存储在内存中*/
step5: compute(sup)
step6: .reduceBykey()
//在分组操作移动前,将相同项支持度结果合并
step7: .cache()
//所得全部支持度计数结果存储在内存中
在考虑分组问题时,首先,对每个Spark分区的分组数进行了定义,可根据需要调整分组数,从而限定了每个子分区的分组数都保持相等。通过加入groupByKey算子,对相同元素项的键值对进行移动一方面减少了分组的时间损耗。另一方面保证了相似的元素移动到同一子分区中,保证了各个子分区的计算量尽量保证接近。
同样,我们给出了分组优化过程的伪代码,如算法3所示。
算法3分组优化过程伪代码
Input:f_list
Output: group
//分完组的事务数据数据集
step1: var pum =()
//人工设定一个数目来控制分组规模
step2: var g_size = (g_count + pum -1)
//人工控制分组规模
step3: var f_list = item.flatMap(t=> {
step4: var pre = -1;i= t.1.length -1
step5: var result = List[(Int, (List[Int],Int))]()
step6: while (i >= 0) {
step7: //执行循环,判定item中的数据是否类似
step8: End for(i=-1)
//当事务数组的长度为0时,分组过程结束
/* g_size是分组的个数,item即数据集中事务以及其出现次数的键值对*/
/*将item中的数据分为g_size个组,所有分组中的均为相关的数据*/
/*每个组中都包含着一组item*/
step9: .groupBykey()
//对相同的项进行移动
step10: .cache()
//存储在内存中
3 实验设计与结果分析
3.1 实验环境设置
为验证优化后的并行化FP_Growth算法的有效性,在私有云平台创建三台四核、6 GB内存的服务器。其中,每台服务器拥有100 GB存储,系统为Centos 6.5。
整个Spark框架采用主从式分布式集群,集群中包括三个节点,其中,Hadoop1为主节点(Master)、Hadoop2、Hadoop3为从节点(slave)。服务器中的jdk版本为1.7.0_79,Hadoop版本为2.2.0,Spark版本为1.1.0。算法的实现语言为scala 2.10.4。
3.2 实验框架搭建
集群1包括三个节点,各个节点之间设置免密码SSH访问,各个节点IP地址和主机名称如表2。其中,表中内存为Spark集群每个worker的运行内存,可通过修改Spark配置文件在硬件内存范围内自行调节。保证了良好的扩展性。

表2 集群1网络配置
3.3 实验数据及结果
配置四台云服务器,为保证单机系统和集群的硬件参数保持一致,其中一台服务器作为单机系统,配置为四核、6 GB内存。利用剩下的三台服务器搭建Spark集群。集群中含有三个节点,每个节点的worker内存设为2 GB,保证了总内存为6 GB。在单机系统上运行FP-Growth算法,Spark集群中运行优化后的并行FP-Growth算法。在实验中使用了机器学习领域中常用的四个数据集,分别为mushroom.dat、pumsbstar.dat、accidents.dat、webdocs.dat。这四个数据集的详细说明如表3所示。

表3 数据集说明
最后将两组实验的运行时间进行比较。实验结果如表4所示。表4中是单机系统下的FP-Growth算法运行时间,是优化后的并行FP-Growth算法在Spark集群下的运行时间。为了保证实验数据的可靠性,每个数据集均运行三次,取三次运行时间的平均值作为最终的运行时间。

表4 实验结果对比
实验初始阶段,在处理较小规模数据集的情况下,由于Spark集群在启动和加载过程中消耗了部分时间,其运行时间与单机系统相差不大。但是,随着数据规模的不断增加,Spark集群充分发挥了其自身优势,在处理大规模数据时,处理性能已经远远优于单机系统。其次,通过优化FP-Growth算法的支持度计数统计及分组过程,运行时间已经大大缩减。通过对比实验,Spark集群在处理相同大规模数据集时,其运行速率已远远超越单机情况下的结果。
实验中,本文还考虑到了Spark集群的一大独有优势,即通过增加/删除节点迅速地调整集群的规模以适应不同需求的计算。因此,在保证Spark集群worker总内存6 GB不变的前提下,调整从节点的数目和主从节点的worker内存,使用优化后的并行FP-Growth算法来处理accidents.dat等数据集。其中,先设置一组含有一个节点的Spark集群,worker内存设为6 GB,运行时间记为,待第一组集群实验完毕后,再设置一组含有两个节点的Spark集群,worker内存分别设为3 GB,总内存保证为6 GB,运行时间记为。设置一组含有三个节点的Spark集群,worker内存分别设为2 GB,总内存保证为6 GB,运行时间即为上述表4中的实验结果,记为T3。实验结果如表5所示。

表5 集群实验结果
通过表5的实验结果,可以看到,随着节点个数的不断增加,整个Spark集群的处理效率更高,运行同一数据集的时间在逐步递减。当数据集规模不断增大时,这种递减的幅度逐渐增大、愈发明显。同样,在其他数据集上也得到了类似的结果。
综上,经过优化后的并行FP-Growth算法执行效率更高,且整个Spark集群的可扩展性好,能够适应各种不同的计算任务。
4 结 语
本文基于Spark分布式框架实现了现有FP-Growth算法的并行化,并优化了算法的支持度计数统计和数据分组过程。通过设置对比实验,比较了单机系统下运行FP-Growth与Spark集群下运行优化后的并行FP-Growth算法的速率。同时,从集群扩展性的角度设置了另一组实验。结果表明,Spark集群具有较好的扩展性,可以适应各种不同的计算任务。且在Spark集群上运行优化后的并行FP-Growth算法具有很高的性能。
基于本文开展的相关工作,发现在处理一些大规模数据时,Spark的RDD数据区内存参数设置可能会影响到算法的运行速率。因此,下一步将考虑内存这一重要参数对于Spark集群性能的影响机制。
[1] Agrawal R,Imieliński T,Swami A.Mining association rules between sets of items in large databases[C]//Acm sigmod record.ACM,1993,22(2):207-216.
[2] Han J,Pei J,Yin Y,et al.Mining frequent patterns without candidate generation:A frequent-pattern tree approach[J].Data mining and knowledge discovery,2004,8(1):53-87.
[3] 段孝国.分布式计算技术介绍[J].电脑知识与技术,2011,7(22):5463-5465.
[4] 胡敏,付琍.对几种典型分布式计算技术的比较[J].电脑知识与技术,2010,6(5):1244-1246.
[5] 王轶,达新宇.分布式并行数据挖掘计算框架及其算法研究[J].微电子学与计算机,2006,23(9):223-225.
[6] 王小妮,高学东,倪晓明.基于云计算的分布式数据挖掘平台架构[J].北京信息科技大学学报(自然科学版),2011,26(5):19-24.
[7] Zeng L,Xu L,Shi Z,et al.Distributed computing environment:Approaches and applications[C]//IEEE International Conference on Systems.IEEE,2007:3240-3244.
[8] Moteria P M,Ghodasara Y R.Novel Most Frequent Pattern Mining Approach,Using Distributed Computing Environment[J].International Journal of Engineering Research & Technology,2013,2(2):1-3.
[9] Song G,Rochas J,Beze L,et al.K Nearest Neighbour Joins for Big Data on MapReduce:a Theoretical and Experimental Analysis[J].IEEE Transactions on Knowledge & Data Engineering,2016,28(9):2376-2392.
[10] Bo C,Yong D C,Xiue G.A frequent pattern parallel mining algorithm based on distributed sliding window[J].Computer Systems Science and Engineering,2016,31(2):101-107.
[11] 吕雪骥,李龙澍.FP-Growth算法MapReduce化研究[J].计算机技术与发展,2012,22(11):123-126.
[12] 杨勇,王伟.一种基于MapReduce的并行FP-Growth算法[J].重庆邮电大学学报(自然科学版),2013,25(5):651-657,670.
[13] 施亮,钱雪忠.基于Hadoop的并行FP-Growth算法的研究与实现[J].微电子学与计算机,2015,32(4):150-154.
[14] Xingshu C,Shuai Z,Tao T.FP-Growth Algorithm Based on Boolean Matrix and MapReduce[J].Journal of South China University of Technology,2014,42(1):135-141.
[15] Sankar K,Karau H.Fast Data Processing with Spark[M].Packt Publishing Ltd,2015.
[16] Zaharia M,Chowdhury M,Das T,et al.Fast and interactive analytics over Hadoop data with Spark[J].USENIX Login,2012,37(4):45-51.
[17] 薛志云,何军,张丹阳,等.Hadoop和Spark在实验室中部署与性能评估[J].实验室研究与探索,2015,34(11):77-81.
[18] Harrington P.机器学习实战[M].北京:人民邮电出版社,2013.
[19] Qiu H,Gu R,Yuan C,et al.Yafim:a parallel frequent itemset mining algorithm with Spark[C]//Parallel & Distributed Processing Symposium Workshops (IPDPSW),2014 IEEE International.IEEE,2014:1664-1671.
[20] 黎文阳.大数据处理模型Apache Spark研究[J].现代计算机,2015,8(13):55-60.
[21] 高彦杰.Spark大数据处理:技术、应用与性能优化[M].北京:机械工业出版社,2014.
OPTIMIZATIONANDIMPLEMENTATIONOFPARALLELFP-GROWTHALGORITHMBASEDONSPARK
Lu Ke Gui Wei Jiang Yuyan Du Pingping
(SchoolofManagementScienceandIndustrialEngineering,AnhuiUniversityofTechnology,Maanshan243000,Anhui,China)
As an important problem of pattern recognition, frequent itemsets mining has been paid more and more attention by researchers. FP-Growth algorithm is widely used in frequent pattern mining because of its high efficiency and fast performance. However, the algorithm relies on the characteristics of local memory operation, making it difficult to adapt to large-scale data calculation. To solve these problems, this paper focuses on the research of frequent itemsets mining in a distributed environment. The FP-Growth algorithm which based on the Spark framework was improved by optimizing the support count and grouping process. Furthermore, the distributed computation and the dynamic allocation of computing resources were realized. The intermediate results were stored in the memory, so the I/O consumption was reduced and the efficiency of the algorithm was improved. The experimental results show that the improved distributed FP-Growth algorithm is superior to the traditional FP-Growth algorithm for large-scale data.
Frequent pattern mining FP-Growth algorithm Distributed computing Spark framework
TP3
A
10.3969/j.issn.1000-386x.2017.09.053
2016-11-09。国家自然科学基金项目(71371013);安徽工业大学校青年教师科研基金项目(QZ201420);安徽省教育厅自然科学基金项目(KJ2016A087)。陆可,讲师,主研领域:数据挖掘与机器学习。桂伟,硕士生。江雨燕,教授。杜萍萍,硕士生。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
当代陕西(2019年13期)2019-08-20 03:54:22
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
电力与能源(2017年6期)2017-05-14 06:19:37
知识就是力量(2017年2期)2017-01-21 18:29:36
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2014年18期)2014-02-27 12:00:13
测绘科学与工程(2014年5期)2014-02-27 07:06:14
