
基于特征空间的文本聚类
2017-09-19 07:26黄建宇周爱武谭天诚
计算机技术与发展 2017年9期
黄建宇,周爱武,肖 云,谭天诚
(安徽大学 计算机科学与技术学院,安徽 合肥 230601)
基于特征空间的文本聚类
黄建宇,周爱武,肖 云,谭天诚
(安徽大学 计算机科学与技术学院,安徽 合肥 230601)
文本聚类是聚类算法的一种具体应用,随着互联网的发展,文本聚类应用越来越广泛,譬如在信息检索、智能搜索引擎等方面都有较为广泛的应用。文本聚类算法主要涉及文本预处理和文本聚类算法,故对文本聚类进行改进可以从这两方面入手。传统文本聚类的文本预处理采用VSM模型,该模型不考虑词与词的语义相似度和词与词的相关性,导致文本聚类精确度非常低。针对该问题,提出了基于特征空间文本聚类的方法。该方法根据文档集合的特征空间构造一个替代词库,并根据这个替代词库得到文档的主题,依据主题配合其对应的领域词典对文档词进行相应的替换。传统的文本聚类使用K-means算法,但该算法需要人工指定K值。为此,提出了基于K值优化的K-means改进算法。实验结果表明,所提出的文本聚类方法和K-means改进算法显著提高了文本聚类的智能性和精确性。
知网;领域词典;主题;义原;聚类;K值优化
0 引 言
文本聚类是聚类算法的一种具体应用。随着互联网的发展,文本聚类应用越来越广泛,如在信息检索、智能搜索引擎等方面都有广泛的应用。文本聚类是一种没有监督的机器学习方法,不需要训练过程,也不需要预先对文档手工标注类别,而是按照一定的相似度对大量文本进行归类。与结构化的数据挖掘对象不同,文本聚类处理的是自然语言类文本,传统的文本聚类算法首先将文本进行分词处理,接着删去代词、停用词和叹词等不影响文本类别的词,然后再计算每个词的TF-IDF值(其中TF表示特征词在某文本中的出现频率,IDF表示特征词在整个文本集中的出现频率),根据TF-IDF值选取每篇文档的特征词。但是这种方法没有考虑词与词的相关性(词与词反映同一个主题),很有可能将相关的两个词当成无关词,若是不考虑词之间的相关性,则可能将两篇相关度较高的文本看作互相没有关联的文本。
针对上述问题,提出了基于特征空间的文本聚类方法。该方法考虑了词之间的相关性,提出了替代词库的概念,对要进行聚类的文档构造替代词库,替代词库中的每一行是由相关度很大的一组词构成的。通过替代词库得到文档集合大致主题,并选取对应的领域词典,根据领域词典,将经过文本预处理后的文档进行相应词的替换[1-5]。
1 相关介绍
1.1知识背景
(1)向量空间模型(VSM)。
VSM(Vector Space Model)是当前自然语言处理中常用的模型,该模型是对文档表示常用的方法。
在VSM中,每一篇文本在特征空间中都表示为一个向量,文本中的一个词条对应向量中的一个参数,由这样的d个参数构成一个特征向量,而每一个特征向量等于该向量的d个参数所对应的特征在文本集中的权值。数学描述如下:
特征词集合X=(x1,x2,…),文本集合D=(d1,d2,…),特征词权重集合W=(w1,w2,…),则文本di=(wi1,wi2,…)[6]。
(2)领域词典。
所用的领域词典是由东北大学自然语言处理开发的,用来存储于指定领域有关的领域关联词的词典,一行由两个字段组成,分别是汉字对应的专业术语和拼音对应的专业术语[7-8],以军事为例(阿哥斯波塔米战役a'ge'si'bo'ta'mi'zhan'yi)。
(3)HowNet。
HowNet是一个较为详细的语义知识词典,但是HowNet通过一种多维的方式表示一个词的语义,这在计算词与词之间的相似度时造成了一定的困难。在HowNet中,词的语义是由多个义原组成的,因此计算词的语义相似性是相当麻烦的[3,7,9]。
1.2相关原理
(1)语义相似性。
义原是最基本的、不易于再分割意义的最小单位。每个词的词义都是由多个不同的义原组成的,必须综合每个词的义原集合来考虑词与词之间的语义相似性,而不是单纯地看某几个常用义原,被所谓的经验误导。并且,每个词的义原集中第一义原所占的比重较大,需要加以考虑。
(2)词汇的相关度。
对于两个词f1和f2,f1有n个义原:s11,s12,…,s1n,f2有m个义原:s21,s22,…,s2m。现规定w1与w2是取各个义原相似度的最大值:

(1)
该式仅从义原方面考虑词汇的相似性,不考虑第一义原的重要位置[7,10]。
(3)构建替代词库。
由于每一个词的词义都是由义原集合组成的,对于任意两个词,若只从语义方面考虑,它们的语义相似度有可能非常低,但是它们又可能实际上是关于同一主题的。所以文中要从词的语义和相关性两个方面进行考虑。假定给定一组词的具体步骤:
首先,取得这组词中每个词的义原集合,再从第一个词开始循环遍历每个词及其义原集。假定一组词及其义原集为:fi(y1,y2,y3),fj(y3),fk(y3,y6),fm(y3,y10),fn(y1)。若两个词不相同,则把它们义原的交集提取出来,并将这两个词分别放在它们共有的义原后面,得到y1[fi,fn],y3[fi,fk,fm]。具体描述如下:
输入:M个词及每个词对应的义原集;
输出:N行相关词集合。
①从1到M:获取对应的词以及它的义原集。
②从2到M:获取对应的词以及它的义原集。
③比较这两个义原集是否有交集,若是交集不为空,则先判断有没有已建立的相关词,若是交集为空,则建立一组相关词。相关词的第一项由它们共有的义原组成,接着在它的后面加上相应的两个词。若是相关词已经存在,则转下一步。
④判断已经存在的相关词中的共有的义原和步骤③中两个词的共有义原是否相同,若相同,则直接把两个词添加在已有相关词的后面,若不同,则依照步骤③新建一组相关词。
通过上述步骤就可以得到一个初步的替代词库。
然后,循环遍历步骤创建的替代词库,计算每组相关词的第一个项的语义相似度。设定阈值α=0.5,如果计算的语义相似度大于0.5,就将这两组相关词进行合并,否则不合并,从而得到替代词库。
(4)选择领域词典。
删除构建的替代词库中的一些与主题无关的相关词组(例如表示属性的一些词),然后循环遍历替代词库,计算每组相关词的数目。依据聚类簇数K,选择数目排在前面的K组相关词,这K组相关词就是文档集合的主题,根据K组相关词选择与其对应的K组领域词典。
(5)K-means算法中的K值优化。
K-means算法在聚类前必须要知道它需要聚类成几个簇,但是对于陌生的数据集并不知道K值的大小,所以在完成聚类操作前需人为指定K值,因此该方法相对不智能。于是提出了一种改进的思路对K值进行优化,其优化流程如下:

②对数据集进行聚类,得到聚类结果。
③根据步骤②得到的簇集合,求得每个簇均值到其他簇均值的距离和,选择其中距离和最小的簇,记为M。
④求得与簇M距离较近的一个簇N,依据聚类的评价标准高内聚低耦合的原则,研究这两簇,设定Discc为簇自身到自身簇均值的距离,Discd为一个簇的数据到另一个簇均值的距离。

(2)

(3)
其中,cx为自身簇的均值;dx为另一个簇的均值。
计算Discc/Discd的值,如果该值越接近于0,说明效果越好,也越能体现聚类高内聚、低耦合的标准。按照这种思路分别计算选定两个簇的比值,选择其中最大的比值作为结果[11-16]。
2 聚类算法的改进
针对传统文本聚类算法的不足,进行如下改进:
输入:M篇文本文档,设定聚类簇数N。
输出:N个集合。
算法描述:
(1)对文档进行分词和去停用词的处理;
(2)使用TF-IDF方法计算文档中所有词的TF-IDF值,然后根据对应的值筛选出文档的特征词;
(3)通过由特征词构成的特征向量来构建这些文档的特征空间;
(4)构建一个替代词库(使用1.2的方法);
(5)选择领域词典(使用1.2的方法);
(6)对分词、除停用词后的词进行遍历,看其是否在领域词典中,如果在就用对应的领域词典第一项进行替换;
(7)将替换后的词文档进行数值化;
(8)使用上面K值优化,确定K值;
(9)对数据进行聚类处理。
3 实验分析
为了检测和验证算法的性能,实验中使用一般的文本聚类语料库,此语料库中包含军事、经济、艺术、医药、政治、体育六个类别。
领域词典采用的是东北大学自然语言处理开发的领域词典。使用Java编写文本预处理的部分,使用Matlab编写文本聚类的部分。在Intel Core i5,2.6 GHz,4 GB内存的计算机上,以MyEclipse8.0 Matlab R2012(a)为运行环境。实验在语料库中通过随机选取的方式获取部分文本,总共进行了五次实验,实验效果如图1所示。
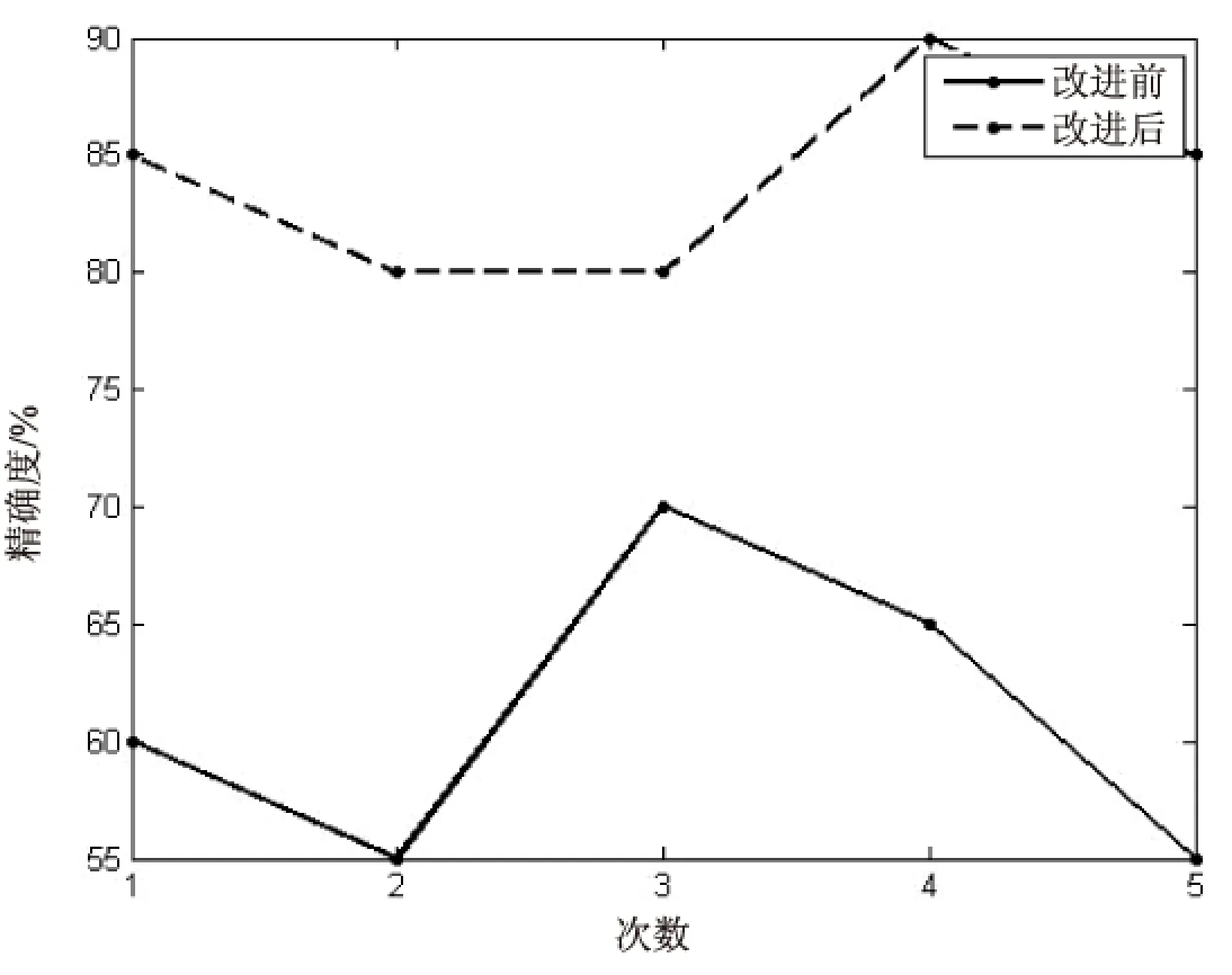
图1 精确度对比图
由图1可知,改进算法相比传统算法在精确度上提升明显,但是由于受到分词工具和HowNet出现的一些未登陆词的影响,导致聚类的精确度并不是很完美。
4 结束语
文中提出了一种基于特征空间文本聚类的方法。依据文档集合的特征空间中的特征词义原集合构建一个替代词库,根据这个替代词库得到大致文档主题,再由这些主题配合相应的领域词典使得聚类精确度得到了很大提升;同时对K-means算法进行改进,使K值不再依靠人为指定,而是根据文中算法进行计算,选出最佳值,提高了文本聚类算法的可靠性和精确性。但是由于分词工具和HowNet出现的未登录词导致精确度不是特别完美,需要进一步进行研究。
[1] 林 利.基于本体的文本聚类的应用研究[D].天津:天津大学,2012.
[2] 庞观松,蒋盛益.文本自动分类技术研究综述[J].情报理论与实践,2012,35(2):123-128.
[3] 曾淑琴,吴扬扬.基于HowNet的词语相关度计算模型[J].微型机与应用,2012,31(8):77-80.
[4] 谌志群,张国煊.文本挖掘研究进展[J].模式识别与人工智能,2005,18(1):65-74.
[5] 路永和,李焰锋.改进TE-IDF算法的文本特征项权值计算方法[J].图书情报工作,2013,57(3):90-95.
[6] 吴国进.基于支持向量机的文本分类研究[D].合肥:安徽大学,2011.
[7] 刘 群,李素建.基于知网的词汇语义相似度的计算[C]//第三届汉语词汇语义学研讨会.出版地不详:出版者不详,2002:59-76.
[8] Zhu Jingbo,Yao Tianshun.FIFA-based text classification[J].
Journal of Chinese Information Processing,2002,16(3):20-26.
[9] Budanitsky A,Hirst G.Evaluating word-net-based measures of lexical semantic relatedness[J].Computational Linguistics,2006,2(1):13-47.
[10] Dai L,Liu B,Xia Y,et al.Measuring semantic similarity between words using HowNet[C]//International conference on computer science and information technology.[s.l.]:IEEE,2008:601-605.
[11] 孙吉贵,刘 杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[12] 钟 勇,赵向辉.一种优化初始中心点的k-means文本聚类算法[J].郑州大学学报:理学版,2009,41(2):29-32.
[13] 田 萱,杜小勇,李海华.语义查询扩展中词语-概念相关度的计算[J].软件学报,2008,19(8):2043-2053.
[14] 汪 中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-304.
[15] 周昭涛.文本聚类分析效果评价及文本表示研究[D].北京:中国科学院计算技术研究所,2005.
[16] Hartigan J A,Wong M A.Algorithm AS 136:a k-means clustering algorithm[J].Journal of the Royal Statistical Society Series C (Applied Statistics),1979,28(1):100-108.
Text Clustering Based on Feature Space
HUANG Jian-yu,ZHOU Ai-wu,XIAO Yun,TAN Tian-cheng
(College of Computer Science and Technology,Anhui University,Hefei 230601,China)
Text clustering is a specific application of the clustering algorithm.With the development of Internet,the text clustering has gotten an increasingly wide utilization in many fields,such as information retrieval and intelligent search engine.Text clustering algorithm involves text preprocessing and text clustering primarily,so some improvements on text clustering from these two aspects have been conducted.The traditional text clustering adopts the VSM without considering the semantic similarity and correlation between words,which leads to low accuracy.In view of it,the text clustering method based on feature space is proposed which constructs an alternative word library through the feature space of document collection and gets the document theme according to the alternative word library,and then replaces the words in document based on the themes and its corresponding domain dictionary.However the traditional text clustering algorithm must need artificialKvalue.Therefore,K-means algorithm is presented based on theKvalue optimization.The experimental results show that the two improvements above mentioned have made text clustering more intelligent and more precise.
HowNet;domain dictionary;theme;sememes;clustering;optimizedKvalue
2016-05-07
:2016-08-12 < class="emphasis_bold">网络出版时间
时间:2017-07-05
安徽大学大学生科研训练计划项目(J18520148)
黄建宇(1993-),男,研究方向为大数据与数据挖掘;周爱武,副教授,硕士生导师,研究方向为数据挖掘、数据库与Web技术。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170705.1649.004.html
TP301.6
:A
:1673-629X(2017)09-0075-03
10.3969/j.issn.1673-629X.2017.09.016
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
动漫界·幼教365(大班)(2020年7期)2020-06-26
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
现代计算机(2019年30期)2019-12-11
英语文摘(2019年5期)2019-07-13
电脑爱好者(2017年7期)2017-05-06
电脑爱好者(2017年5期)2017-05-04
