
基于关联规则挖掘的分类随机游走算法
2017-09-19 07:25施海鹰
计算机技术与发展 2017年9期
施海鹰
(上海大学 计算机工程与科学学院,上海 200444)
基于关联规则挖掘的分类随机游走算法
施海鹰
(上海大学 计算机工程与科学学院,上海 200444)
随着互联网技术的不断进步和互联网的飞速发展,人们可以很方便地在互联网上寻找各种各样的信息。用户在寻找他们真正感兴趣的信息时会花费大量的时间,从而导致效率不高,这种现象被称作“信息过载”。推荐系统是解决信息过载问题的一种行之有效的方法。目前,推荐系统中应用最广泛的两种推荐技术是基于内容的推荐算法和协同过滤推荐算法,但其不能很好地处理冷启动和稀疏性问题。为了更好地解决这两个问题,在对传统分类随机游走算法进行改进的基础上,提出了基于关联规则挖掘的分类随机游走算法。该算法利用关联规则挖掘的特性,挖掘用户属性与项目之间的关联,为新用户构造初始的评分向量,弥补了经典算法的不足,较好地处理了冷启动问题。验证实验结果表明,该算法具有较好的有效性和精确性。
推荐系统;关联规则;分类随机游走算法;信息过载
1 概 述
随着互联网的不断发展,用户在互联网上查询感兴趣的信息的效率越来越低,用户将大量时间花在了浏览不相关的信息上。为了解决上述问题,推荐系统应运而生。推荐系统的任务主要是将信息和用户有效地联系起来,一方面让用户发现自己需要的、感兴趣的、有价值的信息;另一方面让这些信息出现在用户面前。推荐系统的出现就是为了解决“信息过载”问题[1],让用户在查询有价值的信息时具有更高的效率。推荐系统已经广泛应用于各领域,最典型的就是类似于‘亚马逊’的商业领域[2]。
推荐系统通过分析用户的历史兴趣和偏好信息,可以在项目空间中确定用户现在和将来可能会喜欢的项目,进而主动向用户提供相应的项目推荐服务。推荐系统的优劣很大程度上依靠其采取的推荐算法,不同的推荐技术具有不同的推荐质量,产生的推荐结果也不同。推荐技术可以分为基于内容的推荐[3]、协同过滤[4]、混合式推荐[5]。基于内容的推荐是最早应用的推荐算法,不需要征求用户的评价意见,而是根据用户喜欢的商品信息,分析信息的特征,根据这些信息来分析相似性。最早的基于内容的推荐应用于信息检索中,所以很多与信息检索相关的技术都可以用于基于内容的推荐中。
协同过滤是推荐系统中最常用也是最成功的推荐算法。协同过滤技术的基本思想是,相似的用户喜欢的东西也可能是相似的。在现实生活中,如果一个用户想要读一本书,往往会选择和自己品味相近的朋友的推荐。基于内容的推荐算法和协同过滤算法各有各的优缺点,可以通过这两种推荐技术的组合来实现推荐算法的互补,这就是混合推荐算法。
当一个新的系统上线时,这个系统中并没有任何用户对项目的评分信息可以利用,那么协同过滤技术也就无法使用,这就是冷启动问题[6]。除此之外,当一个新用户或者新的项目加入系统时,这些项目既没有得到其他用户的评分,新用户也没有对系统中的其他项目进行过评分,这样,新项目既不会被推荐出去,同时新用户也不会得到推荐。新用户和新项目都面临着冷启动的问题。由于基于内容的推荐算法和协同过滤算法无法很好地解决冷启动问题,研究者们提出了新的算法,例如基于图的推荐算法[7-8]。
文中研究了Zhang Liyan等提出的分类随机游走算法[9],并在此基础上进行改进,提出了一种新的分类随机游走算法。首先建立用户—项目的相关图,在相关图上利用基于项目分类的随机游走不断迭代计算推荐结果。算法避免了传统推荐算法的缺点,同时具有较好的推荐效果。
关联规则挖掘问题是R.Agrawal等于1993年提出的[10]。关联规则是描述数据库中一组数据项之间的某种潜在关系的规则,即从数据集中识别出频繁出现的属性值集,也称为频繁项集[11],然后再利用这些频繁集的创建描述关联规则。关联规则可以找到数据项中的关联关系[12],应用到推荐算法中可以找到新用户的相关性。
为了克服分类随机游走算法不能为新用户进行推荐的缺点[13-14],将关联规则算法引入到推荐系统,提出了基于关联规则挖掘的分类随机游走算法,较好地解决了冷启动问题。
2 基于关联规则挖掘的分类随机游走算法
2.1相关图模型
对于给定的数据集D,该推荐算法涉及的相关数据包括用户集U={u1,u2,…,u|U|}、项目集M={m1,m2,…,m|M|}和用户对项目的评分ri,j,算法的输入可以看成是一个用户—项目矩阵T,矩阵中的元素Ti,j的值为ri,j。
算法第一步是建立一个项目间的相关图,以此表明各个项目之间的相关性。算法用同时选择项目mi和项目mj的用户数量来表示两个项目间的相关性,即在矩阵T中第i列和第j列的值均不等于0的行的数量。
定义ui,j表示矩阵T中第i列和第j列的值均不等于0的行的数量,当i=j时ui,j=0。由于T中大部分数据都为0,为了减轻计算量,计算时对T中的每一行,将其不为0的提取出来,将其中可能的两两组合的ui,j置为1,之后所有行将对应位置的值相加,求得最后所有的ui,j的值。

定义|M|×|M|阶的相关矩阵M,其中元素的值计算如下:


基于矩阵M构建相关图G,在G中,项目mi和项目mj之间存在一条边(当且仅当Mi,j>0),边的权重等于Mi,j。这样就构建了算法的基本模型—相关图。相关图表明了各项目间的关联度,项目mi和项目mj具有高的关联度,潜在的原因是它们具有某些相似的特征。
假设用户-项目矩阵T如下:


则矩阵M为:
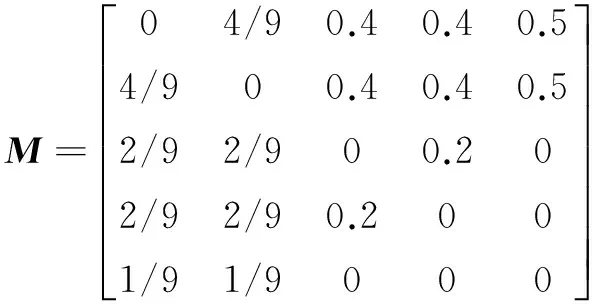
根据M构建相关图G,如图1所示。
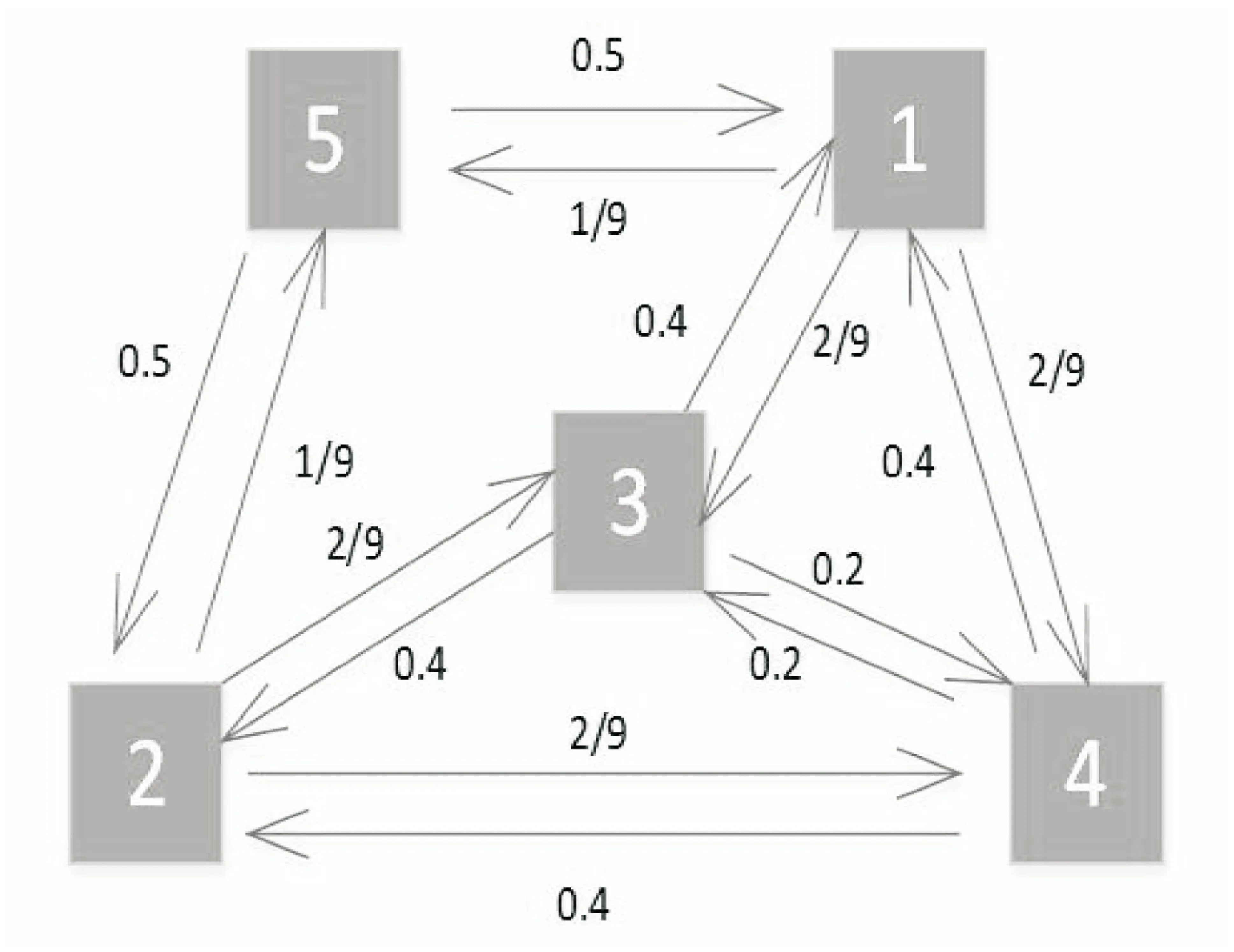
图1 生成的相关图
2.2算法描述
算法的基本思想是通过相关图来预测用户的喜好,相关图揭示了项目与项目之间的关联程度。训练数据集时,通过给定的用户-项目评分在相关图中依靠项目间的连接来传递。例如,如果一个项目mi和用户uj感兴趣的多个项目之间都存在关联,则mi可以作为一个好的推荐结果推荐给用户uj。如果一个项目是用户所喜好的,则其一定还与该用户其他的喜好物品有较高的关联度。基于这样的结论,可以用随机游走的方法去计算用户对其他物品的评分。
用户对某一项目的评分可以从一个项目向该项目邻近的项目传递,不仅仅因为这两个项目同时出现在一个用户的喜好项目里的次数多,而且因为两个项目之间具有某些可见和不可见的相似性。由此定义一个新的概念—分类评分(Categorical Rank,CR),表示在特定分类上的项目评分,而分类随机游走算法就是迭代计算每个用户的CR值。
为了计算CR值,先迭代计算矩阵Ruk,具体的迭代公式如下:
(1)
其中,R为|M|×n阶矩阵,|M|是项目的总数,n是项目类别的总数,元素Rig表示对于某一用户,项目mi在类别g上的评分;M为项目相关矩阵;F为|M|×n阶的辅助矩阵;I为|M|×n阶的矩阵,其元素的值由原始的用户—项目评分生成;d和α分别为链接相关性参数和主题相关性参数,通过实验分别取0.15和0.1。
式(1)表明,对于某一用户,项目mi在类别g上的评分由三部分组成:与项目mi所属类别相同的近邻项目的评分;与项目mi所属类别不同的近邻项目的评分;起始的用户—项目评分。第一个方程的作用是在开始迭代之前初始化Ruk;第二个方程用来计算矩阵F,Pig表示项目mi属于类别g的概率,由数据集中给出的项目分类信息可以计算得出;第三个方程中,Iuk中每一个元素的计算公式如下:
(2)
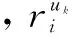

CRuk=Ruk(Profuk)T
(3)
其中,Profuk=RukP,揭示了用户uk对不同类别项目的兴趣。根据式(3)可以计算出用户uk对所有项目的预测评分,如果一个项目最后的预测评分高,则表示用户对该项目比其他项目更感兴趣,将项目按照最后的预测评分逆序进行排序,把排在前面的项目作为最后的推荐结果推荐给用户。
2.3改进的FP-Growth算法
分类随机游走算法的缺点是不能为新用户进行推荐,为了解决这个问题,需要为新用户构建一个初始的评分向量,故提出了基于关联规则的分类随机游走算法。通过关联规则找出用户属性与项目之间的关联关系,根据新用户的属性给新用户构建初始的评分向量,对经典关联规则FP-Growth算法进行了改进。
FP-Growth算法需要扫描事务数据库,数据集D生成的用户-项目矩阵T就作为事务数据库。设定一个最小支持度,对T进行第一次扫描,抽取出那些支持度大于最小支持度的项目和用户属性,并记录其支持度计数(即其出现的次数),生成候选1-项集,记为L,将其按照支持度大小逆序排序。
第二次扫描T,对它的每一行,选择该行的频繁项(项目和用户属性),按照第一步中生成的L的顺序进行排序。之后构造FP-tree,设定排序后的频繁项表为[p|P],其中p为第一个元素,P为剩余元素组成的表。过程如下:如果节点T有子女N与p是同一个项目,则N的计数加1,否则创建新的节点N,将其计数置为1,链接到它的父节点T,并且通过节点链结构将其链接到具有相同项目的节点,如果P非空,递归调用insert_tree(P,Tree)。
建立FP-tree对应的项头表(item header table),逆序遍历项头表,找出FP-tree中由该节点到根节点的路径。根据每个频繁元素对应的条件模式基,生成其对应的条件FP-tree,并删除树中节点记数不满足给定的最小支持度的节点。对于每一棵条件FP-tree,生成所有从根节点到叶子节点的路径,由路径中的集合生成其所有非空子集,所有非空子集和每一个候选1-项集中的元素共同构成了原始数据集中的频繁集,最后生成所有的用户属性与项目之间的关联规则。
运用改进的FP-Growth算法,根据已有的数据集D产生用户属性和项目之间的关联规则之后,对规则R:X⟹Y中后项Y的每一项计算初始评分,对于Y中没有的项目,其初始评分设为0,这样就构成了一个评分向量V;对于Y中有的项目,假设该项目在所有项目中是第i个项目,其初始评分的计算公式如下:
(4)

现有一新用户uk=uk1,uk2,…,ukL,L为用户的属性总数,对于生成的规则集合R={R1,R2,…,R|R|},其中的任一规则Ri:Xi⟹Yi,如果Xi包含于用户uk的属性集,则将Ri加入到R的子集R'中,这样R'所有的规则都是前项中的用户属性是目标用户属性集的子集,即全部是与目标用户相关的关联规则,之后依据式(5)计算uk的初始评分向量:

(5)
其中,Vi为R'中第i个规则所生成的评分向量。
式(5)根据R'中所有规则的评分向量的加权平均来生成uk的初始评分向量。有了初始评分向量后,改进的分类随机游走算法就可以开始为uk进行推荐。
3 算法流程
基于关联规则挖掘的分类随机游走算法在第一次运行时,需要进行用户属性与项目之间的关联规则挖掘,之后只需要在一个新用户对某个项目评分之后,再次进行关联规则挖掘。
算法首先建立相关图模型,之后对新用户进行推荐,需要根据挖掘的所有关联规则,选出与该用户相关的关联规则,对每个关联规则中的所有项目进行初始评分,最后对所有与用户属性相关的关联规则根据支持度和置信度计算加权平均值,得出为新用户构建的初始评分向量。将所有项目分类,计算项目类别概率矩阵P,根据式(1)初始化矩阵R,并迭代计算,之后再根据式(3)计算该新用户的CR值,将CR按照逆序排序,将前几个项目作为结果推荐给该用户。至此算法结束,具体流程如图2所示。

图2 算法流程图
4 实验结果
实验环境:CPU为Intel(R) Core(TM) i3-2350M CPU @ 2.30 GHz ;内存4 GB;操作系统为Windows 7(32位);编程语言为JAVA(JDK1.6)。
实验使用了三个数据集,分别是MovieLens、Anonymous Microsoft Web Data和Entree Chicago Recommendation Data。MovieLens由著名的MovieLens网站上的电影推荐组成,该网站拥有超过50 000名用户对3 000多部电影进行评分,数据集中有943个用户对1 682部电影的100 000条评分,用户自己拥有三个属性,包括年龄、性别和职业。Anonymous Microsoft Web Data记录了网站内38 000名匿名用户过去一周在网站上的浏览记录。Entree Chicago Recommendation Data记录了用户对芝加哥餐馆主菜的评价。对每个数据集抽取100个用户的数据作为测试数据,将这100名用户作为新用户,在三个数据集上分别使用基于FP-Growth的分类随机游走算法和改进的FP-Growth分类随机游走算法,以均方误差(MSE)[13]为评价指标。
在三个数据集中,分别作10次随机抽取100个用户的实验,结果如图3~5所示。
图3~5显示了三个数据集上算法的性能,算法成功地为新用户做出了推荐,且改进的FP-Growth分类随机游走算法的性能普遍好于基于FP-Growth算法的性能。将每个数据集上10次实验的MSE取平均,结果如表1所示。
从表1可见,改进的FP-Growth分类随机游走成功解决了分类随机游走算法中新用户的评分向量问题,利用改进算法生成用户属性与项目之间的关联规则去构造新用户的初始评分向量,之后用分类随机游走算法为新用户进行推荐。相比于基于FP-Growth的分类随机游走算法可以看出,该算法对新用户具有较好的推荐结果。
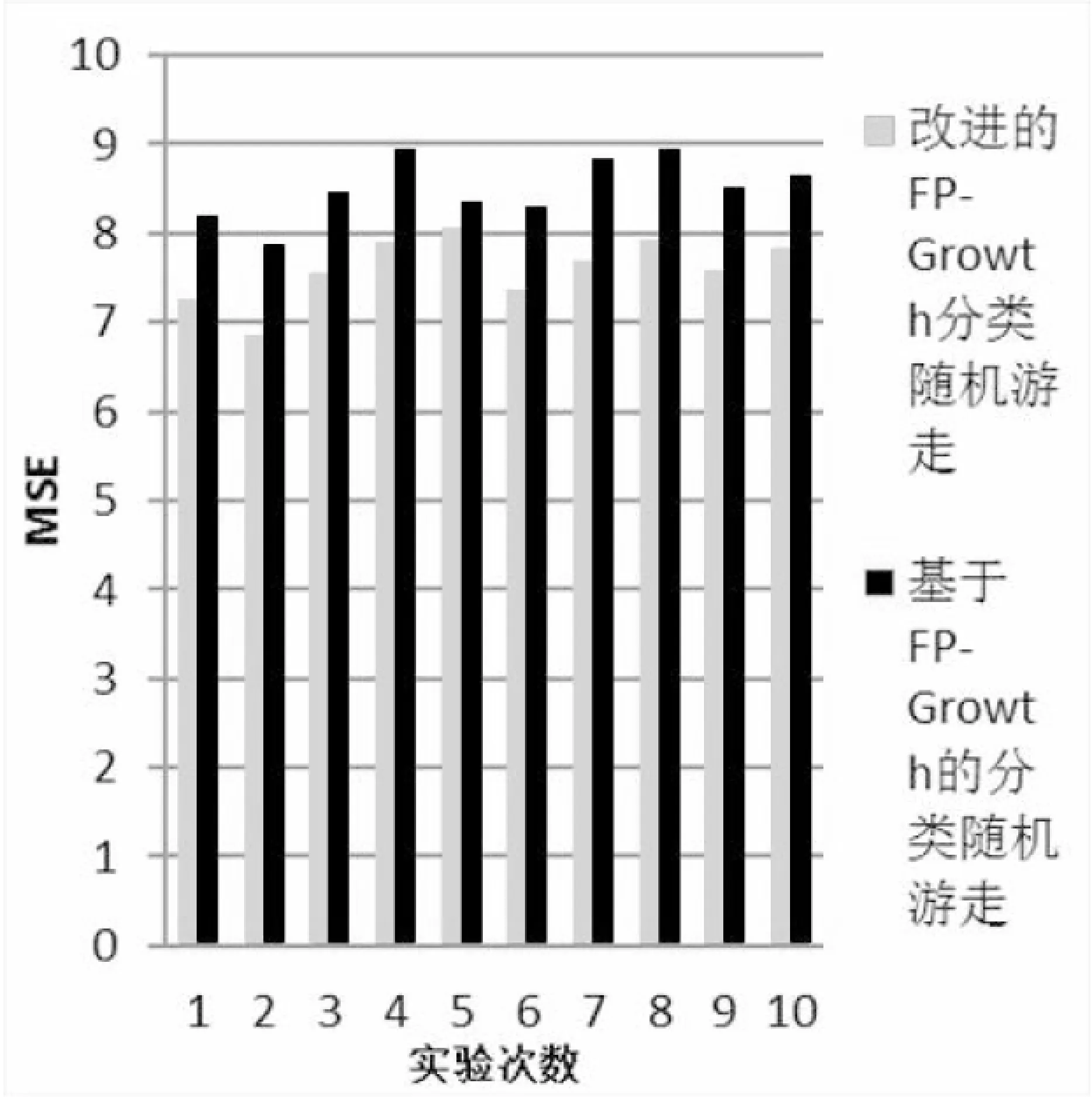
图3 MovieLens的实验结果

图4 Anonymous Microsoft Web Data的实验结果

图5 Entree Chicago Recommendation Data的实验结果

表1 结果对比 s
5 结束语
针对随机游走分类算法的不足,提出了基于关联规则挖掘的随机游走分类算法。为了弥补分类随机游走算法不能为新用户进行推荐的缺点,即新用户没有任何评分数据的问题,该算法利用关联规则挖掘计算用户属性与项目之间的关联规则,利用这些关联规则为新用户构建一个初始的评分向量,之后为该用户计算推荐结果。实验结果表明,该算法对于新用户推荐具有较好的结果。随着信息量的扩大,算法效率也必定会受到一定的影响,为了提高算法在运算大数据量时的效率,算法的并行化和分布式计算是未来研究的重要方向。
[1] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[2] 陈 健,印 鉴.基于影响集的协作过滤推荐算法[J].软件学报,2007,18(7):1685-1694.
[3] 许海玲,吴 潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[4] 曹 毅,贺卫红.基于用户兴趣的混合推荐模型[J].系统工程,2009,27(6):68-72.
[5] 吴丽花,刘 鲁.个性化推荐系统用户建模技术综述[J].情报学报,2006,25(1):55-62.
[6] 刘建国,周 涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[7] 梁昌勇,冷亚军,王勇胜,等.电子商务推荐系统中群体用户推荐问题研究[J].中国管理科学,2013,21(3):153-158.
[8] Zhou T,Jiang L L,Su R Q,et al.Effect of initial configuration on network-based recommendation[J].Physics,2008,81(5):58-62.
[9] Zhang L,Xu J,Li C.A random-walk based recommendation algorithm considering item categories[J].Neurocomputing,2013,120(10):391-396.
[10] Agrawal R,Imieliński T,Swami A.Mining association rules between sets of items in large databases[C]//Proceedings of the 1993 ACM SIGMOD international conference on management of data.New York:ACM,1993:207-216.
[11] Minaei-Bidgoli B,Barmaki R,Nasiri M.Mining numerical association rules via multi-objective genetic algorithms[J].Information Sciences,2013,233:15-24.
[12] Soni R K,Gupta N,Sinhal A.An FP-growth approach to mining association rules[J].International Journal of Computer Science and Mobile Computing,2013,2(2):1-5.

[14] Tong Q L,Park Y,Park Y T.A time-based approach to effective recommender systems using implicit feedback[J].Expert Systems with Applications,2008,34(4):3055-3062.
Random-walk Classification Algorithm with Association Rules Mining
SHI Hai-ying
(Schoolof Computer Engineering and Science,Shanghai University,Shanghai 200444,China)
Along with the continuous progress of Internet technology and the rapid development of the Internet,people can easily find all kinds of information on the Internet.Users would spend a lot of time to search for information what they are really interested in,which is inefficient.The phenomenon is called information overload which is solved effectively by recommendation system as an effective method.However,the two most popular recommendation technologies in the current recommendation system are content-based recommendation and collaborative filtering recommendation,which cannot handle the problems of cold start and sparsity well.In order to better solve them,categorical random-walk algorithm based on association rules is proposed,which uses association rules to mine the association between user attributes and items and constructs the initial score vectors for new users.It has made up for the shortage of the classic algorithm and better handles the cold start problem.The results of experiments prove its effectiveness and accuracy.
recommendation system;association rules;categorical random-walk;information overload
2016-07-08
:2016-11-02 < class="emphasis_bold">网络出版时间
时间:2017-07-11
上海市科委重点资助项目(91330116)
施海鹰(1979-),男,硕士研究生,研究方向为数据挖掘、人工智能;导师:杨洪斌,副教授,研究方向为数据挖掘、人工智能。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170711.1454.040.html
TP301.6
:A
:1673-629X(2017)09-0007-05
10.3969/j.issn.1673-629X.2017.09.002
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读与写·教育教学版(2017年10期)2017-11-10
读者(2017年5期)2017-02-15
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
