
A MATRIX COMPLETION ALGORITHM USING RANDOMIZED SVD
2017-09-15 05:56XUXueminXIANGHua
数学杂志 2017年5期
XU Xue-min,XIANG Hua
(School of Mathematics and Statistics,Wuhan University,Wuhan 430072,China)
A MATRIX COMPLETION ALGORITHM USING RANDOMIZED SVD
XU Xue-min,XIANG Hua
(School of Mathematics and Statistics,Wuhan University,Wuhan 430072,China)
In this paper,we investigate the large low-rank matrix completion problem.By using randomized singular value decomposition(RSVD)algorithm,we compute singular values of sparse matrix.Compared to the Lanczos method,the computational time is greatly reduced with the same error.The algorithm also can be used to solve the relatively low rank matrix.
matrix completion;singular value thresholding;unclear norm minimization; randomized singular value decomposition
1 Introduction
In many situations we need to recover a matrix which has low rank or approximately low rank.The problem requires that we randomly select m entries from an n×n matrix M and fi nd out the missing or unknown values based on the sampled entries.Such problems arise from many areas,such as multi-task learning[3],control[10],machine learning[1,2],image processing,dimensionality reduction or recommender systems in e-commerce,and so on.A well known method for reconstructing low-rank matrices is based on convex optimization of the nuclear norm.
Let M∈Rn×nbe an unknown matrix with rank r satisfying r≪min{m,n},and suppose that one has available m sampled entries{Mij:(i,j)∈Ω},where Ω is a random subset of cardinality m,and Ω⊂{1,2,···,n}×{1,2,···,n}.The authors in[4]showed that most low rank matrices M can be perfectly recovered by solving the optimization problem

provided that the number of samples obeys m≥Cn6/5rlogn for some positive numerical constant C,here the functional k·k∗stands for the nuclear norm of the matrix M,i.e., the summation of all singular values.The optimization problem(1.1)is convex and can berecast as a semidef i nite programming[6,7].If there were only one low-rank object f i tting the data,this would recover M.This is unfortunately of little practical usage because this optimization problem is NP-hard,and all known algorithms which provide exact solutions require time doubly exponential in the dimension n of the matrix in both theory and practice. Some solvers based on interior-point methods can deal with this problem,but they can only solve problems of size at most hundreds by hundreds on a moderate PC.Since the nuclear ball{X:kXk∗≤1}is the convex hull of the set of rank-one matrices with spectral norm bounded by one,the nuclear norm minimization problem can be approximated by the rank minimization problem as its convex relaxation

2 Algorithms for Completing Matrix
2.1 The Singular Value Thresholding(SVT)Algorithm
Problem(1.1)is extended in[4]as follows

where X is an optimization variable.We can use a gradient ascent algorithm applied to the problem with a large parameter τ and scalar step sizes{δk}k≥1.That is,starting with Y0=0∈Rn×n,the singular value thresholding iteration is
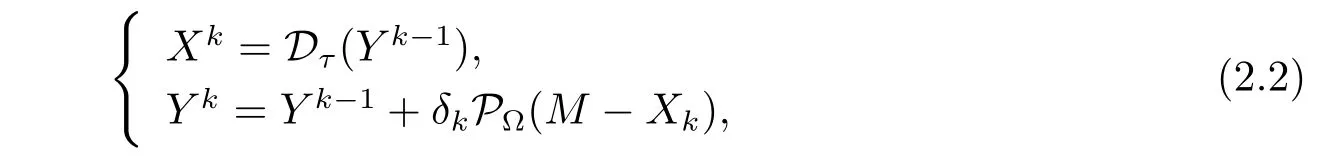
where Dτ(·)uses a soft-thresholding rule at lever τ to the singular values of the input matrix. Consider the singular value decomposition(SVD)of a matrix Z∈Rn×n,and the rank of it is r.That is,

The def i nition of Dτ(Z)is given as follows:

The most important property of(2.2)is that the sequence{Xk}converges to the solution of the optimization problem(2.1)when the values of τ is large.We get the shrinkage iterationswith f i xed τ>0 and scalar step sizes{δk}k≥1.Starting with Y0,we def i ne for k=1,2,···, until the stopping criterion is satisf i ed.
The parameters in the iterations are needed to be given.Let τ=5n and p=m/n2.In general,we use constant step sizes δ=1.2p-1[4],and set the stopping criterion

Since the initial condition is Y0=0,we need to have a big τ to make sure that the optimization problem has a close solution.Now we let k0be an integer and have the following condition

Because Y0=0,we needn’t compute the f i rst several steps[4].It’s easy to know that Xk=0 and Yk=kδPΩ(M)when k≤k0.To reduce the computing time,we begin the iteration at the k0step.
2.2 The Randomized Algorithm
In SVT,we need to compute[Uk-1,Σk-1,Vk-1]sk,where Uk-1,Σk-1,Vk-1are the SVD factors of Yk-1and skis the parameter of Lanczos process.The SVT algorithm uses the Lanczos method via the package PROPACK[9]to compute the singular value decomposition of a huge matrix.The main disadvantage of the classical singular value thresholding algorithm is that we need to compute the SVD of a large matrix at each stage by using a Krylov subspace method such Lanczos or Arnoldi to compute the rank-k SVD. As we know,the efficiency of Krylov subspace depends on the spectrum of the matrix,and only BLAS-2 operations are applied.When the rank of the matrix is not very low,it will take a lot of time to achieve the SVD approximation.

Algorithm 1(RSVD):Given M∈Rm×n(m<n)and l<m,compute an approximate rank-l SVD:M≈UΣVTwith U∈Rm×l,Σ∈Rl×land V∈Rn×l.
We use the randomized algorithm[8]instead of the Lanczos method to compute the SVD.The Lanczos method is one of Krylov subspace method and can be unstable,while the randomized is robust and simply to be implemented.It is not dependent on the spectrum of the sampled matrix.What’s more,the randomized algorithm is easy to be parallelized.
The idea of the randomized algorithm is that we project the matrix onto a smaller matrix which preserves most of the important information and ignore the less important information. The pseudo-codes of the randomized algorithm are given as follows(see Algorithm 1)[11].

Algorithm 2:The R-SVT algorithm
2.3 The SVT Algorithm Using RSVD
In SVT iterations,the SVD is needed in each step.Since the classical methods for SVD approximation are costly.We use the randomized SVD,i.e.,Algorithm 1,to replace the classical one,and obtain the R-SVT algorithm(see Algorithm 2).We can clearly see that in Step 4 of the pseudo-code of Algorithm 2,RSVD is used instead,while the classical SVT algorithm uses Lanczos method to f i nd the singular values.At the beginning of computing, we don’t know the number of the singular values,so we have to spend much time to f i nd this number,and it could be very slow.
On the other hand,in the randomized algorithm,we just preserves the important information and ignore the less important information,so the relatively error of our result can be larger than the SVT algorithm.To obtain a small relatively error at low cost,we combine the two algorithms together,and have the algorithm R-SVT∗(see Algorithm 3).At the f i rst stage we use SVT based on RSVD until the error is smaller than ϵ1,for example 0.1.Then we switch to the classical SVT based on PROPACK,until the error is smaller than ϵ2,for example 1e-4.The pseudo-codes of R-SVT∗algorithm are given as follows.
The classical methods use the PROPACK to compute the approximate SVD,based on Lanczos process.In the algorithm R-SVT∗,we use RSVD instead to perform SVT,and later switch to the classical SVT.Lanczos procedure needs to access the coefficient matrix several times,and use the BLAS-2 operations.In RSVD,the large matrix is accessed by less times, and the BLAS-3 operations are used.So we can expect that the randomized algorithm canbe much faster than Lanczos process for SVD approximation.Note that our work is dif f erent from that in[5].Here we use a dif f erent randomized algorithm,i.e.,algorithm from[11],and we also apply the strategy of switching to the classical SVT in our algorithm R-SVT∗.

Algorithm 3:The R-SVT∗algorithm
3 Numerical Results
In our numerical tests,we use Matlab to implement the R-SVT algorithm,and all the results in this paper are obtained by a computer with 2.13 GHz CPU and 2 GB RAM.At fi rst,we generate an n×n random matrix.Then,we generate a random data array with the length m.Next,we sample the entries of the matrix by the data array.We use the sampled matrix to complete the random matrix we generate.
First,setting the tolerance ϵ is 0.1,we compare the R-SVT with the SVT based onPROPACK to complete the matrix.In Table 1,the matrices of size 500×500,1000×1000, 2000×2000 are tested.We compare the computational time and solution accuracy of the classical SVT and our R-SVT.In Table 1,the notations T,iter,RE stand for the computational time,outer iteration number,and relative error,respectively.And in Table 1 we f i nd that both our R-SVT and the classical SVT can achieve the f i nal relative errors of almost the same order with almost the same number of iterations.According to the computational time,we also f i nd that our R-SVT is faster than the SVT based on PROPACK,and the time dif f erence becomes more obvious when the matrix is larger.For example,when the size of matrix is 2000×2000 with the rank of 400,the computational time of SVT is almost f i ve times of that of R-SVT.
Second,we set the relative error as small as to be 10-4.Based on the former algorithm R-SVT,we just make a small modif i cation.We use the R-SVT until the error is 0.1,and then switch to the SVT based on PROPACK until the error is smaller than 10-4.The computational result are shown in Table 2.We compare the results and can draw the similar conclusions as the f i rst algorithm.

Table 1Comparisons of SVT and R-SVT
4 Conclusion
In this paper,we consider the randomized SVT for matrix completion problems.When we nearly f i nish our work,we notice the work in[5].But here we use a dif f erent randomized algorithm,i.e.,the algorithm from[11],and we also apply the strategy of switching to the classical SVT in our algorithm R-SVT∗.We use the random matrices to test our new algorithm.We can draw the conclusions as follows.
1.The computational time of our randomized-SVT algorithm is less than the classical SVT algorithm.And this advantage becomes more obvious when the rank of the matrix becomes larger.The amazing is that the our R-SVT algorithm works well for the matrixwhose rank is not very low,and this is a great improvement for matrix completion.

Table 2Comparisons of SVT and R-SVT∗.
2.When the tolerance is very small,then the computational time of R-SVT will increase, but this can be overcome when we make a switch in R-SVT∗.That is,when the tolerance is very small we switch from the R-SVT algorithm to SVT algorithm.Using this strategy in R-SVT∗,the advantages of the R-SVT are still kept.
[1]Amit Y,Fink M,Srebro N,Ullman S.Uncovering shared structures in multiclass classif i cation[A]. Proceedings of the 24th International Conference on Machine Learning[C].Providence,RI:ACM, 2007:17-24.
[2]Argyriou A,Evgeniou T,Pontil M.Multi-task feature learning[J].Adv.Neural Inform.Proc.Syst., 2007:41-48.
[3]Argyriou A,Evgeniou T,Pontil M.Convex multi-task feature learning[J].Machine Learning,2008, 73(3):243-272.
[4]Cai Jianfeng,Candes J Ammanuel,Shen Zuowei.A singular value thresholding algorithm for matrix completion[J].Soc.Indust.Appl.Math.,2010,20(4):1956-1982.
[5]Dhanjal Charanpal,Clemencon Stephan,Gaudel Romaric.Online matrix completion through nuclear norm regularisation[EB/OL].http://arxiv.org/pdf/1401.2451.pdf.hal-00926605,Ver.1,9 Jan. 2014.
[6]Fazel M.Matrix rank minimization with applications[D].Stanford,CA:Stanford University,2002.
[7]Fazel M,Hindi H,Boyd S P.Log-det heuristic for matrix rank minimization with applications to Hankel and Euclidean distance matrices[J].Proc.Amer.Control Conf.,2003,3:2156-2162.
[8]Halko N,Martinsson P G,Troop J A.Finding structure with randomness:Probabilistic algorithms for constructing approximate matrix decompositions[J].SIAM Review,2011,53(2),217-288.
[9]Larsen R M.PROPACK-software for large and sparse SVD calculations[OL].http://sun.stanford.edu/rmunk/PROPACK/.
[10]Mesbahi M,Papavassilopoulos G P.On the rank minimization problem over a positive semidef i nitelinear matrix inequality[J].IEEE Trans Automat Control,1997,42(2):239-243.
[11]Xiang Hua,Zou Jun.Regularization with randomized SVD for large-scale discrete inverse problems[J/EB].Inverse Problem,2013,29(8):http://iopscience.iop.org/0266-5611/29/8/085008/.
[12]Guo Wei.Singular value decomposition and algorithm of o-symmetric matrix[J].J.Math.,2009, 29(3):346-350.
用随机奇异值分解算法求解矩阵恢复问题
许雪敏,向华
(武汉大学数学与统计学院,湖北武汉430072)
本文研究了大型低秩矩阵恢复问题.利用随机奇异值分解(RSVD)算法,对稀疏矩阵做奇异值分解.该算法与Lanczos方法相比,在误差精度一致的同时运算时间大大降低,且该算法对相对低秩矩阵也有效.
矩阵恢复;奇异值阈值;核范数最小化;随机奇异值分解
O241.6
A
0255-7797(2017)05-0969-08
∗Received date:2014-12-19Accepted date:2015-04-21
Supported by National Natural Science Foundation of China(10901125; 11471253).
Biography:Xu Xuemin(1991-),female,born at Nanyang,Henan,master,major in numerical algebra.
2010 MR Subject Classif i cation:65F30
猜你喜欢
国家教育行政学院学报(2022年10期)2022-10-31
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
初中生世界·八年级(2021年10期)2021-12-28
湘潮(上半月)(2021年10期)2021-12-02
数学小灵通(1-2年级)(2020年6期)2020-06-24
中国校外教育(下旬)(2017年8期)2017-10-30
数学物理学报(2017年3期)2017-07-01
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
数学年刊A辑(中文版)(2014年1期)2014-10-30
武汉大学学报(哲学社会科学版)(2013年5期)2013-06-26

- 数学杂志的其它文章
- 具有相依理赔量的离散时间风险模型的破产问题
- COMPLETE CONVERGENCE FOR ARRAYS OF ROWWISE M-NSD RANDOM VARIABLES
- OSCILLATION OF NONLINEAR IMPULSIVE DELAY HYPERBOLIC EQUATION WITH FUNCTIONAL ARGUMENTS VIA RICCATI METHOD
- 偏微分方程边值反问题的数值方法研究
- A CLASS OF PROJECTIVELY FLAT SPHERICALLY SYMMETRIC FINSLER METRICS
- 奇异高阶积分边值问题正解的全局结构