
面向入侵检测的高效模式匹配算法研究∗
2017-09-12 08:49赵丽
计算机与数字工程 2017年8期
赵丽
面向入侵检测的高效模式匹配算法研究∗
赵丽
(晋中学院信息技术与工程学院晋中030619)
模式匹配算法是基于模式匹配入侵检测系统的关键,从算法的运行时间和算法的占用空间上分析,提出一种比较高效的模式匹配算法。算法的主要思想是:从攻击模式串中分析以找到足以代表模式串的4个字符的子串,通过分析并构造哈希函数,将其分散到相应的哈希表中,如果在收到的数据包中发现了攻击字符串的子串,再对子串对应的攻击字符串和数据包进行进一步的精确匹配检测,进而确定是否发现了可能的攻击。经过精确匹配后的检测的冲突率较之前大大减少。通过测试,这种匹配算法和其它算法相比,具有较少的运行时间,同时占用较小的内存空间,从而提高了入侵检测系统的检测效率。
模式匹配;入侵检测;特征序列;哈希函数;冲突;性能分析
Class NumberTP393.08
1引言
入侵检测系统(IDS)的基本结构[1]主要由三个部分组成:探测器、分析器和用户接口。其中用于数据分析的分析器是入侵检测的核心。
按照检测技术进行划分,IDS可以分为异常检测和误用检测,在误用检测中,基于模式匹配的入侵检测技术首先将入侵行为表示成一种模式或特征,然后从系统日志或网络流量中查找是否有匹配的发生。模式匹配检测技术主要优点是检测过程简单,无须训练,检测效率高,一般情况下不存在误检测。模式匹配在网络入侵检测中有着非常重要的影响,以前的调查结果表明[2],30%的处理时间都在进行模式匹配,除了运行时间,网络入侵检测系统同时需要较小的内存空间,所以需要找到一种好的模式匹配算法,以提高入侵检测系统的性能。
比较经典的模式匹配算法有单模式匹配算法(比如Brute Force,KMP和BM[3]算法)和多模式匹配算法(比如AC,WM[4~5]),单模式匹配算法一次只能处理一个模式串,而多模式匹配算法一次可以处理多个模式串,所以其匹配速度有了更好的提高。但是多模式匹配算法会占用内存空间,造成频繁的内存释放和分配操作。所以,为了能够提高模式匹配速度并且降低内存使用空间,本文提出一种面向入侵检测的高效模式匹配算法。
高效的模式匹配算法(High Efficiency Pattern Matching,HEPM)是建立在这样的思想基础之上[6],即:尽量减少要匹配的字符个数。具体方法是:如果在数据包有效负载中发现了有4个连续的字符串是一个模式P的子串,那么就可以认为和模式串P产生了匹配。在这种算法中,关键是每一个模式都要用4个连续的最少出现在P中并能足以代表P的字符序列作为特征。HEPM算法只能检测长度大于或等于4的模式串,而那些小于4的模式串则需要单独地去处理。
2 HEPM算法
2.1 HEPM算法基本思想
HEPM算法将一个模式串P每4个字符为一组,划分成若干个子串。比如:在Snort中有模式串P1为“netbus.exe”,根据算法,则把它划分成“netb”,“etbu”,“tbus”,“bus.”,“us.e”,“s.ex”和“.exe”,这些子串之间是“与”的关系。每一个模式用一个逻辑门来描述,每组4字符的子串都是这个逻辑门的输入,而每一个输入都表示这个4字符子串是否出现在网络数据包有效负载之中。模式串P1的逻辑门如图1所示。最初,所有的输入都设为0,然后如果4字符序列出现在网络包中,则相应的输入变为1。当所有对应的输入都是1时,表明网络数据包和模式串P1匹配。
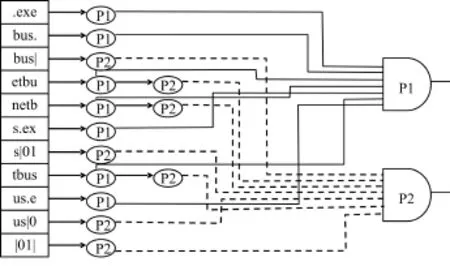
图1 P1和P2对应的索引表和逻辑门
需要注意的是这样的输出并不意味着一个完全精确的匹配。例如,如果网络数据包中包含“net⁃bAAAetbus.exe”这样的字符串,如图1所示,尽管所有P1的4字符序列都出现了,但是其实模式并没有真正匹配。这样每一次逻辑门的输出,都有可能产生冲突,如果在匹配过程中出现冲突的话,那么就需要做进一步的处理。
为了能找到一种快速的匹配方法以表明哪些输入转换为1,HEMP算法需要建立一个索引表。这个索引表保存了模式库存中所有模式的4字符串序列。例如,假定当前有两个模式串,一个是P1,另一个是P2,其中P2为“netbus|01|”,则索引表仍如图1所示。在图1中,序列“netb”,“etbu”,和“tbus”都出现在P1,P2模式串中,“bus.”,“us.e”,“s. ex”,“.exe”仅出现在模式串P1中,而“bus|”,“us|0”,“s|01”,“|01|”则仅出现在模式串P2中。每次匹配到索引表中的一个结点,相应的输入就会转换为1。例如:有一个网络数据包为“tbus.exe”,那么先在索引表中查找“tbus”子串,将P1和P2中相应的输入转换为1,接着,查找子串“bus.”,将P1中相应的输入转换为1,然后,查找子串“us.e”和“s.ex”,将P1中相应的输入转换为1,最后,查找“.exe”,将P1中相应的输入转换为1。这时HEPM算法的运行时间及冲突如表1中“未优化算法”中所示,表中data1和data2取自于MIT Lincoln Lab提供的1999入侵检测数据集[6~7],而模式串取自于Snort规则库。
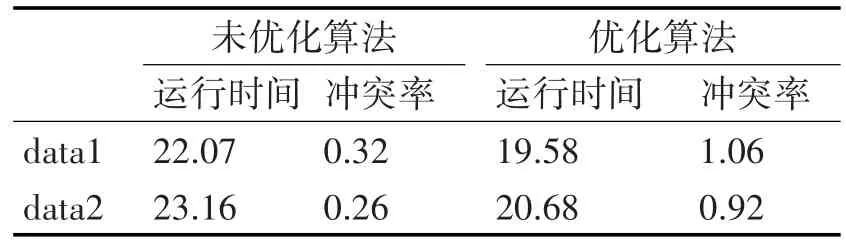
表1 未优化算法和优化算法性能比较
在表1“未优化算法”中,尽管冲突率很低,但是由于在决定网络数据包负载中是否有和模式串相匹配的子串,需要很多的转换步骤,因此HEPM算法的整体性能还不是很好。典型的例子就是,首先查找索引表,然后根据匹配情况对相应的输入进行转换,最后如果所有的输入都为1,那么就得对整个逻辑门进行检测。为了减少转换步骤,降低内存的访问次数,在此将HEPM算法进行优化。优化的方法是为每一个逻辑门只选择唯一的输入作为特征序列,而这个特征序列就是在模式串中最少出现的序列。它的基本思想是这样的:在攻击模式串中最少出现的特征序列是能在规则中找到的最少字符个数的序列,同时也是可以通过计算规则数在相应的索引表中找到的序列。由于这种作为攻击模式串的特征序列在网络数据包中很少出现,所以,如果在收到的网络数据包中发现了攻击模式串对应的特征序列,那么就可以认为在网络数据包中发现了相应的攻击字符串。这样除了这个作为攻击模式串的特征序列外,其它的子串都从图1的逻辑门中移走,相应地除去索引表中的对应的结点。仍以模式串P1,P2为例,假如通过分析将“s.ex”作为模式P1的特征序列,将“|01|”作为P2的特征序列。优化后的索引表如图2所示。由于优化阶段过后,每一个逻辑门只有一个输入,因此,只要索引表中有一个结点匹配,则就触发一个可能的攻击。
优化后的结果在运行时间和冲突率上也在表1“优化算法”中有所体现。由于只有一个输入就能触发可能的模式匹配,这样不可避免地增加了产生冲突的机率,但是优化后的算法减少了转换步骤并且大大压缩了内存,从而使得算法的运行时间大大地缩短,同是出节省了内存空间。
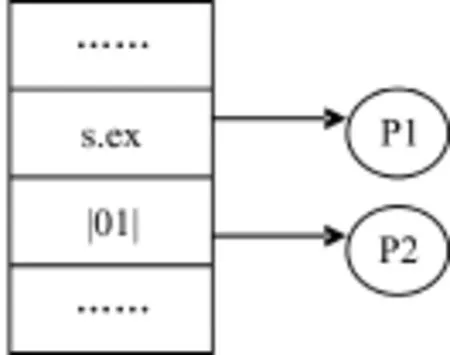
图2 优化后的索引表
2.2哈希表的构造
2.2.1哈希表的引入
一个4字符长度的特征序列,有32位,这样一个完整的索引表需要232个大小,为了占用较少的内存空间,于是将索引表做成一个哈希表[6,8]。既然占用内存的大小及对其访问的位置对于算法的性能来讲非常重要,那么可以根据大小不同哈希表的检测时间取得哈希表的最优大小,哈希表的检测时间可以通过操作系统的时间工具去测量。对于空间大的哈希表,虽然冲突较少,但是由于占用较大的内存而使算法的性能下降。相反,小的哈希表冲突多,从而需要进一步的检测,其运行时间也会随之增加。通过哈希表大小和运行时间关系的实验发现,哈希表的大小在16KB(65536)左右时,使得算法的性能较好,如图3所示。而且通过对Snort规则库中的规则总量分析,其总共的规则数为2000左右,哈希表大小的个数和规则数之比大约是32∶1,这样在查找哈希表时发生冲突的概率就很小。
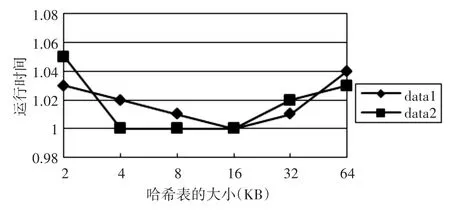
图3 哈希表的大小和运行时间之间的关系
2.2.2哈希函数的选取
借鉴KARP-RABIN算法[9~10],同时结合本文算法的基本思想,每个能标识模式串的特征序列长度为4个字符,每个字符占8位,这样通过拼装字符的二进制ASCII代码就可以构造一个整数。假定任意子串S=s3s2s1s0,那么构造的哈希函数如下:
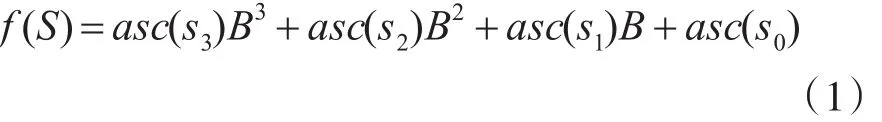
在上述函数中,asc(si)指的是字符si的ASCII值,B=28。通过对Snort规则库中规则的分析,发现规则基本上都是大小写英文字母,0-9数字和一些常见的其它字符组成,而不出现控制字符,因此采用式(1),很容易计算出哈希函数的值。相应的算法如下:
intresult=0;
for(inti=0;i<4;i++)
result=result*B+s[i];
为了提高算法的运算速度,可以利用移位运算和异或运算计算哈希函数的值,其改进的算法如下:
intresult=0;
for(inti=0;i<4;i++)
result=result<<b^s[i];
因为B是2的次幂,所以result与B相乘,只需将result左移b个比特(b=8)。这样改进后的算法可以加快其运行速度。
3实现过程
3.1预处理
1)为了实现优化后的算法思想,将入侵检测规则库中所有的规则进行全面分析,对于每一条规则中的攻击模式,都从中找到足以代表攻击模式串的一个4字符的特征子串序列。
选取特征序列的基本原则如下:
(1)尽量选择类似密码的字符串,即在特征序列中包含字母、数字和其他符号;
(2)尽量选择不经常用的字符串,如两个单词的接合部;
(3)如果发现两个攻击模式串的特征序列相同,则重新选择不同的特征序列。
2)首先根据入侵检测的需求和特点,设计一个大小为16K的哈希表和一个计算攻击模式特征序列值的哈希函数。
3)将每一个攻击模式对应的4字符特征序列,用式(1)计算相应的函数值,将其分布到哈希表中相应的位置。
4)为了能够根据发生特征序列匹配的位置找到对应这个特征序列在原有的攻击字符串的位置,就以要为每一个特征序列维护一个数据结构,其中包含特征序列在该攻击字符串中的起始位置i,特征序列的长度len1、所属攻击字符串的长度len2、特征序列和攻击字符串本身。具体结构如下:
structmark
{intloc;//特征序列在攻击字符串中的起始位置;
intlen1;//特征序列长度;
intlen2;//所属攻击字符串的长度;
char*cha;//特征序列;
char*content;//攻击字符串;
}
3.2匹配算法
1)从收到的网络数据包开始处进行检测;
2)用哈希函数f(s)计算网络数据包中与特征序列长度相同的连续4个字符串的特征值;
3)在哈希表中寻找是否存在与之相匹配的,即具有相同哈希值的攻击字符串信息;
4)如果在哈希表中检测到与网络数据包子串具有相同散列特征值的模式信息,则对特征序列所属的攻击字符串和网络数据包进行进一步的精确匹配检测,进而确定是否真正发现了可能的攻击,然后回到步骤(2)检测下一个网络数据包子串;如果未检测到具有相同特征值的模式信息,则直接回到步骤(2)继续检测下一个网络数据包子串。
5)不断执行上述操作,直到数据包的最后。
3.3具体实现方法
根据算法(2),可以容易地计算出任意相邻4个字符串的值。例如:有网络数据包T=“hideses. exilnabcdl/000|0d|”,通过算法(2)第一次算出“hide”的值,记作result1,下次只需将result1左移b位再和s进行异或运算就可以得计算出“ides”的值result2,依次类推,直到数据包中最后的4个字符串计算完为止。
如上所述,如果检测到与数据包子串具有相同的特征序列时,就会触发与特征序列所属攻击模式串的精确匹配。由于在预处理中,添加了特征序列的长度以及在所属攻击模式串中的位置,所以使得精确匹配变得简单。具体方法为:假设特征序列在原所属攻击模式串中的位置为i,利用HEPM算法进行匹配时,在网络数据包的第j个位置发现了匹配,那么就将网络数据报文回溯到j-i+l位置对其和原攻击字符串进行精确匹配检测。如果完全一致,则可以确定发现了相应的攻击。在精确匹配的过程中,只要发现有一个字符不匹配,就可以结束。
例如,如果网络数据包有效负载是“ablogons. exe”,则必须检测序列“ablo”,“blog”,“logo”,“ogon”,“gons”,“ons.”,“ns.e”,“s.ex”,和“.exe”。根据公式(1)计算各子字符串的特征值,在哈希表中发现与“s.ex”这一特征序列匹配,于是初步认为和P2匹配。但到此并不意味着检测过程的结束,因为初次的匹配结果并不能代表确定真正有攻击的产生。这时查找相应的规则,发现“s.ex”在“netbus. exe”中第6的位置,在数据包“ablogons.exe”中第8的位置,于是根据算法的要求,将数据包有效负载回溯到8-6+1=3的位置,再次和攻击字符串“net⁃bus.exe”进行精确匹配,结果发现第一个字母就不相同,于是立即结束匹配过程,表明并没有真正的攻击产生。而网络数据包中其它的字符序列的特征值在哈希表中没有与它们相匹配的值,所以没有必要再去进行检测。
经过精确匹配后,冲突率大大减少。如表2所示。

表2 未经过精确匹配和经过精确匹配后的冲突率的比较
根据调查表明,对于网络中的数据包而言,绝大多数是合法的,只有一小部分包含着攻击行为。所以在HEMP算法中,首先检测是否和特征序列产生匹配,如果匹配后再和其所属进行精确检测,这样即使是进生了两次匹配检测,其总体性能还是很好的。
4 HEPM算法测试
4.1测试环境
测试时采用的数据data1和data2来自于MIT Lincoln Lab提供的1999入侵检测数据集,规则库取自于Snort。攻击的目标限于使用Windows系列操作系统的网络终端主机,模拟的入侵攻击方式有Smurf攻击、Land攻击、TearDrop攻击、FTP Scanner扫描、IMAP Buffer overflow攻击,分别代表几种不同的攻击类型。并将采用WM、AC和AC-Path模式匹配算法的检测系统和采用HEPM算法的检测系统分别对网络进行入侵检测。
4.2测试结果
4.2.1运算时间
在实验中分别采用WM,AC算法和本文算法HEPM从运行时间上进行比较,得到的测试结果如表3所示。
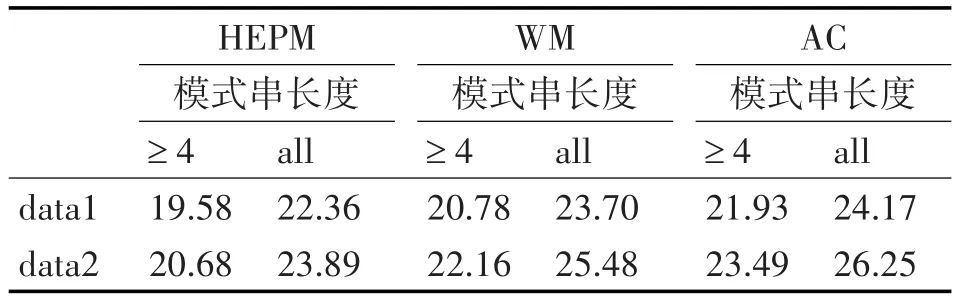
表3 三种算法运行时间的比较(单位:s)
从表3可以看出,HEPM比WM,AC这两种算法有着更好的性能,其运行时间分别比WM,AC这两种算法缩短了5.7%~10.7%左右。尽管HEPM算法主要处理的是大于等于4的攻击模式串,然而通过对整个Snort规则库的详细分析可知,小于4的攻击模式串很少,不足整个规则库中的3%,所以算法的拓展是可以先单独处理这些小串,然后再使用HEPM算法,从表3可知,整体性能没有太大的影响。
4.2.2占用空间
将WM、AC、AC-Path[11]和HEPM从使用空间上作比较,如图4所示。从图中可以看出,WM和AC算法占用的空间要比HEPM算法多,但是AC-Path算法所占用的空间要比HEPM要少,但是AC-Path算法运行时间却将近是HEPM算法的4倍,所以综合考虑,从内存占用情况和处理时间两方面做出一种折衷,选择HEPM算法去做基于模式匹配的入侵检测是可行的。
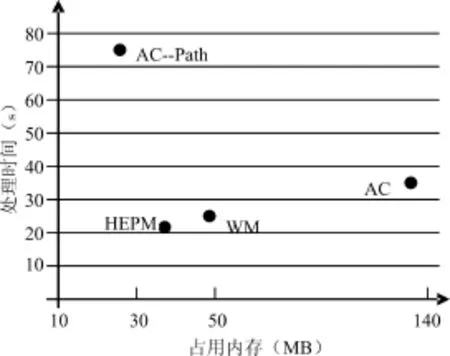
图4 三种算法处理时间和对应的内存使用情况
5结语
本文提出一种面向模式匹配入侵检测的模式匹配算法,总体上来看,无论从模式匹配使用的时间,还是其占用的空间,较与之比较的算法都有所提高。模式匹配算法是基于模式匹配的入侵检测系统的关键,相应的算法还在不断的研究中,愿得到各位专家的指导。
[1]唐正军,等.网络入侵检测系统的设计与实现[M].北京:电子工业出版社,2002:96-103.
TANG Zhengjun.Design and Realization of Network Intru⁃sion Detection[M].Beijing:Publishing House of Electron⁃ics Industry,2002:96-103.
[2]M.Roesch,Snort:Lightweightintrusion detection for net⁃works[C]//Proceedings of the 1999 USENIX LISA Sys⁃tems Administration Conference,1999.
[3]R.S.Boyer.A Fast String Seraching Algorithm[J].Commu⁃nication ofthe ACM,1977,20(10):762-772.
[4]Aho A,Corasick M.Efficient string matching:an aid to bibliographic search[J].Communications of the ACM,1975,18(6):33-40.
[5]S.Wu and U.Manber.A fast algorithm for muti-pattern searching[D].Tucscn:Department of Computer Science,University ofArizona,Tr-94-17,1994.
[6]Antonatos,Polychronakis,Akritidis,et al.PIRANHA:Fast and Memory-Efficient Pattern Matching For Intru⁃sion Detection[J/OL].http://dcs.ics.forth.gr/Activities/pa⁃pers/piranha-IFIP-SEC05.pdf.
[7]1999 DARPA Intrusion Detection Evaluation Data Set[EB/ OL].http://www.ll.mit.edu/IST/ideval/data/1999/1999_ data_index.html.
[8]严尉敏,吴伟民.数据结构(第二版)[M].北京:清华大学出版社,1992:255.
YAN Weimin,WU Weimin.Data Structure[M].Beijing:Tsinghua University Press,1992:255.
[9]赵海波,李建平,杨宇航.网络入侵智能化实时检测系统[J].上海交通大学学报,1999,1:76-79.
ZHAO Haibo,LI Jianping,YANG Yuhang.Intelligent Re⁃al-time Detection System for Network Intrusion[J].Jour⁃nalof Shanghai Jiaotong University,1999,1:76-79.
[10]Karp-Rabin algorithm[OL].http://www-igm.univ-mlv. fr/~lecroq/string/node5.html.
[11]刘鑫.网络入侵检测系统中模式匹配算法的应用研究[D].北京:北京邮电大学,2013:45-57.
LIU Xin.Application Research on Pattern Matching Al⁃gorithm of Network Intrusion System[D].Beijing:Bei⁃jing University of Posts and Telecommunications,2013:45-57.
Research on A High Efficiency Pattern Matching Algorithm for Intrusion Detection
ZHAO Li
(Schoolof Information Technology and Engineering,Jinzhong University,Jinzhong 030619)
Pattern matching algorithm is the key in intrusion detection system based on pattern matching.A high efficiency pat⁃tern matching algorithm is proposed based on the running time and space ofthe algorithm.The main idea ofthis algorithm is to find a string of4 characters which is represented by the attack pattern string.By analyzing and constructing a hash function,the substrings are dispersed into the corresponding hash table.Ifa substring ofattack string is found in the data packet,then the attack string corre⁃sponding to the string and the data packetare detected to determine whether the possible attack is detected.After the accurate match⁃ing ofthe detection,the collision rate is greatly reduced.Compared with other algorithms,this algorithm has less running time,and atthe same time occupies less memory space,thus itcan improve the detection efficiency ofintrusion detection system.
pattern matching,intrusion detection,character string,hash function,collision,performance comparison
TP393.08
10.3969/j.issn.1672-9722.2017.08.028
2017年2月7日,
2017年3月19日
山西省高等学校教学改革项目(编号:J2015108)资助。
赵丽,女,硕士,副教授,研究方向:网络安全。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
民用飞机设计与研究(2020年4期)2021-01-21
无线互联科技(2020年11期)2020-12-01
电脑爱好者(2020年20期)2020-10-22
物联网技术(2018年8期)2018-12-06
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
电脑爱好者(2015年13期)2015-09-10
