
基于情感分析的评论数据用户满意度影响因素研究
2017-08-25 19:58刘甲学陶易
现代情报 2017年7期
刘甲学+陶易

[摘要]通过对用户的满意度影响因素的分析,能够帮助商家挖据用户需求、提升用户满意度、从而提高商品销量。本文使用商业智能软件PowerBI对用户评论文本进行数据挖掘,通过提取评论数据中的质量、物流、尺码、价格、颜色等影响用户满意度影响的因素,利用情感分析法进行赋值,然后统计各影响因素的样本得分,识别出价格和质量是最重要的影响因素。
[关键词]评论数据;情感分析;用户满意度;影响因素
伴随电子商务的蓬勃发展,电商网站下累积了大量用户在线评论数据,通过对评论数据相关研究的解读和分析,我们发现:评论数据是用户表达真实需求和情感极性的重要途径,故而可以挖掘出其隐藏的用户偏好以及真实需求。姜巍等人创造性地将评论数据看作一种内容互连的网络拓扑的形态,利用评论网络节点的重要性来度量评论的有用性,该方法对用户需求获取能够达到较高的准确率和覆盖率。评论数据中的情感极性对商品销量会产生一定程度地影响作用。如Sonnier,G.P.等人验证了积极的评论数据、中性的评论数据、消极的评论数据都对销量有着显著影响作用。因此,通过对评论数据进行情感分析来挖掘用户需求、提升用户满意度最终可以达到提高商品销量的目的。本文将从用户评论数据中提取如质量、颜色、服务等具有实体意义的影响因素指标,通过建设多维度数据集进行用户满意度影响因素研究。
1数据来源
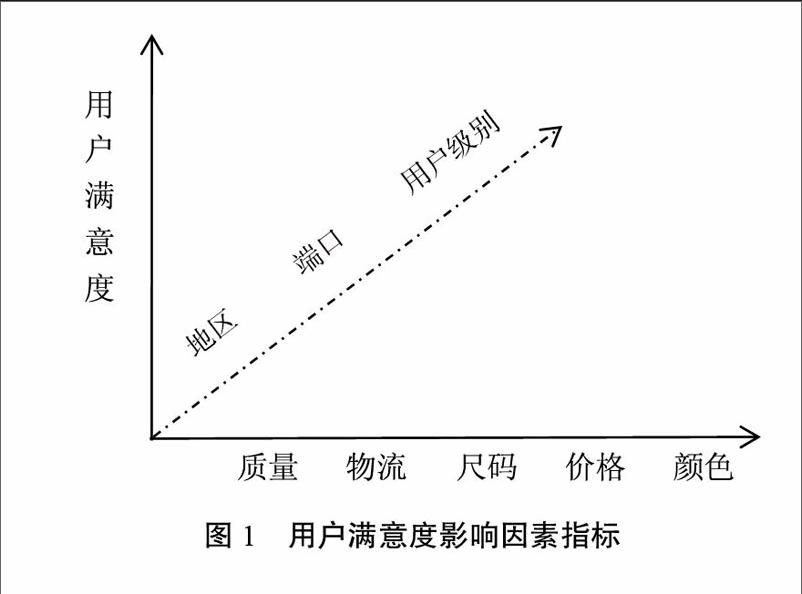
本文对京东商城的用户评论数据进行采集,使用网络爬虫软件八爪鱼对班尼路官方旗舰店男装T恤(链接https://item.id.COB/1574267931.html)的用户评论数据进行抓取,对每一条评论数据(如图1所示)中方框内各字段进行抽取,抽取的字段分别是:用户名、用户级别、地区、用户满意度(星级好评)、评论文本、价格、商品信息、颜色、尺码、评论时间、端口。将抽取的字段设置为自动导入数据库中以备后续分析。
2数据的抽取、清理和加载
由于抽取到数据库中的用户名仅显示首尾字符,中间字符是由星号键组成,故而容易出现不同用户共享同一用户名的情况或者同一用户名在不同时期的评论被数据库禁止读入的情况发生,因此需要将序号代替用户名作为表格中的主键进行分析以避免数据库读取数据失败的情况发生。截止至2017年3月19日共抓取到7000条评论数据,故而形成一张样本容量为7000条数据的评论数据总表(如表1所示)。数据库可实现在线实时更新,抓取的网页数据会自动加载到数据库中的评论数据总表中,为减少数据冗余,需要对数据进行清理,减少垃圾数据的读取。从竞争情报角度考虑,如果用户名、用户级别、地区三者完全一致的用户可被视为同一用户,因此可以设置联合主键的方式作为同一用户的判断条件,如果数据库中显示较为接近的时间段内由大批用户级别较低的评论涌入,则默认为是水军;如果同一用户在较为接近的时间段发表多条评论数据,则默认为是重复评论,只保留该用户的第一条评论;前者的评论数据置信度较低,后者评论数据产生冗余,为保证研究结果的准确可靠性,应将这两类的评论数据予以清除。
3用户满意度的影响因素指标
本文在数据库存储设计时创建多维数据集,从评论用户本身出发,设计以地区、端口(上网设备)、用户级别三个影响指标;从商品属性出发,由表征商品特征属性的特征词质量、物流、尺码、价格、颜色五个影响指标,如图1所示。本文試图从不同维度对用户满意度进行分析,商业智能软件Power BI能够实现对多维数据集进行数据处理,通过对用户满意度与影响指标间的各项数据进行自动化分析,寻找出用户满意度的关键影响因素。地区、端口、用户级别三项指标都能较易地由字符串数据转化为数值型数据;再利用情感分析法将评论文本中的字符型数据转化为语义识别后的数值型数据,从而作为用户满意度影响指标中的可分析处理的自变量,从而被商业智能软件识别和分析。
4评论文本的情感分析
4.1通过分词提取特征词
提取评论文本中特征词的方法中,Li,F等人采用句法结构树Skip-Tree CRFs提取评价特征词进行情感极性分析。Li,C.w等人利用了情报学专业中常见的逆文本频率指数(IDF)方法,对关键词权重进行排序后提取重要特征词并进行情感极性分析。这些方法效率虽高,但是忽略了评论文本中特征词的同义词产生的误差,从而影响研究结果的可靠度。本文采用半自动化提取的方式,设定特征词同义词表以提高整个研究的准确度。具体方法是:特征值显著的特点是词性为名词,因此本文通过对评论文本进行分词并统计词性为名词的高频特征词即可得到用户满意度影响因素指标。分词软件采用PHP简易中文分词(SCWS)第四版,将7000条评论文本分词为词语\词性(如质量\n)统计汇总后得到的高频特征词为以下几类:质量、物流、尺码、价格、颜色、活动、品牌、服务等;本文仅选取排名靠前的五项指标进行详细分析,即将质量、物流、尺码、价格、颜色作为用户满意度的影响因素指标进行后续分析。对出现特征词的同义词进行归类形成一特征词同义词表,如表2所示。特征词同义词表的作用是避免重复提取特征词以提高检索效率。如评论“颜色很好看,色彩很美,价格便宜”,其中“颜色”和“色彩”都属于颜色类特征词,数据库在提取同类型特征词时设置为仅提取首次出现的特征词,因此提取结果为特征词“颜色”、“价格”,将提取结果导人数据库一抽取词表表格中,然后该条评论结束读取跳转至下一条评论。
4.2情感词的定位及提取
相关学者将情感分析分为:有监督方法,如Ali,F采用机器学习的方法使用基于支持向量机(SVM)和改进版的模糊领域本体(FDO)方法进行情感极性判断;无监督方法,如李欣等人采用无监督方法通过多重聚类算法进行情感极性判断;f情感词典方法,如马松岳等人使用ROST EA情感词典工具进行情感分析。特征词显著的标志是词性为名词,而情感词则由多种词性组成,常见的是由副词和形容词组成,本文中采用以对评论文本分词后确定的特征词位置为基准,在特征词附近创建字符区间作为情感词定位区间,例如“挺好,穿了一天,性价比挺高的。”分词结果为“挺/v好/a穿/v了/v一/m天/n性价比/n挺/v高/a的/ui”。能够定位到特征词为“性价比”,属于“价格”类,情感词的取值范围为“一/m天/n、挺/v高/a”,接下来需要通过数据库的一情感词表与一抽取词表进行关联匹配出情感词并赋值得分。
