
基于K-medoids项目聚类的协同过滤推荐算法
2017-08-16 09:38:03万潇逸陶娅芝
重庆邮电大学学报(自然科学版) 2017年4期
王 永,万潇逸,陶娅芝,张 璞
(1.重庆邮电大学 经济管理学院,重庆 400065;2.重庆邮电大学 计算机学院,重庆 400065)

基于K-medoids项目聚类的协同过滤推荐算法
王 永1,万潇逸1,陶娅芝1,张 璞2
(1.重庆邮电大学 经济管理学院,重庆 400065;2.重庆邮电大学 计算机学院,重庆 400065)
针对传统协同过滤推荐算法通常针对整个评分矩阵进行计算,存在效率不高的问题,提出一种基于K-medoids项目聚类的协同过滤推荐算法。该算法根据项目的类别属性对项目进行聚类,构建用户的偏好领域,使用用户偏好领域内的评分矩阵进行用户间相似度的计算,得到目标用户的最近邻居集,并生成推荐结果。与常用的K-means聚类方法相比,采用K-medoids方法对项目类别属性进行聚类,不仅克服了评分聚类可靠性不高的问题,而且算法还具有更好的鲁棒性。实验结果表明,该算法能有效提高推荐质量。
协同过滤;K-medoids聚类;用户偏好;推荐算法
0 引 言
在互联网技术的普及与推动下,网络资源呈现出爆炸增长的态势,人们逐步进入了大数据时代。尤其在电子商务领域,当用户面对海量商品时,往往难以做出准确的判断。如何在海量的商品中快速准确地挑选出用户需求的产品并智能地推荐给目标用户,成为电子商务企业亟待解决的问题。为此,个性化推荐系统[1]被引入到了该领域中。目前,国内外几乎所有的大型电子商务平台都采用了自动化的推荐系统来服务用户。
推荐算法作为推荐系统中最为核心的部分,关系着整个推荐系统性能的好坏。当前推荐算法主要包括以下几种:基于内容的推荐,协同过滤推荐,基于网络的推荐和混合推荐等。协同过滤算法是目前在电子商务领域中应用最为广泛的个性化推荐技术,其基本假设是:如果用户身边的很多朋友都选购某种商品,那么用户自己就会很大几率地选择该商品;或者用户喜欢某类商品,当看到和这类商品相似的商品具有很高的评价时,则购买该商品的机率就会很高[2-4]。
1 相关研究
在电子商务的应用领域,用户对项目的评分数据具有数据覆盖面广,但稀疏性很大的特点。传统的协同过滤推荐算法往往针对整个用户评分矩阵进行计算,这严重制约了算法的运行效率和性能。为此,研究者们将聚类引入到推荐算法中,缩小了用户或项目的最近邻居搜索范围,从而提高了推荐的效率[5]。邓爱林等[6]根据用户对项目评分的相似性进行聚类,然后从与目标项目最相似的若干个聚类中寻找到目标项目最近邻居,该算法能够保证在尽量小的项目空间上查询到目标项目尽量多的最近邻,从而提高推荐系统的实时响应速度。孙辉等[7]提出了一种相似度改进的用户聚类协同过滤推荐算法,该算法提出相似可信度、用户对项目类别喜爱度和用户对项目类别关注度3个概念来优化相似度计算,然后以该相似度为基础进行用户聚类,最后依据同一类别中的用户进行推荐,从而提高推荐效率。王晓耘[8]提出了基于粗糙用户聚类的协同过滤推荐模型,该模型将推荐过程分为离线和在线两部分,离线时,采用粗糙K-means用户聚类算法将用户分配到k个类的上、下近似中形成用户的初始近邻集;在线时,从目标用户的初始近邻集中搜索其最近邻,预测项目评分并向其产生推荐。实验对比表明,该模型能有效提高推荐精度。许鹏远等[9]提出了一种基于聚类系数的推荐算法,该算法在标准二分图网络推荐算法的基础上加入了对聚类系数因素的考虑,重新定义了商品之间相似度的计算公式,从而获得了更加精确的推荐结果。
现有的诸多基于聚类的协同过滤算法虽在一定程度上提升了推荐的实时性与准确性,但同时仍然存在一些不足,主要表现为①仅对项目的评分数据进行聚类,没有考虑项目本身属性的相关性。电子商务领域内的用户评分值往往范围较小,这会导致聚类效果不好;②没有考虑用户实际的购买偏好。通常,用户只会对某个或某几个领域内的商品感兴趣。用户的历史购买记录则反映了用户对该商品所在领域是存在购买偏好的,而已有算法对此信息的关注度不够。针对上述问题,本文提出了一种基于K-medoids项目聚类的协同过滤推荐算法。根据项目的类别属性来对项目进行聚类,实现真正意义上的物以类聚,避免了使用评分数据进行聚类存在的缺陷。然后通过用户的历史购买记录与项目聚类的结果相结合,构建用户的偏好领域,并在用户的偏好领域内进行推荐。所以,本文的算法在提高算法执行效率的同时,也很好地保证了算法的推荐质量,对推荐算法在电子商务领域中的实际应用有着重要意义。
2 基于K-medoids项目聚类的协同过滤推荐算法
2.1 基于类别差异性的项目聚类
2.1.1 项目的类别差异性度量
在电子商务领域,项目往往拥有多个类别标签。假设项目所有的类别标签集合为T={t1,…,tp},那么项目A所属的类别信息则可使用向量IA=(A1,A2,…,Ap)来表示
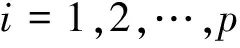
(1)
本文采用二元相异度来定义项目之间的类别差异性。设项目A和B的类别向量分别为(A1,A2,…,Ap)和(B1,B2,…,Bp),则项目A和B之间的类别差异性公式为
(2)
(2)式中:q表示Ai=Bi=1的变量的个数;r表示Ai=1,Bi=0的变量的个数;s表示Ai=0,Bi=1的变量的个数;t表示Ai=Bi=0的变量的个数。
2.1.2 基于K-medoids的项目聚类
本文将项目的类别差异性作为判断项目间距离远近的标准,采用K-medoids方法[10]对项目进行聚类。同时,为了减少K-medoids方法迭代的次数,我们改进了初始点的选择,从而提高了算法的效率。算法的具体处理过程如下。
步骤1 选择初始中心点
1)根据(2)式计算所有项目之间的类别差异性;
2)根据(3)式计算每个项目的Vj值;
(3)
3)将所有的Vj值按升序排序,选择前k个Vj值对应的项目作为初始中心点,得到个聚类簇{C1,C2,…,Ck};
4)计算非中心点与各中心点之间的类别差异性,并将非中心点项目分配到与之类别差异性最小的中心点所对应的簇中;
5)计算每个簇中所有项目与中心点项目之间的类别差异性之和,并将结果保存在变量Sum中。
步骤2 更新中心点。在每个簇中寻找新的中心点项目,要求新的中心点项目与簇中其他项目间之间的类别差异性之和最小。
步骤3 分配项目到各个簇中
1)依据类别差异性最小的原则,重新划分每个非中心点的项目。即将项目分配到与之类别差异性最小的中心点所在的簇中;
2)再次计算簇中其他所有项目与中心点项目之间的类别差异性之和,如果新得到的结果和Sum值相同,则算法结束;否则,返回步骤2。
2.2 用户偏好集合的构建
在电子商务应用领域,用户通常只会对某个或某几个领域内的项目感兴趣,因此,构建良好的用户偏好集合对最终的推荐结果有重要的影响。用户对项目的历史购买记录往往可以作为构建用户偏好集的重要依据。
假设项目的集合为I,根据2.1节提出的K-medoids聚类算法,得到项目聚类的簇集合为Cluster{C1,C2,…,Ck} 。对目标用户u,构建他的偏好集合和对应的评分矩阵过程如下。
步骤1 获取目标用户u已购买的项目集合,将其表示为Iu{Iu1,Iu2,…,Iux}。
步骤2 搜索项目聚类空间Cluster,找到Iu中每一个项目所属的簇集,将这些簇集合并到一起,即为用户u的偏好集合。
步骤3 根据用户的偏好集合,从整体的评分矩阵中抽取对应项目的评分,即得到该偏好集合对应的评分矩阵。
2.3 推荐算法
本文提出的推荐算法的具体步骤如下。
步骤1 项目聚类。首先根据2.1.1节的方法,计算项目之间的类别差异性;然后,根据2.1.2节的K-medoids聚类方法,完成对项目聚类操作,得到相应的簇。
步骤2 构建目标用户评分矩阵。按照2.2节的方法,基于步骤1中得到的项目簇,得到目标用户的偏好集合。然后,以偏好集合为依据,从整个用户评分矩阵中划分出针对目标用户的子评分矩阵。
步骤3 计算用户相似度。由于步骤2已经将计算用户相似度的数据空间从整个用户评分矩阵缩减为了用户偏好领域内的评分矩阵,因此,利于提高推荐算法的执行速度。本文使用修正余弦公式度量用户的相似性,其公式为
sim(i,j)=
(4)
步骤4 计算用户相似度。由于步骤2已经将计算用户相似计算预测评分并产生推荐项目。根据步骤3中得到的用户的相似度,从中选取TOP-N个最邻近的用户;然后,根据邻近用户的评分预测目标用户对项目的评分。假设目标用户为u,其最近邻居集合为Nu,那么用户u对项目i的预测评分Pu,i为

(5)
(5)式中:Rx,i表示用户x对项目i的评分;Ci表示项目i所在的簇;N1和N2分别表示用户u和x在Ci内评分的项目总数。
通过上述方法,对目标用户偏好领域内的所有未评分的项目预测其评分,得到待推荐项目预测评分集合L。设定阈值α,将预测评分Pu,i大于α的项目推荐给目标用户,其余的项目则不推荐。
3 实验结果与分析
3.1 数据集
采用美国Minnesota大学GroupLens项目组提供的MovieLens数据集[2]作为实验数据集。该数据集是目前协同过滤推荐领域使用最为广泛的非商业性质的数据集。MovieLens数据集中,每位用户至少对20部电影进行了评分,评分范围为1到5的整数。MovieLens提供了多种规模的数据集,本文选用ml-100k数据集作为算法测试的对象,该数据集包括了943名用户对1 682部电影的100 000个评分数据。
3.2 评估指标
目前,推荐系统主要使用统计精度度量和决策支持精度2大类方法来评价推荐算法的好坏。统计精度度量方法中最常用的评价指标是平均绝对偏差(mean absolutely error ,MAE)。
MAE通过比较用户对项目的预测评分值与实际评分值之间的偏差来衡量预测结果的准确性,MAE 越小,准确性越高[11]。MAE的计算公式为
(6)
(6)式中:pi表示用户对项目i的预测评分;qi表示用户对项目i的实际评分;N表示总的评分数目。
决策支持精度度量方法中主要的评价指标有召回率(Recall)、准确率(Precision)等。召回率反映了待推荐的项目被推荐的比率,准确率则反映了推荐的成功率,计算公式分别为
(7)
(8)
(7)—(8)式中:PrecisionSet表示算法推荐的项目集合;ReferenceSet表示用户实际进行了评分的项目集合。
由于准确率与召回率之间存在负相关关联,为了综合考虑这两方面的性能,故而使用综合值F在二者间找到最佳平衡点,F的值越高,推荐效果越好,计算公式为
(9)
3.3 实验结果分析
为了测试算法的推荐质量,本文设计了2组实验来进行检验。第1组实验使用数据集提供的已划分好的训练集与测试集来计算MAE并与其他算法进行对比。参与对比的算法有基于用户的协同过滤推荐[3]、一种相似度改进的用户聚类协同过滤推荐[7]和基于粗糙用户聚类的协同过滤推荐[8]。第2组实验使用全部的用户评分数据,然后采用随机抽取的方法将数据集划分为训练集与测试集,训练集与测试集所占的比例分别为80%和20%,该部分实验用来计算Recall,Precision和F,参与该组实验对比的算法有基于用户的协同过滤推荐[3]、基于聚类系数的推荐算法[9]。
第1组实验,将目标用户的邻居个数从10增加到30,间隔为5,查看邻居集大小的改变对MAE值的影响。MAE值越小,预测评分与用户的实际评分之间的偏差越小,推荐精度越高。实验对比结果如图1所示。可以发现,在不同大小的邻居用户集条件下,本文算法的MAE值都明显小于其他几种算法,说明本文算法的推荐质量是优于其他几种算法。
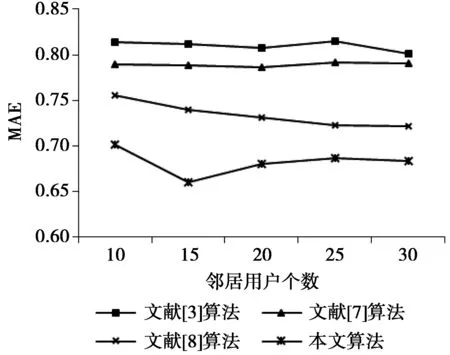
图1 MAE对比图Fig.1 Comparison chart of MAE
第2组实验,考虑到实际推荐过程中不会将所有计算了预测评分的项目都推荐给目标用户,因此,设置阈值过滤预测评分过低的项目,实验结果如图2所示。可以看到,随着阈值的增大,召回率呈现大幅下降的趋势,准确率呈现小幅上升趋势,F值则在阈值处于中间水平时保持较小幅度的波动,当阈值过高时,则会呈现出下降趋势。
表1列出了本文算法与基于用户的协同过滤推荐[3]和基于聚类系数的推荐算法[9]的实验对比结果。可以看出,本文算法的准确率和F值相较于其他2种算法更高,说明本文算法的推荐效果更佳。
本文使用项目类别属性对项目进行聚类,并依据聚类结果来构建用户的偏好领域,最终将整个数据集缩减为目标用户偏好领域内的数据集。相较于传统的协同过滤推荐算法,本文算法在效率上的提升主要体现在2个方面:①计算相似度时,可以提高搜索效率,从而提高计算效率;②在选择待推荐项目时,只选择用户偏好领域内的项目,可以减少无效项目的预测评分的计算,从而提升算法性能。
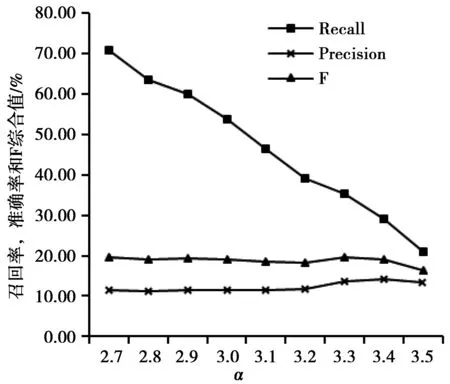
图2 决策精度实验结果Fig.2 Experimental results of decision accuracy
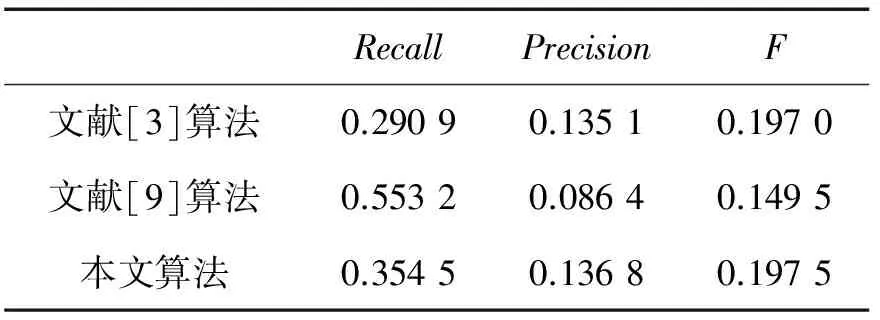
RecallPrecisionF文献[3]算法0.29090.13510.1970文献[9]算法0.55320.08640.1495本文算法0.35450.13680.1975
4 结束语
针对传统协同过滤推荐算法在整个评分矩阵上进行计算存在效率不高以及未考虑用户偏好导致推荐质量不高的问题,本文提出了一种基于K-medoids项目聚类的协同过滤推荐算法。本算法首先根据项目的类别属性对项目进行类别差异性度量并以此为依据对项目进行聚类处理,然后构建目标用户偏好集合及对应的用户评分矩阵。一方面缩减了用户评分矩阵,提升了算法的计算效率;另一方面,考虑了用户偏好问题并在用户偏好领域内进行推荐,提高了推荐质量。实验结果表明,本文提出的基于K-medoids项目聚类的协同过滤推荐算法相较于文中对比的其他几种推荐算法,在评测指标上效果表现更好,说明本文提出的推荐算法是可行且有效的。
[1] 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362. XU Hailing,WU Xiao,LI Xiaodong,et al.Comparison Study of Internet Recommendation System[J].Journal of Software,2009,20(2):350-362.
[2] 奉国和,梁晓婷.协同过滤推荐研究综述[J].图书情报工作,2011,55(16):126-130. FENG Guohe,LIANG Xiaoting.Review on collaborative filtering recommendation[J].Library and Information Service,2011,55(16):126-130.
[3] YU Chuan,XU Jieping,DU Xiaoyong .Recommendation algorithm combining the user-based classified regression and the item-based filtering[C]// International Conference on Electronic Commerce: the New ECommerce-Innovations for Conquering Current Barriers,Obstacles and Limitations To Conducting Successful Business on the Internet,2006.Fredericton,New Brunswick,Canada:DBLP,2006:574-578.
[4] KARYPIS G.Evaluation of Item-Based Top-N Recommendation Algorithms[C]//Tenth International Conference on Information and Knowledge Management. [s.l.]: ACM Press, 2000: 247-254.
[5] 曹洪江,傅魁.协同过滤推荐系统中聚类搜索方法研究[J].计算机工程与应用,2014,50(5):16-20. CAO Hongjiang,FU Kui.Research on clustering search method in collaborative filtering recommendation system[J].Computer Engineering and Applications, 2014,50(5):16-20.
[6] 邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):1665-1670. DENG Ailin,ZUO Ziye,ZHU Yangyong.Col laborative Filtering Recommendation Algorithm Based on Item Clustering[J].Journal of Chinese Computer Systems,2004,25(9):1665-1770.
[7] 孙辉,马跃,杨海波,等.一种相似度改进的用户聚类协同过滤推荐算法[J].小型微型计算机系统,2014,35(9):1967-1970. SUN Hui,MA Yue,YANG Haibo,et al.Collaborative filtering recommendation algorithm by optimizing similarity and clustering users[J].Journal of Chinese Computer Systems,2014,35(9):1967-1970.
[8] 王晓耘,钱璐,黄时友.基于粗糙用户聚类的协同过滤推荐模型[J].现代图书情报技术,2015,31(1):45-51. WANG Xiaoyun,QIAN Lu,HUANG Shiyou.Collaborative Filtering Recommendation Model Based on Rough User Clustering[J].New Technology of Library and Information Service,2015,31(1):45-51.
[9] 许鹏远,党延忠.基于聚类系数的推荐算法[J].计算机应用研究,2016,33(3):654-656. XU Pengyuan,DANG Yanzhong.Modified recommendation algorithm based on clustering coefficient[J].Application Research of Computers,2016,33(3):654-656.
[10] PARK H S,JUN C H.A simple and fast algorithm for K-medoids clustering[J].Expert Systems with Applications,2009,36(2):3336-3341.
[11] 朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175. ZHU Yuxiao,LV Linyuan.Evaluation metrics for recommender systems[J].Journal of University of Electronic Science and Technology of China,2012,41(2):163-175.

万潇逸(1991-), 男, 湖北安陆人, 硕士研究生, 主要研究领域为Web数据挖掘, 管理信息系统等。

陶娅芝(1991-), 女, 重庆人, 硕士研究生, 主要研究领域为知识发现, Web数据挖掘等。

张 璞(1977-), 男, 重庆人, 副教授,博士, 主要研究领域为自然语言处理, 语义分析和文本挖掘。
(编辑:王敏琦)
s:The National Science Foundation of China (61502066);The Chongqing frontier and applied basic research (general) (cstc2015jcyjA40025);The Social Science Planning Fund Program (2015SKZ09)
In general, traditional collaborative filtering recommendation algorithms do the prediction computation based on the whole rating matrix, which leads to the low efficiency. To remedy this weakness, a collaborative filtering recommendation algorithm based on K-medoids item clustering is proposed. The proposed algorithm clustered the items according to the item category attributes, and then constructed the user preference domain. Only the rating matrix in the user preferences domain is used to calculate the user similarity and generates the nearest neighbor set of the target user and recommendation results. Different from the other K-means based clustering methods, the present K-medoids based clustering method focuses on the item category attributes, which overcomes the low reliability problem of using user ratings. Moreover, the present clustering method has better robustness. Experimental results show that the proposed algorithm improves the recommendation quality.
collaborative filtering;K-medoids clustering;user preference;recommendation algorithm
10.3979/j.issn.1673-825X.2017.04.015
2017-01-10
2017-05-22 通讯作者:王 永 wangyong1@cqupt.edu.cn
国家自然科学基金(61502066);重庆市前沿与应用基础研究(一般)项目(cstc2015jcyjA40025);重庆市社会科学规划管理项目(2015SKZ09)
TP391
A
1673-825X(2017)04-0521-06
Collaborative filtering recommendation algorithm based onK-medoids item clustering
(1.School of Economics and Management, Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China;2.School of Computer Science, Chongqing University of Posts and Telecommunications, Chongqing 400065,P.R. China)
王 永(1977-), 男, 四川自贡人, 教授,博士,主要研究领域为Web数据挖掘, 知识发现, 信息安全与信息管理。负责和参与国家和省部级项目10余项,在国内外重要学术刊物上发表学术论文30多篇,被SCI检索10篇次,EI检索10篇次。E-mail:wangyong1@cqupt.edu.cn。
WANG Yong1,WAN Xiaoyi1,TAO Yazhi1,ZHANG Pu2
猜你喜欢
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
电子测试(2017年15期)2017-12-18 07:19:27
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
新校长(2016年8期)2016-01-10 06:43:59
智能系统学报(2015年4期)2015-12-27 09:38:39
大众摄影(2015年9期)2015-09-06 17:05:41
电子设计工程(2015年6期)2015-02-27 12:04:53
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
