
基于MCA与判别字典学习的场景图文字检测方法*
2017-08-09 01:34刘舒萍汤宏颖
传感器与微系统 2017年7期
刘舒萍, 汤宏颖
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
基于MCA与判别字典学习的场景图文字检测方法*
刘舒萍, 汤宏颖
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
传统的文字检测方法在场景图像复杂背景、噪声污染和文字的多种形态特征的干扰下,检测的准确率很低,漏检、误检非常严重。针对这些问题,提出了基于形态成分分析(MCA)与判别字典学习的场景图像文字检测的方法。通过学习过完备字典将文字检测问题转化成稀疏和鲁棒表示的问题。利用MCA与改进的Fisher判别准则学习一个过完备字典,求解待检测图像文字部分的稀疏系数,重建待检测图像中的文字图像,进行文字检测。通过在ICDAR2003/2005/2011和MSRA—TD500数据库中的大量的实验证明了与其他文字检测方法相比,该方法能有效提高检测准确率。
形态成分分析; 字典学习; 稀疏表示; Fisher判别; 图像重构
0 引 言
图像和视频中往往包含着大量的文本信息,这些文本直接携带图像和视频的语义信息,使图像中的文字检测和识别在图像检索和分类中有着非常重要的意义。光学字符识别技术[1]使文字识别变得简单,但是文字识别严重依赖于文本区域检测的结果。
基于连通区域的方法[2]利用图像中文字颜色的相似性构成一个或几个连通区域,该方法对标题文字和嵌入的文字有明显效果,运行效率也很高,但是对复杂的场景图像文字检测的效果很差。基于纹理的方法[3]将文字作为特殊纹理结构,通过检测和评估纹理特征的局部强度及其滤波响应特性来确定文本和非文本,其缺点是当背景的纹理和文字的纹理很相似时,检测准确率很低且耗时。基于频域的方法[4]取得了不错的效果,但是耗时长且文字检测效果相对于基于时域的文字检测效果并没有很大提升。基于梯度的方法[5]对于文字和背景梯度比较大的图像处理效果很好,比基于纹理的方法在时间上运行快,但是对背景特性比较敏感常常产生虚警。
上述方法在处理简单的场景图像和纯文本图像时检测的准确率很高,但是对于复杂的场景图像检测的结果很不理想,文字检测的准确率和召回率很低,原因是场景图像的分辨率比较低、背景纹理很复杂、字体的大小方向变化多样和图像受噪声污染严重[5]等。
受人类视觉稀疏编码机制的启发,用稀疏表示的方法表示信号和图像的方法被提出来了[6]。稀疏表示已经在人脸识别、信号分类、图像恢复和压缩感知[7]等方面有很好的应用。近年来,有研究者提出把稀疏表示应用在文字检测上,通过k-means聚类和奇异值分解(k-singular value decomposition,K-SVD)的算法提取图像的边缘信息来学习的字典[8],但是稀疏表示的方法对于包含大量噪声的图像会产生错误的实验结果。
针对现有文字检测的方法的不足,本文提出一种基于形态成分分析(MCA)和判别字典学习的场景图像文字检测方法。利用MCA的方法把含有文字的图像看成两部分构成:文字部分和背景部分;用提出的字典学习的方法学习一个过完备的判别字典,利用学习到的字典稀疏重构图像的文字部分,进而启发式规则对重构的文字部分进行处理,得到最终文字区域。
1 稀疏表示模型
1.1 稀疏表示
近年来稀疏表示模型经常用于处理图像方面的工作如纹理分割、图像去噪[9]和特征提取等,稀疏表示通过过完备字典中原子的线性组合来稀疏地表示信号,给定一个信号y∈Rn和一个矩阵A={a1,a2,…,am}∈Rn×m,等式y=Ax,(m≫n)是一个稀疏表示问题。为了找到表示图像的最稀疏的解x,需要求解下式

(1)
求解式(1)是一个NP-hard问题,文献[10]提出的一种有效追踪算法可以近似求解这种问题,即把上式中的‖x‖0可以近似地转化为‖x‖1,研究表明在上述解足够稀疏情况下,是一个唯一的解。
1.2 字典学习
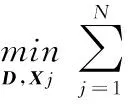
(2)
字典D为通过迭代优化D和Xj求解得到的,这里j=1,…,N,给定Xj时,式(2)转化为最小二乘法求解问题
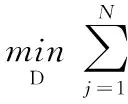
(3)
用拉格朗日对偶算法求解如下
(4)
式中 ∧为对偶向量,Y=[Y1,…,YN]和X=[X1,…,XN]。
固定D,迭代优化Xj,其他的稀疏编码值Xi(i≠j) 固定。式(2)转换为

(5)
这个问题可以用OMP算法求解[10]。
2 基于MCA和判别字典学习的场景图像文字检测
2.1 数据采集和预处理
数据采集阶段的首要任务是增强文字特征,弱化背景的特征。这里在数据采集的时候用自适应滤波器对文字和背景数据预处理,达到在去除噪声的同时弱化背景纹理的目的。另外,由于文字的纹理特征往往具有相似的几何特征,在采集完文字训练数据之后,对文字训练数据进行谱聚类操作,使相似的特征聚在一类为后续字典的学习提高运行效率。由于背景结构复杂没有统一的特征,本文不对背景做聚类操作。
2.2 判别字典的学习
由于Fisher判别准则可以提高稀疏编码的判别能力[11],本文利用图像的底层信息即用改进的Fisher判别f(DX)来增强字典和稀疏表示系数的判别性。判别能力通过最小化类内距Sw(DX)、最大化类间距SB(DX)获得,方法如下
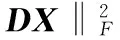
(6)
(7)
用本文提出的字典学习的方法学习一个结构化的字典D=[D(T),D(B)],其中D(T)=[D1,…,Dm,…,DN]为学习的文字字典,文字训练数据共N类,待检测图像表示为Y,Y=[Y1,…,Yk],待检测图像对应的稀疏表示系数为X,如Y=DX。其中X=[X1,…,Xi,…,Xk],Xi为Yi在D中的稀疏表示系数。求解这样过完备字典D需求解下式

(8)
式中λ1,λ2为尺度参数,为了防止出现任意大的l2范数,这里把D中的每个原子di归一化。为了去除图像Y的加性噪声的影响,松弛式(8)的限制条件变为

s.t.‖di‖2=1
(9)
2.3 算法步骤和分析
同时求解式(9)中的D和X为非凸的,但单独求解其中一个,即固定D求解X或固定X求解D时,式(9)为凸函数。因此,本文用迭代优化的方法来求式(9)中最优的D和对应的X。
2.3.1 更新X的算法
在给定D初始值的情况下,求解式(9)转换为求解X=[X1,X2,…,Xk]的问题,以类为单位更新X。当更新Xm时,所有的Xn,m≠n是固定值,m和n是不同的类。式(9)转换为

(10)


(11)
这里
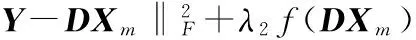
τ=λ1/2
(12)


表1 更新稀疏表示系数X
2.3.2 更新D的算法
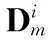

s.t.‖di‖2=1
(13)
2.4 文字图像重构和文字检测
重构的文字图像YT是通过学习到的字典D和待检测图像文字部分对应的稀疏表示系数X(T)重构的,如下式
YT=DX(T)
(14)
正如前面所述,学习的字典D为D(T)和D(B)线性组合

表2 字典学习算法
矩阵,因此,待检测图像对应的稀疏编码系数为X=[X(T),X(B)]T,这里,X(T)和X(B)分别为待检测图像文字和背景部分的稀疏编码。利用式(15)可以获得待检测图像的稀疏编码

(15)
这里的Y为待检测图像数据,D为学习到的字典。通过上式求解到稀疏编码X=[X(T),X(B)]T之后,把X(T)带入式(14)中,得到重构的YT,然后把YT以图像的形式显示出来,图像的大小和原图一样,如图1(c)所示。
在重建的文字图像上进行文字检测。首先对重建的文字图像用启发式规则如形态学处理、双阈值限制,面积宽高比等方法去除错误重建的噪声或背景部分;然后找到重建的文字图像的连通区域的重心点,重心点连线的水平方向和垂直方向角度在一定阈值的连接在一起,其余的连通区域判定为噪声干扰,连接图如图1(d)所示;以连通区域的重心点为中心,给定阈值限定为边长的矩形框包围这些连通区域,这些矩形框所包围的区域为候选的文字区域如图1(e)所示;最后候选的文字区域用水平方向是否一致的方法和矩形框面积阈值限定的方法进行判断矩形框之间是否水平合并,对于不满足合并条件的矩形框直接舍弃最后得到一个大的矩形区域,即检测到的文本区域如图1(f)所示。

图1 本文方法流程
3 实验结果与分析
本方法在ICDAR数据库和MSRA—TD500数据库上进行实验,部分实验结果如图2所示,可以看出本方法不限于文字的类型、语言、颜色和尺度,本部分对不同参数对实验结果的影响进行分析,并与近几年出现的其他的文字检测算法在检测的准确率、召回率和F值等方面进行对比。

图2 本文方法处理结果展示
3.1 参数选择的分析
本实验涉及一些参数设置问题,这些值对实验结果有很重要的影响,本文公式中出现的参数是恒定的常量IST_iter。 表示稀疏编码阶段设置的迭代次数,niter表示字典学习阶段设置的迭代次数, blocksize表示滑动窗口的大小。其设置的具体值如表3所示。

表3 参数设置
在数据预处理阶段文字训练样本分类数对于重建文字图像的效果有很大的影响,通过分析中文和英文的文本特征,发现文字类的分法与文字和背景的纹理特征有很大的关系,在类数过多和过少的情况下都容易重建出噪声部分。实验如图3所示。

图3 不同类对应的文字重建结果
结果显示分类学习到的字典要比不分类学习的字典表征能力强,分的类数越高,文字重建的结果越好,当类数达到5时效果达到最好。当分的类数高于5时,重建的效果变差。
3.2 残差的分析

图4显示这两条曲线下降的都常快,在第4次迭代时基本达到了最小值,两条曲线都在第12次迭代时达到了最小值点,这时字典学习和稀疏系数的求解也都结束。本文设置字典学习的迭代次数为12。

图4 字典学习和稀疏表示阶段对应的残差曲线
3.3 实验对比
表4是在ICDAR数据库上进行的实验对比结果。目前的方法如文献[13]、文献[14]、文献[16]、文献[17]、文献[18]效果很好,其中文献[17]赢得了ICDAR—2013竞赛。
在ICDAR2003数据库做的实验结果显示,本文提出的方法得到了召回率73 %和准确率72 %,文献[15]中的方法在准确率73 %方面和本文提出的方法相差不大,但是召回率60 %和本文有很大差距。在ICDAR—2011数据库中,本文提出的方法得到了最高的准确率81 %和较高的召回率72 %。由于ICDAR2013与ICDAR2011数据库之间差别很小,只是增加了几张图片,所以,两数据库的实验结果也很相近。

表4 不同数据库中本文方法与其他方法对比
图5为在ICDAR2005数据库中进行的字典学习方法的实验对比。可见本文的字典学习更好的表征文字特征。
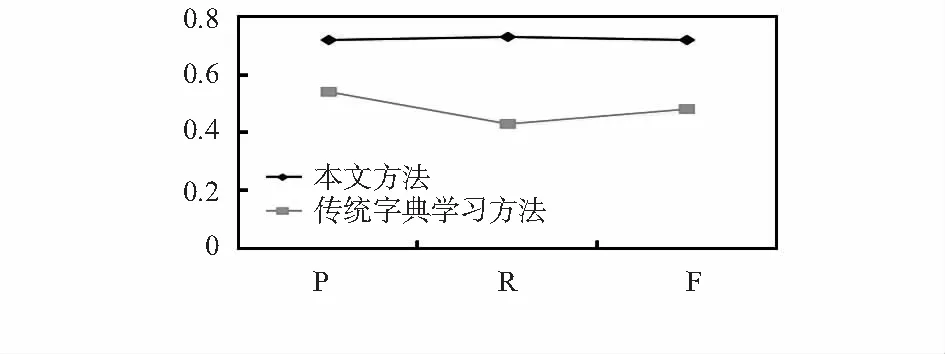
图5 本文提出的字典学习方法与传统字典学习方法对比
4 结 论
将场景图像的文字检测的问题转化为在重构的文字图像上进行文字检测的问题。提出的用形态成分分析的思想将图像分为复杂背景和前景文字两部分,有效地避免了场景图像背景的干扰;用稀疏表示的方法学习字典的时候本文引入了判别字典学习的方法,增强了字典的表示能力;实验结果表明:本文提出的方法比现存的其他方法效果要好,尤其本方法不限于文本尺寸、颜色和其他的一些文本特性。下一步的研究点集中于自适应字典学习的方法研究,学习一个自适应变化的字典更加高效地反映待检测图像特征。
[1] Grafmüller M,Jürgen B.Performance improvement of character recognition in industrial applications using prior knowledge for more reliable segmentation[J].Expert Systems with Applications,2013,40(17):6955-6963.
[2] Liu Y,Song Y,Zhang Y,et al.A novel multi-oriented Chinese text extraction approach from videos[C]∥2013 the 12th International Conference on Document Analysis and Recognition,IEEE,2013:1355-1359.
[3] Yan J,Li J,Gao X.Chinese text location under complex background using Gabor lter and SVM[J].Neuro Computing,2011,74(17):2998-3008.
[4] Shivakumara P,Phan T Q,Tan C L.New wavelet and color features for text detection in video[C]∥International Conference on Pattern Recognition,IEEE Computer Society,2010:3996-3999.
[5] Hu W,Ding X,Li B,et al.Multi-perspective cost-sensitive context-aware multi-instance sparse coding and its application to sensitive video recognition[J].IEEE Transactions on Multimedia,2016,18(1):76-89.
[6] 宋和平,王国利.基于贪婪重建的射频传感器网络稀疏目标跟踪[J].传感器与微系统,2013,32(11):25-28.
[7] 王 冲,张 霞,李 鸥.无线传感器网络中基于压缩感知的分簇数据收集算法[J].传感器与微系统,2016,35(1):142-145.
[8] Aharon M,Elad M,Bruckstein A.K-SVD:An algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing,2006,54(11):4311-4322.
[9] 沈千里,陈 晓,支亚京,等.一种新的人脸图像去噪算法[J].传感器与微系统,2015,34(11):133-136.
[10] Chen S,Billings S A,Luo W.Orthogonal least squares methods and their application to non-linear system identification[J].International Journal of Control,2007,50(5):1873-1896.
[11] Zheng H,Tao D.Discriminative dictionary learning via Fisher discrimination K-SVD algorithm[J].Neurocomputing,2015,162(C):9-15.
[12] Bioucas-Dias J M,Figueiredo M A T.A new twist:Two-step iterative shrinkage/thresholding algorithms for image restoration[J].IEEE Transactions on Image Processing,2007,16(12):2992-3004.
[13] Anton V D H.Characterness:An indicator of text in the wild[J].IEEE Transactions on Image Processing:A Publication of the IEEE Signal Processing Society,2013,23(4):1666-77.
[14] Wang X,Song Y,Zhang Y.Natural scene text detection with multi-channel connected component segmentation[C]∥International Conference on Document Analysis and Recognition,IEEE Computer Society,2013:1375-1379.
[15] Epshtein B,Ofek E,Wexler Y.Detecting text in natural scenes with stroke width transform[C]∥2013 IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2010:2963-2970.
[16] Khare V,Shivakumara P,Raveendran P.A new histogram oriented moments descriptor for multi-oriented moving text detection in video[J].Expert Systems with Applications,2015,42(21):7627-7640.
[17] Zhang Y,Lai J,Yuen P C.Text string detection for loosely constructed characters with arbitrary orientations[J].Neurocompu-ting,2015,168(C):970-978.
Text detection from natural-scene images using MCA and discriminative dictionary learning*
LIU Shu-ping, TANG Hong-ying
(School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China)
It is very difficult to locate and recognize text in natural-scene images by interference of complex background,noise pollution and multiple morphological of text using traditional text detection method.Propose a novel method for detecting text in natural-scene images using MCA and discriminative dictionary learning method.Text-detection problems are converted to sparse and robust representations by learning redundant dictionary.An over-complete dictionary is learned using MCA and an improved version of Fisher’s discriminant law,the sparse-representation coefficients of text components in the query image are obtained using the learned dictionary.Text image is reconstructed in image to be test,and text test is carried not.The proposed method is extensively evaluated using International Conference on Document Analysis and Recognition(ICDAR)2003/2005/2011 datasets and MSRA-TD500 datasets,and it can effectively improve accurary of detection.
MCA; dictionary learning; sparse representation; Fisher discrimination; image reconstruction
10.13873/J.1000—9787(2017)07—0045—05
2016—05—09
国家自然科学基金应急管理项目(NSFC61540042);云南省教育厅科学研究基金重点资助项目(2015Z045)
TP 399
A
1000—9787(2017)07—0045—05
刘舒萍(1989-),女,硕士研究生,主要研究方向为图像处理、模式识别。
汤宏颖(1979-),女,通讯作者,博士,讲师,从事图像处理、模式识别等研究工作,E—mail:tannya_0@163.com。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
软件(2020年3期)2020-04-20
小学阅读指南·低年级版(2019年11期)2019-07-01
摄影之友(影像视觉)(2018年12期)2019-01-28
中国交通信息化(2018年5期)2018-08-21
小天使·一年级语数英综合(2017年11期)2017-12-05
Coco薇(2017年8期)2017-08-03
读者(2016年14期)2016-06-29
