
DBpedia Spotlight上的命名实体识别优化*
2017-07-31 20:56:06付宇新冯志勇
计算机与生活 2017年7期
付宇新,王 鑫+,冯志勇,徐 强
1.天津大学 计算机科学与技术学院,天津 300354
2.天津市认知计算与应用重点实验室,天津 300354
3.天津大学 软件学院,天津 300354
DBpedia Spotlight上的命名实体识别优化*
付宇新1,2,王 鑫1,2+,冯志勇2,3,徐 强1,2
1.天津大学 计算机科学与技术学院,天津 300354
2.天津市认知计算与应用重点实验室,天津 300354
3.天津大学 软件学院,天津 300354
+Corresponding autho author:r:E-mail:wangx@tju.edu.cn
FU Yuxin,WANG Xin,FENG Zhiyong,et al.Nam ed entity recognition optim ization on DBpedia Spotlight.Journalof Frontiersof Com puter Science and Technology,2017,11(7):1044-1055.
命名实体识别任务能够搭建知识库与自然语言之间的桥梁,为关键字提取、机器翻译、主题检测与跟踪等研究工作提供支撑。通过对目前命名实体识别领域的相关研究进行分析,提出了一套通用的命名实体识别优化方案。首先,设计并实现了利用候选集的增量式扩展方法,降低了对训练集的依赖性;其次,通过点互信息率对实体上下文进行特征选择,大幅度降低了上下文空间,同时提高了标注性能;最后,提出了基于主题向量的二次消歧方法,进一步增强了标注准确率。通过在广泛使用的开源命名实体识别系统DBpedia Spotlight上进行多种比较实验,验证了所提优化方案与已有系统相比具有较优的性能指标。
命名实体识别;链接数据;DBpedia Spotlight
1 引言
作为信息提取领域的任务之一,命名实体识别能够在给定的文本中识别出所有实体的命名性指称,并链接到其在知识库中的参照,从而搭建起知识库与自然语言文本之间的桥梁。随着维基百科的发展以及包括DBpedia[1]、YAGO[2]等知识库的发布,使用命名实体识别丰富文本背后的语义并为应用提供智能服务变得越来越重要,因此如何提高命名实体识别的性能成为许多研究工作的焦点。
命名实体识别宏观上包括3个步骤:第一步是命名性指称识别,即尽可能地识别出文本中可能出现的命名性指称;第二步是候选集生成,即对于每个命名性指称,构成一个由知识库中可能与之对应实体组成的候选集;最后一步是候选集消歧,即在每个命名性指称对应的候选集中确定唯一的实体匹配。
本文提出了一套命名实体识别优化方案,能够适用于目前大部分的命名实体识别系统,并从三方面改善命名实体识别的性能。
本文的主要贡献如下:
(1)提出了使用候选集对一个命名实体识别系统进行增量式扩展的方法,降低了对训练数据集的依赖,提高了灵活性。
(2)通过考虑上下文单词与实体的相关性,提出了点互信息率的概念,并使用其作为阈值对每个实体的上下文进行特征选择,大幅度降低了上下文空间,同时提高了系统的标注性能。
(3)使用维基百科文章之间的链接为实体和文本构建主题向量代替M ilne-W itten语义关联度,并基于主题向量提出了二次消歧算法,进一步提高了系统标注的准确率。
(4)通过将优化方案实现在目前广泛使用的开源命名实体识别系统DBpedia Spotlight上,并在多个测试数据集上设计完善的实验,验证了所提优化方案与已有系统相比具有较优的性能指标。
本文组织结构如下:第2章介绍相关研究工作;第3章给出命名实体识别优化方案的三方面内容;第4章介绍基于命名实体识别系统DBpedia Spotlight的优化方案实现;第5章详细描述对比实验设计和实验结果;第6章对全文进行总结。
2 相关研究工作
由于命名实体形式多变并且语言环境复杂,正确地对候选集进行消歧尤为重要。例如,实体China可以在文本中通过命名性指称“China”或“PRC”等来指代,而命名性指称“Apple”也可能指代的是水果或苹果公司。
Cucerzan[3]最先提出了基于词袋的方法,利用维基百科的标注数据构造实体的上下文向量和类别向量,并将文本中的表现形式标注到与之相似度最高的实体上。Medelyan等人[4]考虑到文本应该具有一个中心主题,因此选择候选集中与文本之间的语义关联度最高的实体作为消歧结果。M ilne和Witten[5]在利用语义关联度的同时,考虑了实体的流行度和上下文质量,并结合朴素贝叶斯、C4.5决策树、支持向量机等机器学习方法对候选集进行消歧。Olieman[6]、Lipczak[7]等人的工作选取了更多的特征,使消歧的效果得到了进一步的提高。Kulkarni等人[8]的工作结合了上下文向量的余弦相似度和实体之间的语义相似度,将标注问题规约到了线性优化问题,通过选择一个最优的标注结果,使得最终文本得到的实体之间局部相似度和全局相似度之和最大。Han等人[9]提出了基于图的候选集消歧算法,利用所有表现形式和候选集构造“指示图”,并为图上的每个点赋予一个初始得分,利用随机游走算法,最终选择稳定后的最高得分实体。Hoffart[10]和Usbeck[11]等人也同样使用基于图的候选集消歧方法,并将不同的图构建算法和图消歧算法作为研究的重点。
已有的工作仍然具有以下几点问题:(1)命名实体识别系统普遍使用维基百科知识库中的人工标注结果作为支持数据,因此维基百科中没有出现过的标注也不可能出现在系统的标注结果中;(2)实体上下文是候选集消歧的最重要的特征,而所有命名实体识别系统仅仅选择去除其中的停用词,而忽略了一些“类停用词”带来的噪音;(3)主题一致性同样是一个重要的用于候选集消歧的特征,而一部分命名实体识别系统受限于本身的核心消歧算法,缺少高效的手段来与主题一致性相融合。围绕这些问题,本文提出了一套命名实体识别优化方案,可以有效地提高命名实体识别系统的性能。
3 命名实体识别优化方案
下面主要介绍命名实体识别优化方案的三部分:基于候选集的增量扩展方法,基于点互信息率的特征选择以及基于主题向量的二次消歧。
3.1 基于候选集的增量扩展方法
原有的包括DBpedia Spotlight在内的命名实体识别系统中,例如TagMe(http://acube.di.unipi.it/tagme)、AIDA(http://www.mpi-inf.mpg.de/yago-naga/aida)、Wikipedia M iner(http://w ikipedia-miner.cms.waikato.ac.nz)等普遍都需要使用基于维基百科数据得到的字典和候选集来识别文本中的命名性指称以及实体候选集。这样做的问题是,如果维基百科中并不存在正确的实体与命名性指称的匹配,那么在给定文本中该命名性指称也永远不会得到正确的标注。例如命名性指称“Justin”在维基百科中仅仅被标记为实体Justin Bieber,则对于输入文本中出现的命名性指称“Justin”,将永远不会被标记为其他实体,即便正确的结果希望将该命名性指称标记到实体Justin Timberlake。
通过人工构建这些命名性指称和实体之间的对应关系作为候选集,可以直接对命名性指称模型和候选集模型进行扩展。基于拉普拉斯平滑[12]的思想,对于这些新的实体与命名性指称对应关系,如果它并没有在训练集中出现过,不是认为它不可能作为标注出现,而是给予它一个最低的概率,即认为它的被标记次数为1次。对于模型中未出现的命名性指称,需要设定一个初始的被标记概率,本文选择使用命名性指称和实体的联合被标记概率(式(1))来对新命名性指称的被标记概率(式(2))进行估计。

其中,count(NIL,s)代表命名性指称s并未被标记的次数;S(e)是实体e所有已知的命名性指称集合。
3.2 基于点互信息率的特征选择
特征选择能够通过减少有效的词汇空间来提高分类器训练和应用的效率,同时也能够去除噪音特征,从而提高分类的精度。对于命名实体识别任务来说,候选集消歧的问题也可以抽象成为一个分类问题,因此合理地使用特征选择能够改善命名实体识别问题。
在候选集消歧的过程中能够利用的最重要特征是每个实体周围的上下文。所有命名实体识别系统都需要离线的处理过程,目的是将维基百科中出现在实体周围的单词过滤掉停用词后作为实体的上下文。这些上下文中的单词有很多和实体的出现只是偶然的关系,换句话说,这些单词对于实体而言和停用词的作用是近似的。通过将这些相对实体的类停用词过滤掉,不仅可以减小实体上下文模型的占用空间,提高系统的性能;同时可以有效地避免这些类停用词给消歧带来的噪音,优化系统的标注效果。
信息论中,点互信息量[13](pointw isemutual information,PM I)能够有效地度量两个事件同时发生的关联程度。Islam等人[14-15]使用点互信息量来计算两个单词或文本之间的相似性。因此,结合DBpedia Spotlight的命名实体识别过程,本文定义一个实体e与该实体上下文中的某个单词t之间的点互信息量为:

其中,N为训练集中单词的总数;count(e,t)代表实体e和单词t在维基百科中同一个上下文环境下出现的次数;count(e)和count(t)分别表示实体e和单词t在维基百科中出现的总次数。通过上式可以计算得到单词t和实体e之间的点互信息量,从而衡量两者的关联程度。两者之间的点互信息量值越大,说明这个单词的出现和实体的出现之间的关联性越大,反之,说明这个单词的出现和实体的出现接近于偶然,两者的联系比较小,可以把单词作为停用词处理。
对于点互信息量朴素的使用方法是将所有与实体之间的点互信息量低于一定阈值的单词从其上下文模型中剔除掉,避免这些单词在消歧时带来的噪音。然而实际证明这样的策略并不是最优的,原因是模型中每个实体所具有的信息量各不相同,与其上下文中的单词之间点互信息量能够达到的最大值也各不相同,因此将所有实体的上下文单词使用相同的阈值进行过滤是不合理的。通过考虑以上因素,本文提出了点互信息率的概念(式(4)),即单词t和实体e之间的点互信息量与实体e所具有的信息量的比值。

其中,H(e)是实体e具有的信息量,通过式(5)计算。

3.3 基于主题向量的二次消岐
通常一段文本都具有一个主题,文本内部的实体之间具有紧密的联系,Medelyan[4]和Ferragina[16]等人都将主题一致性作为候选集消歧的主要依据,可以一定程度上提高命名实体识别的性能。而部分命名实体识别系统从截然不同的思路入手来解决候选集消歧问题,缺少一些高效的手段将主题一致性整合到消歧过程中。
3.3.1 主题向量的构造
基于维基百科文章的M ilne-Witten语义关联度[17]被广泛应用在命名实体识别领域。M ilne-Witten语义关联度借鉴了谷歌距离,充分考虑了维基百科文章之间的超链接构成的图结构,而不是使用分类的层次结构和文本内容。给定一篇文章,计算任意实体与文章的主题一致性需要分别计算该实体与其他所有文章中实体的M ilne-Witten语义关联度并求和,对于较长文章或实体出现密集的文章具有较低的效率。通过借鉴M ilne-Witten语义关联度的方法,本节提出了使用实体所出现的维基百科文章集合来表示实体主题和文章主题的方法。
令W={w1,w2,…,wM}为维基百科中所有文章的集合。给出一个实体e,通过统计所有包含它的维基百科中的文章,可以得到该实体主题的01向量表示。

其中,维基百科中的每篇文章对应topic(e)向量中的一位,由该实体是否在该文章中出现决定该位是0还是1。
同样,给出一个文章D,可以通过对文章中出现的所有实体主题向量求和得到文章对应的主题向量。

3.3.2 基于主题向量的二次消岐
对于任意一个命名实体识别系统,最终候选集消歧的结果是对每个命名性指称给予唯一的实体匹配。如果一个候选集中的两个实体消歧的得分比较接近,那么直接选择得分更高的实体很容易出现错误。利用上节提到的主题向量,可以对这部分容易发生错误的标注结果进行二次消歧。
给定一篇文章和候选集实体,利用上节的方法构造文章的主题向量和每个实体的主题向量。对于每个实体,计算其主题向量和文章主题向量的余弦相似度作为两者的主题相似度,并选择主题相似度最高的实体作为最终标注的实体。
为了得到文章的主题向量,需要获得文章中出现的所有实体。然而要想得到文章中出现的所有实体,又需要首先获得文章的标注结果,这就使得两者出现了循环依赖的关系。对于这个问题,本文采取的解决办法是利用一次消歧结果来近似得到文章中出现的实体。
本文认为在一次消歧后满足以下两个条件的候选实体可以作为正确的标注结果,不参与二次消歧,并利用这些实体构建文章的近似主题向量。
(1)该实体在候选集中拥有最高的消歧得分,且不低于一定阈值(取决于具体的系统)。
(2)候选集中没有其他实体的支持度(即维基百科中的出现次数)大于该实体。
在得到文章的主题向量之后,通过计算剩下的候选实体和文章主题之间的主题相似度,将主题相似度最高的实体作为最终的消歧结果。
4 基于DBpedia Spotlight的优化方案实现
本文用于实验的命名实体识别系统是DBpedia Spotlight基于统计的版本[18],也是目前使用最广泛的开源命名实体识别系统之一。本章主要对系统原理进行简单介绍,并阐述优化方案的实现。
4.1 开源系统DBpediaSpotlight
DBpedia Spotlight可以识别文本中的命名性指称,并与DBpedia知识库中的对应实体关联起来,从而丰富文本的信息。系统所需要的统计模型包括实体、命名性指称、候选集、单词和上下文五部分,是通过对维基百科的dump解析得到的,并序列化到硬盘。维基百科文章中包含了大量超链接形式的高质量人工标注,其中链接指向的文章就是标注的实体,链接处的文本是实体在文本中的命名性指称,链接处周围的文本则作为实体出现的上下文。
DBpedia Spotlight的命名实体识别过程也包括命名性指称识别、候选集生成和候选集消歧3个步骤。
(1)命名性指称识别
DBpedia Spotlight通过利用维基百科中出现的所有命名性指称,构建有限自动机字典,然后使用有限自动机算法识别出文本中所有可能出现的命名性指称。系统还会计算出维基百科中每个命名性指称s的被标记概率 P(annotation|s)(式(9)),来刻画一个命名性指称的重要程度,用于在线标注处理时对命名性指称的选择,从而将低于一定阈值的命名性指称舍弃。
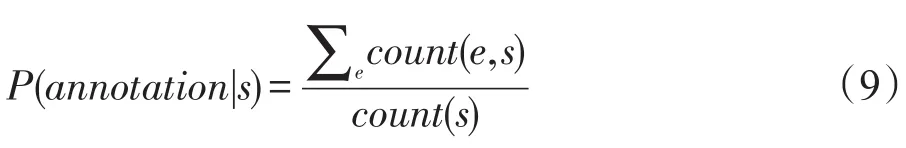
(2)候选集生成
利用候选集模型中保存的统计信息,系统对于识别出的每个命名性指称,构造该命名性指称可能对应的实体集合作为候选集。
(3)候选集消歧
DBpedia Spotlight系统的消歧过程基于生成概率模型[19]。对于给定的标记m(命名性指称是s,上下文是c),它被标记为实体e的概率为:

式中,P(e)、P(s|e)、P(c|e)分别对应实体 e出现的概率、实体e出现时命名性指称为s的概率、实体e出现时上下文为c的概率,在维基百科数据集上使用极大似然估计得到(式(11))。PLM(t)是在训练集中所有单词上估计得到的用于平滑的一元语言生成语言模型。

对于候选集中的每个实体,系统计算得到了命名性指称被标记为该实体的概率,对该概率进行标准化,从而得到一个介于0到1.0之间的消歧得分。最终系统将实体按照消歧得分进行排序,并且将得分最高的实体作为最终标记结果。对于当前上下文,系统还将生成一个NIL实体,用来表示命名性指称不属于任何一个候选实体时的标记结果。通过计算得到NIL实体的消歧得分(式(12)),所有低于该NIL实体得分的结果将被移除。
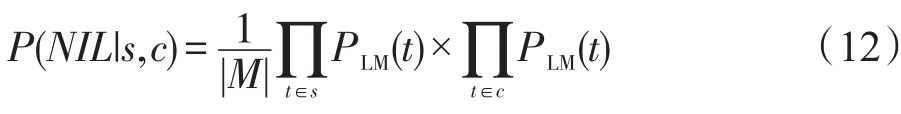
4.2 基于候选集的增量扩展实现
DBpedia Spotlight系统的统计模型是离线过程中序列化到硬盘的,基于候选集的增量扩展需要对其命名性指称模型、候选集模型进行处理。因此,最终利用候选集扩展DBpedia Spotlight模型的步骤如下所示。
步骤1将DBpedia Spotlight的统计模型反序列化导入内存。
步骤2对于输入候选集中每一对实体和命名性指称的匹配关系(e,s),如果e在实体模型中不存在,则跳过这条关系,否则获得e对应的e_id。
步骤3如果s在命名性指称模型中不存在,则使用式(2)估计被标记概率,并将s加入系统原有的命名性指称模型中,设置初始标记次数为1。
步骤4从扩展后的命名性指称模型中获得s对应的s_id,并使用(s_id,e_id)对候选集模型进行扩展,并将出现次数设为1。
步骤5将扩展后的统计模型重新序列化到硬盘。
人工构建这样的高质量候选集是很困难的,需要大量繁琐的工作。因此,为了验证使用候选集对系统模型进行扩展的方法,本节选择通过使用规则生成一些相对质量较低的匹配关系来近似地评价。本文通过选择3个基本的规则(表1),生成了一系列实体与命名性指称的对应关系,从而扩展已有的候选集来验证候选集扩展方法。

Table1 Generative rulesof named references表1 命名性指称的生成规则
4.3 基于点互信息率的特征选择实现
对于DBpedia Spotlight系统来说,候选集消歧过程所使用到的上下文信息保存在上下文模型中,包括训练集中出现在每个实体周围的单词以及对应的出现次数。通过实验调优选择一定阈值,对系统上下文模型进行遍历。对每个实体的上下文中单词,使用离线处理得到的维基百科统计信息计算两者之间的点互信息率,从而将低于阈值的单词过滤掉,完成对上下文模型的特征选择,步骤如下。
步骤1将系统上下文模型反序列化到内存,并对其进行遍历。
步骤2对于每个实体e对应的上下文单词集合中的单词token,从维基百科的统计信息中获得e的出现次数、token的出现次数以及维基百科单词的总数。
步骤3使用式(10)计算得到e和token之间的点互信息率pmi_rate。
步骤4如果pmi_rate小于预先设定的阈值,则将token从e的上下文空间中移除。
步骤5重新将特征选择后的上下文模型序列化到硬盘。
为了验证对于上下文模型使用点互信息率进行特征选择的效果,本文同样实现了利用互信息以及χ2统计量两个主流的特征,并将特征选择之后的模型在多个测试数据集上进行标注,证明了点互信息率要优于以上两种方法。
4.4 基于主题向量的二次消岐实现
DBpedia Spotlight的消歧过程中,仅仅利用一元语言模型计算候选集中每个实体的生成概率,并将生成概率最高的实体作为标注结果,这其中并没有考虑到实体与实体之间的语义关联度,或者说实体和整个文本主题之间的关联度。
原有的DBpedia Spotlight系统消歧之后得到的是文章中所有可能的命名性指称以及对应的所有候选实体集。候选实体集中的每个实体都计算得到了一个消歧得分,最后得分最高的实体将会被保留并作为最终的标注结果,即便最高的得分可能非常低。因此,本文对第一次消歧得到的错误可能性较高的命名性指称进行基于主题向量的二次消歧,从而提高标注的准确率。
本文在DBpedia Spotlight上实现的二次消歧算法表述如下所示。
算法基于主题向量的二次消歧
输入:一次消歧结果TmpResult,维基百科链接数据Links
输出:二次消歧结果FinalResult
1.initFinalResult={};//定义FinalResult为保存最终消歧结果的集合
2.for(sf,entities)←TmpResultdo
3.(top_entity,top_score)=getTop(entities);
4.iftop_score>0.9 then
5.top_support=getSupport(top_entity);//得到消歧得分最高实体的支持度
6.for(entity,score)←entitiesdo
7. if getSupport(entity)>top_supportthen
8. Break;
9. end if
10.add calculateTopic(top_entity)totextTopic;//计算文章的主题向量textTopic
11.add(sf,top_entity)toFinalResult,remove(sf,entities)inTmpResult;
12.end for
13.end if
14.end for
15.for(sf,entities)←TmpResultdo
16.(top_entity,top_score)=getTop(entities);
17.topSim=calculateSim(calculateTopic(top_entity),textTopic);//计算实体和文章之间的主题相似度topSim
18.for(entity,score)←entitiesdo
19.entitySim←calculateSim(calculateTopic(entity),textTopic);
20.ifentitySim>topSimthen
21.topSim=entitySim;
22.top_entity=entity;
23.end if
24.end for
//得到候选集中与文章主题相似度最高的实体
25.add(sf,top_entity)toFinalResult;
26.end for
其中维基百科链接数据(Links)中保存着每一个DBpedia实体所出现的维基百科文章的集合,是通过对维基百科文章数据离线处理解析得到的。由于算法只需要对一次消歧的结果进行线性遍历,显然其时间复杂度是O(N),其中N是文章中识别出所有候选集实体的数目。
5 实验
下面通过实验方法评价本文命名实体识别优化方案,全部实验在Intel®Xeon®CPU E5620@2.40GHz的PC机上运行,内存为64 GB,并配置4 TB硬盘。5.1节介绍实验使用的测试框架、数据集以及评测标准;5.2节给出本文方案的实验结果以及与包括DBpedia Spotlight在内的多个开源命名实体识别系统的对比和分析。
5.1 测试框架、数据集与评测标准
目前已知的标准测试平台BAT-Framework[20]是由Cornolti等人在2013年提出的,它可以公平地针对一个命名实体识别系统进行评估。该框架基于一系列命名实体识别的任务,提出了一套包括上文介绍的所有参数在内的用于评估命名实体识别系统性能的方法,并且容易进行配置来全面地评测一个系统的性能。另外,系统覆盖了多个公开的测试数据集,并且可以很容易地使用新的测试数据集、命名实体识别系统以及评测方法进行扩展。
在本文的实验中,使用了最常用的弱匹配方法对系统的性能进行评估,即只需要两个命名性指称之间有交集并且两个实体在重定向后具有一致性就认为是正确的匹配。本文主要使用的评价指标包括准确率(precision)、召回率(recall)以及F值(F-measure)。

其中,tp(true positive),即系统标注结果中正确的数目;fp(false positive),即系统标注结果中错误的数目;fn(false negative),即标准标注结果中没有被系统标注出来的数目。
为了实验的公平性,本文所有实验中的参数在未提及的情况下都使用默认值。同时,本文选取两个具有代表性的数据集AIDA/CoNLL和MSNBC作为实验的测试数据集,每个数据集的介绍如表2所示。

Table 2 Benchmark datasetsused in experiments表2 实验使用的标准测试数据集
5.2 Ontology层结果分析
本节主要围绕本文三方面的优化在3个测试数据集上进行综合全面的实验。5.2.1节主要介绍使用候选集扩展方法相关的实验结果和分析。5.2.2节主要介绍基于点互信息率的特征选择相关的实验结果和分析。5.2.3节主要介绍基于主题向量的二次消歧相关的实验结果和分析。最后将对三方面优化整合后的系统进行实验和分析,并与多个开源的命名实体识别系统进行比较。
5.2.1 模型扩展框架
本文通过第3章总结的3个简单的规则,利用DBpedia知识库中的5 235 952个实体生成了541 607个实体-命名性指称的匹配。将生成的匹配关系利用候选集扩展的方法融入到原有系统的统计模型中,用DBpedia Spotlight-α来指代扩展模型后的系统。
为了验证DBpediaSpotlight-α的性能,本文在AIDA/CoNLL和MSNBC数据集上分别运行了原系统和DBpedia Spotlight-α,得到的实验结果如表3所示。
从实验结果可以看出,通过利用规则产生候选集,并将这个集合融入到原有的候选集中,可以一定程度增加在测试数据集上识别正确实体的数目,从而提高系统的召回率。同时,由于增加了大量的质量不高的实体命名性指称对应关系,也会增加许多标注错误的情况,从而导致识别的准确率有所下降。DBpedia Spotlight-α所增加的标注正确的数目要远小于候选集中新增的匹配关系数目,是因为使用规则产生的关系,如果在训练集中没有出现,通常实际应用时出现的情况也比较少。因此,如果使用一些人工或机器的手段,获取大量实体与命名性指称高质量的对应关系集合,利用本节的方法融入到字典中,将可以得到更好的结果。另外,尽管系统增加了一些标记错误的结果,但是本文提到的二次消歧方法可以有效地增加准确率,减少标记错误的情况,两者的结合可以得到更好的结果。
5.2.2 基于点互信息率的特征选择
本小节主要介绍基于点互信息率的特征选择方面的实验,其中包括对用于过滤的阈值参数的选择调优。本小节的系统用DBpedia Spotlight-β指代。
为了找到一个最优的用于过滤的阈值参数,本文将阈值从0开始逐步提高,同时观察特征选择后的上下文模型空间的变化,以及系统在测试数据集上的标注性能变化。图1和图2、图3分别对应随着阈值参数的变化,上下文模型的空间占用的变化以及系统在两个测试数据集上的标注结果的变化。
通过观察图1可以发现,系统上下文模型中平均每个实体对应的单词数目随着阈值的提高下降得非常迅速,在阈值设为0.4的时候已经达到了原有模型大小的1/4,这说明了绝大部分的单词与实体同时出现都是具有偶然性的。而从图2和图3中可以看出,尽管模型空间随着阈值的提高成倍地下降,但是系统的消歧效果并没有受到太大的影响。在最初阈值从0提高到0.3的过程中,系统在两个测试数据集上的F值和原系统相比略微下降,从0.3开始系统的标注结果反而开始得到提高,直到阈值为0.4到0.5之间时达到顶峰,其性能也超过了原系统。最后从0.5再继续提高阈值,系统的标注效果又开始逐渐下降。

Table3 Experimental results1表3 实验结果1

Fig.1 Threshold parameter and contextmodelspace图1 阈值参数与上下文模型空间
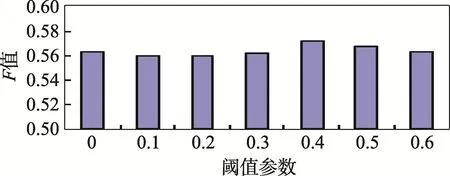
Fig.2 Threshold parameterandF-measureon AIDA/CoNLL dataset图2 阈值参数在测试数据集AIDA/CoNLL上的F值

Fig.3 Threshold parameterandF-measureon MSNBC dataset图3 阈值参数在测试数据集MSNBC上的F值
因此,最终本文采用能够在两个测试数据集上得到较好结果的阈值0.45,此时原有的上下文模型空间从平均每个实体具有66个上下文单词减少到了只有17个上下文单词。表4是将阈值参数设置为0.45时得到的上下文模型整合到系统后,在AIDA/CoNLL和MSNBC数据集上的实验结果。
通过实验结果可以发现,新的模型在大大削减了空间的情况下,并没有影响到标注的性能,而且可以在准确率和召回率上都有略微的提升。
5.2.3 基于主题向量的二次消岐
本小节主要介绍基于主题向量的二次消歧相关的实验。将融入二次消歧算法的系统用DBpedia Spotlight-θ指代,表5是DBpedia Spotlight-θ在两个测试数据集AIDA/CoNLL和MSNBC上的实验结果。
从实验结果中可以看出,通过对原有系统中标注错误可能性较大的命名性指称进行二次消歧,可以有效地降低系统中标注错误实体的数量,从而提高标注的准确率和F值。

Table 4 Experimental results2表4 实验结果2

Table5 Experimental results3表5 实验结果3

Table6 Experimental results4表6 实验结果4
5.2.4 整合后系统
本小节将上述的三部分整合到了一起,整合后的系统用DBpedia Spotlight*指代。通过在测试数据集AIDA/CoNLL和MSNBC上运行实验,得到的实验结果如表6所示。
从实验结果可以看出,通过将三方面工作结合到一起,DBpedia Spotlight*能够得到比每个单一部分更好的标注效果。这说明三方面工作对于系统而言都有着自己独立的优点,将三方面结合起来可以让系统更加完善。另外,对比表6可以看出,在数据集MSNBC上的结果要比数据集AIDA/CoNLL上提升得更加明显,主要是因为数据集MSNBC的特点是只有非常重要的实体才会被标记,所以标注结果集中的实体之间的联系也更加紧密,文本内部的主题一致性更加突出,更适用于本文提出的二次消歧算法。而AIDA/CoNLL数据集会过多地标注一些不重要的实体,为主题向量的构建带来了噪音。
5.2.5 与其他开源系统的比较
本文还与其他4个广泛使用的命名实体识别系统进行了比较,包括AIDA、IllinoisWikifier、TagMe2以及WikipediaM iner。同时,为了与其他系统公平地比较性能,本文将DBpedia Spotlight的一些参数通过调整,取能够使得标注结果达到最优的值。表7是DBpedia Spotlight*在两个测试数据集AIDA/CoNLL和MSNBC上的运行结果同包括原系统在内的5个开源系统的比较。
通过与其他著名的开源系统在AIDA/CoNLL数据集和MSNBC数据集上进行对比的结果可以看出,DBpedia Spotlight系统本身已经能够具有目前接近最好的标注性能,而本文提出的优化框架可以进一步提高原系统的性能,从而超过了其他开源的命名实体识别系统。

Table7 Resultsof comparison experimentsbetween DBpedia Spotlight*and open-source systems表7 DBpedia Spotlight*与开源系统对比实验结果
需要指出的是,在5.2.4小节中实验对比DBpedia Spotlight*与DBpedia Spotlight原系统时,使用的阈值参数为0.4,也是DBpedia Spotlight默认的参数。而本小节的实验是DBpedia Spotlight*和其他几个开源系统之间的对比,鉴于每个系统都有各自的配置参数,用来调节标注的准确率和召回率,为了公平起见,将每个系统都取其能够达到最好标注效果(也就是F值最大)的参数,因此表7中DBpedia Spotlight*的实验数据与表6中的数据不同。
6 总结
由于知识库中实体在文本中存在形式的多样性,提高命名实体识别的综合性能一直是一个挑战性问题。本文通过对现有的命名实体识别方法进行研究与分析,提出了一套通用的命名实体识别优化框架。通过设计并实现使用候选集对系统模型进行扩展的方法,降低了对训练集的依赖,增加了灵活性;同时,提出了点互信息率的概念,通过使用点互信息率对上下文模型进行特征选择,将上下文空间降低为原有的1/4,并且能够提高标注的准确率和召回率。本文还提出了利用主题向量代替M ilne-W itten语义关联度对错误可能性较高的标注结果进行二次消歧,提高了标注的准确率。通过在目前广泛使用的开源命名实体识别系统DBpedia Spotlight中实现所提优化方案,并在两个标准的测试集上设计完善的实验方案,验证了本文优化方案与已有系统相比具有较优的性能指标。
[1]Bizer C,Lehmann J,Kobilarov G,et al.DBpedia—a crystallization point for theWeb of data[J].Web Semantics:Science,Services and Agents on theWorld WideWeb,2009,7(3):154-165.
[2]Hoffart J,Suchanek FM,Berberich K,et al.YAGO2:exploring and querying world know ledge in time,space,context,andmany languages[C]//Proceedings of the 20th International Conference onWorld WideWeb,Hyderabad,India,Mar28-Apr1,2011.New York:ACM,2011:229-232.
[3]Cucerzan S.Large-scale named entity disambiguation based on Wikipedia data[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,Prague,Czech Republic,Jun 28-30,2007.Stroudsburg,USA:ACL,2011:708-716.
[4]Medelyan O,W itten IH,M ilne D.Topic indexing w ith Wikipedia[C]//Proceedingsof the 2008AAAIWorkshop on Wikipedia and Artificial Intelligence:An Evolving Synergy,Chicago,USA,Jul 13-14,2008.Palo A lto,USA:AAAI,2008:19-24.
[5]M ilne D,Witten IH.Learning to link w ith Wikipedia[C]//Proceedings of the 17th ACM Conference on Information and Know ledge Management,Napa Valley,USA,Oct 26-30,2008.New York:ACM,2008:509-518.
[6]Olieman A,Azarbonyad H,DehghaniM,etal.Entity linking by focusing DBpedia candidate entities[C]//Proceedings of the 1st International Workshop on Entity Recognition and Disambiguation,Gold Coast,Australia,Jul 11,2014.New York:ACM,2014:13-24.
[7]Lipczak M,KoushkestaniA,M ilios E.Tulip:lightweight entity recognition and disambiguation using Wikipediabased topic centroids[C]//Proceedings of the 1st International Workshop on Entity Recognition and Disambiguation,Gold Coast,Australia,Jul11,2014.New York:ACM,2014:31-36.
[8]Kulkarni S,Singh A,Ramakrishnan G,etal.Collective annotation of Wikipedia entities in Web text[C]//Proceedings of the 15th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining,Paris,Jun 28-Jul 1,2009.New York:ACM,2009:457-466.
[9]Han Xianpei,Sun Le,Zhao Jun.Collective entity linking in Web text:a graph-based method[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,Beijing,Jul 24-28,2011.New York:ACM,2011:765-774.
[10]Hoffart J,Yosef M A,Bordino I,et al.Robust disambiguation of named entities in text[C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing,Edinburgh,UK,Jul 27-31,2011.Stroudsburg,USA:ACL,2011:782-792.
[11]Usbeck R,Ngomo A C N,Röder M,etal.AGDISTIS—agnostic disambiguation of named entities using linked open data[C]//Proceedings of the 21st European Conference on Artificial Intelligence,Prague,Czech Republic,Aug 18-22,2014.Amsterdam:IOSPress,2014:1113-1114.
[12]Chen S F,Goodman J.An empirical study of smoothing techniques for language modeling[C]//Proceedings of the 34th Annual Meeting on Association for Computational Linguistics,Santa Cruz,USA,Jun 24-27,1996.Stroudsburg,USA:ACL,1996:310-318.
[13]Church KW,Hanks P.Word association norms,mutual information,and lexicography[J].Computational Linguistics,1990,16(1):22-29.
[14]Islam A,Inkpen D.Second order co-occurrence PM I for determ ining the semantic sim ilarity of words[C]//Proceedings of the 5th International Conference on Language Resources and Evaluation,Genoa,Italy,May 24-26,2006.Paris:ELRA,2006:1033-1038.
[15]Islam A,Inkpen D.Semantic similarity of short texts[J].Re-cent Advances in Natural Language Processing,2009,309:227-236.
[16]Ferragina P,Scaiella U.TagMe:on-the-fly annotation of short text fragments(by w ikipedia entities)[C]//Proceedings of the 19th ACM International Conference on Information and Know ledge Management,Toronto,Canada,Oct 26-30,2010.New York:ACM,2010:1625-1628.
[17]Witten I,M ilne D.An effective,low-costmeasureof semantic relatedness obtained from Wikipedia links[C]//Proceedings of the 2008 AAAIWorkshop on Wikipedia and Artificial Intelligence:An Evolving Synergy,Chicago,USA,Jul 13-14,2008.Palo Alto,USA:AAAI,2008:25-30.
[18]Han Xianpei,Sun Le.A generative entity-mention model for linking entitiesw ith know ledge base[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technolgies,Portland,USA,Jun 19-24,2011.Stroudsburg,USA:ACL,2011:945-954.
[19]Daiber J,Jakob M,Hokamp C,et al.Improving efficiency and accuracy in multilingual entity extraction[C]//Proceedings of the 9th International Conference on Semantic Systems,Graz,Austria,Sep 4-6,2013.New York:ACM,2013:121-124.
[20]Cornolti M,Ferragina P,Ciaram ita M.A framework for benchmarking entity-annotation systems[C]//Proceedings of the 22nd International Conference on World Wide Web,Rio de Janeiro,Brazil,May 13-17,2013.New York:ACM,2013:249-260.

FU Yuxinwasborn in 1991.He isan M.S.candidate at Tianjin University.His research interests include named entity recognition and keyword search.
付宇新(1991—),男,吉林通化人,天津大学硕士研究生,主要研究领域为命名实体识别,关键字搜索。

王鑫(1981—),男,天津人,2009年于南开大学获得博士学位,现为天津大学副教授,CCF高级会员,主要研究领域为语义数据管理,图数据库,大规模知识处理。

FENG Zhiyong was born in 1965.He received the Ph.D.degree from Tianjin University in 1996.Now he isa professor and Ph.D.supervisor at Tianjin University,and the seniormember of CCF.His research interests include know ledge engineering,services computing and security software engineering.
冯志勇(1965—),男,内蒙古呼和浩特人,1996年于天津大学获得博士学位,现为天津大学教授、博士生导师,CCF高级会员,主要研究领域为知识工程,服务计算,安全软件工程。

XU Qiangwasborn in 1993.She isan M.S.candidate at Tianjin University.Her research interests include semantic Web and graph databases.
徐强(1993—),女,山西临汾人,天津大学硕士研究生,主要研究领域为语义网,图数据库。
Named Entity Recognition Optim ization on DBpedia Spotlight*
FU Yuxin1,2,WANG Xin1,2+,FENG Zhiyong2,3,XUQiang1,2
1.Schoolof Computer Science and Technology,Tianjin University,Tianjin 300354,China
2.Tianjin Key Laboratory of Cognitive Computing and Application,Tianjin 300354,China
3.Schoolof Computer Software,Tianjin University,Tianjin 300354,China
The task of named entity recognition can bridge the gap between know ledge bases and nature languages,and support the research work in keyword extraction,machine translation,topic detection and tracking,etc.Based on the analysisof current research in the field of named entity recognition,this paper proposesa general-purpose optimization scheme for named entity recognition.Firstly,this paper designs and implements an incremental extending method,by using a candidate set,which can reduce the dependency on the training set.Secondly,by leveraging the conceptof pointw isemutual information ratio,thispapereffectivelymakes feature selection on the contextsof entities,whichmay reduce the contextspace significantly andmeanwhile improve the performance of annotation results.Finally,this paper presents the secondary disambiguationmethod based on topic vectors,which can further enhance the precision of annotation.This paper conductsextensive comparison experiments on thew idely-used open-source named entity recognition system DBpedia Spotlight.Ithas been verified that the proposed optim ization scheme out-performs the state-of-the-artmethods.
named entity recognition;linked data;DBpedia Spotlight
was born in 1981.He
the Ph.D.degree from NankaiUniversity in 2009.Now he isan associate professor at Tianjin University,and the seniormember of CCF.His research interests include semantic data management,graph databasesand large-scale know ledge processing.
A
:TP391
*The National Natural Science Foundation of China under GrantNos.61572353,61373035(国家自然科学基金);the National High Technology Research and DevelopmentProgram of China underGrantNo.2013AA013204(国家高技术研究发展计划(863计划)).
Received 2016-06,Accepted 2016-08.
CNKI网络优先出版:2016-08-15,http://www.cnki.net/kcms/detail/11.5602.TP.20160815.1659.004.htm l
猜你喜欢
英语世界(2023年10期)2023-11-17 09:18:46
计算机与数字工程(2021年12期)2022-01-15 06:24:02
英语文摘(2021年8期)2021-11-02 07:17:46
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
东方女性(2018年3期)2018-04-16 15:30:02
电脑与电信(2018年12期)2018-03-23 02:37:20
散文诗(2017年17期)2018-01-31 02:34:08
读者·原创版(2015年11期)2015-03-01 06:15:34
意林(2014年2期)2014-02-11 11:09:17
