
用户兴趣相似性度量的关系预测算法*
2017-07-31 20:56:07黄宏程陆卫金
计算机与生活 2017年7期
黄宏程,陆卫金,胡 敏,魏 青
1.重庆邮电大学 通信与信息工程学院,重庆 400065
2.重庆大学 计算机学院,重庆 400044
用户兴趣相似性度量的关系预测算法*
黄宏程1,2+,陆卫金1,胡 敏1,魏 青1
1.重庆邮电大学 通信与信息工程学院,重庆 400065
2.重庆大学 计算机学院,重庆 400044
+Corresponding autho author:r:E-mail:huanghc@cqupt.edu.cn
HUANG Hongcheng,LUWeijin,HUM in,et al.User relationships prediction algorithm w ith interest sim ilarity measurement.Journalof Frontiersof Com puter Science and Technology,2017,11(7):1068-1079.
用户兴趣;相似性;多阶量化;关系预测
1 引言
近年来,微博以发布内容简短,关注机制灵活,推送消息及时的特点赢得用户的青睐,取得了快速发展。以新浪微博为例,系统按照用户标签、微博文本、关注用户列表等信息推送消息。充分利用这些基本信息,挖掘用户的兴趣偏好,建立用户兴趣模型,用于准确预测用户间关系,对于改善用户体验,增加网络粘性和精准广告营销大有裨益。因此,基于微博用户兴趣预测用户关系已成为当前互联网数据挖掘的研究热点。
目前对微博用户兴趣的研究大部分是基于用户的注册信息、标签[1]、微博内容、地理位置[2]和社交圈[3]等进行个性化的推荐[4],使用户有选择地添加自己“感兴趣”的好友。张珊靓等人[5]认为用户的好友推荐和时间相关,因此将时间作为一个重要参数引入到随机游走算法中,按照Top N准则将用户作为好友关系推荐给其他用户。吴成超等人[6]利用高斯概率隐语意模型挖掘长期兴趣,通过评分时间窗获取短期兴趣,结合长短期兴趣建立用户兴趣模型。孙静宇等人[7]在基于用户评分的协同过滤算法中,结合用户的长短期兴趣的时间加权方法,重点分析了用户长短期兴趣的识别问题,能够更好地描述用户兴趣的变化。孙威[8]认为在线社交网络的用户关系是稳定的,将微博名人的兴趣作为长期兴趣,将普通用户转发和评论的内容作为短期兴趣,并用遗忘曲线衡量短期兴趣。郭进利[9]通过研究人类的行为动力学,认为用户的兴趣随时间增加而逐步衰减,由此构建了相应的衰减函数。
上述这些研究充分考虑了用户“兴趣漂移”的规律,但是忽略了部分兴趣用户会长期保持的问题,使得建立的兴趣模型难以客观地描述用户兴趣的变化过程,导致推送的消息有效性不高。本文针对该问题提出了基于用户兴趣相似性的关系预测算法。将用户的标签信息表征长期兴趣,微博文本信息表征短期兴趣[10],用户的长期兴趣可以通过关注列表推荐(即被关注用户拥有的标签)和短期兴趣反馈(即用户自己的微博文本信息)来修正;通过用户兴趣状态的转换,更新用户兴趣;按照长短期兴趣的分类,采用频率统计和多阶量化的方法度量用户兴趣度。根据社会学理论[11]:用户间越相似,越可能成为好友的原则,本文通过余弦相似性度量用户间的兴趣相似度,相似度越高,则用户成为朋友的可能性越高。
本文组织结构如下:第2章提出用户兴趣模型,详细阐述用户兴趣的修正、更新以及兴趣度的度量,根据兴趣度计算用户相似性;第3章以新浪微博真实数据作为数据集,通过实验分析了本文提出的基于长短期兴趣进行用户关系预测的算法的有效性;第4章总结本文工作。
2 用户兴趣建模
为了提高用户关系预测的精度,同时兼顾到用户“兴趣漂移”和部分兴趣持久保持的客观规律,将用户兴趣分为长、短期兴趣[6,12]。其中长期兴趣通过关注列表获得,短期兴趣根据用户自身的微博文本信息提取。用户兴趣模型如图1所示。
本文分析微博的用户原始数据,提取用户兴趣所需的标签信息、关注列表和微博文本信息。对文本分词后,提取关键词,参照腾讯、网易、搜狐和新浪微博等,将用户兴趣分为(美食,教育,娱乐,体育,时尚,财经,科技、文化,军事,读书,汽车,音乐,游戏,星座,影视,购物,摄影,宠物,新闻,搞笑,生活)等21类;根据这21个兴趣类提取每个兴趣类所对应的关键词,每个兴趣类会对应多个关键词(特征项)。

Fig.1 User interestmodel图1 用户兴趣模型
经数据处理后形成的用户兴趣向量为(美食,教育,娱乐,…,搞笑,生活),每个兴趣类对应的特征项代表用户的标签和微博文本信息。对于用户i来说,其兴趣可用图2所示。
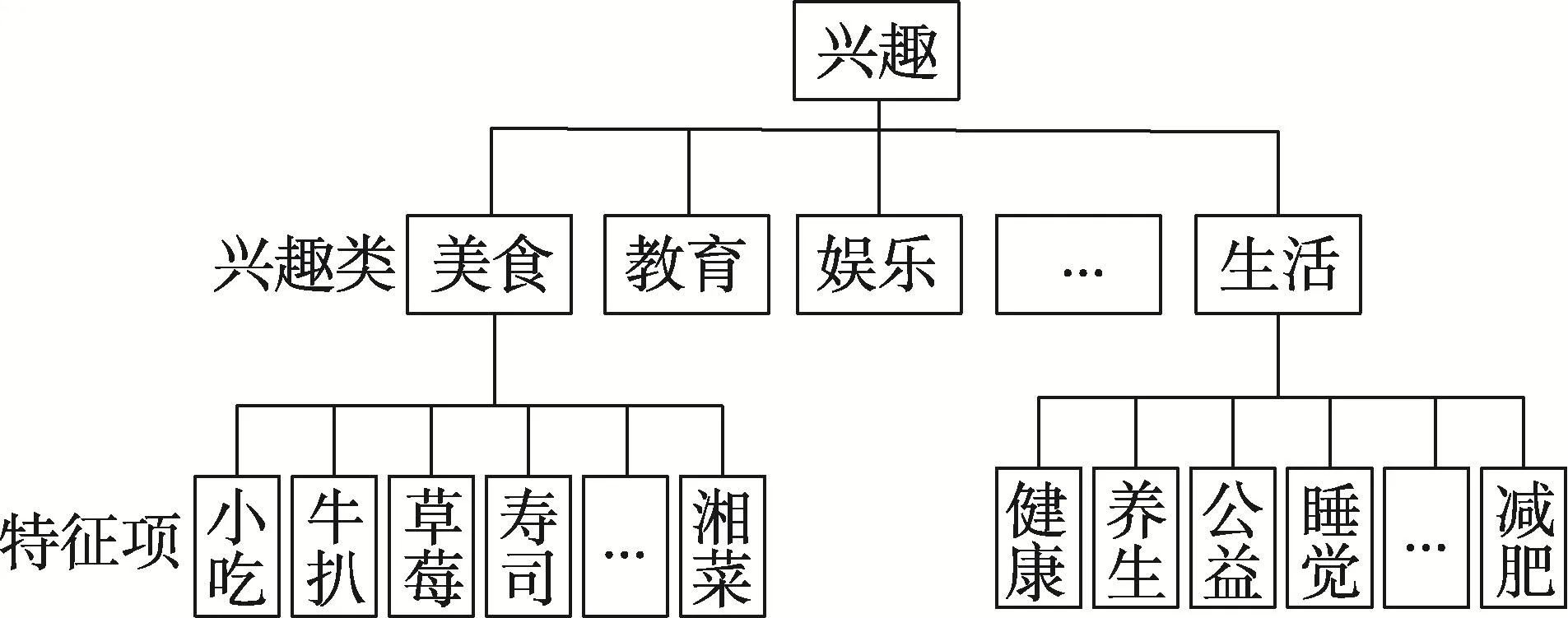
Fig.2 Structureof interest-characteristics图2 兴趣类-特征项结构图
用户i的兴趣向量可以描述为:

式中,ILi是用户i的长期兴趣向量;ISi是用户i的短期兴趣向量。由于用户i的微博文本信息中包含多个特征项,则ILi和ISi用如下向量表示:

其中,wLi是用户i的长期兴趣度向量;wSi是用户i的短期兴趣度向量。
此时用户兴趣向量和兴趣度向量分别为:

由上文分析可知,用户的短期兴趣由微博文本信息中的兴趣类对应的特征项表征,长期兴趣通过用户标签信息来表征。本文将依次介绍用户长期兴趣的修正、更新过程,用户兴趣的度量方法和用户间的相似性计算。
2.1 用户长期兴趣的修正
微博数据包含每个用户的关注列表和标签信息,用户在注册时所填写的用户标签可以是平台推荐的标准标签,如星座、运动等,也可以个性化的填写,比如宅男、爱睡觉等。通过分词、提取、归类后,用户标签中同兴趣类的多个特征项相互合并,只保留一个特征项代表其对应的兴趣类,则用户的长期兴趣就由这些不同的特征项构成。
通常微博用户都会对他人进行关注,一旦用户关注了其他用户,就可以获取到关注用户的微博消息,这相当于用户订阅其关注用户的微博内容,并对这些微博内容感兴趣,因此被关注的用户博文会反映用户的兴趣。
假设任意一个用户i的长期兴趣向量为ILi=(ILi1,ILi2,…,ILim),共有m个兴趣类,即m个兴趣特征项。用户i的关注列表是X={x1,x2,…,xv},共有v个用户,将这v个用户的标签内容求并集,该并集即是用户i的关注列表标签集,标签集内元素的个数是:

本文的长期兴趣是通过关注列表的推荐和短期兴趣的反馈得到的。首先对分类完成以后的所有用户标签进行统计,原始数据经过处理和分类以后,共有48 475个微博用户,184 201个标签,平均每个用户拥有4个标签,因此本文取推荐标签数为4。统计关注列表X中标签集的兴趣类,将出现频率最高的4个兴趣类作为关注列表推荐,即推荐兴趣向量为INi=(INi1,INi2,INi3,INi4),其中INi1在X内出现的频率最高。现有用户i的长期兴趣向量ILi及其内的随机兴趣类j,
用ILij表示;短期兴趣向量ISi;关注列表推荐向量INi及其内的随机兴趣类k,用INik表示。
算法1用户长期兴趣修正算法
输入:用户长期兴趣向量ILi及随机兴趣类ILij
用户短期兴趣向量ISi及随机兴趣类ISik
关注列表推荐兴趣类INi
输出:修正后的长期兴趣向量ILi′
1.初始化 ILi′,令 ILi′=ILi
如果ILi为空,用INi初始化ILi′
2.如果ILi′元素数量小于4
若 ILij∈ ISi,则将 ILij保留到 ILi′
若 ILij∈ INi,则将 ILij保留到 ILi′
若以上两者情况都不满足,将INi中出现频率最高的兴趣类添加到ILi′,直到ILi′元素数量等于4
3.如果ILi元素数量等于4,不做修正
4.如果ILi元素数量大于4
若 INik∈ ILi,则将 INik保留到 ILi′
若 ILij∈ INi,则将 ILij保留到 ILi′
若 ILij∈ ISi,则将 ILij保留到 ILi′
若以上条件均不满足,则将INik保留到ILi′,将ILij删除
5.返回 ILi′
通过上述用户的长期兴趣修正算法可知,修正后用户的长期兴趣向量为 ILi′=(ILi1′,ILi2′,…,ILim′)。此时用户长期兴趣的兴趣类数量为mi′。
2.2 用户兴趣的更新
用户的长短期兴趣都是动态变化的,在微博数据持续的时间段内,如果短期兴趣的某些兴趣类持续活跃,能更充分地反映用户在这段时间内的兴趣,则动态调整短期兴趣为长期兴趣;如果长期兴趣的某些兴趣类在微博文本数据和关注列表中长时间没有体现,表明用户可能对此不再感兴趣,则在用户兴趣修正中将之除去。本节将详细介绍用户兴趣的更新过程。
假设用户i的微博文本中的短期兴趣向量为ISi=(ISi1,ISi2,…,ISin),对于任一兴趣类j的权重为:

式中,N′是用户i的微博文本中所有兴趣类出现的频率和;nj′表示兴趣类j在用户i的微博文本中出现的频率。
从式(7)可以得到每个短期兴趣类的权重,对短期兴趣向量按权重从大到小进行排序形成新的短期兴趣向量 ISi′=(ISi1′,ISi2′,…,ISin′),其对应的权值向量为wSi′=(wSi1′,wSi2′,…,wSin′),其中 wSi1′> wSi2′> … > wSin′,此时用户的长期兴趣向量为修正过后的兴趣向量集ILi′。
算法2用户兴趣更新算法
输入:ILi′=(ILi1′,ILi2′,…,ILim′)及其权重 wLi′ISi′=(ISi1′,ISi2′,…,ISin′)及其权重 wSi′
输出:ILi″,ISi″
1.for j=1 to n
若 ISij′∈ ILi′,则 ISi′删除 ISij′
end for
2.for x=1 to m
若 ILix′∉ ISi′且 wSij′> wLix′
则 ISi′删除 ISij′,ILi′添加 ISij′
3.若 ILix′=ISiq′(1 ≤ q≤n,j≠ q)
且 wSij′> wLix′+wSiq′
则 ISi′删除 ISij′,ILi′添加 ISij′
end for
4.更新长、短期兴趣向量
输出 ILi″,ISi″
上述算法对用户长期兴趣和短期兴趣进行更新,最后形成新的长期兴趣向量ILi″和短期兴趣向量 ISi″。
2.3 用户长短期兴趣的度量
根据用户微博文本的历史信息来构建用户的兴趣度计算模型,对于长期兴趣本文认为用户i对其mi′个兴趣类的偏好程度,可以通过标签集X内标签出现的频率来表征。以兴趣类在关注列表中出现的频率为基础度量用户i对其标签中的兴趣类j的兴趣度为:

对于用户的短期兴趣,历史信息越接近当前时刻越能表示用户的当前兴趣,反之越不能体现用户兴趣,这种现象类似于人类行为动力学中的兴趣衰减函数。因此,本文通过兴趣衰减函数来刻画用户的短期兴趣。另外用户对某个兴趣类关注越多表明用户对该类别的兴趣越明显,本文视这一情况为重复记忆,记忆的次数越多,记忆总量越多,单次记忆的增量越少,直至稳定状态。衰减函数表达式为:

式中,k是衰减速率。假设用户在t0时刻的兴趣度为P(t0),根据兴趣衰减函数从t0到t时刻用户的兴趣度降低到:

其中,kt是在时间段t0到t内的兴趣衰减速率,衰减函数体现了在时间段[t0,t]内记忆量随时间的变化范围。用户在一段时间内可能会多次发表或者转发某一兴趣类,多次重复记忆该兴趣类,因此本文提出多阶量化短期兴趣的方法。对于某兴趣类的一个特征项来说,微博在不同时刻多次发布了该特征项,发布时刻即为重复记忆的时刻。
从图3中可以看出,用户在每个时间段内的兴趣都会衰减,在不同的时段内用户具有不同的衰减曲率。如果相邻时间段的兴趣度初始值和衰减速率之间具有联系,就可以度量当前的用户兴趣。下面将介绍初始值Pn和衰减速率kn计算方法。在任意时刻,用户的兴趣度为:

Fig.3 Multi-orderquantization forshort-term interest图3 多阶量化短期兴趣度
从图3中可以看出,第n阶段的初始时刻,兴趣度Pn为:

式中,Hn是第n次记忆增加的记忆量;Mn是前n次剩余记忆量总和。Mn可以由上一阶段的兴趣度量化公式得出:

用户在重复记忆某一兴趣类的时候,单次的记忆量会不断减少,记忆总量会不断增大,但是增长趋势渐近平缓最终收敛。本文定义Hn为:

此时兴趣度Pn可以表示为:

由上述公式可知Pn和Pn-1之间的关系,为了得出任意时刻用户的兴趣度还需要得出kn和kn-1之间的关系。本文将相邻的兴趣衰减速率线沿着横轴和竖轴进行平移,使得两段曲线具有相同的初始值,该过程如图4所示。

Fig.4 Adjustmentof interest-forgetting rate图4 兴趣遗忘速率的调整
图4中y是tn-1到tn的时间段内相邻两条兴趣度曲线间的衰减差值,可表示为:

由此可推出kn和kn-1之间的关系:
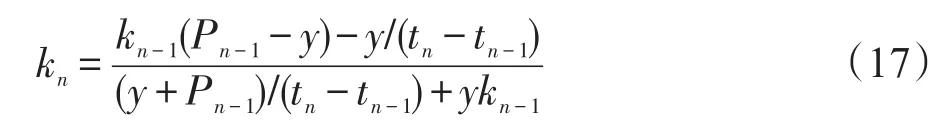
y值的上限是:

由图4可知,y的取值与时间间隔成正相关,因此设置一个惰性因子α,表示二者的关系,时间间隔越大,α的取值越大。将ymax划分为α段,α反映了在不同时刻的重复记忆对遗忘速率调整的程度。
对于αn-1的取值定义为:

式中,α0是惰性因子的初始值。计量时间以天为单位,若未满一天按一天计算。
基于衰减函数的多阶量化短期兴趣度方法,通过初始值可以得到任意时刻的P、k和α,进而可以计算用户的短期兴趣度,得到用户的短期兴趣度向量。
2.4 用户相似性计算
通过上文对用户兴趣的修正和更新以后,分别得到新的兴趣向量ILi″和ISi″,兴趣度向量wLi″和wSi″。则用户i的兴趣向量和兴趣度向量是:

得到Ii″和wi″后,再根据(美食,教育,娱乐,…,搞笑,生活)来调整并统一表征用户兴趣,同样与用户兴趣度向量一一对应,若用户不包含某项兴趣类,则在兴趣度向量中对应的兴趣度值为0。综上所述,可以得到具有相同的兴趣度向量和不同的兴趣度向量的各个用户。
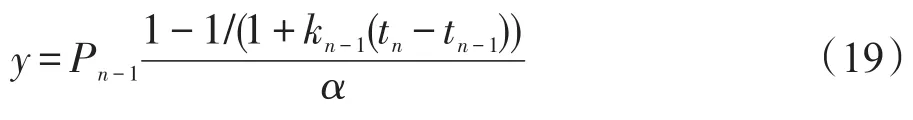
进一步,通过计算用户间的兴趣相似性来度量用户关系,若相似性值较大,则预测用户之间产生关系的可能性较大;反之,则可能性较小。用户间的兴趣相似性是以用户兴趣度向量为基础,使用余弦相似性指标来计算任意两个用户的兴趣相似性,公式为:

3 实验结果和验证
3.1 微博数据处理
本文使用北京理工大学的网络搜索挖掘与安全实验室公布的新浪微博用户数据[13],来验证本文算法的性能。数据集包括72 910条用户的个人信息和285MB的微博数据。微博用户个人信息的原始数据包括用户ID、地区、用户名、关注(关注用户数)、标签、关注列表等字段;用户微博文本信息是指用户发表和转发的微博,包括用户ID、回复数、评论数和微博产生的时间。原始数据如表1所示。
在处理数据之前需要对数据进行预处理,根据本文算法的实际需求,去掉数据集内关注列表数小于10个或者发表的微博数小于10条的不活跃用户,因为该类用户的关注用户和微博内容较少,很难获取到准确的兴趣数据,研究意义不大。经预处理后得到48 475个用户和1 127 164个用户关系。由表2可知,用户的微博数据杂乱,语义模糊,为了准确提取用户兴趣,首先需要对微博数据进行提取和分词。本文采用基于汉语词法分析系统最新版本的“NLPIR汉语分词系统”,用Java重写并将完全开源的汉语分词系统Ansj作为数据的分词工具。Ansj是Java编程,应用于自然语言处理的准确、高效、自由的中文分词工具,可用于人名、地名、组织机构名的识别和关键词提取等领域。在Eclipse中导入ansj-seg.jar和ansj-tree-split.jar这两个Java架包,其中ansj-seg是引用中文语料库,ansj-tree是分词模型。得到的分词效果如表2所示。

Table1 M icroblog dataofusers表1用户的微博数据

Table2 Resultsof participles表2 分词结果
对微博数据分词之后,去掉数据中的一些连词或者无意义词,如“的”,提取关键词,如“睡觉”、“跑步”、“投资”等。根据用户兴趣向量(美食,教育,娱乐,…,搞笑,生活)对用户分类以后,将每个用户标签内的特征项进行同兴趣类合并,得到不同的兴趣类。通过分类和数据提取得到用户的标签、关注列表信息和微博文本信息,如表3所示。
表3中,字段uid是用户ID号;suid表示源用户的ID号;tuid表示目的用户的ID号,并且suid关注tuid;label是用户标签;time是用户发表或转发微博的时间;topic是提取一个微博的主题。微博用户既可以双向关注也可以单向关注,因为本文算法分析的重点是用户的关注列表,所以在分析微博网络时,考虑的用户关系都是单向的。得到该网络的一些关键数据如表4所示。
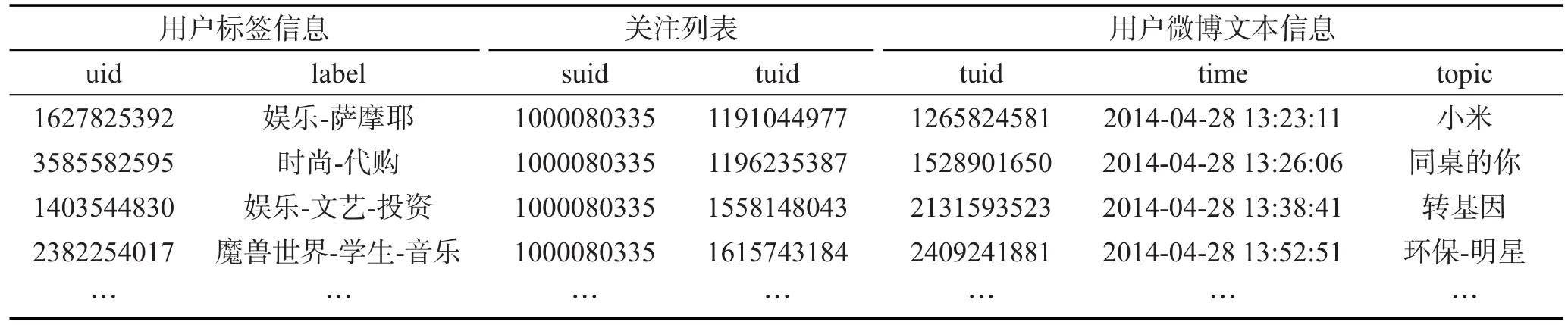
Table3 Processedm icroblog data表3 处理后的微博

Table 4 Data of localnetwork structure in Sinam icroblog表4 新浪微博局部网络结构数据
从表4可知,微博网络的用户量较大,对应的用户关系数量相对较少,表明网络结构较为稀疏,聚类系数指标也可以反映该结论;该网络的平均度和平均路径长度这两项指标反映出用户之间的交流和互动比较方便;网络节点的度分布较为均匀。图5所示为新浪微博用户的度分布。

Fig.5 Degree distribution of Sinam icroblog users图5 新浪微博用户的度分布
由图5的总体趋势可看出,当关注数小于200时,微博用户较为集中;当用户的关注数大于200时,用户数量较少,但是用户度分布范围较大,体现了社交网络的长尾效应。
3.2 实验结果分析
本文提出的基于用户兴趣相似性的关系预测算法使用AUC和Precision评价指标验证预测效果。将网络中实际存在的用户关系集E随机分为95%的训练集ET和5%的测试集EP。用户兴趣是根据用户的标签、微博文本内容和关注列表获取的,用户的兴趣被分为长期兴趣和短期兴趣。
图6表示用户标签数的分布情况,其中微博用户添加标签的上限是10个。从图6中可以得出,不存在标签的用户在数据集内所占比例高达45.73%,低于存在标签的用户数量,因此可以用标签和关注列表来表征长期兴趣。对于存在标签的用户来说,标签数量分布较为不均匀,其中标签数小于4的用户较多,大于4的用户较少。这表明有一些用户可能不知道添加标签或者不愿意去尝试添加标签,导致无法准确地描述用户兴趣;另一些用户可能尝试性地体验添加几个标签,或者特意尽可能多地添加标签直到上限,从而充分地展示自己,但存在虚假或者不活跃兴趣类的问题。因此,通过关注列表修正用户兴趣对于准确描述用户兴趣,进而提高用户关系预测的准确性具有重要的作用。

Fig.6 Distribution of thenumberofusersw ith thetag图6 用户数量随标签的分布
用户的短期兴趣是由微博文本内容表征的,短期兴趣度需要经过多阶量化的方法获取。在求短期兴趣度时,有3个参数需要确定,即兴趣度的初始值P0、衰减曲率的初始值k0和惰性因子α0。本文使用衰减函数进行多阶量化短期兴趣的兴趣度,为了便于计算和分析,设置初始兴趣度P0=1.0,初始衰减速率k0=1.0。惰性因子α反映用户重复记忆的频率,影响着用户的短期兴趣度,但是因为不同用户对同一兴趣类具有不同的记忆频率,为了降低计算的复杂性,设置一个初始定值α0。为了获取α0,本节设置不同取值,通过多阶量化的方式度量用户的微博文本内容,使用余弦函数计算用户间的短期兴趣相似性,最后通过AUC和Precision指标进行评价,经过多次计算取得的平均值如图7所示。

Fig.7 Impactof inertia facton forecasting resultsof short-term interestsim ilarity图7 惰性因子对短期兴趣相似性预测结果的影响
从图7中可以看出,随着初始惰性因子α0取值的增加,算法的AUC和Precision值逐渐变大,这是因为在惰性因子较小时,重复记忆增加的记忆量变化较大,调整效果较明显;在取值为6时,模型的AUC和Precision值最大,预测效果最好;当取值大于6时,AUC和Precision值略有下降直至稳定。这是由基于短期兴趣相似性的预测算法中用户对各个兴趣类的记忆量具有衰减和趋于收敛的特性决定的。
为了验证通过多阶量化的方式度量短期兴趣的效果,本文基于微博文本内容分别利用多阶量化、TF-IDF和遗忘曲线方法度量用户的兴趣度,并通过余弦指标计算用户间的相似性。这3种预测算法的AUC和Precision值对比结果如图8。

Fig.8 Comparison of differentprediction algorithms based onm icroblog contents图8 基于微博文本内容的预测算法的效果对比
从图8中可以看出,基于多阶量化短期兴趣的预测算法的AUC和Precision值都要优于基于遗忘曲线的预测算法[14]和基于IF-TDF的预测算法[15],表明考虑用户兴趣变化并进行多阶量化,能够较为有效地提高用户关系预测的准确性。
本文认为用户的短期兴趣能够转化成长期兴趣,长期兴趣需要短期兴趣的反馈来修正。用户兴趣的更新和修正,表明用户的长短期兴趣之间不但具有一定的差异性,也具有紧密的关联性。为了验证用户的长期兴趣和短期兴趣的关联性,本文继续对所有用户标签、微博数和关注用户数进行统计,得到图9。
从图9中可以看出,用户的标签数量在某种程度上能够反映出用户微博的活跃程度。标签越多的用户,其发布的微博平均数量也越多,关注列表的用户越多;微博和关注用户的数量走势虽然有一些波动,但整体上也呈现上升趋势,这个现象表明用户添加标签的数量与其微博活跃程度呈现正相关关系。因此本文认为采用标签表征的长期兴趣和微博文本内容表征的用户短期兴趣具有相同的变化趋势,体现了二者之间的关联性。

Fig.9 Correlation between numberof tag and interestofusers图9 标签数与用户兴趣关联性

Fig.10 Contrastof interestdegreebetween long-term interestand short-term interest图10 长短期兴趣的兴趣度对比
从图10中可以看出,用户长短期兴趣度具有较大的差异性。用户对每个兴趣类的兴趣度都较低,虽然长短期兴趣对各兴趣类具有不同的偏好程度,但长期兴趣度在整体上低于短期兴趣度。从用户兴趣的持久性来看,教育、音乐、新闻、星座等长期兴趣类的兴趣度高于短期兴趣。在数据持续的这段较短的时间内,用户对科技、娱乐和购物等兴趣类更感兴趣。通过上述对用户长短期兴趣的关联性和差异性的分析可知,本文将用户兴趣分为长短期兴趣,对兴趣的度量和整体更新具有合理性。
为了验证本文用户兴趣更新的效果,对比分析本文的预测算法和在本文算法的基础上忽略用户兴趣更新的预测算法,得到的AUC和Precision值是通过100次实验得到的平均值。
从图11中可以看出,本文的预测算法相比较于忽略用户兴趣更新预测算法的AUC值高1.647%,Precision值高0.932%。由实验结果可知,虽然用户的微博文本内容中包含的信息量较大,但是微博内容特别杂乱,或者由于一些不可预知的原因,导致兴趣类容易发生改变。因此考虑用户的短期兴趣类向长期兴趣的转换和长期兴趣类的消失或沉默,准确地细化用户兴趣的状态并及时更新用户兴趣,能够降低未知因素的干扰,得到较为稳定的用户兴趣,提高用户关系预测的准确性。

Fig.11 Impactof interestupdating ofuserson forecasting results图11用户兴趣更新对预测结果的影响
为了验证本文算法的预测效果,选取4种构建用户兴趣的算法与本文的兴趣相似性算法进行对比分析。这4种算法分别是经典算法TF-IDF和LDA[16],基于隐含语义动态分析用户兴趣的DPLSA算法[17],融合网络结构和微博内容的TFP算法[18]。通过这4种算法计算用户间的相似性,并通过AUC和Precison评价指标对这些算法进行评价,得到的预测效果如图12所示。
从这5类算法的预测效果上来看,本文算法的预测效果最好,TFP算法次之,TF-IDF算法的效果最差。本文算法动态考虑了用户兴趣变化,并通过关注列表推荐兴趣偏好,也在一定程度上融合了社交网络的局部结构特征,因此预测效果较为明显。TFP算法融合了网络结构和微博内容信息,从整体网络结构和用户兴趣两方面考虑用户的相似性,但是因为新浪微博对每个用户信息有严格的限制,难以获取全部的结构信息。另外该算法并未考虑用户兴趣的变化,影响了预测精度。DPLSA算法采用固定的时间窗口跟踪用户兴趣的变化,表征用户兴趣不太准确。TF-IDF和LDA算法都是通过语料库来提取关键字,导致很多与兴趣无关的关键字融入在兴趣集内,从而使得算法的预测精度较低。
综上所述,本文对比并分析了用户长期兴趣和短期兴趣之间的差异性和关联性,并采用不同的方式度量、修正和更新用户兴趣。实验仿真结果表明,本文基于用户兴趣相似性的用户关系预测算法设计合理有效,能够准确地描述用户兴趣,并提高用户间关系预测的准确性。
4 结束语
本文分析了目前基于用户兴趣的关系预测算法忽略用户兴趣具有持久性和易变性的特征,导致无法准确描述用户兴趣,以及用户关系预测准确性低的问题。针对该问题,本文构建了基于微博用户兴趣相似性的预测模型,根据关注列表推荐和短期兴趣反馈来修正用户的长期兴趣,通过兴趣类的长短期兴趣转换实现用户兴趣的更新;采用基于兴趣衰减函数的多阶量化方法计算短期兴趣度,基于兴趣类的频率统计计算长期兴趣度;最后通过余弦相似性计算用户的兴趣相似度来预测用户关系。通过实验证明,本文针对用户长短期兴趣采用不同方式进行度量,并对用户兴趣进行修正、更新,能够准确地描述用户兴趣,对用户关系预测具有较好的预测效果。
[1]Liu Zhiyuan,Shi Chuan,Sun Maosong.FolkDiffusion:a graph-based tag suggestionmethod for folksonom ies[C]//LNCS 6458:Proceedings of the 6th Asia Information Retrieval Societies Conference,Taipei,China,Dec 1-3,2010.Berlin,Heidelberg:Springer,2010:231-240.
[2]Backstrom L,Sun E,Marlow C.Findme if you can:improving geographicalpredictionw ith socialand spatialproximity[C]//Proceedings of the 19th International Conference on World WideWeb,Raleigh,USA,Apr 26-30,2010.New York:ACM,2010:61-70.
[3]Yang Changchun,Yang Jing,Ding Hong.A new friends recommendation algorithm for Sina m icroblogging[J].Computer Application and Software,2014,31(7):255-258.
[4]Wang Guoxia,Liu Heping.Survey of personalized recommendation system[J].Computer Engineering and Applications,2012,48(7):66-76.
[5]Zhang Shanliang,Zhou Yan.Timeweighted social networks link prediction algorithm based on random walk[J].Computer Applicationsand Software,2014,31(7):28-30.
[6]Wu Chengchao,WangWeiping.PLSA collaborative filtering algorithm incorporated w ith user interest change[J].Computer SystemsApplications,2014,23(5):162-166.
[7]Sun Jingyu,Li Xianhua,Yu Xueli.An improved item-based collaborative filtering algorithm w ith distinction between user's long and short interests[J].Journalof Zhengzhou University:Natural Science Edition,2010,42(2):35-38.
[8]Sun Wei.Interestmining and modeling form icro-bloggers ofmicro-blog[D].Dalian:Dalian University of Technology,2012.
[9]Guo Jinli.Complex networks and dynam ic evolutionmodel ofhuman behavior[M].Beijing:Science Press,2013:204-206.
[10]Qiu Jun.Research on user interestmodeling based onmicroblog social network[D].Shanghai:Shanghai Jiao Tong University,2013.
[11]Qiao Xiuquan,Yang Chun,LiXiaofeng,etal.A trust calculating algorithm based on social networking service users'context[J].Chinese Journal of Computers,2011,34(12):2403-2413.
[12]Li Feng,Pei Jun,You Zhiyang.Adaptive user interestmodel based on the implicit feedback[J].Computer Engineering and Applications,2008,44(9):76-79.
[13]Zhang Huaping.Sinam icroblog users'data[EB/OL].(2014-07-08)[2016-04-06].http://www.datatang.com/org/6880.
[14]Li Kechao,Liang Zhengyou.Exponential forgetting collaborative filtering recommendation algorithm incorporated w ith user interest change[J].Computer Engineering and Applications,2011,47(13):154-156.
[15]Pramono L H,Rohman A S,Hindersah D H.Modified weighting method in TF-IDF algorithm for extracting user topic based on email and socialmedia in integrated digital assistant[C]//Proceedings of the 2013 Joint International Conference on Rural Information&Communication Technology and Electric-Vehicle Technology,Bandung,Indonesia,Nov 26-28,2013.Piscataway,USA:IEEE,2013:1-6.
[16]Bian Jinqiang,Jiang Zengru,Chen Qian.Research onmultidocument summarization based on LDA topic model[C]//Proceedings of the 6th International Conference on Intelligent Human-Machine Systems and Cybernetics,Hangzhou,China,Aug 26-27,2014.Piscataway,USA:IEEE,2014:113-116.
[17]Yan Meng,Zhang Xiaohong,Yang Dan,etal.A component recommender for bug reports using discrim inative probabilitylatent semantic analysis[J].Information and Software Technology,2016,73:37-51.
[18]Shang Yanm in,Zhang Peng,Cao Yanan.A new interestsensitive and network-sensitivemethod for user recommendation[J].Journalon Communication,2015,36(2):121-129.
附中文参考文献:
[3]杨长春,杨晶,丁虹.一种新的新浪微博好友推荐算法[J].计算机应用与软件,2014,31(7):255-258.
[4]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[5]张珊靓,周晏.基于随机游走的时间加权社会网络链接预测算法[J].计算机应用与软件,2014,31(7):28-30.
[6]吴成超,王卫平.考虑用户兴趣变化的概率隐语意协同推荐算法[J].计算机系统应用,2014,23(5):162-166.
[7]孙静宇,李鲜花,余雪丽.区分用户长短期兴趣的IBCF改进算法[J].郑州大学学报:理学版,2010,42(2):35-38.
[8]孙威.微博用户兴趣挖掘与建模研究[D].大连:大连理工大学,2012.
[9]郭进利.复杂网络和人类行为动力学演化模型[M].北京:科学出版社,2013:204-206.
[10]仇钧.基于微博社会网络的用户兴趣模型研究[D].上海:上海交通大学,2013.
[11]乔秀全,杨春,李晓峰,等.社交网络服务中一种基于用户上下文的信任度计算方法[J].计算机学报,2011,34(12):2403-2413.
[12]李峰,裴军,游之洋.基于隐式反馈的自适应用户兴趣模型[J].计算机工程与应用,2008,44(9):76-79.
[14]李克潮,梁正友.适应用户兴趣变化的指数遗忘协同过滤算法[J].计算机工程与应用,2011,47(13):154-156.
[18]尚燕敏,张鹏,曹亚男.融合链接拓扑结构和用户兴趣的朋友推荐方法[J].通信学报,2015,36(2):121-129.

黄宏程(1979—),男,河南南阳人,2006年于重庆邮电大学获得硕士学位,现为博士研究生,重庆邮电大学通信与信息工程学院副教授,CCF会员,主要研究领域为复杂网络,信息处理,大数据技术与应用等。

LUWeijin was born in 1989.He is an M.S.candidate at School of Communication and Information Engineering,Chongqing University of Postsand Telecommunications.His research interest ispersonalized recommendation.
陆卫金(1989—),男,江苏南通人,重庆邮电大学通信与信息工程学院硕士研究生,主要研究领域为个性化推荐。

HU M inwasborn in 1971.She received theM.S.degree from Chongqing University of Postsand Telecommunications in 2002.Now she isan associate professor and M.S.supervisor at Schoolof Communication and Information Engineering,Chongqing University of Postsand Telecommunications.Her research interests includew ireless communication,communication network system and protocol,etc.
胡敏(1971—),女,重庆人,2002年于重庆邮电大学获得硕士学位,现为重庆邮电大学通信与信息工程学院副教授、硕士生导师,主要研究领域为无线通信,通信网体系与协议等。

WEIQing was born in 1990.He is an M.S.candidate at School of Communication and Information Engineering,Chongqing University of Posts and Telecommunications.His research interests include communication network system and big dataanalysis,etc.
魏青(1990—),男,河南信阳人,重庆邮电大学通信与信息工程学院硕士研究生,主要研究领域为通信网体系,大数据分析等。
User Relationships Prediction Algorithm w ith Interest Sim ilarity M easurement*
HUANG Hongcheng1,2+,LUWeijin1,HUM in1,WEIQing1
1.School of Communication and Information Engineering,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
2.Collegeof Computer Science,Chongqing University,Chongqing 400044,China
For the problem that current researchers only pay their attention to the changeability and ignore the durability when they study user interest inm icroblog,this paper proposes a user relationship prediction algorithm based on interest sim ilarity.In this algorithm,interests are divided into two types:long-term interest characterized by labels and short-term interestcharacterized by texts,and a frequency statisticsandmulti-orderquantizationmethod isused to measure and update the degree of user interestaccording to the features of the interest.The sim ilarity between user interests is computed by themethod of cosine sim ilarity which is used to predictuser relationship.Results show that the proposed algorithm can accurately describe user's interest,and improve the precision of user relationship prediction.
user interest;sim ilarity;multistagequantization;relationship prediction
gcheng was born in 1979.He
the M.S.degree in communication and information engineering from Chongqing University of Posts and Telecommunications in 2006.Now he is an associate professor at School of Communication and Information Engineering,Chongqing University of Posts and Telecommunications,and the member of CCF.His research interests include complex network,information processing,big data technology and application,etc.
A
:TP391
*The National Natural Science Foundation of China under Grant No.61401051(国家自然科学基金);the Foundation and Frontier Research Projectof Chongqing Science and Technology Comm ission under GrantNo.cstc2014jcyjA 40039(重庆市科委基础和前沿研究项目);the Science and Technology Research Projectof Chongqing Municipal Education Comm ittee under Grant No.KJ1400402(重庆市教委科学技术研究项目).
Received 2016-06,Accepted 2016-09.
CNKI网络优先出版:2016-09-08,http://www.cnki.net/kcms/detail/11.5602.TP.20160908.1045.012.htm l
摘 要:针对目前研究微博用户兴趣变化时,只考虑用户兴趣的易变性而忽略了用户兴趣持久性的问题,提出了基于用户兴趣相似性的用户关系预测算法。将用户兴趣分为短期兴趣和长期兴趣,用户的文本信息表征为短期兴趣,用户的标签表征为长期兴趣。根据长短期兴趣的特征,采用频率统计和多阶量化的方法度量用户兴趣度并更新用户兴趣状态。最后通过余弦相似性指标计算用户间的兴趣相似度来预测用户关系。实验结果表明,该算法能够准确描述用户兴趣,提高用户关系预测的准确性。
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
数学物理学报(2022年5期)2022-10-09 08:56:44
作文大王·低年级(2022年3期)2022-03-19 18:09:52
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
河北画报(2020年8期)2020-10-27 02:54:20
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
校园英语·下旬(2016年2期)2016-03-18 10:23:20
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
