
一种基于混合神经网络的抽取式文本摘要方法
2017-07-24 15:30:48林晶
怀化学院学报 2017年5期
林晶
(怀化学院计算机科学与工程学院,湖南怀化418008)
一种基于混合神经网络的抽取式文本摘要方法
林晶
(怀化学院计算机科学与工程学院,湖南怀化418008)
能够帮助人们快速浏览和理解文档或文档集,传统抽取式摘要方法高度依赖于人工特征,本文设计了一种基于混合神经网络(FNN)的文档摘要方法,它包含了一个分层文档编码器及一个基于关注的抽取器,能够不依赖于人工特征自动抽取句子产生摘要.实验结果表明,该方法效果较好.
文本摘要;句子抽取;混合神经网络
1 引言
电子商务是一种新的商业渠道,伴随其发展也导致大量产品与服务的评论网站出现.如何从其海量资讯中高效地获取有用信息成为人们的迫切需要.从关于特定商品实体及其属性的文本中挖掘并总结观点形成摘要,能够帮助消费者做出购买决定,帮助商家更好地监控市场声誉、了解市场需求.文本摘要的任务就是生成一个有限长度的文摘,能够帮助人们快速浏览和理解文档内容,自动摘要技术是提供这类服务的有效途径.
自动文摘首次提出至今,在六十年来的研究与发展中诞生了许多摘要方法.总的来说,这些方法可分为抽取式和生成式两大类[1].摘要任务在自然语言处理和信息检索领域有着广泛研究,以前大多关注从新闻文档集合中直接抽取句子形成摘要.典型的多文档摘要方法包括基于中心的方法、整数线性规划、基于句子的LDA、子模函数最大化、基于图的方法以及基于监督学习的方法[2].
大文档-摘要语料的开放为使用统计文本生成技术产生生成式摘要提供了可能.与所有抽取技术进行对比,有专家提出支持生成式摘要的论据,并进一步研究了使用统计机器翻译作为生成文本摘要技术的可能性[3].生成式摘要包含通过重写给定文本内容生成摘要的技术,而不是简单抽取重要句子.但多数生成式摘要技术仍然采用句子抽取作为任务的第一步.
相比生成式摘要技术,文本摘要的抽取技术受到长期研究的重点关注.在过去几十年中,特别是DUC和TAC会议出现之后,开发了大量的抽取式摘要技术.
2 相关工作
鉴于文档摘要的重要意义与实用价值,吸引了大量研究人员致力于摘要技术研究.单文档摘要基本上可以通过句子选择来完成.被摘要的文档被分解为句子集,接着摘要程序选择句子子集作为摘要.作为在商业环境下提供更好信息访问的关键技术,单文本摘要受到了大量关注.财经时代及CNN为吸引用户在他们的网站上提供文章摘要,它已被Yahoo采用,在互联网上提供自动文章摘要服务.考虑到人工摘要的高成本,通过构建能够达到人类摘要质量的自动摘要程序将极大提升互联网用户对信息的访问.McDonald(2007)指出,单文档摘要可以形式化为著名的组合优化问题,即背包问题.给定一组句子及其长度与价值,摘要程序将它们选入摘要以使得总价值尽可能大但总长度小于等于给定的最大摘要长度.
为了模仿人工书写的摘要,连贯性是一个重要方面.为获得连贯摘要,Hitoshi等提出基于隐半马尔科夫模型的摘要方法.它具有流行的单文档摘要模型与隐马尔科夫模型两者的特性,隐马尔科夫模型在选择句子时通过决定句子上下文考虑摘要连贯性[4].
在单文档摘要中产生连贯摘要有两类方法:基于树的方法[5]及基于序列的方法[6].前者依靠基于修辞结构理论(RST)的文档的树表示,通过利用句子间的“中心-卫星”关系修剪文档树表示.基于RST方法的优点是能够利用文档的全局信息,缺点是过分依赖所有的分析树.与利用文档全局结构相反,基于序列的方法依赖和使用句子的局部连贯性.对比基于树的方法,基于序列的方法不需要类似RST分析器的工具,因此更加鲁棒.
Shen等通过使用条件随机场(CRF)扩展基于HMM的方法获得区分度[6].CRF能够基于大量特征来识别句子重要性并展示其有效性.这类模型的缺点是只能把句子分为2类,不能直接考虑输出长度.这一不足有很大问题,因为实际应用中摘要长度是有限的.因此,摘要器应该能够控制输出长度.相比于这些方法,本文采用一种混合神经网络的摘要方法,在对文档进行自动摘要时,自然地考虑了最大长度约束.
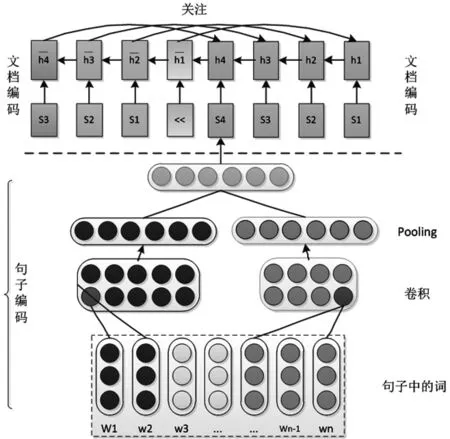
图1 混合神经网络摘要模型
3 系统模型
3.1 问题形式化
给定文档D,包含句子序列{S1,…,Sn},选择k(k 3.2 系统摘要模型 如图1所示,摘要模型关键部分包括基于神经网络的文档读取器和基于关注的内容抽取器.模型分层反映了文档由词、句、段组合而成的本质.所以采用反映相同结构的表示框架,能够发现全局信息,保持局部信息,可以产生最小信息损失并能灵活选择较长上下文内的重要句子,最终依据摘要长度限制产生摘要. 3.3 文档读取程序 每个句子被看作1个词序列,读取程序从句子中推导文档的意义表示.先通过单层神经卷积网络(CNN)获取句子的表示向量,然后使用标准并行神经网络(RNN)递归地组合句子生成文档表示.在分层方式下,词级别的CNN获得句子表示,用作RNN的输入以获取文档表示. 句子编码程序采用卷积神经网络表示句子.因为,单层卷积神经网络可以有效训练并已成功用于句子分类任务.设d表示词向量的维数,s是包含词序列(w1,…,wm)的句子,可表示为一个列矩阵w∈Rmxd.使用W和K∈Rfxd之间的宽度为f的卷积如下: 其中,⊙表示Hadamard积(对应元素相乘),b表示偏差表示第i个特征的第k个元素. 文档编码程序的任务是由RNN把句向量组合成文档向量.RNN的隐状态可看作部分列表表示,这些列表一起构成了文档表示.设文档d={s1,…,sn},ht是t时刻的隐状态,按以下公式[7]调整: 其中,⊙表示对于元素相乘,Wi,Wf,bi,bf为语义组合的自适应选择与删除的历史向量和输入向量.Wr∈Rlh×(lh+loc),br∈Rlh,lh和loc分别是隐向量和句子向量的维数. 3.4 句子抽取程序 读取句子后,由句子抽取程序应用关注直接抽取句子.该抽取程序也是一个RNN,同时考虑句子的相关性及冗余性.设t时刻编码程序的隐态为(h1,…,hm),抽取程序的隐态为(h1,…,hm),通过当前译码状态与对应编码状态的关联,译码器关注第t个句子: 其中,MLP是一个多层神经网络,以t时刻隐态与状态的连接ht:ht为输入.dt-1表示抽取程序认为应该抽取和存储前一个句子的程度. 表1 DUC2005评测结果 表2 DUC2006评测结果 表3 以柬埔寨政治危机为主题的自动摘要实例 本文实验选择DUC的标准数据集和评测方法实施实验,以评估本文在第3节和第4节介绍的方法.评估方法进以DUC2005语料作为测试集,DUC2006语料作为开发集.DUC2005数据集包含约1300篇文档. DUC2006数据集包含1250篇文档. 首先对数据集进行预处理,然后利用斯坦福大学自然语言处理研究小组开发的开源工具包CoreNLP对预处理后的文本进行句子切分、词性标注、命名实体识别、依存分析,以及指代消解等处理,借助组合语义的思想利用词向量表示句子向量. 同众多主流方法一样选择LexRank[8]和Centroid[9]作为DUC2005的基准系统,选择NIST-baseline作为DUC2006的基准系统.实验结果如表1、2所示. 在与主流摘要方法的对比中,我们的方法也取得了不错的成绩.在DUC2005、DUC2006数据集的评测中,本文方法领先于基于相同数据集评测的基线方法.本文方法在整体表现上都很优秀,这也充分说明了混合神经思想在生成式摘要上的可行性. 由于抽取式方法易于机器实现,所以在过去的研究中,主要摘要方法基本上都采用抽取式的思想.表3展示了一篇关于柬埔寨政治危机文章的自动抽取式摘要的实验结果.表格第一栏是包含179个英文句子的短文片段,粗体字部分是自动抽取的摘要句.第二栏是人工编写的参考摘要句.对比来看,自动抽取的摘要句基本上涵盖了人工摘要句1)、3)、5)所要表达的含义,且与主题“柬埔寨政治危机”相吻合. 本文设计了反映文档词、句、段结构本质的表示框架,先通过单层神经卷积网络获取句子的表示向量,然后使用标准并行神经网络递归地组合句子生成文档表示.它能够发现全局信息,保持局部信息,产生最小信息损失,并能灵活选择较长上下文内的重要句子生成摘要.实验表明,本文方法效果较好. [1]Hahn U,Mani I.The challenges of automatic summarization[J]. Computer,2000,33(11):29-36. [2]Xiaojun Wan,Tianming Wang.Automatic Labeling of Topic Models Using Text Summaries[C]//Proceedings of the 54th Annual Meetingofthe Association for Computational Linguistics,2016:2297-2305. [3]Parth Mehta.From Extractive to Abstractive Summarization:A Journey[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics-Student Research Workshop,2016:100-106. [4]Hitoshi Nishik awa1,Kazuho Arita1,Katsumi Tanaka,et al. Learning to Generate Coherent Summary with Discriminative Hidden Semi-MarkovModel[C]//Proceedings ofCOLING 2014,the 25th International Conference on Computational Linguistics:Technical Papers,2014:1648-1659. [5]Hitoshi Nishikawa,Takaaki Hasegawa,Yoshihiro Matsuo,et al. Opinionsummarizationwithintegerlinearprogramming formulation for sentence extraction and ordering[C]//.International Conference on Coling,2010:910-918. [6]Dou Shen,Jian-Tao Sun,Hua Li,et al.Document summarization using conditional random fields[C]//.In Proceedings of the 20th international joint conference on Artifical intelligence(IJCAI),2007:2862-2867. [7]Duyu Tang,Bing Qin,Ting Liu.Document Modeling with Gated Recurrent Neural Network for Sentiment Classification[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,2015:1422-1432. [8]Erkan G,Radev D R.LexRank:Graph-based lexical centrality as salience in text summarization[J].Journal of Artificial Intelligence Research,2004:457-479. [9]RadevDR,JingH,BudzikowskaM.Centroid-based summarizationofmultipledocuments:sentenceextraction,utility-based evaluation,and user studies[C]//Proceedings of ACL,2000:21-30. On Extractive Summarization Via Hybrid Neural Networks LIN Jing A document or a set of documents are easy for readers to read and understand fast by their summaries. But traditional extractive summarization relies heavily on human-engineered features.Hence in this work a summarization approach was proposed based on hybrid neural networks(FNN).Our model includes a neural network-based hierarchical document reader or encoder and an attention-based content extractor.The proposed approach can automatically generate summary by extracting salient sentences from documents.Experiments show that our model outperforms previous state-ofthe-art methods. text summarization;sentences extraction;hybrid neural networks TP391 A 1671-9743(2017)05-0071-04 2017-02-22 湖南省重点实验室项目“武陵山区生态农业农情摘要关键技术研究”(No.ZNKZ2014-8). 林晶,1970年生,男,湖南邵阳人,副教授,研究方向:自然语言处理、大数据分析、信息安全.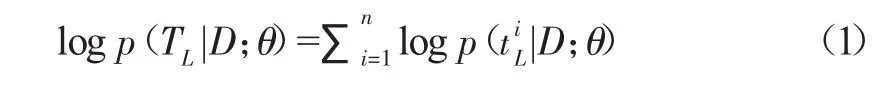






4 实验结果及分析
5 结语
(School of Computer Science and Engineering,Huaihua University,Huaihua,Hunan 418008)
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
人大建设(2019年12期)2019-05-21 02:55:44
瞭望东方周刊(2017年42期)2017-12-05 18:49:38
环球时报(2017-03-30)2017-03-30 06:44:45
信息安全研究(2016年4期)2016-12-01 06:06:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
