
基于通信数据上下文的用户信任度预测
2017-07-19 13:11张小可
移动通信 2017年12期
张小可
基于通信数据上下文的用户信任度预测
张小可
(广州杰赛科技股份有限公司,广东 广州 510310)
为了解决社交网络信任度不全面的问题,通过采用通信数据上下文的用户信任度预测方法,分析了移动用户之间的熟悉信任度以及相似信任度,并结合时间衰减因子,提出了基于时间相关性的用户信任度预测方案。实验证明,考虑时间衰减因子和上下文的通信用户信任度预测方法能够在一定程度上提升用户之间的信任度预测,并具有一定的扩展性。
社交网络 信任度 上下文 时间衰减因子
1 引言
随着移动通信技术的发展和移动互联网应用的广泛普及,国内外有越来越多的基于社交网络和位置融合的移动应用应运而生。因此,很多研究学者利用用户在使用移动应用业务时产生的各类交互通信信息(包含用户交互信息以及用户在特定时间、特定地点的兴趣信息)来研究移动通信用户之间的信任度,以熟人推荐来促进大量的消费行为。例如,张丰[1]结合P2P网络拓扑结构和社交网络自身的关系,提出基于社交网络关系模型的静态信任模型以及基于反馈的动态信任模型;乔秀全等[2]基于社交网络服务中用户上下文信息,将信任度分为熟悉信任度和相似信任度;史艳翠[3]根据通信用户数据的上下文信息计算用户直接信任度,利用用户社交网络的传播距离来计算用户的间接距离;雷环等[4]通过用户之间的熟悉性和相似性来计算用户之间的信任度。这些研究既有针对社交网络,也有针对移动通信行为提出的信任度预测模型。本文通过借鉴上述研究成果,结合当前移动社交网络和移动通信行为的具体情况,提出基于上下文的移动用户行为的信任度预测模型。
2 信任度的研究
2.1 问题定义
信任度是社会心理学的一个关键性问题。用户之间的信任度产生的机制大概分为[2]:
(1)通过其过去的行为以及声誉的了解给予了一定的信任,这种一般是通过对他人进行交互通信而产生的熟悉信任度;
(2)由于社会或者兴趣的相似性程度而产生的信任度;
(3)由法制产生的信任度。
当前对信任度的描述往往是基于人际关系形成的社交网络产生的人与人之间的心理信任。本文借鉴社会心理学的原理,提出基于上下文的通信用户行为信任度模型,该信任度分为熟悉信任度和相似信任度。其中,熟悉信任度源于移动用户的交互行为产生用户关系以及熟悉性程度的信任度;相似信任度源于移动用户使用移动业务相似性程度的信任度。
首先采用分析用户的交互(通话和移动社交业务)行为来获取用户的关系和关系深度(用户之间联系的频率、时长、时间间隔),进而根据用户关系计算用户的熟悉信任度;然后分析用户自身使用移动业务行为(包括使用移动业务的时长、次数),根据用户使用移动业务行为的相似性来计算用户的相似信任度;最后结合时间衰减因子来修正用户熟悉信任度和相似信任度,利用时间相关性提高信任度预测的准确性。
2.2 信任度预测方法
(1)社会相似度预测方法
用户之间共同朋友数越多,其社交、兴趣、偏好就越相似,因此共同朋友的数量也是衡量用户之间的信任程度。设任意两个直接相连的移动用户节点u和v具有共同朋友,节点u的朋友集合为F(u),节点v的朋友集合为F(v),则u和v的共同朋友为F(u)与F(v)的交集。

(2)基于关系强度的预测方法
用户之间的移动社交网络关系网其实就是真实社交网络的镜像,因此不少研究学者提出通过用户交往次数和见面次数来衡量用户的信任程度,其中有选取用户的交往频率等关系强度的因素来计算用户之间的信任度。
用户之间的信任度可以用交往指数来衡量,公式如下:
F=a1×交往频率+a2×通话次数+a3×通话时长(2)其中,交往频率=(双方通话天数+通话的周数量)/30;a1、a2、a3(三个系数之和为1)分别为权重系数,用户可根据衡量的侧重点设定。
(3)基于兴趣相似度的预测方法
基于兴趣相似度预测信任度是基于一种假设:如果用户的兴趣偏好相似,那么相似偏好用户之间的信任度一般会比非相似偏好用户之间的信任度高。设用户u和用户v共同感兴趣的移动应用集合为Iu,v,Ru,c表示某个时段用户u对移动应用c的偏好程度(一般可以用使用次数、使用频率、使用时长来衡量),Rv,c表示用户v对移动应用c的偏好程度,Ru表示某个时段用户u对移动应用集合的平均偏好程度,Rv表示某个时段用户v对移动应用集合的平均偏好程度,则用户u和用户v的兴趣相似度为:

(4)基于用户上下文的通信用户行为信任度预测
综合目前的研究成果,本文结合通话行为本身的属性,提出基于用户上下文的通信用户行为信任度预测模型。该模型除了需要衡量用户之间联系的相处时长、频率、通话时长、时间间隔外,还要分析用户使用移动业务行为(包括使用移动业务的频率、次数、时间间隔),根据用户使用移动业务行为的相似性,计算用户的相似信任度。
◆用户熟悉信任度预测
假设用户u和用户v是有通信行为交互的两个用户,用户u在特定时间段内的轨迹可以表示为:<t1, l1>,<t2, l2>, …, <tn, ln>。其中,n表示发生语音业务或者数据业务的次数;t表示时间戳;l表示基站ID。那么,用户u的区域分布为:

其中,r的集合为关注的基站Loc,当用户u的第i次轨迹点与集合中的某个值匹配时,δ(r, li(u))=1,否则为0。
参考地理和时间的重合度概念,以△T为时间精度(一般设为1个小时),反映用户u与其他用户在邻近时间相同地理位置的比例。
此外,还需要考虑工作时间与非工作时间的影响因素,在工作时间段和非工作时间段权重分别设置不同的θ。
那么,用户的相处时长为:

其中,duration(u, v)表示在特定时间段内用户u和用户v的相处时长;△T表示时间精度;θ表示用户u和用户v通信时刻所属时间段权重;n(u)表示用户u的通信次数;n(v)表示用户v的通信次数;Ti(u)表示用户u第i次通信时刻;Tj(v)表示用户v第j次通信时刻;Ti(u)-Tj(v)表示在特定时间段内用户u第i次通信时刻与用户v第j次通信时刻的时间差;δ(li(u), lj(v))表示用户u第i次通信基站ID和用户v第j次通信基站ID是否相同,当li(u)=lj(v)时则等于1,当li(u)≠lj(v)时则等于0。
[5]的信任度计算方式,则用户之间相处时长的信任度为:
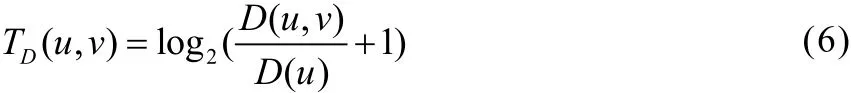
其中,D(u, v)表示在特定时间段内用户u和用户v的相处时长;D(u)表示在特定时间段内用户u与其通信的所有用户的相处时长。
同时考虑用户通信时长,采用任意两个用户在特定时间段内每次通信时长来衡量两个用户的熟悉信任度。因此,任意两个用户的通信时长熟悉信任度表达式为:

其中,TL(u, v)表示在特定时间段内用户u和用户v通信时长熟悉信任度;L(u, v)表示在特定时间段内用户u与用户v每次通信时长总和;L(u)表示在特定时间段内用户u与其通信的所有用户的每次通信时长总和。
用户的熟悉信任度最后还需要考虑用户的通信次数,则在特定时间段内任意两个用户的通信次数熟悉信任度表达式为:
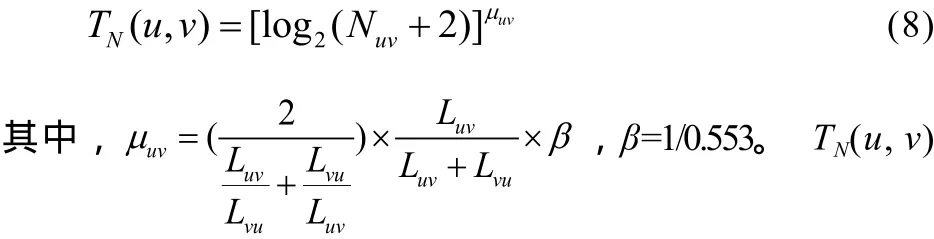
表示在特定时间段内用户u和用户v之间通信次数熟悉信任度;Nuv表示在特定时间段内用户u向用户v主动发起通信的次数;Luv表示在特定时间段内用户u向用户v主动发起每次通信的通信时长总和;Lvu表示在特定时间段内用户v向用户u主动发起每次通信的通信时长总和。
◆用户相似信任度预测
参考相似度协同过滤算法,通过提取用户使用同一种移动业务的时长和间隔,设用户u和用户v共同感兴趣的移动应用集合为Iu,v,则具有相似性用户使用移动业务行为的时长信任度计算公式为:

其中,SL(u, v)表示在特定时间段内用户u和用户v使用同种通信业务的时长信任度;Iu,v表示在特定时间段内用户使用的所有同种通信业务类型的集合;RL,u,c表示在特定时间段内用户u使用通信业务类型c的总时长;RL,u表示在特定时间段内用户u使用Iu,v中所有通信业务类型的平均时长;RL,v,c表示在特定时间段内用户v使用通信业务类型c的总时长;RL,v表示在特定时间段内用户v使用Iu,v中所有通信业务类型的平均时长。
同理,具有相似性用户使用移动业务行为的次数信任度计算公式为:

其中,RN,u,c表示在特定时间段内用户u使用通信业务类型c的次数;RN,v,c表示在特定时间段内用户v使用通信业务类型c的总次数;RN,u表示在特定时间段内用户u使用Iu,v中所有通信业务类型的平均次数;RN,v表示在特定时间段内用户v使用Iu,v中所有通信业务类型的平均次数。
2.3 引入时间衰减因子修正用户信任度
移动用户总是关注当前较近时间段内的交互以及近期的移动应用使用偏好,用户之间的近期交互行为以及偏好的相似性等更能反映用户之间的信任程度。随着用户交互的推进,越早的交互行为对当前的信任值计算影响越小,因此在计算信任值时需要对其进行更多的折扣。本文通过用户交互行为、移动偏好使用的时间间隔来描述时间衰减因子。假如用户u和用户v在进行第n次交互或者使用移动应用偏好,则第k次使用相关业务所产生的信任值的时间衰减因子为γn-k。γ的取值为0至1,表示信任值对当前用户之间的交互或者用户偏好使用的重视程度,γ越接近1则表示越重视。因此,引入时间衰减因子后用户之间的信任度为:

其中,n1表示在特定时间段内用户u和用户v相处总次数;n2表示在特定时间段内用户u和用户v通信总次数;n3表示在特定时间段内用户u和用户v使用同种通信业务的总次数;k1表示用户u和用户v第k1次相处;k2表示用户u和用户v第k2次通信;k3表示用户u和用户v第k3次使用同种通信业务;TD(u, v)表示用户u和用户v相处信任度;TN(u, v)表示用户u和用户v通话次数信任度;TL(u, v)表示用户u和用户v通信时长信任度;SL(u, v)表示用户u和用户v使用同种通信业务的时长信任度;SN(u, v)表示用户u和用户v使用同种通信业务的次数信任度;γ表示时间衰减因子。并且a1+a2+a3=1, a1、a2、a3的取值一般需要根据真实数据情况并结合经验进行取值。
3 基于上下文的通信用户行为的信任度预测的应用
3.1 数据获取
用户在发生移动业务的过程中,运营商会记录用户的各种信令信息,包括发生业务的用户ID、开始时间、结束时间、业务类型、开始站点、切换站点、结束站点、接收ID等。
本文提取某地市运营商20万用户一个月的信令数据,并按照一定的规则把切换基站进行预处理,形成满足本文数据分析的表格。具体如表1所示:

表1 移动用户的业务详单数据示例
由表1可知,如果用户在通话过程中存在基站的切换(从基站20556切换到基站23221),那么基站23221既可作为切换时的结束站点,也可作为切换后的开始站点。
3.2 结合用户共同朋友剔除无效数据
结合用户共同朋友来剔除无效数据,考虑到本文的重点是识别用户之间的信任度,因此重点是预测用户的关系。基于实际工作经验,本文设置用户的共同朋友数量为5,则最后得到满足共同朋友的用户数量为8702。
3.3 基于上下文的通信用户行为的信任度预测的建立
通过剔除无效数据后按照日期分为两部分,其中前15天作为训练集,后15天作为测试集。参考实验结果,设置a1为0.32、a2为0.28、a3为0.4,可保证训练集和测试集的准确性,并避免模型的过拟合性。然后根据用户的信任关系模型对训练集进行打分,得到一系列用户间的信任值,选择信任值区间为[0.3, 0.55],并以此为标准选取用户信任关系的候选集合,再分别将考虑时间衰减因子的信任度和不考虑时间衰减因子的信任度进行对比,最后与测试集比较,得到用户信任度预测准确率如图1所示:
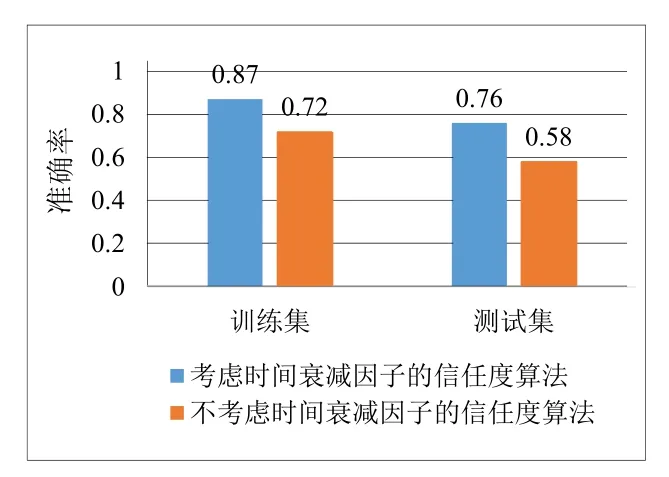
图1 考虑时间衰减因子和不考虑时间衰减因子的用户信任度预测准确率对比
由图1可知,不考虑时间衰减因子的算法在用户信任度预测准确率方面要比考虑时间衰减因子低。因此,结合时间衰减因子的用户信任度预测能够在一定程度上提升用户信任度预测的准确率。
4 结束语
本文基于真实的上下文的移动用户行为,提出了用户信任度预测的模型。首先基于用户共同朋友的算法剔除无效数据,并结合用户发生业务的上下文信息和时间衰减因子预测用户信任度,该方法是先从用户交互行为的角度来衡量用户的熟悉信任度;然后结合移动用户的兴趣偏好的角度来衡量用户的相似信任度;最后结合时间衰减因子,采用时间的相关性来描述用户在不同时间发生的业务行为对用户信任度的不同程度的影响,从而能够较好地预测用户之间的信任度。实验证明,考虑时间衰减因子与不考虑时间衰减因子的基于上下文的通信用户行为的信任度预测算法相比具有较高的准确率。
参考文献:
[1] 张丰. 社交网络中信任度计算[D]. 南京: 南京航空航天大学, 2014.
[2] 乔秀全,杨春,李晓峰,等. 社交网络服务中一种基于用户上下文的信任度计算方法[J]. 计算机学报, 2011,34(12): 2403-2413.
[3] 史艳翠. 基于通信数据的上下文移动用户偏好动态获取方法研究[D]. 北京: 北京邮电大学, 2013.
[4] 雷环,彭舰. SNS中结合声誉与主观逻辑的信任网络分析[J]. 计算机应用研究, 2010,27(6): 2321-2323.
[5] Huang D, Arasan V. On Measuring Email-Based Social Network Trust[C]//Global Telecommunications Conference. Miami, 2010: 1-5.
[6] 肖志宇. 基于社交网络和信任模型的推荐系统的研究与实现[D]. 南京: 东南大学, 2015.
[7] 杨海月,朱玉婷,施化吉,等. 基于用户信任度和社会相似度的协作过滤算法[J]. 电子技术应用, 2016,42(1): 100-103.
[8] 李默,梁永全,赵建立. 融合相似性评价、信任度与社会网络的学术资源推荐方法研究[J]. 情报理论与实践, 2015,38(5): 77-81.
[9] 马尧. 在线社会网络的信任网络发现与信任融合研究[D]. 武汉: 华中科技大学, 2014.
[10] 祝幼菁. P2P网络信任模型研究[D]. 武汉: 华中科技大学, 2006.★
Prediction of User Trust Degree Based on the Context of Communication Data
ZHANG Xiaoke
(G C I S c i e n c e & T e c h n o l o g y C o., L t d., G u a n g z h o u 510310, C h i n a)
In order to deal with the incomplete trust degree in social networks, a prediction method of user trust degree based on the context of communication data was used to analyze the trust degree of acquaintance and the trust degree of similarity between mobile users. Combined with the time decaying factor, a prediction scheme of user trust degree based on the temporal correlation was proposed. Experiments demonstrate that the prediction method considering both the time decaying factor and the user trust degree not only enhances the prediction accuracy of the trust degree between users to some extent, but has certain expansibility as well.
social networks trust degree context time decaying factor
10.3969/j.i s s n.1006-1010.2017.12.011
T P 391.4
A
1006-1010(2017)12-0054-05
张小可. 基于通信数据上下文的用户信任度预测[J]. 移动通信, 2017,41(12): 54-58.
2017-03-10
责任编辑:袁婷 y u a n t i n g@m b c o m.c n
张小可:中级工程师,硕士毕业于西安交通大学,现任职于广州杰赛科技股份有限公司研发中心,擅长于移动互联网和大数据应用软件设计开发以及产品化,主要从事产品架构设计、用户行为分析等工作。
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
今日农业(2020年13期)2020-08-24
环球时报(2018-01-23)2018-01-23
意林(2017年8期)2017-05-02
中学生数理化·中考版(2017年12期)2017-04-18
计算机工程(2015年4期)2015-07-05
医学研究杂志(2015年5期)2015-06-10
中国药业(2014年21期)2014-05-26
