
稀疏表示中字典学习的影响因子研究
2017-07-18 11:48:21赵娜赵彤洲邹冲刘莹蔡敦波
武汉工程大学学报 2017年3期
赵娜,赵彤洲*,邹冲,刘莹,蔡敦波
1.武汉工程大学计算机科学与工程学院,湖北 武汉 430205;2.智能机器人湖北省重点实验室,湖北 武汉 430205
稀疏表示中字典学习的影响因子研究
赵娜1,2,赵彤洲1,2*,邹冲1,2,刘莹1,2,蔡敦波1,2
1.武汉工程大学计算机科学与工程学院,湖北 武汉 430205;2.智能机器人湖北省重点实验室,湖北 武汉 430205
研究了稀疏表示中影响字典矩阵构建质量的关键因素,并实现了关键因子定量化表示.分别对图像数量、取块大小、字典列数和取块步长等因子进行参数调整并生成字典矩阵,结合系数矩阵对原始图像重构,以峰值信噪比和结构相似性索引测量这两种质量评价指标作为字典质量的评估依据.实验以CMU_PIE_Face数据库为数据源,结果表明当图像数量为500张、取块大小为4个像素点、字典列数为512维、取块步长为2个像素点时,所得到的字典具备对原始图像的最佳表示能力.因此,稀疏表示中关键因子的定量化表示可加速字典学习过程且简化模型复杂度,提高字典抽象层质量,具备更强的图像表现力.
稀疏表示;字典学习;字典精度;图像质量评价指标
人类视觉系统中仅用少量视觉神经元就能捕获自然场景中的关键信息[1],即场景主要信息可以通过稀疏表示充分表达.现在稀疏表示已经在信号和图像处理领域得到了广泛应用,如图像去噪[2]、图像恢复[3]、人脸识别[4-5]、物体检测[6]等方面.稀疏表示理论也得到了深入的研究,其中最早由Engan提出了最优方向算法(method of optimal directions,MOD),该算法字典学习方式简单,但是收敛速度很慢.在此基础上,Micheal Elad[7]于2006年提出了K-SVD算法.该算法在收敛速度上有了很大的提升,但是对噪声很敏感,噪声加大时,用该算法降低噪声会丢失图像的纹理细节而产生模糊的效果.Mairal[8]于2010年提出了一种在线字典学习算法(online dictionary learning,ODL).与传统算法相比,该算法能大幅降低计算量,提高字典更新速度,能够较好地恢复图像边缘锐度和纹理细节,使字典学习不再局限于小规模、确定的训练样本.本文在介绍基本稀疏表示模型[9]的基础上,讨论了ODL算法,并使用稀疏建模工具箱(sparse modeling software,SPAMS)对图像不同参数分别训练,从而得到学习字典.通过字典进行图像的重构[10],并通过峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性索引测量(structural similarity index metric,SSIM)质量评价准则对字典质量进行评估分析.
1 稀疏表示模型的构建
稀疏表示是将自然信号压缩表示为一组基向量的线性组合.假设XRm是一个信号,D=[d1,d2,...,dn]Rm´n是一个基向量的集合,称为字典,其中m< 由于m< minα0s.t.D×α=X.(2) 其中RIP条件为存在满足某种条件的常数μN,有: 考虑到信号含噪声的情况,模型可以表示成: 为了实现信号的稀疏表示,就必须求解上述的稀疏表示模型问题.因此,需要解决两个基本问题[12]:一是稀疏分解问题,即如何获取信号在字典D下最稀疏的分解系数α;二是稀疏字典学习问题[13],即如何设计与构造有效的稀疏表示字典D. 2.1 算法原理 构造合适有效的字典是稀疏表示的核心问题之一,其中字典的质量不仅仅取决于算法的优化,而且还与一些影响字典的因素相关,例如:训练图像数量、图像取块大小、字典列数、图像取块步长.本文在ODL算法[14]的基础上,对这些相关因素进行了研究. 假设X Î Rm´n是原始信号,D Î Rm´K(m< 步骤1:初始化.使用固定字典初始化D0,A0¬0,B0¬0,A0,B0为中间变量. 其中η为xt的数量. 步骤3:字典更新.使用式(7)依次更新字典Dt-1的第j列dt-1,j,直到RMSE满足要求. 重复步骤2和步骤3,直到满足迭代次数. 2.2 图像重构 为了衡量字典质量,对原始图像进行重构,并以重构图像质量作为字典质量的评估标准,重构过程如下: 1)对原始图像进行不重叠分块,视每个图像块为一个样本,将图像块按列展开成一个列向量yi,所有样本的列向量并列组合成联合矩阵 3)将每个样本yi重构为,使=D×αi; 2.3 图像质量评价 对重构图像的质量评价可分为客观评价和主观评价,客观评价是以符合人眼视觉特性的计算模型给出量化指标来进行评价,主观评价是以人的主观感知来打分.本文分别采用PSNR和SSIM两种客观评价准则来评估字典的重建能力. 1)峰值信噪比 PSNR是使用最广泛的质量评价方法,其计算公式为: 其中n为每像素的比特数,一般取8,SMSE为原始图像与重构图像的均方误差.QPSNR值越大表明重建质量越高. 2)结构相似性索引测量 SSIM表示了原始图像与重建图像的结构相似程度,其计算公式为: 式(9)中μX、μY、σX、σY分别为图像矩阵X和Y的均值和方差,σXY为图像矩阵X和矩阵Y的协方差,C1、C2、C3为常数.QSSIM取值介于0和1之间,值越大表明重建质量越高. 3.1 实验过程 SPAMS是Julien Mairal(INRIA)开发的稀疏建模工具箱,可以解决各类稀疏优化问题,如矩阵分解和字典学习等. 使用该工具箱中的ODL算法来研究字典D的影响因素(训练字典图像数量、取块大小[15]、字典列数、取块步长).实验数据采用的是CMU_PIE_Face数据库中大小为32×32的人脸图像,其中该数据库包括68位志愿者在不同光照、姿态、表情的11 560张面部图像.假设X为训练集图像按取块大小重新排列后的联合矩阵,X1为原始图像,X2为稀疏表示所得图像,实验步骤如下: 1)确定实验所需取块大小,按取块大小获得训练集图像的联合矩阵X; 2)设置字典学习的参数值,包含字典列数、迭代次数等; 3)求得联合矩阵X的稀疏字典D; 4)求得原始图像矩阵X1的稀疏系数α; 5)通过字典D和稀疏系数α,重构得到稀疏表示图像矩阵X2; 6)计算X1与X2的QPSNR和QSSIM值,以此来评估字典D的质量. 其中步骤3中的稀疏字典D是通过对联合矩阵X中图像块用ODL算法直接训练所得,并没有对其先进行特征提取;步骤4中求取稀疏系数是用SPAMS中的Lasso函数;步骤5中稀疏表示图像X2的重构是按2.2节中的重构方法所得. 本实验分四个阶段对字典D的影响因素进行研究:第一阶段是对图像数量的研究,图像数量以步长为10从10递增到2 000,然后每组数量的取块大小分别采用6、8,并固定字典D的列数为512,通过两段曲线来研究图像数量对字典的影响;第二阶段是对取块大小的研究,取块大小以步长为1从3递增到8,然后每组取块大小的字典列数分别采用128、256、512,并固定训练图像数量为第一阶段的最佳图像数量,通过三段曲线来研究取块大小对字典的影响;第三阶段是对字典D列数的研究,列数以步长为8从128递增到1 024,然后固定图像数量为第一阶段的最佳值,通过取块大小分别为6、8的两段曲线来研究字典列数对字典的影响;第四阶段是对取块步长的研究,取块步长以步长为1从1递增到8,然后每组的取块大小分别采用6、8,并固定训练图像数量和字典列数为前几阶段的最佳值,通过两段曲线来研究取块步长对字典的影响. 3.2 实验结果分析 3.2.1 图像数量对字典的影响分析第一阶段的实验结果如图1所示,图1(a)中随着训练图像数量的增加,QPSNR值也逐渐增大,并在数量为500后趋于平稳,图1(b)中的QSSIM值也有相同的趋势,不同的是在数量为100时就开始趋于平稳.综合两个质量评价准则,选取本实验的最佳训练图像数量为500. 图1 图像数量与(a)QPSNR和(b)QSSIM的关系Fig.1Relationship between the number of images and(a)QPSNRand(b)QSSIM 3.2.2 图像取块大小对字典的影响分析第二阶段的实验结果如图2所示,由第一阶段所得的最佳训练图像数量500作为本阶段的训练数量,选取了字典列数分别为128、256和512的三条曲线来研究取块大小与误差的关系,由图2可以看出,随着取块大小的递增,质量评价值不断在下降,三条曲线均在取块大小为3时,QPSNR和QSSIM处于最高值,但取块大小为3时,所得图像块的信息太少,笔者认为不适合做取块大小,因此,选取结果次优的取块大小为4作为本实验的最佳值. 图2 取块大小与(a)QPSNR和(b)QSSIM的关系Fig.2Relationship between patch size and(a)QPSNRand(b)QSSIM 3.2.3 字典列数取值对字典的影响分析第三阶段的实验结果如图3所示,由图3可知,随着字典列数的不断增加,图3(a)中的QPSNR和图3(b)中的QSSIM值都在不断增大,最后几乎趋于平稳.但是字典列数越大,字典学习时间就越长且计算越复杂,综合图3中两个准则的趋势变化和时间考虑,当字典列数为512时,所得字典能更好地表示图像. 3.2.4 图像取块步长对字典的影响分析第四阶段的实验结果如图4所示,由前三阶段所得的实验结果分析,本阶段选取图像数量500,字典列数为512来进行实验,并设置取块大小为6、8来研究取块步长与误差的关系,分别由图4(a)和图4(b)可以得出,两条曲线均在取块步长为2时,质量评价指标达到最大,因此,取块步长为2时,训练所得的字典效果最佳. 图3 字典列数与(a)QPSNR和(b)QSSIM的关系Fig.3Relationship between dictionary columns and(a)QPSNRand(b)QSSIM 图4 取块步长与与(a)QPSNR和(b)QSSIM的关系Fig.4Relationship between patch step and(a)QPSNRand(b)QSSIM 为了进一步说明各影响因子对字典的影响,训练图像、取块大小、字典列数这3种因子采取不同参数值时的QPSNR和QSSIM对比如表1所示.由表1可知,随着训练图像数量的增加,在其他影响因子相同的情况下,质量评价指标大致呈逐渐上升然后平稳的趋势,并在图像数量为500后保持稳定;在相同训练图像数量和字典列数下,图像取块大小为4时图像重构质量最佳;随着字典列数不断增加,重构质量越来越好. 表1 取不同参数时的QPSNR和QSSIM对比Tab.1Comparison ofQPSNRandQSSIMwith different parameters 以上分别研究了影响稀疏字典的4种因素,研究结果表明在本实验所使用的数据库中,当训练图像数量为500张、取块大小为4个像素点、字典列数为512维、取块步长为2个像素点时,训练得到的稀疏字典能很好地表示该数据库中的图像.当对上述因素定量化时,字典的训练时间维持在几十秒内,因此,本算法无论是训练速度还是字典质量都可达到还原度高的重构图像,满足应用层面的需求.综上所述,本文的研究与图像的尺寸有密切关系,不同的尺寸的图像所需的参数也不尽相同,因此图像大小对字典的影响将是今后的研究方向. [1]OLSHAUSENBA,FIELDDJ.Emergenceof simple-cell receptive field properties by learning a sparse code for natural images[J].Nature,1996,381(6583):607-609. [2]LI S,YIN H,FANG L.Group-sparse representation with dictionary learning for medical image denoising and fusion[J].IEEE Transactions on Biomedical Engineering,2012,59(12):3450-3459. [3]DONG W,ZHANG L,SHI G,et al.Nonlocally centralized sparse representation for image restoration[J].IEEE Transactions on Image Processing,2013,22(4):1620-1630. [4]WAGNER A,WRIGHT J,GANESH A,et al.Toward a practical face recognition system:robust alignment and illumination by sparse representation[J].IEEE TransactionsonPatternAnalysis&Machine Intelligence,2012,34(2):372-386. [5]朱杰,杨万扣,唐振民.基于字典学习的核稀疏表示人脸识别方法[J].模式识别与人工智能,2012,25(5):859-864. ZHU J,YANG W K,TANG Z M.A dictionary learning based kernel sparse representation method for face recognition[J].PatternRecognitionandArtificial Intelligence,2012,25(5):859-864. [6]SHEKHAR S,PATEL V M,NASRABADI N M,et al. Jointsparserepresentationforrobustmultimodal biometricsrecognition[J].IEEETransactionson Pattern Analysis and Machine Intelligence,2014,36(1):113-126. [7]AHARON M,ELAD M,BRUCKSTEIN A.K-SVD:an algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing,2006,54(11):4311-4322. [8]MAIRAL J,BACH F,PONCE J,et al.Online learning for matrix factorization and sparse coding[J].Journal of Machine Learning Research,2010,11(1):19-60. [9]练秋生,石保顺,陈书贞.字典学习模型、算法及其应用研究进展[J].自动化学报,2015,41(2):240-260. LIAN Q S,SHI B S,CHEN S Z.Research advances on dictionary learning models,algorithms and applications[J].Acta Automatica Sinica,2015,41(2):240-260. [10]韦仙,康睿丹.基于降维压缩法的图像重构[J].武汉工程大学学报,2015,37(12):69-74. WEI X,KANG R D.Image reconstruction based on dimension reduction and compression technology[J]. Journal of Wuhan Institute of Technology,2015,37(12):69-74. [11]CANDES E J,TAO T.Decoding by linear programming[J].IEEETransactionsonInformationTheory,2005,51(12):4203-4215. [12]欧卫华.基于稀疏表示和非负矩阵分解的部分遮挡人脸识别研究[D].武汉:华中科技大学,2014. [13]李洪均,谢正光,胡伟,等.字典原子优化的图像稀疏表示及其应用[J].东南大学学报(自然科学版),2014(1):116-122. LI H J,XIE Z G,HU W,et al.Optimization of dictionary atoms in image sparse representations and its application[J].Journal of Southeast University(Natural Science),2014(1):116-122. [14]吴双,邱天爽,高珊.基于在线字典学习的医学图像特征提取与融合[J].中国生物医学工程学报,2014,33(3):283-288. WU S,QIU T S,GAO S.Medical image features extractionandfusionbasedononlinedictionary learning[J].Chinese Journal of Biomedical Engineering,2014,33(3):283-288. [15]霍雷刚.图像处理中的块先验理论及应用研究[D].西安:西安电子科技大学,2015. 本文编辑:陈小平 Influence Factors of Dictionary Learning in Sparse Representation ZHAO Na1,2,ZHAO Tongzhou1,2*,ZOU Chong1,2,LIU Ying1,2,CAI Dunbo1,2 We studied the key factors influencing the construction quality of dictionary matrix in sparse representation,and represented them quantitatively.The factors such as the number of images,patch size,dictionary columns and patch step were adjusted as parameters and the dictionary matrix was generated. Combined with the coefficient matrix,the original image was reconstructed,and the dictionary quality was evaluated by using the image quality assessment indices of peak signal to noise ratio and structural similarity index metric.Experiments on CMU_PIE_Face database demonstrate that the resulting dictionary has the best ability to represent the original image at image numbers of 500,patch size of 4 px,dictionary columns of 512 and patch step of 2 px.We found that the quantitative representation of key factors in sparse representation can accelerate the dictionary learning process,simplify the complexity of the model,improve the quality of the dictionary abstraction layer,and show stronger image expression. sparse representation;dictionary learning;dictionary accuracy;image quality assessment index TP391 A 10.3969/j.issn.1674⁃2869.2017.03.011 1674-2869(2017)03-0267-06 2016-12-06 国家自然科学基金(61103136);武汉工程大学创新基金(CX2015057);武汉工程大学创新基金(CX2016070) 赵娜,硕士研究生.E-mail:zhaona_wit@163.com *通讯作者:赵彤洲,硕士,副教授.E-mail:zhao_tongzhou@126.com 赵娜,赵彤洲,邹冲,等.稀疏表示中字典学习的影响因子研究[J].武汉工程大学学报,2017,39(3):267-272. ZHAO N,ZHAO T Z,ZOU C,et al.Influence factors of dictionary learning in sparse representation[J].Journal of Wuhan Institute of Technology,2017,39(3):267-272.

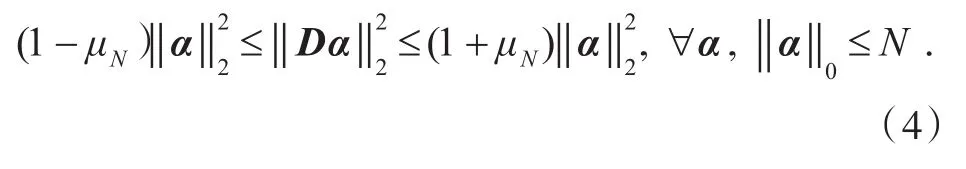
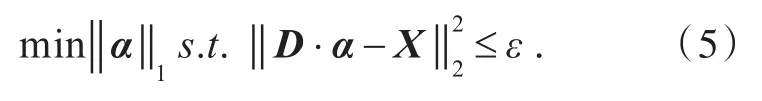
2 ODL算法
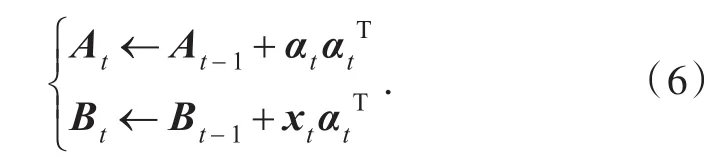


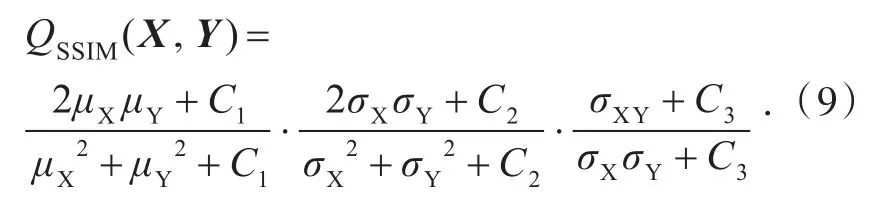
3 实验过程与结果分析





4 结语
1.School of Computer Science and Engineering,Wuhan Institute of Technology,Wuhan 430205,China;2.Hubei Key Laboratory of Intelligent Robot(Wuhan Institute of Technology),Wuhan 430205,China
猜你喜欢
小学生学习指导·高年级(2023年8期)2023-11-19 05:33:56家教世界(2023年28期)2023-11-14 10:13:50家教世界(2023年25期)2023-10-09 02:11:56成都信息工程大学学报(2021年5期)2021-12-30 06:25:30新世纪智能(数学备考)(2021年11期)2021-03-08 01:08:16中国科技博览(2016年29期)2017-04-07 09:39:35创新作文(小学版)(2016年19期)2016-08-22 05:54:08读者(2016年14期)2016-06-29 17:25:50河北科技大学学报(2015年5期)2015-03-11 16:16:37电测与仪表(2014年2期)2014-04-04 09:04:00
