
一种基于情感依存元组的简单句情感判别方法
2017-07-18 10:53:46欧阳纯萍阳小华刘志明张书卿
中文信息学报 2017年3期
周 文,欧阳纯萍,阳小华,刘志明,张书卿,饶 婕
(1. 南华大学 计算机科学与技术学院, 湖南 衡阳 421001;2. 怀化市烟草专卖局,湖南 怀化 418000)
一种基于情感依存元组的简单句情感判别方法
周 文1,2,欧阳纯萍1,阳小华1,刘志明1,张书卿1,饶 婕1
(1. 南华大学 计算机科学与技术学院, 湖南 衡阳 421001;2. 怀化市烟草专卖局,湖南 怀化 418000)
基于依存句法“动词配价”原理与组块的概念,提出以情感依存元组(EDT)作为中文情感表达的基本单位。它以句中能承载情感的几类实词作为中心词,修饰词依附于中心词,程度词和否定词依附于中心词和修饰词。该文对句子进行句法分析,在句法树和依赖关系中按规则提取情感依存元组,建立简单句情感依存元组判别模型计算情感倾向性。针对COAE2014评测公布的网络新闻语料,将该方法分别与有监督分类算法(KNN、SVM)和半监督算法(K-means)进行实验对比。结果表明,基于EDT的情感分类性能与有监督的机器学习算法相当,远高于半监督的聚类算法。
情感依存元组;情感倾向性;依存语法;句法分析
1 引言
互联网的兴盛催生了大数据时代的到来,数据已经渗透到各个行业和技术领域,成为不可或缺的生产要素。网络数据中存在大量包含用户观点、心情、态度等主观性信息的文本,对带有情感色彩的主观性文本进行分析、处理、归纳和推理叫文本情感分析[1]。文本情感分析具有重要的研究价值和应用价值,例如,对产品评论分析,可以帮助商家对产品进行改进,也可指导用户消费;对新闻评论分析,可以给企业、政府等机构提供重要的决策依据[2]。文献[1]阐述了文本情感分类的两种研究思路: 基于情感知识和基于特征分类的方法。基于特征统计的机器学习方法实现代价小,但最终获得的概念层次结构的可理解性难以达到较高的水平[3];基于预定义知识工程的方法则需要过多人工参与,实现代价高。
传统的文本挖掘方法由于不能有效运用语义信息而难以达到更高的准确度,越来越多的学者转向从计算语言学角度进行文本分析。对以微博、网络新闻为代表的社会媒体而言,简单句是它们的主要构成成分,所以要分析这类社会媒体的情感倾向性,关键在于对简单句进行情感分析。本文提出了一种结合浅层句法分析和语义分析,对简单句情感表达结构进行抽取和分析的方法。通过对中文情感的表达结构进行分析、归纳,提出以情感依存元组(emotional dependency tuple,EDT)作为情感表达的单位,并基于情感依存元组建立情感判别模型,从而实现对句子级及篇章级简单文本的情感判别。
2 相关概念
目前基于句法分析的研究大多只是借助句法构造基于机器学习的高精度句法分析程序,并没有实现从句法层面到语义层面的转换。这种对句法依存关系的笼统分析容易引入主题不相关情感噪声,为避免噪声影响,本文致力于探寻一种能有效抽取句子情感表达成分,针对情感表达结构进行精确分析,以判别句子情感倾向性的方法。情感表达结构应具有下述特征:
(1) 情感表达结构是句子的一部分,严格遵循句法规则。
(2) 每个情感表达结构以一个中心词为框架,其他成分修饰中心词,中心词为能够承载或者抒发情感的实词,如名词、动词、形容词、代词等。
(3) 情感表达结构的粒度不宜过大,粒度越大其本身的正确识别就越困难,只考虑对与情感有关的依赖关系进行分析,即情感修饰及程度和否定关系。
(4) 程度依赖决定修饰程度因子,否定依赖决定情感极性因子,两者的顺序虽对情感表达结构的情感强度有影响,但不影响情感结构的极性,在进行倾向性判别的任务时暂不细分。
(5) 修饰词对中心词的情感贡献及情感表达结构对句子的情感贡献可以采用线性组合模型计算得到。
分析发现情感表达结构与依存句法的“动词配价”理论及组块的概念存在诸多相似之处。与“动词配价”理论的区别在于情感表达结构的中心词为能够表达或承载情感的实词,即可以是产生情感的对象,也可以是情感描述的对象,不限定为动词;不同于组块理论的是情感表达结构不是按词性划分,其相当于情感功能组块。下面对句法分析与组块进行介绍。
2.1 句法分析
句法分析是根据给定的语法体系,以词法分析结果为基础,自动推导出句子的语法结构,并识别出句子所包含的语法单元和这些语法单元之间的关系。句法分析是自然语言处理的核心技术,是对语言进行深层理解的基石,同时也由于自然语言中大量歧义的存在和随着句子长度增长候选搜索树的空间过大使其成为一个难点[4-5]。目前广泛应用的语法体系有短语结构语法和依存语法。短语结构语法描述能力强,对语言学界和自然语言处理领域都产生了重要的影响,但其不能很好地理解自然语言的歧义结构。依存语法(配价语法)认为句子中的述语动词是支配其他成分的中心,而它本身却不受其他任何成分的支配,所有受支配成分都以某种依存关系从属于其支配者。
短语结构语法目前的研究集中在英文语料上,而依存语法则可直接表示词语间的关系,并侧重反映语义关系,对深层次的角色标注和信息抽取十分有利,被各国学者广泛接纳,使得对它的研究已经在多种语言中开展。在中文句法分析方面,清华大学和哈尔滨工业大学都基于依存语法分别建立各自的句法树库(SDN、CDT)。周明[6]最先从事汉语句法分析工作,采用分块的思想抽取句子中固定关系的语块进行依存分析。罗强[7]等用产生式模型进行依存分析,然后用SVM分类器训练,并在哈工大依存树上实验取得不错的效果。张莉[8]等采用句法结构提取候选特征,结合CRFs进行模型训练抽取评价对象。本文沿用了依存语法体系,认为句子的情感表达结构符合情感表达结构特征的句法树中的子树,子树内部各节点符合配价语法规则。
2.2 组块
在文本情感分析时,有时我们并不需要实现完全句法分析,可只进行浅层句法分析以降低难度。浅层分析技术已广泛应用于分词、命名实体识别等任务中[9]。组块分析作为浅层句法分析的代表致力于识别句子中的某些结构相对简单、功能和意义相对重要的成分,只限于把句子解析成较小的单元[4]。浅层句法分析的结果并不是一棵完整的句法树,各个组块是完整句法树的子树,只要加上组块之间的依附关系,就可以构成完整的句法树,对语块的识别是组块分析的主要任务[10]。
Abney[11]最早提出了一个完整的组块描述体系,他把组块定义为句子中一组相邻的属于同一个s-投射的词语的集合。其后,学者们对英文组块的定义达成了共识[4]: 句子是由一些短语构成的,而每一个短语是由句法相关的词构成的,这些短语彼此不重叠、无交集,不含嵌套关系。然而,中文组块的定义尚未达成统一,最初的研究集中在对名词短语、介词短语及短语的自动界定上。文献[12]和文献[13]在Abney定义的基础上各自做了扩展,但他们都强调组块是一种语法结构,是符合一定语法功能的非递归短语,每个组块都有一个中心词,并围绕该中心词展开,以中心词作为组块的开始或结束。后者还指出组块是严格按照句法定义的,不能破坏句子的句法结构,不体现句子的语义和功能;组块的划分只依据局部的表层信息,例如词信息、词性信息等,而不考虑远距离约束及句子的整体句法结构。文献[14]则认为组块是由实词(名词、动词、形容词、数词、量词、副词等)组成的词语序列。除此之外,还有大量研究结合基于统计的方法在开放标准的语料库进行了组块识别、内部结构分析等一系列研究,并取得了不错的成绩。
本文综合了上述几种中文组块的定义,认为组块是围绕中心词展开的实词序列,严格按照句法定义,不能破坏其内部的句法结构。同时将情感表达结构理解为具有情感表达功能的组块。
2.3 情感依存元组
句子中词语依存关系的树形表示叫作“依存树”(dependency tree),树中节点之间的关系主要有支配关系和前于关系两种。同一树枝上的上层节点支配所有下层节点,不同分支上左边的节点前于所有右边分支的节点。如句子“铁路工人学习英语语法”的依存树如图1所示。其中“学习”节点支配其他四个节点,“工人”节点和“语法”节点又分别支配“铁路”和“英语”节点,“工人”和“铁路”节点都前于“语法”和“英语”节点。

图1 句子依存树
综上所述,情感表达结构是句子组块在功能上的划分,用以表达句子情感的基本单位,是句子句法树的子树,结构内部仍遵守句法规则。如图1所示,“学习”、“工人”和“语法”可以作为中心词构成三个情感表达结构,本文将这种情感表达结构定义为情感依存元组。
定义1情感依存元组(EDT, emotional dependency tuple): 以承载情感或产生情感的实词作中心词(CW),情感修饰词(EW)依附于中心词,程度词(DW)和否定词(NW)序列修饰核心词和情感修饰词,构成的中文情感表达的基本结构。
定义2情感依存元组匹配模型: EDT=[*NW/DW][*[*NW/DW]EW]CW[*[*NW/DW]EW],每个EDT有且仅有一个中心词、若干个修饰词,每个中心词和修饰词又包含若干个程度和否定依赖关系。
情感依存元组是句子情感表达的片段,虽不是完整的句子,但其依存树中节点同样遵守句子依存树中节点的关系,中心词节点支配着其他所有修饰词和情感词节点,一般否定和程度词前于被修饰的词,完整的情感依存元组的树形表示如图2所示。
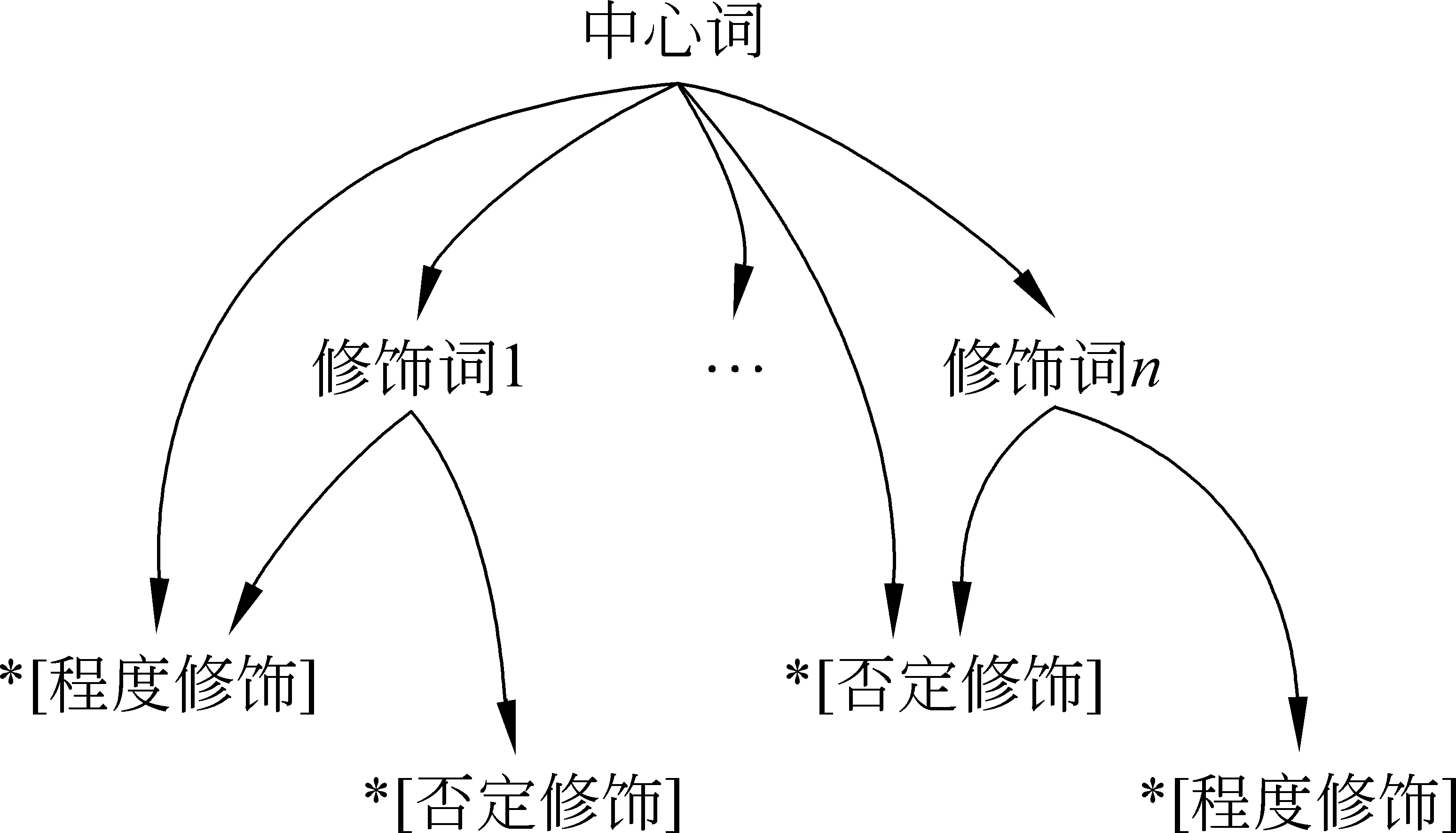
图2 完整的情感依存元组的树形表示
3 基于情感依存元组模型的情感判别
基于情感依存元组的简单句情感判别方法要先对句子进行句法分析,生成句法树和依存关系,然后根据统计创建的规则,从中抽取出情感依存元组,再基于情感依存元组对简单句建立情感判别模型进行情感倾向性分析。规则的创建与文本体裁无关,且基于简单句建立情感判别模型,使得本方法具有通用性,并在无领域区分的数据集上进行了验证。
3.1 EDT的抽取
句法分析产生的依赖关系和句法分析树是一种结构化数据,在此基础之上进行信息抽取能更准确地获取知识,提高信息抽取系统的性能。本文采用Stanford句法分析器,句法分析前先采用中科院分词器(NLPIR)进行分词,为保证句法分析的准确性,对用户词典进行了扩充,未进行停用词过滤。以句子“记者还发现很多心态较好的股民十分乐观”为例,其分词和词性标注结果为: “记者/NN 还/AD 发现/VV 很多/CD 心态/NN 较好/JJ 的/DEG股民/NN 十分/AD 乐观/VA”,对应的句法分析树和依赖关系如图3所示。

图3 句法分析树与依赖关系
准确和全面的情感依存元组抽取是建立情感分析模型的基础和关键,其具体抽取流程具体如下。
(1) 构建中心词集T: 情感依存元组的中心词应该是能引出情感动词,或者是承载情感的名词或代词,在一些主语省略的句子里,形容词也可以作为中心词;若中心词来源于主题特征集,则可只提取与主题相关的情感依存元组,这对排除其他情感因素干扰很有帮助。本文直接从句子提取符合词性要求的词作为中心词,即T={记者,发现,心态,股民}。
(2) 提纯中心词集: 对T中的每个词判断,若该词是句法分析树的叶子节点则从T中删除该词,因为叶子节点中的这些词不能单独存在,一定存在支配它们的词,即它们已经属于其他情感依存元组。遍历完之后T={发现,股民}。
(3) 提取中心词的修饰成分: 根据《现代汉语实词搭配词典》中的搭配框架和根据实验数据统计的提取规则(见表1)进行修饰结构提取。在中心词所在的兄弟节点及兄弟节点的所有子树中根据规则进行匹配,抽取中心词的修饰成分,如对中心词“股民”可提取出(股民,心态)、(股民,较好)、(股民,乐观)三对形如(中心词,修饰词)的修饰结构。
(4) 提取程度和否定依赖: 从句子的依赖关系中提取中心词和修饰词的否定依赖和程度依赖关系, 提取出依赖关系advmod(乐观-10, 十分-9)和nummod(心态-5, 很多-4)。
按上述步骤即可完成对一个简单句的情感依存元组的提取,其中中心词为“股民”的元组根据匹配模型可表示为[[很多[心态]][乐观]股民[十分[乐观]]]。

表1 中心词的修饰关系提取规则
3.2 基于EDT的情感判别模型
不考虑复杂句间的语义关系,句子的情感极性与强度由句子中包含的情感依存元组的个数和极性决定,我们建立情感分析模型对句子进行情感倾向性判别,具体算法设计如下。
(1) 对每个情感依存元组,设置中心词的原始极性PriorPolarity(CW)=1,执行以下操作。
(2) 查询情感词典获取并设置每个中心词CW的情感极性 PriorPolarity(CW),正极性为1,负极性为-1,无极性时采用原始极性。
(3) 对每个中心词获取其修饰词EW,若存在修饰词则设置其原始极性PriorPolarity(EW)=0,并为每个修饰词从情感词典中获取它的情感极性;若中心词没有支配任何修饰词,则执行步骤(5)。
(4) 初始化修饰词的每个程度和否定修饰为1,即ModifiedPolarity(EW)=1,然后从句子的依赖关系集中获取程度依赖和否定依赖,每获取一个程度依赖,则将ModifiedPolarity(EW)乘以程度系数(首先建立程度词表),每获取一个否定依赖则ModifiedPolarity(EW)=-ModifiedPolarity(EW),最终得到每个修饰词的否定程度。
(5) 对每个中心词按步骤(4)中的方法计算其否定程度ModifiedPolarity(CW)。
(6) 计算整个情感依存元组的情感极性Polarity(EDT),中心词和修饰词的极性都由原始极性和修饰极性两部分叠加而成,所以元组的情感计算公式为
其中,n为中心词的修饰词个数,P表示Polarity,MP为ModifiedPolarity,PP为PriorPolarity。式中加1是使得当没有修饰词或修饰词无情感时,由中心词的极性决定。
(7) 句子的情感值为句子各情感依存元组的情感之和,句子总情感计算公式为
其中,n为句子Sen中情感依存元组的个数。
基于情感依存元组的情感分析模型综合考虑了中心词有、无修饰词的情况,将否定和程度作为一个整体进行考虑,并可以叠加计算多层否定和程度关系,保证在极性和强度上与实际情感值一致。
4 对比试验
4.1 实验设置
实验数据采用第六届中文倾向性评测(COAE2014)“面向新闻的情感关键句抽取与判定”任务提供的评测数据,数据样本采集自各大新闻网站、博客及论坛,未划分领域,且长度、文体各异,共5 355条已人工标注倾向性的句子。先从数据集中排除了具有多义性的样本,然后随机抽取3 000条作为训练数据,剩余的2 347作为测试数据。共设置了两组实验,分别采用有监督的KNN和SVM分类算法及半监督的K-Means聚类算法与本文方法在同一数据集上进行简单句情感倾向性判别的对比实验。由于特征表示对于机器学习算法性能的影响巨大,本文采用了已实验成功的特征表示方法[17],即基于频率和频率比值的方法提取特征词和特征词性。最后采用F值(F-measure)、准确率(Precision)、召回率(Recall),以及微平均(Micro)准确率、召回率和F值作为实验结果评价指标。计算公式如下:
Micro_Precision=
Micro_Recall=
Micro_F-measure=
其中,#gold是测试集中人工标注情感为Y的样本数目;#system_correct是测试集中计算结果与人工标注结果匹配的数目;#system_proposed是测试集中计算结果为Y的样本数目;i分别表示句子的正、负情感。
4.2 基于有监督分类算法的情感判别
分类算法又称为有监督学习算法,分类器可以根据已标注类别的训练集通过训练对未知类别的样本进行分类。在有监督的机器学习算法中我们挑选了KNN和SVM两种公认效果比较好的分类算法来做对比实验。
KNN(KNearestNeighbors,K最近邻)算法是通过待分类样本周围最近的K个样本中分布数目最多类别确定待分类样本的类别,K值的选定对算法的准确性有重大影响,K值选取过大容易引入不相似样本的干扰,K值选择过小则影响算法精度。我们在训练过程中不断调整K值的大小,通过实验确定K值为21。通过为每个句子构建特征向量,以测试样本向量与每个训练样本向量间的余弦距离找出最近的K个训练样本,确定测试样本的类别。
SVM(support vector machine,支持向量机)算法,是一种基于结构风险最小化原则的分类方法,可以根据有限的样本信息在模型的复杂度和学习能力之间求得最佳折中,即获取局部最优解。SVM可将多标签分类问题分解成多个二分类问题,为提高分类效果,本文先构造一个有、无情感的二分类器,再为有情感的样本构造一个正、负倾向的二分类器。SVM训练程序是来自台湾大学林智仁教授等开发的Libsvm,通过3 000条训练数据训练出一个稳定的分类器,然后对测试数据进行分类。
4.3 基于半监督聚类算法的情感判别
有监督算法需要人工标注大量的样本作指导,而大规模标注不切实际。无监督聚类算法能在没有任何先验数据的条件下对样本进行聚类分析,但性能还有待进一步提高。在实际问题中,我们能利用少量先验知识对大量没有标注的样本数据进行无监督的聚类分析,这类算法通常被称为半监督算法[16]。本文选取K-means聚类算法在半监督条件下进行对比实验。
K-means是一种有效的基于样本间相似度的间接聚类算法,算法通过迭代将N个对象划分成K个簇,每次迭代利用各聚类中各项与“质心”相似度均值更新“质心”,使得同一簇中的对象相似度较高,不同簇中对象的相似度较低。初始质心的选择对K-Means算法的聚类效果十分关键,随机选取初始质心的聚类效果往往很差。本实验中类别标签已知为正向、负向和中性三类,K取值为3,并通过小样本先验知识确定3个初始质心来提高聚类效果。
K-means算法实现过程如下:
(1) 令K=3,从实验数据D={d1,d2,…,dn}中取出各类样本50条,先分别手工计算出各聚类质心{CP-1,CP0,CP1}。
(2) 对数据集D中的每个数据点di,计算di与CPk(k=-1,0,1)的余弦距离CosDistance(k),将数据点di划归为CosDistance(k)最大值对应的质心。
(3) 对每个质心,根据其所包含的数据点集合,重新计算得到一个新的质心。
(4) 计算新质心和原质心之间的距离,若新、旧质心的距离达到设定阈值,即质心变化不大,趋于稳定,则终止算法,否则迭代步骤(2)~(4)步,直到新旧质点达到阈值或迭代规定的次数。
(5) 输出每个文档所属分类。
4.4 实验及结果分析
基于情感依存元组的情感判别方法是基于情感知识和规则相结合的无监督方法,而SVM、KNN和K-means均属于基于统计的机器学习方法,其中SVM和KNN算法是有监督的方法,K-means算法则是半监督聚类方法。文献[2]和[18]对这几类方法做了总结,基于机器学习的分类器要比手工分类效果好得多;基于有监督学习的方法精度较高,但依赖于人工标注语料库;无监督的方法依赖于处理语料的领域范围,正确率较低。为分析基于情感依存元组的无监督方法与机器学习方法的对比效果,分别在同一组实验数据上进行了四组实验,并在实验数据上采用N-CV(cross validation)方法进行验证,其中N值取2。从正向、负向和微平均查准率、查全率及F值几个指标对四种方法进行分析,结果如表2所示。

表2 实验结果
从实验结果来看: 基于EDT的方法总体上与有监督的分类方法的效果处于同一水平,明显高于半监督的K-means聚类方法。再单独分析各个指标,EDT的准确率较高,召回率较SVM和KNN两者略低。可见,基于中文句子语法提取情感表达的结构,分析句子情感的思路是可行的,对情感依存元组的定义及(中心词、修饰词)的提取规则是正确的,迭代地对每个情感依存元组的程度和否定关系进行了细化分析提高了准确率。为进一步提高准确率,还需进一步完善情感本体库的构建。
针对本方法召回率不高的问题,分析其主要原因有情感依存元组抽取规则不够完善,句法分析和模型分析的细节处理不够精细。我们将在情感依存元组的提取规则进一步完善和句法分析的准确性方面做更加深入的研究,并可对情感依存元组的中心词做了同义替换,提高情感分类的召回率。
5 总结
本文从中文句子的语法结构出发,分析情感表达的基本结构、组织形式、成分间的关系,并将情感表达结构定义为情感依存元组(EDT)。通过建立提取情感依存元组的中心词-修饰成分的规则集,实现了情感依存元组的有效抽取。并针对简单句建立了完整的情感判别模型,对情感依存元组的否定和程度关系做迭代分析,实现了一种新的无监督简单句情感分类方法。通过与经典的聚类算法和分类算法效果进行比较,本方法分类性能基本接近有监督分类算法,远高于半监督的聚类算法,并且克服了两类机器学习方法各自的局限。
本文总结了情感依存元组的提取规则,下一步,我们将对词的语义分析进行研究,考虑研究中心词的同义替换,以提高本方法的性能,并在不同的语料集,特别是以微博、微信为代表的新兴社会媒体语料中进行交叉对比实验,验证本方法统计的显著性与普适性。同时考虑将互联网上弱监督的数据作为训练数据,将情感依存元组以不同特征组合的形式加入分类器中,进一步提升算法的分类性能。
[1] 赵妍妍, 秦兵, 刘挺.文本情感分析[J].软件学报, 2010, 21(8): 1834-1848.
[2] 周立柱, 贺宇凯, 王建勇. 情感分析研究综述[J].计算机应用,2008,28(11): 2725-2728.
[3] 贾焰, 王永恒, 杨树强.基于本体论的文本挖掘技术综述[J].计算机应用,2006,26(9): 2013-2015.
[4] 李业刚, 黄河燕.汉语组块分析研究综述[J].中文信息学报,2013(3): 1-8.
[5] 吴伟成, 周俊生, 曲维光. 基于统计学习模型的句法分析方法综述[J].中文信息学报,2013(3): 9-19.
[6] Zhou M. A block-based robust dependency parser for unrestricted Chinese text [C]//Proceedings of 2nd Chinese Language Processing Work shop, ACL. 2000: 224-30.
[7] 罗强, 奚建清. 一种结合SVM学习的产生式依存分析方法[J]. 中文信息学报,2007,21(4), 21-26。
[8] 张莉, 钱玲飞, 许鑫. 基于核心句及句法关系的评价对象抽取[J].中文信息学报,2011,25(3): 23-29.
[9] 刘挺, 马金山. 汉语自动句法分析的理论与方法[J]. 中文信息学报,2009,11(2),100-112.
[10] 孙宏林, 俞士汶. 浅层句法分析方法概述[J].当代语言学,2000,2(2)74-83.
[11] Berwiek R, Abney S , Carol T, eds. Principle-based parsing[M]. Dordrecnt: Kluwer Academic Publishers, 1991: 257-278.
[12] 李素建, 刘群, 白硕. 统计和规则相结合的汉语组块分析[J]. 计算机研究与发展,2002,39(4): 385-391.
[13] 孙广路. 基于词聚类特征的统计中文组块分析模型[J].电子学报,2008,36(12): 2450-2454.
[14] 张昱琪, 周强. 汉语基本短语的自动识别[J].中文信息学报,2002,16(6): 1-8.
[15] 肖宇, 于剑. 基于近邻传播算法的半监督聚类[J]. 软件学报,2008, 19(11): 2803-2813.
[16] 欧阳纯萍, 阳小华, 雷龙艳. 多策略中文微博细粒度情绪分析研究[J]. 北京大学学报(自然科学版), 2014,50(1): 67-72.
[17] 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1): 73-83.
ASimple-sentenceSentimentClassificationMethodBasedonEmotionalDependencyTuples
ZHOU Wen1,2, OUYANG Chunping1, YANG Xiaohua1, LIU Zhiming1, ZHANG Shuqing1, RAO Jie1
(1. School of Computer Science and Technology, University of South China, Hengyang, Hunan 421001, China; 2. Huaihua Tobacco Monoply Bureau, Huaihua, Hunan 418000,China)
Based on the principle of “Verb Valency” and the dependency parsing, this paper proposes to treat the emotional dependency tuple (EDT) as the basic unit of Chinese emotional expression. An EDT consists of the core words (i.e. several selected categories of contents words expressing emotion in the sentence), the modifier attached to the core words, and the degree or negative words attached to either the core words or the modifiers. The EDTs are extracted from the parsed sentences, and the emotional dependency tuples based sentiment classification model is established. Experimented on the web news corpus released by COAE2014, the proposed method outperforms the semi-supervised algorithm(K-MEANS), producing comparable results to the supervised classification algorithms(KNN,SVM).
emotional dependency tuple; emotional tendencies; dependency syntax; parsing

周文(1988—), 硕士研究生,主要研究领域为数据挖掘、自然语言处理。

欧阳纯萍(1979—),副教授,硕士生导师,主要研究领域为命名实体识别、自然语言处理。

阳小华(1963—),通信作者,教授,博士生导师,主要研究领域为信息检索与知识科学。
1003-0077(2017)03-0177-07
2015-02-04定稿日期: 2016-01-05
国家自然科学基金(61402220);湖南省自然科学基金(13JJ4076);湖南省教育厅优秀青年项目(13B101);南华大学重点学科和创新团队建设基金项目
TP391
: A
猜你喜欢
电脑报(2021年14期)2021-06-28 10:46:22
作文周刊·小学一年级版(2021年48期)2021-01-04 17:51:49
疯狂英语·新悦读(2020年2期)2020-04-29 10:50:22
计算机与生活(2019年5期)2019-07-18 01:08:56
吉林大学学报(理学版)(2018年2期)2018-03-29 04:58:03
少年文艺·开心阅读作文(2018年1期)2018-01-19 22:13:47
高中生学习·高二版(2016年2期)2016-05-30 19:07:04
武汉冶金管理干部学院学报(2013年1期)2013-10-31 09:37:22
电信科学(2013年10期)2013-08-10 03:41:54
考试周刊(2013年89期)2013-04-29 00:44:03
