
汉英篇章结构平行语料库的对齐标注评估
2017-07-18 10:53:46冯文贺李艳翠周国栋
中文信息学报 2017年3期
冯文贺 ,李艳翠,任 函,周国栋
(1. 广东外语外贸大学 语言工程与计算实验室,广东 广州 510006;2. 河南科技学院 中文系,河南 新乡 453003;3. 河南科技学院 信息工程学院,河南 新乡 453003;4. 苏州大学 计算机学院,江苏 苏州 215006)
汉英篇章结构平行语料库的对齐标注评估
冯文贺1,2,李艳翠3,任 函1,周国栋4
(1. 广东外语外贸大学 语言工程与计算实验室,广东 广州 510006;2. 河南科技学院 中文系,河南 新乡 453003;3. 河南科技学院 信息工程学院,河南 新乡 453003;4. 苏州大学 计算机学院,江苏 苏州 215006)
汉英篇章结构平行语料库是为汉英翻译文本标注对齐篇章结构信息的语料库,对齐标注是其核心工作,基本原则是“结构对齐、关系对齐”。该文基于所开发的对齐标注平台,进行人工对齐标注实验,提出切分对齐、结构对齐、关系对齐、连接词对齐、关系角色与中心对齐等对齐标注任务的评估方法,并给出评估分析。实验表明,对齐标注是构建汉英篇章结构平行语料库的合理、有效工作方式。
篇章结构;平行语料库;对齐标注;结构对齐;对齐评估
1 引言
汉英篇章结构平行语料库(Chinese-English discourse treebank,CEDT)是为汉英翻译文本标注了对齐篇章结构信息的语料库[1]。例1给出了一个汉英篇章结构对齐标注文本。
例1现在,我代表国务院,A//@[条件] 向大会做政府工作报告,B@/// [目的]请予审议,C@/@[并列] 并请全国政协各位委员提出意见。D(《中国政府工作报告》,2014年)
On behalf of the State Council,1//@[条件] I now present to you the report on the work of the government2@/// [目的]for your deliberation,3@/@[并列] and I welcome comments on my report from the members of the National Committee of the Chinese People’s Political Consultative Conference (CPPCC).4
(说明: 例1中上标的字母和数字分别表明汉英小句,“/”多少表明篇章结构层次高低,篇章关系用[ ]标记,连接词用下划线标记,@标明每一个关系中心项所在位置)
可以看出,这种对齐既要求语言单位对齐,也要求语言层次结构对齐。结构对齐是CEDT的核心理念,标注了结构对齐信息的双语篇章结构语料库可以为机器翻译等提供较为直接的双语篇章结构转换知识。
现有汉英平行语料库[2-4],一般仅进行段落、句子等语言单位对齐,并不提供双语篇章结构等结构对齐信息。而现有篇章结构语料库主要面向单语(如英语[5-6]、汉语[7-9])。这些工作篇章结构体系不尽一致,也没有基于双语文本,由此,难以提供直接的汉英篇章结构转换知识。至今双语篇章结构知识资源还相当匮乏,这直接制约着篇章机器翻译等研究的进展。
结构对齐是汉英篇章结构平行语料库的关键所在,然而由于双语差异等,实践汉英篇章结构对齐标注相当有挑战性。汉英篇章结构对齐标注的可行性如何,还有待验证评估。本文对汉英篇章结构对齐标注进行实验评估研究。
2 汉英篇章结构平行语料库的对齐标注
在篇章结构模式上,CEDT采用连接依存树模式[10],这种模式融合修辞结构[11]的层次化结构和宾州篇章模式的连接词论元结构。连接依存树的主要特征: 篇章结构为层次化结构,其中叶子节点为子句,内部节点为连接词,连接词通过其层级地位表示篇章层次结构,通过其语义表示篇章关系,连接词所连接的篇章单位根据篇章整体意图区分主次,又根据语义关系区分不同关系角色。该模式已成功应用于汉语篇章结构语料库构建与分析技术研究[10-12]。
不过,CEDT并非各自独立对汉英平行语料标注篇章结构。结构对齐是CEDT的核心思想,基本原则是“结构对齐,关系对齐”,基础假设在于具有对译关系的篇章,其内部的层次结构和关系也一一对应。本质上篇章结构是一种逻辑语义结构,对于一个优质翻译文本,源语的因果、转折等逻辑语义关系必然在目的语中反映,而且关系的结构层级也会得到反映。“结构对齐、关系对齐”本质上是逻辑语义结构对齐。图1是 例1的结构对齐图。
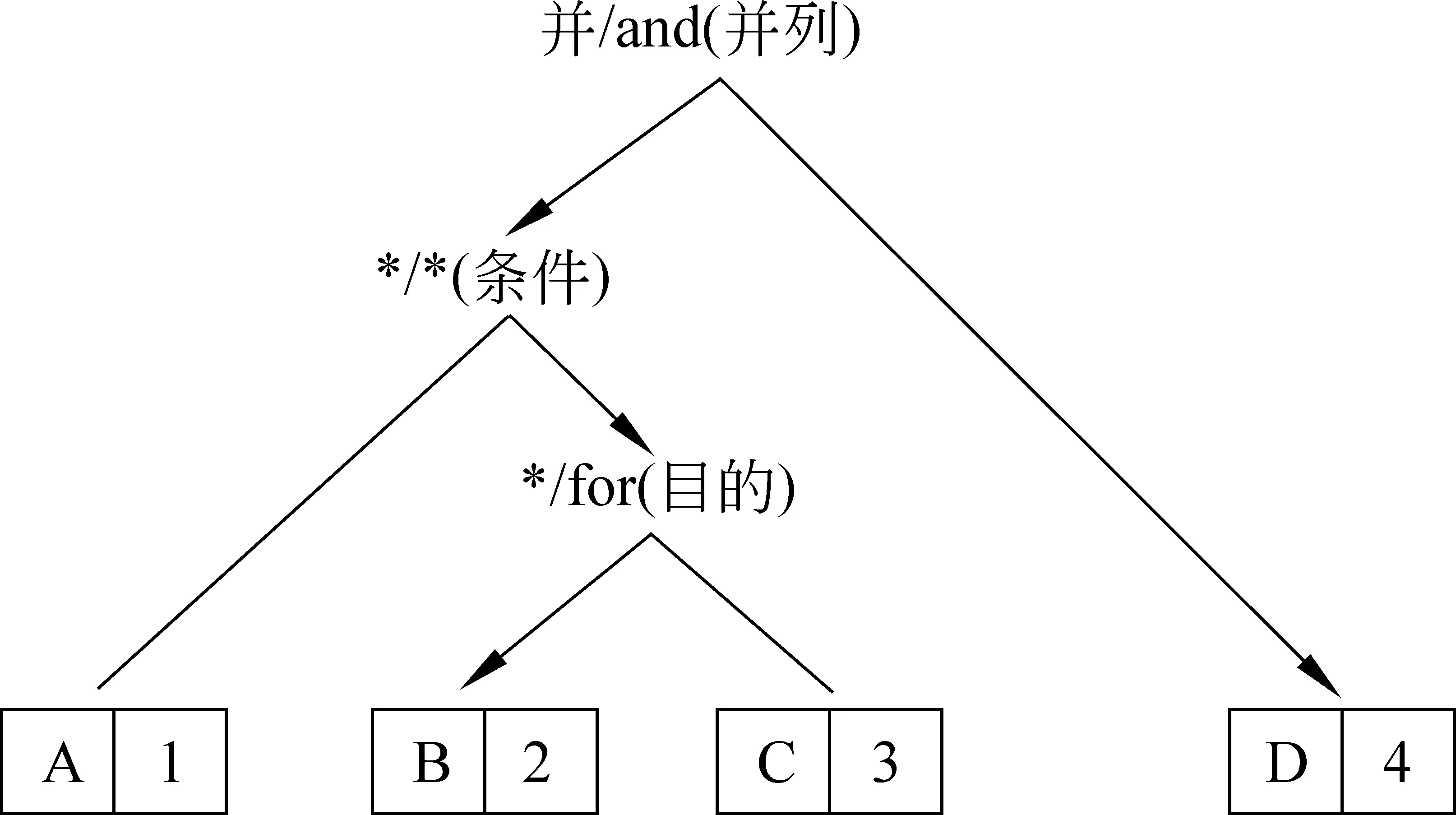
图1 例1的汉英篇章结构对齐标注实例注: 箭头指向关系中心项,“*”表示无显式连接词
基于以上思想,形成汉英篇章结构的对齐标注任务及对齐标注策略,主要包括:
(1) 切分对齐标注: 双语基本篇章单位(elementary discourse unit,简称EDU或子句)的对齐。如图1所示,例1的汉英EDU对齐为: A-1、B-2、C-3、D-4。切分对齐标注的基本策略以汉语子句分析[13]为指导标准,对齐切分英语。
(2) 结构对齐标注: 双语相应切分的层次结构对齐。如图1所示,汉语层次结构与相应英语结构一一对应,即((A (B C))D) —— ((1 (2 3))4)。层次结构对齐标注的基本策略以英语为指导标准,对齐分析汉语。
(3) 关系对齐标注: 对于双语对齐的层次结构,其相应篇章关系对齐。如图1所示,汉语的层次结构关系与英语层次结构关系一一对应,即(并列(条件A (目的B C))D) —— (并列(条件1 (目的2 3))4)。篇章关系对齐标注的基本策略以英语为指导标准,对齐标注汉语。
(4) 连接词对齐标注: 对于双语对齐的层次结构,其相应的篇章连接词对齐。如图1所示,汉语的连接词及其管辖与英语的层次结构及其管辖一一对应,即(并(*A (*B C))D) —— (and(*1 (for2 3))4)。连接词对齐标注的基本策略以双语对齐的结构层次为基础,标注双语实际相应的连接词。
(5) 关系角色对齐标注: 对于双语对齐的层次结构及关系,其相应的篇章关系角色项对齐。例1各关系的角色项对应的线性顺序位置正好一致,而在另外情况下可能不一致,如因果关系,汉语可能为前因后果,相应英语却前果后因。关系角色对齐标注的基本策略以汉语的关系角色位置分布常规为指导标准,标注双语具体关系角色是否符合这一常规。
(6) 中心对齐标注: 对于双语对齐的层次结构及关系,其中心项对齐。如图1所示,目的关系中,双语的“行为”均为中心项,而“目的”均为非中心项。中心对齐标注的基本策略以英语主从句等结构形式区分为指导,对齐标注具体关系的中心。
以上对齐标注策略中,子句对齐分析的汉语(源语)优先策略保证对齐分析始终在篇章范畴内,又反映篇章单位对应句法结构等情况;结构与关系对齐分析的英语(目的语)优先策略保证对齐结构是翻译者构造的翻译结构;连接词、关系角色及中心的对齐标注策略,保证基于结构对齐准确,反映双语的篇章语法形式差异。
CEDT的价值在于: 第一,不同于单语篇章结构分析,这种双语篇章结构对齐分析,是一种反映了翻译关系的篇章结构分析。对比例2的A、B及例1,其对于相同汉语语段,不同翻译者有不同的结构理解,由此有不同的翻译结构。本质上CEDT构造的对齐结构反映的是翻译者的理解结构(源语)与翻译结构(双语)。由此,CEDT对于翻译研究有更直接的价值。第二,不同于一般平行语料库,CEDT既有单位对齐又有结构对齐,并且基于结构对齐,标注了双语的连接词、中心等重要语篇属性。由此,CEDT可以提供更丰富的双语篇章结构翻译信息。具体而言,CEDT在篇章单位(含其主从地位)、篇章结构与关系(含关系角色顺序)、连接词等方面的汉英篇章结构翻译等研究中起基础性资源作用。
例2(A) 现在,我代表国务院,//@[条件] 向大会作政府工作报告,@///[目的]请各位代表审议,@/@ [并列]并请全国政协委员提出意见。(中国政府工作报告,2011)
On behalf of the State Council,1//@[条件] I now present to you my report on the work of the government2@///[目的]for your deliberation and approval.3@/@ [并列]I also invite the members of the National Committee of the Chinese People’s Political Consultative Conference (CPPCC) to submit comments and suggestions.4(2011译)
(B) 现在,我代表国务院,/@ [条件]向大会报告政府工作,//@[目的] 请各位代表审议,@///@[并列] 并请全国政协委员提出意见。(中国政府工作报告,2012)
On behalf of the State Council,1/@ [条件]I now present to you my report on the work of the government2//@[目的] for your deliberation and approval3@///@[并列] and for comments and suggestions from the members of the National Committee of the Chinese People’s Political Consultative Conference (CPPCC).4(2012译)
3 对齐标注实验
基于对齐标注任务和策略,开发了对齐标注平台[1],以方便大规模语料库的创建与应用。本文在标注平台上进行人工对齐标注实验,以考察这种对齐标注策略的可行性。
3.1 语料选择
标注实验语料为2014年《中国政府工作报告》(汉英双语)的前半部分,共16 000多个字/词。对于该语料,标注者A标注有效标注段落156个,共1 136个子句,816个关系;标注者B标注有效标注段落156个,共1 163个子句,819个关系。
语料选择的主要考虑: 第一,政府公文及其英译严谨规范,可以较好实现篇章结构的对齐标注;第二,语段的长度和深度具有代表性,包含7个左右子句,结构深度在3~4层,比较符合一般的段落长度和深度。
3.2 标注训练
两名中文系大四学生在项目导师指导下进行标注训练,随机从《中国政府工作报告》选择十个平行段落标注训练语料。标注训练主要由三个阶段构成: (1)导师示范标注两个段落,讲解主要标注策略及标注规范与标注平台操作;(2)学生各自完成剩余八个段落的标注;(3)两名学生各自与导师校对自行标注的八个段落,校对分三次完成,主要讨论存在问题及校正与标注策略方法等。在此基础上,两名学生各自进行实验语料标注。
3.3 对齐标注实现
对齐标注工作在对齐标注平台上实现,功能包括切分对齐标注、层次结构对齐标注、连接词对齐标注、关系对齐标注、角色分布对齐标注、中心对齐标注。对齐标注主要操作规范: (1)从上到下,从左至右,双语步步对齐分析;(2)双语都是句群结构,以汉语分析对齐到英语分析,主要方便母语为汉语的标注者的理解分析,而双语句群结构一般完全对应;(3)复句结构的对齐标注以英语分析为指导。主要考虑英语有较好形式标志,也从根本上反映翻译结构。
3.4 标注结果
标注结果保存为XML格式,双语标注结果各自独立保存。汉英双语的对齐关系可通过段落号(P ID)和段内关系号(R ID)体现。例1的部分对齐标注保存结果见图2。
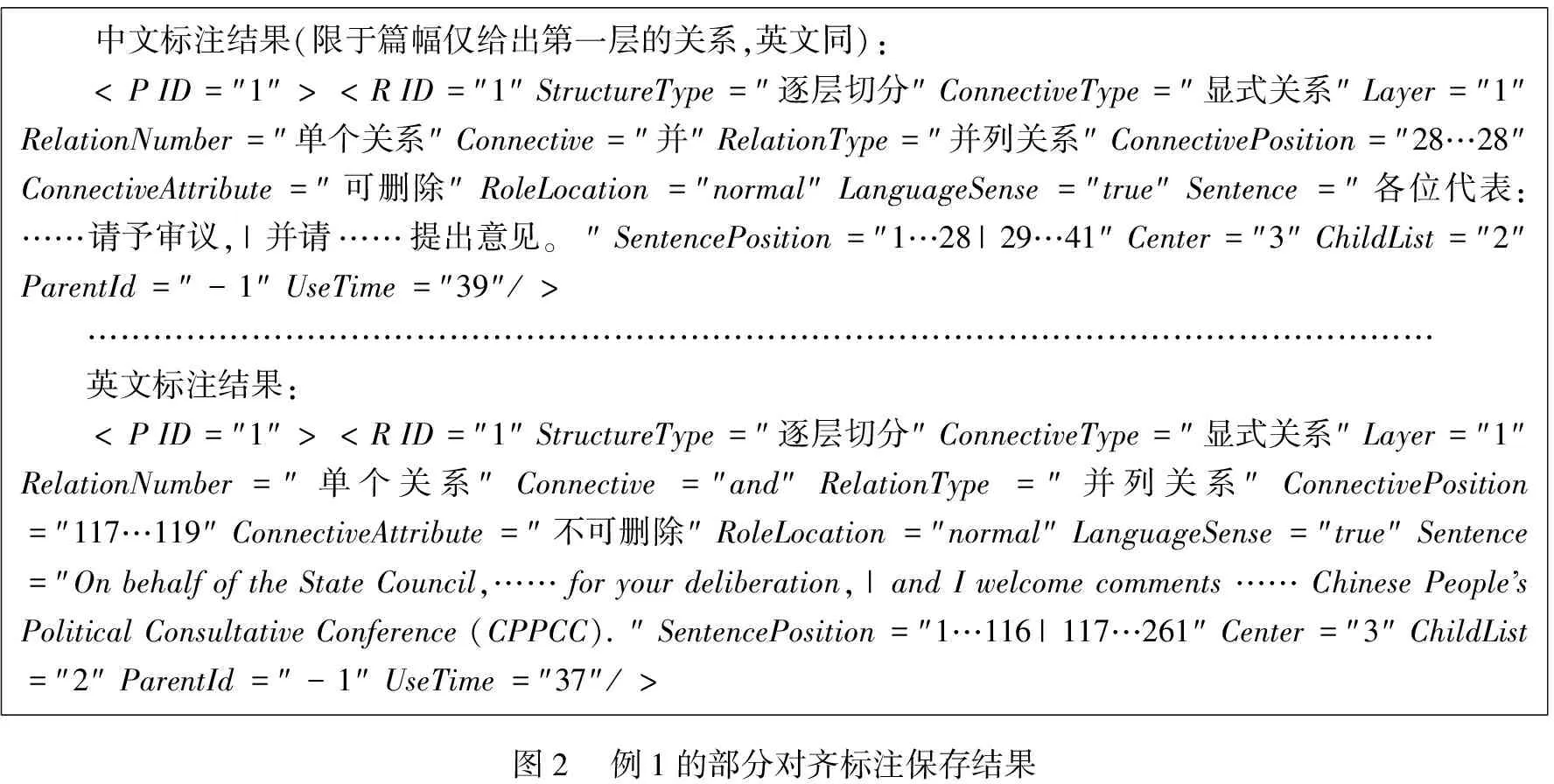
中文标注结果(限于篇幅仅给出第一层的关系,英文同):
4 对齐标注的评估与分析
标注一致性(consistency)是衡量语料库标注质量的重要标准,也是衡量标注模式可行性的关键标准。不同理论下的篇章结构语料库一致性评估内容有所差异,如针对修辞结构和宾州篇章模式的评估[5,9,13]。这些语料库均为单语,还不涉及双语结构对齐标注的评估。对CEDT的对齐标注评估,既要考虑篇章结构的独特性,又要考虑双语结构对齐的独特性。
对两名标注者A和B的共同标注语料进行标注一致性分析。根据CEDT的对齐标注任务,对双语的切分、结构、关系、连接词、关系角色、中心等对齐标注项目进行评估。其中结构对齐是基础评估,关系、连接词、关系角色、中心等的对齐评估在结构对齐基础上进行评估。在每一个评估项目上,均考虑两名标注者的汉语标注一致性、英语标注一致性、汉英混合标注一致性、汉英对齐标注一致性四个方面:
(1) 汉语标注一致性: 计算两名标注者对相同汉语文本标注的一致性。
(2) 英语标注一致性: 计算两名标注者对相同英语文本标注的一致性。
(3) 汉英混合标注一致性: 计算两名标注者对所有汉语、英语文本标注的一致性。
(4) 汉英对齐标注一致性: 计算两名标注者对相同文本的汉语标注一致且相应英语对齐文本标注也一致的一致性。
一致性评估主要计算标注一致率,即考察两名标注者标注的一致内容与所有标注内容之比,一致率=A∩B/ AUB。对于不同的对齐标注任务,其计算内容根据具体情况有所不同。
另外,也对标注效率进行了评估。
4.1 切分对齐标注
4.1.1 评估方法
切分对齐即基本篇章单位(子句)对齐。评估方法有二。
切分对齐I: 计算所有可能切分的标注一致性。汉语子句的切分位置均有标点标记,对可能作为切分标记的标点进行切分与否的一致性计算。英语的子句切分并不一定以标点作为标记切分,形式上空格(实质是任意单词或标点)均可做切分标记,对任一空格可否作为切分标记进行一致性计算。
切分对齐II: 计算不同标注者所有切分(AUB)中共同切分(A∩B)的一致性。对于句子位置SentencePosition="X1…X2|Y1…Y2",计算A、B标注切分位置相同的情况。
这里方法I考虑了所有可能的切分结果,可以反映切分的分析难度,并且该方法和自动切分过程一致,便于和自动切分结果对比。而方法II根据标注者的具体标注结果进行计算,可以准确反映标注者间的一致程度,并可统一汉英语的切分评估标准,便于跨语言比较。
4.1.2 结果与分析
表1显示,切分对齐表现出较好的一致性,“汉语一致”可达0.971(共有需要判断的标点位置700个,A、B均判断切分395个,均不切分285个,A切分B不切分7个,A不切分B切分13个)/0.968(A、B共切分408个标点,A、B均切分395个),“英语一致”可达0.992(英文共有需要判断的位置6 974个,A、B均切分514个,A、B均不切分6 403个,A切分B不切分 22个,A不切分B切分35个)/0.936(A、B共切分位置549个,A、B均切分514个),最严格情况下(“汉英对齐一致”)“切分对齐II”也可达到0.909的一致率。然而,“汉英对齐一致”还有待进一步提高,相比“汉语一致”(0.968)还有一定提高空间。汉英对齐一致切分制约着各项对齐工作的性能,其进一步提高具有重要性和必要性。

表1 汉英篇章结构的切分对齐标注一致率
值得注意,在“切分对齐I”下,“英语一致”好于“汉语一致”(0.992/0.943>0.971/0.941),而在“切分对齐II”下,“汉语一致”好于“英语一致”(0.968>0.936),这是因为在I中汉英一致性计算的基数不一致,汉语仅对有限标点符号计算,而英语却对任一空格计算,由于空格不切分的情况较多且容易判断,这就使得英语的切分一致性表现得好于汉语。
然而实际是汉语切分好于英语。这一结果可以在“切分对齐II”下得到显示(0.968>0.936),此时双语均采用同样的对齐评估标准。汉语切分对齐好于英语,是因为汉语切分有标点做标记,相对容易;而英语切分并不以标点为标记,具体切分位置容易判断错误。所以,相比“切分对齐I”,“切分对齐II”可以更准确地反映双语对齐效果差异。
可从两方面改善切分对齐标注: 第一,注意英语切分对齐标注的位置精准性。第二,进一步在汉语指导下,实现英语切分对齐,并从根本上提高汉英切分对齐一致的性能。
4.2 结构对齐标注
4.2.1 评估方法
对于结构对齐,采用三种方法进行评估。
篇章单位对齐: 计算不同标注者所标注语料中所有篇章单位的一致性。即对于一个标注切分SentencePosition=“X1…X2|Y1…Y2”,计算不同标注者所有标注切分中,任意一个切分块“X1…X2”或“Y1…Y2”之间的一致性。这种算法的依据在于,不同层级上的篇章单位首尾跨度不同,所以篇章单位的跨度一致性一定程度上可以反映篇章结构对齐。
论元部分对齐: 对于一个相同的切分位置,计算不同标注者对于该切分的左论元或右论元的一致性。即对于一个标注切分SentencePosition=“X1…X2|Y1…Y2”,计算A=“X1…X2”=B,或A=“Y1…Y2”=B。与篇章单位对齐不同之处在于,这种对齐基于一个共同切分位置(X2|Y1),比对对象要求同时是该切分的左论元(“X1…X2”)或右论元(“Y1…Y2”)。相对于篇章单位对齐,论元部分对齐要求严格一些。
论元完全对齐: 对于一个相同的切分位置,计算不同标注者对于该切分的左论元和右论元的一致性。相比论元部分对齐,这种对齐要求同一个切分位置(X2|Y1)的左论元(X1…X2)和右论元(Y1…Y2)完全一致。对于一个切分或一个关系来说,这种对齐是完全对齐。
4.2.2 结果与分析
表2显示,(1)“篇章单位对齐”一致率整体基本达到0.80以上,由于篇章单位有大有小,处于不同层级,这一效果显示汉英篇章结构对齐呈现良好一致性。

表2 汉英篇章结构的层次结构对齐标注一致率
(2) 在切分位置对齐的情况下,论元部分对齐达到更好效果,整体平均约0.90(汉语共标注关系594个,论元部分对齐551个;英语标注关系605个,论元部分对齐533个),说明切分位置的准确把握,对于结构对齐是非常有帮助的。
(3) 论元完全对齐的效果基本可以,一致率整体为0.630~0.709(汉语标注关系594个,论元完全对齐421个;英语标注关系605个,论元完全对齐381个),但还不尽如人意。说明对每个关系的管辖范围还不够精准。其原因与结构理解歧义等有关。如例3的A、B,切分虽然完全一致,但由于英语的状语管辖(On behalf of the State Council)歧义,A、B的论元完全对齐毫无一致。关于结构对齐困难见文献[14]。
(4) 各种对齐的“英语一致”整体低于“汉语一致”,原因在于汉语切分有标点符号做标记,较易统一,而英语不以标点符号作标记,准确切分位置难于确定,导致错误和不一致。
结构对齐制约进一步的关系、连接词、中心等对齐标注,还需提高结构对齐,特别是论元完全对齐的水平。可从两方面改进结构对齐标注: 第一,针对英文,提高精确结构切分水平;第二,进一步提高切分点的对齐水平,从而以对齐切分点为基础明确论元管辖。
以上评估没有考虑句群结构和复句结构的不同,一般来说复句结构对齐标注难度大,但对于翻译的指导意义更大。进一步的评估研究中,将考虑对句群和复句结构赋予不同权重。
例3(A) 现在,我代表国务院,///向大会做政府工作报告,//请予审议,/并请全国政协各位委员提出意见。(《中国政府工作报告》,2014年)
On behalf of the State Council,/// I now present to you the report on the work of the government//for your deliberation,/and I welcome comments on my report from the members of the National Committee of the Chinese People’s Political Consultative Conference (CPPCC).(2014译)
(B)现在,我代表国务院,/向大会作政府工作报告,///请予审议,//并请全国政协各位委员提出意见。
On behalf of the State Council,/I now present to you the report on the work of the government///for your deliberation,//and I welcome comments on my report from the members of the National Committee of the Chinese People’s Political Consultative Conference (CPPCC).
4.3 关系对齐标注
4.3.1 评估方法
在结构对齐(论元完全对齐)基础上,计算不同标注者关系类型*共设置并列、顺承、选择、递进、对比、因果、假设、条件、目的、推断、背景、转折、让步、解说、总分、例证、评价等共17个类,本语料涉及较多的类别主要有: 并列、解说、目的、因果、条件、评价等。的标注一致性。
4.3.2 结果与分析
表3显示,关系对齐标注整体达到较高的一致率,其中最严格的“汉英对齐一致”可达0.835(A、B标注汉英结构位置都相同的有802个,其中关系相同的有670个)。同时显示,“汉语一致”和“英语一致”的对齐情况接近(0.872|0.860)。英语关系形式(连接词)标记多,易于判断,对齐策略采用以英语为指导标准的关系对齐,评估显示这种策略非常有效。

表3 汉英篇章结构的关系对齐标注一致率
关系对齐还有一定提高空间,对齐结果显示,“英语一致”还略逊于“汉语一致”(0.860<0.872),说明英语的关系判定还有一些难点。根据分析[14],其难点在无关系词、关系词一词多义、主从复句和句内关系等情况。
4.4 连接词对齐标注
4.4.1 评估方法
连接词对齐标注评估在结构对齐(论元完全对齐)的基础上进行。从以下三个方面评估。
(1) 显隐对齐: 同一结构下,对连接词显式、隐式的标注一致性计算。
(2) 显式连接词对齐: 同一结构下,对显式连接词的具体取值一致性进行计算。
(3) 全部连接词对齐: 对于同一结构关系,对连接词的具体取值进行比对计算。
4.4.2 结果与分析
表4显示,显隐对齐标注一致率非常高。其中,汉英混合一致率达0.974(A、B标注结构位置相同的有802个,显隐关系相同的有781个)。
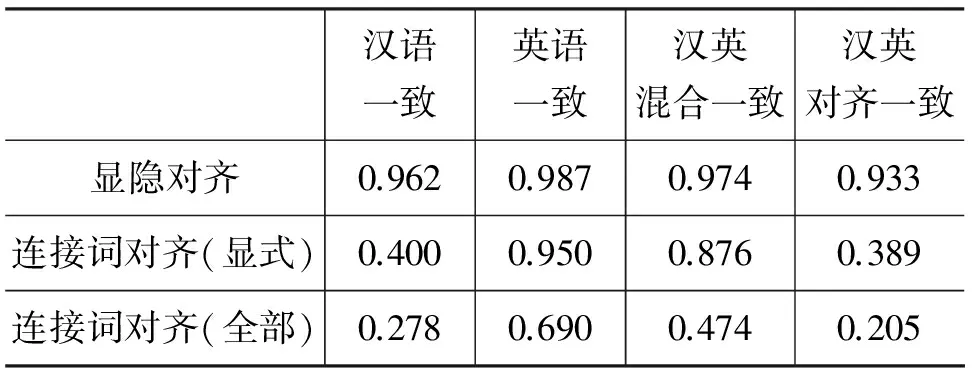
表4 汉英篇章结构的连接词对齐标注一致率
表4又显示,对于连接词对齐标注,“英语一致”明显高于“汉语一致”,特别表现在“连接词对齐(显式)”0.950 > 0.400(英语结构位置相同的显式连接词位置201个,其中连接词相同的有191个;汉语结构位置相同的显式连接词位置有32个,其中连接词相同的有13个)和“连接词对齐(全部)”上0.690>0.278(英语结构位置相同的连接词位置381个,其中连接词相同的有263个;汉语结构位置相同的连接词位置421个,其中连接词相同的有117个)。这一结果不难理解,英语显式连接词多,且对于连接词有比较共性的认识;汉语显式连接词少,且对于连接词的认识分歧较大。这也证明在关系对齐标注时以英语为指导性标准的可靠性。
结果又显示,“连接词对齐(全部)”低于“连接词对齐(显式)”,这是因为我们为隐式连接词添加了可以表达该结构关系的连接词,由于表达同一结构关系的连接词可能有多个,比如表达“并列关系”的有“并且、同时”等,这就使得对齐较难统一。
可从两方面改进连接词对齐标注: 第一,进一步明确汉语连接词的定义,从而增强汉语显式连接词的对齐标注效果;第二,规范隐式连接词的添加,减少隐式连接词添加的分歧。
4.5 关系角色与中心的对齐标注
4.5.1 评估方法
相对于一定的结构关系,对关系角色和中心的对齐标注的评估在结构对齐(论元完全对齐)的基础上进行。
关系角色对齐: 对于相同的结构,计算不同标注者对于其关系角色的分布取值(“符合常规”和“不合常规”)的标注一致性。
关系中心对齐: 对于相同的结构,计算不同标注者对于其关系中心分布位置取值[(1)中心在前;(2)中心在后;(3)前后均为中心]的标注一致性。
4.5.2 结果与分析
表5中,关系角色对齐“汉英混合一致”、“汉语一致”和“英语一致”的一致率分别为0.961、0.957和0.966,其中,A、B标注汉英结构位置相同的有802个,角色相同的有771个;汉语结构位置相同的有421个,角色相同的有403个;英语结构位置相同的有381个,角色相同的有368个。
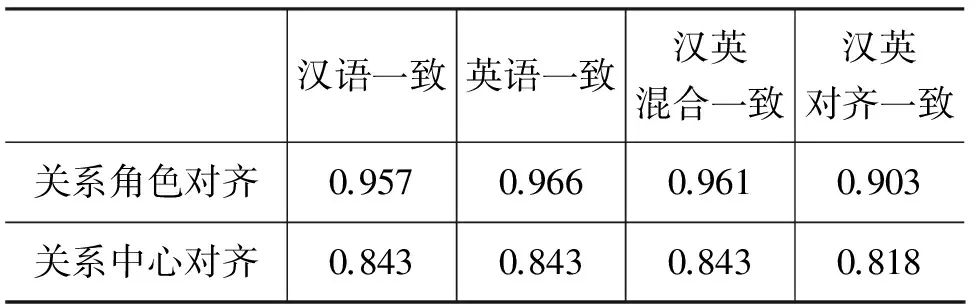
表5 汉英篇章结构的关系角色与中心对齐标注一致率
关系中心对齐“汉英混合一致”“汉语一致”“英语一致”均接近85%。其中,汉英结构位置相同的有802个,中心相同的有676个;汉语结构位置相同的有421个,中心相同的有355个;英语结构位置相同的有381个,中心相同的有321个。
表5显示,汉语和英语的“关系角色对齐”“关系中心对齐”标注一致率整体较高。同时呈现两个特点: 第一,两种对齐水平基本相同,表现出语言平衡性;第二,两种对齐一致率有差异,“关系角色对齐”高于“关系中心对齐”。前者的原因在于,这两项对齐工作均采用同步对齐标注的策略,即对于同一个关系项一般总是同时应用于汉英双语标注,所以表现出双语对齐标注一致的平衡性。后者的原因在于,两项对齐工作采用不同的对齐标注指导标准,“关系角色对齐”以汉语角色分布常规为标准,标准易于把握;而“关系中心对齐”主要以英语的主从句等形式为指导标准,对于没有显性形式的情况则难以把握。
改善中心对齐的关键是,对于英语没有形式标记的情况,提出明确的中心判定标准。
4.6 标注效率
对标注效率进行评估。根据标注语料的时间属性取值,计算每一个关系标注的耗费时间(秒/关系)。每一个关系标注,包含切分、结构、关系、连接词、角色、中心等全部标注。表6中,“汉语关系”计算只考虑汉语 关系标注所用时间; “英语关系”计算只考虑英语关系标注所用时间; “汉英混合关系”对全部汉英关系标注所用时间计算; “汉英对齐关系”
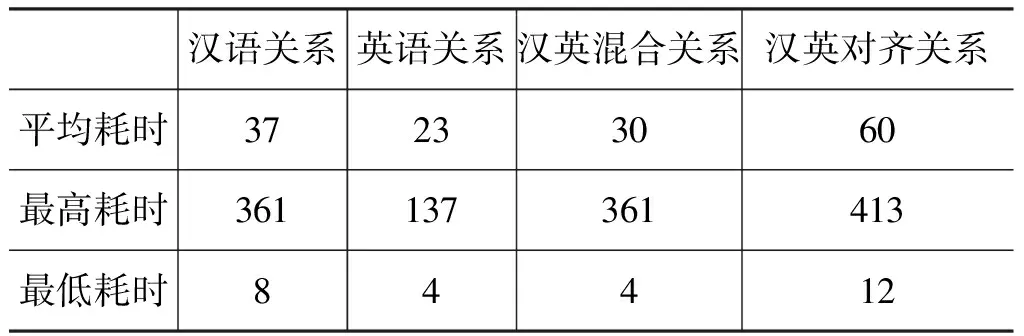
表6 汉英篇章结构标注耗时分析(秒/关系)
计算对同一个关系,标注完汉语和所对齐的英语所用的时间。
表6显示,篇章结构关系标注的效率较高,一个“汉英混合关系”的标注平均时间为30秒,一对“汉英对齐关系”标注平均耗时60秒。相比汉语,英语的标注效率更高(23<37;137<361;4<8)。这一方面与英语有较多形式标记容易判断有关;另一方面可能也与理解和标注策略有关,标注者的母语是汉语,总是倾向于从汉语理解入手,初步理解后才进行英语分析及对齐标注。
5 结语
汉英篇章结构平行语料库对基于篇章结构的机器翻译研究等起基础性作用,其研制具有重要理论和实践意义。结构对齐是汉英篇章结构平行语料库的核心工作机制,本文在“结构对齐、关系对齐”的标注策略指导下,进行了汉英篇章结构的对齐标注实验,提出了对齐标注的评估方法,并进行了实验结果分析。实验结果表明,汉英篇章结构的对齐标注在各个标注任务层面均取得较高一致率,具有可行性和可信性,也取得较高的标注效率。
下一步将对本研究所发现的一些对齐标注问题进行针对性研究,以改善对齐标注效果,还将改良评估方法,从而为最终提供良好质量的汉英篇章结构平行语料库打下基础。
[1] 冯文贺.汉英篇章结构平行语料库的对齐标注研究[J].中文信息学报,2013(6): 158-165.
[2] 柏晓静, 常宝宝, 詹卫东, 等. 构建大规模的汉英双语平行语料库[C]. 黄河燕. 机器翻译研究进展:2002年全国机器翻译研讨会论文集.北京:电子工业出版社,2002.
[3] 王克非. 双语对应语料库: 研制与应用[M].北京: 外语教学与研究出版社,2004.
[4] 刘泽权,田璐,刘超朋.《红楼梦》中英文平行语料库的创建[J]. 当代语言学, 2008, 10(4): 329-339.
[5] Carlson L, Marcu D, Okurowski M E. Building a discourse-tagged corpus in the framework of rhetorical structure theory [M]. Jan van Kuppevelt, Ronnie W.Smith (eds.),Current and New Directions in Discourse and Dialogue, Kluwer Academic Publishers,2003: 85-112.
[6] Prasad R, Dinesh N, Lee A,et al. The Penn Discourse Treebank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation,2008.
[7] 乐明. 汉语篇章修辞结构的标注研究[J]. 中文信息学报, 2008, 22(4): 19-23.
[8] ZhouY, Xue N. PDTB-style Discourse Annotation of Chinese Text[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 2012: 69-77.
[9] 张牧宇,宋原,秦兵,等.中文篇章级句间语义关系体系及标注[J].中文信息学报,2014,(2): 28-36.
[10] Li Y, Feng W, Sun J, et al. Building Chinese discourse corpus with connective-driven dependency tree structure[C]//Proceedings of EMNLP 2014, 2014: 2105-2114.
[11] Mann W C, Thompson S A. Rhetorical structure theory: toward a functional theory of text organization[J]. Text, 1988, 8(3): 243-281.
[12] 李艳翠,冯文贺,周固栋,等. 基于逗号的汉语子句识别研究[J]. 北京大学学报(自然科学版), 2013,49(1): 7-14.
[13] Marcu D,Amorrortu E,Romera M.Experiments in constructing a corpus of discourse trees[C]//Proceedings of the ACL Workshop on Standards and Tools for Discourse Tagging,1999: 48-57.
[14] 冯文贺,李艳翠,周国栋.汉英篇章结构平行语料库对齐标注的难点与对策[C]. 第十届全国机器翻译研讨会,2014: 25-35.
EvaluationforAlignmentAnnotationofChinese-EnglishDiscourseTreebank
FENG Wenhe1,2,LI Yancui3,REN Han1, ZHOU Guodong4
(1. Laboratory of Language engineering and computing, Guangdong University of Foreign Studies, Guangzhou, Guangdong 510006,China; 2. Department of Chinese Language and Literature,Henan Institute of Science and Technology, Xinxiang ,Henan 453003, China; 3. School of Information Engineering, Henan Institute of Science and Technology, Xinxiang,Henan 453003,China; 4. Department of Computer Science and Technology, Soochow University, Suzhou,Jiangsu 215006,China)
Chinese-English discourse treebank (CEDT) is a parallel corpus annotated with alignment discourse structure information for Chinese and English. Its core task is alignment annotation supervised by the principle of structure and relation alignment. With the corresponding annotation platform, we manually annotate the corpus, propose the evaluation methods for the alignment annotation and give the evaluation analysis, including segmentation, structure, relation, connective, relation role and center alignment. Experimental results show that the alignment annotation strategy is a feasible and efficient method of building CEDT.
discourse structure;parallel corpus; alignment annotation; structural alignment;alignment evaluation

冯文贺(1976—),博士,博士后,硕士生导师,主要研究领域为理论语言学、计算语言学。

李艳翠(1982—),博士,主要研究领域为计算语言学。

任函(1980—),通信作者,博士,主要研究领域为计算语言学。
1003-0077(2017)03-0086-08
2014-12-05定稿日期: 2015-07-22
教育部人文社科项目(13YJC740022、15YJC740021);河南高校哲社基础研究重大项目(2015-JCZD-022);中国博士后基金(2013M540594);国家自然科学基金(61402341,61502149,61273320);广东外语外贸大学语言工程与计算实验室2016年招标课题(LEC2016ZBKT001,LEC2016ZBKT002)
TP391
: A
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26 22:28:29
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
语言与翻译(2015年4期)2015-07-18 11:07:45
语言与翻译(2014年1期)2014-07-10 13:06:14
外语学刊(2011年4期)2011-01-22 05:34:26
当代外语研究(2010年3期)2010-03-20 14:36:38
外语学刊(2010年4期)2010-01-22 03:33:52
