
一种基于小波概要的数据流量子聚类算法
2017-06-29 12:00:34米滢
计算机应用与软件 2017年5期
米 滢
(大连职业技术学院信息工程学院 辽宁 大连 116035)
一种基于小波概要的数据流量子聚类算法
米 滢
(大连职业技术学院信息工程学院 辽宁 大连 116035)
针对传统的聚类分析技术面对长度无限且随时变化的海量级数据流无法直接使用或使用缺陷突出等问题,从数据流自身特性出发,结合小波变换与量子理论,提出一种新的数据流量子聚类算法。该算法首先采用离散小波变换,从每个数据流中动态分层地提取出其概要结构作为其相应的特征属性,同时计算出每个数据流到聚类中心的近似距离,结合量子理论估算出较优的核宽度调节参数进行类调整,最终获得一个较为理想的聚类效果。实验表明,该算法较好地解决了传统聚类方法无法良好解决的多数据流并行聚类问题,并表现出较好的聚类性能。
多数据流聚类 小波变换 量子势能
0 引 言
随着网络通信、监控、实时股票行情等领域的深入发展,数据挖掘领域中涌现出了许多连续不断且随时间变化而演变的序列型数据,面对新的研究环境,数据挖掘的研究也迎来了新的挑战。为此,研究者们纷纷提出了许多新的数据流聚类、分类、关联挖掘等应用算法。概括起来,可以分为两个方面:第一,从单条数据流出发进行挖掘,着重关注于不同时间段内数据间的隐含信息;第二,对多条数据流的挖掘,主要关注于多条数据流之间的相关性。
针对多数据流的聚类问题,文献[1]构建SPIRIT算法来挖掘多条数据流之间的相关性,该算法利用主成分分析法,采用动态更新的策略不断更新代表多数据流的隐藏变量及其权重;文献[2]引入滞后相关性增量公式来发掘多条数据流之间滞后相关性的Braid算法;文献[3]中,Yang利用概貌偏差(snapshot deviation)计算出两个不同数据流间的加权聚合信息,以此来判断各数据流间的相似性。文献[4]中,Beringer等人首先利用离散傅里叶变换对原数据流进行处理,得到其低频分量,然后利用这些低频分量的欧氏距离来评判数据流之间的相似性;文献[5]引入“按需聚类( Clustering on Demand)”的概念,提出了ADAPTIVEclustering算法,该算法将多数据流聚类划分为两个阶段:在线信息的统计与维护、离线的自适应聚类。这些算法在某种程度上解决了传统挖掘算法的一定缺陷问题,但大都忽视了数据流的遗忘特性。在数据流中,人们往往会遗忘掉比较久远的数据或者仅需了解久远数据的大略概况,而更多关注于数据流中的近期数据,以及近期数据的细节信息。另外,现存的算法大都采用活动窗口技术,且认为窗口中的数据可以重复存取,于是产生了较大存储与计算的代价需求。
针对这些问题,本文充分分析了数据流的遗忘特性,引入随时间推荐而衰减的影响因子来标注数据流中不同数据的影响力,采用离散小波变换DWT(discrete wavelet transform)适度地压缩海量数据流。然后结合量子理论,利用改进的量子聚类算法对用概要结构表示的一组并行数据流进行聚类分析。本文将该算法称为W-HAS-PEQC。通过实验对比表明,该算法不仅解决了传统聚类方法无法较好解决的多数据流并行聚类问题,而且在多数据流聚类问题上表现出良好的性能。
1 相关研究
1.1 数据的小波压缩
面对海量级规模的数据流,在对其进行分析前先进行数据压缩处理是很有必要的。在数据压缩处理中,DWT[7]技术以其优异的特性越来越受研究者们的青睐,尤其是Haar小波变换,作为DWT技术中最简单的一种,凭借着它简单、易实现且有效的优异特性得到了广泛的应用。
利用一维Haar小波变换,可以将向量D=(x1,x2,…,xn)分解表示为n个小波系数(c1,c2,…,cn),我们使用一个简单的实例来说明Haar小波变换。
例:假设某一数据序列D=(9,5,6,4,4,4,5,7)(n=8),对其进行Haar小波变换,具体过程如表1所示。

表1 序列D的Haar小波变换
本例中,小波层次由表1中的Resolution列中的l值表示,原始数据序列存储在l=3这一层次的Averages列中,将原数据序列中的数据项两两组对,求其均值记为l=2中的Averages值,即:((9+5)/2,(6+4)/2,(4+4)/2,(5+7)/2)=(7,5,4,6),经过这一变换后,原数据序列的8个数据项将被压缩成4个数据项,显然丢失了原始数据序列中的某些数据信息。为了能够重新构造出原始数据序列集,我们在保存组合后的数据对均值的同时,将该均值与原组对中第2个数据项之差也保存起来。表1中Detailcoefficients列即为数据对均值与原组对中第2个数据项之间的差值。即:(7-5,5-4,4-4,6-7)=(2,1,0,-1),迭代重复此步骤,直至层次达到l=0,最后得到的均值与Detailcoefficients列中的全部数值即组成原数据序列的小波系数(5.5,0.5,1,-1,2,1,0,-1)。
采用树形结构来表示该分解过程,如图1所示,该树称为误差树。图中节点ci(i=1,2,…,8)即为分解后的小波系数,叶子节点xi(i=1,2,…,8)为原数据序列中的数据项。以ck为根节点的子树叶节点可划分为左右两个子集合:左子树叶节点leftleavesk、右子树叶节点rightleavesk。树中从ck(或xk)节点到根节点的所有非零系数集合记为路径pathk。由误差树可知,节点ck=(ak-bk)/2,其中k=2,3,…,n,ak为leftleavesk中数据的均值,bk为rightleavesk中数据的均值,而c1则为全部数据的均值,故原数据序列xi=∑cj∈pathiδij·cj,这里δij为一符号函数:
比如x2=+5.5+0.5+1-2=5,由此便可以重构出原始数据序列集。

图1 序列D的误差树
1.2 基于参数估计的量子聚类
以粒子在量子空间中的分布为主要研究对象的量子力学在数据挖掘领域里得到了越来越多的应用,尤其是在聚类分析技术中,近年来,许多学者都开始着手研究量子聚类算法[6]的研究。
量子理论中,粒子的分布状态采用概率波函数描述,对其求解常采用有势场约束的薛定谔方程:
(1)
式中,H代表Hamilton算子,φ表示波函数,V表示势能函数,E表示算子H的相应能量特征,▽代表劈型算子,方程中包含了唯一的参数δ。由该方程可知,如果两个分布空间具有相同的势场,则其粒子的分布状态相同;如果将粒子所在的分布空间变换为一维无限深势阱的状态时,则它们将集中分布在势能等于零的某一宽度势阱内,因此该势能函数可以抽象地看成是一个源,当势能逐步减少至零时,将会有更多的粒子分布在势阱内。
反过来,由波函数φ则可以根据式(1)反推出来粒子分布的势能函数:
(2)
研究表明,高斯函数是式(1)的一个有效解,是一个能够有效代表粒子分布状态的波函数。一个高斯波包形式如下:
(3)
假设某观测样本集为X={x1,x2,…,xi,…xn}⊂Rd,其中xi=(xi1,xi2,…xid)T∈Rd,则利用式(3)可将其分布表示成一个宽度为δ的高斯波包。特殊的,如果n=1,即空间里仅有一个粒子x1时,利用上述式(2)、式(3)可得到此时的势能函数:
(4)

(5)
假设V值确定且非负,则其最小势能值为零,由式(2)可得:
(6)
至此既可以计算出样本的势能。
对样本集的聚类就相当于将样本都聚集在势能为零或者最小的样本附近,因此,势能最小的样本即为类中心。采用梯度下降法来求解,其迭代公式为:
yi(t+Δt)=yi(t)-n(t)▽V(yi(t))
(7)
其中,初始化变量为yi(0)=xi,学习速率为n(t),势能梯度为▽V。
对于算法中唯一的参数δ,我们根据高斯核宽度的参数估计法,采用式(8)来估计参数δ的值。
(8)
其中,m为样本维数,n为样本个数。这样,样本集的大小、维度等信息便隐含在了参数δ的计算中,从而将样本集潜在的结构信息隐含在了算法模型中,提高算法性能。
2 W-HAS-PEQC算法基本思想
W-HAS-PEQC算法首先动态地维护各个数据流的小波摘要,然后利用所得到的各数据流小波摘要,结合改进的量子聚类算法对其进行在线聚类分析。
2.1 数据流的小波摘要结构
遗忘特性是流数据所特有的性质,利用这一特性,算法首先利用小波变换,采用动态的方式不断抽取出各条数据流的摘要信息,具体提取过程[8]如下:
将原始流数据中的各数据项视为第0层,当数据项的数目达到m时,就对所收集的m个数据项进行压缩,形成第1层中的一个新数据项。伴随原始流数据中各数据项的不断抵达,第1层中的新数据项数目也逐渐增多,当达到某一指定值后,就对最老的M个节点进行归并形成第2层上的1个新数据项。以此类推,便可构造出原始数据流的一个小波误差树。由该误差树的构造可知,层次越高的数据项节点所包含的原始数据越久远,且对应的原始数据序列就越长,因此所含原始流数据的信息就越粗糙,遗忘的程度就越大。
2.2 节点归并
假设长度为n(n为2的幂次)的两个数据序列D1、D2,其小波分解得到的各数据节点,即小波系数为(c11,c12,…,c1n)和(c21,c22,…,c2n),则由D1与D2串联起来的子序列D1∪D2的小波系数(c1,c2,…,c2n)满足:
(9)

2.3 聚类距离
数据流之间的近似距离为:
(10)
其中,S1、S2为任意两个有q个数据节点构成的数据流,d(P1j,P2j)为S1中第j个数据节点与S2中第j个数据节点之间的近似距离,这里任意两节点之间的近似距离计算如下:
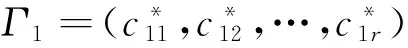
3 W-HAS-PEQC算法实现
3.1 小波摘要结构的动态维护

输入:D,α,m,M,重构误差ε,遗忘函数b;
输出:小波摘要结构。
Begini0=0,j=0;
for新到达的数据项x
{i0=i0+1;x0=x;
ifi0≥m
{P=node(x1,x2,…,xm);
iferror(P,b)<ε
//error(P,b)节点P的重构误差
{ifj=0
{i1=1;j=1;}

苗种是水产养殖的基础,鱼苗培育工作是水产养殖的基础工作。做好鱼苗培育工作,为后续养殖提供优良的苗种,是保证养殖生产顺利进行的关键因素。下面笔者就鱼苗培育过程中的关键技术要点介绍如下,供养殖户参考。
xm+1,xm+2,…⟹x1,x2,…;
//为0层上余下的数据重新编号
}
fork=1:j
{ifik≥M

iferror(P,b)<ε
{ifk=j
{ik+1=1;j=j+1}
elseik+1=ik+1+1;


}
}
}
}
end
3.2 W-HAS-PEQC聚类算法
W-HAS-PEQC算法的主要步骤如下:
(1) 动态维护小波摘要结构。假设我们仅需考虑长度为N的原始数据流序列,则在近似重构原始数据序列时,要选取最近的q个数据节点,要求其包含的原始数据项要大于或者等于N;
(2) 规范化取出的q个数据节点的小波系数,由式(3)初始化样本的分布状态,根据式(8)估算出参数δ,并根据式(7)进行算法迭代,找出类中心;
(3) 如果有新数据项到达,或者是有老数据项从数据流中删除,则更新小波系数。每次聚类的初始化均采用前一次的聚类结果进行。
4 实验结果与分析
为验证算法的有效性,本文利用Matlab编程实现上述算法,并采用人工数据集与真实数据集进行实验。其中,人工数据集是利用随机过程分别生成的4个类别互不相同的数据集组合而成,每个类均含有100条不同的数据流序列,该数据集在实验中,误差树所含的节点数目取q=4,小波系数的保留值取r=4。真实数据集采用Tickwise[10],该数据集包含了1985年5月20日到1991年4月12日美元兑瑞士法郎的实时汇率,共329 112个数据项,为计算方便,选取前262 144个数据项构成数据序列,另外为了验证并行数据流的聚类性能,我们又随机生成4个各含100条不同数据流序列的并行数据流类:
p(t)=T(t)+p′(t)
p′(t+Δt)=p′(t)+u(t)
其中,T(t)为Tickwise数据序列,p(·)代表产生每一类数据流的随机过程,u(t)为区间[-0.01,0.01]上服从均匀分布的独立随机变量。
为比较不同算法的聚类质量,本文采用文献[9]中Gavrilov等人提出的性能评估标准——“聚类相似度”作为算法评估指标。该指标客观比较了聚类的结果与数据集本身的真实类标签,相似度值越大,表示聚类结果越接近数据的真实类别,聚类效果越好。具体的计算公式如下:
(11)

(12)
1) 基于误差控制小波摘要结构的数据流重构实验
实验设置误差树第一层中的每个数据项由第0层中的128个数据项浓缩而得,且每个上层中的数据项均由其下层中对应的2个数据项浓缩而得,将一个数据节点距离最顶层数据节点的节点数目的倒数作为衰减函数。图2对比了两个数据集的实验结果,其中横轴代表控制误差ε,纵轴代表控制误差≤ε所需要的数据节点数目。

图2 小波摘要结构的重构
2) 不同聚类算法的对比
为验证文中算法,本文设置了两个对比实验算法:一个是基于小波摘要的Kmeans聚类算法,记作W-HAS-Kmeans;一个是基于离散傅里叶变换的量子聚类算法,记作DFT-PEQC。图3分别表示出了这3个算法在Tickwise数据集上的实验结果。从图3中可以看出,相比于其他两种方法,在数据节点中保留的各个不同的小波系数下,本文提出的算法取得了最好的聚类相似度值,W-HAS-Kmeans算法也取得了较好的聚类相似度,DFT-PEQC算法的聚类结果相对较差一些。

图3 不同算法的实验结果
通过实验对比可以发现,基于小波变换的数据压缩算法具有更加良好的性能,能够在最小的误差下保留原数据流的主要特征,同时该算法能够去除数据流中的某些噪声,有利于改善聚类质量。另外,相比于Kmeans聚类算法,基于量子理论的量子聚类算法能够在一定程度上克服Kmeans算法的固有缺陷,在多数据流的聚类上具有更为优异的效果。
5 结 语
本文针对多数据流的聚类问题展开探讨,设计出了一种新的数据流量子聚类算法。该算法充分考虑了数据流的遗忘特性,利用动态维护的小波摘要结构和改进的量子聚类算法,对并行的多数据流进行聚类分析。实验表明,所提方法在并行的多数据流聚类问题上表现出了更好的聚类性能。
[1]PapadimitriouS,SunJ,FaloutsosC.Streamingpatterndiscoveryinmultipletime-series[C]//Proceedingsofthe31stInternationalConferenceonVeryLargeDataBases,Trondheim,Norway,2005:697-708.
[2]DaiBR,HuangJW,YehMY,etal.Adaptiveclusteringformultipleevolvingstreams[J].IEEETransactionsonKnowledgeandDataEngineering,2006,18(9):1166-1180.
[3]YangJ.Dynamicclusteringofevolvingstreamswithasinglepass[C]//Proceedingsofthe19thInternationalConferenceonDataEngineering,Bangalore,India,2003:695-697.
[4]BeringerJ,HüllermeierE.Onlineclusteringofparalleldatastreams[J].DataandKnowledgeEngineering,2006,58(2):180-204.
[5]KeoghE,KasettyS.Ontheneedfortimeseriesdataminingbenchmarks:asurveyandempiricaldemonstration[J].DataMiningandKnowledgeDiscovery,2003,7(4):349-371.
[6] Abdulsalam H,Skillicorn D B,Martin P.Classification using streaming random forests[J].IEEE Transactions on Knowledge and Data Engineering,2011,23(1):22-36.
[7] Gilbert A C,Kotidis Y,Muthukrishnan S,et al.One-pass wavelet decompositions of data streams[J].IEEE Transactions on Knowledge and Data Engineering,2003,15(3):541-554.
[8] Chen H,Shi B,Qian J,et al.Wavelet synopsis based clustering of parallel data streams[J].Journal of Software,2010,21(4):644-658.
[9] Gavrilov M,Anguelov D,Indyk P,et al.Mining the stock market: which measure is best?[C]//Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining.New York,NY,USA:ACM Press,2000:487-496.
[10] Tickwise数据集[DS/OL].http://www-psych.stanford.edu/~andreas/Time-Series/Data/.
A DATA STREAM QUANTUM CLUSTERING ALGORITHM BASED ON WAVELET SYNOPSIS
Mi Ying
(CollegeofInformationEngineering,DalianVocationalandTechnicalCollege,Dalian116035,Liaoning,China)
In view of the traditional clustering analysis technology, faced with the problem unlimited length and always changing mass data stream can’t be directly used or the use of defects, a new data stream quantum clustering algorithm is proposed based on the characteristics of data stream, combined with the wavelet transform and quantum theory. Firstly, the discrete wavelet transform is used to extract the profile structure from each data stream as its corresponding characteristic property, and calculate the approximate distance of each data stream to the clustering center. The optimal kernel width adjustment parameters are estimated by quantum theory, and an ideal clustering effect is obtained finally. Experiments show that the proposed algorithm can solve the problem of multiple data stream parallel clustering which can’t be solved by traditional clustering method, and show good clustering performance.
Multiple data stream clustering Wavelet transform Quantum potential energy
2016-04-10。米滢,讲师,主研领域:数据挖掘。
TP391.41
A
10.3969/j.issn.1000-386x.2017.05.050
猜你喜欢
科技风(2021年19期)2021-09-07 14:04:29
汽车维修与保养(2020年11期)2020-06-09 05:42:22
甘肃科技(2020年19期)2020-03-11 09:42:42
电子制作(2019年13期)2020-01-14 03:15:32
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
电脑与电信(2018年12期)2018-03-23 02:37:36
制造技术与机床(2017年10期)2017-11-28 05:20:43
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国卫生(2014年7期)2014-11-10 02:32:54
