
面向系统吞吐量与公平性的存控调度算法综述
2017-06-29 12:00:34邱东黎施晶晶
计算机应用与软件 2017年5期
邱东黎 施晶晶
(江南计算技术研究所 江苏 无锡 214000)
面向系统吞吐量与公平性的存控调度算法综述
邱东黎 施晶晶
(江南计算技术研究所 江苏 无锡 214000)
现代处理器多使用片外存储器动态随机存储器DRAM(Dynamic Random Access Memory),但受到工艺限制,对片外存储器的存储速度一直是制约处理器性能的瓶颈。存储控制器作为处理器芯片与片外存储器的接口,使用的调度算法会对访存性能产生直接且关键的影响。针对现代DRAM的结构,以及几种典型的面向系统吞吐量与公平性的存控调度算法,对这些算法各自的优势与劣势作了简要分析,提出有待改进的地方。通过对面向系统吞吐量与公平性的存控调度算法的设计框架作一般化分析,得出新算法的设计与优化的方向。
Dram 存储控制器 多核调度算法 系统吞吐量 公平性
0 引 言
现代处理器多使用片外存储器动态随机存储器DRAM。而现代处理器的计算速度提升与访存速度提升之间的“剪刀差”,使得片外存储器访问往往成为现代处理器性能发挥瓶颈。近十年来,为了追求更高的计算速度,处理器芯片上集成的核心数越来越多,这些核心一般共享片外存储资源[1]。多个核对同一个片外存储器的同时访问还会造成竞争,降低单个核心的性能。访存调度算法作为一种通过乱序调度访存请求的方法,可以通过合理安排访存队列的调度顺序,降低核心之间的竞争,是提升核心服务质量,提升存储系统性能的有效途径之一。对于多核或众核处理器来说,其访存系统有两个重要的因素会直接影响整体性能:系统吞吐量与公平性。系统吞吐量表示系统总的工作量,是系统性能的直接体现。而公平性表示的是多个核访问存储系统的机会是否相等,一个公平的访存系统不应当使任何一个核心访问存储系统时相比于别的核心减速过多甚至是饿死。
1 DRAM结构与访存调度
现代DRAM采用由BANK(体)、ROW(行)、COLUMN(列)构成的三维地址结构[2],如图1所示。新型的存储结构高带宽存储器HBM(High Bandwidth Memory)、混合存储立方体HMC(Hybrid Memory Cube)也是由DRAM颗粒堆叠而成的,因此本文讨论的调度算法同样适用于这些存储器结构。在DRAM中,一方面,对不同体的访问可以并行进行,即该结构具有固有的并行性,开发体级并行性是隐藏访存延迟、提高存控工作效率的重要手段。另一方面,体内部是行列的二维存储阵列,对存储阵列访问时实际是对一个页,即行缓冲(ROW BUFFER),进行操作:当需要读出存储阵列中的某一行时,首先需要将整行写入到页中,即行激活;当需要将内容写入存储阵列中时,需要对页操作完毕后整行写回,即预充电。对页中内容直接操作称为列访问,其延时远小于行激活或者预充电。当访存序列流具有较好数据局部性时,可以采用页打开的策略,即只有当下一个待处理的请求所在行与页冲突时,才执行预充电指令,这样对同一行中不同列连续操作时,只执行一次行激活与预充电指令,而中间是连续的列访问指令。页命中时,除第一条访存请求外,后面的请求延迟很小,可有效降低总访存时间、提升工作效率。
存储控制器是处理器与片外存储器之间的接口,面向提升系统吞吐率、保证公平性的调度是存储控制器的主要功能之一。存储控制器将核心发出的读写请求经过一定的调度后,转换成对存储器器进行操作的命令。打乱请求队列的执行次序会改变存储器命令的个数以及次序,影响存储系统的系能,进而影响整体性能。因此对请求队列次序的优化是提升性能的有效途径之一。本文研究的访存调度算法便是通过利用现代DRAM的结构与访存序列流中的数据局部性,对请求队列进行调度,在保证多核公平性的前提下尽量缩短访存序列流的延迟,从而提升系统的性能。
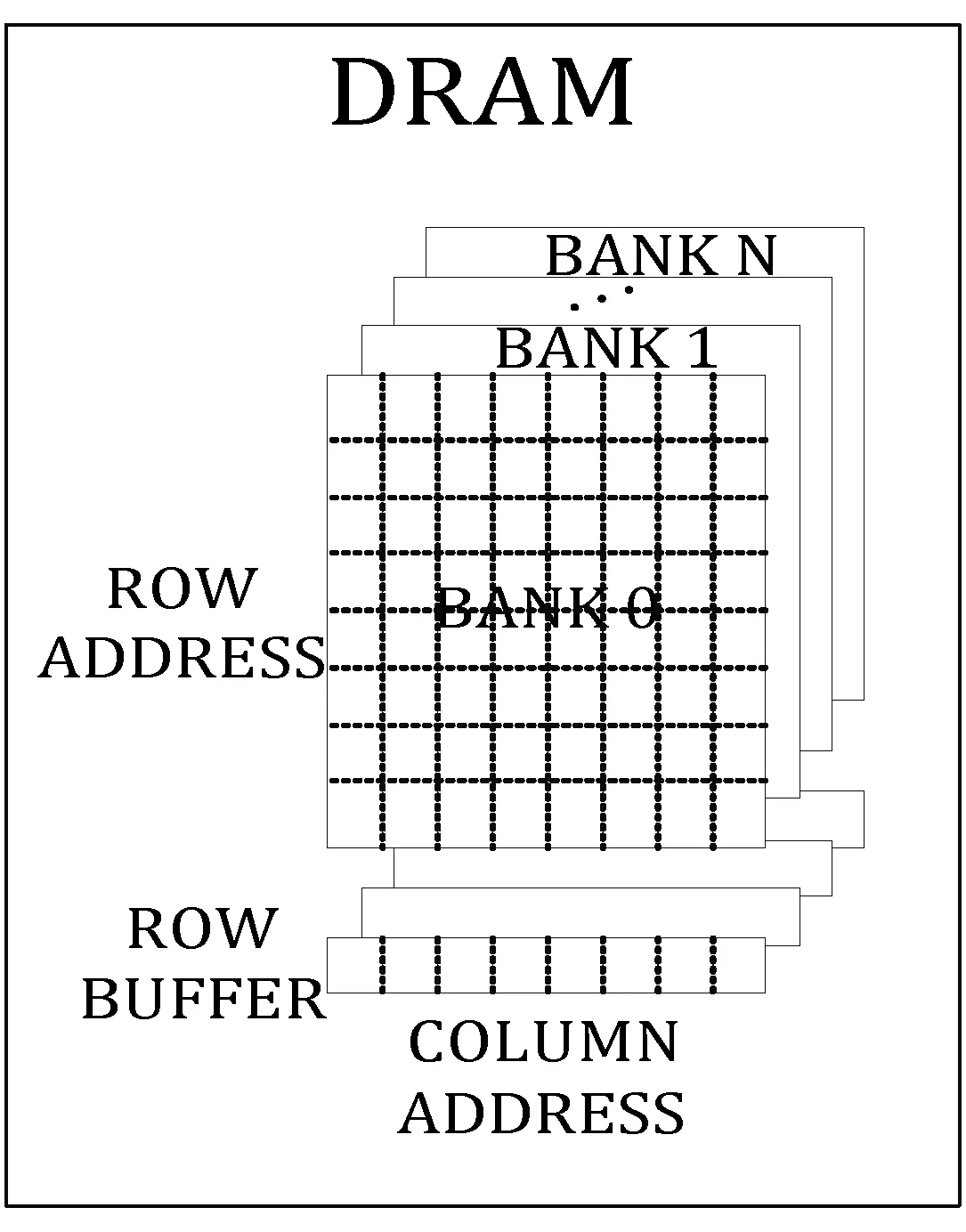
图1 现代DRAM结构
2 基础调度算法
处理访存请求最为原始的方法是FCFS(First Come First Service,先到达先服务)方法,即顺序执行,其请求优先级规则如算法1所示。该方法硬件实现代价最小,只需要一个FIFO(First In First Out/先入先出)队列即可。但是这种方法的问题也十分明显:该方法可能会破坏访存请求的数据局部性以及体级并行性,使得片外存储带宽利用率极低。
算法1 FCFS: 请求优先级
1) 老请求优先: 年龄最大的请求优先。
对于FCFS算法一个简单但有效的改进是FR-FCFS(First Ready-First Come First Service,先就绪、先到达先服务)调度算法[3],其请求优先级规则如算法2所示。其中Ready(就绪)的含义是,访存请求的目标存储位置所在行已经位于页中,并且该请求不违反任何约束条件。已经就绪的访存请求可以立即执行,且一定能页命中。这种算法考虑了DRAM内部结构特征,优先处理页命中的请求,通过对请求序列流中数据局部性的进一步挖掘,连续处理同一主存行的请求,能够有效缩短访存请求时间,增大片外存储带宽的利用率。
算法2 FR-FCFS: 请求优先级(由上到下优先级递减,下同)
1) 页命中优先: 行缓冲命中的请求优先。
2) 老请求优先: 年龄最大的请求优先。
当多核共享片外存储时,FR-FCFS会有问题:该算法不区分请求来源,会使数据局部性好的核心优先级高于局部性差的,也使访存密集型核心优先级高于计算密集型。因此虽然片外带宽利用率较高,但会造成严重的不公平,甚至饿死,使系统公平性与整体吞吐率较低。
3 多核调度算法
当存储控制器进行的访存调度从单核调度拓展到多核调度时,由于片外存储器是作为多核心的共享资源使用的,多核心访问除了增加访存请求数量外,还带来两个主要问题:
• 对于单个核心来说,其他核心对片外存储带宽的使用会加大自己原本的访存延迟,降低自身性能。
• 对于多个核心来说,要保证公平性,即外部没有事先设置不同优先级时,多个核心应当具有相同的访存机会,不应当有任何一个核心相比于其他核心减速过大。
对某个核心来说,假设其单独使用片外存储器时,访存延迟为Talone,当多核心共享片外存储器时,访存延迟为Tshared,则定义其减速比S=Tshared/Talone[4]。对于有n个核心的系统,其公平性反比于最大减速比Smax=max{Si|1≤i≤n}。由于多个核心相互干扰,有可能会降低系统总吞吐量或者造成不公平。下面按照其提出的时间顺序介绍几种多核调度算法。
3.1 等待时间公平算法
针对FR-FCFS的问题,Mutlu等人提出了等待时间公平访存调度STFM(Stall-Time Fair Memory Scheduler)算法[4]。该算法设置一个公平阈值α,当最大减速比与最小减速比的比值Smax/Smin>α时,表示公平性遭到了超过设定程度的破坏,此时对调度过程进行强制调解,使具有最大减速比的核心Tmax具有最高优先级。该算法的优先级规则如算法3所示。
算法3 STFM: 请求优先级
1) 不公平时Tmax优先: 如果Smax/Smin>α,Tmax的请求优先。
2) 页命中优先: 行缓冲命中的请求优先。
3) 老请求优先: 年龄最大的请求优先。
STFM算法中,不公平性上限α是对整个算法影响最大的参数。若α过大,则该算法退化为FR-FCFS。若α过小,则会因为过于顾及公平性使系统其它指标受损严重。
STFM算法的思路比较简明,但缺陷也比较大:
•Smax/Smin没有考虑核心的相互影响,作为公平性阈值标准还有优化空间。
• 该算法不考虑产生不公平性的原因,只当严重不公平现象产生时才处理。这种维护公平性的方法有局限性,还有优化空间。
• 该算法没有考虑强制加速一个核心对系统吞吐量的影响,因此这种维护公平性的方式可能会对系统吞吐量产生较大影响。
3.2 分批次调度算法
Mutlu等人提出了并行性敏感的分批次调度PAR-BS(Parallelism-Aware Batch Scheduling)算法[5]。该算法的核心思想有两条:(1)访存请求分批次调度;(2)维护请求的体级并行性。在程序执行过程中,通过对请求标记的方式,被标记的请求属于批次内,未被标记的请求在当前批次处理完毕后按规则划分新的批次。组建新批次时,通过Marking-Cap参数限定同一核心在同一体内的最大请求数。批次内部,体内最大请求数越小的核心次序越靠前。若体内最大请求数相同,则总请求数越小的核心次序越靠前。请求数小的核心单独访问时的延迟小,长访问延迟对请求数越小的核心影响越大。维护体级并行性是降低访存延迟的有效方式,通过本算法的核心次序可以使各个体内核心执行顺序大致相同,有效维护请求数小的核心的体级并行性,并降低其延迟。其优先级规则参见算法4。
算法4 PAR-BS: 请求优先级
1) 带标记优先: 被标记的请求优先。
2) 页命中优先: 行缓冲命中的请求优先。
3) 高次序优先: 拥有高次序的核心的请求优先。
4) 老请求优先: 年龄最大的请求优先。
该算法通过分批次确定当前阶段需要处理的有限个请求。Marking-Cap参数可以有效控制同一个核心对同一个体占用的时间,维护公平性。通过使各个核心在各个体内的优先级相同,可以使访存量越小的核心在不同体内的请求越能同时执行,维护其体级并行性。对于行局部性很差,但是体级并行性很好的核心而言,该算法在对其他核心影响较小的前提下,有效地降低其等待时间,提升了系统吞吐量与公平性。
PAR-BS算法的不足在于其分批次的方式。当批次划分完毕后,再到达的请求只能等待批次处理结束,进入下一个批次。因此,该算法有两个导致系统吞吐量降低的问题:
• 某个体在请求处理完毕后需等待时间最长的体,若批次内请求集中于某个体,而其余体的请求在批次划分完毕后才到来,会产生该体忙碌而其余体空闲的低效状态。
• 若某一核心在不同体内的少量请求由于到达时间原因被分到了两个批次,那PAR-BS不仅不能维护,反而会进一步破坏其体级并行性。
3.3 最少被服务优先算法
Kim等人提出了自适应性最少被服务核心优先访存调度ATLAS(Adaptive per-Thread Least-Attained-Service memory scheduling)算法[6],目的是针对多存控,使存控间不需大量协调就可获得较大系统吞吐量。该算法借鉴排队论中“最少获得服务优先”的思想,在不改变对片外存储带宽的使用情况下,减小多个核心总延迟,提高系统吞吐量。每经过某个设定的时长T,各存控协同统计每个核心在该时段内对片外存储器的总访问量,为各个核心设定下一个时段内的优先级。其请求优先级规则见算法5。
算法5 ATLAS: 请求优先级
1) 超时优先: 等待时间超过T的请求优先。
2) 最少被服务优先:最少获得服务的核心的请求优先。
3) 页命中优先: 行缓冲命中的请求优先。
4) 老请求优先: 年龄最大的请求优先。
该算法与PAR-BS都蕴含着“访存量小的核心优先”的思想,不同的是:(1)PAR-BS分批处理,ATLAS可以处理所有请求。(2)PAR-BS根据批次内访存量排序,ATLAS是历史访存量。(3)PAR-BS通过强制分批维护公平性,ATLAS只通过超时优先防饿死。相比于PAR-BS,ATLAS算法一般情况下系统吞吐量上升而公平性下降。
该算法另一个目标是减少存控间协调量。多存控时,PAR-BS需要在每个新的批次建立时都协调一次,而且要确定每个核心在各个体内的最大请求数,协调量过大。ATLAS通过较长时间片,以及仅协调每个核心的总访问量,减小协调信息量,提升可扩展性。
该算法不足在于不维护公平性。超时优先是防饿死的有效手段,但是饿死是极端不公平现象,即该算法对公平性的维护程度很低。而且由于最少被服务核心优先原则,访存量大的核心会被始终减速,访存量小的核心则始终加速,即该算法具有固有的不公平性。
3.4 分组调度算法
针对PAR-BS与ATLAS的问题,Kim等人提出了兼顾公平性和吞吐量的核心分组存储调度TCM(Thread Cluster Memory Scheduling)算法[7]。该算法在其执行过程中,将核心根据对片外存储带宽的使用量排序,从最小的依次累加,当达到一定阈值时,将已经累加的分为延迟敏感组(非访存密集型),剩下的分为带宽敏感组(访存密集型)。TCM算法的核心思想为:(1) 使延迟敏感组优先于带宽敏感组,以提升系统吞吐量;(2) 引入“友好度”评价标准来衡量一个核心干扰其他核心的倾向;(3) 通过“友好度”标准在带宽敏感组中阶段性地对核心优先级进行混洗,以减少核心间干扰,保证公平性。当核心行局部性好而体级并行性差时,更容易干扰其他核心,破坏公平性。因此根据核心i在所有核心中的体级并行性次序bi与行局部性次序ri,定义其“友好度”标准Nicenessi≡bi-ri。混洗方式采用插入混洗,使具有高“友好度”核心获得高优先级的几率更大。请求优先级规则如算法6所示。
算法6 TCM: 请求优先级
1) 分组优先: 延迟敏感组优先。
2) 最少被服务/混洗优先:延迟敏感组内最少被服务优先,带宽敏感组内按混洗排定优先级。
3) 页命中优先: 行缓冲命中的请求优先。
4) 老请求优先: 年龄最大的请求优先。
访存密度小的核心更需要低访存延迟,快速完成访存可以有效减少计算资源的浪费,提升系统吞吐量;访存密度大的核心更需要高访存带宽,且更容易通过占用片外存储带宽与其他核心产生干扰。TCM算法考虑不同的核心的需求,希望获得整体较优的吞吐率和公平性。
该算法有待改进之处如下:
• 当访存密集型核心与访存非密集型核心的比例发生大幅度变化,例如大量核心都是访存密集型时,该算法的分组方式会导致一定程度的固有不公平。
• 延迟敏感组中最高优先级是最小获得服务,但对多个访存量小的核心,该原则的效果会降低。延迟敏感组对低延迟需求更高,因此应提高页命中优先级,以降低延迟。
3.5 分时段优先级算法
Elhelw等人提出了基于时间的最小访存密度优先调度TB-LMI(Time-Based Least Memory Intensive scheduling)算法[8],以及改进版本自适应基于时间的最小访存密度优先调度ATB-LMI(Adaptive Time-Based Least Memory Intensive scheduling)[9]。其请求优先级规则见算法7。
算法7 TB-LMI/ATB-LMI: 请求优先级
1) 有限次页命中优先: 行缓冲命中的请求优先直到该行缓冲达到一定访问次数。
2) 最少被服务优先:最少获得服务的核心的请求优先。
3) 老请求优先: 年龄最大的请求优先。
从系统吞吐量来说,页命中优先本身可以降低访存延迟。从公平性上来说,一方面,相比于公平性遭到严重破坏时才维护的方式,有限次数页命中杜绝了单核心对页的长时间占用,对公平性维护效果更好。另一方面,有限次页命中优先级最优高,避免了最少被服务优先带来的固有不公平性。
ATB-LMI是TB-LMI的自适应性版本,其请求优先级也如算法7所示。不同之处在于ATB-LMI统计访存量的时长是变化的。在ATB-LMI中,若核心优先级经过一个时段没有发生变化,则将时段加长,否则减短。若在一个时段内,核心优先级没有变化,则表示该时段内核心的相对访存量变化不大,核心行为相对稳定。加大时段可以减少存控协调信息量,提升存控效率。若核心优先级有变化,则表示至少有一个核心行为有较大变化,此时应当加大协调量,跟踪核心行为变化,制定更合适的优先级顺序。TB-LMI与ATLAS一样,都是通过历史预测未来,当访存行为变化较大时性能会降低。ATB-LMI对访存行为变化敏感的特点能够较为有效地弥补TB-LMI的不足。
TB-LMI与ATB-LMI的关键之处在于页命中的上限次数。上限次数过高时,算法会趋近于FR-FCFS。上限次数过低时,算法会严重降低系统吞吐量。上限次数作为经验型的固定值,需要反复试验确定。相比于TCM算法,TB-LMI以及ATB-LMI对核心访存行为特征的关注度相对较低,对不同特征核心访存行为的可控程度较低,尚有可提升空间。
4 算法总结
4.1 算法对比

表1 调度算法简要对比表
对上文涉及到的调度算法的简要总结对比见表1所示。可以看出,所有乱序调度的算法都使用了页命中优先与老请求优先的规则,这两条是将FR-FCFS算法的规则作为乱序调度算法基础的原因:由于DRAM的行缓冲机制,页命中是掩盖连续请求访存延迟的最有效方式之一,相比于维护体级并行性也更容易实现。而年龄是所有请求都不相同的,因此在其他优先级都相同时可用作调度的参考。
4.2 算法框架分析
访存请求的调度顺序与其自身的三个因素相关:来源、去向与时间,对应到调度算法中也就是:所在核心、页命中情况与请求年龄。制定算法的过程实际上也就是对三个因素所带来的影响进行考虑,并通过对这些因素的控制来达到预期的效果的过程。其中,关于请求年龄多使用老请求优先(先到先服务)的原则,也可以附加考虑超时的影响;页命中情况可以直接通过查看存储器行缓冲状态确定,多使用页命中优先的原则;所在核心虽然是请求的固有属性,但如何合理制定核心优先级是个难点,也是提升系统吞吐量与公平性的重点。假设系统中有k个核心,访存请求队列中有n个请求,则n个请求的执行次序如公式1所示。其中x为请求在队列中的位置,s为核心号,r为执行次序,c为核心的优先级,h为页命中情况,t为年龄,f为调度算法。一般情况下,只关心当前r值最小的x,执行该请求;t通常直接取x值,因为请求的位置就代表了其到达次序。
r(x)=f(c(s),h(x),t(x)) (0 (1) 核心优先级与其自身的行局部性、体级并行性、访问延迟和带宽使用四个因素相关。前两者是核心请求分布的自身属性,后两者是核心访存的历史情况。算法使用前两个因素时,需要通过当前请求序列的特征制定策略;使用后两个因素时,则是通过历史预判未来的情况。就单个核心来说,好的行局部性与体级并行性都是降低访存延迟、提升访存效率的有效方式。但是考虑到多核心共享存储时,如果某个核心行局部性很好,但是体级并行性差,则会长期占用某一个体,可能会破坏公平性,以及其他核心的体级并行性,降低系统吞吐量。因此,通常体级并行性好核心优先级高,行局部性好的核心优先级低。访问延迟与带宽使用是访存的两个基本性能指标,带宽使用量小的核心往往更需要低的延迟,带宽使用量大的核心往往更需要高的带宽,而带宽使用量小的核心对于提升系统吞吐量作用更明显[6-7]。因此,一方面需要关注核心的访存延迟,防止减速过大乃至饿死;另一方面需要提高带宽使用量小的核心的优先级,以此提升系统吞吐量。综上所述,核心的优先级如公式2所示。其中,c即是式(1)中的核心优先级,r表示行局部性,b表示体级并行性,l表示延迟,w表示带宽使用量,g为核心优先级规则。一般情况下,四个自变量不会同时使用,可根据算法的目标与思路选取特定的特征进行评价即可。 c(s)=g(r(s),b(s),l(s),w(s)) (0 (2) 通过上述分析,面向系统吞吐量与公平性的访存调度算法有两个主要部分:(1)确定核心优先级;(2)确定访存请求调度顺序。两部分的各个因素以及相应的调度方法如上所述,但是其具体方法、参数以及相互次序需要试验具体确定,以取得最好效果。 在多核、众核时代,由于“存储墙”问题对系统性能的限制,以及核心竞争对公平性、系统吞吐量带来的严峻挑战,存储控制器的访存调度技术成为影响现代处理器性能的关键技术之一。本文研究了现有的面向系统吞吐量与公平性的访存调度算法,并对这些算法进行了分析,抽象出了存储调度算法的设计框架,为对新算法的设计以及优化提供了参考建议。由于现代处理器中存储系统性能问题依然严峻,如何进一步提升访存调度算法的效率,并且在一些本文涉及的算法中未重点提及的方面,诸如能耗、硬件复杂度等方面,进一步提高调度算法的可用性,依然是研究者应当认真研究的课题。 [1] 赵鹏. 多核环境下的DRAM内存分类调度算法[J]. 中国科技论文在线, 2011, 6(1): 6-9. [2] Davis B T. Modern DRAM architectures[D]. Dearborn, MI, USA: University of Michigan, 2001. [3] Rixner S, Dally W J, Kapasi U J, et al. Memory access scheduling[N]. ACM SIGARCH Computer Architecture News, 2000, 28(2):128-138. [4] Mutlu O, Moscibroda T. Stall-time fair memory access scheduling for chip multiprocessors[C]//Proceedings of the 40thAnnual IEEE/ACM International Symposium on Microarchitecture. IEEE Computer Society, 2007: 146-160. [5] Mutlu O, Moscibroda T. Parallelism-aware batch scheduling: enhancing both performance and fairness of shared DRAM systems[N]. ACM SIGARCH Computer Architecture News, 2008, 36(3): 63-74. [6] Kim Y, Han D, Mutlu O, et al. ATLAS: a scalable and high-performance scheduling algorithm for multiple memory controllers[C]//High Performance Computer Architecture (HPCA), 2010 IEEE 16thInternational Symposium on. IEEE, 2010: 1-12. [7] Kim Y, Papamichael M, Mutlu O, et al. Thread cluster memory scheduling: exploiting differences in memory access behavior[C]//Microarchitecture (MICRO), 2010 43rd Annual IEEE/ACM International Symposium on. IEEE, 2010: 65-76. [8] Elhelw A S, El-Moursy A, Fahmy H A H. Time-based least memory intensive scheduling[C]//Embedded Multicore/Manycore Systems-on-Chip (MCSoc), 2014 IEEE 8th International Symposium on. IEEE, 2014: 311-318. [9] Elhelw A S, El-Moursy A, Fahmy H A H. Adaptive time-based least memory intensive scheduling[C]//Embedded Multicore/Manycore Systems-on-Chip (MCSoC), 2015 IEEE 9thInternational Symposium on. IEEE, 2015:167-174. SUMMARIZE OF STORAGE CONTROLLER SCHEDULING ALGORITHM FOR THROUGHPUT AND FAIRNESS Qiu Dongli Shi Jingjing (JiangnanInstituteofComputerTechnology,Wuxi214000,Jiangsu,China) Modern processors use off-chip memory DRAM, but by the process limitations, off-chip memory storage speed has been the bottleneck of processor performance constraints. As the interface between the processor chip and its off-chip memory, the storage controller uses the scheduling algorithm to have a direct and critical impact on the access performance. Aiming at the structure of modern DRAM and several typical storage controller scheduling algorithms for system throughput and fairness, the advantages and disadvantages of these algorithms are briefly analyzed, and some improvements are proposed. Through the general analysis of the design framework of the storage controller scheduling algorithm for the throughput and fairness of the system, the direction of the design and optimization of the new algorithm is obtained. DRAM Storage controller Multi-core scheduling algorithm System throughput Fairness 2016-04-25。邱东黎,硕士生,主研领域:计算机体系结构。施晶晶,工程师。 TP301 A 10.3969/j.issn.1000-386x.2017.05.0475 结 语
猜你喜欢
计算机与数字工程(2023年2期)2023-06-04 06:24:12计算机应用(2019年3期)2019-07-31 12:14:01电脑与电信(2018年12期)2018-03-23 02:37:36集装箱化(2016年11期)2017-03-29 16:15:48集装箱化(2016年12期)2017-03-20 08:32:27高中生学习·高二版(2016年11期)2016-12-01 20:00:48中国卫生(2015年3期)2015-11-19 02:53:16集装箱化(2014年2期)2014-03-15 19:00:33华东理工大学学报(自然科学版)(2014年1期)2014-02-27 13:48:36计算机工程(2013年1期)2013-09-29 05:19:56
