
一种基于Spark的改进协同过滤算法研究
2017-06-29 12:00:34许智宏蒋新宇董永峰赵嘉伟
计算机应用与软件 2017年5期
许智宏 蒋新宇 董永峰 赵嘉伟
1(河北工业大学计算机科学与软件学院 天津 300401)2(河北省大数据计算重点实验室 天津 300401)
一种基于Spark的改进协同过滤算法研究
许智宏1,2蒋新宇1董永峰1,2赵嘉伟1
1(河北工业大学计算机科学与软件学院 天津 300401)2(河北省大数据计算重点实验室 天津 300401)
为提高协同过滤算法在大数据环境下的可扩展性以及在高维稀疏数据下的推荐精度,基于Spark平台实现了一种分层联合聚类协同过滤算法。利用联合聚类对数据集进行稀疏性处理并构建聚类模型,运用层次分析模型并结合评分密集度分析联合聚类模型中用户和项目潜在类别权重,由此进行项目相似度计算并构建项目最近邻居集合,完成在线推荐。通过在GroupLens提供的不同规模MovieLens数据集上实验表明,改进后的算法能够明显提高推荐的准确度,并且在分布式环境下具有良好的推荐效率和可扩展性。
协同过滤 联合聚类 层次分析模型 Spark
0 引 言
互联网的普及和快速发展为用户提供了大量的信息,满足了用户的信息需求,但用户在海量信息中如何获取对自己有用的信息成为了一个急需解决的问题,个性化推荐系统的出现使得这一问题得到改善。
常见的个性化推荐系统,如协同过滤、内容过滤和社会化推荐系统[1]等。其中,基于协同过滤的推荐系统最为成熟、有效并且应用广泛。它根据目标用户对推荐对象最近邻居的评价来预测对推荐对象的评价。通常包括:基于用户的协同过滤[2]、基于项目的协同过滤[3]。
基于项目的协同过滤推荐算法需要计算项目间相似性搜索被推荐项目的最近邻居,从而为目标用户进行评分预测和推荐。由于用户和项目数量的不断增长,协同过滤算法面临着严重的数据稀疏性和数据规模可扩展性问题。
针对数据稀疏性问题,许多研究者从不同的角度对协同过滤提出了改进方法,如文献[4]从相似度传播的角度对数据稀疏性问题进行了相关研究,但该算法的复杂度较高,时空开销较大。文献[5]通过融入社交网络好友信任关系,有效缓解了数据的稀疏性问题,文献[6]使用奇异值分解来降低评分矩阵的维数从而达到降低矩阵稀疏性的目的,但该方法计算量较大,而且降维也会导致信息缺失。通过聚类技术降低稀疏度的方法,如文献[7]首先通过k-means算法进行基于项目的聚类,然后在项目聚类的基础上计算最近邻用户全局相似度。文献[8]提出了基于双向聚类的协同过滤推荐算法,利用双向聚类平滑填充的方法去解决数据稀疏性问题。
针对传统协同过滤算法在处理大规模数据所遇到的可扩展性问题,许多研究者采用分布式计算实现协同过滤算法来改善算法的可扩展性。文献[9]将基于用户的协同过滤算法部署在Hadoop分布式处理平台上。文献[10]将改进的基于项目的协同过滤推荐算法,在Hadoop平台下实现了并行化。文献[11]提出了一种基于Hadoop平台的k-means和slope one的混合协同过滤推荐算法。文献[12]分别在Hadoop和Spark平台上实现了基于项目的协同过滤算法,并在Spark平台上获得了更高的执行效率。
本文针对传统协同过滤算法的稀疏性和可扩展性问题展开研究,在基于项目的协同过滤算法基础上,引入联合聚类、评分密集度、层次分析模型,提出了一种分层的联合聚类协同过滤算法(AHCCF),并基于Spark平台实现AHCCF算法并行化。通过基于用户维度的聚类将数据划分为不同用户族,缓解数据稀疏性对相似度计算的影响。在每个不同用户簇中计算项目的相似性,再根据联合聚类和层次分析模型计算用户簇的权重,进而得到项目的最终相似性,提高了推荐的准确性。通过Spark平台构建推荐算法,可以充分利用Spark基于RDD的内存计算优势,在并行计算阶段进行高效的数据共享,使算法能够具有良好的可扩展性和执行效率。
1 一种分层的联合聚类协同过滤算法
1.1 构建用户模型
协同过滤算法的用户模型通常是一个m×n的评分矩阵Rmn,用来表示m个用户数对n个项目的兴趣偏好。其中,用户的兴趣偏好可通过评分值来表示,如rij可用来表示用户i对项目j的评分,评分高低决定了用户对项目感兴趣程度。
1.2 项目相似性度量
项目的相似性计算,AHCCF算法主要采用皮尔森相关相似性[13],其中皮尔森相关相似性是目前采用比较广泛的度量方法。皮尔森相关系数公式如下:
(1)
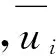
传统基于项目的协同过滤算法仅仅采用了单一的相似度来描述项目之间对于所有用户的相似程度,而没有考虑到用户所属类别的不同对相似度产生的影响。日常经验告诉我们,在一个喜好程度相近的用户群中,由于其共同喜好,用户群中的用户对感兴趣的项目评分比较密集。因此用户群感兴趣的两个项目之间的相似性能够比较真实地反映这两个项目的实际的相似性,因此可以在不同的用户群中考虑项目的相似性,最后通过用户群的权重获得项目最终的相似性。
为了改善数据稀疏性在相似度计算过程中所带来的影响,AHCCF算法在皮尔森相关系数的基础上提出了一种新的项目相似性计算方法。通过对评分矩阵R进行用户聚类得到k个用户潜在类别,在每个用户潜在类别的评分矩阵当中运用式(1)进行项目相似性计算,进而得到每个用户聚类的相似度矩阵集合simUC={simUC1,simUC2,…,simUCk},使用层次分析模型计算得到用户潜在类别权重向量WUC,根据式(2)得到最终项目之间的相似度。权重向量WUC需要通过联合聚类对原始评分矩阵分块,评估分块矩阵的评分密集度,构造分层模型计算得到。
(2)
1.2.1 联合聚类
聚类是将具有相同类别属性的内容聚集在一起的机器学习方法,是一种处理海量、稀疏数据的有效方法。联合聚类(Co-Clustering)是对于行列相关的二维矩阵数据模型[14],从行、列两个角度进行聚类。相对于传统仅考虑一维相关信息的单聚类算法,该算法能够更加有效地挖掘出数据模型当中的潜在类别。
如图1所示,AHCCF算法采用联合聚类分别对用户维和项目维聚类得到用户潜在类别、项目潜在类别,其中用户聚类UC={UC1,UC2,…,UCk}、项目聚类IC={IC1,IC2,…,ICk}。经过联合聚类,可从用户和项目两个维度上将评分矩阵划分成分块矩阵BC=[BC11,BC12,…,BC1k;…;BCk1,BCk2,BCkk]。通过联合聚类,可获取用户类别在项目维度上的评分分布情况以及项目类别在用户维度上的评分分布情况。一般来说,一个用户群在一个项目类别中的评分越密集,表示该类项目更能体现用户的兴趣偏好,计算的项目相似度越真实。因此,可通过分析分块矩阵以及项目类别矩阵的评分分布情况,来计算每个用户群在相似度计算过程中所占权重。
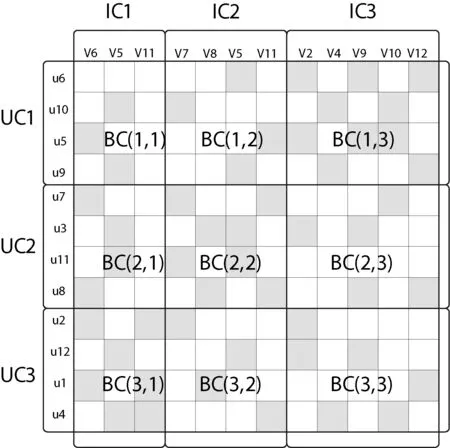
图1 联合聚类
AHCCF算法采用k-means算法,从用户和项目两个维度上进行联合聚类(CoCluster),算法具体步骤如下所示:
联合聚类CoCluster流程:
function [UCIndex, UC, ICIndex,IC] = CoCluster(data, kUCluster, kICluster)
1. UCIndex =kmeans(data, kUCluster);
//用户维聚类划分
2. for i = 1: kUCluster
//循环遍历用户维聚类
3. UCUserIds = find(UCIndex == i);
//生成用户类簇所包含的userId集
4. for j=1:length(UCUserIds)
5. uc(j,:)=data(UCUserIds(j),:);
//获取用户类簇包含的评分向量集
6. end
7. UC{i}=uc;
//保存所有用户类簇的评分向量集UC
8. end
9. data = data’;
//转置生成项目-用户矩阵
10. ICIndex =kmeans(data,kICluster);
//项目维聚类划分
11. for i = 1: kICluster
//循环遍历项目维聚类
12. ICItemIds = find(ICIndex == i);
//生成项目类簇所包含的itemId集
13. for j=1:length(ICItemIds)
14. ic(j,:)=data(ICItemIds(j),:);
//获取项目类簇包含的评分向量集
15. end
16. IC{i}=ic;
//保存所有项目类簇的评分向量集IC
17. end
1.2.2 评分密集度
分块矩阵的评分密集度(Rating Intensity)能够反映分块矩阵在项目相似度计算上的真实性,一般评分密集度越高的矩阵计算的项目相似度越真实。因此,可通过评分密集度来评价分块矩阵中的评分分布情况。评分密集度的计算方法:
ri=n/N
(3)
其中n为分块矩阵中非零评分的个数,N为分块矩阵中所有评分的个数。
根据式(3)计算基于项目维度的每个聚类IC1,IC2,…,ICk的评分密集度,并构造向量RIIC=(riIC1,riIC2,…,riICk)T,计算每个分块矩阵BC(i,j)的评分密集度,进而得到评分密集度矩阵RIBC=(αIC1,αIC2,…,αICk),其中的每个列向量为αICk=(riUC1,riUC2,…,riUCk)T,即αICk是图1中ICk列各分块矩阵的评分密集度构成的向量。
AHCCF算法,根据CoCluster的计算结果:用户聚类评分矩阵(UC)、项目聚类评分矩阵(IC)以及项目聚类所包含的项目索引矩阵(ICIndex),可计算出分块矩阵(block)和评分密集度(RatingIntensity)。之后,在AHP中便可通过评分密集度,生成相应的判断矩阵,计算用户类簇的相似度计算权重。评分密集度计算的具体步骤如下所示:
评分密集度计算流程:
function [blockIntensityMat, ICIVector]=RatingIndensity(UC, IC, ICIndex)
1. for i=1: kICluster
//项目维聚类遍历
2. ICItemIds=find(ICIndex ==i);
//查找项目簇包含的ItemIds集
3. for j=1: kUCluster
//用户维聚类遍历
4. for k=1:length(ICItemIds)
5. block(:,k)=UC{j}(:,ICItemIds(k));
//构建分块矩阵
6. end
//计算分块矩阵评分密集度矩阵
7. blockIntensityMat (j,i)=nnz(block)/numel(block);
8. end
//计算项目聚类评分密集度向量
9. ICIVector(i)=nnz(IC{i})/numel(IC{i});
10. end
1.2.3 层次分析模型
层次分析法是20世纪70年代由美国运筹学家Saaty提出的一种层次权重决策分析方法。通过建立层次分析模型,进行定量计算权重的方法。AHCCF算法通过层次分析模型,并根据1.2.2节中的项目类别评分密集度以及分块矩阵评分密集度来分析用户类别在项目相似度计算过程中所占权重。
AHCCF算法以项目聚类的各个潜在类别作为准则层,各个用户潜在类别作为方案层,通过每个项目潜在类别中的各个分块矩阵的评分密集度作比较,可以得到每个用户潜在类别在当前项目潜在类别中的权重,最后综合各项目潜在类别的权重得到用户潜在类别的权重。计算用户潜在类别权重WUC按照下面3个步骤进行:
(1) 构建层次结构模型
分层过程中将用户潜在类别权重作为目标层,项目潜在类别作为准则层,用户潜在类别作为方案层,如图2所示。

图2 层次分析结构图
(2) 构造各层次的判断矩阵
通过联合聚类过程将用户和项目划分成k个潜在类别,每个潜在类别的评分密集度分别为ri1,ri2,…,rik,把这些评分密集度两两比较,得到表示相对关系的判断矩阵:
将权重向量w右乘矩阵A,则有:
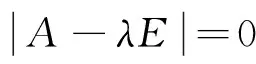
(3) 层次单排序和总排序
根据步骤(2)得到的项目潜在类别权重向量WIC和每个项目潜在类别中用户潜在类别权重矩阵WBC,依据式(4)计算得到用户潜在类别权重WUC。
WUC=WBC·WIC
(4)
在用户和项目聚类数均为3时,AHP的层次排序过程,如表1所示。
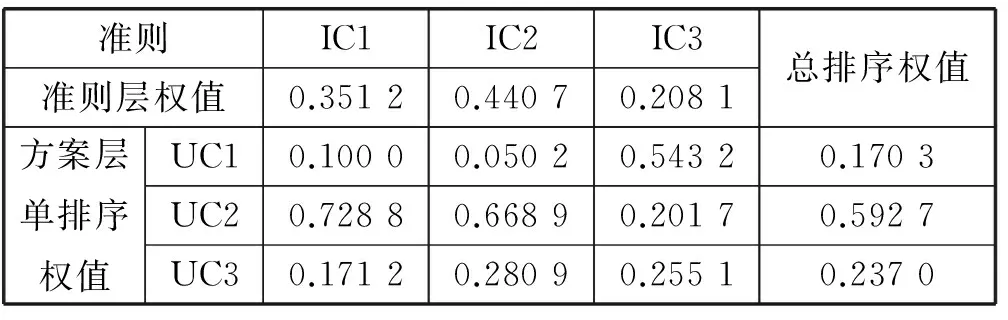
表1 AHP层次排序
AHCCF算法,采用AHP计算用户潜在类别在项目相似度计算时所占权重,权重计算的具体步骤如下所示:
用户潜在类别权重计算:
function [Wuc]=UCWeight (blockIntensityMat, ICIVector, kICluster)
1. for i=1:kICluster;
//计算每个项目类别中的每个分块矩阵权重向量
2. w=AHP(blockIntensityMat(:,i));
3. Wbc(:,i)=w;
//将每个项目类别分块矩阵权重向量放入权重矩阵
4. end
5. Wic=AHP(ICIVector)
//计算项目类别权重向量
6. Wuc= Wbc* Wic
//层次总排序,计算用户类别权重向量
1.2.4 项目相似度
AHCCF算法,经过CoCluster处理后将喜好程度相近的用户划分到同一个簇中。在该用户族中计算项目相似性,能够更加反应项目真实相似性。AHCCF算法,在CoCluster生成的每个用户类簇中,运用式(1)进行项目间相似度计算。然后,根据1.2.3节计算出的用户潜在类别权重,计算出项目的最终相似度。算法的具体步骤如下所示:
项目相似度计算:
function [sim]=computeSim (UC, kUCluster)
1. for i = 1: kUCluster
//循环遍历用户维聚类
2. uc = UC{i};
//获取某个用户类簇评分矩阵
//皮尔森相似度计算
3. for i=1:size(uc,2)
4. for j=1:size(uc,2)
5. temp=find(uc(:,i)~=0 & uc (:,j)~=0);
//查找item共同评分记录
6. Rui=data(temp,i);
//获取item i的共同评分信息
7. Ruj=data(temp,j);
//获取item j的共同评分信息
8. Ri=mean(data(:,i));
//获取item i的共同评分均值
9. Rj=mean(data(:,j));
//获取item j的共同评分均值
10. D(i,j)=(Rui-Ri)'*(Ruj-Rj)/(norm(Rui-Ri)*norm(Ruj-Rj));
11. if isnan(D(i,j))
12. D(i,j)=0;
13. end
14. D(i,j)=abs(D(i,j));
15. D(i,i)=0;
16. end
17. end
18. ucSims(i)=D
//保存每个用户类簇的相似度计算结果
19. end
20. sim=itemSim(ucSims,Wuc)
//根据用户聚类权重,计算项目最终相似度
1.3 评分预测
根据1.2节计算出的项目间相似度,找出与目标项目最相似的最近邻居集合,即为其生成一个相似度递减排列的最近邻居列表Ni。该过程分两步完成:首先,采用1.2.4节中的方式计算项目之间的相似度;其次,将最相似的前k个项目作为最近邻居集合。
经过项目相似度计算,并生成最近邻居集Ni后,可对目标用户u的未评分项目进行评分预测,计算方法如下:
(5)

1.4 算法流程
整个AHCCF算法的流程如图3所示。

图3 AHCCF算法流程图
输入:目标用户u,用户-项目评分矩阵Rm×n,聚类数k
输出:目标用户对每个项目的预测评分Pu,j,Top-N推荐
Step1 对用户-项目评分矩阵Rm×n进行用户聚类划分得到k个用户聚类UC1,UC2,…,UCk,利用式(1)计算每个聚类中项目与项目之间的相似度得到项目相似度矩阵集合simUC={simUC1,simUC2,…,simUCk}。
Step2 对用户-项目评分矩阵Rm×n进行项目聚类划分得到k个项目聚类IC1,IC2,…,ICk,根据式(3)计算每个聚类的评分密集度得到RIIC=(riIC1,riIC2,…,riICk)T。
Step3 根据步骤1和步骤2将评分矩阵Rm×n分块得到分块矩阵BC=[BC11,BC12,…,BC1k;…;BCk1,BCk2,BCkk],计算每个分块矩阵BCij的评分密集度得到评分密集度矩阵RIBC=(αIC1,αIC2,…,αICk),αICk=(riUC1,riUC2,…,riUCk)T。
Step4 利用层次分析模型(AHP)对Step2、Step3得到的RIIC和RIBC的列向量αICk构造判断矩阵并计算特征向量,得到项目潜在类别权重向量WIC=(wIC1,wIC2,…,wICk)T和每个项目潜在类别中用户潜在类别的权重向量所构成的矩阵WBC=(βIC1,βIC2,…,βICk)。
Step5 利用式(4)计算得到用户潜在类别的权重,再根据Step1计算得到的每个用户潜在类别中项目之间的相似度,利用式(2)计算得到项目间的最终相似度矩阵Sim。
Step6 在Sim中求得目标项目i的最近邻集合Ni={n1,n2,…,nk}。
Step7 根据用户u对i的最近邻集合Ni的评分值,利用式(5)预测用户u对目标项目i的评分,产生Top-N推荐列表。
2 基于Spark平台AHCCF算法并行化
AHCCF算法,在Spark分布式计算平台下实现算法的并行化。通过基于RDD的内存计算以及数据共享等技术优势,能够有效提高AHCCF算法的可扩展性和执行效率。
并行化AHCCF算法,可分为如图4所示的三个阶段。阶段一,利用基于Spark平台的k-means聚类算法[12]分别从用户维度和项目维度对数据集进行聚类划分,并生成相应的聚类模型。阶段二,对用户-项目评分记录进行聚类划分,并进行用户聚类相似度计算以及利用AHP计算用户潜在类别权重。其中AHP的特征值求解,在Spark平台下基于幂法并行求解实现。阶段三,根据用户潜在类别项目相似度以及用户潜在类别权重,计算项目最终相似度。然后,生成项目最近邻居集合,进行评分预测及推荐。

图4 基于Spark的AHCCF算法流程
AHCCF算法并行化,采用如上图所示的三个阶段来完成。在阶段一,需要将训练集中的每个用户或项目的评分记录(userId,ItemID,rate),转化为相应的评分向量(userID,Vector)/ (itemID,Vector)。进而进行用户和项目维度的聚类。由于推荐系统中的评分矩阵是稀疏矩阵,平均每个用户所包含的评分记录很少。若在计算过程中,直接存储或传输这样的矩阵将会占用过多的内存和网络资源。因此,在加载用户-项目评分矩阵时,为减少内存消耗以及网络通信量,采用稀疏向量存储用户-项目评分矩阵中的每行记录。Spark中SparseVector结构如图5所示。
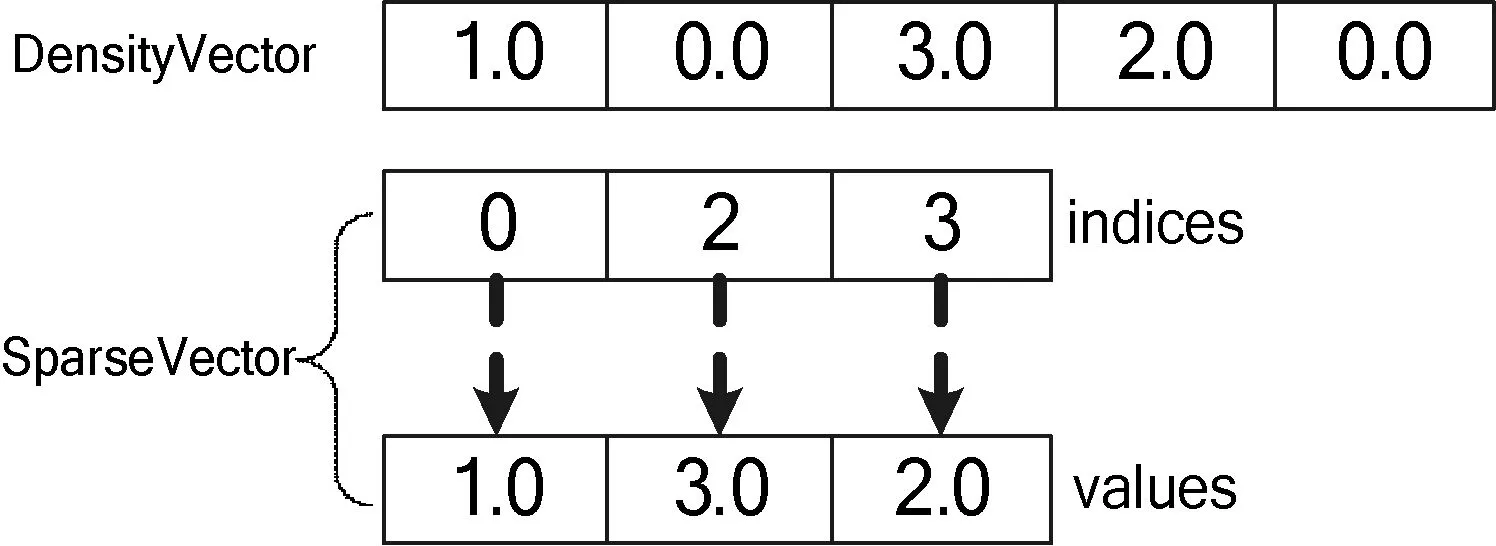
图5 稠密向量和稀疏向量
SparkVector对应的实例化签名为newSparseVector(valsize:Int,valindices:Array[Int],valvalues:Array[Double])。其中,size表示向量长度,indices表示非零元素索引,values表示非零元素值。因此,采用稀疏向量存储n×n的稀疏矩阵时,空间复杂度由O(n2)降为O(nk),遍历矩阵的时间复杂度由O(n2)降为O(nk)。其中,k为每行的非零元素个数。
阶段二中,项目聚类划分结果(UClusterRDD)和用户聚类划分结果(IClusterRDD),需要被重用。因此通过Spark的cache算子将其缓存。当下次使用该RDD时,不会进行重算,直接从缓存中获取该RDD,提高算法执行效率。
在进行分块矩阵评分密集度计算时,需要根据用户类簇评分矩阵信息UClusterRDD(UCId,Vector)以及每个项目类簇所包含的项目索引信息ICIndexRDD(ICId,ICItemIndex),进行分块矩阵划分以及评分密集度计算。在Spark平台下,需要将UClusterRDD和ICIndexRDD进行笛卡儿积(Cartesian),获取每个用户类簇中的项目类簇信息,然后进行分块矩阵划分以及评分密集度计算。少量数据时,Cartesian性能良好。当数据量相对较大时,Cartesian操作,一方面会占用大量网络资源;另一方面,在Cartesian后会增加RDD分片数量,可能会增加额外的调度开销。因此Cartesian操作之后一般需要调整分区(repartition),然后再通过map、reduceByKey等算子统计评分密集度。然而repartition同样会造成额外的shuffle开销。 因此,需要对Cartesian进一步优化。
经分析发现,参与笛卡儿积的ICIndexRDD其维度要远小于UClusterRDD,ICIndexRDD中仅包含每个项目类簇的编号(ICId)以及该项目类簇对应的项目索引(ICItemIndex),占用空间较少可视为小表。因此可将ICIndexRDD内容转换为一个HashMap结构:ICMap(ICId,ICItemIndex)。通过Spark广播机制,将ICMap广播发送到每个节点上来共享该信息。进而RDD中的每个分片均可访问到ICMap,在map-side本地即可完成Cartesian操作,具体流程如图6所示。
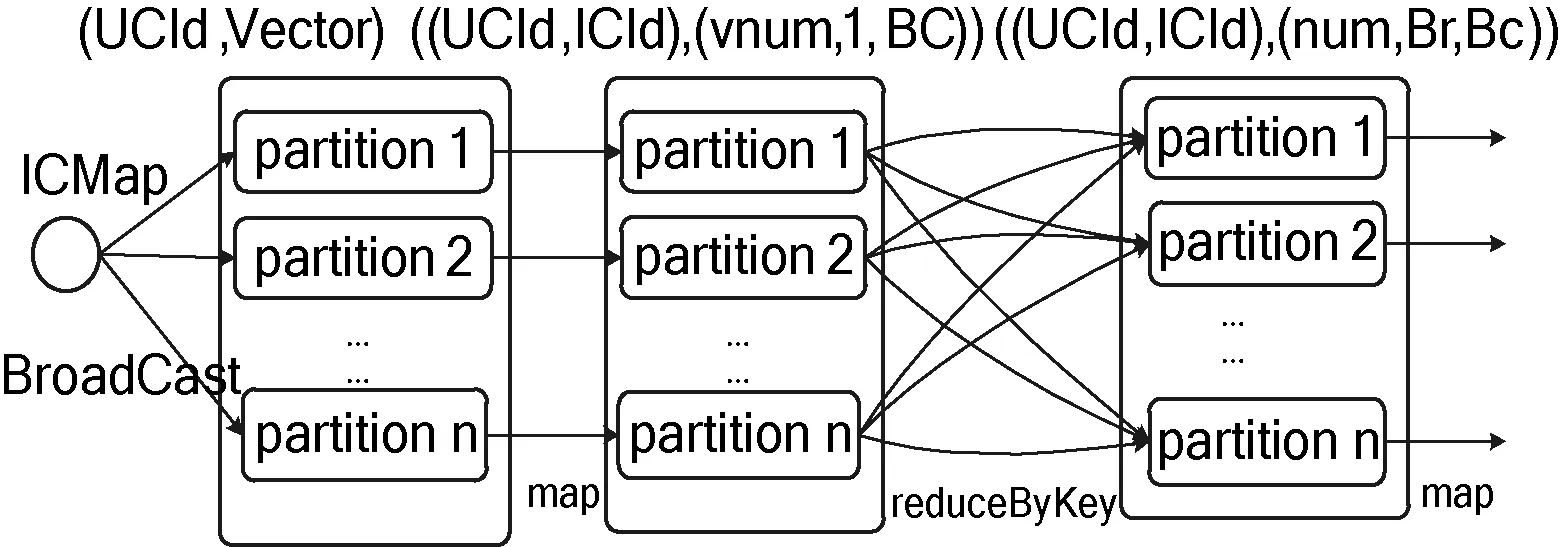
图6 评分密集度计算
如图6所示,经broadcast机制优化后,与ICIndexRDD的关联操作在本地即可完成,降低了网络IO,而且不影响原始分区数量,一般不需要repartition,使得运行效率大幅度提高。其中,每个节点的平均网络IO由O(nc′)变为O(c′),n为节点中的分片数量,c′为小表容量,c′≤nc′。
在阶段三中,不管是近邻集合选取还是推荐列表计算,均需要生成一个递减排序的列表项。然后从中选取前k个列表项,即TopK。在少量数据情况下,可通过groupBy算子进行分组后,再通过flatMap算子选取每个分组的前k个列表项。在数据量较大的情况下,由于groupBy没有本地combine特性直接进行分组,shuffle过程中的网络通信量较高,影响算法性能。
因此当数据量较大时,可通过mapPartition算子实现以数据分片为粒度,进行TopK计算。可以在每个分片中维护一个大小为k的大根堆,然后对大根堆进行不断调整。经过mapPartition处理后,便可求出每个分区的TopK。最后,通过reduceBykey算子,将每个Key所对应的多个分区的TopK进行合并,即可生成每个Key的最终列表项,具体流程如图7所示。

图7 计算每个Key对应的TopK Value
经过mapPartition计算,可过滤大量信息。因此可降低shuffle过程中网络IO,由O(nc)降到O(nk)。其中,n表示分片数量,c表示每个分片中原始数据量,k表示每个分片经过TopK处理后的数据量,k≪c。
3 实验分析
3.1 数据集与实验环境
为了验证AHCCF算法的基本表现和分布式环境下的并行效率,本文选取明尼苏达大学的GroupLens项目组提供的一组中等规模和两组较大规模的数据集,具体描述如表2所示。
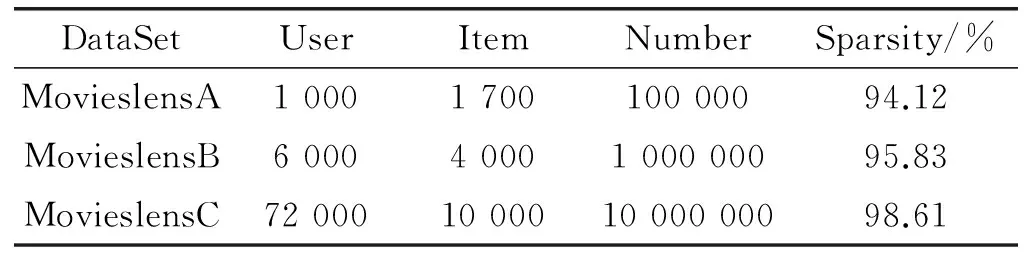
表2 数据集信息
AHCCF算法,在一个配备有5个节点的Spark集群进行实验。1个主节点,4个从节点。在集群的每个节点中,操作系统为Ubuntu14.04,Spark版本为1.3.0,Hadoop版本为2.6.0。
3.2 算法精准度实验
AHCCF算法采用平均绝对偏差MAE,作为算法精准的评价指标。其计算公式定义如下:
(6)
其中,N表示项目数量,pi表示项目的实际分数,qi表示项目的预测分数。MAE越小,推荐质量越高。
AHCCF算法选取MovieLensA数据集,来对算法的精准度进行验证。设计两组实验:AHCCF算法在不同联合聚类数k下的准确度、在数据不同稀疏度下AHCCF算法与IBCF算法[3]、GBCF算法[7]、BSCF算法[8]的对比。
实验1 测试不同联合聚类数k对推荐结果的影响,k分别取5、10、20、30、40、50,最近邻居数取5、10、20、30、40、50、60、70、80、90、100,结果如图8所示。
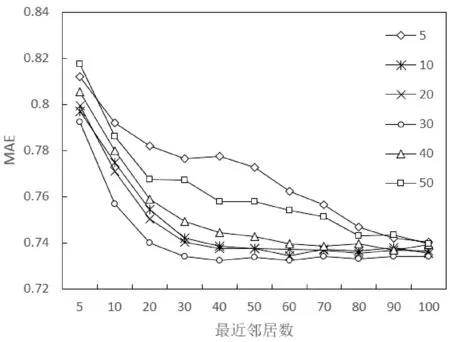
图8 不同联合聚类参数K下算法精度
实验结果表明:算法精度受参数k所影响,联合聚类数k过大、过小都会使推荐精度不理想。一般聚类数越接近项目真实类别数,结果越精确,本实验中当k=30时算法性能最好,在较少项目最近邻的情况下,算法很快收敛到误差最小的推荐结果。
实验2 测试AHCCF算法在不同稀疏度下的准确度,并通过与IBCF算法、BSCF算法、GBCF算法对比来验证算法的有效性。实验过程中,通过调整训练集和测试集所占评分比重,观测数据稀疏度对算法精度的影响,实验结果如表3所示。
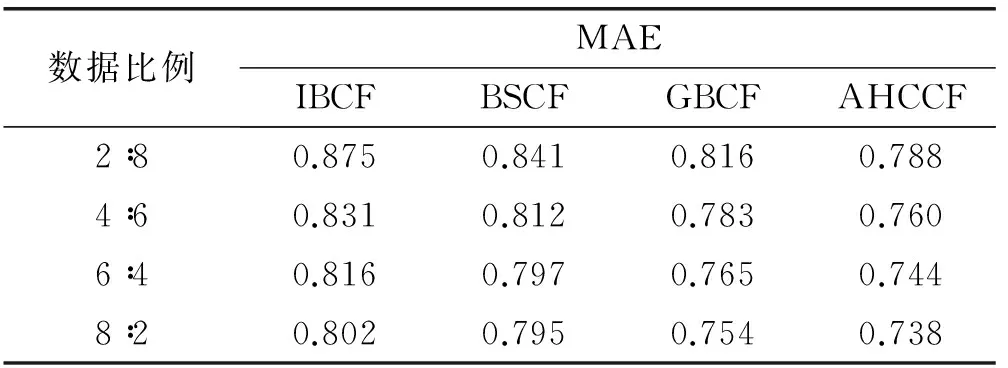
表3 算法运行结果
实验结果表明:随着训练集在整个数据集中所占比重的提高,数据的稀疏度逐渐减小,几个算法的MAE值都在减小,即几个算法的准确度不断提升。其中,BSCF算法、GBCF算法的准确度均高于传统IBCF算法,表明两者在一定程度上缓解了数据稀疏性问题,提高了算法的准确度。本文提出的AHCCF算法在每种稀疏度情况下,其MAE值均低于BSCF和GBCF算法,表明AHCCF算法能够更加有效地处理数据的稀疏性问题,提供更高的推荐效率。
3.3 算法并行实验
AHCCF算法通过采用加速比,来验证通过对Spark集群的扩展能有效提高不同数据规模下AHCCF算法的执行效率。其计算定义公式如下:
(7)
其中,T1表示在单节点情况下算法运行时间,Tn表示n个节点算法的运行时间。理想情况下,依次增加节点时S将与y=x重合。
AHCCF算法选取表1中不同规模的MovieLens数据集来对算法的并行效率进行验证。设计两组实验:相同数据集下AHCCF算法在Hadoop平台与Spark平台执行时间对比、不同规模数据集下AHCCF算法的加速比对比。
实验3 测试在相同数据集下AHCCF算法在Hadoop平台与Spark平台上的执行效率。本实验选取MovieLensB数据集,在Hadoop和Spark两种计算平台上实验,结果如图9所示。
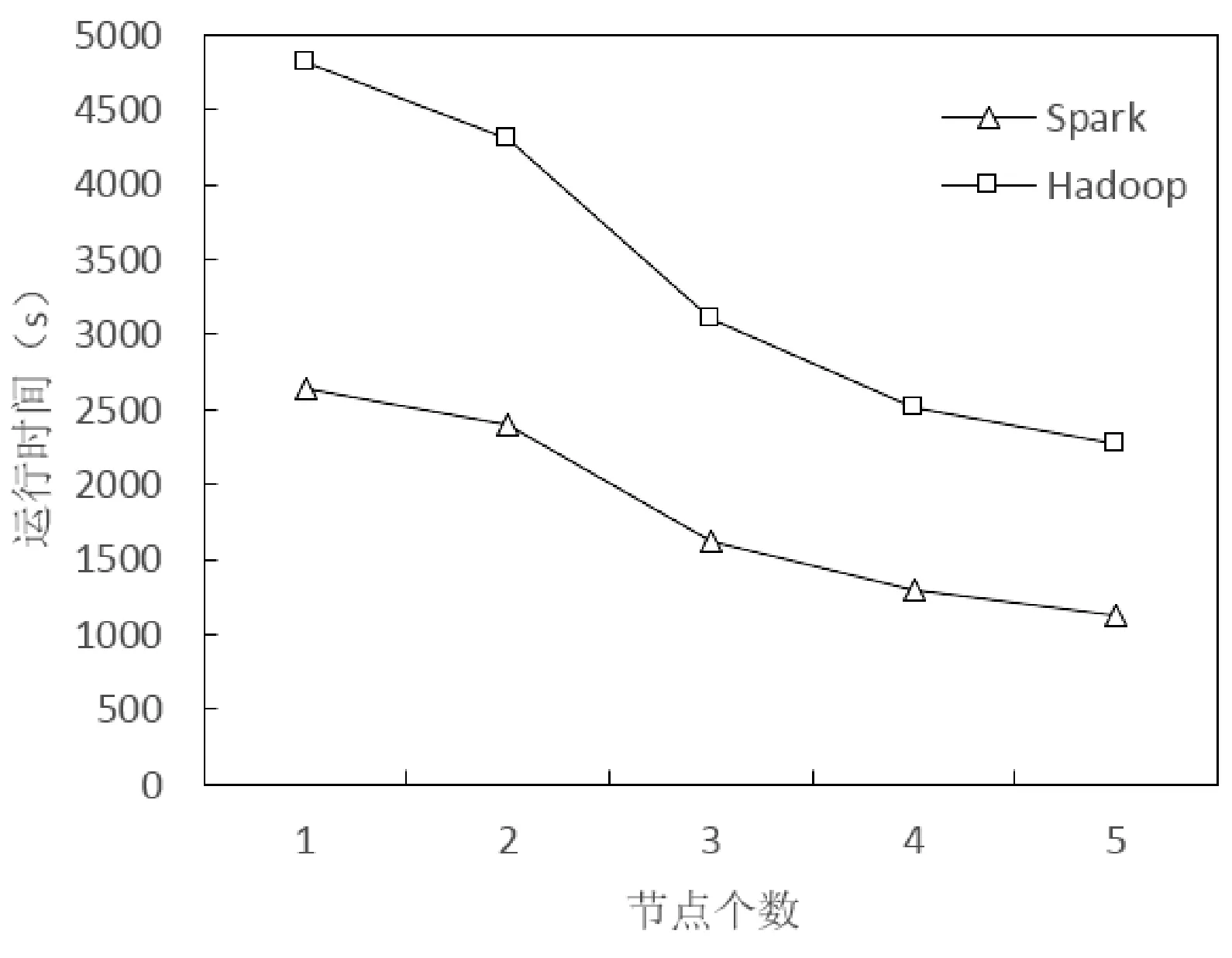
图14 Hadoop与Spark平台运行效率对比
从图9实验结果可以看出,随着节点数量的增加,AHCCF算法在两种计算平台上的执行时间逐渐减少。其中,在Spark计算平台上算法获得更好的执行效率,表明了AHCCF算法在Spark平台上更具有优势,基于Spark的并行方案是有效的。
实验4 测试不同规模数据集下AHCCF算法加速比随集群大小的变化情况,集群大小取1~5。伪分布模式下,集群只有一个节点,master和slave为同一节点,集群大小大于等于2时,为完全分布模式,结果如图10所示。
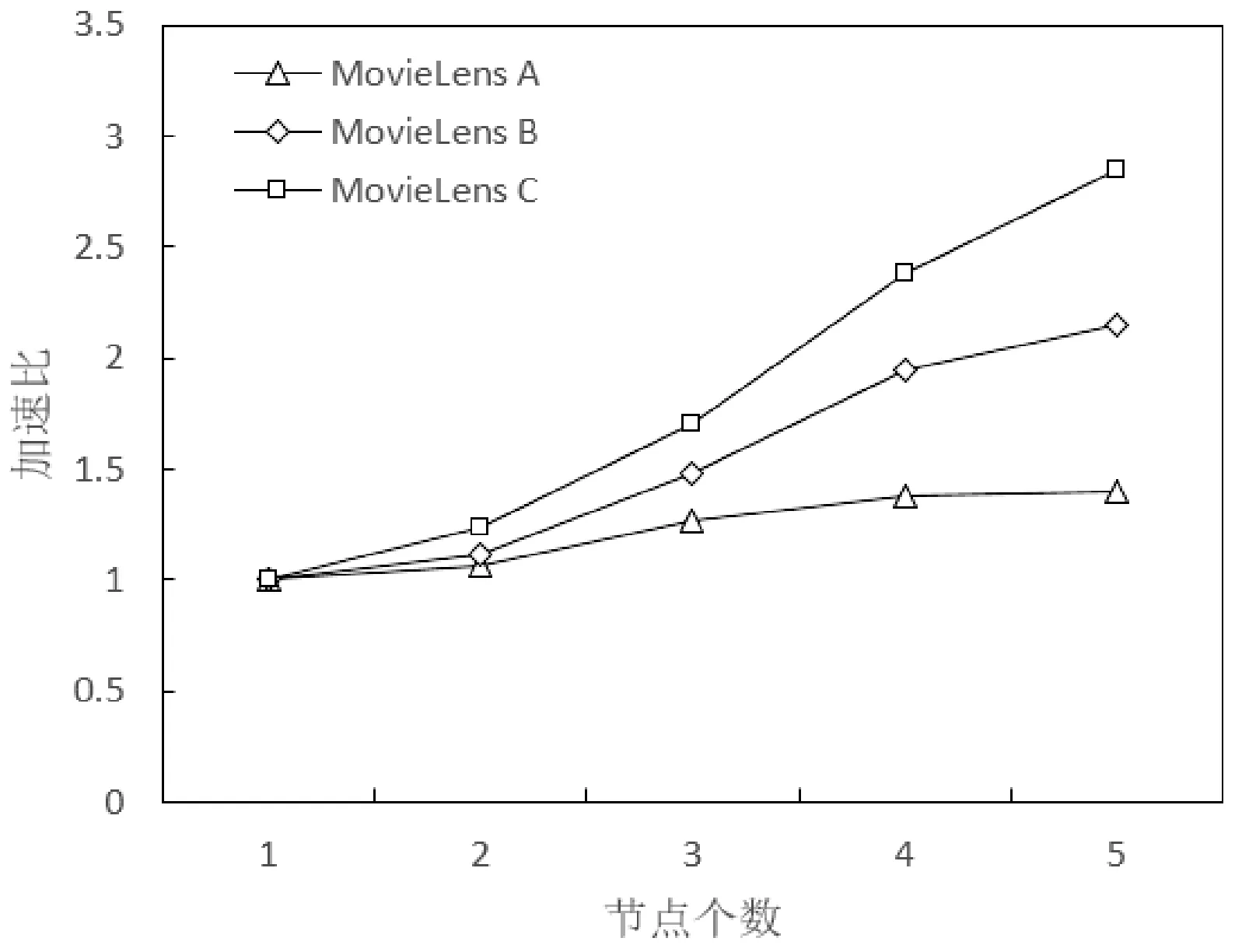
图10 不同规模数据集的加速比对比
实验结果表明,随着集群节点数量的增加,三个数据集的加速比曲线在不断增大。相同数据集在节点数量较少时,算法效率提升不是很明显。这是因为在少量节点时,节点要分担一定计算任务的同时,也要分担一定的资源调度等任务,影响节点的计算性能。在节点个数大于3时,算法效率提升的更为明显。与此同时,可以看出在相同节点情况下,算法效率在规模较大的数据集上提升更为明显,加速比曲线逐渐向线性靠拢,这也说明了并行化的AHCCF算法在处理大数据集时更有优势。
4 结 语
AHCCF算法针对传统协同过滤算法存在的稀疏性以及可扩展性问题展开研究,在基于项目的协同过滤算法基础上,提出了一种分层的联合聚类协同过滤算法(AHCCF),并在Spark平台下实现了AHCCF算法的并行化。实验表明,AHCCF算法改善了传统协同过滤算法的性能,提高了算的推荐精度,并在Spark分布式平台具有良好的执行效率和可扩展性。下一步研究需要对算法进行严格的理论推导,同时研究不同维聚类个数的选取以及在更大规模数据上算法的并行效率。
[1] 郭磊,马军,陈竹敏,等.一种结合推荐对象间关联关系的社会化推荐算法[J].计算机学报,2014,37(1):219-228.
[2]WangJ,VriesAPD,ReindersMJT.Unifyinguser-basedanditem-basedcollaborativefilteringapproachesbysimilarityfusion[C]//Proceedingsofthe29thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM,2006:501-508.
[3] Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th Internationnal World Wide Web Conference.New York,NY,USA:ACM Press,2001:285-295.
[4] 赵琴琴,鲁凯,王斌.SPCF:一种基于内存的传播式协同过滤推荐算法[J].计算机学报,2013,36(3):671-676.
[5] 何洁月,马贝.利用社交关系的实值条件受限玻尔兹曼机协同过滤推荐算法[J].计算机学报,2016,39(1):183-195.
[6] Kumar R,Verma B K,Rastogi S S.Social popularity based SVD++ recommender system[J].International Journal of Computer Applications,2014,87(14):33-37.
[7] Wei S,Ye N,Zhang S,et al.Collaborative filtering recommendation algorithm based on item clustering and global similarity[C]//Proceedings of the 5th International Conference on Business Intelligence and Financial Engineering.IEEE,2012:69-72.
[8] Wang J,Song H,Zhou X.A collaborative filtering recommendation algorithm based on biclustering[C]//Cyber Technology in Automation,Control and Intelligent Systems (CYBER),2015 IEEE Internationa Conference on.IEEE,2015:803-807.
[9] Zhao Z D,Shang M S.User-based collaborative filtering recommendation algorithms on Hadoop[C]//Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining,2010:478-481.
[10] Fan L,Li H,Li C.The improvement and implementation of distributed item-based collaborative filtering algorithm on Hadoop[C]//2015 34th Chinese Control Conference (CCC).IEEE,2015:9078-9083.
[11] Lin K,Wang J,Wang M,et al.A hybrid recommendation algorithm based on Hadoop[C]//2014 9thInternational Conference on Computer Sicence and Education,2014:540-543.
[12] Kupisz B,Unold O.Collaborative filtering recommendation algorithm based on Hadoop and Spark[C]//Industrial Technology (ICIT),2015 IEEE International Conference on.IEEE,2015:1510-1514.
[13] 朱锐,王怀民,冯大为.基于偏好推荐的可信服务选择[J].软件学报,2011,22(5):852-864.
[14] 吴湖,王永吉,王哲,等.两阶段联合聚类协同过滤算法[J].软件学报,2010,21(5):1042-1054.
[15] Ketu S,Agarwal S.Performance enhancement of distributed K-Means clustering for big data analytics through in-memory computation[C]//Contemporary Computing (IC3),2015 Eighth International Conference on.IEEE,2015:318-324.
AN IMPROVED COLLABORATIVE FILTERING ALGORITHM BASED ON SPARK
Xu Zhihong1,2Jiang Xinyu1Dong Yongfeng1,2Zhao Jiawei1
1(SchoolofComputerScienceandEngineering,HebeiUniversityofTechnology,Tianjin300401,China)2(HebeiProvinceKeyLaboratoryofBigDataCalculation,Tianjin300401,China)
In order to improve the scalability of collaborative filtering algorithm in big data environment and the recommendation accuracy in high dimensional sparse data, a hierarchical co-clustering collaborative filtering algorithm based on spark is implemented. The data sets are sparsely processed by using co-clustering and the clustering model is constructed. The potential categories weight of users and projects in the co-clustering model are analyzed by using the analytic hierarchy model combined with the score-density analysis. The project similarity is calculated and the project nearest neighbor set is constructed to complete the online recommendation. The experiments different scale MovieLens datasets provided by GroupLens show that the improved algorithm can significantly improve the accuracy of recommendation, and it has good recommendation efficiency and expansibility in distributed environment.
Collaborative filtering Co-clustering Analytic hierarchy model Spark
2016-04-07。天津市科技计划项目(14ZCDGSF00124);河北省青年科学基金项目(F2015202311)。许智宏,副教授,主研领域:分布式技术,智能信息处理。蒋新宇,硕士。董永峰,副教授。赵嘉伟,硕士。
TP3
A
10.3969/j.issn.1000-386x.2017.05.043
猜你喜欢
兵器装备工程学报(2020年11期)2020-12-16 10:11:20
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
光学精密工程(2016年3期)2016-11-07 09:03:44
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
中国学术期刊文摘(2016年8期)2016-02-13 13:04:44
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
新校长(2016年8期)2016-01-10 06:43:59
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
