
位置正则的支持向量域描述在人脸识别中的应用研究
2017-06-29 12:00:34曾青松
计算机应用与软件 2017年5期
熊 昕 曾青松
1(广州番禺职业技术学院教育技术与信息中心 广东 广州 511483)2(广州番禺职业技术学院信息工程学院 广东 广州 511483)
位置正则的支持向量域描述在人脸识别中的应用研究
熊 昕1曾青松2*
1(广州番禺职业技术学院教育技术与信息中心 广东 广州 511483)2(广州番禺职业技术学院信息工程学院 广东 广州 511483)
支持向量域描述是一种有效的一分类数据描述方法,能够有效地对单一类别的数据进行表达,并能有效地降低负样本的干扰。应用支持向量域描述方法,将人脸图像集合投影到高维特征空间构建描述特征空间中人脸图像的超球体,并定义两个超球体之间的相似性度量,应用最近邻分类器进行分类。在基于集合的人脸识别应用标准数据库上测试了该方法,在Honda/UCSD、CMU Mobo和YouTube数据分别取得100%、97.55%和59.78%的识别率。实验结果表明,该方法是一种有效的基于图像集匹配的人脸识别方法。
支持向量域描述 人脸识别 模式识别 集合匹配
0 引 言
近年来,在人脸识别领域中,随着数字监控系统的普及视频采集技术的提高,人们能够方便地采集到更多的数据样本,研究人员转向关注以图像集为研究对象的识别方法[1-2]。由于光照、遮挡等因素的影响,视频监控系统的数据源一般经过压缩,获取到的图像的分辨率和清晰度都比较低。但是在监控环境中,人们可以获取更多的图像,这些图像能够从不同角度提供有助于鉴别分析的信息,最终提高识别的精度。
与传统的方法相比,基于集合的识别方法把整个图像集合当作一个整体,建立相应的数学模型。这一类方法需要解决如何提取人脸的特征,建立相应的数学模型,设计两个模型之间的相似性的度量方法等一系列的问题。一般可以对图像集合张成的子空间建模,将图像集投影到低维线性子空间,计算子空间之间的主夹角,用典型相关作为相似性的度量[3]。或者计算图像集合的张成的仿射子空间,使用两个仿射包中最近邻点之间的几何距离来度量集合之间的相似性[4],在这个基础上,Hu等人引入稀疏表达的通过仿射包对图像集合建模,运用最近邻点来度量两个仿射包之间的相似性[5]。
一般可以把一个子空间理解成成格拉斯曼流形上的一个点,通过核函数将流形上的特征映射到欧式空间,然后在新的空间中学习一个分类器。比较流行的方法是使用核函数将欧式空间的特征投影到再生核希尔伯特空间,核Fisher鉴别分析中应用格拉斯曼核进行鉴别分析[6]。或者将每一个图像集合当成构成格拉斯曼流形的子空间,组合使用投影核和典型相关核进行鉴别分析[7]。
流形学习是一种非线性降维方法。流形能够有效刻画样本数据的本质结构,并提供一种结构紧致的表示[8]。这一类方法,使用流形来刻画一个图像集合,比较两个流形的相似性。作为一种子空间的相似性的度量方法,主夹角方法可以有效地捕捉两个子空间之间的公共的数据变化模式[9],通过主夹角度量两个子空间或者流行上两个局部线性模型之间的距离[3,10],通过多流形学习解决有监督的流形间距离计算问题[11]。

支持向量域描述SVDD(Support Vector Domain Description)是一种基于支持向量机学习的方法[16-17]。它用一个包含大部分正例样本的超球表示一个集合。本文使用支持向量域描述方法建立数据集合进行的数据域描述模型,并通过对不同位置的样本赋予不同权来进一步提高了数据域的描述能力,并将该方法应用到基于集合的人脸识别中。
1 支持向量域描述
数据域描述的主要任务是学习数据集的有效描述,使得该描述能够有效地覆盖数据空间的正样本点同时排除数据空间的负样本点。而作为识别用途的数据域描述,构建的模型还要能够方便、有效地区分不同类别的样本[18-19]。
1.1 支持向量域描述
支持向量域描述是一个球状的数据域描述方法,通过一个非线性映射函数将数据集从原始数据空间投影到高维核空间,构建一个仅仅依赖于少数支持向量的非常精确的数据域描述,寻找一个能够围住大部分样本的最小闭球来表示整个数据集。
给定一个包含N个样本的数据集,X={xi∈RD|i=1,2,…,N}及一个从原始数据空间投影到高斯核空间的非线性映射φ,我们需要学习一个核空间上围住大部分的映射样本点的最小超球体。采用超球中心μ以及球的半径R表示超球体,∀ξi≥0,在满足约束条件:
‖φ(xi)-μ‖2≤R2+ξi
(1)
的前提下,最小化目标函数:
(2)
其中‖·‖表示欧式距离,μ、R分别表示超球体的球心和半径,ξi≥0是使得允许边界存在的松弛变量,平衡参数C控制对噪声点的惩罚,权衡了超球体的体积与数据域描述的精度。由拉格朗日法则,我们有:

(3)
(4)

核半径函数定义为:
R(x)=‖φ(x)-μ‖=

(5)
理想的情况下,所有的SV都应该具有相同的半径。由于数值误差的存在,可能会有轻微的不同。一般超球体的半径可以定义所有样本点的核半径的最大值:
(6)
数据集的数据域描述定义为原始的空间中,{x|R(x)=R}的这些样本点的轮廓线。图1给出一个标准测试集的特征空间中的超球体的示意图,所有的边界向量连接在一起构成超球体的球面,少量的位于球面外部的点可以理解成负样本点。

图1 特征空间的超球示意图
1.2 位置正则的支持向量域描述
式(2)描述的模型严重依赖于参数C。这个参数决定了超球体的大小,影响到超球体表面样本的分布。
在核空间,如果样本点离样本集合中心的距离越远,它们成为离群点的可能性就越大,在原始输入空间该样本与其它样本越远。因此可以赋予一个与样本位置相关的权重来描述孤立程度。基于上述分析,通过对不同位置的样本赋予不同权来代替目标函数中的参数C,进一步提高了数据域的描述能力[20]。为计算公式基于位置的权重参数,首先通过式(7)计算一个核距离矩阵:D=[Dl|l=1,2,…,N]。


(7)
接着,权重wi可以定义为:
(8)
(9)
∀i=1,2,…,N在满足约束条件式(1)的前提下,最小化超球的半径:
(10)
与式(2)描述的目标函数不同的是,式(10)中,每个权重Wi分别正则化对应的样本点xi成为奇异点的可能性。权重Wi越小,则松弛变量ξi越大。而松弛变量ξi则直接对应于产生超球体软边界和边界支持向量。
2 图像集建模
2.1 图像集的数据域描述
本文直接使用图像的灰度值作为特征,每一张图通过列拼接得到一个向量表示一个图像的特征,多张图像组合在一起构成一个矩阵,作为图像集合的输入空间。
设SV和BSV分别表示支持向量和边界向量的集合,图像集合可以表达为D(μ,R,R(x))={SV,BSV,μ,R(x)}。其中核半径函数R(x)在式(5)中定义,半径R在式(6)中定义。
2.2 相似性度量

(11)
式(11)中球心的距离通过式(12)计算:
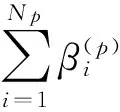


(12)
3 实验设置与结果分析
本节我们讨论在HondaUCSD视频数据库、CMUMoBo数据库[22]和YouTube视频数据库[23]上进行基于集合的人脸识别实验。实验计算机配置为:Intel(R)Xeon(R)E7-4807双1.87GHzCPU(2×6核),64GB内存,安装WindowsServer2008R2,程序使用MATLAB2013编写。
3.1 数据集
Honda/UCSD数据集是人脸识别领域的基准数据集,它一共包含19个人的59段视频。这个数据库的所有视频是在室内光照条件受到控制的条件下录制的,视频相对比较清晰。每个视频片段内只有一个人,包含该人的不同姿态和表情的变化。每段视频长度大约300~500帧,被分割成多个视频小片段,用于构建训练和验证集合。实验使用Viola[24]算法逐帧检测出人脸区域。如图2所示,检测到的人脸图像都接近正面人像。

图2 Honda/UCSD数据库人脸示意图
CMUMoBo数据库最初是为了研究远距离人的身份识别问题而收集的[22]。每一个人包含4种不同的走路的方式,这些视频是室内固定位置摄像机拍摄的。本文使用它的一个子集,包含96个视频序列,24种不同的主题,每一个序列包含大约300帧。
YouTube数据库是收集来自于YouTube网站的一些公开视频片段,共计47个人的1 910段视频,每个人的视频片段分为3个小节,每一个小节对应不同的采集时间与场景。这个数据库包含大范围的姿态、光照和表情变化,本文使用对象跟踪算法,提取相应的人脸图像[25]。由于视频的清晰度不高,部分视频中包含超过1个人的头像,尽管我们采用了对象跟踪方法获取人脸图像,但是实验中发现有人像跟丢和错误跟踪的问题,导致视频中有部分的人像不完整甚至是错误的。

图3 YouTube数据库人脸跟踪的结果
3.2 比较的方法和设置
实验以原始论文公开的代码为基础,检测到的人脸图像经过简单的直方图均衡化处理之外,按照列堆叠成行向量。Honda/UCSD和YouTube数据库使用灰度特征,CMUMoBo数据库使用LBP特征[26]。实验中,算法的具体参数设置如下:互子空间方法MSM[3]、流形-流形距离MMD[10]和图像集稀疏最近邻逼近SANP[5]算法使用PCA降维,保留95%的能量。MMD算法采用原文相同的参数设置:欧式距离与几何距离比值设置为2.0,使用最大典型相关计算距离,邻域大小设置为12。格拉斯曼流形鉴别分析GDA[6]算法采用投影核,格拉斯曼流形上图嵌入鉴别分析GGDA[7]算法实现了最简单的二分图结构,使用最大典型相关计算核函数,邻域参数k设置为2。
本文的方法,首先建立数据库中每个集合的数据域描述模型Di(i=1,2,…)。测试阶段,先计算查询图像集合的数据域描述模型Q,然后应用式(11)计算其与数据库中的每一个模型之间的距离,应用最近邻分类器进行分类。
3.3 实验结果与分析
表1 报告了Honda/UCSD、CMUMoBo和YouTube数据库上5次随机实验的平均识别率(RR)、方差(STD)和平均计算时间(秒)。在Honda/UCSD和CMUMoBo数据库上,本文提出的方法取得了最好的识别结果。YouTube数据库的视频质量比较差,带有一定程度的噪声污染,根据实验设定,对象跟踪的结果中含有部分噪声点,这些噪声点被描述成超球体的外点,有效地降低其对识别结果的影响。
从表1的实验结果分析,所有算法在YouTube这个数据库上取得的结果都比较差,但是本文提出的方法取得的结果相对好于其它的算法。虽然本文的方法比SANP方法识别率要低,但是计算速度比SANP方法快了近100倍。
4 结 语
图像集匹配是模式识别领域研究的热点问题之一。虽然现在有若干较有效的图像集匹配方法,但是由于多视角、多光照变化等复杂环境所导致的多局部模型分布下的无监督图像集匹配问题仍然是一个具有挑战性的问题。支持向量域描述不仅对一类数据具有很好的描述能力,而且在例外点检测和降噪方面表现非常优秀。本文扩展了SVDD,借助位置正则的方法,对特征空间中样本动态加权,提高SVDD对数据集合的表达能力,有效地解决了全局单一平衡参数所带来的问题。
[1] Barr J R, Bowyer K W, Flynn P J, et al. Face recognition from video: A review[J]. International Journal of Pattern Recognition and Artificial Intelligence, World Scientific, 2012,26(05).
[2] 严严, 章毓晋. 基于视频的人脸识别研究进展[J].计算机学报,2009,32(5):878-886.
[3] Yamaguchi O, Fukui K, Maeda K. Face Recognition Using Temporal Image Sequence[C]//3rd International Conference on Face & Gesture Recognition. Nara, Japan: IEEE Computer Society, 1998:318-323.
[4] Yang M, Zhu P, Gool L J Van, et al. Face recognition based on regularized nearest points between image sets[C]//10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, FG 2013. Shanghai, China: IEEE, 2013:1-7.
[5] Hu Y, Mian A S, Owens R. Face recognition using sparse approximated nearest points between image sets[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2012,34(10):1992-2004.
[6] Hamm J, Lee D D. Grassmann discriminant analysis: a unifying view on subspace-based learning[C]//Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008:376-383.
[7] Harandi M T, Sanderson C, Shirazi S, et al. Graph embedding discriminant analysis on Grassmannian manifolds for improved image set matching[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2011:2705-2712.
[8] 王瑞平. 流形学习方法及其在人脸识别中的应用研究[D]. 北京: 中国科学院研究生院,2010.
[9] Kim T K, Arandjeloviĉ O, Cipolla R. Boosted manifold principal angles for image set-based recognition[J]. Pattern Recognition,2007,40(9):2475-2484.
[10] Wang R, Shan S, Chen X, et al. Manifold-Manifold Distance with application to face recognition based on image set[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition,2008:1-8.
[11] Wang R, Shan S, Chen X, et al. Manifold-Manifold Distance and its Application to Face Recognition With Image Sets[J]. IEEE Transactions on Image Processing, 2012,21(10):4466-4479.
[12] Jayasumana S, Hartley R, Salzmann M, et al. Kernel Methods on the Riemannian Manifold of Symmetric Positive Definite Matrices[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2013:73-80.
[13] 曾青松. 黎曼流形上的保局投影在图像集匹配中的应用[J]. 中国图象图形学报,2014,19(3):414-420.
[14] Wang R, Guo H, Davis L S, et al. Covariance discriminative learning: A natural and efficient approach to image set classification[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on,2012:2496-2503.
[15] 詹增荣, 曾青松. 基于协方差矩阵表示的图像集匹配[J]. 湖南师范大学自然科学学报,2015,38(4):74-79.
[16] Tax D M J, Duin R P W. Data domain description using support vectors[C]//Esann 1999, European Symposium on Artificial Neural Networks, Bruges, Belgium, April 21-23, 1999, Proceedings,1999:251-256.
[17] Ben-Hur A, Horn D, Siegelmann H T, et al. Support Vector Clustering[J]. Journal of Machine Learning Research, 2002,2(2):125-137.
[18] 曾青松. 基于支持向量域描述的图像集匹配[J]. 模式识别与人工智能,2014,8(8):735-740.
[19] Zeng Q S, Lai J H, Wang C D. Multi-local model image set matching based on domain description[J].Pattern Recognition,2014,47(2):694-704.
[20] Wang C D, Lai J H. Position regularized Support Vector Domain Description[J]. Pattern Recognition,2013,46(3):875-884.
[21] Wang C D, Lai J H, Huang D, et al. SVStream: A Support Vector-Based Algorithm for Clustering Data Streams[J].IEEE Transactions on Knowledge & Data Engineering,2013,25(6):1410-1424.
[22] Gross R, Shi J. The CMU Motion of Body (MoBo) Database[R].Pittsburgh, PA, 2001(CMU-RI-TR-01-18).
[23] Kim M, Kumar S, Pavlovic V, et al. Face tracking and recognition with visual constraints in real-world videos[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008). Anchorage, Alaska, USA: IEEE Computer Society, 2008.
[24] Viola P, Jones M J. Robust real-time face detection[J]. International Journal of Computer Vision, Springer, 2004,57(2):137-154.
[25] Ross D A, Lim J, Yang M-H. Adaptive Probabilistic Visual Tracking with Incremental Subspace Update[C]//Computer Vision-ECCV 2004, 8th European Conference on Computer Vision. Prague, Czech Republic: Springer, 2004:470-482.
[26] Chan C H, Tahir M A, Kittler J, et al. Multiscale local phase quantization for robust component-based face recognition using kernel fusion of multiple descriptors[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(5):1164-1177.
APPLICATION OF POSITIONAL REGULAR SUPPORT VECTOR DOMAINS IN FACE RECOGNITION
Xiong Xin1Zeng Qingsong2*
1(EducationalTechnologyandInformationCenter,GuangzhouPanyuPolytechnic,Guangzhou511483,Guangdong,China)2(SchoolofInformationandTechnology,GuangzhouPanyuPolytechnic,Guangzhou511483,Guangdong,China)
Support vector domain description is an effective method to describe a single class of data, and can effectively reduce the interference of negative samples. In this paper, the support vector domain description method is used to construct a hypersphere that describes the face image in the feature space by projecting the face image set into the high-dimensional feature space. And the similarity measure between two hyperspheres is defined and classified by nearest neighbor classifier. This method was tested on the standard database of face recognition based on collection. The recognition rate of Honda/UCSD, CMU Mobo and YouTube data were 100%, 97.55% and 59.78% respectively. Experimental results show that the proposed method is an effective method for face recognition based on image set matching.
Support vector domain description Face recognition Pattern recognition Set matching
2016-04-25。广东省自然科学基金项目(2015A030313807)。熊昕,实验师,主研领域:模式识别。曾青松,副教授。
TP391.4
A
10.3969/j.issn.1000-386x.2017.05.029
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
作文中学版(2022年1期)2022-04-14 08:00:34
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
数学物理学报(2020年2期)2020-06-02 11:28:48
学生天地(2020年31期)2020-06-01 02:32:06
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
数学物理学报(2019年1期)2019-03-21 05:26:18
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
计算机工程(2015年8期)2015-07-03 12:19:07
