
面向多源异构信息的频繁项集挖掘算法
2017-06-27 08:14刘自力范军丽陈文伟吴润泽
计算机技术与发展 2017年6期
刘自力,范军丽,陈文伟,吴润泽
(1.国网山西省电力公司 晋城供电公司,山西 晋城 048000; 2.北京国电通网络技术有限公司,北京 100070; 3.华北电力大学 电气与电子工程学院,北京 102206)
面向多源异构信息的频繁项集挖掘算法
刘自力1,范军丽2,陈文伟3,吴润泽3
(1.国网山西省电力公司 晋城供电公司,山西 晋城 048000; 2.北京国电通网络技术有限公司,北京 100070; 3.华北电力大学 电气与电子工程学院,北京 102206)
电网调度运行过程中产生海量复杂度高的多源异构数据,利用数据挖掘将这些数据转化为知识是调度智能化发展的必然趋势。为此,构建了基于调控大数据的多源异构数据分析模型,提出了一种能够处理大数据的频繁项集挖掘算法,将分布式统计引入到频繁项集挖掘过程。该算法根据组合学原理,利用MapReduce扫描一次数据库从原始事务数据库中完成频繁项集的整个挖掘过程;且在支持度阈值改变的情况下无需重新扫描数据库进行挖掘,改进了现有频繁项集挖掘算法多次扫描事务数据库和挖掘效率低的问题。通过利用Hadoop平台对故障信息事务库进行处理,将所提出的算法与其他频繁项集挖掘算法进行了对比验证实验。实验结果表明,所提出的算法不受支持度阈值的影响,处理海量事务数据算法时间开销小,可为实现以准确、安全、经济等目标综合最优的调度智能化分析和决策提供有益的知识。
智能调度;频繁项集;组合理论;Hadoop
0 引 言
当前信息通信技术(ICT)的高速发展推动了智能电网的全面建设,ICT和电网建设的深度融合催生了智能电网大数据的爆炸性增长。这些数据不仅规模大,其结构也多样化,构成了智能电网中的海量多源异构大数据。海量多源异构大数据的高效快速处理和深度挖掘分析为建设坚强可靠、稳定运行的智能电网提供基础[1]。电网调度控制系统中产生的大数据是智能电网大数据的主要来源,这些数据隐藏着电网运行中的实时状态信息。而数据挖掘是实现将实时数据和沉淀的历史数据转化为有用知识的有效方法,为电网调度运行提供辅助性决策和科学性建议[2]。智能调度中的数据来源丰富,人们从不同的数据源获取的信息也越来越多,而且这些数据创造的价值也被人们所接受,但是这些数据源之间形成了众多的“信息孤岛”。因此,有必要采用大数据思想,对智能调度中的数据进行分析和挖掘,来实现数据共享,为智能调度的实现提供参考。关联分析是数据挖掘和知识发现的重要技术之一。关联规则算法主要用来挖掘事务数据库中有意义或用户感兴趣的规则。1993年,美国的R.Agrawal等首次提出关联规则算法[3],其主要思想是从原始事务数据库中找出满足一定支持度和置信度要求的项集。其中满足用户定义的最小支持度的项集称为频繁项集,从频繁项集中找出满足最小置信度的频繁项集,将其转化成最终的强关联规则形式完成关联规则挖掘。将频繁项集转化成关联规则的过程较为简单,所以频繁项集挖掘是关联规则挖掘的重点和关键。
Apriori算法是由R.Agrawal等提出的经典频繁项集算法,该算法通过连接和剪枝方法完成,能够有效挖掘出用户需要的关联规则,但是存在产生大量的候选项集和重复多次扫描事务数据库的缺陷。为了克服这些缺陷,Han Jiawei等在Apriori算法的基础上提出了FP-growth算法[4]。该算法建立了树结构,用来保存每项的支持度计数,在建立频繁模式树的过程中只需扫描两次事务数据库,并且不产生候选项集。尽管该算法提高了频繁项集的挖掘效率,但是针对大量且事务比较长的事务数据库,其挖掘效率较低。为了提高频繁项集的挖掘效率,文献[5-8]基于磁盘存储的算法改进了挖掘大量事务数据库和内存有限的问题,但其算法复杂度较高。文献[9]的FIMM算法在挖掘频繁项集的过程中其运行时间不受支持度阈值的影响,改善了算法的计算复杂度;然而,事务数据库数据量很大时,其结果也不理想。
针对以上问题,在分析智能调度中数据特点的基础上,建立了智能调度多源异构数据分析模型,实现了多源异构数据为智能调度创造价值。根据该模型中的关联分析,根据组合学原理,结合MapReduce思想,提出基于大数据的频繁项集挖掘算法(Frequent Itemset Mining Based on Big data,FIMBB)。该算法只扫描一次原始事务数据库来完成整个频繁项集的挖掘过程;利用大数据中的MapReduce平台并行挖掘出最终的所有目标频繁项集,整个流程采用了分布式和并行的思想,挖掘效率得到有效提高。
1 基于大数据的智能调度多源异构数据分析模型
智能调度大数据分析的主要思想为使用适当的大数据工具,抽取和集成多源异构数据,按照分析需求的统一格式存储预处理后的数据,采用数据分析和数据挖掘技术对存储的数据进行分析和深度挖掘,以提取出隐藏在数据中的知识,并根据智能调度的新需求,形成新的智能应用。
1.1 智能调度多源异构数据特点分析
调度环节的数据在传统电网基础上,数据来源、种类、规模都有了极大的扩充和丰富[10],这些来自于不同系统的数据彼此之间有一定的关联性,不完全独立,这些数据结构复杂、数据量很大,彼此之间存在着复杂的关系。根据大数据的基本特征和电网调度的具体特点,智能调度多源异构数据具有以下特征:
(1)数据来自各调度中心,每个调度中心的数据又来源于多个系统,包括SCADA、EMS、WAMS、AMI、OMS、GIS等。每个系统采集到的数据模型、格式、特点不完全相同。
(2)数据规模大,维度多,实时性强。晋城供电公司SCADA系统大概总共有80 000个遥测点,采样间隔按4 s计算,每年将产生11.014 TB的数据。具体计算公式为:
11.014 TB=(12字节/帧×0.4帧/s×80 000遥测点×86 400 s/天×365天)/240
(3)数据的真实性和安全性高[11]。高质量电网调度数据对于数据分析和挖掘至关重要;调度是电网的中枢神经,数据的安全性是电网稳定、安全和可靠运行的前提条件。
(4)数据源之间的关联性强,集成全面分析产生的结果具有很大的经济和社会价值。例如,负荷预测[12]是智能调度中的一个关键应用,其预测主要以负荷数据为主,但是负荷预测与气象、地理、人口、经济等方面的数据有一定关联,若利用大数据技术,将这些相关的数据源进行全面负荷预测,将为电力用户创造极大的价值。
1.2 基于大数据的多源异构数据分析模型建立
与传统数据分析的主要区别在于:智能调度中大数据分析的数据往往包括大量的结构化、半结构化和非结构化数据。从数据来源到数据应用整个数据分析过程中,每个环节均能利用大数据处理平台Hadoop、MapReduce[12]等方式进行并行处理。根据智能调度多源异构数据的特征和大数据思想,建立了基于大数据的智能调度多源异构数据分析模型,如图1所示。

图1 基于智能调度多源异构数据分析模型
图1描述了将电网智能调度的数据转化为对调度管理和决策有益的知识的过程,打破了调度控制系统中各系统之间的信息孤岛。在异构数据源层,SCADA、WAMS等系统都会产生海量数据,这些系统彼此不相同,数据类型复杂,因此需要首先对数据源的数据进行ETL预处理,保证数据质量及可靠性。NoSQL[13]数据库技术是一种分布式数据存储方式,具有良好的可扩展性,解决了海量数据的存储难题。其中代表性的包括Google的BigTable和Amazon的Dynamo等。在云计算[14]平台上,完成智能调度海量信息的可靠存储和快速并行处理。对存储后的数据通过数据挖掘等数据分析技术,将广泛的异构数据分类,这样多源异构数据源通过数据预处理和分析挖掘转化成了面向主题的、集成的调度全景大数据,如设备基础数据仓库、告警类数据仓库等统一数据模型,从而为系统提供全面的数据共享。将各类电网内外部数据和相应的调度业务数据进行结合,形成新的智能调度大数据应用场景。关联分析在智能调度数据分析挖掘中具有广泛应用,分析历史故障数据,找出故障之间的相关性,为快速找出根源故障,提供故障预测参考。
2 FIMBB算法
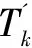

图2 FIMBB算法流程
Mapping阶段算法的主要思想是:首先将输入的故障事务数据转化成程序中的统一格式,设置频繁项集挖掘的最小支持度阈值和k频繁项集的上限;读取每一条处理后的事务数据,将每条数据在满足项数上限的条件下组合事务,输出〈Key,Value〉。
算法主要步骤为:
(1)将电网故障事务数据库的事务记录逐条读入;
(2)每条事务记录按照自然项进行处理;
(3)根据组合学原理,完成调整后的事务中项的组合;
(4)根据项的组合集合以〈Key,Value〉的形式输出,其中Key为事务记录项的组合,Value为1。
在Reducing阶段,将Map阶段的输出当作输入,合并相同的项集的计数。具体步骤为:当读到非空项集时,将项集的计数累加,然后统计其支持度;如果其支持度大于等于其最小支持度阈值,输出该项集。
3 实验与结果分析
实验分析中,采用人工随机电网调度中的故障信息事务集Datafile进行实验,其中故障事务中包含10个不同的故障信息项,并和Apriori、FIMM算法进行性能比较。FIMBB算法是基于台式机搭建的Hadoop平台,该平台由三台计算机集群组成。其中,两台机器作为DataNodes和TaskTrackers,这两台计算机配置了N3700核心处理器(主频1.6 GHz)和4 GB内存;第三台计算机作为NameNode和JobTracker,其配置了G3260双核处理器(主频3.3 GHz)和4 GB内存。网络环境为同一局域网。实验结果如图3和图4所示。

图3 三种算法运行时间随着支持度阈值的变化趋势

图4 运行时间随事务数据量的变化趋势
从图3可以看到,FIMM和FIMBB算法的运行时间基本不受支持度阈值的影响,而Apriori算法的运行时间和支持度阈值的变化有很大关系,原因在于随着支持度的增大,Apriori算法产生的候选项集数目变少,从候选集中找出真正的频繁项集相应所需的时间就变少。
从图4可以看到,FIMM算法运行时间与事务数据量大小基本呈线性关系:当事务数据量小于600时,FIMM的运行时间小于FIMBB;当事务数大于600时,FIMBB运行效率明显高于FIMM。因为FIMBB算法在事务数据量较少时花费在配置运行环境和节点间通信上的时间占很大比例,当事务数据量较大时,FIMBB算法的运行效率具有很大优势。在事务数较多时,Apriori算法的运行效率明显要低于其他两种算法,原因在于事务数据量越大,Apriori算法将产生大量的候选集且需要多次扫描原始事务数据库,因此耗时较多。当对不同数据量的事务进行挖掘时,FIMBB算法的加速比如表1所示。

表1 FIMBB加速比
根据理想加速比公式得到集群中机器台数分别为2和3的理想加速比为2和3。从表1可以看出,在实际运行中得到的加速比往往和理想的差别很大。主要是由每台机器的硬件性能不完全相同造成的。另外,加速比计算公式为:
其中,Tq、Ts分别为集群和单机运行算法的时间开销;c1、c2为两者的系统开销。当事务数据量很大时,计算加速比可忽略系统开销。
从以上分析可知:对于大量的事务数据,FIMBB算法的性能优于FIMM和Apriori算法,且具有很好的可扩展性,适用于智能调度中大量故障事务的频繁项集挖掘。
4 结束语
调度数据分析和处理是实现智能调度的关键,在分析智能调度数据特点的基础上,根据智能调度大数据的需求,构建基于大数据的智能调度多源异构数据分析模型,实现了通过大数据挖掘技术,将调度控制系统中的多源异构数据转化成智能调度的有价值信息。FIMBB算法是一种针对大量电网调度事务数据的频繁项集挖掘算法。该算法将分布式计算的思想引入挖掘频繁项集中。
根据组合学原理,利用MapReduce扫描一次数据库从原始事务数据库中完成频繁项集的整个挖掘过程;且在支持度阈值改变的情况下无需重新扫描数据库进行挖掘,提高了频繁项集的挖掘效率。实验结果表明,该算法不受支持度阈值的影响,且对于大量事务数据,运行效率高,适用于智能调度大数据的关联分析。大数据在智能调度中的应用价值不可估量,但是,要加速智能调度化的进程,需要在多源数据融合和全景数据深度分析方面有所突破。
[1] 刘振亚.智能电网技术[M].北京:中国电力出版社,2010.
[2] 辛耀中,石俊杰,周京阳,等.智能电网调度控制系统现状与技术展望[J].电力系统自动化,2015,39(1):2-8.
[3] Agrawal R, Imieliński T, Swami A.Mining association rules between sets of items in large databases[C]//Proceedings of the ACM SIGMOD conference on management of data.Washington,D C:ACM,1993:207-216.
[4] Han Jiawei,Pei Jian,Yin Yiwen.Mining frequent patterns wi-thout candidate generation[C]//Proceedings of the ACM SIGMOD conference on management of data.Dallas,TX:ACM,2000:1-12.
[5] Baralis E, Cerquitelli T, Chiusano S,et al.Scalable out-of-core itemset mining[J].Information Sciences,2015,293(4):146-162.
[6] Baralis E,Cerquitelli T,Chiusano S.A persistent HY-Tree to efficiently support itemset mining on large datasets[C]//Proceedings of the 2010 ACM symposium on applied computing.New York:ACM,2010:1060-1064.
[7] Adnan M,Alhajj R.DRFP-tree:disk-resident frequent pattern tree[J].Applied Intelligence,2009,30(2):84-97.
[8] Buehrer G,Parthasarathy S,Ghoting A.Out-of-core frequent pattern mining on a commodity PC[C]//Proceedings of the 12th ACM SIGKDD international conference on knowledge discovery and data mining.New York:ACM,2006:86-95.
[9] 张东霞,苗 新,刘丽平,等.智能电网大数据技术发展研究[J].中国电机工程学报,2015,35(1):2-12.
[10] 宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013,37(4):927-935.
[11] 彭小圣,邓迪元,程时杰,等.面向智能电网应用的电力大数据关键技术[J].中国电机工程学报,2015,35(3):503-511.
[12] 李建江,崔 健,王 聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[13] 孟小峰,慈 祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[14] 吴凯峰,刘万涛,李彦虎,等.基于云计算的电力大数据分析技术与应用[J].中国电力,2015(2):111-116.
Frequent Itemset Mining Algorithm for Multi-source Heterogeneous Information
LIU Zi-li1,FAN Jun-li2,CHEN Wen-wei3,WU Run-ze3
(1.Jincheng Power Supply Company,State Grid Shanxi Electric Power Company,Jincheng 048000,China; 2.Beijing Guodiantong Network Technology Co.,Ltd.,Beijing 100070,China; 3.School of Electrical and Electronic Engineering,North China Electric Power University,Beijing 102206,China)
Power grid dispatching has produced large amount of multi-source heterogeneous data with high complexity,and it is the inevitable development trend of intelligent dispatching that power data are transformed into knowledge by data mining.An analysis model of multi-source heterogeneous data based on big data in power dispatching and control system has been established and a frequent item set mining algorithm for processing big data has been proposed.The distributed statistics has been introduced into mining frequent item sets.Combining MapReduce programming and combinatorics,the target frequent item set mining has been completed via scanning transaction database with the proposed algorithm and thus there is no need to scan database again for mining while support degree is under variation.This algorithm has been promoted to solve the problem of multiple scanning transaction database and low mining efficiency.Compared with other frequent item set mining,the algorithm takes advantage of Hadoop in dealing with fault information transaction database.Experimental results show that the proposed algorithm performs well in expansibility and has less time cost with large transaction database and that the method adopted has provided useful knowledge for intelligent analysis and decision making with comprehensive optimal objectives of accuracy,security,economic and others,which single data source could not achieve.
intelligent dispatching;frequent itemsets;combinatorics;Hadoop
2016-06-20
2016-09-22 网络出版时间:2017-04-28
国家自然科学基金资助项目(51507063)
刘自力(1969-),男,电力高级工程师,研究方向为电力通信技术及网络规划。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1702.028.html
TP39
A
1673-629X(2017)06-0076-05
10.3969/j.issn.1673-629X.2017.06.016
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
小学教学研究(2022年5期)2022-04-28
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
电子制作(2019年14期)2019-08-20
计算机技术与发展(2019年7期)2019-07-23
商周刊(2019年1期)2019-01-31
计算机与数字工程(2018年10期)2018-10-23
