
基于共振峰曲线的语音信号动态特征提取方法
2017-06-27 08:14韩志艳
计算机技术与发展 2017年6期
韩志艳,王 健
(渤海大学 工学院,辽宁 锦州 121000)
基于共振峰曲线的语音信号动态特征提取方法
韩志艳,王 健
(渤海大学 工学院,辽宁 锦州 121000)
为了提高噪音环境下语音识别的鲁棒性,提出了一种基于共振峰曲线的语音信号动态特征提取方法。采用基于Hilbert-Huang变换的方法来估算预处理后的语音信号共振峰频率特征,然后按照从第一帧到最后一帧的帧序,将预处理后的每帧语音信号的第一共振峰频率特征值进行组合获得第一共振峰曲线,依此类推,获得第二共振峰曲线、第三共振峰曲线及第四共振峰曲线。对获得的每条共振峰曲线进行快速傅里叶变换获得线性频谱,然后再求取能量谱,计算对数能量和离散余弦变换。与MFCC方法相比,提取的语音信号动态特征具有时间相关性,揭示了语音信号前后以及相邻之间存在的密切关联,提高了语音识别的性能。
语音信号;动态特征;语音识别;特征提取;共振峰曲线
0 引 言
语音识别最基础最重要的开发环节是语音信号特征参数的提取。语音信号特征参数提取,即利用数学理论提取语音信号中所携带的有用信息,获得一个矢量序列。R.K.Potter等[1]早在二十世纪四十年代就提出了“可视语音”的概念,指出语谱图对语音信号有很强的描述能力,而且用语谱图进行了语音识别,即形成了最早的语音特征。到了五十年代,人们发现要想减少模板数目、运算量、存储量及提高识别率,就必须提取语音信号中能够反映语音特性的某些参数,滤除语音信号中的冗余信息,于是就出现了幅度特征、短时帧平均能量特征、短时帧过零率特征、短时自相关系数特征、平均幅度差函数特征等。但随着语音识别技术的发展,发现无论从稳定性还是区分能力,上述时域特征参数的表现都不是很好,于是开始利用频域特征参数进行识别,比如基音周期[2]、共振峰频率特征[3]、线性预测系数(LPC)特征[4]、线谱对(LSP)特征[5-6]、倒谱系数特征等[7]。目前基于全声道全极点模型的线性预测倒谱系数(LPCC)[8-10]和基于人耳听觉模型的梅尔倒谱系数(MFCC)[11-14]应用最为广泛。
但上面所述的特征参数反映的都是语音信号的静态特征,要使提取出的特征参数能更好地表达语音信号,就必须提取动态特征参数,语音信号的动态特性即为从连续几帧语音信号中提取的特征参数。动态特性是语音多样性的一部分,它不同于平稳的随机过程,具有时间相关性,比如可以通过静态特征的差分参数和加速度参数来获取。但它们并不能将动态信息挖掘得很充分,所以尚不能很好地反映语音信号的动态特性。
因此,提出了一种基于共振峰曲线的语音信号动态特征提取方法,构成的共振峰曲线具有时间相关性,揭示了语音信号前后以及相邻之间存在的密切关联。其中采用基于Hibert-Huang变换方法来估算预处理后的语音信号共振峰频率特征,其中用经验模态分解法(EMD)将信号分解成一组含有不同尺度的固有模态函数(IMF)分量,经分解得到的每一个IMF分量都代表了一个频率成分,这些频率成分可以有效突出信号的局部特性和细节变化,有助于快速有效地掌握信号的动态特征。
因此,语音特征的动态变化,可以通过动态特性来描述,而研究语音信号的动态特性,也是匹配新的语音动态模型、提高语音辅助工程性能的必然趋势。
1 共振峰特征提取
在语音识别技术应用领域,共振峰特征参数是重要的声学特征参数之一。长期以来该参数的提取都是基于人的发声系统是线性的和语音信号是短时平稳的两个基本假设。随着对语音发声机理的深入研究,发现在语音产生过程中存在着非线性,因此传统的线性共振峰特征参数估计方法的准确性就会受到影响[15]。另一方面,由于传统分析方法建立在短时平稳的假设上,对快速变化的共振峰特征参数的提取无能为力。所以研究者们越来越重视对随时间快速变化的动态信息的提取。
近年来,尽管也提出了一些新的参数提取方法,如逆滤波器法[16]和频域线性预测算法等[17],但这些方法都只是在算法和处理方法上进行改进,本质上仍属于线性分析方法的范畴,而且分析计算过程复杂,需要根据主观经验来调整参数。文中采用一种基于Hilbert-Huang变换(Hilbert-Huang Transform,HHT)的适用于非平稳、非线性信号处理,具有自适应特性的时间-频率分析新方法。
HHT包括2个基本步骤:第一步是经验模态分解(Empirical Mode Decomposition,EMD),它的核心是“筛选”,即从被分析信号中提取一族固有模态函数(Intrinsic Mode Function,IMF);第二步是计算信号的Hilbert谱(Hilbert Spectrum),将每个IMF与它的Hilbert变换构成一个复解析函数,并由此导出作为时域函数的瞬时幅值(能量)和瞬时频率。
通过EMD得到的每个IMF满足两个条件:
(1)在整个序列上,极值点个数和过零点个数相等或至多相差一个;
(2)分别连接其各局部极大值和局部极小值所形成的上、下2条包络线的均值在任一点处为零。
分解后得到信号x(t)的n个IMF分量c1(t),c2(t),…,cn(t)和剩余项rn(t),即有:
(1)
对每个ci(t),i=1,2,…,n,求其Hilbert变换di(t),然后计算相应的瞬时频率ωi(t)和幅值ai(t):
ωi(t)=dθi(t)/dt
(2)
(3)
其中,θi(t)为瞬时相位。
θi(t)=arctan[di(t)/ci(t)]
(4)
根据每个IMF的瞬时频率和幅值,可将信号表示为:
(5)
由于rn(t)不是一个常数就是一个单调函数,对信号分析和信息提取没有实质性的影响,所以式(5)中略去了式(1)中的剩余项。在时间-频率面上画出每个IMF以其幅值加权的瞬时频率曲线,这个时间-频率分布谱图就是Hilbert谱,记为H(ω,t)。
当采用HHT方法估计语音信号的共振峰频率时,为了避免和抑制各个共振峰分量在EMD过程中产生互相干扰,需要事先对各个共振峰分量进行分离,对分离后的各个共振峰分量作EMD,最后求出相应的共振峰频率及其随时间的变化曲线。
2 动态特征提取
动态特征提取流程如图1所示。
其具体步骤如下:
步骤1:利用麦克风输入语音数据,然后以11.025 kHz的采样频率、16 bit的量化精度进行采样量化,获得相应的语音信号。然后利用一阶数字预加重滤波器对获取的语音信号进行预加重处理,其中预加重滤波器的系数取值范围为0.93~0.97。接下来以帧长256点的标准进行分帧处理,并对分帧后的语音信号加汉明窗,再利用短时能零积法进行端点检测。短时能零积方法如下:
短时能量与相应的短时过零率之积称为短时能零积,每一帧的短时能量En和短时过零率Zn以及短时能零积EZn的定义分别为:
(6)
(7)
EZn=En*Zn
(8)
其中,n为语音信号的第n帧;N为每一帧的长度;sw(k)为加窗语音信号。
用短时能零积法进行语音端点检测的步骤如下:
(1)确定噪声的门限阈值。
无音片段主要包括的是背景噪声,由于录音开始阶段往往有一段无音区,所以在实验室环境下通常取最开始的5帧信号作为背景噪声的分析,对这5帧信号按式(6)和式(7)分别按帧计算En和Zn,并按式(8)计算EZn,通过多帧平均,就得到了平均短时能零积EZ,并按照式(9)确定噪声的门限阈值TH。
TH=k×EZ
(9)
其中,k为经验值,通常取1.2。

图1 动态特征提取流程图
(2)利用短时能零积进行语音端点检测。
计算每帧录音信号的短时能零积EZn,与噪声的门限阈值TH做比较。EZn大于TH,就以该帧的帧号作为有音片段的起点N1,表明进入了有音片段。如果由过去帧已经得到了N1,那么当EZn小于TH时,就以该帧的帧号作为有音片段的终点N1。相反,如果N1还未得到,那么当EZn小于TH时,表明当前帧仍处于无音片段。
步骤2:计算共振峰频率特征参数,其中获得的每帧语音信号的第一共振峰特征值为F1、第二共振峰特征值为F2、第三共振峰特征值为F3和第四共振峰特征值为F4。
步骤3:构成共振峰曲线。具体为:
(1)按照从第一帧到最后一帧的帧序,将预处理后的每帧语音信号的第一共振峰频率特征值F1进行组合,获得第一共振峰曲线x1(n),n=0,1,…,N-1,N为语音信号的帧数;
(2)按照从第一帧到最后一帧的帧序,将预处理后的每帧语音信号的第二共振峰频率特征值F2进行组合,获得第二共振峰曲线x2(n);
(3)按照从第一帧到最后一帧的帧序,将预处理后的每帧语音信号的第三共振峰频率特征值F3进行组合,获得第三共振峰曲线x3(n);
(4)按照从第一帧到最后一帧的帧序,将预处理后的每帧语音信号的第四共振峰频率特征值F4进行组合,获得第四共振峰曲线x4(n)。
步骤4:对获得的第一、第二、第三和第四共振峰曲线进行快速傅里叶变换,获得每条共振峰曲线的线性频谱。
(10)
其中,Xi(k)表示第i条共振峰曲线进行快速傅里叶变换后得到的线性频谱,i=1,2,3,4,k=0,1,…,N-1,N为语音信号的帧数;xi(n)表示第i条共振峰曲线。
步骤5:根据线性频谱获得每条共振峰曲线的能量谱。即取上述线性频谱Xi(k)模的平方来获得相应的能量谱Si(k):
(11)
步骤6:根据能量谱获得每条共振峰曲线的对数能量。即为了使结果对噪声有更好的鲁棒性,将获得的能量谱Si(k)取对数,即可获得对数能量Li(k):
Li(k)=log(Si(k))
(12)
步骤7:对上述对数能量进行离散余弦变换,获得倒频谱域,即获得语音信号动态特征参数:
(13)
其中,Ci(t)表示第i条共振峰曲线的动态特征参数,i=1,2,3,4;t=1,2,…,T,T表示设定的倒谱系数个数,取值范围为12~16。
3 仿真实验及结果分析
采用50个典型的汉语词汇进行实验。由于考虑识别系统容易受环境噪声、信道变化和说话人变化等因素的影响,因此,训练集采用安静环境下的语音数据,而测试集采用含有噪声的数据。
为了验证该特征参数对不同说话人变化的鲁棒性,训练集数据由前后两次录成,共50人,每人每词发音一遍,共获得5 000个数据,测试集数据也是分两次录成,共30人,每人每词发音一遍,共3 000个数据;为了验证该特征参数对不同信道变化的鲁棒性,每次使用不同的麦克风来录音;为了验证该特征参数对不同环境噪声变化的鲁棒性,在测试集的每个语音中手工加入四种噪声,包括:白噪声、粉噪声、街道噪声、坦克噪声,构成信噪比为15 dB,10 dB,5 dB,0 dB,-5 dB的含噪语音信号。采用基于遗传算法改进的小波神经网络作为分类器[18-19]。图2~5为采用与文中算法相同条件的MFCC方法和文中方法分别在白噪声、粉噪声、街道噪声和坦克噪声干扰下的系统识别性能曲线。

图2 白噪声环境下的系统识别性能曲线

图3 粉噪声环境下的系统识别性能曲线

图4 街道噪声环境下的系统识别性能曲线
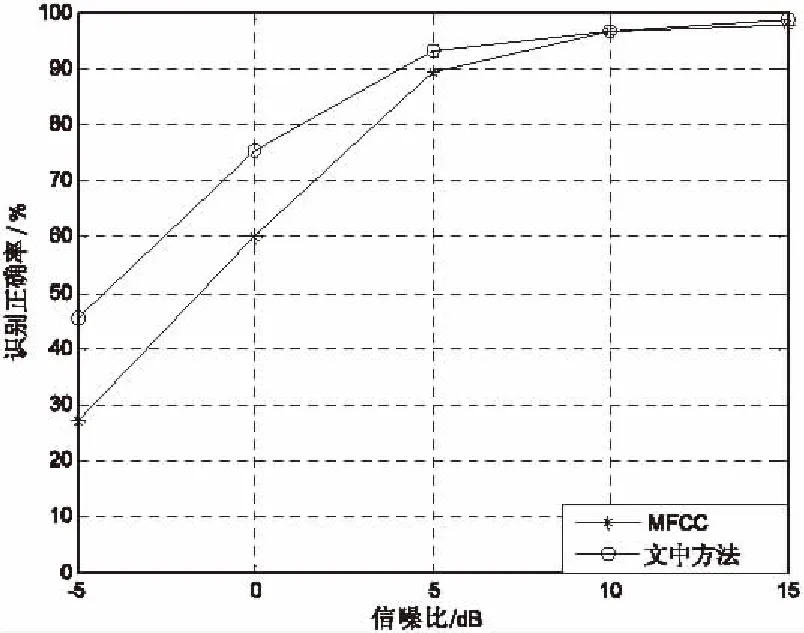
图5 坦克噪声环境下的系统识别性能曲线
从图中可以看出,在信噪比较低时,文中方法与MFCC方法相比识别率提高了很多。这是因为文中方法构成的共振峰曲线具有时间相关性,揭示了语音信号前后以及相邻之间存在着密切关联,这一特性,使得在强噪声环境下应用语音识别技术成为了可能。
4 结束语
文中提取的语音信号动态特征,采用基于Hibert-Huang变换的方法来估算预处理后的语音信号共振峰频率特征,其中用EMD将信号分解成一组含有不同尺度的IMF分量,经分解得到的每一个IMF分量都代表了一个频率成分,这些频率成分可以有效突出信号的局部特性和细节变化,有助于快速有效地掌握信号的动态特征。相比于传统的MFCC方法,大大提高了语音识别的性能。但是语音信号的某一特征中一般只包含部分语音信息,所以采用动静态特征参数的组合,这样动态信息和静态信息形成了互补,当各组合参数间相关性不大时,会有很好的效果。
[1] Potter R K,Kopp G A,Green H C.Visible speech[M].New York:Van Nostrand,1947.
[2] 赵瑞珍,宋国乡.基音检测的小波快速算法[J].电子科技,1998,43(1):16-19.
[3] 黄 海,陈祥献.基于Hilbert-Huang变换的语音信号共振峰频率估计[J].浙江大学学报:工学版,2006,40(11):1926-1930.
[4] Christensen R L,Sreong W J,Palmer E P.A comparison of three methods of extracting resonance information from predictor coefficient coded speech[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1976,24(1):8-14.
[5] Girin L. Joint matrix quantization of face parameters and LPC coefficients for low bit rate audiovisual speech[J].IEEE Transactions on Speech and Audio Processing,2004,12(3):265-276.
[6] Trentin E, Gori M. Robust combination of neural networks and hidden Markov models for speech recognition[J].IEEE Transactions on Neural Networks,2003,14(6):1519-1531.
[7] Hong K K,Rose R C.Cepstrum-domain model combination based on decomposition of speech and noise for noisy speech recognition[C]//IEEE international conference on acoustics,speech,and signal processing.[s.l.]:IEEE,2002:209-212.
[8] Songhita M,Tusharkanti D,Partha S,et al.Comparison of MFCC and LPCC for a fixed phrase speaker verification system,time complexity and failure analysis[C]//International conference on circuit,power and computing technologies.[s.l.]:[s.n.],2015:1-4.
[9] Yuan Y J,Zhao P H,Zhou Q.Research of speaker recognition based on combination of LPCC and MFCC[C]//International conference on intelligent computing and intelligent system.[s.l.]:[s.n.],2010:765-767.
[10] Zhu J C,Liu Z L.Analysis of hybrid feature research based on extraction LPCC and MFCC[C]//10th international conference on computational intelligence and security.[s.l.]:[s.n.],2014:732-735.
[11] Kopparapu S K,Laxminarayana M.Choice of Mel filter bank in computing MFCC of a resampled speech[C]//10th international conference on information sciences signal processing and their applications.[s.l.]:[s.n.],2010:121-124.
[12] 周 萍,李晓盼,李 杰,等.混合MFCC特征参数应用于语音情感识别[J].计算机测量与控制,2013,21(7):1966-1968.
[13] 庞 程,李晓飞,刘 宏.基于MFCC与基频特征贡献度识别说话人性别[J].华中科技大学学报:自然科学版,2013(S1):108-111.
[14] 沈 燕,肖仲喆,李冰洁,等.采用GW-MFCC模型空间参数的语音情感识别[J].计算机工程与应用,2015,51(10):219-222.
[15] 张家騄.论语音技术的发展[J].声学学报,2004,29(3):193-199.
[16] Watanabe A.Formant estimation method using inverse-filter control[J].IEEE Transactions on Audio Processing,2001,9(4):317-326.
[17] Rao P,Barman A D.Speech formant frequency estimation: evaluating a nonstationary analysis method[J].Signal Processing,2000,80(8):1655-1667.
[18] 韩志艳,伦淑娴,王 健.基于遗传小波神经网络的语音情感识别[J].计算机技术与发展,2013,23(1):75-78.
[19] 韩志艳,伦淑娴,王 健.语音信号鲁棒特征提取及可视化技术研究[M].沈阳:东北大学出版社,2012.
Dynamic Feature Extraction for Speech Signal Based on Formant Curve
HAN Zhi-yan,WANG Jian
(College of Engineering,Bohai University,Jinzhou 121000,China)
In order to improve the robustness of speech recognition in noise environment,a dynamic feature extraction for speech signal based on formant curve is put forward.It uses Hilbert-Huang transform to estimate speech signal formant frequency characteristics after preprocessing,and then gets the first formant curve by combining the first formant frequency characteristics of each frame from the first frame to the last frame,and so forth,gets the second,the third and the fourth formant curve.And then takes Fast Fourier Transform for each formant curve to obtain linear spectrum,and calculates the energy spectrum,logarithmic energy and discrete cosine transform.Compared with the method of MFCC,the proposed dynamic feature of speech signal has the time correlation,revealing the close correlation between the speech signal frames,improving the performance of speech recognition.
speech signal;dynamic feature;speech recognition;feature extraction;formant curve
2016-07-29
2016-11-03 网络出版时间:2017-04-28
国家自然科学基金资助项目(61403042,61503038);辽宁省教育科研项目(L2013423)
韩志艳(1982-),女,博士,副教授,研究方向为语音识别、情感识别。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1704.084.html
TP391.4
A
1673-629X(2017)06-0072-04
10.3969/j.issn.1673-629X.2017.06.015
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
金桥(2022年1期)2022-02-12
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
当代陕西(2018年12期)2018-08-04
人大建设(2017年6期)2017-09-26
电子技术与软件工程(2016年22期)2016-12-26
