
基于刷卡数据和高斯混合聚类的地铁车站分类
2017-06-21 15:05:43岳真宏陈峰王子甲黄建玲汪波
都市快轨交通 2017年2期
岳真宏,陈峰,2,王子甲,2,黄建玲,汪波
(1.北京交通大学土木建筑工程学院,北京100044;2.北京市轨道交通线路安全与防灾工程技术研究中心,北京100044;3.北京市交通信息中心,北京100161)
基于刷卡数据和高斯混合聚类的地铁车站分类
岳真宏1,陈峰1,2,王子甲1,2,黄建玲3,汪波3
(1.北京交通大学土木建筑工程学院,北京100044;2.北京市轨道交通线路安全与防灾工程技术研究中心,北京100044;3.北京市交通信息中心,北京100161)
合理的城市轨道交通车站分类对车站的规划设计及客流预测有重要作用。基于刷卡数据提取出行时间、频次、车票类型等反映车站客流特性的若干变量,运用主成分分析法(PCA)和高斯混合模型(GMM)进行车站聚类。该聚类方法不仅可以识别车站类别,同时可以根据后验概率确定混合类型的车站。以北京地铁为例,将全网233个车站分为4类,利用地理信息系统(GIS)工具可视化分类结果,并叠加地理信息描述各类车站的特征,直观地展示了部分混合性质的车站。与K-均值聚类结果比较显示,GMM方法可以更好地解释多种特性混合的车站类型。
地铁;车站分类;刷卡数据;高斯混合模型;地理信息系统
城市轨道交通车站的分类对车站个性化设计有重要意义。目前,国内对于站点分类的研究主要集中在以节点导向的分类和以场所导向的分类[1]。大多数分类仅仅基于定性分析[24],而定量分析也有很大的局限性[56]。首先采用的数据量有限,不能全面反映车站的特性;其次分类结果往往是单纯的几类车站,不能反映车站可能同时属于多种类型的实际。这种问题在基于用地性质或客流特性的分类上表现更为突出。如果车站紧邻同等开放强度的居住用地或商业用地,非此即彼的分类可能掩盖一些重要信息,不能很好地指导站点的个性化规划设计。
既有研究表明,可以从交通智能卡数据中挖掘乘客出行时空分布、频次等关键信息。这些信息可以为车站分类提供丰富的数据支撑。本文针对目前车站分类存在的问题,基于刷卡数据,引入主成分分析法和GMM聚类方法,建立了基于车站客流特性的具有一定柔性的车站分类方法。该方法不仅能从大量刷卡数据中提取最有效的信息,同时能给出车站从属于某种特定类别的概率,以判断车站是否为混合类型及其回合程度。本文采用该方法对北京地铁网的所有车站进行了分类并利用GIS工具可视化了分类结果,取得了较好的效果。这种分类可以为轨道交通规划、设计者基于客流特性和车站承担的功能对站内及站外导向、便民服务等设施的配置提供数据支持。
1 基于卡数据的客流特征指标选取
城市轨道交通车站是乘客乘降的场所,是城市交通网络的重要节点和集散点。对车站进行聚类分析,首先要从刷卡数据中提取出反映车站客流特性的具有代表性的相关因素作为初始变量。
1.1 刷卡数据描述
智能卡数据一般包含了卡号、上车站点、上车时间、下车站点、下车时间等信息,这些信息中包含了乘客出行的时空特性和卡属性。在车站层次对客流的时空特性进行分析,获得了早晚高峰客流分布、通勤客流分布、工作日和周末客流差异等特性,对卡属性进行分析得到一票通的比例,为初始变量的选取提供支撑。
1.2 初始变量的提取与描述
综合考虑通勤客流、早晚高峰客流特性、工作日与周末客流差异、一票通的比例等因素的影响,选取以下13个因素作为聚类分析的初始变量。各个变量的编号及主要反映的车站客流信息如下:
1)工作日早高峰进站客流量/工作日全天进站客流量(F1)、工作日晚高峰进站客流量/工作日全天进站客流量(F2)、工作日早高峰出站客流量/工作日全天出站客流量(F3)、工作日晚高峰出站客流量/工作日全天出站客流量(F4):这4个变量主要反映车站早晚高峰的客流特性,通常早高峰取6:30—9:30,晚高峰取17:00—20:00;
2)工作日全天客流量/周末全天客流量(F5):反映车站工作日和周末的客流差异;
3)工作日ABBA_A客流量/工作日全天客流量(F6)、工作日ABBA_B客流量/工作日全天客流量(F7):反映车站通勤客流的特性,其中,ABBA_A客流量表示满足一天中从A站进站B站出站再从B站进站A站出站的乘客在A站的客流量,ABBA_B客流量表示满足一天中从A站进站B站出站再从B站进站A站出站的乘客在B站的客流量;
4)一票通比例(F8):表示使用临时卡进出站客流量与全天客流量的关系;
5)工作日单次进出站客流量/工作日全天客流量(F9):表示一天内在某车站内仅仅进站一次或出站一次的客流量与全天客流量的关系;
6)周末上午8:00—12:00出站客流量/周末全天出站客流量(F10)、周末下午3:00—7:00进站客流量/周末全天进站客流量(F11)、周末晚8:00—10:00进站客流量/周末全天进站客流量(F12)、周末晚8:00—10:00出站客流量/周末全天出站客流量(F13):反映了周末各个时段的进站(或出站)客流量与周末全天进站(或出站)客流量的关系。
2 GMM方法
将城市轨道交通车站分为K类,每一类车站均由一个单高斯分布生成,然而具体车站属于哪个单高斯分布未知,因此假设每一个车站分别由K个单高斯分布的混合模型表示,即轨道交通车站由高斯混合模型生成的概率密度函数为:

式中,x是维度为d的向量;k为单高斯模型的数量;πk为第k个单高斯分布被选中的概率;μk,∑k为第k个单高斯分布的均值和方差;η(x|μk,∑k)为第k个单高斯分布的概率密度函数,可表示为:
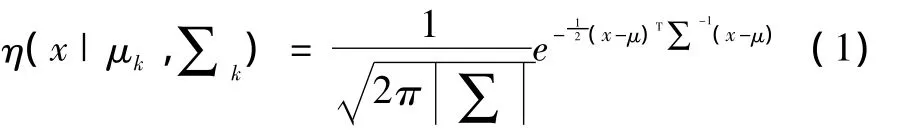
利用高斯混合模型进行聚类的一般步骤如下:
1)估计数据由每个单高斯分布生成的概率,对于每个数据xi来说,它由第k个单高斯分布生成的概率为:
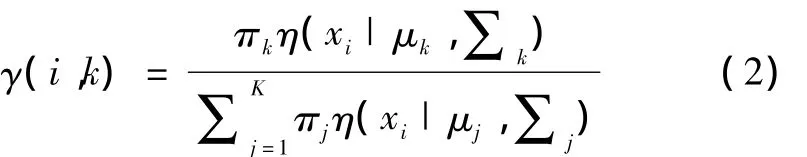
2)估计每个单高斯分布的参数,通过极大似然估计求出对应的参数值:
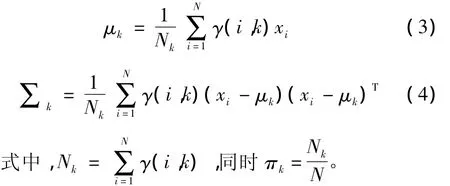
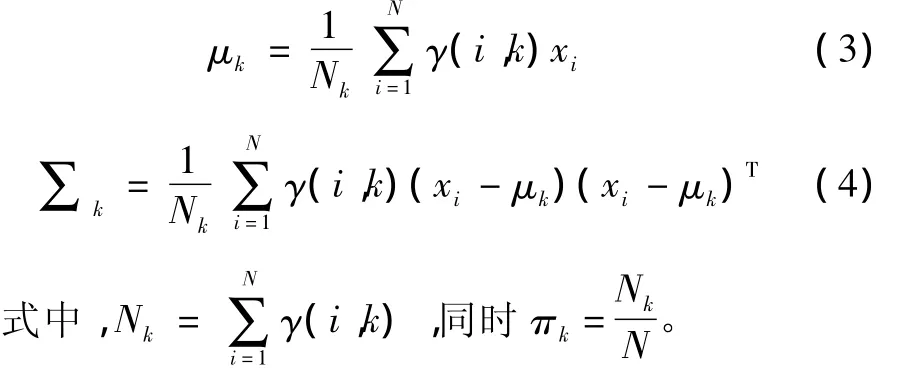
3)重复迭代以上两步,直到似然函数的值收敛为止。
3 应用案例
本文以北京市轨道交通2014年10月13日至19日一周的刷卡数据为依据进行客流分析,刷卡数据经过筛选清理后,可用于车站客流特性分析。
3.1 公共因子的提取
选取了与车站客流特征相关的13个初始变量进行车站聚类分析,由于选取的初始变量较多,变量之间可能存在较大的相关性,因此需要对变量进行降维处理以从多个变量中提取隐藏的公共因子。本次公共因子的提取选择主成分分析法从众多的初始变量中提取出主成分变量。
在运用主成分分析法降维之前,需要进行KMO检验和Bartlett检验以考察结构效度,结果如表1所示,KMO检验系数0.867,概率值为0.000,结构效度较高,可以进行主成分分析。

表1 KMO和Bartlett的检验Tab.1 Tests of KMO and Bartlett
基于主成分分析法提取隐藏的公共因子,从13个反映车站客流信息的初始变量中提取出初始特征值大于1的2个成分。这2个成分可以解释原信息中81.443%的信息量,可以较好地提取出客流信息。因此,可以选用这2个成分作为主成分分析法的公共因子。
3.2 GMM聚类结果及分析
以提取出的2个公共因子为聚类变量,利用GMM模型进行聚类,分别选取K值为3,4,5,6,将不同的聚类结果进行分析比较,得知当K=4时聚类结果更符合实际情况,因此将全网233个车站分为4类进行聚类分析。刷卡数据中提取出来的信息不含车站的社会属性等定性的描述,而刷卡数据反映的交通枢纽和旅游商业区性质的车站具有相似的分类指标,因此文中将交通枢纽和旅游商业区归为一类,后续研究可以进一步做定性区分。
根据GMM模型将北京地铁全网233个车站分为4类,则各类质心附近的典型车站初始变量指标如表2所示。
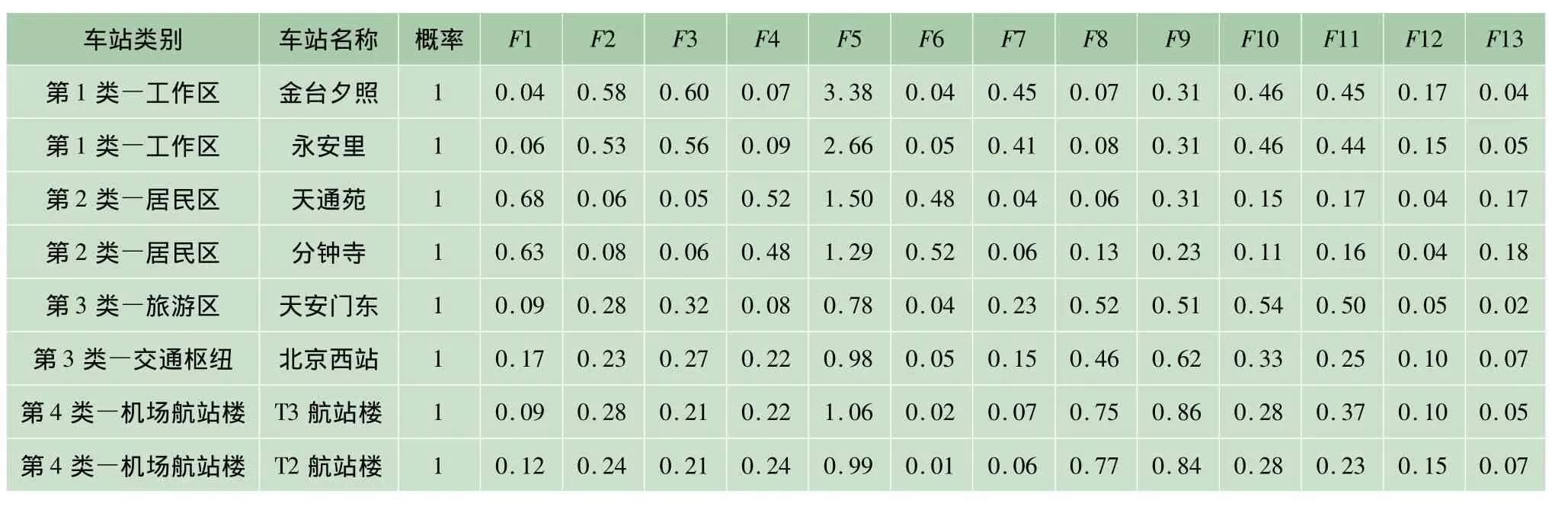
表2 质心附近典型车站初始变量指标Tab.2 Initial variable indicators of typical stations near the center ofmass
基于GMM模型进行站点分类的依据为模型产生的后验概率,站点聚类结果由GIS工具展示如图1。
对聚类结果进行分析,所得结论描述如下:
1)第1类站点为工作区车站,如金台夕照站、国贸站、中关村站、永安里站、西二旗站、生物医药基地站。该类车站多分布于市二环至四环之间,从地理位置上看,北城工作区站点数量明显高于南城工作区站点数量,工作日出行客流多为“先出后进”的通勤客流,周末全天客流分布较平缓,属于特征显著的工作区站点;
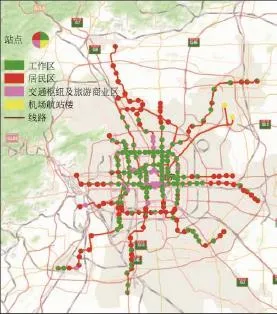
图1 站点GMM聚类GIS展示Fig.1 The stations visualization with GIS based on GMM clustering
2)第2类站点为居住区车站,如天通苑站、生命科学园站、苹果园站等。该类站点多为各条线路远离市中心的端头站,乘客早上乘坐地铁上班,晚上乘坐地铁回家,居住区域车站周边区域多体现“睡城”特性,八通线、昌平线所属车站均为该类型车站;
3)第3类站点为交通枢纽类车站和旅游区车站,如北京西站、北京站、前门站、天安门东站、天安门西站。该类车站有大量临时客流,属于外地乘客聚集地,北京站和北京西站是大型火车站,前门站、天安门东站、天安门西站属于旅游景点类车站;
4)第4类站点为机场T2、T3航站楼站。这两个站点为一票通比例超高的对外交通枢纽站,工作日临时客流量占工作日全天客流量的85%左右,较其他对外交通枢纽表现出更明显的特性。
3.3与K-均值聚类的比较
K-均值聚类算法是通过迭代算法,逐次更新各类的中心值,直至得到最好的聚类结果。以提取出的两个公共因子为聚类变量,利用K-均值聚类算法进行聚类,得到的聚类结果由GIS展示,如图2所示。
基于GMM模型产生的后验概率来识别混合型车站,部分混合型车站的后验概率及对应的K-均值聚类结果如表3所示。
比较GMM聚类结果和K-均值聚类结果,两者的车站分类基本相同,但基于GMM的聚类是依后验概率进行车站聚类,对于混合程度较高的车站,单纯的类别划分并不能准确地表示该车站的特征,因此对于车站分类,GMM算法优于K-均值算法。
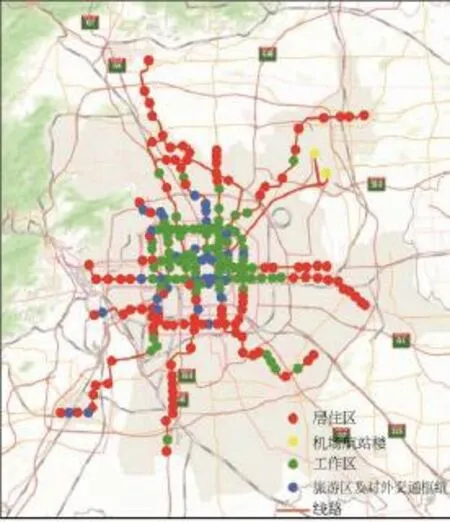
图2 站点K-均值聚类GIS展示Fig.2 The stations visualization with GISbased on K-means clustering
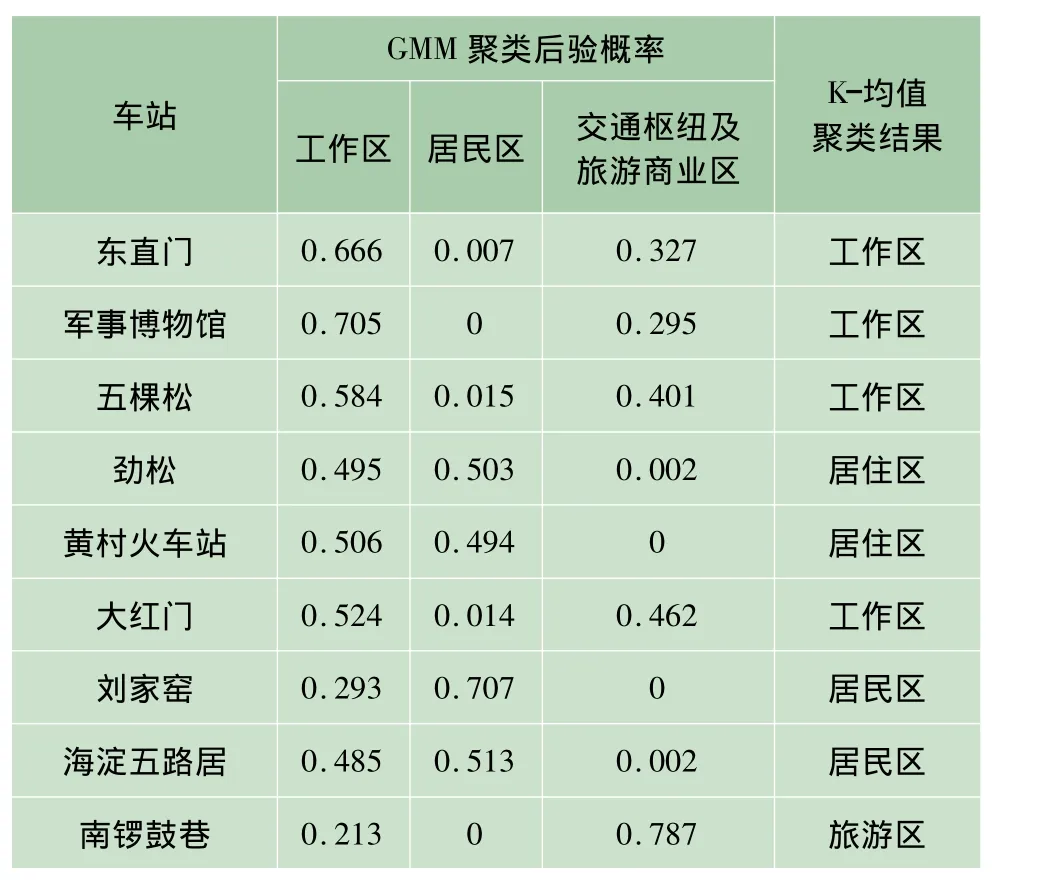
表3 部分混合车站GMM聚类与K-均值聚类比较Tab.3 Partialm ixed stations’com parative analysis between GMM clustering and K- means clustering
4 结论
本文提出了一种基于刷卡数据和GMM模型的地铁车站聚类方法。其中,刷卡数据为地铁站点分类研究提供了一种全新高效的数据来源,考虑一票通比例、单次出行比例、早晚高峰特性与通勤客流特性、工作日与周末客流差异等因素后利用GMM模型进行车站聚类,并依据模型产生的后验概率识别了混合类型的车站。
该聚类与K-均值聚类结果比较表明,GMM聚类方法对混合类型车站的识别有良好的效果,较传统单一的车站分类模式更具有现实意义,可为站点周边土地的开发利用与城市空间结构的识别提供技术支持。
[1]邵滢宇,丁柏群.基于聚类分析的地铁站点分类:以哈尔滨地铁1号线为例[J].森林工程,2015,31(3):106- 111.
SHAO Yingyu,DING Baiqun.Metro stations classification based on clustering analysis:A case study of harbin metro line 1[J].Forest engineering,2015,31(3):106- 111.
[2]王俊.地铁车站综合开发及影响的初步探讨[D].成都:西南交通大学,2000.
WANG Jun.Primarily study ofmetro stations’comprehensive development and influence[D].Chengdu:Southwest Jiaotong University,2000.
[3]惠英.城市轨道交通站点地区规划与建设研究[J].城市规划汇刊,2002(2):30 33.
HUIYing.Planning and construction of the areas round the rail transportation station[J].Urban planning forum,2002 (2):30- 33.
[4]金磊,彭建,柳昆,等.城市地铁车站分类理论及方法研究[J].地下空间与工程学报,2010,6(Z1):1339 1342.
JIN Lei,PENG Jian,LIU Kun,et al.Sorting theory and investigation of urban metro station[J].Chinese journal of underground space and engineering,2010,6(Z1):1339 1342.
[5]李向楠.城市轨道交通站点分类的聚类方法研究[J].铁道标准设计,2015,35(4):19- 23.
LIXiangnan.Classifying urban rail transit stations using cluster analysis[J].Railway standard design,2015,35 (4):19- 23.
[6]罗芳,柴蕾,邱星.基于交通换乘的城市轨道交通车站分类研究[J].洛阳理工学院学报(自然科学版),2015,25(3):45 48.
LUO Fang,CHAI Lei,QIU Xing.Classification of urban rail transit station based on traffic transfer[J].Journal of Luoyang Institute of Science and Technology(natural science edition),2015,25(3):45- 48.
(编辑:曹雪明)
Classifications of Metro Stations by Clustering Smart Card Data Using the Gaussian Mixture Model
YUE Zhenhong1,CHEN Feng1,2,WANG Zijia1,2,HUANG Jianling3,WANG Bo3
(1.School of Civil Engineering,Beijing Jiaotong University,Beijing 100044; 2.Beijing Engineering and Technology Research Center of Rail Transit Line Safety and Disaster Prevention,Beijing 100044;3.Beijing Transportation Information Center,Beijing 100161)
Reasonable classification of urban rail transit stations is of great significance to station planning,designing and ridership forecasting.This research focused on the characteristics of station ridership and proposed travel time,frequency,ticket type and other variables extracted from smart card data.Accordingly,Principal Component Analysis(PCA)and the Gaussian M ixture Model(GMM)were used in clustering and classifying stations.Themetro stations are classified into arbitrary types and m ixed types using the posterior probability generated by GMM,which revealed to what extent and by which arbitrary types a mixed station wasmixed.Beijing was selected as a case and 4 clusters were determined for the 233 stations on Beijingmetro network.The classification resultswere visualized by GISand all types of stationswere characterized by superposing geographic information,meanwhile,parts of m ixed stations were presented intuitively.At last,comparative analysis was conducted between GMM and K-means algorithm and the results showed thatGMM can explainmixed stationsw ith various characteristics preferably.
metro;station classification;smart card data;Gaussian M ixture Model;geographic information system
U231.4
A
1672- 6073(2017)02- 0048- 04
10.3969/j.issn.1672 6073.2017.02.010
2016- 05 03
2017 01 09
岳真宏,男,硕士研究生,主要从事城市轨道交通规划与设计,14121208@b jtu.edu.cn
王子甲,男,博士,讲师,主要从事城市轨道交通规划与设计,zjwang@b jtu.edu.cn
中央高校基本科研业务费专项资金资助(2016YJS102)
猜你喜欢
精密制造与自动化(2018年1期)2018-04-12 07:42:49
小学生·新读写(2016年5期)2016-05-14 13:48:40
中国铁道科学(2015年1期)2015-06-26 08:33:56
作文大王·笑话大王(2015年7期)2015-05-30 10:48:04
奥秘(2014年8期)2014-08-30 06:32:04
城市道桥与防洪(2014年6期)2014-02-27 07:26:48
中国工程咨询(2013年1期)2013-02-13 02:48:04
商(2012年14期)2013-01-07 07:46:16
资源导刊(2011年4期)2011-08-15 00:51:44
故事作文·低年级(2009年7期)2009-11-23 02:46:10
