
一种基于ARM的异构CPU—GPU集群调度模型
2017-06-20 08:08李瑞林周亦敏
软件导刊 2017年4期
李瑞林+周亦敏
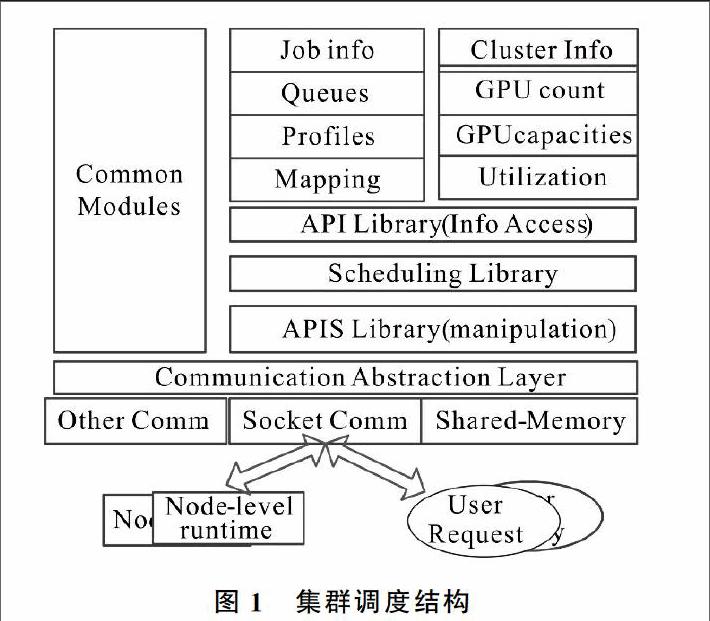

摘要:随着技术的发展,基于异构的CPU-GPU计算系统成为高性能计算趋势。但是,异构计算面临着扩展性、负载均衡等问题。提出了一个集群调度模型,并结合GPU虚拟化运行,设计了分层集群资源管理框架,该框架允许异构CPU-GPU集群有效利用。实验结果表明,通过利用有效资源,调度框架无论是在应用程序吞吐量还是延迟上都优于现有批处理调度程序关键词:高性能计算;异构CPU-GPU集群;ARM;调度模型DOI:10.11907/rjdk.162656中图分类号:TP303文献标识码:A 文章编号:16727800(2017)0040022030引言 基于CPU-GPU的异构计算系统逐渐成为HPC领域新的研究方向,许多基于 CPU-GPU 的异构计算机系统应用表现出良好性能。但是,由于各种原因制约,异构高性能计算仍然面临许多问题,其中主要的问题是开发程序困难,特别是扩充到集群规模层时这个问题尤为突出。传统的集群资源管理有一定性能限制:如负载不均衡、GPU共享资源有限、有限的GPU虚拟化等,往往不方便配置调度策略。最佳调度策略依赖于性能目标、集群硬件、软件配置与应用程序等。因此,集群调度管理在异构环境中显得尤为重要。 本文设计一个新的集群调度模型,并将其与节点层GPU虚拟运行整合。这个模型能够很好地利用异构CPU-GPU集群[14]各自的优势,可自行配置,管理员能够轻松定义调度策略,满足集群配置、应用程序以及用户目标。1集群调度 本文提供一种有效的CPU-GPU集群调度模型。異构环境需要在两次粒度上进行调度:①任务要被映射到计算节点上(粗粒度调度);②特定库的调用要映射到GPU集群上(细粒度调度)。为了使它具有可扩展性,要设计一个异构环境。 集群调度[56]主要目标是:①运行集群调度策略;②运行节点层组件;③允许管理员自行定义调度策略。1.1调度结构 图1是集群调度模型框架[78]。该框架的下层实现集群要求的通信机制调度程序以及用户与节点层运行时的交互。接口提供了Socket与节点内通信、共享内存与节点内通信。调度组件包括调度API、(用户自定义)共享库调度策略、数据结构存储和集群相关信息的访问。1.2调度API 表1显示调度API的主要原始事项,管理员必须创建自定义调度库。调度接口提供两个机制:API和回调函数[9]。〖JP〗 API函数:允许API函数(见表1)查询节点状态、分配执行工作节点、收集分析信息等。API函数分为3类:一般API、节点层运行管理API、作业和队列管理API;通用API进行调度库维护工作;节点层管理的API函数可以相互控制在组件节点层上,具有查询和管理功能;作业和队列管理API函数任务调度的目的是为了限制资源,将上述信息收集分配给当前运行的作业,然后在特定节点上安排运行。
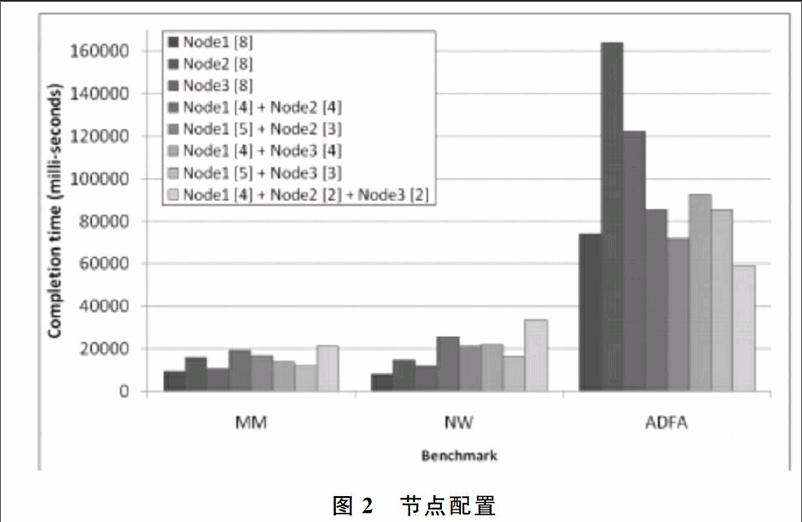
2集群调度策略 提出两种调度策略:①异构CPU-GPU集群调度;②减少延迟[1011]。前者目的是在共享通信之间使整体吞吐量最大化;后者尽量缩短等候时间。2.1集群调度库 现代高性能计算集群配备有多个节点的GPU,它提高了节点的整体性能和利用率,但降低了队列作业时间。 在3个节点、3个应用程序进行实验,执行8个进程集群。每个实验必须使用测试进程映射1-3个节点,每个节点包含2-4 GPU。图2显示性能的3个指标与8个运行应用程序在不同的节点配置,显示出执行时间有不同的映射策略。每个节点上的进程数在地图上显示在方括号内。 MM和NW是通信密集型应用程序,而ADFA是计算密集型应用程序。从图中可以看出,通信密集型[12]的应用程序不能扩展到更多节点,而一个计算密集应用程序已经分配了多个大规模的性能节点。2.2延迟减少调度 通过利用GPU的共享提高整体的吞吐量。如在图2中发现应用程序有不同的运行时间:MM和NW是短期运行的作业,而ADFA是长期运行,这些应用程序在运行时隔离。当不同的作业竞争资源时,长时间运行的作业会严重降低性能。具体来说,短期作业和长期作业以同样的方式可能会造成资源利用不公平。2.3节点层运行 节点层的运行时间用一个灵活的调度来虚拟化[1316],最终用户在GPU上能重现映射过程。 图3显示节点层运行时的状态,由连接管理器、背景队列、调度、虚拟的GPU、内存管理器和队列监视器等组成。3实验结果3.1实验设置 两个集群实验配置:8个工作站集群各配备一个四核CPU和一个低端的GPU,高端集群包括3个HPC服务器,每个配备有超线程8或12核CPU,2至4的NVIDIA GPU。3.2异构负载实验 对CPU-GPU异构工作时的负载方案进行评估。构造一个批处理调度库模拟转矩,在一个循环方式下分配各项工作GPU,而不在节点层的GPU上共享。 图4、图5显示标准吞吐量、平均质量及服务性能。通过改善公平性,减少延迟调度策略,合理调度长期和短期运行作业,提高了平均服务质量,同时增大了吞吐量。4结语 通过研究典型的集群调度模型[17],提出了一种基于异构CPU-GPU集群的分层调度框架。系统包括调度API,允许管理员自定义集群级调度策略和配置,在节点层使用共享和调度方案。提出两个集群级调度方案(GPU共享和减少延迟调度),使用两种异构集群和计算密集型应用程序对其进行测试。研究结果表明,调度模型改进了传统的间歇调度情况,有一定实用价值。参考文献:[1]陈钢.众核GPU体系结构相关技术研究[D].上海:复旦大学,2011.[2]吴佳骏.多核多线程处理器上任务调度技术研究[D].北京:中国科学院计算技术研究所,2006.[3]M BECCHI,K SAJJAPONGSE,I GRAVES,et al.A virtualmemory based runtime to support multitenancy in clusters with GPUs[C].In Proceedings of the 21st internationalsymposium on HighPerformance Parallel and Distributed Computing,Delft,The Netherlands,2012:97108.[4]V T RAVI,M BECCHI,W JIANG,et al.Scheduling concurrent applications on a cluster of CPUGPU nodes[C].In Proceedings of the 12th IEEE/ACM International Symposium on Cluster,Cloud and Grid Computing(CCGRID),2012:140147.[5]耿晓中.基于多核分布式环境下的任务调度关键技术研究[D].长春:吉林大学,2013.[6]朱福喜,何炎祥.并行分布计算中的调度算法理论与设计[M].武汉:武汉大学出版社,2003:6068.[7]KITTISAK SAJJAPONGSE,TEJASWI AGARWAL,MICHELA BECCHI.A flexible scheduling framework for heterogeneous CPUGPU clusters[EB/OL].https://www.researchgate.net/profile/Kittisak_Sajjapongse.[8]吴恩华,柳有权.基于图形处理器(GPU)的通用计算[J].计算机辅助设计与图形学学报,2004,16(5):601612.[9]V T RAVI,M BECCHI,G AGRAWAL,et al.ValuePack:valuebased scheduling framework for CPUGPUclusters[C].In Proceedings of the International Conferenceon High Performance Computing,Networking,Storage and Analysis(SC),Salt Lake City,Utah,2012:112.[10]SALAMY H,RAMANUJAM J.An effective solution to task scheduling and memory partitioning for multiprocessor systemonchip[J].IEEE Transactions on ComputerAided Design of Integrated Circuits and Systems,2012,31(31):717725.[11]何琨,赵勇,黄文奇.基于任务复制的分簇与调度算法[J].计算机学报,2005,31(5):733740.[12]J D OWENS,M HOUSTON,D LUEBKE,et al.GPU computing[J].Proceedings of the IEEE,2008,96(5):879899.[13]虚拟化与云计算小组.虚拟化与云计算[M].北京:电子工业出版社,2009.[14]王鹏,吕爽,聂治,等.并行计算应用及实战[M].北京:机械工业出版社,2009:6263.[15]J DUATO,A J PENA,F SILLA,et al.Enabling CUDA acceleration within virtual machines using rCUDA[C].In Proceedings of the 2011 18th International Conference on High Performance Computing,2011:110.[16]吴佳骏.多核多线程处理器上任务调度技术研究[D].北京:中国科学院计算技术研究所,2006.[17]金胜男.基于异构的静态任务调度策略研究[D].哈尔滨:哈尔滨工程大学,2012.(责任编辑:杜能钢)
猜你喜欢
小学教学研究(2022年5期)2022-04-28
电脑报(2019年12期)2019-09-10
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
信息通信技术(2015年6期)2015-12-26
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
计算机世界(2009年34期)2009-11-17
