
基于关键词挖掘的客户细分方法
2017-06-15 18:52陈星宇黄俊文
深圳大学学报(理工版) 2017年3期
陈星宇,周 展,黄俊文,陶 达
1) 深圳大学管理学院,广东深圳 518060;2) 深圳大学人因工程研究所,广东深圳 518060

【电子与信息科学 / Electronic and Information Science】
基于关键词挖掘的客户细分方法
陈星宇1,周 展1,黄俊文1,陶 达2
1) 深圳大学管理学院,广东深圳 518060;2) 深圳大学人因工程研究所,广东深圳 518060
提出一种基于关键词的数据挖掘方法对客户群进行细分,采用自然语义处理的方法从原始客户信息文本中提取客户特征关键词.再通过人工标记一些与内在特征维度相关的关键词,基于这些关键词找到特征客户.最后以特征客户作为训练集,获得更多关于某个维度内客户特征的关键词,再进行新一轮的客户细分.经此模式学习过程,得到基于内在特征维度的客户细分群体.通过与采用随机选择特征关键词的基准化方法进行自动客户细分结果对比,发现采用基于关键词数据挖掘的自动客户细分结果得到的准确度更高,结果更稳健.
人工智能;自然语言处理;知识工程;客户细分;关键词挖掘;客户特征;数据挖掘
对企业来说,单纯地满足客户需求,强调为所有客户提供同样优质的服务,可能使企业不能将有限的资源恰当地运用到有价值的客户身上,企业的努力很可能事倍功半.因此,企业需要区别对待客户,客户细分是客户关系管理中基础性的重要内容[1].
客户细分指根据行为和偏好等因素从群体中识别出特定客户的建模方法.在概念上,客户细分是将客户分为有相似行为方式或需求的客户子集的过程[2].不同于传统的市场细分理论[3],客户细分方法可管理大量的客户特征属性,并且基于特定数据维度进行细分.细分方法的选择取决于研究的具体目标[4].
客户细分方法通常包括以下步骤[5]:① 数据确定与收集;② 不同来源数据的整合及预处理;③ 开发细分的数据分析方法;④ 建立关于细分的相关业务部门(如市场营销和客户服务)之间的有效沟通;⑤ 利用应用程序处理数据,并为程序提供的信息作出反馈等.
以往关于客户细分技术可分为监督和无监督两种.聚类分析法是常见的无监督客户细分技术,它包括一组不同的技术.给定一组选定的细分变量,利用这些技术将个体汇总成群体.每个群体中包含着最相似的个体,且这些个体与其他群体并无关联.基于客户数据之间模糊距离的聚类客户数据分析可得到比其他方法更有效的市场细分结果[6].另一种常见的无监督方法是联合分析[7],它通过评估拥有不同属性层面的替代品的秩或者总价值进行整体信息判断,并通过回归、层次贝叶斯模型或线性规划来估计单属性值函数的离散水平来实现细分[8].此外,科霍南映射或者自组织映射也被广泛用于降维和聚类,同时也用于多维数据的各种应用[9].其他人工智能技术,包括模拟退火算法[10]、神经网络[11]和遗传算法[12]也被用到无监督客户细分方法中.相比无监督聚类方法,监督分类方法要求在进行分类前为每一类生成代表性的参数,而无监督方法会自动从数据集中识别集群.常见的监督分类方法有线性判别分析(linear discriminant analysis, LDA)[13]、k邻近法[14]和决策树法[15]等.无监督方法在进行数据分类时只有少量的先验知识,或者在分类过程中需要避免主观性时才非常实用[16].若监督条件可被满足,也就是说,导出分类规则所需要数据点的成员能够阐明集群的一般结构,则监督数据更加准确[17].
然而,上述监督和无监督客户细分技术都不能很好的基于客户内在特征做细分.因为客户的内在特征通常是抽象模糊的,通过准确的词语(特征)来描述客户的内在特征(如客户的生活方式、价值观和个性等)也非常困难.同时,网络传播语言的抽象性[18]也使这些数据更加难以处理.此外,基于这些抽象维度将客户手动划分为不同群体更是一项繁冗的工作.为此,本研究提出一种基于关键词的数据挖掘方法,针对客户的内在特征对客户进行细分,既避免了无监督分类方法准确度欠佳的问题,又解决了监督分类方法对数据要求较高的问题,且保证了低成本和高准确率.
1 方法及范例
本研究提出的模型包含数据收集、数据预处理、基于关键词挖掘的客户分类及方法评估4部分,如图1.
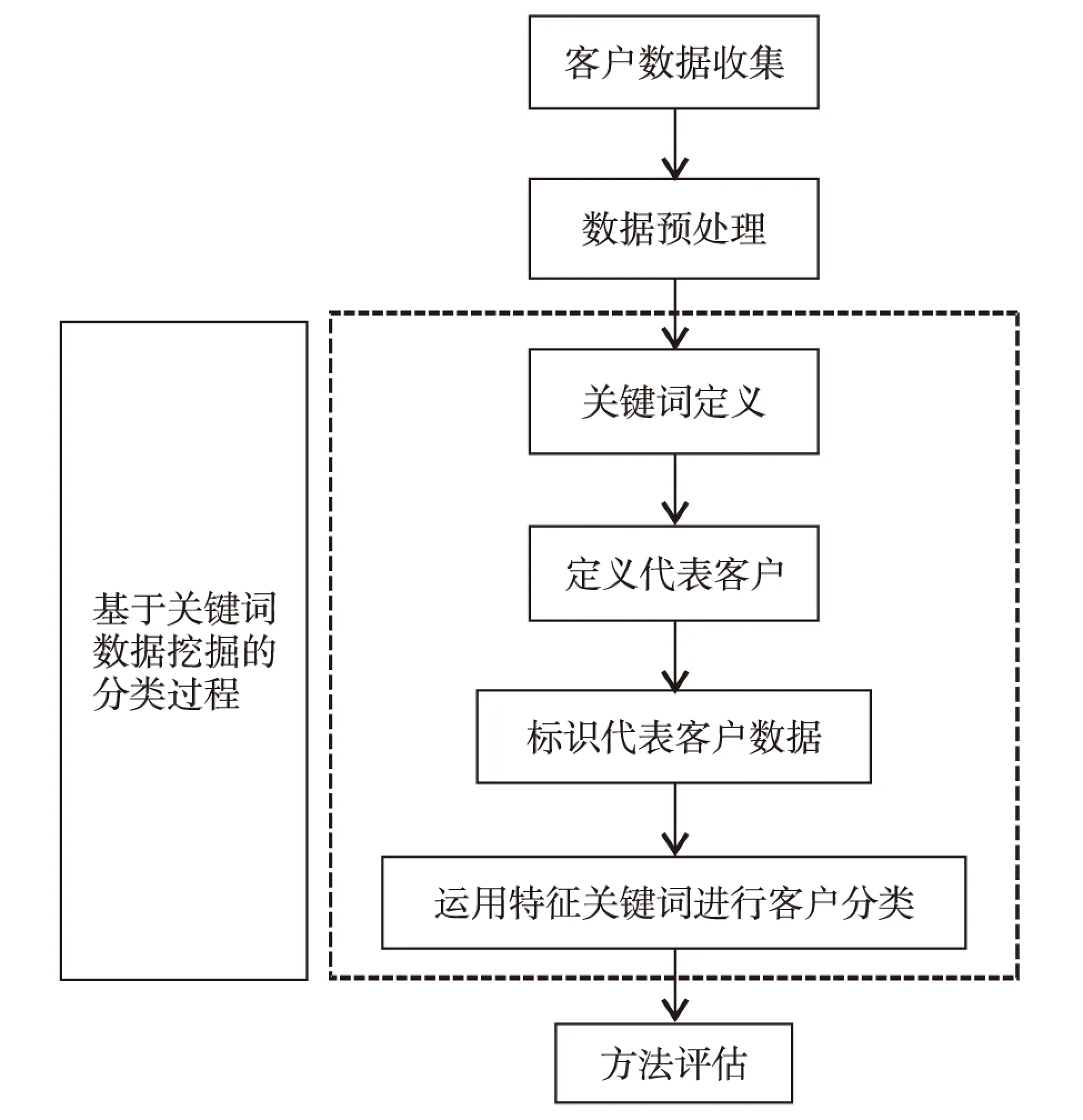
图1 基于关键词的客户细分框架Fig.1 Keyword-based customer segmentation framework
1.1 客户数据收集
由于在线数据中包含了大量客户信息,因此本研究选取亚马逊购物网站(https://www.amazon.cn)用户数据作为输入.首先从此网站的注册用户中,选取在近3个月中进行过交易的1万名中国用户,再从这1万个用户中随机筛选出600名用户作为样本用户,最后从这600名用户的个人资料里提取出自我描述部分的文本数据,组成本研究的样本数据集.对于这600个样本数据,取其中500名用户的数据,利用本研究提出的模型进行分类,其余100名用户的数据则用作测试数据.
1.2 数据预处理
预处理阶段,本研究应用自然语言处理将整个文本按照名词、动词和形容词标签分割成小的词汇单位[19].例如,某客户自我描述是:“我是一个家庭主妇.我的享受生活的方式是成为饥饿的浪漫读者,所以我痴迷于亚马逊网站.我非常享受安静的时间,阅读是我最喜欢的爱好之一.”通过基于自然语言处理的预处理分析,则变成了下面的语法单元:((主语(名词性物主代词“我”))(谓语(系动词“是”))(宾语(定冠词“一个”)(名词“家庭主妇”))(主语(形容词性物主代词“我的”)(名词“享受生活的方式”))(谓语(情态动词“是”)(动词“成为”))(状语(形容词“饥饿的”))(宾语(名词“浪漫”)(名词“读者”))(状语(连接词“所以”)(主语(名词性物主代词“我”))(状语(介词短语“当然”))(谓语(动词短语“痴迷于”))(宾语(名词“亚马逊网站”))(主语(名词性物主代词“我”))(状语(副词“非常”))(谓语(动词“享受”))(状语(形容词“安静的”))(宾语(名词“时间”))(主语(动名词“阅读”))(谓语(系动词“是”))(宾语(名词性物主代词“我”)(形容词“最喜欢的”)(名词“爱好”)(介词短语“之一”))))仅带有名词、动词和形容词标签的词汇单元才被收集为关键词.冠词和描述性的形容词,如“一个”、“许多”和“几个”都被删除.基于与特定领域相关的候选关键词,从客户数据中生成关键词,如“家庭主妇”、“享受”、“饥饿的”、“浪漫”、“读者”、“痴迷”、“亚马逊”、“享受”、“安静”、“时间”、“阅读”、“最喜欢”和“爱好”等.
1.3 基于关键词挖掘分类的4个步骤
1.3.1 关键词定义
根据客户样本数据中生成的关键词,基于客户内在特征的角度,从客户的参与(使用频率和使用时间等)、客户的认知(职业和经历等)以及客户的情感(热爱和好奇等)3个方面将关于客户内在特征的关键词分为3个维度.分别选取3位网站管理者(在亚马逊中国区客户经理职位上有3年以上工作经历)、3位网站老用户(在亚马逊网站使用时间3年以上,同时使用亚马逊频率很高且经常有反馈的用户),以及3位数据挖掘专家(在亚马逊网站从事文本数据挖掘工作3年以上的工程师)作为领域专家,从上述3个维度手动预定义相关关键词,最后确定了如表1的40个预定义关键词.

表1 每个客户特征维度的特征关键词
1.3.2 定义代表客户
定义代表客户为在客户的自我描述数据中某一维度的关键词词频大于1的客户.通过此定义,500名客户中有158人被选为代表客户,这些代表客户相当于自我描述中出现第1步中预定义的特征关键词频率较高的人.同时,发现在大多数的代表客户中,出现关键词的词频大于3,说明基于上述定义的识别代表客户的标准,识别准确率较高.
1.3.3 标识代表客户数据
找出代表客户后,通过标识代表客户数据中的预定义特征关键词进行关键词挖掘.具体操作为:
1) 在代表客户数据中标识出相应维度的预定义关键词.首先,分别确定用于区分不同维度的相应标识(本研究通过不同颜色来标识,红色为维度1;蓝色为维度2;黄色为维度3).然后,在代表客户的自我描述数据中将相应维度的预定义关键词标识出来,作为下一步进行机器学习的范例.

3)在挖掘出的关键词数据集中选择出至少出现3次的关键词.初步选出相应维度的数据集后,在每个数据集中进行词频分析,剔除出现频率少于3次的关键词后,得到更精确的数据集.
此关键词挖掘过程,既通过预定义关键词保证了挖掘的准确性,又利用了机器学习的自动化过程实现快速高效地挖掘出大量关键词.经此过程,更多的关键词被挖掘出来,如表2.

表2 每个维度中挖掘出的特征关键词
1.3.4 运用特征关键词进行客户分类
基于近邻法和客户特征指数(客户自我描述数据与3个维度的特征关键词的匹配程度),利用第1步和第3步提取的关键词,将500个客户分为8类,分别归类为不同创新程度的用户,具体为:
1)自我描述与特征关键词完全不匹配的客户(有1类客户,记为类型A),此类型为最不具创新特征的用户.
2)自我描述只与一个维度的特征关键词匹配的客户(有3类客户,记为类型B、C和D),其创新性较低.
3)自我描述与两个维度的特征关键词匹配的客户(有3类客户,记为类型E、F和G),属于创新性较好的用户.
4)自我描述与3个维度的特征关键词均匹配的客户(有1类客户,记为类型H),则属于创新用户.
实际上,在此分类中可以将用户的某一特点(如创新性)进行更精细的分类,而非简单的是与否分类,从而使企业在客户细分时可更灵活地根据需求来选取细分类别.同时,该方法应用性强,只要确定细分依据(创新、活跃和忠诚等),并选取相应的刻画维度,即可按照上述过程进行细分.
1.4 方法评估
方法评估有2个步骤:
第1步:检验自动分类法准确度和特征关键词数量的关系.提供一组预定义的关键词.然后,根据这组关键词,利用本研究提出的自动分类方法生成不同的客户分类.用自动分类的客户类别数量与相应的手动分类的客户类别数量的匹配百分比来表示自动分类方法的准确度,比较自动分类和按同一标准进行手动分类的结果.关键词挖掘的过程旨在发现更多关键词,而自动分类法是通过关键词挖掘产生新一组关键词.所以,可通过计算新一组关键词进行自动分类的准确度,再次比较自动分类的结果与手动分类结果,此过程一直持续到准确度值不再变化为止.这样就可以得到以自动分类方法的准确度为纵轴,相应的特征关键词数量为横轴的关系曲线,由此确定自动分类法准确度和特征关键词数量的关系.若两者正相关,说明所提方法有助于提高自动分类的准确度.
第2步:比较自动分类和基准化方法[21]分类的结果.在关键词挖掘过程中,把使用自动分类方法进行客户细分的结果与使用基准化方法进行客户细分的结果进行比较.基准化方法并未在分类开始就手动定义关键词,也无关键词挖掘过程,它对特征关键词的选择是随意的.通过比较在不同数量的关键词的情况下两种分类方法的准确度,验证基于关键词挖掘方法的自动分类的效率.
2 结果与讨论
本研究通过对手动分类(测试组)和系统自动分类的结果进行对比来检验本研究中客户细分方法的可行性.随机选定500个用户,通过系统自动进行细分,而另外随机选定100个用户,通过同样的细分标准进行手动分类,结果见表3.其中,匹配用户数为在500位用户自动分成8类以后,每一类中的用户与手动分类出来的对应类别中的用户相匹配的数目;准确率即为匹配用户数与手动分类的用户数的比值.
由表3可见,不同客户群体的平均精度达77.0%,表明大部分采用特征关键词自动分类算法具有较高准确率,且与先前的只将用户分为普通用户和领先用户的领先用户理论相比,该客户细分模型分类结果精确.此外,分类准确率随着特征关键词数量增加而上升,这进一步验证本研究提出的分类方法的可行性和稳健性.这项试验从40个已定义的关键词(表1)开始,在通过机器学习挖掘关键词的过程中,分别选定含有60、80、100和120个关键词的4组关键词,并用这5组关键词为测试组的100个用户做客户分类.客户分类结果与手动分类结果比较如图2.

表3 自动分类中每种客户类型的准确率

图2 关键词挖掘和随机选择之间的结果比较Fig.2 Comparison of results from keyword mining and random selection
图2展示了分别采用机器学习的关键词挖掘方法和采用随机选择特征关键词的基准化方法进行自动客户细分结果.其中,采用随机选择特征关键词的基准化方法的客户细分方法的准确率计算过程为:通过基准化方法随机选取出与关键词挖掘方法数量一样的关键词;再使用与同样的步骤计算出基于不同数量关键词的分类结果的准确率,并将这一准确率作成折线图.
由图2实线可见,随着从代表性客户中学习的特征关键词数量增加,采用自动分类方法的准确度亦明显增加,未采用机器学习挖掘时准确度仅39%,而采用机器学习挖掘关键词后最终的准确度达77%.结果表明,采用机器学习的关键词挖掘方法较采用随机选择特征关键词的基准化方法进行客户细分结果更准确.
实证研究还表明,该模型能够识别更多的创新客户.在之前的研究中,领先用户是通过那些已经从相关角度所定义好的领先用户特征来确定的.而在研究中,在所列出的3个内在特征中有任意两个显示是高水平的话就将被确定为创新用户.在所选客户样品中所识别的创新客户的25%,高于基于传统的问卷调查的研究提供的数据[22].此外,基于关键词挖掘的客户细分方法因所有数据均采集自互联网,可以非常低的成本找到狂热的创新者(或领先用户、创新用户).
需要指出的是,本研究方法对非创新客户识别的准确度仅为54.5%.这是因为本研究仅关注创新用户的识别,对创新用户识别的总准确率达86.8%,基本满足相关公司选取创新用户的需求.因此,依然可认为该细分模型在客户细分和创新用户识别上是成功的.下一步,将针对非创新用户识别作深入探索,以进一步提高分类方法的准确性.
结 语
本研究提出一种基于关键词的数据挖掘方法对客户进行细分,通过对比采用关键词数据挖掘分类方法的结果与采用人工分类及标杆进行分类的结果,发现所提方法能够更准确地细分基于不同内在特征的客户群体.研究可供企业单位通过分析网上客户数据,定位潜在客户群体,制定相应的市场与新产品开发策略.
/ References:
[1] 王扶东,马玉芳.基于数据挖掘的客户细分方法的研究[J].计算机工程与应用,2011,47(4): 215-218. Wang Fudong, Ma Yufang. Research of method for customer segment based on data mining[J]. Computer Engineering and Application, 2011, 47(4): 215-218.(in Chinese)
[2] Foedermayr E K, Diamantopoulos A. Market segmentation in practice: review of empirical studies, methodological assessment, and agenda for future research[J]. Journal of Strategic Marketing, 2008, 16(3): 223-265.
[3] Saliba S J, Turner R E. Marketing management: analysis, planning, implementation and control[M]. 8th ed. Philip K, Ronald E T. Scarborough, Canadian: Prentice-Hall, 1995.
[4] Tsiptsis K, Chorianopoulos A. Data mining techniques in CRM: inside customer segmentation[M]. Hoboken, USA: John Wiley & Sons, 2011.
[5] Liang Daolei, Chen Haibo. An online mall CRM model based on data mining[C]// Quantitative Logic and Soft Computing. Hangzhou, China: Springer International Publishing, 2017, 510: 599-606.
[6] Chan K Y, Kwong C K, Hu B Q. Market segmentation and ideal point identification for new product design using fuzzy data compression and fuzzy clustering methods[J]. Applied Soft Computing, 2012, 12(4): 1371-1378.
[7] Green P E, Carroll J D, Goldberg S M. A general approach to product design optimization via conjoint analysis[J]. The Journal of Marketing, 1981, 45(3): 17-37.
[8] Butler J C, Dyer J S, Jia Jianmin, et al. Enabling e-transactions with multi-attribute preference models[J]. European Journal of Operational Research, 2008, 186(2): 748-765.
[9] Rojanavasu P, Dam H H, Abbass H A, et al. A self-organized, distributed, and adaptive rule-based induction system[J]. IEEE Transactions on Neural Networks, 2009, 20(3): 446-459.
[10] Brusco M J, Cradit J D, Stahl S. A simulated annealing heuristic for a bicriterion partitioning problem in market segmentation[J]. Journal of Marketing Research, 2002, 39(1): 99-109.
[11] Ayoubi M. Customer segmentation based on CLV model and neural network[J]. International Journal of Computer Science Issues, 2016, 13(2): 31.
[12] Liu H-H, Ong C-S. Variable selection in clustering for marketing segmentation using genetic algorithms[J]. Expert Systems with Applications: an international Journal, 2008, 34(1): 502-510.
[13] Lee E-K, Cook D, Klinke S, et al. Projection pursuit for exploratory supervised classification[J]. Journal of Computational and Graphical Statistics, 2012, 14(4): 831-846.
[14] Duda R O, Hart P E. Pattern classification and scene analysis[M]. New York, USA: Wiley, 1973.
[15] Swain P H, Hauska H. The decision tree classifier: design and potential[J]. IEEE Transactions on Geoscience Electronics, 1977, 15(3): 142-147.
[16] Zou K H, Warfield S K, Bharatha A, et al. Statistical validation of image segmentation quality based on a spatial overlap index 1[J]. Academic radiology, 2004, 11(2): 178-189.
[17] Budayan C, Dikmen I, Birgonul M T. Comparing the performance of traditional cluster analysis, self-organizing maps and fuzzy c-means method for strategic grouping[J]. Expert Systems with Applications, 2009, 36(9): 11772-11781.
[18] 袁 兵,黄 静, 曾一帆.网络评论语言的抽象性对消费者品牌态度与购买意愿的影响——一项基于语言类别模型 (LCM) 的实证研究[J].营销科学学报,2013(3):17-30. Yuan Bing, Huang Jing, Zeng Yifan. The effect of language abstraction in online reviews on consumer’s brand attitude and buying intention: an empirical research based on the linguistic category model (LCM)[J]. Journal of Marketing Science, 2013, 9(3): 17-30.(in Chinese)
[19] 陈星宇,黄俊文,周 展,等. 基于本体论的大数据下用户需求表征[J]. 深圳大学学报理工版,2017,34(2):173-180. Chen Xingyu, Huang Junwen, Zhou Zhan, et al. Ontology-based user requirements representation in the context of big data[J]. Journal of Shenzhen University Science and Engineering, 2017,34(2): 173-180.(in Chinese)
[20] 张 润,王永滨.机器学习及其算法和发展研究[J].中国传媒大学学报自然科学版,2016,23(2):10-18. Zhang Run, Wang Yongbin. Research on machine learning with algorithms and development[J]. Journal of Communication University of China Science and Technology, 2016, 23(2): 10-18.(in Chinese)
[21] Davies J, Sure Y, Grobelnik M, et al. Automated knowledge discovery in advanced knowledge management[J]. Journal of Knowledge Management, 2005, 9(5):132-149.
[22] Lüthje C. Characteristics of innovating users in a consumer goods field: an empirical study of sport-related product consumers[J]. Technovation, 2004, 24(9): 683-695.
【中文责编:英 子;英文责编:子 兰】
2016-11-30;Accepted:2017-03-18
Lecturer Tao Da. E-mail: taoda@szu.edu.cn
A keyword-based mining method for customer segmentation
Chen Xingyu1, Zhou Zhan1, Huang Junwen1, and Tao Da2
1) College of Management, Shenzhen University, Shenzhen 518060, Guangdong Province, P.R.China2) Institute of Human Factors and Ergonomics, Shenzhen University, Shenzhen 518060, Guangdong Province, P.R.China
We propose a novel customer segmentation method using keyword-based data mining approach. First, keywords about customer characteristics from original customer information are extracted by natural semantic processing. Then, keywords related to intrinsic characteristics are tagged. Based on the keywords, customers with the specific characteristics are identified. Finally, we use the identified customers as the training samples to obtain more keywords about the customer characteristics, and conduct a new round of customer segmentation. After the learning process, customer segmentation groups based on intrinsic characteristics are obtained. Compared with the benchmarking method of random selection of feature keywords for customer segmentation, the feasibility and validity of the proposed method are verified by a case study where a high level of accuracy rate and robustness is observed in the customer segmentation results.
artificial intelligence; natural language processing; knowledge engineering; customer segmentation; keyword mining; customer characteristics; data mining
:Chen Xingyu, Zhou Zhan, Huang Junwen, et al. A keyword-based mining method for customer segmentation[J]. Journal of Shenzhen University Science and Engineering, 2017, 34(3): 300-305.(in Chinese)
国家自然科学基金资助项目(71502111)
陈星宇 (1983—),女,深圳大学讲师、博士.研究方向:新产品体验及客户需求管理.E-mail:celine@szu.edu.cn
TP 311
A
10.3724/SP.J.1249.2017.03300
Foundation:National Natural Science Foundation of China (71502111)
引 文:陈星宇,周 展,黄俊文,等.基于关键词挖掘的客户细分方法[J]. 深圳大学学报理工版,2017,34(3):300-305.
猜你喜欢
当代陕西(2022年4期)2022-04-19
学生天地(2020年5期)2020-08-25
华人时刊(2020年23期)2020-04-13
中华诗词(2019年7期)2019-11-25
小天使·一年级语数英综合(2017年3期)2017-04-25
莫愁(2017年9期)2017-04-07
汽车博览(2016年9期)2016-10-18
灯与照明(2016年4期)2016-06-05
专用汽车(2016年9期)2016-03-01
专用汽车(2015年2期)2015-03-01
