
基于微博标签和LDA的微博主题提取算法∗
2017-06-05 15:03:55
计算机与数字工程 2017年5期
基于微博标签和LDA的微博主题提取算法∗
邓丹君姚莉
(湖北理工学院计算机学院黄石435002)
论文根据微博文本所具有的特点,将微博文本具有的三种的特殊符号:“@”、“//”和“#”纳入微博主题提取的分析中。在传统的LDA模型的基础上,建立一种微博标签的LDA模型,该模型考虑到微博的主题、转发的微博、微博的评论等内容,增强对微博主题的提取的准确性。实验结果表明,论文提出的算法对于新浪微博的主题提取的效果良好。
微博;主题提取;LDA;微博标签
Class NumberTP391
1 引言
近年来,微博已成为新时代的社交网络工具之一。微博用户可以通过发布不超过140个字符的微博表达自己的兴趣爱好,对某种主题信息进行关注,微博的更新速度和传播速度很快。微博内容虽然简短但蕴含着丰富的信息,对微博文本内容进行主题信息提取可以获取用户的潜在的个体兴趣。因此如何获取微博的主题信息成为很多计算机相关领域的学者研究的热点话题。
微博中的内容与通常意义上的文本内容不同,微博内容比较简短,包含的词语数量有限,且语法结构不特定,因此对微博主题内容的提取不能简单使用传统的文本主题提取算法,必须对传统文本主题提取算法进行改进。近些年来,有很多学者使用在传统的LDA主题模型的基础上进行改进来提取微博主题,并取得了一定的成果。文献[1]考虑到微博转发的特征并引入时间因子利用LDA模型进行主题信息提取。文献[2]通过追踪不同时间片内主题的变化趋势进行主题演化分析从而建立并实现在线LDA模型。文献[3]将文本聚类与LDA模型相融合进行微博主题的提取。文献[4]将微博的联系人关联信息和文本关联关系考虑到LDA的微博生成模型中。
然而,这些学者并没有针对微博类型提取不同微博类型的微博主题,并且没有考虑微博的微博文本的三种其专属的特殊符号:“@”、“//”和“#”来分析微博文本本身具有的特点。
本文结合用户兴趣、微博文本的三种专属的特殊符号:“@”、“//”和“#”,对不同微博类型进行主题分析,结合传统的LDA模型提出一个新的在微博平台下适用的微博标签主题模型,采用吉布斯抽样(Gibbs sampling)对该模型进行求解,实现微博内容的主题提取,最后在新浪微博数据集上进行验证该模型的有效性。
2 LDA主题模型
2.1LDA主题模型的基本思想
LDA(Latent Dirichlet Allocation)主题模型是一种生成主题概率模型,是一种对文本数据的主题信息进行建模的方法[5]。LDA主题模型由如图1所示的结构组成,假设文档是由多个隐含主题构成,这些隐含主题又是由若干个特定特征词构成,LDA模型忽略特征词的先后次序,从而简化主题模型的复杂性。LDA主题模型认为文档的每个特征词都是通过“以一定概率选择某个隐含主题,并且从这个隐含主题中以一定概率选择某个特征词”这种过程中得到。

图1 LDA模型的隐含主题结构
当有M篇文档,K个主题,N个的特征词,在一篇文档中的第i个特征词wi的概率表示为

其中,P(wi|zi=j)表示特征词wi出自主题zi的概率,P(zi=j)是文档包含主题zi的概率。
首先从参数为α的Dirichlet分布中取样生成文档d的主题分布θd,接着从为参数θd的主题多项式分布中取样生成文档d的第i个特征词的主题zd,i,然后从参数为β的Dirichlet分布中取样生成主题zd,i的特征词分布ϕzd,i,从特征词的多项式分布ϕzd,i
中采样生成特征词wd,i[6]。整个过程如图
2所示。

图2 LDA模型的贝叶斯网络
文档d用LDA生成的概率为

文档集D中所有文档用LDA生成的概率为

2.2微博文本的特征
由于微博短文本的特性会造成高维稀疏,从而使用传统的LDA模型会导致微博主题不易提取。因此,需要针对微博本身所具有的特点进行分析,在传统的LDA模型上进行改进。
微博文本具有的三种专属的特殊符号:“@”、“//”和“#”,这些符号对于微博主题的提取具有一定的作用。这些符号的含义如下:
1)“@”符号:“@”后面接着用户名称,表示提到该用户并与该用户展开对话。
2)“//”符号:“//”表示转发,后面接着“@用户名称”,转发该用户的某一条微博内容并对这条微博进行评论。“//”符号代表的转发微博比较特殊,这种微博的内容包含其他用户所发表的微博内容,包含或者不包含评论内容,这种微博的主题往往和被转发的微博主题相同。“//”符号和“@”符号揭示了转发微博和被转发微博之间的主题内容的联系,能更好地建立用户对话过程中的主题模型。
3)“#”符号:“#”与“#”之间含有发布的微博的主题内容。该符号是用户在发布微博的时候添加的符号,因此具有任意性,不同用户可能会为相同主题的微博添加不同的话题标签,但是“#”符号之间的语义信息对微博的主题分析仍然是有帮助的[7]。
此外,有很多微博都有他人参与评论,微博的评论内容对于微博的主题分析有一定的作用,影响的程度会随着评论的内容的不同而不同。因此,在分析微博主题分布时可以将微博及其评论放在一起进行分析,并且设置影响因子表示影响的程度。
2.3微博标签的主题模型LDA的构建
由于微博文本具有的三种专属的特殊符号:“@”、“//”和“#”以及微博是否是回复他人评论的微博,对于微博主题的分析有重要的作用,需要设定参数表示微博文本中是否含有这些特殊符号来确定该微博的主题分布。根据微博文本d内容中含有的符号的不同含义,可设置参数λd表示微博文本中是否含有“@”、“//”或“#”符号。如果微博文本d中含有“#”符号,则λd=0,该条微博的主题分布θd由“#”符号内部的内容的主题分布θs决定;如果微博文本d中含有“//”或“#”符号,则λd=1,该条微博的主题分布θd由被转发的微博的主题分布θr决定;如果微博文本d中不含有任何符号,则λd=2,该条微博的主题分布θd由该条微博内容的主题分布决定;如果微博文本d为回复他人评论的微博,则λd=3,该条微博的主题分布θd由该条微博内容和被回复的微博的主题分布共同决定。主题分布公式如下:

其中,N是特征词个数;K是主题个数;z-i表示除特征词i之外的所有特征词主题;w代表所有特征词;对应含有不同标签符号的微博,α、β和γ会对应不同的参数值。Gibbs抽样迭代直至收敛后最终得到以下公式:
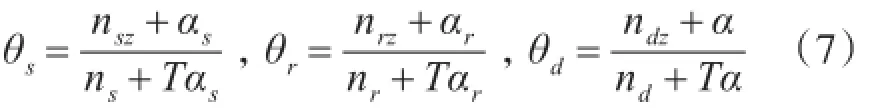
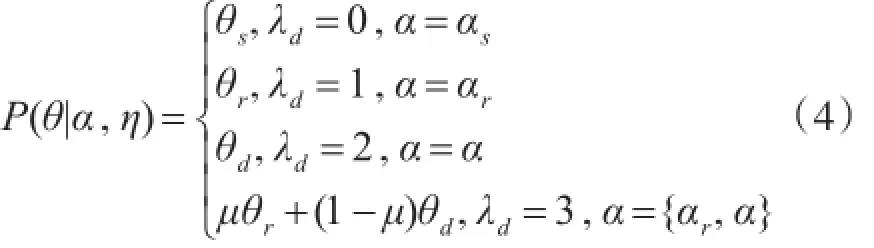
该主题模型的生成过程如下:
1)参数为β的Dirichlet分布中取样生成主题zd,i的特征词分布ϕzd,i;
其中,θs为“#”符号内部的内容的主题分布,θr为转发的微博的主题分布,θd为微博内容的主题分布;回复他人评论的微博的主题分布可以通过式(4)计算;αs、αr和α为对应参数;nsz为含有“#”符号的微博出现主题z的次数,nrz为转发的微博出现主题z的次数,ndz为不含有任何符号的微博出现主题z的次数。
2)对于每条微博d,确定微博d中是否含有“@”、“//”或“#”符号,得到参数λd的值,进而得到该条微博的主题分布θd;
3)从为参数θd的主题多项式分布中取样生成文档d的第i个特征词的主题zd,i;
4)从特征词的多项式分布ϕzd,i中采样生成特征词wd,i。
3 实验
微博标签的主题模型LDA如图3所示。

图3 微博标签的主题模型LDA
微博d的生成概率如下:

3.1微博数据的采集
为了验证对微博主题提取的正确性,本文采用新浪的开放API接口进行采集原始数据。人工选择微博用户500多名(以具有较大影响力的微博用户为主),抓取44721条微博数据。针对每条微博按照是否包含“@”、“//”和“#”符号进行分类,采用ICTCLAS中文分词系统进行分词和词性标注,去掉停用词,最后生成预处理数据。
3.2实验过程及结果分析
实验环境为Intel i5 6500 3.2GHz的CPU,4G的内存,1T的硬盘,操作系统为Windows7。实验的目的是测试相对于传统的LDA模型,本文在将包含“@”、“//”和“#”符号的微博进行特殊处理的情况下,对主题提取的影响。本文采用Perplexity指标进行度量实验结果。Perplexity指标用来度量主题模型的性能,表示预测数据时的不确定性。指标越小,性能越好[9]。Perplexity指标的计算公式如下:
2.4微博标签的主题模型的推导
微博标签的主题模型采用Gibbs抽样进行推导。Gibbs抽样会估计微博文本中每个特征词对应每个主题的条件概率[8]。微博标签的主题模型的Gibbs抽样后验公式具体如下:
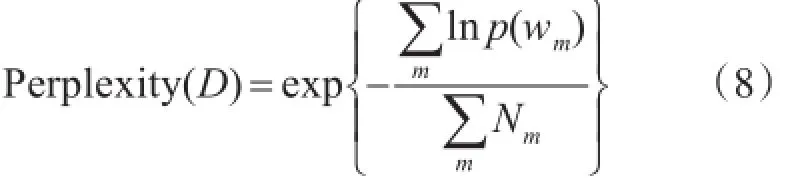
式中,D为测试集,wm为测试集中可观测到的词,Nm为词的总数[11]。
计算得到LDA与本文提出的模型的Perplexity指标如图4所示。
图4 两种模型的Perplexity指标对比
从图4中可以看出,在相同参数的条件下,微博标签的LDA模型的Perplexity指标均小于LDA,从而证明微博标签的LDA模型的性能较好。表1显示了微博标签的LDA模型主题关键词的准确性,针对每个主题给出出现概率最大的前5个词语。
从表1可以看出,相对于传统的LDA模型,微博标签的LDA模型准确程度更高。

表1 两种模型的主题准确度对比
4 结语
本文根据微博文本所具有的特点,将微博文本具有的3种的特殊符号:“@”、“//”和“#”纳入微博主题提取的分析中,在传统的LDA模型的基础上,建立一种微博标签的LDA模型,该模型考虑到微博的主题、转发的微博、微博的评论等内容,增强对微博主题的提取的准确性。实验结果表明,本文提出的算法对于新浪微博的主题提取的效果良好。在今后的研究工作中,将进一步考虑微博标签对于微博主题的影响,继续优化本文提出的模型。
[1]陶永才,何宗真,石磊,等.基于加权动态兴趣度的微博个性化推荐[J].计算机应用,2014,34(12):3491-3496.
TAO Yongchai,HE Zongzhen,SHI Lei,et al.Micro-blog personalized recommendation based on weighted dynamic interest degree[J].Computer application,2014,34(12):3491-3496.
[2]崔凯,周斌,贾焰,等.一种基于LDA的在线主题演化挖掘模型[J].计算机科学,2010,37(11):156-159.
CUI Kai,ZHOU Bin,JIA Yan,et al.A LDA based online topic evolution mining model[J].Computer Science,2010,37(11):156-159.
[3]唐小波,房小可.基于文本聚类与LDA相融合的微博主题检索模型研究[J].情报理论与实践,2013,36(8):85-88.
TANG Xiaobo,FANG Xiaoke.Research on micro-blog theme retrieval model based on text clustering and LDA[J].Information theory and Practice,2013,36(8):85-88.
[4]张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
ZHANG Chenyi,SUN Jianling,DING Yiqun.Micro-blog theme mining based on MB-LDA model[J].Computer re⁃search and development,2011,48(10):1795-1802.
[5]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022.
[6]赵华,纪晓文,曾庆田,等.基于话题相关空间的微博用户兴趣识别及可视化方法[J].计算机科学,2015,42(6A):500-502.
ZHAO Hua,JI Xiaowen,ZENG Qingtian,et al.Mi⁃cro-blog user interest recognition and visualization meth⁃od based on topic related space[J].Computer Science,2015,42(6A):500-502.
[7]MA Dashun,RAO Lan,WANG Ting.An empirical study of SLDA for Information retrieval[J].Information Re⁃trieval Technology,2011(1):84-92.
[8]Pennacchiotti M,Popescu A-M.Democrats,republicans and starbucks afficionados:user classification in twitter[C]//Proceedings of the 17th ACM SIGKDD International Conference Knowledge Discovery and Data Mining,2011:430-438.
[9]秦雨等.基于特征映射的微博用户标签兴趣聚类算法[J].Journal of Data Acquisition and Processing,2015,30(6):1246-1252.
QIN Yu,etc.A clustering algorithm based on feature map for micro-blog user Tags.Journal of Data Acquisition and Processing,2015,30(6):1246-1252.
[10]Griffiths T L,Steyvers M.Finding scientific topics[J]. Proc of the National Academy of Sciences o1 the United States of America,2004,101(Suppl1):5228-5235.
A Topic Extraction for Micro-blog Based on Micro-blog Tags and LDA
DENG DanjunYAO Li
(Department of Computer Science,Hubei Polytechnic University,Huangshi435002)
According to the characteristics of micro-blog text,this paper takes the micro-blog three kinds of special symbols,“@”,“//”and“#”,into consideration for topic extraction analysis of micro-blog text.On the basis of the traditional LDA model,a micro-blog tag LDA model is established,which considers the micro-blog theme,forwarded micro-blog,micro-blog comment con⁃tent,and enhances the accuracy of the extraction of micro blog theme.Experimental results show that the algorithm proposed in this paper has a good effect on the topic extraction of Sina micro-blog.
micro-blog,topic extraction,LDA,micro-blog tags
TP391
10.3969/j.issn.1672-9722.2017.05.034
2016年11月6日,
2016年12月27日
湖北理工学院校级科研项目(编号:15xjz02Q,15xjz03Q)资助。
邓丹君,女,硕士,讲师,研究方向:社交网络数据提取。姚莉,女,硕士,讲师,研究方向:计算机网络应用。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
中国新闻周刊(2021年26期)2021-07-27 04:02:12
计算机技术与发展(2018年8期)2018-08-21 02:08:14
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
中国机械工程(2017年22期)2017-12-02 01:52:34
信息安全研究(2016年4期)2016-12-01 06:06:54
校园英语·下旬(2016年2期)2016-03-18 10:23:20
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中文信息学报(2015年4期)2015-04-21 08:29:12
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
