
ADCS:一种基于SSD的阵列数据库缓存技术∗
2017-06-05 15:03:56
计算机与数字工程 2017年5期
ADCS:一种基于SSD的阵列数据库缓存技术∗
杨庆1,2李晖1,2陈梅1,2戴震宇1,2朱明3
(1.贵州大学计算机科学与技术学院贵阳550025)(2.贵州大学贵州省先进计算与医疗信息服务工程实验室贵阳550025)(3.中国科学院国家天文台北京100012)
论文提出了在阵列数据库中引入固态硬盘作为Cache的内存-SSD-磁盘的多级存储架构,研发了以阵列数据库的存储单元chunk为粒度的缓存技术—ADCS,并在FASTDB中进行了实现。ADCS采用最近最少使用(LRU)算法作为缓存淘汰算法,得益于内存和磁盘之间的SSD cache构建技术,阵列数据库的查询性能提升了34%左右。
二级缓存;阵列数据库;ADCS;LRU
Class NumberTP392
1 引言
随着科学技术的发展,在各个研究领域均产生了PB级的科学数据。科学数据一般为数组模型且数据量大。很多科学应用利用关系型数据库很难实现。科学分析需要涉及大量复杂的矩阵运算等,这些运算难以用SQL语句表示出来。科学应用中需要的版本控制等信息在关系型数据中也很难实现[3~4]。当前用在天文方面的主流关系型数据库,有Oracle、Mysql、PostgreSQL、SQL Server等。如LSST[5]项目,每晚产出TB量级的科学数据,关系型数据库在处理这样量级的数据时依然显得力不从心[6]。因此,关系型数据库(RDBMS)已经不能满足科学数据处理的需求。于是,阵列数据库应运而生。以SciDB[7~8]为代表的阵列数据库具有典型的非关系型科学数据库的特征。SciDB是share-noth⁃ing架构的分布式数据库,存储单元是chunk,chunk中的属性采用垂直分割的形式,一个chunk存储了一个属性。并且采用分发数据到各个节点,更好地进行并行查询。
SciDB在处理简单查询时,性能很好。但是,针对复杂查询,SciDB查询效率不高。其中低速的磁盘IO是其主要瓶颈。
固态硬盘已成为目前广泛使用的一种存储设备。目前的混合存储应用中,SSD主要有两种优化思路。一种是SSD-HDD混合存储系统[9~11],SSD和HDD是同等的存储设备。另一种是SSD-HDD构成多级缓存的层次存储模型[12~15]。第一类将SSD作为主要的存储设备,数据的读写先重定向到SSD中,随后将SSD中的脏数据写到HDD中。文献[12]通过过滤合适的数据到SSD,提高SSD的利用率。文献[13]通过降低SSD缓存代价,提升cache的有效容量。第一类在数据量较小时效果很好,但是将海量天文数据全部存储在SSD中的方式不经济。因此,本文采用的是第二种方式。
在处理海量规模数据时,第一种方式不可行。于是有人提出,根据每个页面产生的随机I/O的数量,将产生随机IO多的表或者索引放在SSD上可以最大化利用SSD的特征,提升数据库的性能[16~17]。但是这种方法要搜集每个页面的统计信息,将数据移动到SSD或者从SSD中移出去,代价很大。也可以采取整个表或者索引为粒度进行替换的策略。但是进行数据库查询时,并不是表中的每个记录都被访问到,而是表中的一部分经常被访问。因此SSD缓存的数据可能被污染。
根据数据访问的局部性原理,现在访问的数据将来也可能访问到,因此,内存中暂时不用的数据以后也可能访问到,将这部分数据缓存到SSD中,若再次访问到该数据,则可以提升性能。阵列数据库SciDB在进行查询时是以chunk为单位进行查询的。例如,数组A与数组B进行连接查询,是A中的chunk与B中的chunk进行连接,其中各个chunk中的cell分别进行连接操作。如果以阵列(Array)为粒度进行缓存,由于科学应用具有倾斜性[18],Ar⁃ray中的经常访问的属性集中在一小部分,缓存整个Array必定会造成SSD中存储的大量的无效空间。如果以chunk中的cell为单位进行缓存,过多的小块会增加内存定位的开销。因此,本文以chunk为粒度进行缓存,可以避免缓存空间的浪费,又可降低大量cell造成的内存定位开销。
2 基于SSD的缓存技术
FastDB是基于阵列数据库SciDB研发的一个原型系统。FastDB系统架构如图1所示。
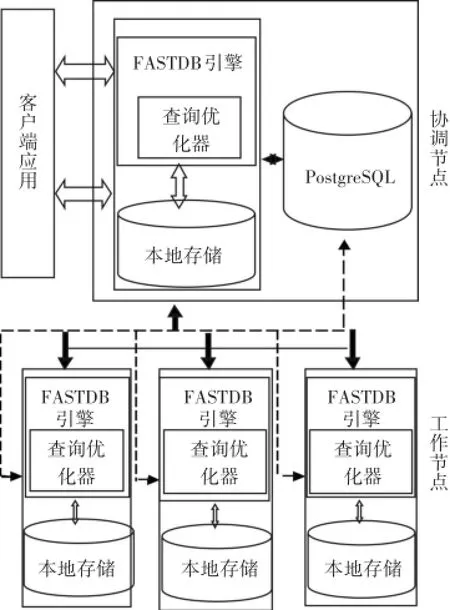
图1 FastDB系统架构图
此系统主要由协调(Coordinate)节点和工作(Worker)节点组成。Coordinate节点负责分发任务,Worker结点负责接收任务,执行任务将结果返回给Coordinate节点。Coordinate节点收集整理返回给客户端。
这些年来,CPU处理速度增加570倍,而磁盘的速度却只增加了20倍[19],可见,低速的磁盘已经成为阵列数据库I/O性能的瓶颈。因此针对磁盘IO瓶颈,我们进行了优化工作,优化后的FastDB系统如图2所示。SSD作为扩展缓存,存放的是内存暂时不用的数据。由于科学应用的倾斜性[18],这部分数据很可能再次被访问,提高了cache的有效性。
在FASTDB阵列数据库中,查询执行引擎通过缓冲管理器调用块,缓冲区管理通过磁盘管理访问具体的IO设备。当请求数组中的一个chunk时,缓冲管理首先检查缓冲池,如果找到直接返回;否则,首先检查缓冲池是否有空闲,如果有,磁盘管理器直接从磁盘读数据到缓冲区;如果缓冲区没有空闲,缓冲管理器根据替换算法将chunk淘汰。磁盘管理器主要处理缓冲区发送的读写请求,处理异步IO,最大化CPU和IO资源。
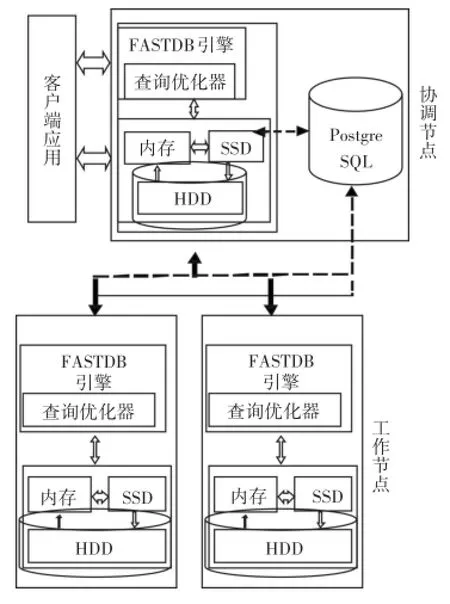
图2 加入了SSD的FastDB系统架构图
3 基于SSD的阵列数据库缓存算法ADCS
在天文学领域中,有各种不同的研究方向。某一类研究方向主要涉及某些数据,即数据具有倾斜性。例如,小行星巡天目标识别的研究,主要涉及到小行星相关表的查询。此外,河外星系的研究主要涉及到河外星系的查询。因此在很长一段时间内,科学分析只访问某一部分的数据,也就是访问具有时间和空间局部性。
针对以上这些特性,结合FASTDB阵列数据库的特点,提出了基于SSD的阵列数据库缓存算法(Array Database Caching algorithm based on SSD,ADCS),设计了基于SSD的缓存系统—CSBSF(Cache system based on SSD on FASTDB)。由于天文学应用主要包括巡天观测、数据检索、交叉证认,很少进行数据的修改操作,并且考虑到SSD的读写不对称性以及SSD的寿命问题,因此SSD主要缓存的是从内存淘汰的干净chunk。而从内存淘汰的脏的chunk则直接写回磁盘。如图3所示,内存中淘汰的chunk存入SSD缓存表,SSD缓存表负责维护干净chunk。把共享缓冲池中淘汰出来的干净的chunk写入SSD中,这样把多数可能被访问的chunk缓存到SSD中,明显减少了对磁盘的I/O操作,提高了数据库的性能。将内存中淘汰的chunk,缓存到SSD中。如果SSD中有空间存放chunk,就直接将chunk放入SSD中,并将chunk加入到SSD最近最少访问(ssdLRU)链表中;否则循环淘汰ssdLRU中的链表末尾元素直到SSD中有位置可以存放chunk。
当一个查询请求到来时,例如SQL查询“select name from Student”,经过词法分析,语法分析,最终转换成对于数组Student中的属性name的数据请求。进行查询时,为了在SSD中快速查找数据,数组ID(arrId)和属性ID(attId)作为key,通过key可以判断此chunk是否在SSD中,如果在,则直接从SSD中读取数据。否则,从磁盘读取,并把chunk放到SSD中。
当数据库请求某个chunk,而chunk不在内存,要先将chunk放入到cache中。算法1描述了这个过程。当内存空间满,放不下此块chunk时,根据LRU淘汰算法,需要淘汰内存中暂时不用的块vic⁃tim到SSD中。这个过程首先要检查SSD是否能够容纳得下victim,如果不能存放,则从SSDlru链表末尾淘汰一个chunk,直至可以放victim到SSD中。算法2描述了SSD存储空间满,不能存放内存淘汰的chunk时,根据最近最少使用(LRU)算法,从SSDlru链表的末尾获得victim,淘汰SSD中的chunk并将其在SSD上占用的空间删除。
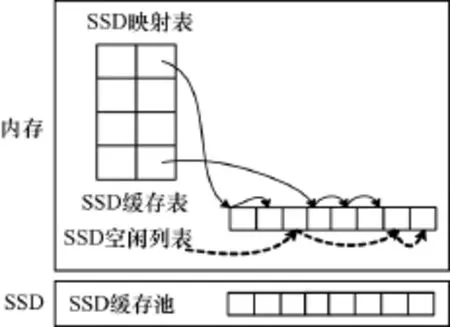
图3 SSD缓存管理图
如图3所示,当往SSD中写数据时,首先查找SSD空闲列表SsdFreelists。SsdFreelists设计成一个有序map,std::map<size_t,std::set<off_t>>。其中根据请求的chunk的大小,从集合中找到一个位置(offset),将chunk缓存到SSD缓冲池的offset上。并将此位置从空闲列表中删除。
算法1.SSD中块的加入算法(ADCS)
Input:chunk为不在内存,要加入到cache的块。
Begin:
1do while memory is full
2do while ssd is full
3 Evict chunk from SSD
4loop
5Get the victim from the memlru
6Add victim to SSDlru
7Allocate address of SSD to victim
8Erase victim adderss from SSD FreeLists
9loop
10Add chunk to cache
End
算法2.SSD淘汰算法
Begin:
1Get the victim from the SSDlru
2Remove victim from SSDlru
3Add victim adderss to SSD FreeLists
4Erase victim from SSD
End
算法3.块的读算法
Input:chunk为要查找的chunk
Begin:
1if find chunk in memory then
2read chunk from memory
3else
4if chunk in SSD
5 read chunk from SSD
6else
7 read chunk from Disk
8 Add chunk to SSD
End
算法3描述了读chunk的过程。首先获得chunk的描述(属性ID,数组ID等),从内存中查找chunk,命中则直接读取。否则,通过图3中的SSD映射表,根据属性ID,数组ID等信息,判断SSD中是否存在此chunk。如果存在,则根据SSD映射表中的地址找到在SSD缓冲池中的位置,读取chunk。如果不存在,则从磁盘中读取chunk,并将chunk加入到SSD中。
4 实验设计
这一节主要介绍实验的配置。为了验证构建的SSD缓存的效果,对比了FASTDB和基于SSD的缓存系统CSBSF的性能。
所有实验都在Intel(R)Xeon(R)CPU E5-2630 V2@2.6GHz(2 Sockets),4核amd64,CentOS6.6操作系统上运行。我们的FASTDB和CSBSF中使用SciDB的版本是15.7,SciDB有4个结点,SciDB中每个结点均配置8G内存,500GB硬盘,转速为15000r/ min。两者用的内存,硬盘配置完全相同。其中CS⁃BSF中用的是三星(SAMSUNG)750 EVO 250G SA⁃TA3固态硬盘,总容量设为200GB。
实验的数据量分为四个规模,分别为5GB、50GB、100GB、250GB。选取天文学中常见的8个查询(Q1-Q8)作为代表,测试缓存的效果。主要测试查询时间、磁盘IO、网络开销等指标。每次实验结束后,数据都不清空。
5 实验结果及性能分析
查询结果如表1所示。其中,第一类为简单查询语句(Q1-Q6)。查询特定区域,满足特定条件的天体;该类语句可以归为“SELECT*FROM* WHERE*”形式。
第二类查询为带JOIN的简单查询语句(Q7)。例如找出混杂在星体表Star中的星系,并输出该星系的光度以及天体的objID等信息。该类语句可以归为“SELECT*FROM*JOIN*ON*WHERE*”形式。
第三类查询为带JOIN的复杂条件查询语句(Q8)。例如合并所有星系,并输出星系的总数。该类语句可以归为“SELECT*FROM*AS*JOIN *ON*AS*JOIN*ON*WHERE*AND*”形式。

表1 各个查询执行时间(s)
SciDB中一个chunk存储了一个属性,SciDB中一个一维数组[i=0:*,500000,0],假设有三个实例分别存储这些数据。采用round robin的方式存储,主要是为了负载均衡[20]。则实例0将存储chunk{0},chunk{1500000},chunk{3000000};实例1将存储chunk{500000},chunk{2000000},chunk{3500000},实例2将存储chunk{1000000},chunk{2500000},chunk{4000000}。其中实例分布在各个节点中。正是这种灵活分割的垂直存储的数据结构,使得FASTDB能够更好地并行执行。但是当执行复杂查询时,例如Join或者Aggregate查询,数据库涉及到大量的对磁盘的随机访问以及大量的网络开销,因此,将以后可能访问的数据缓存到SSD上,由于SSD随机访问的开销比磁盘访问开销小,因此能够有效提升数据库性能。
如图4中所示,当数据量为5GB时,数据能够完全放入内存,当请求到来时,数据能够在内存中命中,因此,有SSD时和没有SSD做缓存时候的性能几乎一样。随着数据量的增大,数据不能够完全在内存中进行,内存出现换进换出现象,若换出的chunk需要再次被访问,若能够在SSD中命中,那么数据库的性能能够在一定程度上得到提升。图5,当数据量小于内存时,有缓存和无缓存时间无明显差异;当数据量大于内存时,性能提升增幅从5%到25%,增长速度提升了20%。当数据量大于内存而小于SSD缓存的容量时,由于SSD缓存的命中使得FASTDB性能提升越来越快。而从100GB到250GB的时候,性能提升增幅从25%~34%,增长速度提升了9%。图5中相对执行时间表示查询执行过程中每隔40s取样一次,获得磁盘读取的字节数。图7中相对执行时间类似。随着数据规模越来越大,由于FASTDB中采用分发数据到节点的方式进行查询,分布式数据库FASTDB中产生的网络开销也越来越大,网络性能越来越差,此时网络开销成为主要瓶颈,因此性能增长幅度变缓。

图4 不同数据量下有缓存和无缓存时查询响应时间
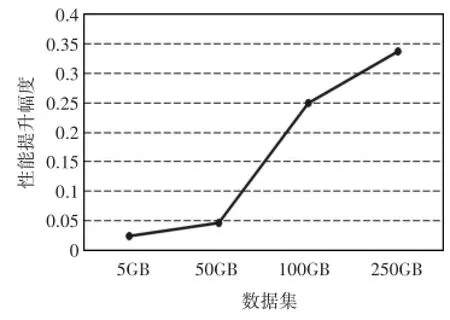
图5 不同数据量下有缓存的性能增长幅度
如图7所示,在没有缓存的情况下,从磁盘读的字节数比有缓存时候的字节数多。这是因为二级缓存的存在,使chunk在内存中缺失时,一部分数据在SSD中命中,所以从磁盘读的字节数减少,从而提升了查询的性能。
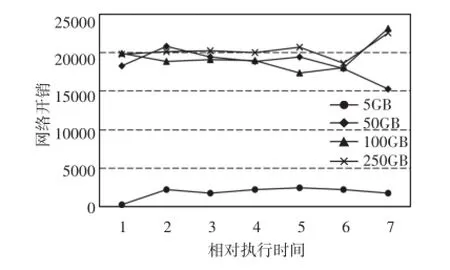
图6 有缓存下,不同数据量的数据产生的网络开销

图7 有缓存和无缓存时,执行查询磁盘读的字节数
6 结语
本文针对阵列数据库中复杂查询效率低下的问题,提出了用新型硬件SSD作为数据库二级缓存的方法。当进行复杂查询,查找的chunk不在内存时,若在SSD中能够命中,则能够有效提升数据库性能。结果表明,使用SSD作为二级缓存有34%左右的性能提升。随着数据量的增大,网络开销也越来越大,分布式查询中的主要瓶颈从I/O变为网络开销,下一步我们的研究方向是降低网络开销,进一步提升阵列数据库的性能。
[1]Soroush E,Balazinska M,Wang D.Arraystore:a storage manager for complex parallel array processing[C]//Pro⁃ceedings of the 2011 ACM SIGMOD International Confer⁃ence on Management of data.ACM,2011:253-264.
[2]Li H,Qiu N,Chen M,et al.FASTDB:An Array Database System for Efficient Storing and Analyzing Massive Scien⁃tific Data[C]//International conference on algorithms and architectures for parallel processing,2015:606-616.
[3]Hey T,Tansley S,Tolle K.The Fourth Paradigm:Data In⁃tensive Scientific Discoveries[J].Microsoft Research,2009,1:153-164.
[4]Gray J,Liu T D,DeWitt D,et al.Scientific Data Manage⁃ment in the Coming Decade[R].MSR-TR-2005-10,2005,34:35-41.
[5]Ivezic Z,Tyson J A,Abel B,et al.LSST:from science drivers to reference design and anticipated data products[J].American Astronomical Society,2014,41:336.
[6]Li J,Cui C,He B,et al.Review and Prospect of astronomi⁃cal database[J].Progress in Astronomy,2013,31(1):1-16.
李建,崔辰州,何勃亮,等.天文数据库回顾与展望[J].天文学进展,2013,31(1):1-16.
[7]Stonebraker M,Becla J,Dewitt D,et al.Requirements for Science Data Bases and SciDB[C]//Conference on Innova⁃tive Data Systems Research(CIDR)Perspectives,2009:7-16.
[8]Brown P G.Overview of sciDB:large scale array storage,processing and analysis[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data.ACM,2010:963-968.
[9]Xiao W,Lei X,Li R,et al.PASS:A Hybrid Storage Sys⁃tem for Performance-Synchronization Tradeoffs Using SS⁃Ds[C]//IEEE,International Symposium on Parallel and Distributed Processing with Applications.IEEE,2012:485-91.
[10]Yamato Y.Use case study of HDD-SSD hybrid storage,distributed storage and HDD storage on OpenStack[C]// international database engineering and applications sym⁃posium,2015:228-229.
[11]Jo H,Kwon Y,Kim H,et al.SSD-HDD-Hybrid Virtual Disk in Consolidated Environments[C]//European con⁃ference on parallel processing,2009:375-384.
[12]Huang M,Serres O,Narayana V K,et al.Efficient cache design for solid-state drives[C]//Proceedings of the 7th ACM international conference on Computing frontiers. ACM,2010:41-50.
[13]Jiang D,Che Y,Xiong J,et al.uCache:A utility-aware multilevel SSD cache management policy[C]//High Per⁃
ADCS:An Array Database Caching Technology Based on SSD
YANG Qing1,2LI Hui1,2CHEN Mei1,2DAI Zhenyu1,2ZHU Ming3
(1.College of Computer Science and Technology,Guizhou University,Guiyang550025)(2.Guizhou Engineering Laboratory for Advanced Computing and Medical Information Services,Guizhou University,Guiyang 550025)(3.National Astronomical Observatories,Chinese Academy of Sciences,Beijing100012)
This paper introduced solid state disk(SSD)as cache in array database,designed a hierarchical storage architec⁃ture with memory-SSD-disk and proposed an array database caching technology based on SSD(ADCS),which in granularity of chunk and finally realized in FASTDB.The least recently used(LRU)algorithm was used as the cache elimination algorithm. Through cache construction technology between the memory and disk,the query performance of array database was increased by about 34%.
L2 cache,array database,ADCS,LRU
TP392
10.3969/j.issn.1672-9722.2017.05.029
2016年11月4日,
2016年12月19日
国家自然科学基金(编号:61462012,61562010,U1531246);基于云计算的医疗信息管理系统关键技术研究及应用(编号:GY[2014]3018);贵州省重大应用基础研究项目(编号:JZ20142001,JZ20142001-01,JZ20142001-05);贵州省教育厅自然科学项目(黔科合人才团队字[2015]53号);贵州大学研究生创新基金(院级);贵州大学研究生创新基金(编号:2016049)资助。
杨庆,女,硕士研究生,研究方向:分布式数据库、数据库查询优化。李晖,男,副教授,硕士生导师,研究方向:大规模数据管理与分析,高性能数据库,云计算。陈梅,女,硕士生导师,研究方向:数据库新技术、计算机应用技术。戴震宇,男,实验师,研究方向:数据库新技术、计算机应用技术。朱明,男,研究员,博士生导师,研究方向:射电天文学,天文大数据处理。
猜你喜欢
电脑报(2022年13期)2022-04-12 00:32:38
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电脑报(2020年24期)2020-07-15 06:12:41
电子制作(2019年13期)2020-01-14 03:15:18
电脑爱好者(2019年2期)2019-10-30 03:45:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
网络安全和信息化(2017年3期)2017-03-10 07:45:51
网络安全和信息化(2016年8期)2016-11-26 06:42:50
