
面向学术文献的知识挖掘方法研究
2017-06-03 14:17王凯孙济庆李楠
现代情报 2017年5期
王凯++孙济庆++李楠

〔摘要〕学术文献中包含的大量有价值的知识往往无法在摘要中体现出来。本文提出一种基于位置加权的核心知识挖掘方法,旨在以句为知识处理粒度,抽取正文中的核心句子作为独立的知识单元。该方法通过量化句子间的关联,将正文表示成一个以句子为节点,句子间关联为边的文本关系网络,提出基于章节的位置加权算法,结合社会网络分析方法,挖掘出文本中核心知识单元部分的句子。实验结果表明,该方法可以实现对文章核心章节中重要句子的抽取,达到初步预期效果。
〔关键词〕学术文献;知识挖掘;方法;位置加权;知识抽取;文本网络;社会网络分析
DOI:10.3969/j.issn.1008-0821.2017.05.009
〔中图分类号〕G203〔文献标识码〕A〔文章编号〕1008-0821(2017)05-0047-05
Research on Method of Knowledge Minning in Academic DocumentsWang KaiSun JiqingLi Nan
(Institute of Science and Technology Information,East China University of
Science and Technology,Shanghai 200237,China)
〔Abstract〕There is abundant valuable knowledge inside academic documents that is not revealed in abstracts.This paper promoted a method of core knowledge discovery based on position weights,aiming to extract the core sentences as separated knowledge units in the main text with the processing size of sentence.By measuring the connection between sentences,the paper transformed main text into a text network that considers sentences as dots and connection between sentences as sides.An algorithm to compute position weights based on chapters was promoted in this paper.With the help of social network analysis,the paper could find sentences that revealed the core knowledge of the text.The result of the experiment showed that this method could realize the extraction of key sentences in the core chapter from the text,which is primarily expected.
〔Key words〕academic documents;knowledge minning;method;position weight;knowledge extraction;text network;social network analysis
互联网技术的发展使得信息,尤其是文本信息呈爆炸式的发展,在海量的文本信息面前,人们希望可以从中抽取出最关键最有价值的信息,并转化成知识进行存储应用。学术文献中包含大量有学术价值的知识,特别是期刊论文,凝聚着科学家的研究成果与智慧,论文中知识点非常丰富,而且比较新颖,实现自动对学术文献中的关键知识进行提取并利用是一个研究趋向。学术文献与其他类型的文献,如新闻、博客、网页等文献不同,学术文献具有独特的结构化特性,其基本形式为标题、摘要、关键词、正文、参考文献组成;而正文又通常包括引言、相关研究、方法、实验、结论几大部分。早期的研究主要是针对学术文献的题录信息来研究学术文献中所包含的主题内容,利用标题、关键词、参考文献以及摘要作为研究对象。摘要和关键词虽然可以对文献的内容进行高度概括和总结,但是却往往没有体现文献中的核心知识,这些核心知识往往包含在正文之中。为更好地挖掘文献中内涵的知识,本文提出一种位置加权的方法,以句子为粒度,将学术文献正文表达成一个句子为节点的文本网络,通过句间关系来抽取出学术文献中的核心知识。
1相关研究
知识抽取(Knowledge Extraction)是对蕴含于文献中的知识经识别、理解、筛选、格式化,从而把文献中的各个知识点抽取出来,是信息抽取的升华和深化[1]。温有奎,朱晓芸,文孝庭等人在国内较早提出了知识元的概念,表示知识单元是文章中可以表达知识且可以独立使用的最小单位,并对其的抽取规则进行了描述[2-5]。知识抽取的方法可以分为3大类:基于模式匹配的抽取方法、基于本体的抽取方法以及基于语义的抽取方法。
1)基于模式匹配的抽取方法主要用于实体和属性的抽取,适用于有一定规则可循的抽取对象。Chunxia Zhang和Peng Jiang研究了如何对汉语语料进行定义抽取。他们通过设定句子模式,然后利用模式的匹配进行抽取;温有奎等利用学术文獻中创新点表述的句子结构特点对创新点进行抽取[6-7]。这种方法要求所抽取的知识表述具有一定的规则和模式,对于那些大量无规则的非结构化文本无法很好地完成抽取工作。
2)基于本体的抽取方法是通过建立本体描述概念与概念之间的关系,再基于建立好的本体在文档中抽取相匹配的知识内容。车海燕等提出基于本体主题的属性识别方法和基于本体属性约束的三元组元素识别方法,抽取出非结构化文本中隐含的知识元素,并找出元素间的属性关系[8]。本体是一个理想的可以表达领域内所有语义及语义关系的一种语料库,基于本体的抽取方法的效果好坏完全取决于本体建立的完善程度。基于语义的抽取方法是结合自然语言处理技术(Nature Language Processing,NLP)、语义Web、文本挖掘、机器学习、句法分析以及图论等理论与技术,深入到组成文档的词句和语法结构来理解文本所包含的语义。Dingding Wang等人指出常用的给句子打分的方法只把句子当作独立的对象研究而忽略了上下文中隐含的主题,而且打分的方法缺少清晰严格的概率解释,并提出一种使用贝叶斯算法的基于句子的主题模型进行多文档的自动摘要研究[13]。Rada Mihalcea结合基于图论的网页信息组织的3种常用算法:HITS、Positional Power Function和谷歌的PageRank算法,提出了以句子为节点、句子之间的关联为边的文本关系图方法,不仅考虑到句子内容的特征还考虑了句子之间的相互影响[14]。Dingding Wang等人提出了一种自动文档摘要方法,以词共现计算句子间的相似度,构建相似矩阵,再基于对称矩阵因式分解法对文本的句子进行聚类并从每类中抽取出目标句子组成摘要[15]。
3)基于语义的抽取方法研究着重关注文本的语义,试图让计算机能够像人类一样理解文本,但是目前尚且没有一个可行且效果理想的抽取方法,但是对于文献中基于句子粒度的抽取方法从只考虑句子本身,慢慢发展到从文献整体研究句子与句子之间的联系来考量句子的重要程度。本文所采用的研究方法正是将正文看作是由句子构成的一个复杂文本网络,通过句子之间的联系去寻找文献中的核心模块。
2核心知识抽取方法
每一篇学术文献都有其核心的知识点,是其文章的学术价值所在,而这些核心知识往往没有在摘要中全面体现出来,仅从摘要无法反映文献的内含的所有知识。为能充分挖掘文献中包含的各知识点,本文提出了一种以句子为粒度的基于章节位置加权的核心知识抽取方法,抽取出学术文献中能反映文章核心知识的核心句子。
21基础知识抽取
211构建复杂句子网络
以文献中的句子为粒度是本方法研究的核心。构建复杂句子网络是以句子为网络中的节点,以句子之间的关联度为节点间的边,连接构成一个网络结构。因此,计算句子之间的关联度是构建复杂句子网络的关键,句子关联度的计算效果如何直接决定了构成的句子网络所能反映的文本内容的质量。
句子是学术文本中表达一个完整语义内容的最小单位,而句子从形式上是由词和语法结构组成。通过句子与句子之间复杂的关联关系可以反映出整个文本网络的关联情况,并且找出网络中核心的区块。本文采用在统计自然语言处理中被广泛接受和采用的方法,以词耦合数来计算两个句子之间的简单关联度。这种方法中,在对句子Si进行分词、过滤停用词等操作之后,每个句子Si被处理成由若干实义词组成的词集Si(W1,W2,…,Wn),若两个句子Sj和Sk的词集中都出现了相同的词W,那么这两个句子之间就出现了一个词耦合对,只要两个句子之间出现了至少一个词耦合对,就在Sj和Sk两个句子节点之间形成一条边。将文章中的句子两两进行如此处理计算,最终可以形成一个以句子为节点、句子相似度为边的句子网络。但是,这样方法形成的句子网络中每条边的价值都是相等,句子之间要么相似要么不相似,而在实际应用中,文本中句子间的相似度是有很大差异的。因此,在计算句子间相似度的时候,使用两个句子之间出现的词耦合对的次数作为句子间的相似度,若句子Sj和Sk之间有n个词耦合对,则Sj和Sk之间的相似度为n,由此形成的句子网络是带有权重的复杂句子网络[18]。
句子之间的关联度除了用词关系进行描述,句子的语法结构也起着很大的作用。在学术文本中,两个句子之间的语义关联绝不仅仅由词来表现,句子内部以及句子之间还有语法结构来表现句子的语义。如“虽然…但是…”、“如果…就…”等复句结构,同样的词出现在从句和主句从能反映句子内容的程度并不一样。而句子之间往往会有类似“基于该理论,…”、“因此……”、“…该方法…”等代词和连词来表现句子之间紧密的联系,而这样的关联通过词耦合对的方法是很容易被削弱或忽略。
212社会网络分析
通过上述方法构成的复杂句子网络类似于一个社会网络,可以使用社会网络分析中对节点重要性的评价方法来寻找句子网络中的核心句子。常用的社会网络分析方法被称为度分析方法,以计算节点的中心度来评价节点的重要性,常用的中心度计算方法有点度中心度、中介中心度和接近中心度[20]。点度中心度用网络中与某节点有联系的节点的数量来衡量该节点在网络中的中心地位,如果一个节点与其他节点之间有直接的联系,则该节点就居于中心位置,有较大的“权力”;中介中心度通过某节点出现在其他两点之间的路径上的数目来衡量该节点的控制能力,如果一个节点出现在其他两个节点的路径上,则认为该节点处在网络中的重要地位;接近中心度通过某节点与其他节点的最短路径来反映该节点不受控制的能力[21-23]。
学术文本中的核心句子是文章的叙述核心知识,应该处在网络关联的中心,其他句子通过核心句子相互产生关联。因此,本文使用中介中心度来寻找学术正文中的核心句子。
22位置加权
学术文献是结构性比较强的文献类型,作者在撰写的时候通常会按照章节把文章的内容分為几个部分。常见的学术文献的结构有引言、相关研究、方法、实验以及结论,但是不同学科不同类型的学术文献所包含的结构并不相同,理论性研究或综述一般没有方法和实验部分。
本文基于复杂句子网络提出了一种基于章节网络位置加权方法。学术文献正文按照一级章节划分为N个部分,在构建正文的复杂句子网络时,对每个句子进行章节区分,比如第一部分的第10个句子序号为1010。最终在形成复杂句子网络的同时,也形成了以章节为节点的网络,章节之间也以词耦合对的形式联系着,章节之间联系的程度由词耦合对的数目决定。但是由于章节有长度的区别,篇幅越大,出现重复词耦合对的可能性越大,为了消除篇幅的影响,去掉章节之间的重复词耦合对。由于章节的网络只有4~5个节点,且各个章节之间都会有不同程度的联系,因此不适用社会网络分析方法计算中心度,本文提出一种计算章节重要性的方法来确定正文第i章节的权重wi:
wi=∑j=iNiN-1·Lij∑i,jLij(1)
其中,wi代表文章第i部分应赋予的权重,N为一级章节的数目,Ni为与第i部分直接连接的一级章节数,Lij为章节i与章节j间出现的词耦合对数。计算出各个一级章节的权重之后再对相应章节的句子的中介中心度进行加权,得到位置加权后的中介中心度WCij:
WCij=wi×Cij (2)
其中,WCij为位置加权后的第i部分的第j个句子的中介中心度,wi是第i部分的权重,Cij是未加权的第i部分第j个句子的中介中心度。根据加权后的中心度后由高到低进行排序,得到文章的关键句子。
3实验及分析
31数据准备
本文的实验数据选取10篇情报学领域的学术文献,所选的文献类型各有不同但均来自同一期刊,且为了方便对比权值计算的效果,所选文献都包含5个章节。
32实验过程
321建立句子网络
以一篇“基于商品属性与用户聚类的个性化服装推荐研究”的文章[26]为例进行说明。首先要对原始数据进行预处理,将每篇学术文献以一级章节标题分隔,再对具体的每句话以句号为分隔符进行分隔,对文章正文的每句话进行标识。标识的方法按照“章节序号+句子序号”进行,例如,第一章节中的第三个句子编号为1003,第三章节中的第48个句子的编号为3048,以此类推。第二步对正文进行分词处理,筛除停用词,把每个句子转换成了一个词袋。第三步通过计算句子与句子之间的词耦合对来表示句子间的相似度,最终形成了一个句子相似矩阵,矩阵中的每一个值都代表着两个句子之间的联系,从而形成了一个句子网络,利用UCINET可视化出每篇文献正文的句子网络,如图1所示。利用UCINET可以直接计算出每个句子的中介中心度。
322基于章节的位置权重
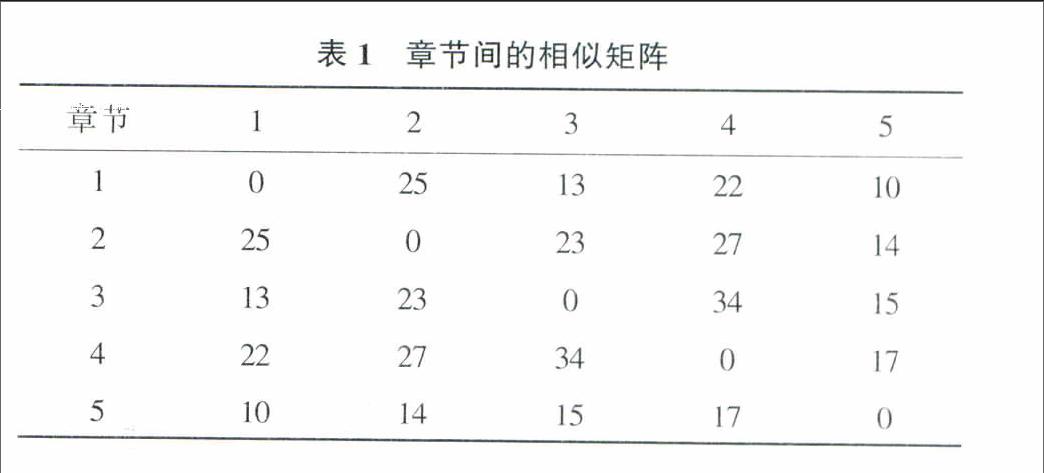
类似于句子间的相似度,现在将范围扩大到章节,把正文分为以章节为单位,而每个章节又都可以表示成一个大词袋,为了消减章节长度的影响,每个词袋中1个词只出现1次。类似地,计算章节与章节之间的词耦合对,形成一个相似矩阵,如表1所示,矩阵中的每个值表示两个章节之间的词耦合对数。
3结果及分析
对比这篇文章的加权前后的中介中心度句子抽取结果,各取排序前10的句子,如表3所示。
从表中可以看出,总体上,加权后的抽取结果可以提升文章核心部分的内容的排序,从而把文献中核心的知识块抽取出来,所抽取出的句子相对于未加权的抽取结果更加详细与具体符合初步预期。但是也可以看出,由于本
表3加权前后排名前十的句子对比
对比序号句子内容加权前3001鉴于上述对推荐算法的研究分析,针对服装商品,本文提出基于商品属性内容与用户聚类的混合推荐模式。2030温廷新、唐小龙等提出基于商品内容与基于用户协同过滤的混合模式网络超市商品推荐(2013)[12],其中商品的内容特征提取太过宽泛,只有商品的外在属性值如价格、重量、销售量等。4001本文的研究对象为特定用户推荐个性化的服装商品,目前淘宝网也有类似的功能推荐,如“看了又看”、“掌柜推荐”等,个性化不够明显,只是根据关键词的简单关联推荐,推荐结果不够精确。3005实现混合推荐模式的过程如下图:1)对于任何一个进入店铺的用户,根据用户浏览的商品,基于商品属性利用KNN函数找到最相近的TOP-N推荐候選集;1012针对商品的个性化推荐问题,很多学者进行了研究,基于客户聚类的商品推荐[3],根据客户的浏览、点击、收藏行为进行聚类,实现推荐;或是根据用户对商品的评分矩阵,进行协同过滤推荐[4]。4034432评估绝大数的推荐系统都利用准确度评价推荐算法的好坏,假设用户可以对商品反馈喜欢或是不喜欢,那么准确度可以定义为推荐算法中预测的商品,用户喜欢的商品数所占比例。4021通过分析服装消费者在选购服装时注重的服装属性特征,我们从评价中提取用户所购买商品的尺寸颜色信息,以及店铺中用户对商品的评价信息,包括评价等级、评价内容,如宝贝有无色差、是否合身等。5001采用基于商品内容与用户聚类的混合推荐,能够很好地解决推荐中的冷启动问题。30073)求出该用户与类中其他用户之间的相似度,将相似度作为权重值赋给用户对商品的评分,综合用户的评分与权重值,对推荐候选集商品,进行喜好排序,得到最终的推荐列表;2008根据用户过去选择过的商品,从推荐商品中选择属性值相近的商品作为推荐结果。表3(续)
对比序号句子内容加权后4001本文的研究对象为特定用户推荐个性化的服装商品,目前淘宝网也有类似的功能推荐,如“看了又看”、“掌柜推荐”等,个性化不够明显,只是根据关键词的简单关联推荐,推荐结果不够精确。4034432评估绝大数的推荐系统都利用准确度评价推荐算法的好坏,假设用户可以对商品反馈喜欢或是不喜欢,那么准确度可以定义为推荐算法中预测的商品,用户喜欢的商品数所占比例。4021通过分析服装消费者在选购服装时注重的服装属性特征,我们从评价中提取用户所购买商品的尺寸颜色信息,以及店铺中用户对商品的评价信息,包括评价等级、评价内容,如宝贝有无色差、是否合身等。4038准确率是指在系统的推荐列表中,用户喜欢的商品数所占的比率;而召回率是指推荐列表中用户喜欢的商品数占用户所有喜欢的商品数量的比率。4004针对服装这一特定推荐对象,查找服装行业相关的类目信息,不同类目下的服装商品属性特征具有一定的差别。2030温廷新、唐小龙等提出基于商品内容与基于用户协同过滤的混合模式网络超市商品推荐(2013)[12],其中商品的内容特征提取太过宽泛,只有商品的外在属性值如价格、重量、销售量等。4025根据,前面提取的商品、用户特征属性,进行数据处理,可以将数据存储为三张数据表:商品信息表、用户信息表和用户评分表。4028取K=10,输出10件与该商品最相近的商品,也就是初始的推荐列表。4031用户对商品会有一个评分,将用户相似度作为权重值赋给商品评分,计算得到加权后的商品评分。3001鉴于上述对推荐算法的研究分析,针对服装商品,本文提出基于商品属性内容与用户聚类的混合推荐模式。
文计算句子间的关联度使用的是简单的词耦合数方法,导致句子间的关联无法更完整地表达,大大影响了句子抽取结果的准确率。
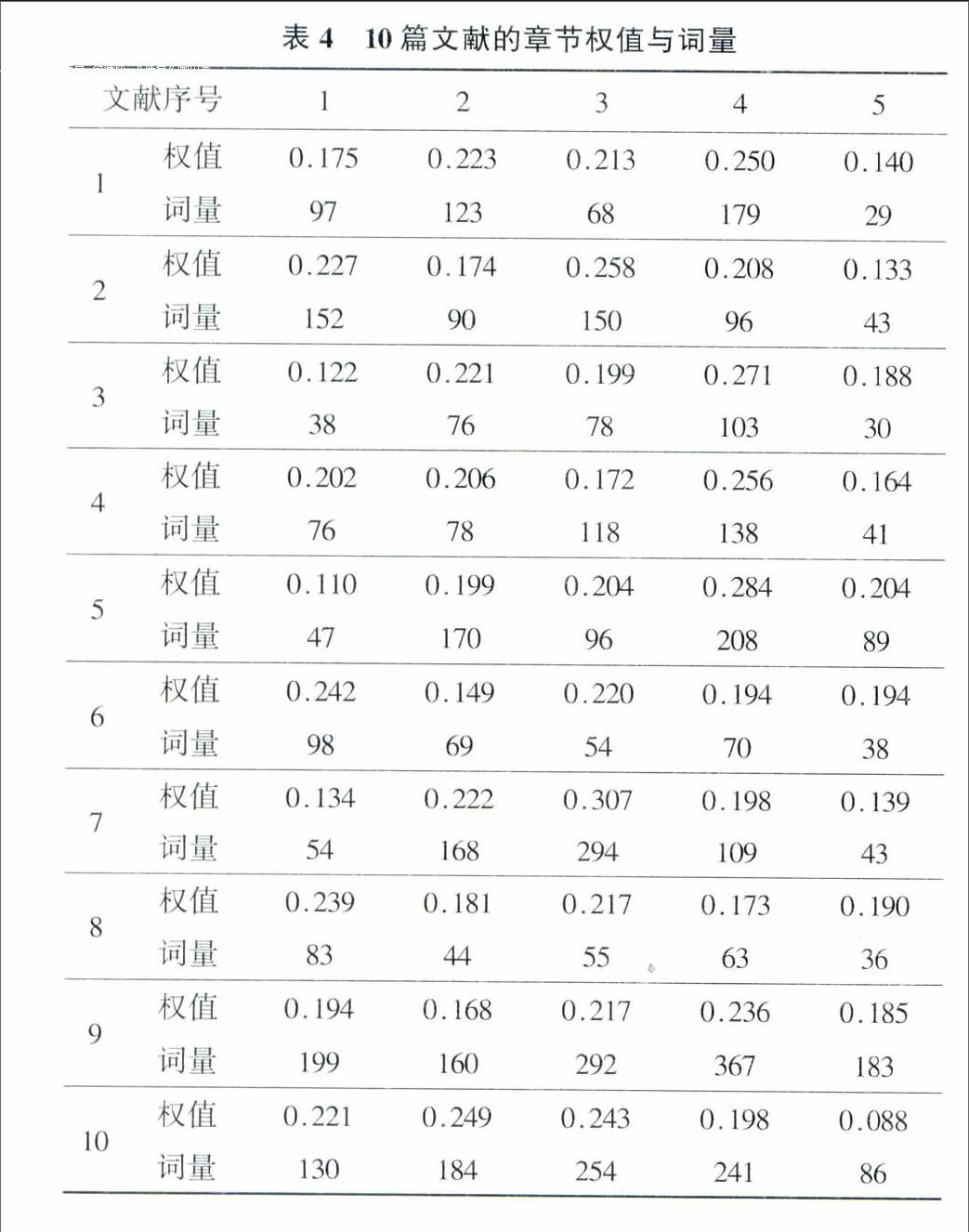
为了对比权值计算方法的效果,本文将10篇学术文献所计算出的各章节权值进行对比,综合各章节所包含的词量来探讨权值与章节长度之间的关系,从表4中可以看出,权值最高的章节大多分布在第三和第四章节,符合常理认识,不同类型的文献各个章节之间权值的分配也各不相同,初步符合本文的预期目标。但是不难发现,尽管权值大小与章节词量并不是完全正相关,但不可否认,章节的词量在一定程度上影响了权值的大小,这是使用词统计方法时很难避免的问题。
4总结与展望
本文针对学术文献中摘要与正文所反映的核心知识不对等的现象,提出了一种基于位置加权的核心知识抽取方法,将学术文献正文看作是一个以句子为节点,句子间的关联度为边的文本网络,并对基于章节的位置权重的赋值进行了探讨。从实验结果来看,该方法可以提高核心章节句子的重要程度,并且权值的分配也较为合理,达到了初步的预期效果。但是本文中所使用的方法也有其局限性,基于词统计的方法来量化句子之间的关联度无法表达句子之间复杂的语义关联,且所计算得出的权值一定程度上受到词数量的影响。因此下一步研究将着重关注句子与句子之间更为深入复杂的语义关联,尝试构建更为完整的文本语义网络。
参考文献
[1]化柏林.国内外知识抽取研究进展综述[J].情报杂志,2008,27(2):60-62.
[2]文庭孝.知识单元的演变及其评价研究[J].图书情报工作,2007,51(10):72-76.
[3]温有奎,徐国华.知识元链接理论[J].情报学报,2003,22(6):665-670.
[4]朱晓芸,陈奇,杨枨,等.决策支持系统中的广义知识元及模型库[C]∥1993中国控制与决策学术年会论文集,1993.
[5]温有奎,温浩,徐端颐,等.基于知识元的文本知识标引[J].情报学报,2006,25(3):282-288.
[6]Zhang C,Jiang P.Automatic extraction of definitions[C]∥Computer Science and Information Technology,International Conference on.IEEE,2009:364-368.
[7]温有奎,温浩,徐端颐,等.基于创新点的知识元挖掘[J].情报学报,2005,24(6):663-668.
[8]车海燕,冯铁,张家晨,等.面向中文自然语言文档的自动知识抽取方法[J].计算机研究与发展,2013,50(4):834-842.
[9]Luhn H P.The Automatic Creation of Literature Abstracts[J].Ibm Journal of Research & Development,1958,2(2):159-165.
[10]王洋洋.基于海量学术资源的知识元抽取研究[D].宁波:宁波大学,2014.
[11]Sekine S,Nobata C.Sentence Extraction with Information Extraction technique[C]∥2002.
[12]Shen D,Sun J T,Li H,et al.Document Summarization Using Conditional Random Fields[C]∥IJCAI 2007,Proceedings of the,International Joint Conference on Artificial Intelligence,Hyderabad,India,January.DBLP,2007:2862-2867.
[13]Wang D,Zhu S,Li T,et al.Multi-document summarization using sentence-based topic models[C]∥Acl-Ijcnlp 2009 Conference Short Papers.Association for Computational Linguistics,2009:297-300.
[14]Mihalcea,Rada.Graph-based ranking algorithms for sentence extraction,applied to text summarization[J].Unt Scholarly Works,2004:170-173.
[15]Wang D,Li T,Zhu S,et al.Multi-document summarization via sentence-level semantic analysis and symmetric matrix factorization[C]∥International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR 2008,Singapore,July.DBLP,2008:307-314.
[16]Li X,Zhu S,Xie H,et al.Document Summarization via Self-Present Sentence Relevance Model[M]∥Database Systems for Advanced Applications.Springer Berlin Heidelberg,2013:309-323.
[17]陶余会,周水庚,关佶红.一种基于文本单元关联网络的自动文摘方法[J].模式识别与人工智能,2009,22(3):440-444.
[18]刘红红,安海忠,高湘昀.基于文本复杂网络的内容结构特征分析[J].现代图书情报技术,2011,27(1):69-73.
[19]Su G C,Kim S B.Summarization of Documents by Finding Key Sentences Based on Social Network Analysis[M]∥Current Approaches in Applied Artificial Intelligence,2015:285-292.
[20]張瑞.基于复杂网络技术的社会网络结构分析[D].济南:济南大学,2015.
[21]朱庆华,李亮.社会网络分析法及其在情报学中的应用[J].情报理论与实践,2008,31(2):179-183.
[22]Freeman L C.Centrality in Social Networks:IConceptual Clarification[J].Social Networks,1979,1(3):215-239.
[23]Wasserman S,Faust K.Social network analysis:Methods and applications[J].Contemporary Sociology,1994,91(435):219-220.
[24]陆伟,黄永,程齐凯.学术文本的结构功能识别——功能框架及基于章节标题的识别[J].情报学报,2014,(9):979-985.
[25]黄永,陆伟,程齐凯.学术文本的结构功能识别——基于章节内容的识别[J].情报学报,2016,35(3):293-300.
[26]艾黎.基于商品属性与用户聚类的个性化服装推荐研究[J].现代情报,2015,35(9):165-170.
(本文责任编辑:郭沫含)
猜你喜欢
儿童故事画报(2019年5期)2019-05-26
旅游世界·旅游发展研究(2016年3期)2016-12-12
意林原创版(2016年10期)2016-11-25
中国教育信息化·基础教育(2016年9期)2016-10-18
Coco薇(2016年2期)2016-03-22
Coco薇(2015年1期)2015-08-13
小雪花·成长指南(2015年7期)2015-08-11
小雪花·成长指南(2015年4期)2015-05-19
