
学生成绩数据仓库模型设计与转换
2017-05-31 04:08洪明镜李民尧王首钧
魅力中国 2016年28期
关键词:数据仓库
洪明镜+++李民尧++王首钧
摘 要:学生成绩数据仓库的概念模型的主要任务就是需求分析,界定系统边界、确定主题域及内容是其所要完成的主要工作。运用数据仓库的理论与方法对学生成绩管理中各种相互联系的数据进行提取、综合,以成绩分析作为主题建立学生数据仓库可以帮助教师找到决策所需信息,以达到优化教学的目的。本文主要是按照逻辑模型技术对学生成绩数据库进行设计。
关键词:学生成绩 数据仓库 模型设计
一、学生成绩数据仓库模型设计
按照逻辑模型技术可以把数据建模分为两类,一类是维度建模,其又可分为星型结构以及雪花型结构,维度建模是数据仓库中典型的逻辑结构,是针对相对独立的业务创建针对性的模型。另一类是实体关系建模,此类模型的建立可以通过概念结构设计中的E-R图来完成。下面我们来看一下这几类模型的设计分析。
1、星型结构
星型结构是由一个事实表和一组维表组成的,是一种多维的数据关系。每个维表都有一个维作为主键,事实表主键的每个元素都是维表的外键,也可以说事实表的组件就是由这些维组成的。事实表包含联系事实与维度表的数字度量值和键,它是数据仓库架构中的中央表。维表是数据仓库中的表,包含创建维度所基于的数据,主要是描述实时数据表中的数据。
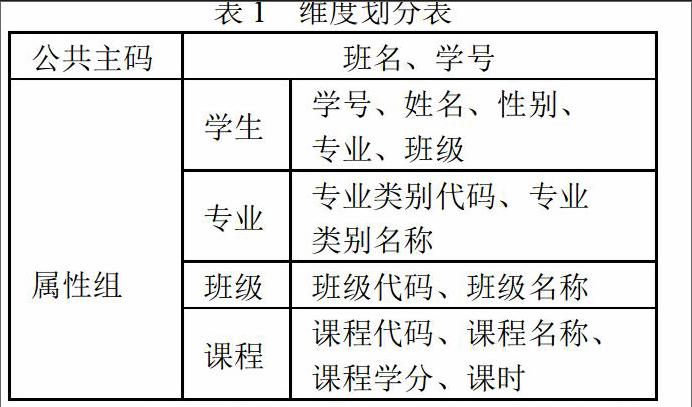
本系统中的分析主题就是学生成绩分析,在此我们主要是研究数据仓库系统的学生成绩分析。依据学生成绩分析数据库中的数据,其维度划分可以归结为下表:
2、关于学生成绩数据仓库设计的雪花型结构
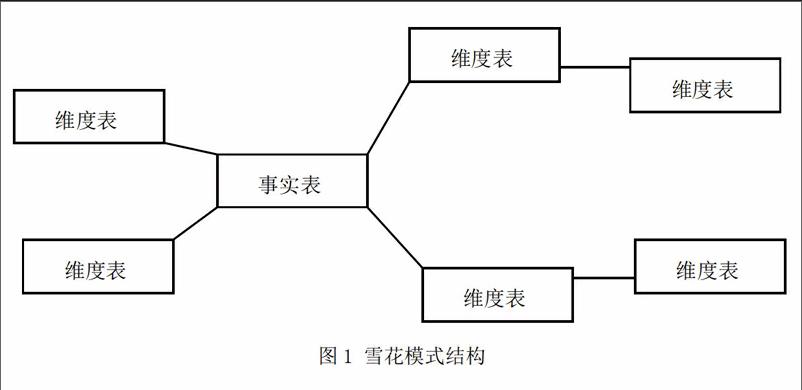
雪花型结构是由多个表定义一个多个维度,可以说是星型结构的一个扩展,其结构域星型结构本质是相同的。该结构中事实数据表与主维度表连接,同时其他的维度表也连接到主维度表。雪花型结构也是由事实表和维表构成的,它与星型结构最大的区别在于该结构将维表进行了规范化。所以雪花型结构在维度较多的情况下也可以使复杂维度的层次结构清晰,可以节省存储空间。但是也应该看到在查询的时候,雪花型结构设计的连接操作更多。雪花型结构的示意图如图1。
在进行数据仓库建模中,星型结构和雪花型结构的优点是比较明显的,这两种结构比传统的方法更加简单,而且用户也很容易就能理解模型;这两种结构使数据库的设计面向用户的查询。
二、数据库中数据的抽取、转换和加载
数据仓库中的数据是统一、完整的数据集合,仓库中数据的获取要经过数据的清洗和转换,而不是简单地从数据源中直接转移过来。如果只是对原始数据进行简单的堆砌,而不加以清洗和转换,就会导致不必要的大量数据的存在,也会产生数据间不完整、不一致的情况。由此可以看出来在数据仓库构建与运行中,数据的抽取、转换和加载是非常主要的环节,该项工作做的好坏直接关系着数据和分析的正确性。
1、关于数据抽取
数据仓库中的数据量非常大,所以在数据抽取中应该采取按需抽取的原则,而不能够从数据库中抽取所有的数据。数据抽取的主要依据可以归为两点,首先是按照用户所使用的数据进行抽取,抽取的数据应该根据用户所关心的内容进行抽取,如果是管理部门可能比较关心学生的基本信息情况,而教务部门可能更加关注的是抽取学生的成绩信息。其次是可以依据某个主题来进行学生相关数据的抽取工作,可以采用手动、自动和半自动的方式进行,也可以根据需要多种方式结合。
2、关于数据仓库建立过程中数据的转化
将数据库中不同类型的数据进行转化,实现数据的统一规范,可以避免由于数据类型不同而产生的不一致性。数据仓库中数据转化的关键就是“对数据进行统一。数据转化就是应该将不同格式的数据类型转化成统一的数据格式,数据转化的目的就是为了改善数据仓库中数据质量,所以应该完成数据的清理和转化之后再进行数据仓库中数据的装载工作,”以消除数据错误和不一致问题,填充数据空缺值,消除数据噪声影响,纠正数据集中的不一致数据,识别数据集中的孤立点等。在学生成绩数据库中的相关数据都是非常重要的,一般不会存在错误现象,因为这些数据都是经过多次复查而得到的。
3、关于数据的加载
首先对转化后得到的相关数据进行清理,然后将这些数据装入数据仓库中,通常会涉及到将大量数据从源数据库系统传送到目标数据仓库。可以通过设置代理等方式进行数据加载,一定要保证数据的完整性。对學生成绩数据信息进行定期的转换和加载,其目的就是为了保持学生数据仓库和学生成绩数据库的一致性。一般采用设置代理的方法,对学生成绩数据库中的信息进行定期的转换和加载,时间一般是设置在每年的2月、8月和11月的第一天,这样就可以把新生的基本信息以及每学期的学生成绩及时地转换加载到数据仓库中,这样的方法可以使数据仓库数据和学生成绩数据库数据一致起来。
参考文献:
[1] 郭桂蓉等编著.模糊模式识别[M]. 国防科技大学出版社, 1992
[2] 王国胤编著.Rough集理论与知识获取[M]. 西安交通大学出版社, 2001
[3] 曾黄麟编著.粗集理论及其应用[M]. 重庆大学出版社, 1998
[4] 毛国君等编著.数据挖掘原理与算法[M]. 清华大学出版社, 2005
猜你喜欢
江苏教育·职业教育(2022年6期)2022-07-08
电子乐园·下旬刊(2021年3期)2021-02-08
计算机与网络(2019年20期)2019-09-10
计算机世界(2019年28期)2019-08-06
电子技术与软件工程(2016年22期)2016-12-26
国外科技新书评介(2016年8期)2016-11-16
现代经济信息(2016年7期)2016-05-19
电子技术与软件工程(2014年22期)2015-02-04
卷宗(2014年12期)2014-04-02
法制与社会(2009年26期)2010-06-29
