
基于教育数据挖掘的在线学习者学业成绩预测建模研究
2017-05-30 05:19陈子健朱晓亮
中国电化教育 2017年12期
陈子健 朱晓亮

摘要:该文采用数据挖掘和机器学习的方法,研究从教育数据中挖掘影响在线学习者学业成绩的因素并构建分类预测模型。首先,通过计算所有单个数据属性和学业成绩类别之间的相关系数和计算所有属性的信息增益率两种方法共同确定学业成绩的影响因素。然后,提出采用集成学习的方法构建集成式学业成绩分类预测模型,并比较多种算法构建的单一分类模型和集成分类模型的性能。最后,进一步采用嵌套集成学习的方法构建在线学习者学业成绩分类预测模型,并对模型的性能进行评估。研究成果可以为在线学习者学业成绩影响因素研究和预测建模研究提供借鉴,也有助于推进在线学习学业预警、学业成绩预测和评价的实践。
关键词:教育数据挖掘;机器学习;预测建模;学业成绩;在线学习
一、引言
在线教育已经逐渐被人们认可和接受,特别是在K12教育、语言类教育和职业技能培训领域发展迅速。截至2016年12月,中国在线教育用户规模达1.38亿,较2015年底增加2750万人,年增长率为25.0%。不同于面对面的课堂教学情境,在线学习中师生处于分离状态,且学习者数量庞大。如何对在线学习者的学业成绩进行预测,依据预测结果实施学业预警,并为教学决策提供依据,是在线教育需要解决的一个问题。利用教育数据挖掘技术,通过数据驱动的方式构建在线学习者学业成绩预测模型,即从数据中自动学习预测模型是目前研究的热点。然而,采用决策树、人工神经网络等算法训练的单一预测模型性能不稳定,对数据变化比较敏感。针对上述问题,本文基于“集体决策优于个体决策”的假设,尝试采用集成学习(EnsembleLearning)方法构建集式模型。在实验验证的基础上,进一步采用嵌套集成学习方法构建在线学习者学业成绩分类预测模型,并对模型的性能进行评估分析。
二、概念界定及相关研究
(一)概念界定与分析
教育数据挖掘(Edueational Data Mining,EDM)是数据挖掘技术在教育领域的应用。根据国际教育数据挖掘工作组网站的定义,教育数据挖掘是指运用不断发展的方法和技术,探索特定教育环境中的各类数据,挖掘出有价值的信息,以帮助教师更好地理解学生,并改善他们所学习的环境,为教育者、学习者、管理者等教育工作者提供服务。EDM与学习分析(Learning Analytics,LA)交叉,但是两者又存在差异:(1)EDM强调自动发现,侧重建立模型和发现模式,多采用机器学习和数据挖掘技术;LA尽管也强调自动发现,但同时还需要人为干预,多采用统计分析技术。(2)EDM起源于智能辅导领域,强调预测学习者的学业成绩和关注预测建模;LA也包括这些要素,但它更强调系统干预,注重个性化和自适应。(3)LA侧重于描述已发生的事件或其结果,而EDM侧重于发现新知识与新模型。
預测建模(Predictive Modeling)是指根据现有数据先建立一个模型,利用模型可以对未来的数据进行预测。本研究中的学业成绩预测建模主要是利用已知学生学业成绩类别的训练数据训练得到一个分类函数或分类模型(即分类器),并评估模型的性能。学业成绩预测的目的是将学习者在学习过程中的相关数据输入预测模型,预测学习者在学习结束时可能的成绩类别,为是否进行学业预警和调整教学策略提供依据。
(二)相关研究
教育数据量的急剧增长、数据类型的多样性、数据的可获取性以及数据挖掘技术的发展等多种因素共同推动了教育数据研究的发展。学习者模型、学业成绩预测、行为模式发现、学习反馈与评价等是当前教育数据研究的主要热点,已有的学业成绩预测相关研究,根据其研究的侧重点大致可以分为三类。
1.学业成绩预测与评价的理论模型研究
美国佛罗里达农工大学的Ohia博士在Nichol的五步模型的基础上,提出了采集学业成绩相关数据并进行评价的六步模型一FAMOUS,模型名称由六个关键步聚的首字母组成。蔚莹等对QFD(质量功能展开)模型进行适当的调整,提出基于QFD的学生学习能力评估理论模型。张涛等参考Kirkpatrick评估模型建立了翻转课堂环境下的学习绩效评价理论模型。武法提等基于学习行为分析模型和学习结果分类理论设计了学业成绩预测框架,包括学习内容分析、学习行为分析和学习预测分析三个模块。金义富等在讨论学业预警系统设计框架的基础上,提出了课程、课堂、课外“三位一体”预警信息发现与生成模型LAOMA。
2.学业成绩影响因素研究
Carmel McNaught等关注香港高校中e-Learning学习过程和学业成绩预测,探索学习设计,特别是学习设计中的策略设计与学习环境设计,与学业成绩之间的关系。Galbraith,Craig S调查116门课程的学生评教与学生学业成绩的相关数据,研究学生评教与学业成绩和教学效能之间有无相关性。Gary Pike等使用美国“全国大学生学习参与度调查”(NSSE)数据,并引入学生特征和院系特征,调查教育支出、学习参与度和学生自我报告学业成绩之间的联系。J.Fredericks Volkwein等通过40个机构的203个工程项目的数据,研究评价标准与学生经历和学业成绩的关系。赵艳等运用相关分析、多元回归分析方法得出了影响中小学教师远程培训效果的主要因素。赵慧琼等利用多元回归分析法分析学习者在线学习行为数据,判定影响学业成绩的预警因素。刘铭、马小强等采用质性研究方法,通过访谈、现场观察和实物收集等手段,从学习者的视角挖掘了学习者参与云教室学习并取得绩效的影响因素。傅钢善等以陕西师范大学“现代教育技术”网络课程为例,探讨学习者的行为特征与学业成绩的关系。吴青等选择远程教学平台的学习行为数据,采用关联规则算法挖掘学习风格、学习行为和学习成就之间的内在规律。
3.学业成绩预测和评价的数学建模
LC Duque等采用问卷收集数据,利用象限分析、ANOVA测试和结构方程模型组成的多重方法研究学业成绩和满意度的建模。Arsad等使用人工神经网络方法建模,预测马来西亚玛拉工业大学工程学专业学生的学业成绩。模型以学习者的基础课程的学分积点作为输入,以学分积点的平均值作为输出。陆柳生等提出基于离群点检测的学生学习状态分析方法,对学生考试成绩数据进行挖掘,判定学生学习状态是否异常。施俭等在分析教育数据挖掘技术及应用的基础上,建立以关联规则挖掘和聚类分析为核心的网络学习过程监管的数据挖掘模型,可以从学习数据中判定学生网络学习效果。舒忠梅等利用神经网络算法建立17个输入节点,7个隐藏节点,1个输出节点的三层神经网络模型对学生的学业成绩进行预测。
通过文献分析,发现国内外学术界在学业成绩预测和评价方面已经做了不少研究工作。但是现有研究,特别是国内研究,主要集中在:(1)从理论视角研究学业成绩预测和评估的框架模型,实证研究稍显不足,缺乏对理论框架的详细验证;(2)基于理论演绎推导和经验,建立某些因素与学业成绩之间存在相关性的假设,再采用问卷和访谈等方法收集数据,分析验证假设;这种方式只能证明选定因素与学业成绩之间存在相关性,但难以确定选定因素与学业成绩之间数量关系;(3)部分研究者采用决策树、神经网络等算法建立学业成绩预测模型,但是建立的模型往往是单一的分类器,由于算法本身特性的原因,单个分类器的性能容易受数据变化的影响。
本研究尝试使用数据驱动的建模方法,从数据中挖掘影响在线学习者学业成绩的因素,通过机器学习从数据中自动学习分类预测模型。针对单一分类预测模型容易受数据变化影响而表现出分类性能不稳定的问题,采用集成学习的方法构建集成式预测模型。在比较多种算法构建的单一分类器和集成分类器的分类性能的基础上,进一步提出采用嵌套集成学习的方法构建在线学习者学业成绩分类预测模型,并对模型的性能进行评估,以期为在线学习者的学业成绩预测建模提供借鉴。
三、数据来源及学业成绩影响因素的选择确定
(一)数据来源
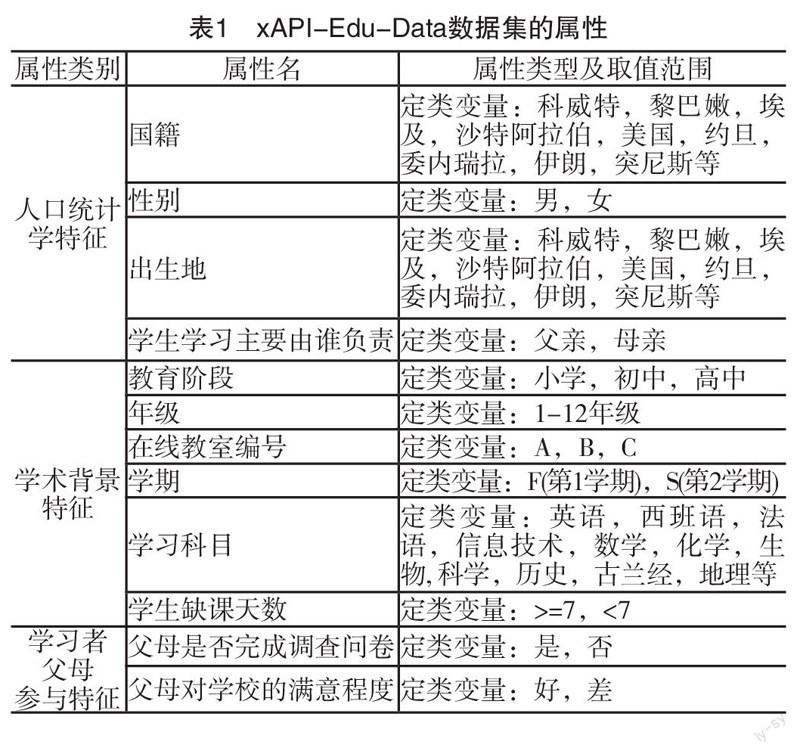
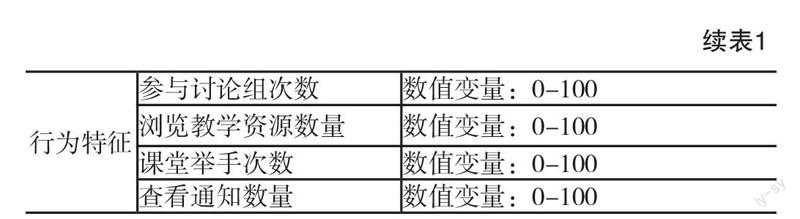
本研究使用约旦大学e-Learning学业成绩数据集(xAPI-Edu-Data)。数据来自Kalboard 360学习管理系统,并在学习管理系统内嵌入学习者活动跟踪工具ExperienceAPI(xAPI)采集学习者行为相关数据。采集到的原始数据共500条记录,其中20条记录中存在缺失值,剔除含缺失值的数据,最后保留480条有效记录。学习者中男生305名,女生175名,主要来自科威特、约旦等中东国家,也有少量来自突尼斯、美国、墨西哥、委内瑞拉等欧洲和美洲国家。每条数据记录包括16个属性(如表1所示),除了与学习者自身相关的人口统计学特征,学习背景特征和学习行为特征之外,数据集中还包括与学习者父母相关的数据,如学习者的学习主要由父亲还是母亲负责,学习者父母是否完成问卷调查以及学习者父母对教学的满意度。数据采集的时间跨度为两个学期,其中245名学习者的记录是第一个学期采集的,235名学者的数据是第二个学期采集的。依据学习者最终的成绩将学习者的学业成绩划分为三个层次,其中,70分以下为低水平(Low),70~89分为中等水平(Middle),90分以上为高水平(High)。
数据集中同时包含定类属性和数值属性,为避免數值属性取值范围的差异对分类预测的干扰,首先对数值属性进行归一化处理,使所有的数值属性的取值范围处于[0,1]区间内。
(二)学业成绩影响因素的选择确定
学业成绩影响因素的选择确定在数据挖掘中表现为数据属性子集的选择确定。原始数据集中通常包含一些不相关或冗余的属性,例如学生的学号与学生的学业成绩显然不存在相关性。去除冗余和不相关的特征可以提升分类的准确率,并且在属性子集上学习到的预测模型也更好理解。属性子集选择的目标是找出最小属性集,并使得数据子集的概率分布尽可能地接近原始数据的分布。属性子集选择的理想方法是:将所有可能的属性子集作为数据挖掘算法的输入,然后选取产生最好结果的子集。然而,由于涉及n个属性的子集多达2n个,这种方法一般行不通,需要其它策略。
本研究采用对原始数据中所有的单个属性进行评估并排序,然后依据排序结果来选择属性子集的方法。具体实现是借助Weka,采用两种方法对数据集的属性进行评估和排序。第一种方法是计算所有单个属性和学业成绩类别之间的皮尔森相关系数,并依据皮尔森系数的大小进行排序,系数值越大表示该属性与学业成绩类别之间的相关性越强。第二种方法是计算所有属性的信息增益率,并根据信息增益率的大小对属性进行排序,属性的信息增益率越大表示该属性对学业成绩进行分类的能力越强。两种属性评估方法的排序结果如下页表2所示。第1列是属性的相关系数或信息增益比率,第2列是属性的序号,第3列则是属性的名称。从下页表2可以发现,虽然两种属性评估方法的排序结果有差异,但两种方法的排序结果的前9项组成的属性子集具有一致性。从相关系数和信息增益率的数值大小可以判断这9项也是影响学业成绩的主要影响因素,因此将其作为预测建模的自变量。
四、预测算法与实验设计
(一)预测算法
分类和回归是两类主要的预测问题,分类是预测离散的值,回归是预测连续的值。本研究主要是预测在线学习者在学习结束时学业成绩的类别,类别∈{Low,Middle,High}。分类一般分为两个步骤,首先利用已知类别标签的数据集训练分类模型,并评估模型,该步聚也称作有监督的学习;然后利用模型将未知类别的数据对象映射到某个给定的类别。目前,常用的分类算法有贝叶斯网络(BN)、决策树(DT)、人工神经网络(ANN)和支持向量机(SVM)等。
传统分类建模方法是将原数据分为训练集、验证集和测试集,其中训练集用于学习模型,验证集用于模型调参,测试集来检验模型的性能。这样学习到的往往是一个单一分类器。基于“集体决策优于个体决策”的假设,本研究采用集成学习方法对原始数据进行二次抽样以得到多个训练集,使用特定算法在每个训练集建立一个分类器(基分类器),每个基分类器分别预测未知样本的类别,最后对基分类器的分类结果进行某种组合来决定最终的类别。集成学习的逻辑视图如图1所示。常见的集成学习方法有装袋(Bagging)和提升(Boosting),另外随机森林算法也是一种集成学习方法。
1.装袋(Bagging)
通过对原数据集进行有放回的抽样构建出大小和原数据集D一样大小的新数据集D1,D2,D3……,然后用这些新的数据集训练多个基分类器C1,C2,C3……。因为是有放回的抽样,所以在同一个训练集中同一个样本可能会出现多次,也可能有的样本不会出现。装袋算法对所有基分类器的预测值进行多数表决,将得票最高的类别指派给测试样本。
2.提升(Boosting)
提升为每一个训练样本赋一个权重,在每一轮提升过程结束时自动调整权重。开始时所有样本的权重都等于是1/N,抽到的概率都一样,抽样得到的训练集经过训练得到一个分类器。利用分类器对原始数据集中所有样本进行分类,然后增加错误分类样本的权重(对错分数据进行惩罚),减少正确分类样本的权重,使分类器在后续迭代中关注那些难以分类的样本。
3.随机森林(Random Forest)
随机森林是一种专门为决策树基分类器设计的集成学习方法。它集成多棵决策树的预测,其中每棵树都是基于随机向量的一个独立集合的值产生。随机森林得到基分类器Ci的算法主要分为两步:(1)对原始训练集采用有放回的自助抽样,得到和原始训练集大小一致的训练集,与装袋方法一致;(2)随机选取分裂属性集。在每个内部节点,从M个属性中随机选取F(F(二)实验设计
采用十折交叉验证方法将原始数据分为训练集和验证集,分别使用BN、DT、ANN和SVM四种算法在训练集上训练单一分类器,然后分别以四种算法训练基分类器,采用三种集成学习方法构建集成分类器。比对单一分类器和集成分类器的性能,检验集成分类器能否提升分类性能,是否对所有基分类器有效。在上一步实验的基础上,尝试采用嵌套集成学习方法构建学业成绩分类预测模型,优化模型参数,评估模型对学业成绩分类预测的效果。实验在安装Weka 3.8的PC(Intel(R)Core(TM)i5-6600cpu@3.30GHz,8G RAM)上完成。完整的实验流程如下頁图2所示,其中数据预处理和属性选择在“学业成绩影响因素的选择确定”阶段已经完成。
五、实验结果与分析
(一)单一分类器与集成分类器性能比较
实验采用BN、DT、ANN和SVM四种算法训练得到4个单一分类器;将4个单一分类器作为基分类器,分别采用装袋和提升方法训练得到8个集成分类器;以DT分类器为基分类器,采用随机森林算法训练得到1个集成分类器,共计13个分类器。各个分类器的性能指标如表3所示。表中所有指标是分类器对Low、Middle、High三个学业成绩类别进行预测的平均值。
结果显示,对于贝叶斯网络(BN)、决策树(DT)和人工神经网络(ANN)三种算法,通过构建集成分类器都能不同程度地提升分类性能,真正率、精度和召回率都有所提升,假正率都有所降低。以ANN算法为例,单一分类器的精度是0.722,而装袋方法训练得到的集成分类器的精度是0.769,提升方法训练得到的集成分类器的精度是0.767。虽然精度提升幅度不明显,但是如果测试样本数量较大,能够正确分类的实例数还是会有较大差异。相比而言,在几种不同类型的基分类器中,集成学习对于ANN类型的基分类器性能提升最为显著f提升6.5%),通过随机森林方法得到的DT类型的集成分类器性能最好。实验结果同时显示,对于SVM算法,构建集成分类器并不能提高分类性能,反而相对于单一分类器,性能有轻微的降低。
(二)学业成绩分类预测模型构建与分析
依据前面实验结果,选择分类性能最好的随机森林集成分类器作为基分类器,采用装袋方法训练集成分类器,即进行集成学习的嵌套,并对训练过程中的参数进行调整,构建学业成绩分类预测模型。
学业成绩分类预测模型(嵌套集成分类器)的性能摘要如表4所示。
分类器能对480个实例中的380个实例进行正确分类,分类的准确率为79.1667%,分类的准确性有了进一步提高。kappa系数为0.6785,一般认为kappa系数处于[0.6,0.8]就可以判定为分类性能较好。分类器的真正率(TP Rate)、召回率(Recall)、精度(Precision)、受试者操作特征曲线面积(ROC Area)等各项指标如表5所示。各项指标显示分类器对学业成绩类别集合{Low,Middle,High}中的Low预测更为准确,其精度为0.857,表示分类器预测为学业成绩差的学习者中有85.7%学习者在学习结束时的学业成绩是较差的。ROC Area=0.968(如下页图3所示),随机分类时ROC Area=0.5,ROC Area值介于0.5和1之间,ROC Area越接近1越好。ROC Area=0.968表示分类器性能很好。总体来说,分类器对Class=Low的分类性能最好,对Class=High的分类性能次之,对Class=Middle的分类性能最差。
分类预测模型对学业成绩类别Class=Low的分类预测更为准确也符合实际应用,因为分类预测的主要目的之一就是为了及早发现学业成绩可能较差的学习者,及时进行干预。如下页表6所示的分类器混淆矩阵的行代表真实的类别,列代表分类器的预测结果。混淆矩阵显示,127个真实类别为Low的实例中,108个预测正确,19个错误预测为Middle,没有实例错误预测为High;211个真实类别为Middle的实例中163个预测正确,18个实例错误预测为Low,30个实例错误预测为High;142个真实类别为High的实例中,109个预测正确,33个错误预测为Middle,没有实例错误预测为Low。
六、结论与讨论
学习者学业成绩的预测和评价是全世界教育研究者共同关注的话题,而在线教育的快速发展又赋予它新的使命,即如何对在线学习者的学业成绩进行预测,以便及时提供预警和其它干预措施。在大数据时代,学习者在线学习过程中会积累海量结构性和非结构性的数据,可以通过数据挖掘技术探寻在线学习者学业成绩的影响因素,也可以通过机器学习的方法从数据中自动学习到学业成绩预测模型。
针对本研究所使用的数据集,在学业成绩影响因素的挖掘过程中发现学习者行为对学业成绩影响最大,父母的参与度与态度对学业成绩的影响次之,学习者人口统计学方面的特征对学业成绩的影响最小。该发现对在线教育平台的设计和在线教育的数据采集具有借鉴意义。要实现真正个性化在线教育,实现对学业成绩的精准预测和提供及时干预,首先需要通过在线教育平台的功能设计实现对学习者相关数据的自动采集;其次,数据的采集类别除了现在普遍关注的人口统计学方面的特征数据,还需特别注重对学习者行为特征数据的采集。随着情感计算技术在教育中的应用,学习者情感特征数据也需要进行采集;另外,对于不同类型的在线学习者,影响其学业成绩的因素不同,需要采集的数据类别也存差异;例如,本研究中的K12阶段的中小学生不同于大学生等成人学习者,中小学生父母的行为和态度也是预测学习者学业成绩时需要考虑的一个重要方面。
对于通过机器学习从数据中自动学习分类预测模型的问题,本研究假设相比于单一分类模型,学习多个基分类器,然后对基分类器的结果进行组合的集成学习方法可以提升预测模型的性能。研究发现,对于贝叶斯网络(BN)、决策树(DT)、人工神经网络(ANN)三种算法,通过集成学习构建集成分类模型确实都能不同程度地提升分类预测的性能;但是对于支持向量机(SVM)算法,学习到的集成分类模型并没有提升分类预测的性能,反而相比于单一分类模型,分类性能有所降低。理论上讲,集成学习可以或多或少地提升分类性能,但提升的幅度与基分类器的稳定性有关,对于不稳定的基分类的性能提升更加明显。对于SVM算法,集成学习降低模型的分类性能的原因在于:SVM算法得到基分类器本身比較稳定,集成学习算法对分类性能的提升并不明显;同时,由于集成学习算法在训练基分类器时,因为算法本身的特性会使得训练子集可能存在重复样本,导致基分类器性能降低,从而使得整个模型的分类性能轻微下降。
在确认集成学习方法可以提升学业成绩分类预测模型性能的前提下,本研究进一步采用嵌套集成学习的方法从数据中自动学习分类预测模型。用随机森林算法训练基分类器,采用装袋算法对基分器的预测值进行多数表决,并对模型的性能进行分析。研究发现:通过嵌套集成方法学习到的模型的分类精度得到了进一步提高。需要说明的是模型分类精度的高低除了受算法本身优劣性的影响之外,还受分类的类别数量的影响。分类的类别越多,准确分类的难度越大,例如本研究中将学业成绩的预测结果划分为三个类别,平均精度是79.2%;但如果只将预测结果划分二个类别,分类的精度将得到较大幅度的提升。假设是对学业成绩预测结果为“差”的学习者进行预警,则只需将预测结果划分为“差”和“不差”两个类别,分类的准确度得到大幅提升,如下页图4所示。在下页图4的混淆矩阵中,列代表预测类别,行代表真实类别,预测类别和真实类别一致代表预测正确。a代表学业成绩预测结果为差(class=Low),b代表预测结果不为差(Class≠Low,即Class=High'Class=Middle)。预测结果为差的样本中,109个样本预测正确,18个预测错误;预测结果不为差的样本中,335个样本预测正确,18个样本预测错误;预测准确度为92.5%((109+335)/(109+18+335+18)=0.925)。
最后,对于数据驱动的在线学习者学业成绩预测建模问题,模型分类预测的准确性除了受到上面分析中提到的算法优劣性、分类类别数量的影响之外,还和原始数据集有较大关系。因为数据驱动的预测建模首先需要在原始数据的属性集中筛选出影响学业成绩的主要属性,然后再以选定的属性作为自变量,以学业成绩为因变量建立数学模型。那么原始数据的属性集能否涵盖影响学业成绩的全部主要因素,对构建的预测模型的精确性有影响。数据集中的噪声也会影响模型分类准确度的提升。
猜你喜欢
无线互联科技(2022年8期)2022-06-23
新教育时代·教师版(2016年31期)2016-12-07
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
价值工程(2016年29期)2016-11-14
电脑知识与技术(2016年24期)2016-11-14
科学与财富(2016年28期)2016-10-14
当代教育理论与实践(2015年9期)2015-12-16
中国教育信息化(2015年10期)2015-08-23
卫生职业教育(2014年24期)2014-05-20
