
基于大数据的微视频推荐算法研究
2017-05-15 03:49:05尚松涛石民勇尚文倩洪志国
中国传媒大学学报(自然科学版) 2017年2期
尚松涛,石民勇,尚文倩,洪志国
(中国传媒大学 计算机学院,北京100024)
基于大数据的微视频推荐算法研究
尚松涛,石民勇,尚文倩,洪志国
(中国传媒大学 计算机学院,北京100024)
随着网络的迅速发展,以及移动网络资费的逐渐下调、移动流量日益充足,微视频在网络上传播的速度日益加快。越来越多的人,尤其是年轻人,更偏向于使用移动设备观看视频和分享视频。在大数据的环境下,给微视频的推荐算法提出了更多的挑战。传统的推荐算法,如基于内容的推荐算法、基于协同过滤的推荐算法、基于图的推荐算法等,在用于微视频推荐时,时间效率不高,推荐的准确率也不高。因此,本文提出了基于超链-图模式的个性化推荐算法,不仅能够提高推荐的命中率,而且能够适应大数据集上的视频推荐应用。此外,本文分析了传统大数据的Slopeone算法,并对其进行改进,使之能够适应海量数据的微视频推荐。
大数据;微视频推荐算法;超链-图算法;Slopeone
1 引言
近年来随着互联网的飞速发展,尤其是电子商务的异军突起,个性化推荐已经成为各大主流网站的一项必不可少的服务。但是,与当今蓬勃发展的电子商务网站相比,微视频的个性化推荐服务水平仍存在较大差距。微视频[1-2]是当前媒体发展中的一种新的媒体形式,它是指短则30秒,长则20分钟的视频短片。微视频的内容涉及面广泛,视频形态多样,通常涵盖微电影、纪录短片、DV短片、视频剪辑短片、广告片段等。微视频可通过PC、手机、DV、DC、MP4等多种视频终端摄录或播放。大部分的互联网用户都会在线观看一个视频短片(微视频),如果能够更好地挖掘用户的潜在兴趣并进行相应的视频推荐,就能够产生更大的社会和经济价值。
目前的推荐算法[3]大致可以分为以下几种:基于文本的推荐算法[4],基于图的推荐算法[5],基于协同过滤的推荐算法[6-7],以及混合推荐算法[8]等。基于文本的推荐算法是根据用户浏览行为记录,构造用户偏好模型,计算推荐项目与用户偏好文档的相似度,将最相似的项目推荐给用户。基于协同过滤的推荐算法[9]的基本假设是:找到与该用户偏好相似的其他用户,将他们共同感兴趣的内容推荐给用户。文献[10]中将协同过滤算法分为基于记忆模型的方法(memory-based)和基于模型的方法(model-based)。基于图的推荐算法主要是基于用户和内容构建的二部图[11-13],文献[14-15]中通过构建资源分配矩阵的二部图算法,以及随机游走[16-17]的二部图推荐算法,实现了个性化推荐,但其计算和存储的开销都很大。文献[18]中基于小世界网络和贝叶斯网络提出了两层混合图模型,达到了较好的推荐效果,但是该模型在处理微视频个性化推荐中很容易变成NP问题。在本文中,提出基于超链接-图的模式的个性化微视频推荐算法,很好地对用户进行个性化推荐。混合推荐算法(hybird-based)是为解决协同过滤算法、基于内容的推荐算法和基于图结构的推荐算法各自问题提出的,以达到最好的推荐效果。
大数据技术[19]是近年来发展起来的一个比较流行的概念。其含义是数据的大小已经超越了当前机器的数据处理能力,即以当前计算机的处理能力和算法不可能在一个可以接受的时间内获取、处理该数据[20]。随着微视频的蓬勃发展,围绕微视频的数据量也将在短时间内快速膨胀,如微视频本身的信息、视频简介、视频评论、分享等相关的信息将会越来越多,信息之间的关系也将变得越来越复杂。因此,传统的数据处理方法将无法处理如此大规模的信息和数据,利用大数据的相关技术来处理微视频及其相关的数据将是研究者所面临的问题。针对数据量巨大的问题,开源的大数据处理平台Hadoop[21]和开源的大数据处理算法库Mahout[22]。Mahout是一个可扩展的机器学习算法库,包括各种聚类、分类、推荐等各种算法,Mahout算法库是经过检验的一种廉价解决方案能够解决机器学习中的问题。因此,在本文中使用Hadoop大数据技术平台和Mahout算法库来实现微视频的统计和个性化推荐。
2 传统推荐算法
推荐问题可以概括为:假设C是用户集合,S是所有可能推荐的物品。同时假设u是一个可以测量物品c对用户s可用程度的工具,即:u:C×S→R,其中R表示用户订购的产品集合。那么,对于每个用户c∈C,选择使得u取得最大值的物品s∈S进行推荐:

(1)
其中,u(c,s)表示某个用户s喜欢某件物品c的喜爱程度,在推荐系统中称之为推荐率。
2.1 基于内容的推荐算法
基于内容的推荐大多应用与文本信息推荐领域,其基本问题包括用户兴趣的建模与更新以及相似性计算方法。首先建立用户兴趣特征的描述模型,然后使用向量空间模型(Vector Space Model,VSM)[23]来表示用户兴趣模型,最后进行相似度的计算。“特征词”是文本处理中常用的用来表示一篇文本,“特征权重”用来衡量文本中一个特征词的重要程度,TF-IDF(Term Frequency/Inverse Document Frequency)算法是一个比较著名的计算特征权重的算法[13],算法描述如下:
假设N表示可推荐给用的所有文本的总数,ni表示特征词wi在所有文本中出现的频次,fi,j表示特征词wi在文本dj中的频次。那么,TFi,j可定义为:

(2)
其中,maxzfz,j表示文本dj中特征词出现的最大值。
从公式(2)中可以看出,TF反映了在一个文本中,一个特征词出现的频率越高,那么该特征词就越重要。然而,如果一个特征词反复出现在不同的文本中,则说明该特征词不具备较强的区分性,也就越不重要。IDF正是反映了这种情况,IDF的定义如下:
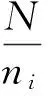
(3)
综合公式(2)和公式(3),特征词wi在文档dj中的TF-IDF定义为:
TF-IDFi,j=TFi,j×IDFi
(4)
确定特征词wi的TF-IDF值(也成为“权重”)之后,文本dj可以表示为向量形式,即:dj={
在推荐系统中,待推荐的文本与输入文本进行比较,将最佳匹配结果推荐给用户,即在公式(1)中,函数u(c,s)表示为待推荐的文本与输入文本之间的相似度。在众多的计算相似度的算法中,常用的是Cosine算法,那么u(c,s)函数可表示为:
u(c,s)=cos(TF-IDFc,TF-IDFs)

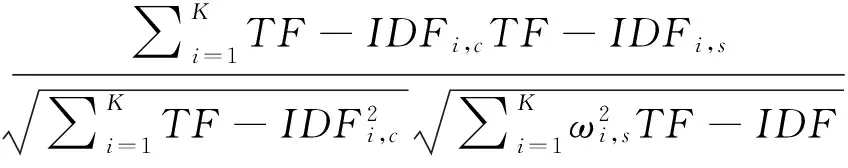
(5)
其中,K是特征词的总数。
2.2 基于协同过滤的推荐算法
协同过滤算法分析用户的兴趣,在用户群中找到指定用户的相似兴趣用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。协同过滤算法包括基于内容的协同过滤和基于项目的协同过滤。
基于内容的协同过滤算法根据用户过去喜欢的商品(item),为用户提供他过去喜欢的产品相似的产品。基于内容的协同过滤推荐一般分为以下三步:
1)特征抽取:为每个商品抽取一些特征,用这些特征来表示该商品。
2)特征学习:利用一个用户过去喜欢/不喜欢的商品特征,以此计算出此用户的喜好特征。
3)推荐:通过上一步得到的用户特征与商品特征,为此推荐一组相关性最大的商品。
通过以上分析,基于内容的协同过滤算法的重点在于相似度的计算,一种改进的Cosine算法被广泛的应用在基于内容的协同过滤算法中,其公式如下:
sim(i,j)=
(6)
其中,Ris是用户i选择商品s的比例,As是用户i选择所有相关商品的平均比例,Iij是用户i与用户j同时选择商品的总和。
2.3 基于图的推荐算法
传统的基于图的推荐算法主要基于资源分配矩阵的二部图算法、随机游走的二部图算法等,基于资源分配矩阵得到的推荐列表的算法原理如下:
Step1:假设现有U个用户和N个视频构成的推荐系统,该系统可以用一个包含U+N个节点的二部图表示(图1):

图1 基于用户-内容的二部图
Step2:建立矩阵,用户的相似度可以通过两次资源分配得出,即视频到视频的一次资源分配、用户到视频的一次资源分配。视频j到视频i的资源分配权重ωij计算公式如下:
(7)
其中,Dj表示视频j被多少用户看过,Dk表示第k个用户看过的视频的总数。由此,可得到矩阵W=(ωij)N×N.

(8)
该算法在给目标用户进行推荐,都需要对整个二部图进行迭代,这一过程时间复杂度高,生成推荐结果耗时长。
3 改进的推荐算法
3.1 改进的基于链接-图推荐算法
用户在互联网上浏览视频时,大都会从一个基础页面开始,然后层层深入到网页内的其它视频。这种浏览行为模式是由网页的链接结构所决定的,如表1所示。

表1 网页的链接结构
通过分析用户浏览链接行为,构建Web图并建立邻接矩阵。每个视频构成图的一个节点,图的边为视频之间的连接,这样可以建立一个基于视频的二部图。传统的基于图的推荐算法构造了一个资源分配权重矩阵,最终实现了个性化推荐。然而这个矩阵的建立,到生成推荐列表耗费的时间比较长,且需要较大的存储空间。基于链接-图模式生成视频推荐列表的流程如图2所示。
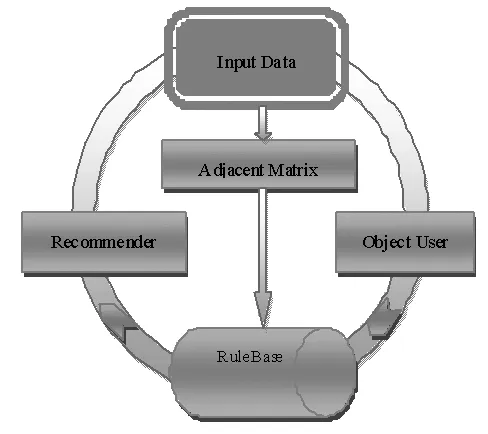
图2 推荐流程
Step1:构建二部图的邻接矩阵,矩阵元素的计算方法由公式(9)确定。
rij=count(i∩j)
(9)
其中,count(i∩j)表示有序对(i,j)出现的次数。为避免有序对的数量长度对结果造成影响,使用归一化因子对公式(9)进行归一化,从而得到公式(10)。
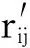
(10)
Step2:生成规则库,根据建立的邻接矩阵,按行读取top-N相应的元素,其所对应的有序对(i,j)作为规则。
Step3:读取目标用户最近浏览的视频链接。
Step4:生成推荐列表。
例如:设U={user1,user2,user3,…,user6}和N={hy1,hy2,hy3,hy4}分别作为用户列表和视频链接列表。用户的详细浏览记录如下:
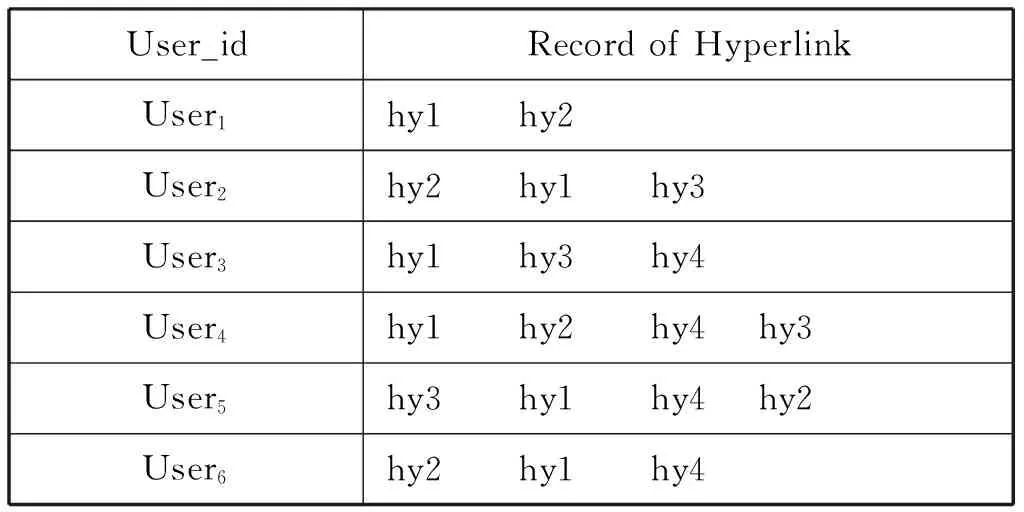
表2 用户浏览记录
因此,可以计算出邻接矩阵如下:
(11)
归一化之后的结果为:
(12)
生成推荐规则:按行选取top-N作为推荐规则,如果N=1时,则需按行选择最大的rij作为推荐规则。在本例中,由矩阵第二行可知:
(hy2,hy1)=2,(hy2,hy2)=(hy2,hy3)=(hy2,hy4)=0,因此r21最大,那么生成规则为(hy2,hy1)。
决策规则:若生成规则为(hyi,hyj),那么读取每个用户最近浏览视频行为中的N个(latestN)。如果N=1,则根据最后一次浏览记录进行推荐,如用户ui的最后浏览记录为hyi,则向该用户推荐视频hyj。在本例中,根据规则(hy2,hy1),将给用户user1和user5推荐视频hy1。
3.2 基于MapReduce的Slope one推荐算法

在典型的推荐算法中,用户ui对项目itemj的评分用rij表示,其值的大小表示用户ui对项目itemj的喜好程度。在Slope one算法中,同样需要估算rij的值,首先使用公式(13)计算itemi与itemj之间的差异性:
(13)
其中,Dij是itemi与itemj之间的差异的平均值,Rci表示用户c对itemi的喜好程度,Rcj表示用户c对itemj的喜好程度,Ii和Ij是第i个与第j个item,n和m表示itemi和itemj的项目总数。
计算完项目之间的差异之后,可以利用(14)式来计算用户ui对项目itemj的评分rij,即ui对项目itemj的喜好程度:

(14)
其中,Si表示用户ui评过分的项目集合,||Si||表示Si中所包含的元素个数。
MapReduce 是基于Hadoop框架的并行计算模型,它包括两个阶段:Mapper阶段和Reducer阶段。MapReduce的基本思想是将输入数据分成n部分,每个部分由一个Mapper来处理,每个Mapper的输出为一个键/值对(Key/Value pairs)。如果Mapper阶段输出m个类型键/值对,那么将有m个Reducer来接收这m个类型键/值对并进行处理,Reducer阶段输出最终的结果。
在基于MapReduce的Slope one算法中,使用两个MapReduce和一个Mapper来对传统的Slope one算法进行并行化处理。第一个MapReduce用来完成计算每一个用户的Dij,其核心算法如下:
Mapper阶段:
Mapper输入:
Mapper输出:
Reduce阶段:
Reducer输入:
Reducer输出:
从以上可以看出:在Mapper阶段并没有进行任何的处理或计算,而在Reducer阶段计算用户的Dij。第二个MapReduce用于计算Dij的平均差异性,其核心算法如下:
Mapper阶段:
Mapper输入:
Mapper输出:
Reducer阶段:
Reducer输入:
Reducer输出:
同样的,在Mapper阶段并未进行任何计算,但在Reducer阶段计算出了所需的结果。根据这个结果,在最后一个Mapper阶段即可完成用户推荐项目的喜好程度rij,核心算法如下:
Mapper输入:
Mapper输出:
其中,Mapper的输出表示对每个用户(UserID),其感兴趣的项目(itemID)的喜好程度(Rating)的度量,根据这些数据可以推荐给用户最感兴趣的项目。
4 实验及结果分析
4.1 实验数据和评价标准
为了验证本文的算法设计,选取的第三方的视频网站(Youtube的视频点击数据集)的用户浏览数据,其中一个数据集包括大约10,000个用户,另一个数据集包括大约20,000个用户。在实验中,将数据的90%作为训练集,剩下的10%作为测试集。
为了评估算法的性能,采用F1 measure[26],包括准确率(Precision)和召回率(Recall)两部分,其计算方法如下:
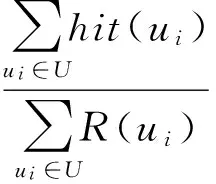
(15)
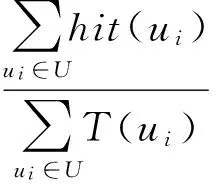
(16)

(17)

4.2 实验结果及分析
从表3和图3、图4中可以看出,改进后的算法要比传统的推荐算法性能要高,准确率的性能从1.6%提高到了14%,召回率从4%提高到11%。F1的性能在数据集1中提升到29.5%,在数据集2中提升到了24%。
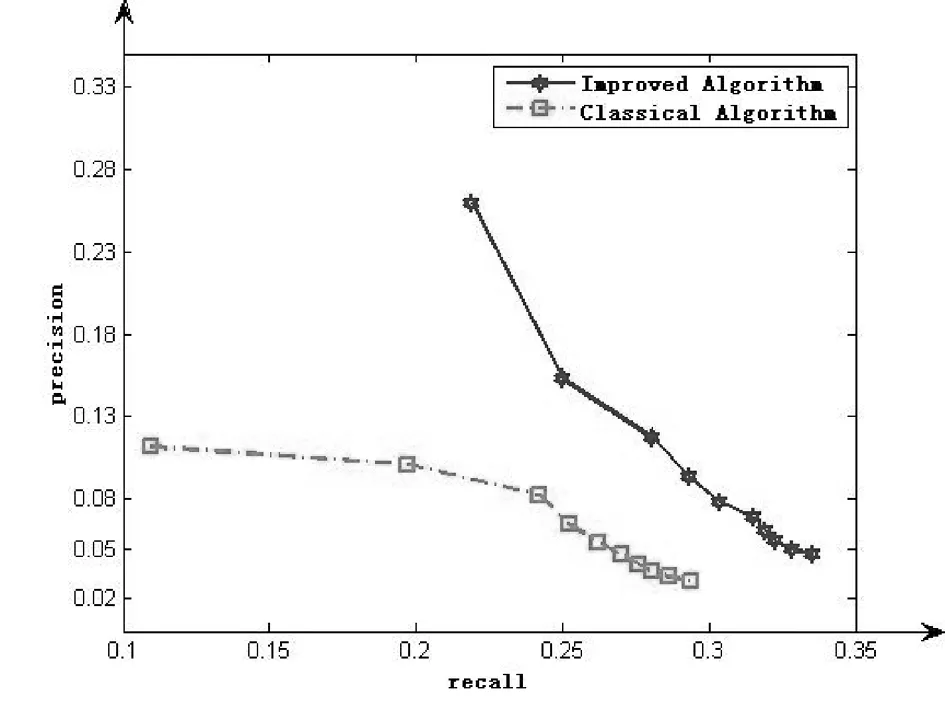
图3 数据集1上的实验结果
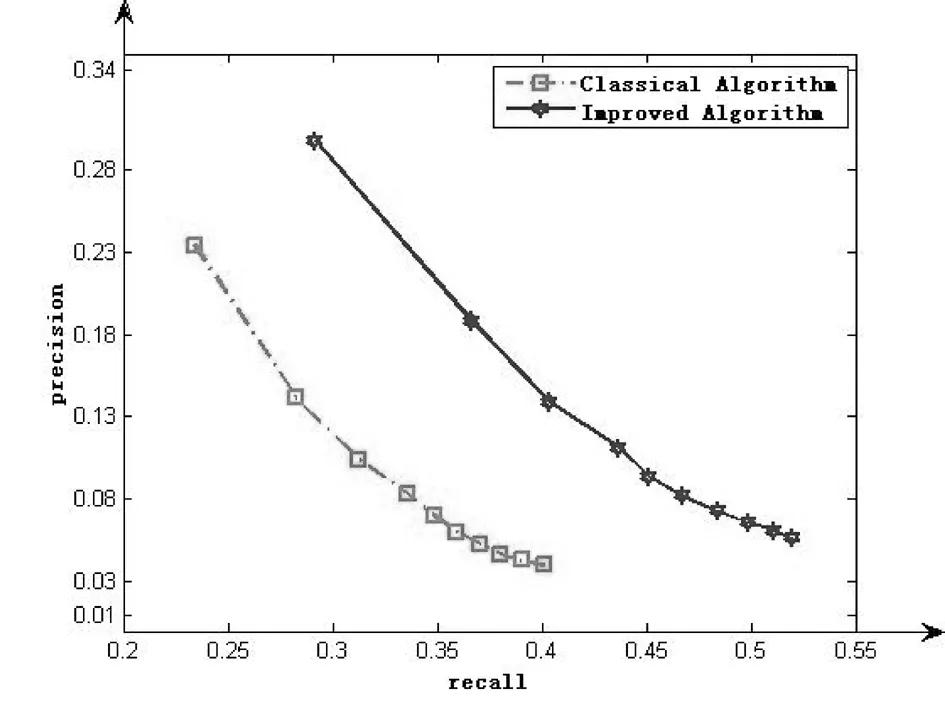
图4 数据集2上的实验结果
表3 在两个数据集上的实验结果

DatasetDataset1Dataset2AlgorithmClassicalalgorithmImprovedalgorithmClassicalalgorithmImprovedalgorithmF1measureTop10.234090.294680.1107620.237562Top20.188390.248660.1336530.18979Top30.156450.207280.1234760.16511Top40.134240.177060.1030890.141617Top50.116360.156730.0895880.124863Top60.102680.140050.0791990.113263

续表
5 结论
随着网络的发展和移动手持设备的普及,微视频的发展日益迅速,尤其年轻人更喜欢在移动设备上观看各类视频。由此可知,视频的推荐算法日益的受到研究者的关注。本文在传统的推荐算法的基础上改进了传统的推荐算法,通过实验验证了改进后的算法具有更好的性能。基于MapReduce的大数据的计算平台也日益的受到关注,本文也通过改进传统的Slope one算法,使算法能够在大数据集上提高性能。
[1] 李英壮,高拓,李先毅. 基于云计算的视频推荐系统的设计[J].通信学报. 2013,34(2):138-140.
[2] 李玥.微视频传播的发展模式探析[J].学术交流,248(11):177-181,2014.
[3]B Yang,P F Zhao. Recommendation algorithm overview[J].Journal of Shanxi University(Nat Sci Ed),34(3):337-350,2011.
[4]Lops P,de Gemmis M,Semeraro G. Content-based recommender system. State of the art and trends[M].Recommender System Handbook,Spring US,2011:73-105.
[5]S Z Zhang,D R Chen. Hybrid graph Model with two layers for personalized recommendation[J]. Journal of Software,2009,(12):123-130.
[6]X Y Su,T M Khoshoftaar. A survey of collaborative filtering techniques[J]. Advanced in Artificial Intelligence,2009,(12).
[7]J Zhang,Z Lin,B Xiao,C Zhang. An optimized item-based collaborative filtering recommendation algorithm[J].IEEE International Conference on Network Infrastructure and Digital Content,2009:414-418.
[8]Lucas J P,Luz N,Moreno M N. A hybrid recommendation approach for a tourism system[J]. Expert System with Application,2013,40(9):3532-3550.
[9]L Dong,Y Nie,C X Xing,K H Wang. Research and Implementation of a Personalized Recommendation System[J].Lecture Notes in Computer Science,2006,(4312):183-191.
[10]J S Breese,Heckerman D,Kadie C. Empirical Analysis of Predictive Algorithm for Collaborative Filtering[J]. Process of the 14th Conference on Uncertainty in Artificial Intelligence,1998:43-52.
[11]C C Aggarwal,J L Wolf,K L Wu,P S Yu. Horting hatches an egg:A new graph-theoretic approach to collaborative filtering[J]. Proceeding of the KDD,1999:201-212.
[12]R Feldman,J Sanger.The Text Mining Handbook:Advanced Approaches in Analyzing Unstructured Data[M]. Cambridge University Press,2007:242-272.
[13]F Abel,N Henze,D Krause.Exploiting additional Context for Graph-based Tag Recommendations in Folksonomy System[J].2008 IEEE/WIC/ACM International Conference on Web Intelligence an Intelligent Agent Technology,(1):148-154,2008.
[14]T Zhou,J Ren,M D M. Bipartite network project and personal recommendation[J]. Phys Rev E,2007,(76):046-115.
[15]T Zhou,L L Jiang,R Q Su. Effect of initial configuration on network-based recommendation[J]. Europhys Lett,2008,(81):58004.
[16]F Fancois P Alain,S Marco. Random-walk computation of similarities between nodes of a graph with application to collaboration recommendation[J]. Knowledge and Data Engineering,IEEE Trans,2007,19(3):355-369.
[17]S Shang,S R Kulkami. Random walk based model incorporating social information for recommendation[J]. IEEE International Workshop on Machine Learning for Signal Processing,2012:23-26.
[18]D J Watts,S H Strogatz. Collective dynamics of small-world networks[J]. Nature,1998,(393):440-442.
[19]程学旗,靳小龙,王元卓.大数据系统和分析技术综述[J].软件学报,2014,25(9):1889-1908.
[20]S M Meng,W C Dou.X Y Zhang.KASR:a keyword-aware sevice recommendation method on MapReduce for Big Data application[C]. IEEE Transactions on parallel and distibuted system,25(12):3221-3231.
[21]刘文峰,顾君忠,林欣.基于Hadoop和Mahout的大数据管理分析系统[J].计算机应用与软件,2015,32(1):47-50.
[22]E Jain,S K Jain.Categoring Twitter users on the basis of their interests using Hadoop/Mahout platform[J].Industrial and Information Systems(ICIIS),9th International Conference,2014:15-17.
[23]鲁松,白硕,黄雄.基于向量空间模型的有导词义消歧[J].计算机研究与发展,2001,38(6):662-667.
[24]S Song,K J Wu.A creative personalized recommendation algorithm—User-based Slope One algorithm[J]. 2012 International Conference on Systems and Informatics,2012:2023-2027.
[25]L N Li,H Chen,X Y Du.MapReduce-Based SimRank Computation and Its Application in Social Recommender System[J]. 2013 IEEE International Congress on Big Data,2013:133-140.
[26]C J Van Rijsbergen.Information Retrieval[M].London:Butterworths,1979.
(责任编辑:宋金宝)
Research on Micro-video Recommendation Algorithms Based on Big Data
SHANG Song-tao,SHI Min-yong,SHANG Wen-qian,HONG Zhi-guo
(Computer Science School,Communication University of China,Beijing 100024,China)
With the development of the Internet,the micro-video is becoming more popular. Nowadays,the mobile tariff is gradually down,and the mobile data traffic is becoming sufficient. More and more people,especially young teenagers,are eager to watching and sharing micro-video on mobile devices. Under the conditions of big data,there are more challenges to micro-video recommendation algorithms. The traditional recommendation algorithms,such as content-based recommendation algorithm,collaborative filtering recommendation algorithm,and graph-based,are low efficiency. Thus,this paper improves the traditional recommendation algorithms and proposes an improved recommendation based on hyperlink-graph model. Not only it can reduce the cost of the machine running time,but also it can be used for massive data. In addition,this paper also improves the traditional Slope one algorithm. The improved Slope one algorithm is based on MapReduce framework and has higher precision and recall. The algorithm also can be used to massive micro-video recommendation.
big data;micro-video recommendation;bipartite graph;Slope one
2016-11-10
尚松涛(1978-),男(汉族),北京人,中国传媒大学博士研究生.
TP
A
1673-4793(2017)02-0038-08
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
制造技术与机床(2019年10期)2019-10-26 02:48:08
汽车观察(2019年2期)2019-03-15 06:00:50
电子制作(2018年18期)2018-11-14 01:48:06
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
中国卫生(2016年5期)2016-11-12 13:25:26
小学教学参考(2015年20期)2016-01-15 08:44:38
中文信息学报(2015年4期)2015-04-21 08:29:12
生物进化(2014年2期)2014-04-16 04:36:26
