
交互点值图上的可视化抽象和探索
2017-05-15 03:49:19肖子达朱立谷
中国传媒大学学报(自然科学版) 2017年2期
肖子达,朱立谷
(中国传媒大学 计算机学院,北京 100024)
交互点值图上的可视化抽象和探索
肖子达,朱立谷
(中国传媒大学 计算机学院,北京 100024)
多类离散数据在地理空间的分布,是地理相关可视化领域研究的热点。作为此类数据基本可视化呈现方式,点值图具有直观、细节丰富的优点,但是亦存在点重叠导致的可读性差的问题。本文提出了一种按分辨率进行密度估计方法对点值图进行优化,灵活地调节当前分辨率下取样参数,以期尽最大可能显示细节,同时保持各类属性的相对密度特征;为了弥补取样导致的离散特征的丢失,我们使用了一系列交互手段,能有效地提高可视分析的准确性并辅助整体的可视表达。本文最后通过实例分析和用户研究证明了本方法的有效性。
点值图;密度估计;地图信息;交互式数据分析
1 引言
多类离散数据在地理空间的分布,是从制图学、地理信息系统到数据可视化、人机交互领域的学科交叉研究热点。作为一种最基本的可视化呈现方式,点值图(dot maps)按照离散数据的地理坐标值直接在地图上绘制点,具有显示方式直观、细节丢失少的优点。但在点数量极多或分布严重不均的情况下,该方法亦存在点重叠导致的可读性差的问题。故而以点值图为基础存在多种变形呈现方式。如将离散点转换成连续形式表现的等值线图、热力图[1];
描述区域内统计值的等值区域图、统计地图[2];以及把统计图与地图结合起来的图表地图[3]等。虽然这些方法提高了可读性,但却普遍存在丢失细节、忽视离群值的问题。因此在地理相关数据的可视分析领域,解决可读性与细节呈现之间的矛盾依然是一大挑战。
为了应对这一挑战,需要强化视觉效果方法,目前主要有两个研究方向[4]:其一是通过采样和密度映射,重新定位(或移位)数据点,以解决地理空间中的图元重叠等显示问题。其二是通过建立数据抽象对象(例如,聚类或分类)以降低数据大小。再通过支持向下钻取的交互操作以查看细节。
受此启发,本文提出了一种按分辨率进行密度估计方法用以优化点值图。基于地理数据的特点,使用核密度估计算法获取离散数据的地理分布,通过蓝噪声取样提升地图密集区域的呈现水平;根据显示分辨率的不同,灵活地调节当前分辨率下取样参数,以期尽最大可能显示细节;在探索环节中优化人机交互过程,使用缩放、选择、焦点+上下文、更改视觉变量等交互方式辅助分析。本文主要贡献如下:
•在地理空间上提出了一种按地图分辨率进行密度估计的点值图优化方案
•在该方案的基础上,设计了一个交互式可视化系统,用以检查和分析地理相关的离散数据
•通过实际案例说明该方法有效性
2 相关工作
地图是生动描绘地理变化数据的主要方法,在过去30年中发展起来的地理信息科学将地图理解为包含点、线和面积的空间模型[5]。对于离散的、地理空间上分布不均的数据,点值图是一种基础的、直观的、细节丰富的可视化呈现方案。虽然可以将其理解为是2D散点图在地理空间坐标系下的扩展,但由于地理空间的特殊性,点值图的点绘制面临着如下几个问题:1)如何区别具有不同属性值的点;2)如何避免密集的点与地图背景之间的视觉混淆;3)如何确定点的密度权值,使密度小的地区能得到表示,而密度大的地区点子不产生连续、重叠现象。
这三个问题是互相关联的。因为地图已经使用了位置和大小相关的视觉变量,可用的描述其他属性的视觉变量就很有限了。首选方案是使用颜色分量,包括亮度、饱和度和色调,用以描述不同类别的数据[6]。次之是调节点的大小或形状[7]。同时,地图背景往往选用单色方案以避免视觉混淆。但是,以上方法并没能解决点重叠问题,反而因为多种视觉变量的引入使得不同类别的离散数据相互扰乱[8],造成更严重的可读性问题。
为了优化可读性,现有的解决方案主要分为三类。第一类是更改视觉变量,典型方法如轮廓线、混、颜色交织。但是以上三类方法不能很好地捕捉离群值,并且都存在陈述性误导[9],对于不同类别之间渲染的顺序会导致重叠区域的变化,不能进行完好的定量分析。对此,Martin等人提出了对齐交织技术[10],将重叠区域的不同类型点对齐后均匀着色,在高分辨率的情况下具有很好的辨识度,但在低分辨率依然需要改进。
第二类方案是使用空间变形方法。该方法将密集区域的点依某种算法移动到临近的稀疏区域,以使密度大区域不出现点重叠。此类方法有Daniel A. 等人提出的Gridfit算法[11],Keim等人提出的广义散点图方法[12]等。但这一大类方法直接改变了点的实际分布,虽然可以在一定程度上解决点重叠的问题,但是在需要定量分析的场景是不合适的。
第三类方案是采用密度估计方法。该方法通过计算地图上可显示的最大点数量与所有离散点数量之间的密度函数,以便将实际显示的点数量控制在合理的范围内。此类方法一定程度上损失了离群值,但有较好显示效果。传统制图学中很早就提出了使用诺谟图[13]进行密度估计。Bachthaler等人[14]提出了一个严谨、准确、通用的数学模型来创建连续散点图。更进一步地,Zinsmaier等人[15]提出采用核密度估计方法来解决点重叠问题。然而,以上方法无法保持多类数据之间的相对密度特征。陈海东等[16]提出的一种基于多类蓝噪声采样的密度估计方法,能够减少显示数据点的数目同时保持不同数据类之间的相对密度特征。
除了以上三类方案之外,交互技术对改进离散数据的可读性、增强用户理解也有着不可忽视的作用。Ellis等人使用取样镜头,一种焦点+上下文技术展示放大的局部取样数据[17]。Leland等人则主要通过栅格图特征排序的方式,探索散点图的分布特征[18]。袁晓如等人[19]提出了一种综合工具,通过选择、缩放、拖拽和链接,交互地探索散点图的局部特征。考虑到地图空间的特殊性,选择、缩放、概览+细节是其中关键的交互方法。
最后,一些混合方法也值得关注。Mayorga 和 Gleicher提出在使用密度估计方法的同时使用轮廓线或者颜色映射来标注离群值,同时用户可以交互地选择选举范围和呈现方式。虽然这种方法在可视化多类数据点时依然会遇到前文所述的陈述性误导问题,不能很好地显示各类属性的相对密度特征。但是此方案依然很有启发,即新的研究可以在多种解决方案的综合、密度估计算法的持续改进、交互方式的创新上做进一步探索。
3 点值地图的优化方法
为了解决点值图在呈现地理空间上的离散数据分布时的视觉效果问题,我们提出了一种分辨率自适应取样方法,根据地图空间分辨率的不同,灵活地调节当前分辨率下取样参数,以期尽最大可能显示细节。
此方法与缩放这一交互操作相绑定。缩放会将整个视图按空间分辨率纵向分割[20]。我们使用地图不同的分辨率θ来限制密度估计的级别。当视图区域放大时,更多的点被显示出来;而当视图区域缩小时,一些点就应该由于取样原则不显示在这个层级上。
如前文相关工作一节所述,密度估计方法会在一定程度上忽略离群值。在本方法的默认情况下,只显示在当前分辨率下有代表性的离群值。除此以外,还辅助以多种交互方式来辅助用户探索细节。下文将从密度估计算法、取样方法、交互方法三个方面,具体描述该方法。
3.1 密度估计算法
分辨率自适应取样方法的首先要考虑的问题是,以什么样的密度估计函数将实际显示的点数量控制在合理的范围内。核密度估计是依据当前样本来估计其概率密度函数的经典方法。

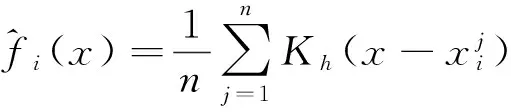
(1)
其中(x-xi)表示估计点x到样本点的距离,Kh称为在带宽h条件下的核函数,其公式为:

(2)
在密度估计中,带宽h的选择对于计算的结果影响很大,随着h的增加,空间上点密度的变化更为光滑,但会掩盖密度的结构。依据Jones分析几种生成带宽h的方法特性[21],我们采用Solve-the-EquationPlug-InApproach。这个方法的主要思想是通过减小渐近均方误差来获取最优的h值[22]。首先通过插件估算器计算出一个初始密度,再通过迭代算法来求解最优带宽h。
3.2 取样方法
通过对多元数据的密度估计计算,获得取样过程所需的区域估计密度后,就需要选择取样方法。
在过去的几年中,取样方法被广泛地应用在各种可视化技术中,尤其是对于产生拥有蓝噪声特性的取样方法。蓝噪声的频谱只拥有最小限量的低频成分,也没有能量峰值。蓝噪声的这种特性使得在取样时没有低频导致的混淆现象和杂波导致的间隙,再加上支持重要度取样、高效的计算特性使得蓝噪声取样被广泛研究和应用。Li-YiWei[23]等研究出了两种针对多数据的蓝噪声采样方法,这两种方法一种严格控制点之间的距离,一种控制点的数量。
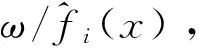
3.3 交互方法
结由于密度采样方法终究会丢失一些细节和离群值,所以需要以交互方法进行补充,允许用户探索细节。以分辨率自适应取样方法为基础,我们实现了一个探索离散数据地理分布的数据探索系统,其支持的交互方式主要有如下几类:
(1)缩放

在分辨率最小的顶层,点的覆盖问题也比较突出,使用蓝噪声取样的取样率也最低,从而减少数据点提高可读性。这样能有效地帮助用户人员洞察整张地图的数据特征和分布模式。随着放大倍数的提升,取样率逐渐提升,用户亦可观察到更多的离散数据地理分布的细节。
(2)选择
为了方便用户对不同类别的数据进行定量分析,系统提供一个方形选择刷,用户可以通过它选择数据集中感兴趣的数据,如图 1所示。同时,这个选择刷还有类似魔术透镜的功能,可以在选框上实时地显示当前选择区域内各类型数据的量和所占总数的百分比。选择刷之所以是方形主要是为了方便计算,提示文字直接显示在方形选择刷的下方以减少用户的交互延时。
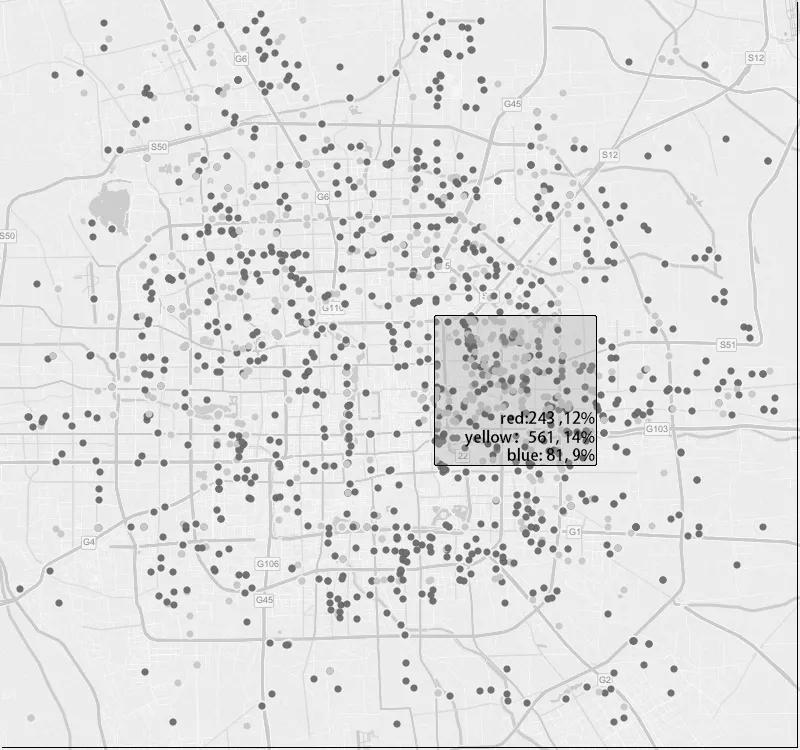
图1 方形选择刷和定量分析
(3)焦点+上下文
该方法一种将焦点视图和关联视图结合在一个可视空间里的呈现。焦点能有效地减少用户的短期记忆负担,上下文则潜在地提高用户的理解和处理信息的能力。我们提供类似取样镜头的方式,当用户的方形选择刷停留在某个地理区域时,可以显示更高分辨率下的细节,如图2所示同时提供快照Snapshot,允许用户记录当前选择区域的细节视图。多个快照以排序的栅格图方式呈现,允许用户对比不同区域的细节。
(4)重绘图
为了更好地对比不同数据类型之间的差别,系统允许用户将选定的数据类型用点值图以外的方式展示,如饼图、热力图、等值线图。RossMaciejewski等人[24]设计了一种热力图改进方法能展示单类别的分布密度,这种方法可以辅助用户获得单类别的整体信息。等值线图或者轮廓线则可以配合点值图使用对比多类数据。在这一过程中,用户还可以隐藏一些数据类型,专门对比选中的数据类型。
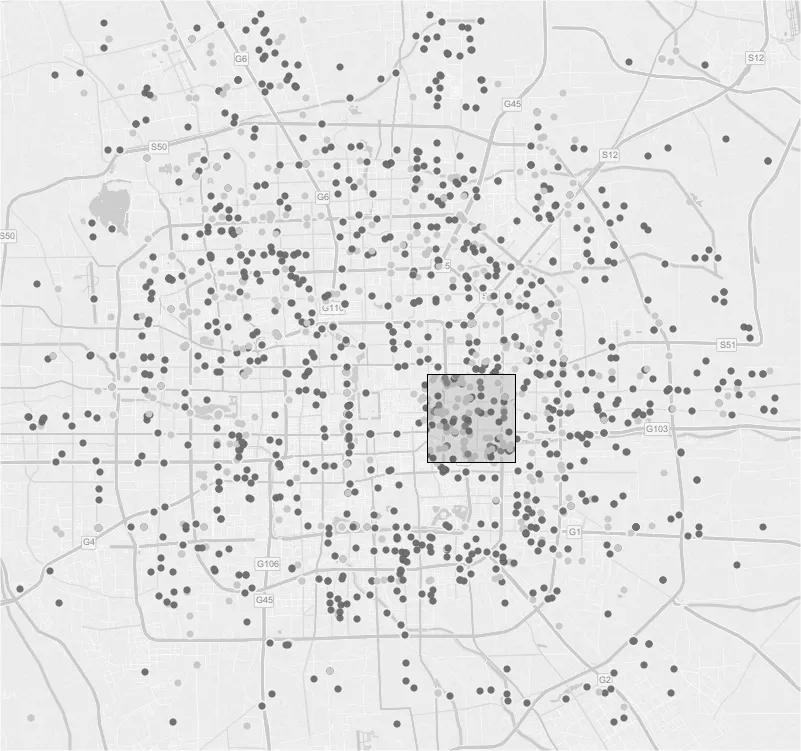
图2 在选择刷中放大分辨率,显示更多细节
4 案例分析
新案例数据集记录了4年内北京市区6000台ATM机警报设备的数据,每条记录包括报警类型(3类报警:类型1为摄像头的报警,类型2为人员手动报警,类型3为震动传感器的报警)和地理位置的相关字段。

图3 低分辨率下北京市区报警数据,红、蓝、黄点分别为类型1、类型2、类型3报警数据。在密集区域的点覆盖导致地理特征不明显
图3是原始数据的地理分布图。其中红色代表类型1的报警,蓝色代表类型2的报警,黄色代表类型3的报警。可以观察到直接投射出现密集地区点遮盖问题。这种地图也无法满足如下定量分析的要求:不同种类的报警与不同区域是否相关联系?
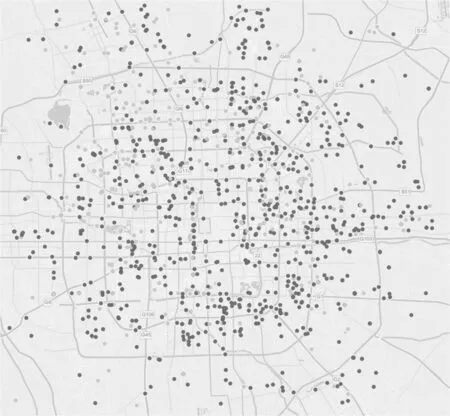
图4 低分辨率下取样后的北京市区报警数据,可以看到其数据复杂度相对图3已经有了很好的改善
通过我们处理的结果(见图4)可以看出报警类型对的地理分布依赖于城市繁荣度,而繁荣地区不同网点的ATM设备覆盖现象又特别多。同图中可以看到,市区西北区域的报警类型3出现更加频繁,通过后期验证分析出该区域报警的设备为同一批次的震动触发器,该批次设备中出现故障报警的频率更加突出。此外我们也发现取样使得类型2在城区南部的分布更加明显。
当用户进行放大操作时,地图将进入更细致的层次。计算机将依据分辨率重新计算取样参数以增加展示的样本点(见图5)。观察重新取样后的区域西北角,原先模糊的故障类型1(红色圆点)在该地区已经形成一个聚合中心,这可能说明了该故障的原因与该区域有关。在这一层次下,其他零散的数据点依然被取样过滤。
5 用户分析
在用户研究中,我们将三种解决地理数据点覆盖的方法横向比较:原始的点值图方法,Ross等人改进的热力图方法以及我们的方法。通过两个实验评估这三种可视化方法在多类数据环境下的视觉识别率。
(1)参与者
我们从一所大学里召集22名人员参与测试,其中12名为男性,10名为女性。总人数中有8名为研究生,其余14名本科生,总体年龄分布在21至27岁之间。所有人都通过颜色辨识能力的测试。
(2)设备
测试设备为28寸的LCD显示器,分辨率3840×2160像素。总共使用20个数据集(包括真实的数据和人造的数据),其中10个数据集供测试1使用,另10个数据集为测试2使用。所有可视化结果的地图大小都以850×750的像素展示。数据类别的颜色采用CIELAB颜色空间中的高对比度颜色组。
(3)任务
测试1通过用户识别指定区域内的数据类别数目来衡量方法的准确率。我们将10个数据集随机排序。每个测试人员进行4次测试。每次测试中识别正确的结果计分为1,识别错误的结果计分为0,最后统计累计分数。
测试2让用户选择指定区域的数据密度分布的顺序,顺序由4个备选答案提供。同测试1的评估方式一致,我们将剩余未使用的10个数据集随机排序组合。同时也使用一致的评分策略。
(4)过程
在测试前,我们将向参与人员简要描述测试内容以及系统的使用方法,并要求其完成一份测试前问卷调查。参与测试的人员在依此进行完两个任务后,还需完成测试报告,其中包括可视分析和视觉认知相关的评估内容。
(5)结果分析
表1展示出测试中3种方法的平均识别成功率,我们的方法相比其他两种方法有着显著的提高。传统的点值图的方法在测试结果中得分最低。其随后的人员报告也指出,原始地图高密度区域的大面积覆盖问题使得测试人员基本只能依据猜测来进行分析多类数据的分布。虽然热力图能够有效地显示密度特征,但是在多类数据探索上就出现了问题,其使用不同的可视变量来描述多元数据的方法使得多元数据在地图上展示不一致,进而影响了不同类别的定量比较。

表1 3种方法的平均分数
6 总结和讨论
本文提供了一种多类离散数据的地理空间分布的可视化呈现方法。我们对传统点值图进行了视觉效果优化,采用分辨率自适应取样方法,根据地理空间分辨率的不同,灵活地调节当前分辨率下取样参数,以期尽最大可能显示细节。其中所采用的蓝噪声取样法优化了数据点的重分布过程,在有效地解决点覆盖的问题的同时保持不同数据类之间的相对密度特征,不会因为不同类别的数据点的渲染顺序问题导致呈现效果大相径庭。为了弥补取样导致的离散特征的丢失,我们使用了一系列交互手段,能有效地提高可视分析的准确性并辅助整体的可视表达。
本方法也有很多值得改进的方面。首先是所采用基于蓝噪声采样的密度估计方法,依然会损失离群值。因此算法方面依然可以继续改进。其次,该方法只使用了颜色来区分不同的类别,配合其他视觉变量,如点的大小、形状或透明度,或许可有更好的效果。最后,本系统所采用的交互操作还是较为简单。如选择操作只提供了方形选择刷,限制了用户选择查看区域的方式。在未来的工作中,还可以在交互方面做进一步改进,例如允许用户引入自定义的任意形状的选择工具,做进一步的细节分析。
[1]Wilkinson L and M Friendly.The History of the Cluster Heat Map[J]. Zitiert auf,2012:7.
[2]Dorling D.WORLDMAPPER:the world as you ve never seen it before[J]. IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS,2006,5(12):757-764.
[3]Fuchs G and H Schumann.Visualizing abstract data on maps[J].IEEE,2004,139-144.
[4]Diansheng Guo,J C A M.A Visualization System for Space-Time and Multivariate Patterns[J]. IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS,2006,6(12):1461-1476.
[5]Kwakkel,J H,et al.Visualizing geo-spatial data in science,technology and innovation[J]. Technological Forecasting and Social Change,2014,81:67-81.
[6]BREWER,C A.Chapter 7 - Color Use Guidelines for Mapping and Visualization[M].Academic Press,1994.
[7]Li J,J Martens and J J van Wijk. A model of symbol size discrimination in scatterplots[J]. 2010:ACM.
[8]Luboschik M,A Radloff and H Schumann.A new weaving technique for handling overlapping regions[J]. ACM,2010,25-32.
[9]Mayorga A and M Gleicher.Splatterplots:Overcoming Overdraw in Scatter Plots[J]. IEEE Transactions on Visualization and Computer Graphics,2013,19(9):1526-1538.
[10]Luboschik M,A Radloff and H Schumann.A new weaving technique for handling overlapping regions[J]. ACM,2010,25-32.
[11]The Gridfit Algorithm:An Efficient and Effective Approach to Visualizing Large Amounts of Spatial Data[Z].
[12]Keim D A,et al.Generalized scatter plots[J]. Information Visualization,2010, 9(4):301-311.
[13]Evesham H A.Origins and development of nomography[J]. IEEE Annals of the History of Computing,1986(4):324-333.
[14]Bachthaler S and D Weiskopf.Efficient and Adaptive Rendering of 2-D Continuous Scatterplots[A]. 2009,Wiley Online Library,743-750.
[15]Zinsmaier M,et al.Interactive level-of-detail rendering of large graphs[J]. Visualization and Computer Graphics,IEEE Transactions on,2012,18(12):2486-2495.
[16]Chen H,et al.Visual Abstraction and Exploration of Multi-class Scatterplots[J]. IEEE Transactions on Visualization and Computer Graphics,2014,20(12):1683-1692.
[17]Ellis G,E Bertini and A Dix. The sampling lens:making sense of saturated visualisations[J]. in CHI '05 Extended Abstracts on Human Factors in Computing Systems,Portland,OR,USA:ACM.
[18]Wilkinson L,A Anand and R Grossman.High-dimensional visual analytics:Interactive exploration guided by pairwise views of point distributions[J]. Visualization and Computer Graphics,IEEE Transactions on,2006,12(6):1363-1372.
[19]Yuan X,et al.Dimension projection matrix/tree:Interactive subspace visual exploration and analysis of high dimensional data[J]. Visualization and Computer Graphics,IEEE Transactions on,2013,19(12):2625-2633.
[20]Cockburn A,A Karlson and B B Bederson.A review of overview+detail,zooming,and focus+context interfaces[J]. ACM Comput Surv,2009,41(1):1-31.
[21]Jones M C,J S Marron and S J Sheather.A brief survey of bandwidth selection for density estimation[J]. Journal of the American Statistical Association,1996,91(433):401-407.
[22]Alexandre L A.A Solve-the-Equation Approach for Unidimensional Data Kernel Bandwidth Selection[Z]. 2008.
[23]Wei L. Multi-class blue noise sampling[J]. in ACM SIGGRAPH 2010 papers,Los Angeles,California:ACM.
[24]Maciejewski R,et al. Understanding syndromic hotspots - a visual analytics approach[J]. in Visual Analytics Science and Technology,IEEE Symposium on,2008.
(责任编辑:马玉凤)
Visual Abstraction and Exploration of Interactive Dot Map
XIAO Zi-da,ZHU Li-gu
(Computer Science School,Communication University of China,Beijing 100024)
The distribution of multiclass discrete data in geographic space is a research hotspot in the field of geographic-related visualization. As a basic visual presentation of such data,the advantages of dot maps are perceptual intuition and abundant details,but there is also the problem of poor readability due to the points overlap. The approach of density estimation by resolution is proposed in this paper to optimize dot maps,and to flexibly adjust sampling parameters of the current resolution,so as to show the details to the maximum extent and maintain the relative density characteristics of various types of property. In order to compensate the missing discrete features caused by sampling,a series of interactive tools are used to effectively improve the accuracy of visual analysis and assist the overall visual representation. Finally,the effectiveness of this approach is proved through case analysis and user research.
dot maps,density estimation,geographic information,interactive data analysis
2016-6-13
肖子达(1992-),男(汉族),湖南长沙人,中国传媒大学计算机学院硕士研究生.E-mail:shawzida@gmail.com
TP302.1
文章编号:1673-4793(2017)02-0046-07
猜你喜欢
廊坊师范学院学报(自然科学版)(2022年3期)2022-10-11 04:32:06
北京航空航天大学学报(2022年8期)2022-08-31 08:58:24
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
科技视界(2021年4期)2021-04-13 06:03:56
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
数学物理学报(2019年3期)2019-07-23 01:15:40
传媒评论(2019年4期)2019-07-13 05:49:14
家庭影院技术(2018年9期)2018-11-02 05:31:32
自动化学报(2017年5期)2017-05-14 06:20:52
