
基于机器学习的网络流量分类算法分析研究
2017-05-15 03:47:51李晓明任慧颜金尧
中国传媒大学学报(自然科学版) 2017年2期
李晓明,任慧,颜金尧
(1.中国传媒大学信息工程学院,北京 100024;2.视听技术与智能控制系统文化部重点实验室,北京 100024;3.现代演艺技术北京市重点实验室,北京 100024)
基于机器学习的网络流量分类算法分析研究
李晓明1,2,3,任慧1,2,3,颜金尧1
(1.中国传媒大学信息工程学院,北京 100024;2.视听技术与智能控制系统文化部重点实验室,北京 100024;3.现代演艺技术北京市重点实验室,北京 100024)
基于应用的流量分类在网络安全和管理中具有非常重要的作用。传统流量分类大部分是基于端口的预测方法和基于有效载荷的深度检测方法。由于当前网络环境中各种隐私问题以及基于动态端口和加密的应用,传统的网络流量分类策略的有效性已经逐步下降,目前主要集中在基于机器学习技术的流量分类模型进行研究。本文对各种基于机器学习算法的流量分类的比较,如贝叶斯网络(BayesNet)、朴素贝叶斯(NaiveBayes)、基于RBF的SVM流量分类和基于遗传算法的SVM(GaSVM)流量分类等。这些算法分别使用了全特征选择和优化后的特征集合,实验结果表明基于遗传算法的SVM流量分类精度较高,并在使用主成分特征也可以达到很高的精度。
贝叶斯网络;朴素贝叶斯;机器学习;遗传算法;SVM;GaSVM
1 引言
网络流量分类在过去几年一直是互联网应用的重要分支。目前,互联网中新的应用模式(如P2P)与应用需求不断涌现,网络流量的井喷式增长以及基于http协议的应用多样化给网络运营商的服务质量带来了巨大的挑战。实时网络流量分类对帮助互联网服务提供商了解网络运行状态、优化网络运营与管理具有重要的意义。一方面,网络运营商使用流量分类实时地将网络中的流量按照网络流的特征进行分类、分析,根据实时的分析结果动态的部署服务质量(QoS),从而避免网络拥塞,提高关键业务的服务质量,实现网络的高效利用率;另一方面,网络服务运营商根据流量分类结果可以预测网络中主要业务的发展趋势,从而制定合理的网络体系架构,为用户提供更好的网络体验。而在网络安全方面,由于有效载荷加密与新型应用的不断涌现,数据包载荷明文难以获取导致基于有效载荷的深度分析的有效性逐步下降。这使得传统的入侵检测系统(intrusion detection system,IDS)[1],难以发现网络中的异常流量(如蠕虫传播、大规模分布式拒绝服务攻击等)与未知协议流量,导致不能及时采取防御遏制措施。而传统的流量分类主要基于端口[2]与基于分组深度解析两种方法。在现有的网络环境中,传统的流量分类方法遭受了巨大的挑战,一些网络应用使用动态随机的端口选择算法[3-4](被动FTP和P2P),导致基于端口的分类算法失效。
2 基于机器学习的网络流量分类分析研究
2.1 基于有监督机器学习的流量分类
基于监督的流量分类算法分为两类:带参数的分类,比如贝叶斯网络(Bayes Net),ID3决策树,SVM[5],朴素贝叶斯[6],贝叶斯网络[7],无参数的分类器如K近邻(KNN)[8]。基于监督的流量分类算法通过训练数据生成一个分类模型,后续的网络流量根据该分类模型确定类别。有监督分类算法是基于人工标注的流量样本集进行训练,并将后续的未知的流量样本根据分类器进行分类。这种方法一般对于已知的流量类型检测率较高,但无法对未知应用类型的流量进行分类;为了算法的泛化性能,需要大规模人工标注数据提高算法性能。其中SVM具有较强的泛化能力。在实际应用中由于业务的有效载荷所面临的困难(如用户隐私、应用数据加密),Moore 和Zuev[9]实现了一种基于网络数据流特征的朴素贝叶斯分类器。Bernaille[10]只使用SSL连接的数据包的大小来识别加密的应用类型。文献[11]应用支持向量机作为流量分类器。这些算法都需要对算法中的超参数进行交叉验证,这需要一个不断的训练过程来得到较理想的超参数。也有一些工作尝试使用非参数的机器学习算法,Nguyen[12]以实时分类为目标,只使用一条流的最近的几个包作为分类依据。Roughan[13]已经证明使用LDA可以实现对流的五类统计特征进行分类。
2.2 基于无监督的机器学习流量分类
无监督的机器学习聚类算法包括K-Means、DBSCAN(密度聚类算法)、EM期望最大化、SC谱聚类等,无监督的方法(或聚类算法)从未标记的流量数据中根据特征进行聚合分簇,并将未标记的测试流分配到距离最近的聚合簇中。Erman等人[14]通过流量聚类实验比较K-Means,DBSCAN和EM算法,实验结果表明当聚类簇的数量高于实际应用类型的数量时,流量聚类算法可以产生高纯度的聚类簇。也就是说,聚类算法可以帮助我们找到一些未知的流量类型,但此类方法通常需要事先去设定一个聚类簇的数量,而且大规模样本聚类时间通常较长。Bernaille等人[15]使用TCP连接特性中的前5个数据分组来区分不同的流量类型,通过实验表明这样可以实时识别流量的应用类型。此方法采用离线训练模型,通过训练模型进行在线的实时分类,离线训练时采用K-Means 算法进行聚类分析,在线分类时计算未知流量与聚类中心的欧式距离确定应用流量类型。但是为了满足实时分类的有效性,该方法依赖于数据包分组的到达顺序,而由于实际网络的实时可变性往往会影响数据包的排列顺序,因此在对网络流量的实时分类中,该方法不能很好的保证分类的准确性。
2.3 基于遗传参数寻优的SVM流量分类模型
支持向量机(SVM)是现阶段泛化能力较好的分类算法之一,通过核函数的变化使得该算法可以处理高维特征。SVM 解决二值分类问题的方法是构造特征空间上正例和反例两类样本最大间隙分隔平面y=wT·φ(x)+b。支持向量机理论的基础是统计学习理论中的 VC维理论与结构风险最小化原理,在对网络流量进行分类时,使用较少的流量特征达到较好的分类效果,并在先验知识相对不足的情况下,仍保持较高的分类准确率。
使用支持向量机时,定义不同的核函数,以及松弛因子,可以实现较好泛化效果的分类器。支持向量机的优化模型如下:

(1)
原函数的最优化问题转化为相应的拉格朗日对偶函数的极大值:
(2)
分别对w,b,ε求偏导
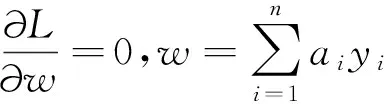
带入公式(2)得到相应的拉格朗日对偶函数的优化模型如下:

(3)
c-ai-μi=0
c≥ai≥0
μi≥0
注意公式中超参数松弛因子C,以及高斯核函数RBF中的gamma,在SVM中一般通过交叉验证的方法对这些参数进行寻优,本文采用遗传算法进行相应的参数寻优。基于遗传算法的SVM分类算法系统模型如图1所示。
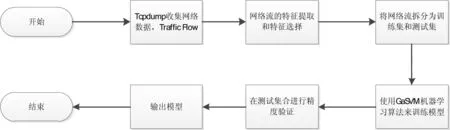
图1 基于遗传算法的SVM分类算法系统模型
本文引用分类精确度(accuracy),训练时间(train-time),召回率(recall),查准率(precision)作为评估算法性能的参数,召回率和查准率如表1所示进行说明。
表1 召回率和查准率
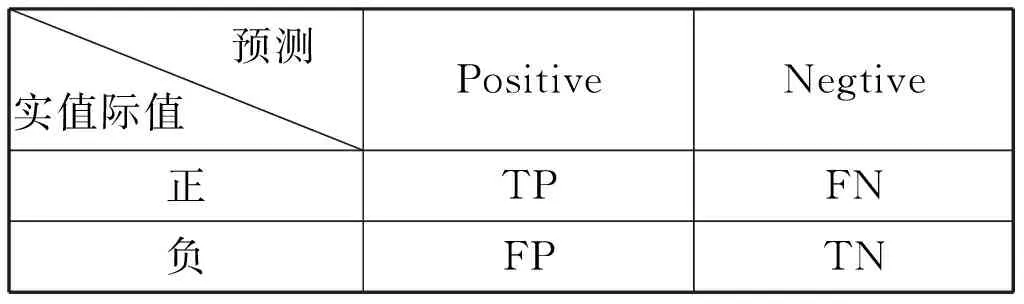
预测实值际值 PositiveNegtive正TPFN负FPTN
TP(true positive):样本所属类型为正例,分类器预测类型也为正例;
FN(false negative):样本所属类型为正例,但被分类器预测错误为负例;
FP(false positive):样本所属类型为负例,但被分类器预测错误为正例;
TN(true negative):样本所属类型为负例,分类器预测类型也为负例。

(4)
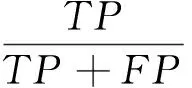
(5)
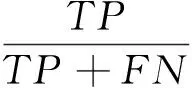
(6)
如公式(4)表示的是分类精确度,公式(5)表示的是查准率,公式(6)表示的是召回率。
3 实验及结果分析
3.1 实验数据集
目前大多数关于流量分类的研究都是以Moore_set为标准。在这个过程中,本文使用了前两个数据子集,并通过全特征数据集,以及优化特征选择的方式减少特征维度,这些数据采集自同一个站点的流量数据,采集间隔12h,每一个数据集包含几万条数据。每一个样本包含了248项属性,标签项为249项,即分类标签,表明该样本的流量类型,流量类型如表2所示。
这些数据集合被分为10个子集,本文使用了前两个数据子集,如表3所示。
本文中Moore_set数据集包含248个特征,如数据包的最小,最大值,平均数据包,数据包的大小,持续时间等。分别采用全特征以及主成分分析的方法选取特征,并使用贝叶斯网络BayesNet、朴素贝叶斯分类器、SVM、以及基于遗传算法对SVM超参数寻优来对Set01和Set02进行训练。试验中我们将样本数据的66%作为训练数据,剩下的作为测试数据,使用3折交叉验证。其中SVM采用RBF函数作为核函数。

表2 Moore_set数据集的流量应用类型所占比例

表3 Moore_set的前两个子集
3.2 实验结果分析
在全特征的情况下,BayesNet、SVM、GaSVM算法都取得了较好的准确率,其中GaSVM的精度高达98.875%,而朴素贝叶斯的模型只能达到63.8285%,而训练时间基于RBF的GaSVM训练时间最长,高达123.09秒,如表4所示。
减少特征后的分类准确率与训练时间,本文采用了Weka3.8自带的特征选择模块进行特征选择。经过选择后的分类器的训练时间与准确率如表5所示。
采用主成分的特征选择算法后,Bayes Net、Naive Bayes、GaSVM的精确度都有所提高,而由于参数选择的问题导致SVM算法本身精度有所下降,如图2所示。

表5 经过特征选择后的各个分类器准确率
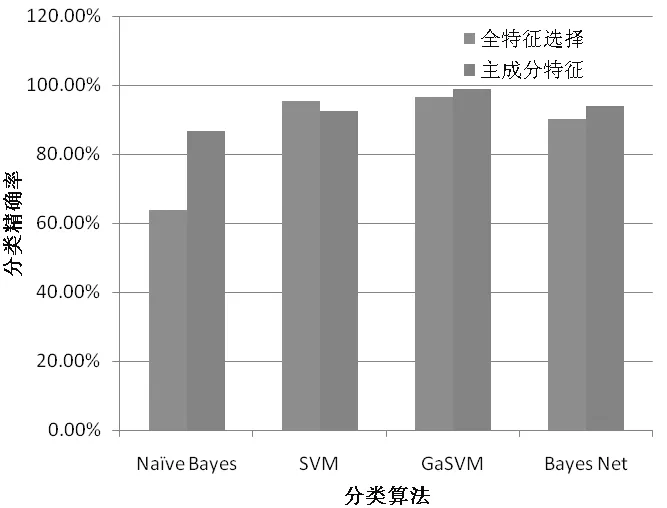
图2 全特征选择和主要特征选择后的分类算法精确率(Accuracy)
当c=10.278,gamma=0.86975的时候SVM分类器的分类精确率最高,约为98.8764%,如图3所示。

图3 基于遗传算法的SVM参数寻优
基于遗传算法的SVM分类器提高了ATTACK和DATABASE流量类型的查准率,在其他流量类型中的表现也是较好的,如图4所示。

图4 各个分类器在不同流量类型上的查准率(Precision)
4 结论
本文通过对比贝叶斯网络、朴素贝叶斯、SVM、GaSVM分类算法的精度和查准率,发现对于基于遗传的GaSVM分类算法,通过使用主成分特征的降维技术后也可以达到较高的精度,并通过检查计算性能指标,如建立时间和分类速度,贝叶斯网络和朴素贝叶斯分类器的速度较快,但精度相对减低,而SVM和GaSVM的模型训练时间较长,精度较高。在针对不同应用场所时,当对分类结果精度要求较高时,可以采用线下GaSVM训练模型,线上使用模型进行实时预测;当对分类结果精度要求一般时,可以直接采用贝叶斯网络来进行流量的实时分类。
[1]Snort[EB /OL]. http:/ /www. snort. org,2008.
[2]Internet assigned numbers authority[EB /OL]. http:/ /www.iana.org,2008.
[3]Karagiannis T,Broido A,Brownlee N. Is P2P dying or just hiding[J]. IEEE Globecom 2004 - Global Internet and Next Generation Networks,2004,(3):1532 - 1538
[4]Madhukar A,Williamson C. A Longitudinal Study of P2P Traffic Classification[J].IEEE International Symposium on Modeling,Analysis,and Simulation, IEEE Computer Society,2006:179-188.
[5]H Kim,K Claffy,M Fomenkov,D Barman,M Faloutsos,K Lee.Internet traffic classification demystified:myths,caveats,and the best practices[J].Proceedings of the ACM CoNEXT Con- ference,New York,NY,USA,2008,1-12.
[6]R Kohavi.Scaling Up the Accuracy of Naive-Bayes Classifiers:a Decision-Tree Hybrid[J].in Proceedings of 2nd International Conference on Knowledge Discovery and Data Mining(KDD),1996.
[7]A W Moore,D Zuev.Internet Traffic Classification using Bayesian analysis techniques[J].ACM SIGMETRICS 05,2005.
[8]Huang S,Chen K,Liu C. A statistical-feature-based approach to internet traffic classification using Machine Learning[J].International Conference on Ultra Modern Telecommunications,Icumt 2009:12-14,Petersburg,Russia,2009:1 - 6.
[9]A W Moore,D Zuev.Internet traffic classification using bayesian analysis techniques[J].SIGMETRICS Perform Eval Rev,(33):50-60,June,2005.
[10]L Bernaille,R Teixeira.Early recognition of encrypted applications[J].Proceedings of the 8th international conference on Passive and active network measurement,Berlin,Heidelberg,2007,165-175.
[11]A Este,F Gringoli,L Salgarelli.Support vector machines for tcp traffic classification[J]. Computer Networks,53(14):2476-2490,2009.
[12]T Nguyen,G Armitage.Training on multiple sub-flows to optimise the use of machine learning classifiers in real-world ip networks[J].Local Computer Networks,Annual IEEE Conference on,Los Alamitos,CA,USA,2006,369-376.
[13]M Roughan,S Sen,O Spatscheck,N Duffield.Class-ofservice mapping for QoS:a statistical signature-based approach to IP traffic classification[J].Proceedings of the 4th ACM SIGCOMM conference on Internet measurement,New York,NY,USA,2004,135-148.
[14]Erman J,Mahanti A,Arlitt M. QRP05-4:Internet Traffic Identification using Machine Learning[J].IEEE Global Telecommunications Conference,2006:1-6.
[15]Bernaille L,Teixeira R,Akodkenou I.Traffic classificationon the fly[J]. ACM Special Interest Group on Data Communica-tion(SIGCOMM)Computer Communication Review ,2006,36(2):23-26.
(责任编辑:宋金宝)
Research on Network Traffic Classification Algorithm Based on Machine Learning
LI Xiao-ming1,2,3,REN Hui1,2,3,YAN Jin-yao1
(1.Information Engineering School,Communication University of China Beijing 100024; 2.Key Laboratory of Acoustic Visual Technology and Intelligent Control System,Ministry of Culture,Beijing 100024; 3.Beijing Key Laboratory of Modern Entertainment Technology Beijing,Beijing 100024,China)
Traffic classification based on their generation applications plays an important role in network security and management. The port-based prediction methods and payload-based deep inspection methods comes under traditional methods. The standard strategies in currentnetwork environment suffer from variety of privacy issues,dynamic ports and encrypted applications. Recent research efforts are focused on traffic classification based on Machine Learning Techniques,and made comparison the various Machine Learning(ML)techniques such as Bayes Net,Naive Bayes,SVM based on RBF,VM based on genetic algorithm for IP traffic classification.These classification algorithms used full feature selection and optimized feature set to classify network traffic. It can be seen from the experimental results that GaSVM traffic classification can achieve high accuracy,especially in the use of principal component features.
Bayes Net;Naive Bayes;machine learning;genetic algorithm;SVM;GaSVM
2017-1-05
国家科技支撑计划重大项目(2012BAH38F00)
李晓明(1984-),男(汉族),山西朔州人,中国传媒大学博士研究生.E-mail:290664743@qq.com
TP
A
1673-4793(2017)02-0009-06
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
微型电脑应用(2021年3期)2021-03-31 08:56:46
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
数理化解题研究(2017年4期)2017-05-04 04:07:54
电子制作(2017年23期)2017-02-02 07:17:06
铁道通信信号(2016年6期)2016-06-01 12:10:20
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电子器件(2015年5期)2015-12-29 08:43:15
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
振动工程学报(2014年4期)2014-03-01 01:15:41
