
基于Hive数据仓库的物流大数据平台的研究与设计
2017-05-13 11:16张锐
电子设计工程 2017年9期
张锐
(驻马店职业技术学院 河南 驻马店 463000)
基于Hive数据仓库的物流大数据平台的研究与设计
张锐
(驻马店职业技术学院 河南 驻马店 463000)
针对物流企业数据仓库扩展性不好、运行自动化程度不高、处理大规模数据效果较差等问题。本文通过对Hive技术的物流数据仓库进行分析,提出物流数据仓库的具体实现方案,该数据仓库结合云平台虚拟化技术,部署了 Hadoop和Hive环境,搭建了基于虚拟化技术的大数据处理平台。同时从数据ETL和数据查询分析处理两方面对数据仓库的可扩展性Hive数据存储分析、Hive数据前置处理等进行研究设计。通过Hive数据仓库运行效果进行分析,表明该系统能够很好地支持企业管理层决策。
智慧物流大数据平台;Hive数据仓库;ETL;查询分析
随着电子商务的不断壮大,物流业的蓬勃发展,物流数据开始呈现爆炸式增长。目前用于物流行业的仍然是传统数据仓库居多,已有的物流信息管理系统的建设也大多采用常规的解决方案,即购置昂贵的的大型服务器,以此为基础,采用数据库分片的方式将数据存放到磁盘阵列中,这导致系统的扩展升级较为困难,花费巨大,且整个系统的耦合性较强,难以满足高效、可靠、经济的需求。然而,Hive数据仓库作为新型数据仓库架构,其利用大数据集群的优势,能够采用普通服务器集群满足物流企业对数据仓库提出的各项需求。因此,文中提出了基于Hive数据仓库的物流大数据平台设计。
1 基于Hive的物流数据仓库系统设计
1.1 总体框架设计
DK智慧物流大数据平台分为数据源、Hive数据仓库、Web展示共计3个模块,总体架构设计如图1所示。
1)数据源
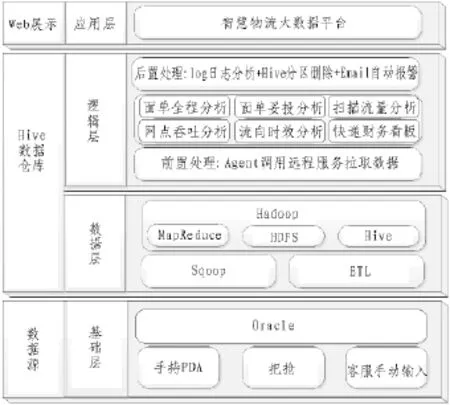
图1 总体框架
数据源即基础层,采用关系型数据库管理业务数据,为数据仓库提供原始物流数据。这些数据来源于不同操作:派件员通过手持 PDA扫描运单条码时,该票运单信息即入库,其状态信息是“已收”。在一天结束后,对所有已收的货物统一进行过秤扫描,分拣员通过把枪 (类似于超市购物结账时使用的价钱扫描器件)扫描运单条码,同时输入其发往地信息和重量信息,此时该运单状态对于发件人来说是“派件中”,而对于发件站来说是“应派件”,对于下一个中转站来说是“应收件”。在运单状态成为“已签收”之前,如果出现任何特殊情况,则该运单状态变成“问题件”或“异常件”。另外,运单信息还可以通过客服人员手动输入的方式生成。所有的运单信息都保存在Oracle数据源中,这一部分组成总体架构的基础层。
2)Hive数据仓库
Hive数据仓库由数据层和逻辑层共同构成:
数据层由Hadoop平台及其组件组成,包括Sqoop、Hive、MapReduce和 HDFS,原始数据通过ETL方式进入数据层,以文件形式存储在HDFS上,作为逻辑层的输入数据。
逻辑层对已存储在数据仓库中的原始数据进行数据分析之前,需要进行前置处理,通过Python脚本拉取远程映射数据,之后根据系统的业务需求进一步对数据进行查询分析处理。整个Hive数据仓库工作过程中,会将代码执行时耗等保存为 log日志,自动化程序会对此日志进行分析,不同程序的执行开始时间和结束时间以 email的形式发送给管理员。同时,查询分析处理的结果数据则会被导出至Mysql数据库中,这些结果数据就是我们需要关注的有价值数据。
3)Web展示
Web展示模块的全部功能由应用层提供,应用层采用 B/S结构,开发J2EE项目,选用 MVC模式,通过Web端以图表的形式展示关注数据。前后的数据传输方式采用 ajax异步传输,数据使用 json格式。
1.2 开发语言选择
开发语言选择如图2所示。

图2 智慧物流大数据平台技术架构
上图从左往右依次体现了开发过程中涉及的各个步骤所需开发语言。数据 ETL部分将采用SHELL脚本开发,前置和后置处理则通过 Python脚本开发,数据分析部分通过SHELL脚本调度内嵌的HiveQL语句,同时使用Hive的transform和using关键字调用Python脚本进行复杂数据查询分析处理,最后采用 J2EE技术构建 Web项目,结合 echarts工具展示图表数据。
2 数据处理实现
2.1 前置处理
考虑到不同的业务调用的预处理脚本实现方法差不多,只有拉取到的数据不同,因此,以下分析以妥投率的预处理脚本为例,前置处理过程涉及到的脚本名称及其说明如表 1所示。
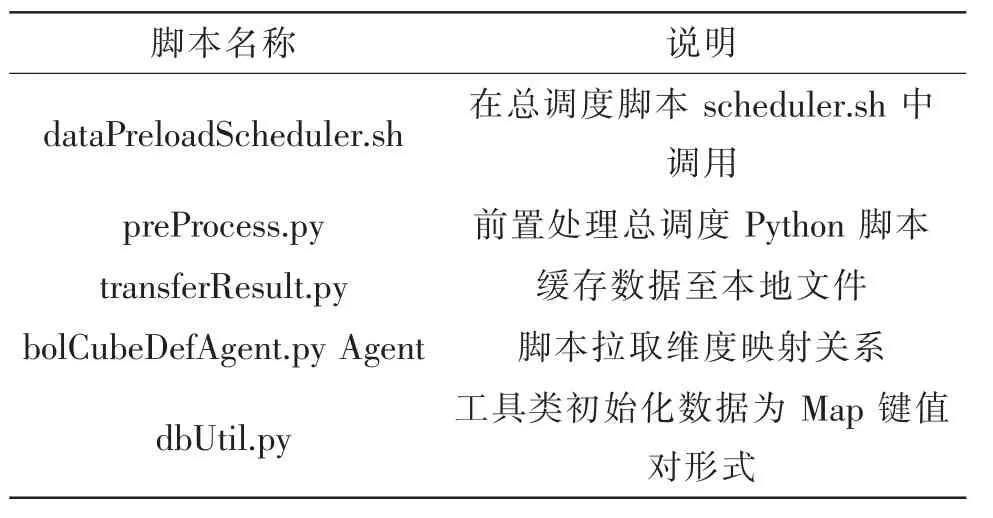
表1 前置处理过程涉及到的脚本
2.2 查询分析处理
查询分析处理目的是通过对 Hive数据仓库中的数据进行分析,从而将处理结果保存至 mysql数据库中,作为Web展示的数据源。
数据成功导入 Hive之后,会立即执行bolScheduler.sh脚本,该脚本会根据业务需求,对每个不同的业务,调用相应的业务处理脚本,这些业务脚本都存放在 bol文件夹中,该文件夹与bolScheduler.sh属于同级目录,它们都属于 stats文件夹的子目录,以妥投率为例,查询分析处理SHELL脚本目录结构如图 3所示。
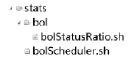
图3 业务处理SHELL脚本目录结构
图3中,bol文件夹中存放的查询分析处理脚本的编写形式都差不多,不同点在于要针对不同业务功能实现不同HiveQL和Python脚本的编写,以妥投率分析脚本 bolStatusRatio.sh为例,其具体实现过程如下:
首先,需要设置好脚本中到的变量值,包括脚本运行日志记录文件的路径、控制台输出结果保存的文件路径、开始和结束日期值、需要调用的其他脚本文件名和所属包名等。
接下来,通过 SHELL命令进入 Hive,然后运行HiveQL语句,代码如下:

在上述代码中,以“$”符号开头的表示变量,这些变量在进入Hive环境之前已经设置过,所以第一句的作用就是通过SHELL命令进入HiveShell运行环境中,同时保证将 Hive运行结果(即最后在控制台上显示的标准输出)保存到日志文件 (用变量resultFile表示)中。接着,ADD FILE命令会将HiveQL执行过程中需要使用的 Python脚本添加进来,成功添加后,使用 use命令进入 dkcore数据库。妥投率分析涉及的 HiveQL语句过于冗长,没有单独贴出来,仅使用Concrete_HiveQL来表示,该语句中主体部分如下所示:

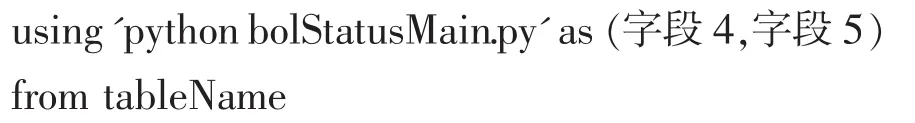
上述 HiveQL片段表示从表名是 tableName的数据表(可以是临时表)中查询出字段 1至字段 3,使用 transform关键字可以将查询出的这 3个字段作为Python脚本的输入。接下来使用using关键字引入妥投率分析脚本,该脚本的输出即为字段 4和5,注意,Python输出字段个数与输入字段个数可以不相同,这也是使用 python作为复杂数据分析脚本的一个重要原因,因为Hive本身对于查询字段只能作简单统计,不能减少或增加输出字段个数。
字段 4和 5一般就是妥投率分析需要展示的最终数据,当然,这些数据也可以作为外层 HiveQL的输入数据,只要将此数据集看作一个临时表即可。HiveQL成功执行后,使用 EOF命令退出Hive命令行模式,此时Hive中的执行结果会在控制台屏幕上显示,同时,前面已经提到过,这些结果还被保存在了文件resultFile中,但是该文件中除了结果集数据,还是存在一些不需要的命令语句,可以使用 sed命令,辅助正则表达式,将不需要的字符删除,最后剩下的就是有价值的数据了,将该文件中的数据再导出至数据库(项目中使用的是 Mysql),则整个查询分析过程就此完成。
3 基于Hive的物流数据仓库运行
3.1 Hive数据仓库运行
基于 Hive的物流数据仓库运行处理过程全部由自动化脚本完成,不需要人工干预,因此未提供良好的用户界面,但是其运行过程中,会将一些后台运行情况使用标准输出方式打印在控制台上,通过控制台显示信息,可以监控当前后台程序运行的进度。
1)ETL过程监控
ETL过程后台运行情况可以通过 SSH终端访问客户端 SecureCRT远程连接Hadoop集群查看,如图4所示。
图4中,显示了SHELL程序调用Sqoop命令完成数据导入的部分基本过程,可以看到,在程序执行时,系统将 Sqoop程序作为 MapReduce程序来运行,首先为它指定了一个任务号,然后开始执行数据导入操作,同时将执行进度通过百分比显示出来。任务完成后,会列出整个任务处理过程中使用到的计数器(Hadoop为每个作业维护若干计数器,可以用来描述该作业已处理的数据量、已产生的输出数据量等各项指标)。
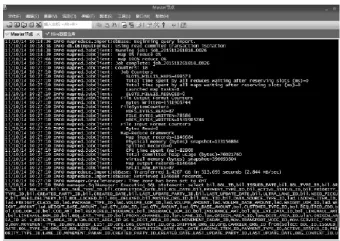
图4 查看Hive表
任务完成后,控制台会显示数据导入成功信息。在 Hive中,可以查看导入的数据是否已保存为Hive表,如图5所示。
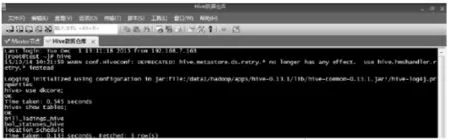
图5 数据处理片段
上图中,使用 use命令进入 dkcore数据库,使用 show tables命令可以看到当前数据库 dkcore中存在的所有 Hive表,如 bill_ladings_hive,该表的表名是在Sqoop命令中写好的。
2)数据处理过程监控
数据的前置处理、查询分析处理、后置处理均由自动化脚本统一调度,其运行过程使用 Hadoop的并行计算框架MapReduce去处理,与数据ETL类似,数据处理过程中仍然先确定一个任务号,然后通过百分比显示该任务进度。数据处理片段如图6所示。

图6 部分结果数据
上图中,Ended Job表示任务正常结束,此时,结果数据已经被写入文本文件,同时导出至数据库。图7是部分结果数据。

图7 部分结果数据
图7中,第一行表示的是字段名,每个字段名之间通过逗号分隔,从第二行开始是每个字段对应的值,字段值之间通过制表符分隔,具体的字段含义在3.3节数据存储部分已经介绍过。
3.2 Web展示
以面单妥投分析为例,妥投率有3个功能:站点妥投率,以表格的形式列出每个站点在某日期下的妥投率。地理区域妥投率,以地图的形式列出省,市,县在某日期下的妥投率。业务区域妥投率,先以组织关系树列出组织,点击组织查看某日期下的一周妥投率趋势。
点击导航”妥投率”进行妥投率主页面,有3个标签页展示3个功能,如图8所示。
对图8中显示的查询条件:首先是区域,能够筛选出某区域下的站点。日期表示查看该日期的妥投率(必选项)。妥投率类型含 3种,24小时、48小时、和 72小时、最近一周(7天)和最近一个月(30天),默认是 24小时,若选择其他的类型,则表格的到件数、签收数等数据也会相应变化。
4 结 论
文章以 DK智慧物流大数据平台建设为背景,设计了基于Hive的物流数据仓库的系统架构,实现了该基于 Hive的物流数据仓库的基本功能,包括Hive数据存储分析,Hive数据的前置处理、查询分析处理、后置处理脚本实现以及Hive数据查询分析结果的 Web展现等,很好的支持了物流行业的信息化建设和管理决策。

图8 面单妥投率页面
[1]牛瑞瑞,一种基于数据仓库的物流系统构建研究[J].信息与电脑(理论版),2012(11):37-38.
[2]冯强郑垂勇,商业智能技术在物流企业数据仓库设计中的应用[J].物流技术,2015(14):192-194.
[3]孟小峰 慈祥,大数据管理:概念,技术与挑战[J].计算机研究与发展,2015,50(1):146-169.
[4]吴明礼,张宏安,李也白,基于 Hadoop的高性能数据仓库建设研究[J].信息与电脑(理论版),2015(9):50-53.
[5]Zhu K,Applying data mining technology to solve the problem of traffic:a case study[J].Journal of Simulation,2014,2(4):214-217.
[6]Jiang P,Liu X S.Big data mining yields novel insights on cancer[J].Nature genetics,2015,47(2):103-104.
[7]Juan Y.Discussion on Integration of Data Warehouse and Big Data[J].Telecommunications Science,2015,31(3):62-66.
[8]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communi-cations of the ACM,2008,51(1):107-113.
[9]张京一,基于 Hadoop的 Web查询平台的权限控制与性能优化模块.2015,北京邮电大学。
[10]费仕忆,Hadoop大数据平台与传统数据仓库的协作研究.2014,东华大学.
[11]叶文宸,基于 hive的性能优化方法的研究与实践[D].南京大学,2011.
[12]郭超,刘波,林伟伟.基于Impala的大数据查询分析计算性能研究 [J].计算机应用研究,2015(5): 1130-1335.
[13]陈龙,万定生,顾昕辰.基于Hive的水利普查数据仓库[J].计算机与现代化,2014(5):127-131.
[14]王德文,肖凯,肖磊.基于Hive的电力设备状态信息数据仓库[J].电力系统保护与控制,2013(9): 125-131.
[15]查礼.基于Hadoop的大数据计算技术[J].科研信息化技术与应用,2012(6):26-33.
[16]游进国,杨卓荦,胡建华,等.一种支持大规模数据的多维可视化分析框架[J].计算机工程,2011(19):26-31.
[17]王苏卫.基于Hadoop和Hive的电信行业数据仓库研究[J].电子技术与软件工程,2013(11):89.
Based on the Hive of data warehouse logistics research and design of the big data platform
ZHANG Rui
(Zhumadian Vocational and Technical College,Zhumadian 463000,China)
According to logistics enterprise data warehouse extensibility is bad,do not have a high level of automation operation and dealing with large-scale data effect is poor.This article through to the Hive logistics data warehouse technology is analyzed,put forward the concrete implementation of data warehouse logistics solution,the combination of cloud data warehouse platform virtualization technology,deployment of Hadoop and Hive environment,build a large data processing platform based on virtualization technology.At the same time from two aspects of data ETL and data query analysis and processing of the data warehouse extensibility Hive data storage analysis,Hive data pre-processing and so on carries on the research design.Through the Hive data warehouse operation effect is analyzed,indicates that the system is able to support management decisions.
intelligent logistics big data platform;Hive data warehouse;ETL;query analysis
TN915
A
1674-6236(2017)09-0031-05
2016-06-05稿件编号:201606041
河南省科技计划项目(9412014J0069)
张 锐(1980—),女,河南驻马店人,讲师。研究方向:计算机科学与技术、多媒体技术。
猜你喜欢
现代经济信息(2022年31期)2022-12-13
作文小学中年级(2022年11期)2022-11-25
铁道运输与经济(2022年5期)2022-05-25
课堂内外(小学版)(2020年11期)2020-12-04
自然资源信息化(2019年4期)2019-03-29
电子测试(2018年14期)2018-09-26
中学生(2017年19期)2017-09-03
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
实践·党的教育版(2016年4期)2016-05-04
