
针对瞬时故障和间歇性故障的NoC链路容错方法
2017-05-13 03:44欧阳一鸣孙成龙李建华梁华国黄正峰杜高明
计算机研究与发展 2017年5期
欧阳一鸣 孙成龙 李建华 梁华国 黄正峰 杜高明
1(合肥工业大学计算机与信息学院 合肥 230009)2 (合肥工业大学电子科学与应用物理学院 合肥 230009) (oyymbox@163.com)
针对瞬时故障和间歇性故障的NoC链路容错方法
欧阳一鸣1孙成龙1李建华1梁华国2黄正峰2杜高明2
1(合肥工业大学计算机与信息学院 合肥 230009)2(合肥工业大学电子科学与应用物理学院 合肥 230009) (oyymbox@163.com)
片上网络中链路是路由器之间连接的关键通路,其发生故障将严重影响网络性能.针对这一问题,提出了一种针对瞬时和间歇性故障的高可靠链路容错方法,该方法可以在网络中实时检测数据是否发生错误,并以此定义瞬时故障和间歇性故障,从而进行容错.在减轻网络拥塞和延时的同时,保证了数据的正确传输,有效保障了系统的高可靠性.当链路中发生瞬时故障导致数据出错且不能正确纠正时,通过设置的重传缓冲区内备份的数据重新进行传输.当链路中发生间歇性故障导致数据出错且不能正确纠正时,数据包传输被截断,对被截断的数据重新添加头微片或尾微片,从而进行重新路由或资源释放.实验结果表明:该容错方法在不同故障情况下较对比对象,均较大地降低了延时,提高了吞吐率,该方法能有效地提高网络的可靠性,保证了系统性能.
片上网络;瞬时故障;间歇性故障;容错;重传;可靠性
随着半导体技术的发展,单个芯片上集成的核数目越来越多,传统的基于总线(bus)架构的片上系统(system-on-chip, SoC)由于可扩展性差、通信效率低等问题已不能高效地实现处理器之间快速的数据资源交换.片上网络(network-on-chip, NoC)作为一种新的片上多核系统(multiprocessor system-on-chip, MPSoC)互连通信架构的解决方案,由于其可扩展性高、低延时和高带宽的优点被提出[1-4].
NoC系统的主要功能是通过路由器保证数据包能够正确无损地从源节点传输到目的节点.链路作为路由器之间连接的关键数据通路,起着至关重要的作用.而由于软错误、线间串扰、温度和老化等问题,链路传输可靠性受到了极大的挑战.当链路故障发生时,即使路由器无故障,也不能发挥其正常的路由功能,大大降低了整体网络性能.因此针对链路的容错设计显得尤为重要[5-7].
面对链路容错问题很多研究学者纷纷展开了深入研究.在链路上发生的故障可分为永久性故障、瞬时故障和间歇性故障.
1) 链路永久性故障是高能粒子击穿硅氧界面,导致链路功能损害[8].永久性故障一旦发生就会一直存在不会消失,故永久性故障可控性好,容错一般采用重路由[9]或硬件冗余[10]来解决.
2) 瞬时故障的发生随机且没有规律,一般发生是瞬时性的且可恢复.文献[11]中指出大约有80%的通信故障为瞬时故障.对于瞬时故障容错,一般可以分为两大类:①基于随机通信的容错机制,如文献[12]提出的洪泛算法,通过广播和扩散,目的节点会收到很多冗余的数据包备份,即使有数据被损坏,仍然能收到正确的数据,但同时也带来了很大的功耗开销;②基于检错码和纠错码的请求重传机制,主要有端到端(end-to-end, e2e)的重传[13]和跳到跳(switch-to-switch, s2s)的重传[14-15],文献[13]中使用e2e重传机制,在发送端和接收端的网络接口中进行差错校验编码(error correcting code, ECC)编解码,若接收端检测到数据包出现错误,则向发送端请求重传数据包,但是该方法仅在目的节点进行错误检测,发生重传时会导致延时翻倍,且传统ECC仅能纠正一位数据出错,检测效率低下,在多位数据出错时,重传会大幅增大传输延时.文献[15]使用s2s重传机制,通过在每个路由器内部设置重传缓冲区(buffer)暂存传输的数据,当下游ECC检测到数据出错,则重新传输,但是ECC只能覆盖一位数据错误,多位数据出错时会触发重传机制,也会增大网络延时.
3) 间歇性故障是指由于温度、电压等因素的影响导致故障间歇性发生,且持续多个时钟周期,其可控性差.既不能通过重传机制来解决,也不能定义为永久性故障进行解决,间歇性故障发生时,数据包的传输路径被故障链路截断[16].已通过故障链路的数据由于缺少尾微片(flit)对其所占用资源的释放,长时间的资源占用会造成网络拥塞,从而导致网络延时增加、吞吐量下降,降低了网络性能.同样地,由于间歇性故障链路的存在,未通过故障链路的数据缺少头flit的路由引导,长时间占用Buffer资源会造成网络拥塞,甚至有可能导致死锁.文献[17]提出一种混合路由机制,设置North-last和South-last两个子网,使用不同路由算法复制数据进行传输,增加了数据传输的成功率,但2个子网的复制传输明显造成了资源的浪费.
结合以上内容,本文提出了一种针对瞬时和间歇性故障的高可靠链路容错方法.主要有2点创新之处:
1) 设计一种分离式ECC编码策略,可同时容忍4个连续错误,并在此基础上提出一种瞬时故障链路重传容错方法,最大化提高容错的能力.在路由器中添加重传Buffer,当链路发生瞬时故障时,重传Buffer结合分离式ECC编码最大化容忍瞬时故障.
2) 提出一种间歇性故障链路截断重传容错方法.在路由器的虚通道中备份头flit,当链路发生间歇性故障时,已通过故障链路的数据添加伪尾flit,进行资源释放.未通过故障链路的数据添加伪头flit,重传路由,减轻故障对系统性能的影响.
1 NoC中路由器架构
1.1 基准虚通道路由器结构
基准的P端口的虚通道路由器结构如图1所示,包含5个基本单元:输入缓冲区Buffer、路由计算单元(routing computation, RC)、虚通道分配单元(virtual channel allocator, VA)、交叉开关Crossbar和交叉开关分配单元(switch allocator, SA).每个端口对应一条物理链路,每条物理链路对应着多个虚通道(virtual channel, VC)进行数据传输.
在路由器发送数据包时,本地处理单元将数据包划分为格式统一的flit,以方便路由数据包.典型地,数据包被划分为3种类型的flit:头flit(head flit, HF)、数据flit(data flit, DF)、尾flit(tail flit, TF).其中HF携带了源节点和目的节点的地址信息等,数据包在每一跳的数据传输的过程中,都需要HF中的目的节点的地址信息进行路由选择,因此HF对于整个数据包的传输至关重要;DF携带了数据包的数据信息;TF用来释放数据包所占用的资源.
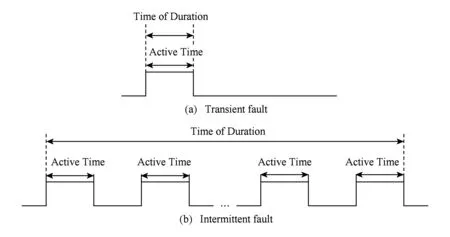
Fig. 2 Transient and intermittent fault model analysis图2 瞬时和间歇性故障模型分析
1.2 链路故障分析
路由器之间通过2条单向链路进行连接通信,由于温度、电压和串扰等因素的影响,链路会发生瞬时故障或间歇性故障.由于高能粒子轰击晶体管、串扰等因素的影响就有可能发生瞬时故障,引发数据出错,这些错误是瞬态且可恢复的[8,18].如图2(a)所示,瞬时故障导致的数据错误表现为一段时间内单脉冲的活跃时间,其故障持续时间即为活跃时间.文献[15]中指出瞬时故障的持续时间一般为一个时钟周期.如图2(b)所示,间歇性故障表现为一段时间内数据频繁无规律的错误跳变,且持续多个脉冲周期[16,19].从时间角度分析,间歇性故障将突然发生并持续一段时间,而瞬时故障一般只会持续一个时钟周期.瞬时故障和间歇性故障的发生均不会导致链路的永久性失效,本文考虑的故障类型为瞬时故障和间歇性故障.
2 高可靠链路容错路由器结构
本文综合考虑NoC中链路发生瞬时故障和间歇性故障情况,提出了高可靠链路容错路由器结构.在传统ECC编码的基础上设计一种分离式ECC编码,从而提高路由器的容忍错误能力.通过在路由器内部设置重传Buffer,结合分离式ECC编码策略,实现对链路瞬时故障容错.当链路中发生间歇性故障时,链路表现为多个时钟周期的数据出错.通过在VC上备份的头flit,对被截断数据包添加伪头flit或伪尾flit,实现对间歇性故障容错,并且在一定程度上减轻了网络拥塞.
2.1 容错路由器整体设计
本文提出的高可靠链路容错路由器设计,其整体结构如图3所示.容错路由器基本部分包括东(E)、西(W)、南(S)、北(N)、本地(L)五个端口,还有虚通道、交叉开关以及相应的控制逻辑部分.图3灰度部分所示为本文添加的容错部分,主要由ECC单元、一组三态门、多路选择器(multiplexer, MUX)、截断恢复单元(truncate recovery unit, TRU)和重传恢复单元(retransmission recovery unit, RRU)组成.
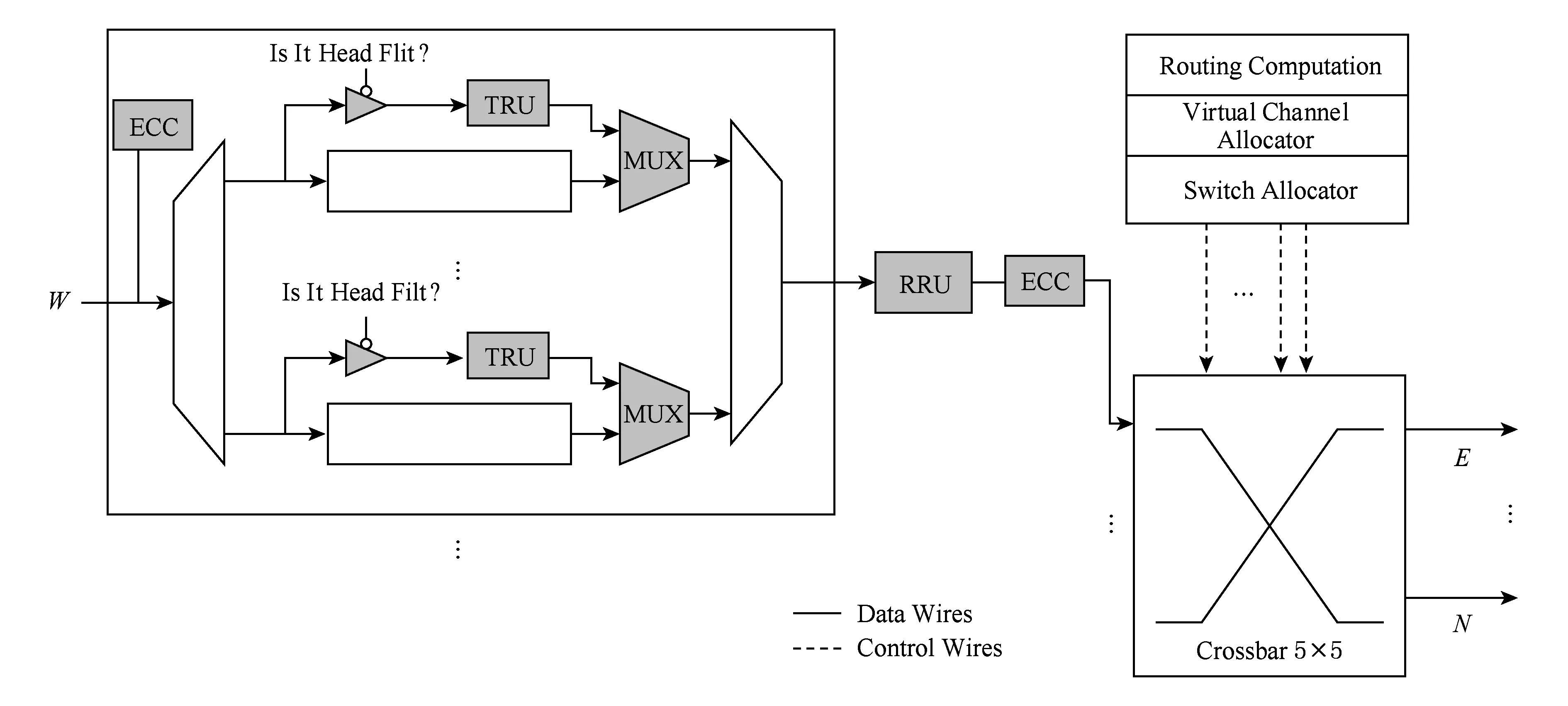
Fig. 3 The proposed fault-tolerant router architecture图3 本文提出的容错路由器结构

Fig. 4 Separated ECC data encoding format图4 分离式ECC数据编码格式
当数据包到达输入端口时,首先根据其虚通道标识(virtual channel identifier,VC_ID)存储到对应的VC当中,然后依次经过RC,VA,SA,交叉开关传输(switch transmission, ST)和链路传输(link transmission, LT)阶段,经过链路路由至下游路由器.相较于传统路由器的流水而言,本文无故障时路由流水没有增加额外的流水周期.
2.2 容错路由器详细设计
2.2.1 分离式ECC检测单元
ECC是通过在原本的数据位上添加校验位来实现的.ECC能够纠正1 b错误发现2 b错误,可以用来对数据包进行编码[20].由图3可以看出,ECC编码模块设置在交叉开关之前,数据经过交叉开关传输之前都要通过ECC编码模块对数据编码.ECC解码检错模块设置在输入端口,每当数据到达输入端口都要经过ECC检错模块进行分析,用于检测数据是否发生错误.
传统ECC编码对于flit的128 b数据而言,需要8 b的冗余校验.然而8 b仅能纠正128 b数据中的1 b数据错误和发现2 b数据错误,当数据位中发生多位错误时,则需要源节点重新发送数据包,增加了整体传输的时间和功耗开销,检测效率低下.
如图4所示为本文提出的分离式ECC数据编码格式,采用交叉编码的方式,同一颜色深度的为同一编码分组.数据出错在不同分组中,具有同时容忍4 b连续数据出错并纠正的能力.本文把128 b数据交叉划分为4组32 b的数据,每组32 b的数据需要6 b冗余校验,每组可纠正1 b错误,则可同时纠正4 b不同分组的数据错误,有更强的容错能力.
2.2.2 RRU
RRU设置在输入端口和交叉开关之间,其内部结构及数据重传容错逻辑如图5所示.RRU内部包括2个flit大小的重传Buffer、一个多路选择器MUX、计数器counter、RRU控制器(RRU controller)和一张VC追踪表(VC_IDtracker table).其中,RRU Controller用于控制MUX的选通输出以及控制信号的发送,Counter1用于计数RRU Controller连续收到NACK信号的次数,VC追踪表保存重传Buffer内数据原始所在的VC_ID,在TRU数据容错时用到.下游路由器中Counter2用于计数ECC Controller连续检测数据出错且不能正确纠正的次数.
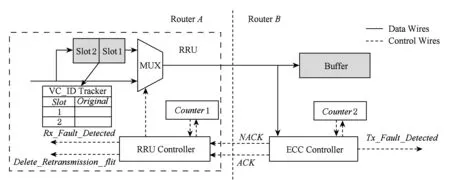
Fig. 5 RRU internal structure and data retransmission recovery logic图5 RRU内部结构及数据重传恢复逻辑
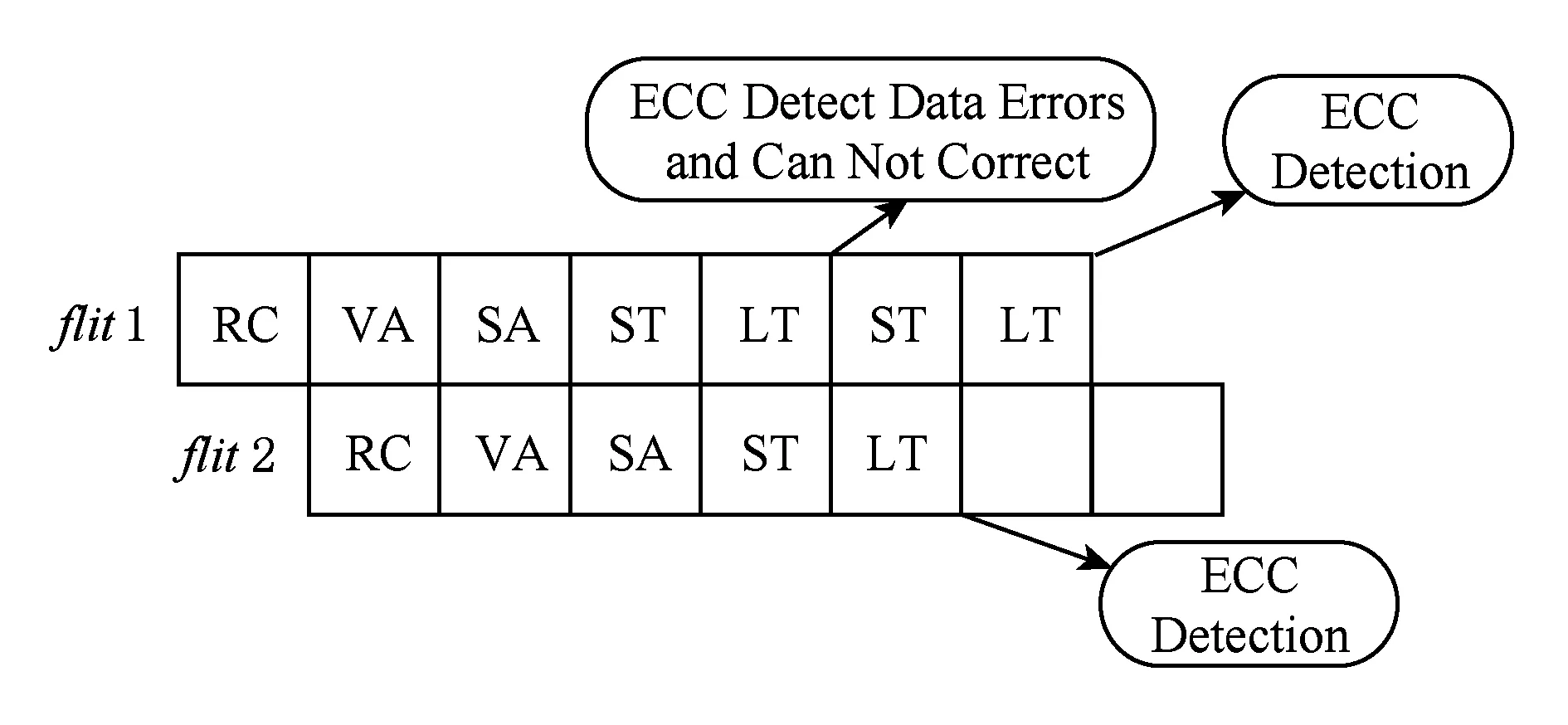
Fig. 6 Data retransmission flow schematic diagram图6 数据重传流水示意图
当下游输入端口ECC模块检测到上游传输的数据发生错误且不能正确纠正时,Counter2+1,并反馈NACK信号给上游,否则反馈ACK信号,告知上游数据传输正确.RRU Controller接收到下游反馈的NACK信号时,Counter1+1,通过控制MUX选通重传Buffer内数据进行传输.
由于RRU设置在输入端口和交叉开关之间,重传机制的数据传输流水如图6所示.数据flit1经过LT传输至下游路由器时,ECC检测数据出错且不能正确纠正,存储上游重传Buffer中的flit1重新经过ST,LT阶段传输.注意到重传的flit1进行ST阶段时,flit2进行LT阶段,即下游路由器在收到重传的flit1之前会收到flit2,为了保证数据包的顺序性,在检测到flit1出错且不能正确纠正后,需要丢弃错误数据flit1和flit2,且无论flit2错误与否均需重传flit2.ECC会依次对flit1,flit2、重传的flit1进行检测.
ECC检测flit2和重传的flit1的4种结果如表1所示,1表示数据出错,0表示数据正确,根据检测结果定义故障类型并进行相应操作.表1中1表示检测到数据出错且不能纠正,0表示数据没有出错或可正确纠正.当出现1或2个flit错误如表中行①~③,可通过重传Buffer重传数据保证数据的正常传输,RRU Controller通过Delete_Retransmission_flit信号删除重传Buffer内正确传输的数据,并将Counter1和Counter2清0.当连续3个flit传输错误且不能正确纠正时,即为表1中行④认为该条链路存在间歇性故障,Counter2阈值达到3,ECC Controller向本地TRU发送Tx_Fault_Detected信号.RRU Controller通过Counter1计数器计数连续收到NACK信号的次数,当达到阈值3时,RRU Controller向TRU发送Rx_Fault_Detected信号.

Table 1 Fault Type Definitions and Corresponding Operation表1 故障类型定义及相应操作
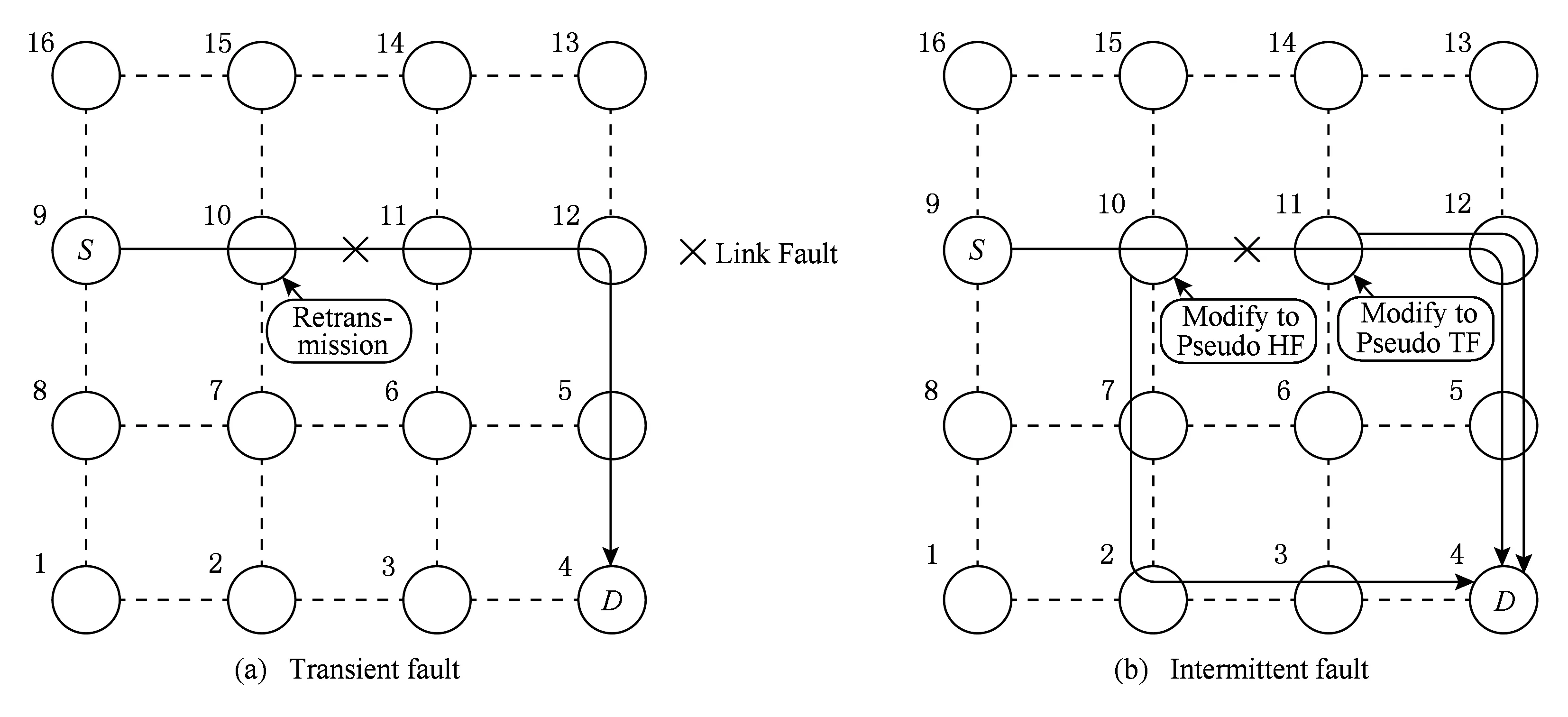
Fig. 8 Fault-tolerant method analysis diagram图8 容错方法分析示意图
2.2.3 TRU
TRU设置在每个VC上,其内部结构及逻辑示意图如图7所示.内部的1-flit Buffer用来存储每个到来数据包的HF,TRU有2条数据通路:伪头flit修改通路Head和伪尾flit修改通路Tail.控制器TRU Controller用来控制数据流的输出.
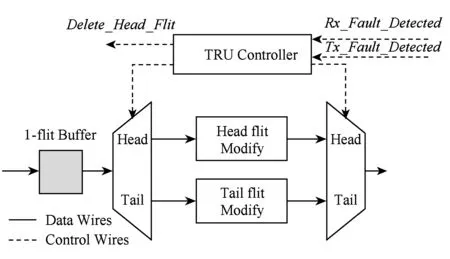
Fig. 7 TRU internal structure and logic图7 TRU内部结构和逻辑
当来自ECC Controller的Tx_Fault_Detected信号有效时,TRU Controller控制选通Tail通路,将存储的头flit经过Tail flit modify修改为伪TF进行传输,释放数据包所占用资源,伪TF传输后TRU Controller通过Delete_Head_Flit信号删除1-flit Buffer内存储的头flit;当来自RRU Controller的Rx_Fault_Detected信号有效时,则选通Head通路,将存储的头flit经过Head flit modify修改为伪HF,将其重新进行路由计算,选择其他可用输出端口进行输出,由于RRU重传Buffer内VC_IDtracker table保存数据的原VC_ID,重传Buffer内数据跟随伪HF进行传输,并根据伪HF修改其VC_ID,故障数据正常传输,实现容错的目的,在一定程度上减轻网络拥塞.
2.2.4 容错方法分析
HF在链路传输时可能会发生错误,当下游路由器检测到HF发生错误且在可纠正范围内,则纠正出错数据位完成正常传输;当HF出错且不能正确纠正,由于上游路由器中重传Buffer中保存有HF,则进行重传,若下游连续3次接收到数据出错,则认为该链路中存在间歇性故障,上游TRU中备份的HF则重新路由.
图8中针对链路中出现的故障情况,对瞬时故障和间歇性故障容错方法进行了分析说明.在4×4mesh网络中,如图8(a)所示,黑色实线为其路由路径,源节点9向目的节点4发送数据包.当数据到达节点11并检测到数据出错,则该链路存在瞬时故障,即存在表1的①情况,在节点10中通过RRU的重传Buffer重新传输,检测重传数据无故障则恢复了正常传输.如图8(b)所示,当在节点11连续检测到数据出错达到3次,则节点10通往节点11的链路存在间歇性故障,此时数据传输被截断.此时进行表1中的④操作,在节点11中TRU把HF修改为伪TF进行资源的释放,在节点10中TRU将HF修改为伪HF重新路由,未传输的数据跟随伪HF重新路由的路径进行传输,如图8(b)中被截断的数据路由如图所示,2部分数据包在目的节点重新组合成一个数据包.
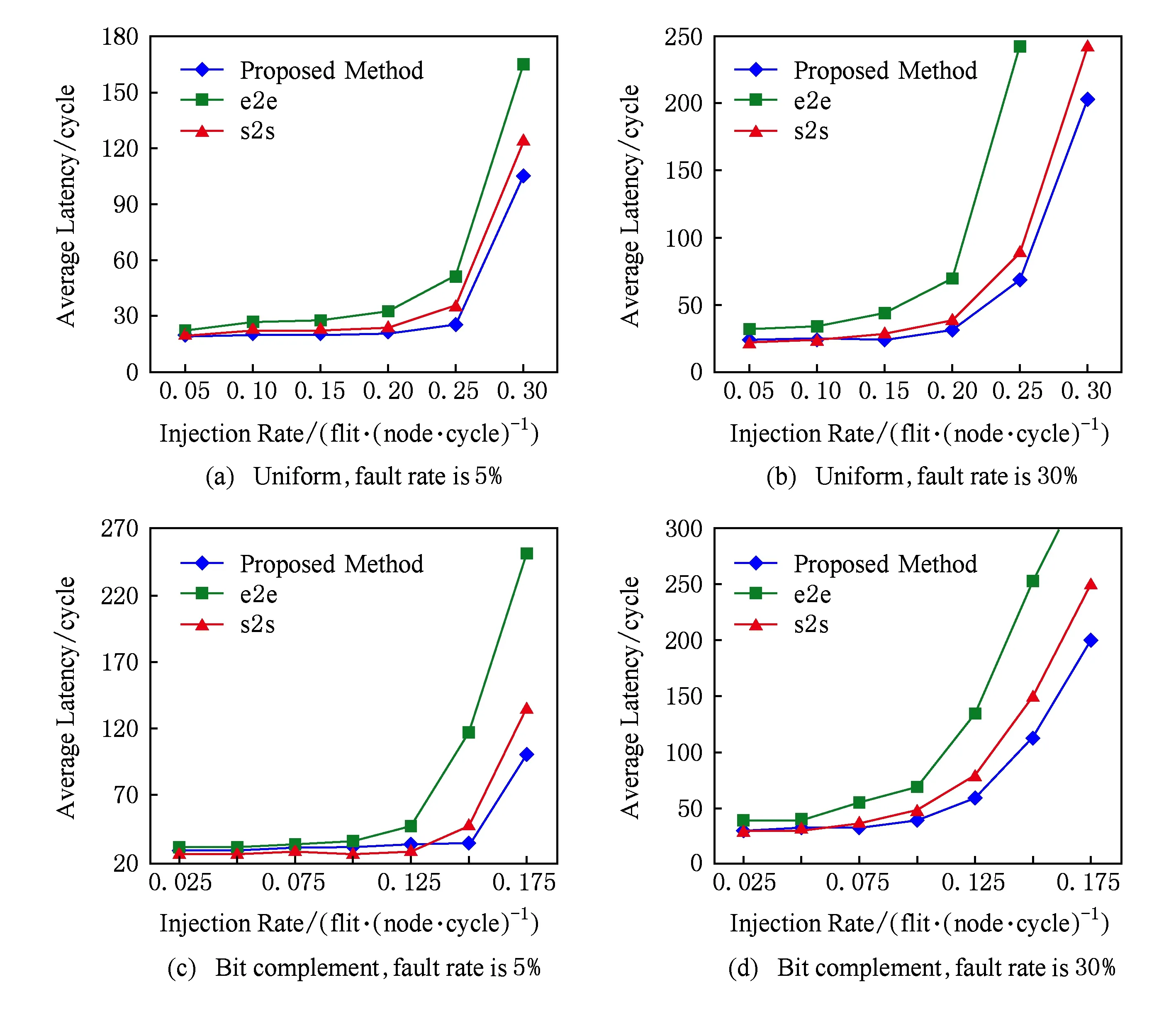
Fig. 9 Average latency of different packet injection rate under transient faults图9 瞬时故障下不同数据包注入率的平均延时比较
3 实 验
本文实验在网络性能、面积开销和功耗3个方面进行展开,其基本参数设定为路由器有E,W,S,N,L这5个端口,每个端口有4个VC,VC的深度为8个flit大小,具体实验结果及分析如下.
3.1 网络性能
NoC中网络性能主要有两大类:延时和吞吐率.实验的仿真工具使用的是Booksim[21]扩展的仿真器,在4×4的2D-Mesh拓扑下对网络的延时和吞吐率做出实验分析,本文假定数据包由本地输入端口进入路由器时不会出错,本文的故障分布仅针对片上网络中路由器间的数据传输链路,不针对本地传输链路.通信模式采用标准模式(uniform)和位补模式(bit complement),采样周期为1 000.瞬时故障对比对象为文献[13]使用的基于ECC的端到端请求重传机制e2e和文献[15]使用的传统基于ECC的跳到跳请求重传机制s2s.间歇性故障对比对象为文献[17]提出的NS-FTR,其划分North-last和South-last这2个子网算法复制数据进行传输,数据包在2个子网内分别进行传输.本文分别对瞬时故障、间歇性故障以及混合故障类型分布下,比较不同容错方案的性能.
图9为在瞬时故障的2种不同模式下不同数据包注入率的平均延时比较.图9(a)(b)为在标准模式的5%和30%故障率下平均延时的比较.可以看出链路发生5%低故障率时,在注入率比较低的时候,本文方案较对比对象优势不明显;随着注入率的增加,e2e和s2s容错能力低的弊端逐渐凸显,本文方案较对比对象优势逐渐凸显.链路发生30%高故障率时,在注入率比较低时,本文方案的延时已明显小于对比对象.在发生故障时,e2e延时会明显高于s2s和本文方法,由于本文采用的分离式ECC编码具有高容错能力,本文方法延时会低于s2s.当注入率为0.2flit/(node·cycle)时,本文方案在5%故障率下,较s2s方案延时降低9.9%,较e2e方案延时降低30.6%;在30%故障率下,较s2s方案延时降低18.6%,较e2e方案延时降低54.4%.图9(c)(d)是在位补模式的5%和30%故障率下平均延时的比较.当注入率为0.125flit/(node·cycle)时,本文方案在5%故障率下较s2s方案延时降低13.0%,较e2e方案延时降低34.3%;在30%故障率下较s2s方案延时降低24.8%,较e2e方案延时降低55.81%.
图10为在瞬时故障的2种不同模式下不同数据包注入率的吞吐率比较.由图10可看出随着注入率的增加,本文方案吞吐率会大于e2e和s2s方案.e2e的重传路径长,占用资源引发拥塞,吞吐率会明显低于本文和s2s,高故障率时尤为明显.本文较s2s提出的分离式ECC编码具有高容错能力,减少了重传,在一定程度上减轻了整体网络拥塞,因此本文吞吐率最高.图10(a)(b)是在均匀模式的5%和30%故障率下吞吐率的比较,当注入率为0.2flit/(node·cycle)时,本文方案在5%故障率下吞吐率较s2s方案吞吐率提高7.6%,较e2e方案吞吐率提高30.7%.在30%故障率下较s2s方案吞吐率提高12.5%,较e2e方案吞吐率提高63.6%.图10(c)(d)是在位补模式的5%和30%故障率下吞吐率的比较,当注入率为0.125flit/(node·cycle)时,本文方案在5%故障率下较s2s方案吞吐率提高11.5%,较e2e方案吞吐率提高33.8%.在30%故障率下较s2s方案吞吐率提高13.9%,较e2e方案吞吐率提高57.9%.
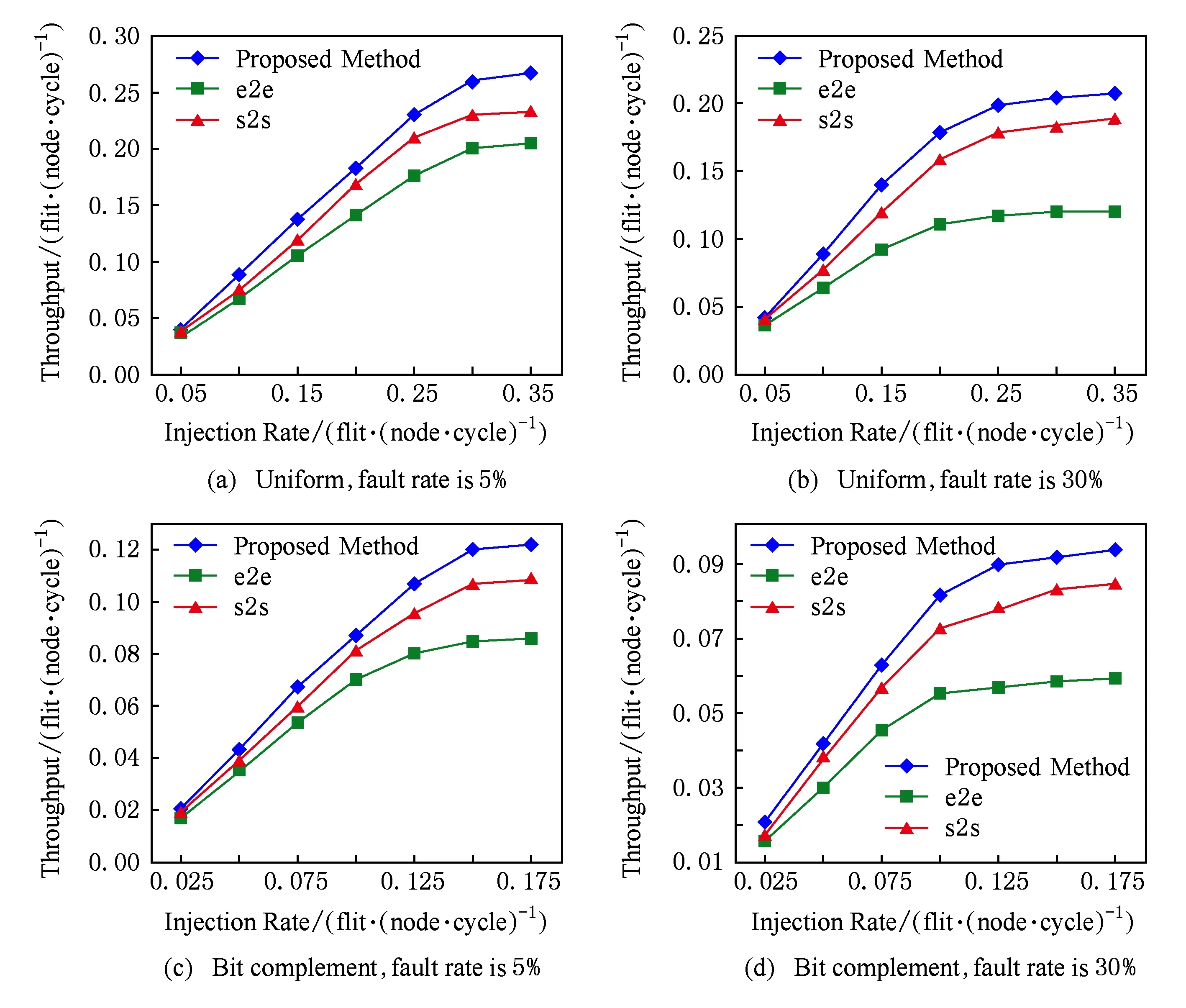
Fig. 10 Throughput of different packet injection rate under transient faults图10 瞬时故障下不同数据包注入率的吞吐率比较
图11为在间歇性故障的2种不同模式下不同数据包注入率的延时比较.图11(a)(b)为在均匀模式的5%和30%故障率下平均延时的比较.链路发生5%低故障率时,在注入率比较低的时候,本文方案延时会稍微高于文献[17]的NS-FTR方法,这是因为在低注入率低故障率下,NS-FTR方法采用的2个子网复制传输数据,传输成功率高.随着注入率的增加,NS-FTR的容错能力趋近饱和,本文方案较对比对象优势逐渐明显.链路发生30%高故障率时,在注入率比较低时,本文方案的延时小于对比对象.主要原因在于:NS-FTR在高故障率的情况下,2个子网的复制传输会占用很大资源,且不能容忍高故障率下的数据出错,整体平均延时会高于本文.当注入率为0.15flit/(node·cycle)时,本文方案在5%故障率下较NS-FTR延时降低2.9%,在30%故障率下较NS-FTR延时降低21.2%.图11(c)(d)是在位补模式的5%和30%故障率下平均延时的比较,当注入率为0.125flit/(node·cycle)时,本文方案在5%故障率下较文献延时降低7.36%,在30%故障率下较文献延时降低50.1%.
图12为在间歇性故障的2种不同模式下不同数据包注入率的吞吐率比较.随着注入率的增加,本文方案吞吐率会大于NS-FTR.NS-FTR采用的2个子网算法复制传输数据,在低注入率低故障率时可以达到不错的效果,随着注入率的增加,子网复制传输的弊端逐渐凸显,2个子网各占用一半的资源,且在高故障率下容错能力很有限,造成网络吞吐率不高.图12(a)(b)是在均匀模式的5%和30%故障率下吞吐率的比较,当注入率为0.2flit/(node·cycle)时,本文方案在5%故障率下吞吐率较NS-FTR吞吐率提高6.9%;在30%故障率下吞吐率提高12.5%.图12(c)(d)是位补模式下在5%和30%故障率下吞吐率的比较,当注入率为0.125flit/(node·cycle)时,本文方案在5%故障率下较NS-FTR吞吐率提高14.1%,在30%故障率下吞吐率提高28.6%.
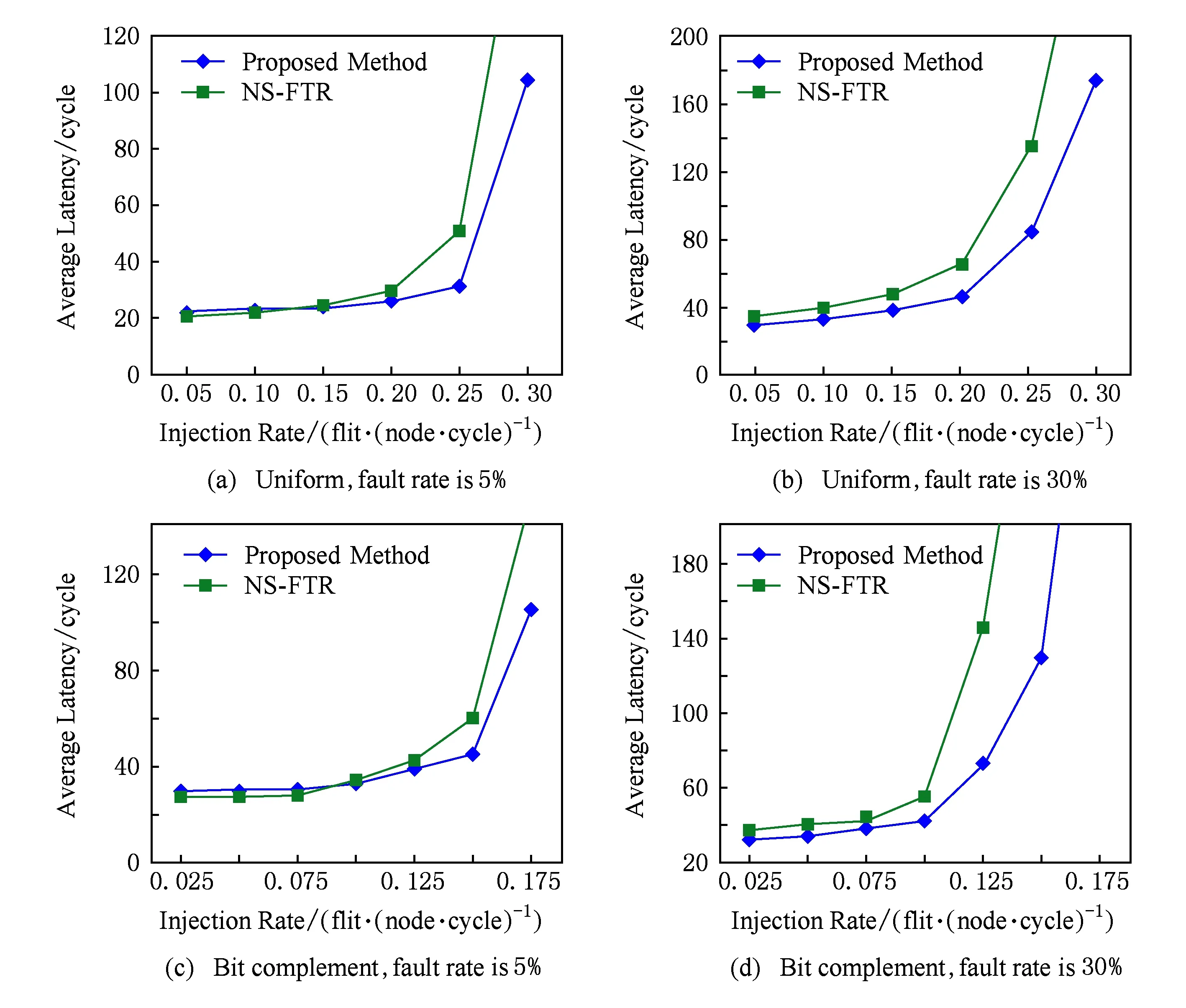
Fig. 11 Average latency of different packet injection rate under intermittent faults图11 间歇性故障下不同数据包注入率的平均延时比较
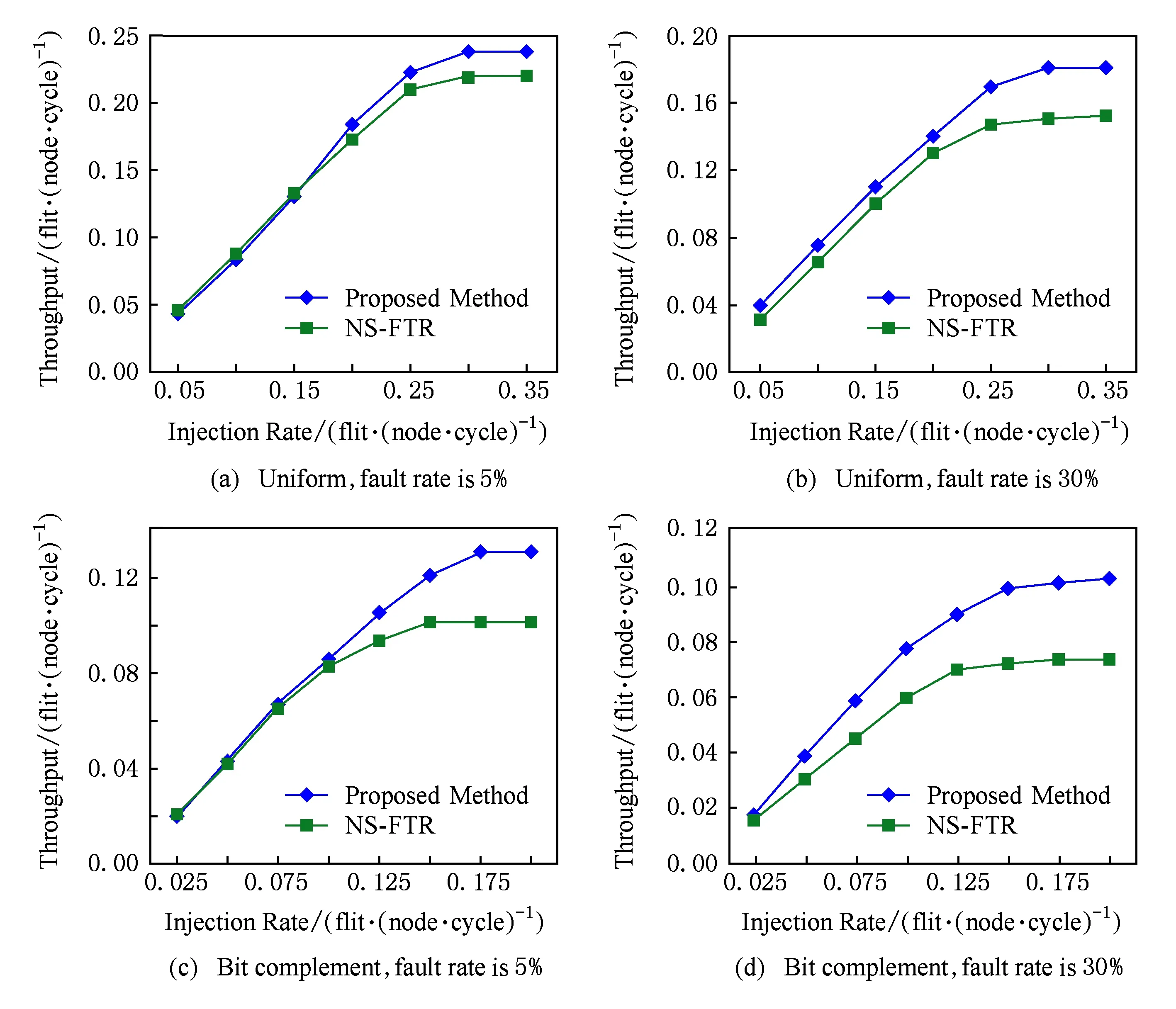
Fig. 12 Throughput of different packet injection rate under intermittent faults图12 间歇性故障下不同数据包注入率的吞吐率比较
图13为在混合故障率的均匀模式下不同数据包注入率的延时比较.由于本文采用的分离式ECC编码的高容错能力,结合重传Buffer和备份的头HF能有效容忍瞬时故障和间歇性故障的发生.e2e,s2s在混合故障下,不能有效容忍间歇性故障的发生,其性能低下;NS-FTR方法的2个子网的传输在故障率较低时可以容忍瞬时故障和间歇性故障的同时发生,但当故障率增大时,其弊端逐渐凸显.当注入率为0.15flit/(node·cycle)时,本文方案在5%混合故障率下较s2s方案延时降低33.3%,较e2e方案延时降低37.1%,较NS-FTR延时降低18.2%;在30%故障率下较s2s方案延时降低38.6%,较e2e方案延时降低50.0%,较NS-FTR延时降低25%.
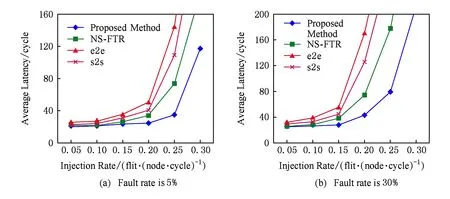
Fig. 13 Average latency of different packet injection rate under mixed faults图13 混合故障下不同数据包注入率的平均延时比较
图14为在混合故障率的均匀模式下不同数据包注入率的吞吐率比较.随着注入率的增加,本文方案吞吐率大于e2e,s2s,NS-FTR.图14(a)中,当注入率为0.15flit/(node·cycle)时,本文方案在5%故障率下较s2s方案吞吐率提高21.4%,较e2e方案提高36.2%,较NS-FTR提高6.8%.图14(b)中,在30%故障率下较s2s方案吞吐率提高38.9%,较e2e方案提高56.3%,较NS-FTR提高25%.
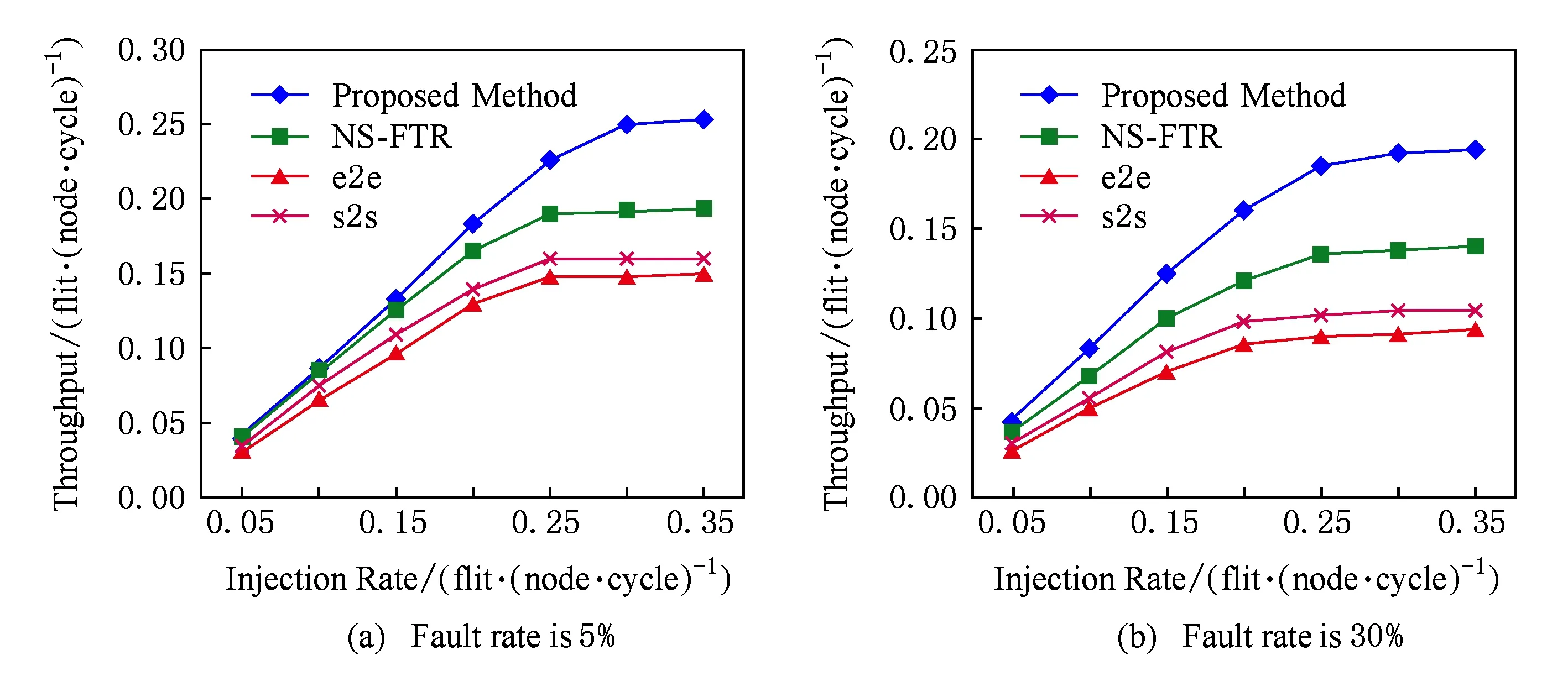
Fig. 14 Throughput of different packet injection rate under mixed faults图14 混合故障下不同数据包注入率的吞吐率比较
3.2 面积开销及功耗
本文使用Synopsis Design Compiler在45nm工艺下,对比本文设计路由器与基准路由器、e2e路由器、s2s路由器的面积和功耗进行了仿真,其中设置对比路由器中重传Buffer数目一致.实验结果如表2所示:
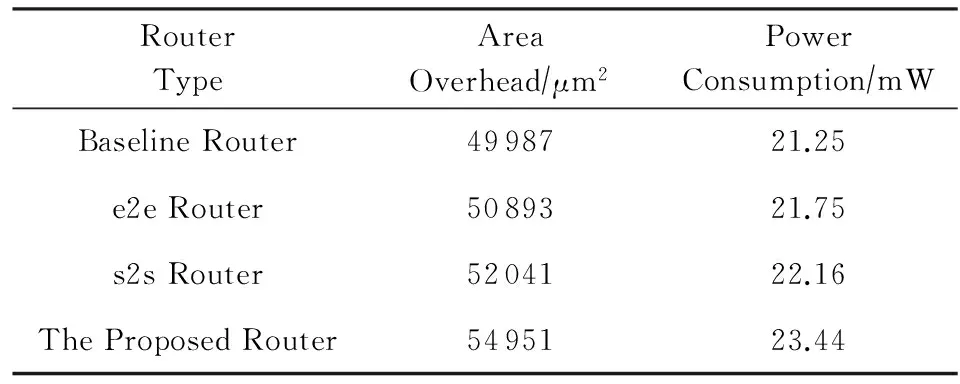
Table 2 The Router Area Overhead and Power Consumption表2 路由器面积和功耗开销
数据表明,本文方案路由器面积较基准路由器约增加9.9%,较e2e路由器约增加8.0%,较s2s路由器约增加5.6%.本文结合参考文献瞬时故障容错和间歇性故障容错的优势,并在此基础上加以改进,容错部分增加的ECC,TRU,RRU会使面积有所增加.本文方案较基准路由器功耗约增加10.3%,较e2e路由器功耗约增加7.8%,较s2s路由器功耗约增加5.8%.这是因为本文方案路由器在基准路由器基础上增加了容错模块,会使功耗有所增加.在发生故障时,考虑本文方案在延时和吞吐率上的良好表现,增加的面积开销和功耗也是可以接受的.
4 结束语
本文针对路由器链路瞬时故障和间歇性故障,设计了一种高容错能力的分离式ECC编码,并在此基础上提出了一种针对瞬时故障和间歇性故障的高可靠链路容错方法.该方法根据链路瞬时故障和间歇性故障发生持续时间的特性,依情况进行容错.重传Buffer结合分离式ECC编码能有效地容忍瞬时故障,对于间歇性故障,保存头flit修改成头flit或尾flit,减轻网络拥塞,平衡网络负载,能有效地减轻故障对网络性能的影响.实验结果表明:本文在仅增加可接受的面积开销和功耗的前提下,在发生故障时,能有效地减轻故障对网络性能的影响,具有很好的容错效果,保障了系统可靠性.
[1]Dally W J, Towles B. Route packets, not wires: On-chip interconnection networks[C] //Proc of the 38th Int Conf on Design Automation. Piscataway, NJ: IEEE, 2001: 684-689
[2]Ouyang Yiming, Zhang Yidong, Liang Huaguo, et al. Design of fault-tolerant router for 3D NoC based on virtual channel fault granularity partition[J]. Journal of Computer Research and Development, 2014, 51(9): 1993-2002 (in Chinese)(欧阳一鸣, 张一栋, 梁华国, 等. 基于虚通道故障粒度划分的3D NoC容错路由器设计[J]. 计算机研究与发展, 2014, 51(9): 1993-2002)
[3]Ouyang Yiming, Chen Yijun, Liang Huaguo, et al. Design of a low-overhead fault channel isolated fault-tolerant router[J]. Acta Electronica Sinca, 2014, 42(11): 2142-2149 (in Chinese)(欧阳一鸣, 陈义军, 梁华国, 等. 一种故障通道隔离的低开销容错路由器设计[J]. 电子学报, 2014, 42(11): 2142-2149)
[4]Wang Xinyu, Xiang Dong, Yu Zhigang. TM: A new topology for networks-on-chip[J]. Chinese Journal of Computers, 2014, 37(11): 2327-2341 (in Chinese)(王新玉, 向东, 虞志刚. TM: 一种新的片上网络拓扑结构[J]. 计算机学报, 2014, 37(11): 2327-2341)
[5]Ganguly A, Pande P P, Belzer B. Crosstalk-aware channel coding schemes for energy efficient and reliable NOC interconnects[J]. IEEE Trans on Very Large Scale Integration Systems, 2009, 17(11): 1626-1639
[6]Feng Chaochao, Zhang Minxuan, Li Jinwen, et al. A fault-tolerant deflection router with reconfigurable bidirectional link for NoC[J]. Journal of Computer Research and Development, 2015, 52(2): 454-463 (in Chinese)(冯超超, 张民选, 李晋文, 等. 一种可配置双向链路的片上网络容错偏转路由器[J]. 计算机研究与发展, 2015, 52(2): 454-463)
[7]Dimopoulos M, Gang Y, Anghel L, et al. Fault-tolerant adaptive routing under an unconstrained set of node and link failures for many-core systems-on-chip[J]. Microprocessors and Microsystems, 2014, 38(6): 620-635
[8]Constantinescu C. Trends and challenges in VLSI circuit reliability[J]. IEEE Micro, 2003 (4): 14-19
[9]Fu Binzhang, Han Yinhe, Li Huawei, et al. Building resilient NoC with a reconfigurable routing algorithm[J]. Journal of Computer-Aided Design & Computer Graphics, 2011, 23(3): 448-455 (in Chinese)(付斌章, 韩银和, 李华伟, 等. 面向高可靠片上网络通信的可重构路由算法[J]. 计算机辅助设计与图形学学报, 2011, 23(3): 448-455)
[10]Ouyang Yiming, Wang Qiao, Liang Huaguo, et al. A link adaptive fault-tolerant method based on fault granularity partition in NoC[J]. Journal of Electronic Measurement and Instrumentation, 2015, 29(8): 1102-1113 (in Chinese)(欧阳一鸣, 王悄, 梁华国, 等. 基于故障粒度划分的 NoC 链路自适应容错方法[J]. 电子测量与仪器学报, 2015, 29(8): 1102-1113)
[11]Benini L, De Micheli G. Networks on chips: A new SoC paradigm[J]. Computer, 2002, 35(1): 70-78
[12]Pirretti M, Link G M, Brooks R R, et al. Fault tolerant algorithms for network-on-chip interconnect[C] //Proc of the 2014 IEEE Computer Society Annual Symp on VLSI. Piscataway, NJ: IEEE, 2004: 46-51
[13]Schley G, Batzolis N, Radetzki M. Fault Localizing end-to-end flow control protocol for networks-on-chip[C] //Proc of the 21st Euromicro Int Conf on Parallel, Distributed and Network-Based Processing. Piscataway, NJ: IEEE, 2013: 454-461
[14]Murali S, Theocharides T, Vijaykrishnan N, et al. Analysis of error recovery schemes for networks on chips[J]. IEEE Design & Test of Computers, 2005, 22(5): 434-442
[15]Feng Chaochao, Lu Zhonghai, Axel J, et al. Addressing transient and permanent faults in NoC with efficient fault-tolerant deflection router[J]. IEEE Trans on Very Large Scale Integration Systems, 2013, 21(6): 1053-1066
[16]Gil-Tomás D, Gracia-Moran J, Baraza-Calvo J C, et al. Analyzing the impact of intermittent faults on microprocessors applying fault injection[J]. IEEE Design & Test of Computers, 2012, 29(6): 66-73
[17]Pasricha S, Zou Y. NS-FTR: A fault tolerant routing scheme for networks on chip with permanent and runtime intermittent faults[C] //Proc of the 16th Asia and South Pacific Conf on Design Automation. Piscataway, NJ: IEEE, 2011: 443-448
[18]Zhang Ying, Li Huawei, Li Xiaowei. Selected crosstalk avoidance code for reliable network-on-chip[J]. Journal of Computer Science and Technology, 2009, 24(6): 1074-1085
[19]Behrouz R J, Modarressi M. A reconfigurable fault-tolerant routing algorithm to optimize the network-on-chip performance and latency in presence of intermittent and permanent faults[C] //Proc of the 29th Int Conf on Computer Design. Piscataway, NJ: IEEE, 2011: 433-434
[20]Zimmer H, Jantsch A. A fault model notation and error-control scheme for switch-to-switch buses in a network-on-chip[C] //Proc of the 1st IEEE/ACM/IFIP Int Conf on Hardware/Software Codesign and System Synthesis. New York: ACM, 2003: 188-193
[21]Jiang N, Michelogiannakis G, Becker D, et al. Booksim interconnection network simulator[OL]. (2010-09-11)[2012-06-05]. https://nocs.stanford.edu/cgibin/trac.cgi/wiki/Resources/BookSim
Addressing Transient and Intermittent Link Faults in NoC with Fault-Tolerant Method
Ouyang Yiming1, Sun Chenglong1, Li Jianhua1, Liang Huaguo2, Huang Zhengfeng2, and Du Gaoming2
1(School of Computer and Information, Hefei University of Technology, Hefei 230009)2(School of Electronic Science and Applied Physics, Hefei University of Technology, Hefei 230009)
As the link is the critical path between routers in NoC,it will seriously affect the network performance when faults occur in the link. For this reason, we propose a high reliable fault-tolerant method addressing transient and intermittent link faults. The method can detect real-time data error occurring in the network, and then define that whether the fault is transient fault or intermittent fault, thereby realizing fault-tolerance. As a result, it not only alleviates the network congestion and decreases the data delay, but also ensures the correct transmission of data, effectively guaranteeing the high reliability of the system. It is well known that when a transient fault occurs in the link, the fault link will result in a data error, which cannot be corrected properly. Therefore, the proposed method set up the retransmission buffer and then the backup data will be retransmitted. If an intermittent fault occurs, the packet transmission is truncated. To solve this problem, the proposed method adds a pseudo head flit and a pseudo tail flit to the truncated data, then re-routing begins and the occupied resource is released. Experimental results show that, in different fault conditions, this method outperforms the comparison objects with significant reduction in average packet latency and obvious improvement in throughput. In a word, this scheme can effectively improve network reliability in addition to ensuring network performance.
network-on-chip (NoC); transient fault; intermittent fault; fault-tolerant; retransmission; reliable

Ouyang Yiming, born in 1963. PhD and professor. Senior member of CCF. His main research interests include the network on chip (NoC) and system on chip (SoC), embedded systems integrated and testing, digital system design automation.

Sun Chenglong, born in 1993. Master candidate. His main research interests include the methods of fault-tolerant network on chip.

Li Jianhua, born in 1985. Lecturer. His main research interests include computer system architecture, non-volatile memory, network on chip and near data computation.

Liang Huaguo, born in 1961. Professor and PhD supervisor. Senior member of CCF. His main research interests include embedded system integration and testing, digital system design automation, ATPG algorithms and distributed control.

Huang Zhengfeng, born in 1978. Associate professor. His main research interests include embedded system integration and testing, hardware fault tolerance of digital integrated circuits and anti radiation hardening of spaceborne SoC chip.

Du Gaoming, born in 1977. PhD and associate professor. His main research interests include multi-core architecture, performance evaluation and fault-tolerant design for 2D/3D network-on-chip.
2015-12-01;
2016-10-20
国家自然科学基金项目(61474036,61274036,61371025,61574052);国家自然科学基金青年科学基金项目(61402145);安徽省自然科学基金青年基金项目(1508085QF138);安徽省自然科学基金项目(1508085MF117) This work was supported by the National Natural Science Foundation of China (61474036, 61274036, 61371025, 61574052), the National Natural Science Foundation for Young Scholars of China (61402145), the Natural Science Foundation for Young Scholars of Anhui Province of China (1508085QF138), and the Natural Science Foundation of Anhui Province of China (1508085MF117).
孙成龙(18256910706@163. com)
TP302
猜你喜欢
科教新报(2022年24期)2022-07-08
现代电子技术(2022年9期)2022-05-12
作文小学中年级(2021年10期)2021-12-26
云南民族大学学报(自然科学版)(2021年4期)2021-09-11
科教新报(2021年23期)2021-07-21
防爆电机(2021年2期)2021-06-09
恋爱婚姻家庭·养生版(2021年5期)2021-05-31
浙江工业大学学报(2019年2期)2019-03-19
计算机与数字工程(2018年9期)2018-09-28
中国交通信息化(2017年4期)2017-06-06
