
一种正交分解大数据处理系统设计方法及实现
2017-05-13 03:44向小佳赵晓芳龚关俊
计算机研究与发展 2017年5期
向小佳 赵晓芳 刘 洋 龚关俊 张 晗
1(中国科学院计算技术研究所 北京 100190)2 (北方工业大学计算机学院 北京 100144) (xiangxiaojia@ncic.ac.cn)
一种正交分解大数据处理系统设计方法及实现
向小佳1赵晓芳1刘 洋1龚关俊1张 晗2
1(中国科学院计算技术研究所 北京 100190)2(北方工业大学计算机学院 北京 100144) (xiangxiaojia@ncic.ac.cn)
MapReduce等计算框架的出现开启了大数据处理新纪元,以Hadoop,Spark为代表的大数据处理系统具有大吞吐率、跨平台、高可扩展的优势,并得到广泛应用.然而,为避免与具体的操作系统、硬件平台绑定,这些系统的设计与优化集中在计算模型、调度算法等方面,无法充分利用底层平台的优势.提出了一种基于正交分解的大数据处理系统设计与优化方法,将系统分解为松耦合的多个功能正交的模块,使存储、处理功能分离出来,交给能够利用底层平台操作系统甚至硬件资源的存储、执行引擎,原大数据系统退化为调度平台;进而,提出基于锁无关机制的存储底层优化策略和基于指令超级优化的执行引擎底层优化策略.以此为指导,以Hadoop作为兼容和改进的对象,实现了原型大数据处理系统Arion.Arion既能保持Hadoop的跨平台、高可扩展的优势,又能消除任务执行的瓶颈,其本地化的设计与优化手段对非Hadoop平台同样有效.通过在原型系统上的实验证明,Arion能够提升大数据处理任务的执行效率,最高达7.7%.
大数据处理系统;计算框架;本地化;锁无关;超级优化;执行引擎
网络大数据的复杂性、不确定性、涌现性[1]给当前IT系统的架构、计算能力带来了挑战和机遇,催生了大数据处理框架.围绕着这些计算框架,诞生了各种大数据处理系统.例如用于批量大数据处理的Google GFS与MapReduce[2],Nokia的Disco[3]、面向流式处理的Google Dremel[4],Microsoft的Dryad[5],Twitter的Storm[6],Yahoo的S4[7]等,学术界和开源社区也围绕着面向批量大数据处理的Apache Hadoop、基于Hadoop的更具实时性的Impala*Cloudera Impala. https://github.com/cloudera/impala、伯克利AMP Lab的基于RDD[8]的、面向工作集迭代应用的Spark[9]展开了深入研究,国内的互联网巨头百度、阿里、腾讯等也在Hadoop等系统上部署了应用.
各类系统面向不同的应用,设计有针对性的计算模型、调度算法、数据结构,从而不断演进.如Dremel,Storm等流式处理模型,相对于Hadoop,更适合海量流数据的即时查询;而Spark则针对MapReduce模型不擅长的迭代处理和交互应用,提出了RDD内存数据集及相关迭代模型;Hadoop自身的计算框架由原本单一的MapReduce演化出了基于有向无环图(directed acyclic graph, DAG)的更为灵活的Tez*Apache Tez. http://incubator.apache.org/projects/tez.html;Hadoop自身的调度系统也从单一的全局任务调度发展到了新一代的Yarn[10],分离了JobTracker的资源管理与任务调度功能.
然而,由于大数据处理系统规模大,强调平台无关性,避免与具体的操作系统、硬件平台挂钩,上述系统的演进都忽视了对底层平台技术的利用.Intel中国研究院的NativeTask[11]通过设计外挂的计算引擎模块,将部分Hadoop计算引擎内部的计算外延到Java虚拟机之外,取得了一定的本地化效果,思想值得借鉴,但还未充分发挥存储结点、计算结点本地操作系统、硬件平台的潜力.国内的百度公司也提出了Hadoop的C++扩展*Hadoop C++ Extension: A Framework for Making MapReduce More Stable and Faster. http://wenku.baidu.com/view/1859f988d0d233d4b14e69c8.html,通过使用类似Pipe的协议将Map和Reduce两阶段的Java执行逻辑替换为C++编写并预编译好的二进制可执行文件,向本地化迈进了一步,但其失去了中间逻辑表示的灵活性,同时本地化仅限于Map和Reduce的用户逻辑,没有考虑通用中间处理环节的本地化,也没有深度挖掘代码的优化空间.
我们首先提出一种基于正交分解的大数据处理系统设计与优化方法,主张大数据处理系统的设计应采用松耦合架构,能明确区分出功能正交的调度管理、数据存储、任务执行三大功能模块;与任务逻辑紧相关的数据存储与任务执行应下沉到具体的硬件平台去完成,大数据系统只负责最核心的资源与任务调度.进而,在此方法的指导下,我们提出了基于锁无关机制的存储底层优化策略,以及基于二进制指令超级优化的执行引擎底层优化策略.前者利用存储结点操作系统的原语,构造锁无关数据结构(lock free data structure)作为构造共享存储的基石;后者基于大数据系统的应用针对性,采用超级优化(super optimization)方法,在执行逻辑中间表达或二进制代码层面作离线静态分析,利用编译技术来发挥底层平台潜力.
基于上述技术,以Hadoop作为兼容和改进的对象,我们实现了原型大数据处理系统Arion.Arion采用了松耦合的方式,将Hadoop的任务调度与存储、计算引擎拆分开,通过通信协议连接;数据存储下沉到ArionFS,这是一个采用C语言实现的大数据分布式文件系统,其中实现了基于锁无关(lock free, LF)结构的元数据存储,以及基于状态机的文件数据锁无关共享读写协议;任务执行则下沉到基于LLVM[12]的本地化执行引擎,能够在代码中间表示(IR)层面或二进制代码层面采用类似窥孔(peep-hole)这样的超级优化方法,提升执行引擎效率.
1 方法与设计
1.1 基于正交分解的大数据处理系统设计与优化方法
基于正交分解的设计优化方法原则有4点:
1) 大数据处理系统的设计应能明确区分出调度管理、数据存储、任务执行三大正交功能模块;
2) 各功能模块松耦合,由类RPC通信协议互联;
3) 大数据系统只负责最核心的资源与任务管理,工作于中间层,与平台、语言无关;
4) 与任务逻辑紧相关的两大功能模块,数据存储与任务执行,应外包到具体的硬件平台去完成,且应平台相关,以期充分发挥平台潜力.
平台相关是指利用物理节点的操作系统、硬件机制来设计与优化,与平台底层软硬件紧耦合.优点是能够充分利用平台资源,挖掘其潜力;缺点是某一平台的优化成果,如优化二进制代码,不能无缝迁移到其他平台;但这并不影响整个系统的平台无关性与可扩展性,这是由第3点原则保证的.
进而,我们提出了2条平台相关优化设计策略:
1) 基于锁无关机制的存储底层优化策略.利用存储结点操作系统的原语,构造锁无关数据结构作为元数据共享存储的基石;进而可将锁无关机制扩展到文件数据的访问流程中.
2) 基于指令超级优化的执行引擎底层优化策略.大数据系统有应用针对性,平台执行引擎中的计算也具备一定的模式,有规律可寻,因此可采用超级优化的方法,在执行逻辑中间表示或二进制硬件指令层面作离线静态分析,提取优化指令序列,创建优化数据库,采用一次写入多次读取(write once read multi-time, WORM)模式,利用编译技术来挖掘底层平台的潜力.
1.2 Arion整体架构设计
Arion以Hadoop作为兼容和改进的对象,将数据存储、任务执行与调度管理分离;以Hadoop pipe*Hadoop Pipes. http://www-01.ibm.com/support/knowledgecenter/SSGSMK_6.1.1/mapreduce_integration/map_reduce_hadoop_pipes.dita为基础,使用C语言扩充了一套功能模块间的通信协议;任务的调度管理工作于中间层,采用LLVM的中间表示语言IR作为任务执行逻辑的载体,与具体底层平台、语言无关;数据存储下沉到全C语言实现的分布式文件系统ArionFS,支持锁无关元数据与数据访问;任务执行则下沉到基于LLVM的本地化执行引擎,能够在代码中间表示(IR)层面或二进制代码层面采用超级优化方法,提升执行引擎效率.
图1为Arion的整体框架图.一个高级语言(例如C++)书写的MapReduce大数据处理程序的处理过程如下:1)该程序作为输入,通过编译前端(例如Clang*Clang: A C Language family frontend for LLVM. http://clang.llvm.org)编译后转变为中间表达IR文件;接下来,中间表达被提交给大数据处理框架,例如Hadoop,Hadoop会根据框架的定义生成大数据处理任务,交给JobTracker调度,具体工作派发给任务执行代理Task Tracker,而IR文件则通过Hadoop上传到大数据存储文件系统ArionFS中;2)任务执行代理通过类RPC的通讯协议ArionPipe与本地化执行引擎通信,后者会根据指令从ArionFS中获取IR文件,从预编译的函数库中抽取本次处理会使用的连接件(见第2节),并将它们组装起来;3)LLVM本地执行引擎执行上述组装好的任务,起始阶段会通过连接件reader从ArionFS读取需要处理的数据子集Split,结束阶段通过writer向ArionFS回写处理结果.
图1中最上部虚线框中部分为退化Hadoop,主要负责调度管理,数据存储与任务执行的功能被拆分出去;外部存储通过加载ArionFS的函数库接入,通信协议为ArionFS的基于状态机的锁无关共享读写协议(见2.3.2节);外部任务的控制与状态反馈则由Task Tracker任务执行代理接入,通信采用ArionPipe协议.
图1的中部为基于LLVM的任务执行引擎及其适配层.执行引擎中,SuperOptimization指令级加速引擎依赖平台技术和编译超级优化技术,挖掘优化代码片段,提升引擎效率;Pass Manager为LLVM的编译阶段管理结构;即时编译(just in time, JIT)引擎为代码执行的核心.适配层为针对框架(Hadoop)所编写的便于大数据处理工作流无缝衔接的通用代码库,一般会被预编译成JIT引擎可以执行的二进制代码,或易于发布的IR形式,并于任务执行时按需动态加载.这些框架相关的大数据处理通用代码在Arion中按功能封装为类,后文称之为连接件,典型连接件如用于Map和Reduce阶段衔接的通用Partitioner.
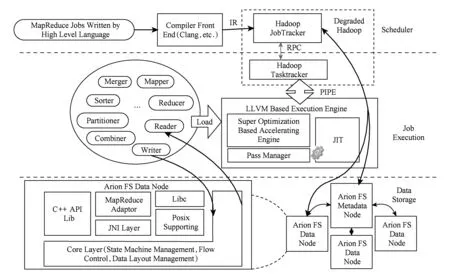
Fig. 1 Arion architecture图1 Arion框架图
存储如图1的底层,即数据管理层.该层为全C语言实现的锁无关大数据文件系统Arion FS.采用锁无关机制可以有效解决数据访问过程中的冲突,提高并发性.锁无关机制包括基于OS原语的锁无关元数据和基于状态机的数据锁无关读写协议两部分.
数据管理层左部为ArionFS软件模块堆栈,底部为核心层,上部为接口层.核心层封装了文件系统的名字空间布局管理(layout)、流管理、状态机管理等功能,能够直接调用OS本地系统调用,Libc函数库;接口层高度模块化,支持标准的Posix文件访问协议及其上的Libc函数库,同时提供二次开发用C/C++ API和Java API,其中Posix相关模块在内核实现.
综上,Arion采用面向平台的本地化设计方法,对Hadoop做了正交化分解,形成了专职调度管理的退化版大数据框架、基于LLVM的任务执行引擎以及大数据存储ArionFS的三大松耦合模块架构.
1.3 数据存储底层优化
分布式文件系统作为共享大数据的载体,其上的数据访问具有高并发的特点.为了利用底层优化技术来应对海量高并发的负载,我们采用全C语言实现了一个原型大数据分布式文件系统ArionFS,其特点是:1)C语言实现,能够直接利用操作系统的底层函数库和资源.2)充分利用Lock Free结构.文件系统的元数据存储采用Lock Free的Hash Table,能够直接利用操作系统原语和数据结构设计来解决热点元数据的并发访问冲突,避免死锁等问题;文件系统的海量数据访问采用基于状态机的锁无关读写协议,解决并发访问冲突,提高并发性.
ArionFS不支持类似HDFS的多副本流水线技术,其高可靠机制目前在卷、块设备这一层级实现.
文件系统的元数据存储采用了锁无关Hash表(lock free Hash table, LFHT),支持对元数据条目查询、插入、删除,这里的元数据主要是DENTRY条目(后文简称条目),用来存储文件名与具体数据分布等属性的映射关系.相对于基于锁的并发元数据访问,实现锁无关Hash表有3个特点:
1) 碰撞Hash值的条目置于同一Hash桶中,Hash桶组织为链表结构,基于CAS(比较与交换)原语来解决读写冲突;
2) 基于Pin来标识条目的所有权,支持批量删除(Pin是一种所有权声明工具,用来声明对资源的占有,控制对资源的回收,以免出现一致性问题);
3) 不同Hash桶采用动态分配队列(dynamic allocated array)来组织,访问文件条目速度为LogN,且空间动态分配删除,节省存储资源.
文件系统的数据访问采用了基于状态机的锁无关读写协议,取消了共享文件并发访问时的锁操作(file lock).数据的锁无关读写是基于CAS的锁无关算法在状态机层面的扩展.ArionFS中,客户端与服务器端都有各自的运行时状态机.每个状态代表一个执行阶段,伴随着一段文件访问的执行逻辑,逻辑执行的结果是事件,事件会触发状态机跳向下一状态或者下一个子状态机,循环往复.这里的状态机可以类比于CPU,每个状态所封装的执行逻辑类比于指令,因此,对ArionFS的客户端和服务器端而言,状态所封装的执行逻辑是原子的,这是在状态机层面实现类CAS原语的前提.
锁无关读写流程如图2所示,图2中通信的三方包括分布式文件系统的元数据服务器、客户端、数据服务器.读写由客户端发起,执行过程如左部的客户端IO子状态机所示:①客户端首先进入初始化状态;②根据要访问的文件名或ID向元数据服务器发消息以获得相应文件的分布等信息;③检查文件属性、访问权限;④初始化代表访问请求的消息;⑤通过专用信道向数据服务器发送代表访问请求的消息,并等待回复;若回复为数据访问成功,则接收返回数据或结果,并提交给下一状态;否则根据一定策略,选择重试或者放弃;⑥检查返回结果;⑦如状态机执行过程中发生故障,检查IO错误,处理并退出子状态机.
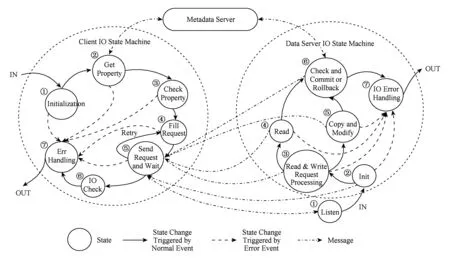
Fig. 2 Lock free IO state machine for data reading and writing图2 文件数据锁无关读写状态机
数据服务器端的IO子状态机如图2右半部所示,其执行过程是:
1) 主状态机执行监听任务,等待各个客户端的访问请求,一旦接收到请求消息,转入IO子状态机;
2) 初始化状态机,初始化相关数据结构,启动流处理机制;
3) 分析请求类型,如果是读请求,派送给“读IO”状态;如果是写请求,派送给“拷贝并修改”状态;
4) 读IO状态中,执行读取操作,并将结果以消息的形式发送给客户端;
5) 拷贝并修改状态,数据会被拷贝出来1份,形成新版本,并按照写请求来进行更新;
6) “结果检查并提交或退出”状态是原子的,对于读请求结果检查总是成功,对于写请求,该状态执行逻辑会检查数据的版本,确认数据没有被服务器的其它并发线程修改过,确认结果为真则提交修改并通知元数据服务器,确认结果为假则修改作废并通知客户端;
7) 如状态机执行过程中发生故障,检查IO错误,处理并退出子状态机.
1.4 任务执行底层优化
大数据平台具有应用针对性,平台执行引擎中的计算也具备一定的模式,计算的规律性使得我们可以利用线下耗时的SuperOptimizaion编译优化技术来构建具有应用针对性的优化执行引擎,从指令级别去加速计算.图3所示为指令级加速引擎的框图.
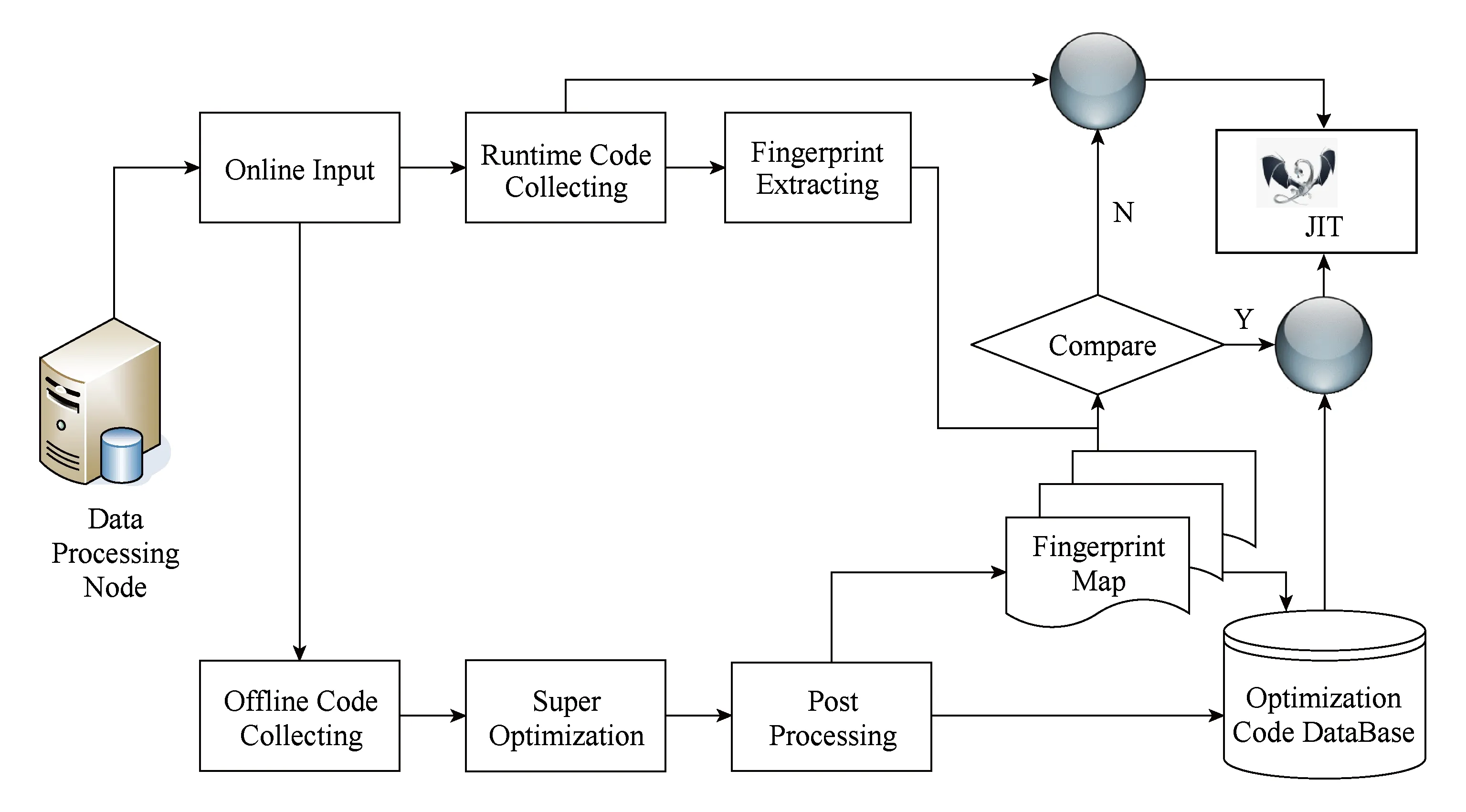
Fig. 3 Super optimization based execution engine framework图3 Super Optimization指令级加速引擎框图
图3中部为执行引擎使用的辅助存储:优化代码数据库和指纹Map.首先,引擎的优化以基本块(basic block)为单位,即程序中可连续执行的指令序列的集合.代码优化数据库用来存放优化过后的基本块;指纹Map则记录了基本块的Hash值与数据块存放地址间的映射关系.
图3下部为学习流程,功能模块依序为离线采集模块、超级优化模块、后处理模块.采集模块以Basic Block,即程序中可连续执行的指令序列集合,为单位,结合部分启发式的规则,来预先选取值得进一步优化的程序段.被选中的基本块进一步被各个优化模块处理.目前的原型实现中包括3种优化:常量合并(constant fold)、无用变量消除(unused variable suppression)、子表达式提取(sub expression extrac-tion).这些优化在其他工程中,如GCC,都是比较成熟的技术,我们这里优化的特点是:1)2阶段,不仅在LLVM的中间表示(IR)阶段作优化,而且在平台选择后,执行Target-Dependent的优化;2)穷举模式的优化,对于无用变量消除、子表达式提取,对表达式采用黑盒法作输入值的穷举测试,通过观测确定可以消除的变量或提炼表达式,虽然耗时,但由于在架构中属于离线操作,所以不影响平台的执行效率.这种优化方式不仅对平台上用户提交的大数据应用,甚至对于成熟的算法也具备优化的潜力.
学习流程后处理模块以优化成功的基本块为输入,计算指纹,将指纹及优化成功后的基本块中间表示或机器码段分别存入指纹Map和优化代码数据库.
图3上部为工作流程,功能模块依次为在线输入模块、运行时采集模块、指纹提取模块、比较模块、优化JIT引擎.采集模块处理经在线输入模块导入的程序,提取其中的基本块;指纹提取模块以采集模块提取的基本块为输入,计算其指纹;比较模块将计算得到的指纹与指纹Map中的指纹作匹配,根据结果(命中与否)来控制开关,保证输入JIT引擎的是最优的机器码段.优化JIT引擎负责执行,对于中间表示代码,JIT首先编译基本块为相应的机器码段,进而将其交给CPU执行;对于机器码段,则由CPU直接译码执行.
2 实 现
我们以Hadoop为基础,采用我们的设计思路和优化方法进行改造,得到原型大数据处理系统Arion,其中,任务执行层位于大数据框架与硬件平台的衔接处,是系统正交分解的关键.首先,执行层中的连接件是框架技术的外延,是封装为类的大数据处理通用代码库,在大数据处理中会被执行引擎频繁调用;其次,执行引擎向上承接用户的大数据处理请求,向下驱动底层平台,其选型与实现直接影响系统的整体性能和跨平台特性.
图1中部任务执行层的左边为面向Hadoop MapReduce框架的连接件,通过选择合适功能的连接件,才能无缝衔接Map和Reduce阶段,形成大数据处理工作流.
连接件以类的形式被预编译成JIT引擎可以执行的二进制代码,或易于发布的IR形式,并于任务执行时按需动态加载.对于较常用的连接件,如Hadoop中的文件读取类LineRecordReader(见Hadoop官方API),需要预先编译成所在平台的二进制代码,以动态链接库的形式加载,这种方式更具性能优势;对于不常使用的连接件,如TeraSort中的TotalOrderPartitioner(见Hadoop官方API),会收集输入数据的样本来构建Trie树,进而为Map的结果做分区;这是一种特殊逻辑,仅在TeraSort处理流程中使用,因此实现中该类以IR形式发布,便于增加灵活性,同时减小动态加载的大数据处理通用代码库的内存占用量.
连接件向上与调度管理层通过代理协议来通信和同步.实现中代理协议ArionPipe基于HadoopPipe来实现,扩充了HadoopPipe的命令,使其能够支持更多平台相关的连接件,如用于排序的连接件Sorter,能够支持分布式缓存等等.ArionPipe目前是基于Socket的点对点协议,在拓扑和协议数据压缩方面还有较大优化空间.
连接件通过调用库函数的形式来集成ArionFS客户端,进而能够向下直接访问ArionFS.如LineRecordReader,LineRecordWriter都分别集成了ArionFS客户端,在大数据读取和写入时通过运行锁无关IO状态机来与ArionFS服务器通信.又如TotalOrderPartitioner通过集成ArionFS客户端,能够读取缓冲的采样文件,进而构建Trie树完成分区任务;Kmeans大数据计算的Mapper用来完成浮点数的聚类,也能够通过IO状态机来读取缓冲在ArionFS中的分类文件.
Arion的任务执行引擎基于LLVM实现,不但能够利用平台相关技术来优化大数据处理,还能够保证系统的跨平台特性.
3 实 验
为了验证Arion正交分解框架改造的正确性以及相对的性能提升,我们做了文件系统测试,性能扩展性测试,以及MapReduce任务的阶段分析.
测试集包括类HiBench的4个大数据应用:
1) DFSIO.用于对分布式文件系统做读写性能测试,每个Map任务根据键值做对应文件的读或写操作,根据Value值确定文件大小,Reduce任务收集吞吐率等统计信息.
2) WordCount.用于提取大文件中出现的单词并统计分析单词出现的频次.
3) TeraSort.该实验采用TeraGen产生的1GB大文件(文件中每行记录在百字节左右,总行数为千万量级),通过TotalOrderPartitioner做数据的采样分区(采样参数为100 KB),进而排序.
4) Kmeans.该实验实现了机器自动聚类,采用了循环迭代的算法,实验中采用了10 KB的双精度数据集,并设定了初始聚类参数.
实验共采用了5台同配置HP服务器、Intel Xeon 32核处理器、32 GB的内存、1 TB SATA硬盘;操作系统为CentOS 6.文件系统实验、性能扩展性实验中,1台服务器固定用作Hadoop/Arion的JobTracker和任务提交、监测客户端;另外1~4台服务器用作任务执行TaskTracker.Case Study实验中,共采用了3台服务器,1台用作JobTracker和客户端,另外2台用作TaskTracker.所有实验中,分布式文件系统(HDFS/ArionFS)部署在参与当前实验的服务器上.
3.1 文件系统测试
本实验中,1台服务器用作:1)MapReduce任务管理JobTracker;2)文件系统元数据节点Namenode;3)任务提交客户端.其他1~4台服务器用作:1)任务执行TaskTracker;2)文件系统数据节点DataNode.所有Map任务会发起对分布式文件系统的读写操作,形成对各个数据节点的IO压力,Reduce任务则收集、分析各个Map任务的IO相关统计信息.
本实验中,HDFS和ArionFS文件系统的基本分块大小ChunkSize皆为64 MB;由于ArionFS暂不支持副本机制,将HDFS的副本数设置为1;实验测试文件集设置为:10个文件,每个文件1 GB.每组实验分别作了10次,根据平均数绘制实验图表.
由图4(a),对于写测试,随着分布式文件系统节点数的增加,无论是HDFS还是ArionFS,其执行时间有增加的趋势,而吞吐率有减小的趋势,这是由于DFSIO测试中,数据是由客户端节点分发到各个数据节点的,随着数据的分布范围的增加,10GB实验数据的分发带来了网络开销,致使执行时间增加;另一方面,随着节点数增加,并发IO也会带来带宽的聚合、性能的提升,由图4(a)可知,4节点实验的执行时间与3节点实验相比,反而有所减少.
从完成时间上分析,1~4个节点的文件系统写测试中,ArionFS的完成时间较HDFS分别减少了2.0%,2.7%,3.7%,3.1%;从吞吐率上分析,ArionFS的吞吐率较HDFS分别提高了2.2%,3.1%,1.0%,0.8%.综上,ArionFS的平均完成时间较HDFS减少2.9%,ArionFS的平均吞吐率较HDFS提高1.8%.
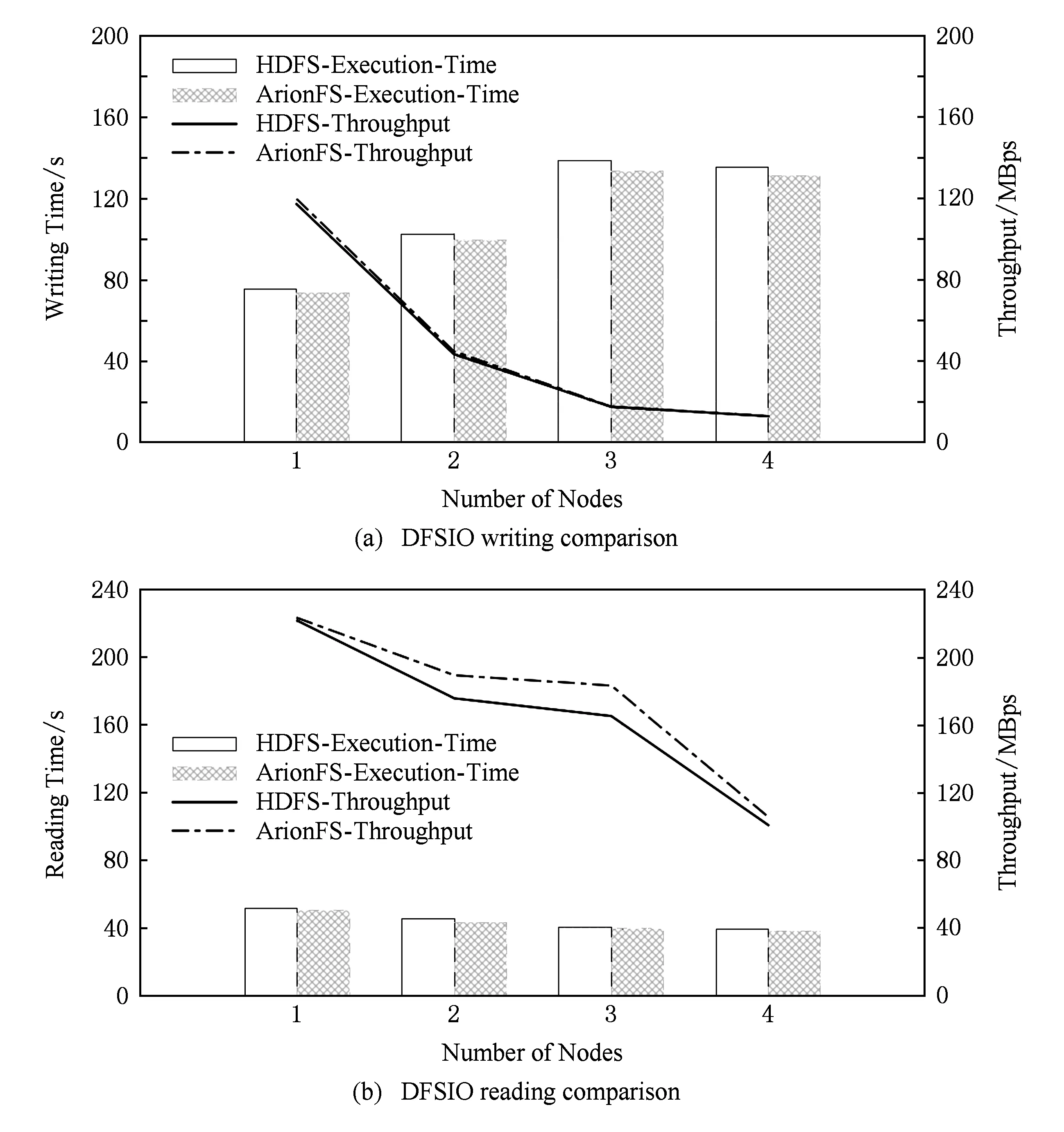
Fig. 4 Distributed file system test based on DFSIO benchmark图4 基于DFSIO测试集的分布式文件系统测试
由图4(b),对于读测试,随着分布式文件系统节点数的增加,无论是HDFS还是ArionFS,其执行时间变化不大,略有减少,这里执行时间记录的是整个实验从开始到结束的总时间,即包括文件读阶段,也包括Shuffle,Merge等衔接阶段,以及最后的Reduce阶段和统计信息分析阶段;吞吐率方面,两个文件系统均随着节点数的增加而减小,这是由于数据分布带来了网络开销,ArionFS在吞吐率上的表现要略优于HDFS.需要说明的是,本实验中吞吐率与完成时间不成反比的原因是DFSIO实验中吞吐率并非由完成时间计算得出,而是根据每个Map任务中的文件读取时间来计算的.
从完成时间上分析,1~4个节点的文件系统读测试中,ArionFS的完成时间较HDFS分别减少了2.0%,4.2%,1.8%,2.9%;从吞吐率上分析,ArionFS的吞吐率较HDFS分别提高了0.7%,7.7%,10.8%,4.7%.综上,ArionFS的平均完成时间较HDFS减少2.7%,ArionFS的平均吞吐率较HDFS提高6.0%.
3.2 性能、扩展性测试
本实验首先从性能上针对3种负载展开Hadoop与Arion的对比.实验中,文件系统的基本分块大小ChunkSize和大数据处理引擎的处理单元大小SplitSize皆为64 MB.
由图5(a),WordCount实验中,单节点Arion在Vanilla Hadoop基础上优化后,执行时间缩短3.0%;2,3,4个节点也分别缩短5.0%,3.0%,3.0%,平均缩短3.5%.根据图5(b)(c),TeraSort实验中,相较Vanilla Hadoop,Arion的执行时间平均缩短7.7%;Kmeans实验中,平均缩短3.5%.
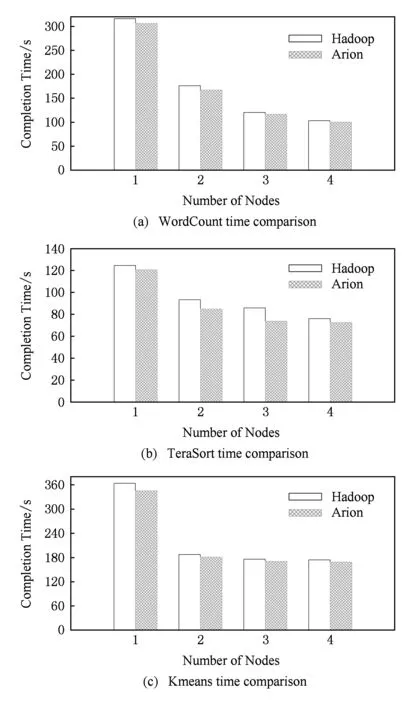
Fig. 5 Performance and scalability test图5 性能及扩展性测试
其次,由实验结果可知,各个实验中随着节点数的增加,无论是Vanilla Hadoop还是Arion,其执行时间都是在缩短的,可见Arion在做正交分解和优化后,保留了原有大数据处理系统的良好扩展性.其中,Kmeans实验后期,随着节点的增加,性能改善较小,多节点时扩展性表现一般的原因是Kmeans随着节点的增多,瓶颈主要集中在Reduce阶段,包括从各个分节点调度、提取、排序数据,并重新计算分类中心点.
3.3 Case Study
本实验中我们作典型MapReduce任务执行各阶段的精细化分析.表1、表2中,依序(由下至上)记录了如下9种大数据任务处理阶段的执行时间:
1) 适配层的连接件Reader,如LineRecord-Reader,用于与ArionFS对接,通过运行锁无关IO状态机读取分布式文件系统的数据;
2) Mapper,MapReduce框架的Map任务处理阶段;
3) 连接件Partitioner,如3.1节介绍的Total-OrderPartitioner,用于对Mapper的输出结果根据一定的算法做分区;
4) 连接件Combiner,用于对Mapper的输出结果作部分合并;
5) 连接件Merger,对多个分布式的Mapper的输出结果做归并提取;
6) 连接件Sorter,在Reduce预处理阶段,做多路Mapper提取数据的排序;
7) Reducer,MapReduce框架的Reduce任务处理阶段;
8) 连接件Writter,如3.1节介绍的LineRecord-Writer,用于与ArionFS对接,通过运行锁无关IO状态机向分布式文件系统写入数据;
9) Others,除去上述阶段外的其他开销,如Arion中LLVM引擎与上层Hadoop JVM虚拟机间的通信等.
本实验皆采用1台JobTracker服务器、2台TaskTracker服务器的硬件配置,与Map相关的任务处理阶段的执行时间为平均值.
表1为WordCount实验,采用100 MB的文件,而计算引擎的Split Size为64 MB,共切分为2个Map任务.该实验Arion的面向底层平台的优化集中在Reader,Mapper,Reducer,Writer四个阶段.如表1,Arion的Mapper阶段经优化其执行时间较Hadoop减少7.9%,但是,在Others阶段,Arion的通信、调度开销较大,执行时间反而增加了5.0%.因此,总时间Arion仅比Hadoop减少了3.0%.
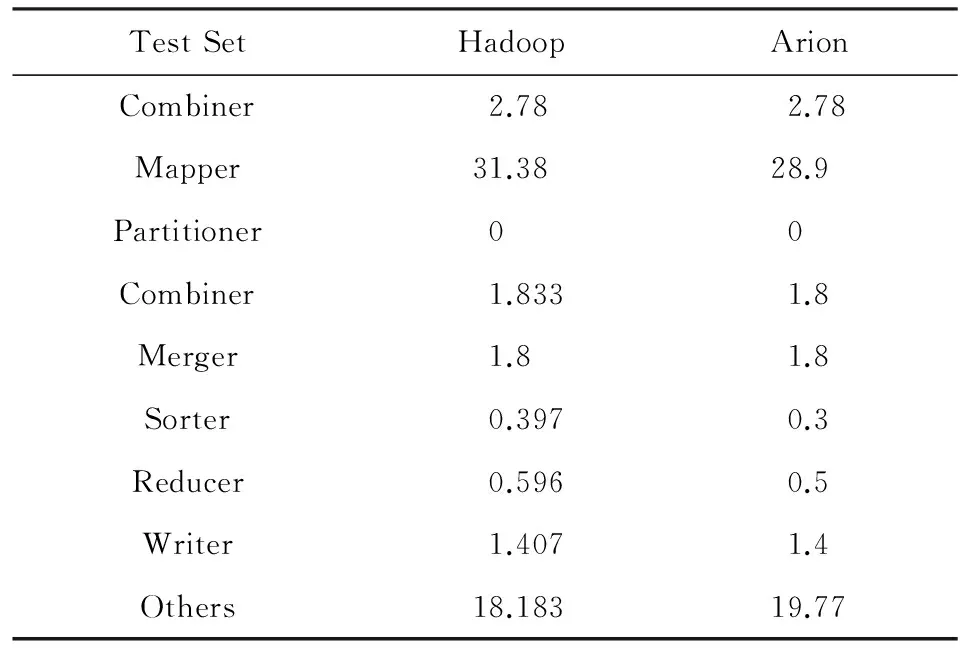
Table 1 Wordcount Stage Analysis表1 Wordcount执行阶段分析
表2为TeraSort实验,采用1 GB的文件,而计算引擎的Split Size为512 MB,共切分为2个Map任务.该实验Arion的面向底层平台的优化集中在Reader,Mapper,Partitioner,Merger,Reducer,Writer六个阶段.如表2所示,相对于Hadoop,Arion的Mapper阶段执行时间减少9.8%,Partitioner部分,即TotalOrderPartitioner,执行时间减少11.2%,Reducer部分减少14.4%,这几部分提升较大与计算密集,引擎优化效率较高有关;但是,在Others阶段,Arion的通信、调度开销较大,执行时间反增29.5%.因此,总时间Arion仅比Hadoop减少了10.0%.
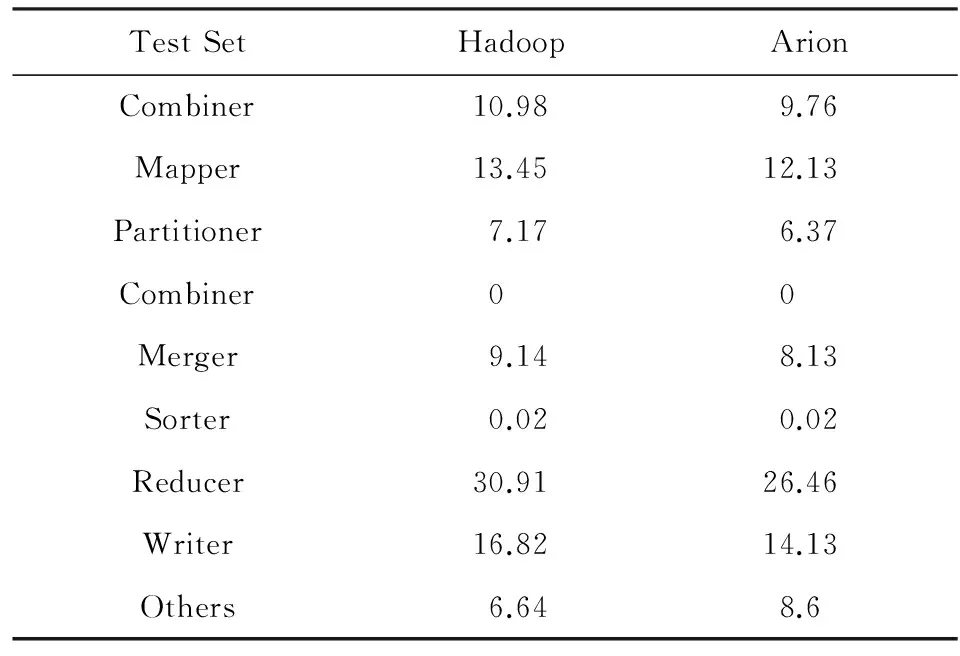
Table 2 Terasort Stage Analysis表2 Terasort执行阶段分析
综上,本实验表明:Arion对大数据处理部分执行阶段、读写阶段的优化具有明显效果,但也会引入额外的通信、调度开销.
4 相关工作
大数据处理系统的发展是二维的.从横向看,各个系统的框架主要围绕着数据处理负载的特性来进化.Google的MapReduce[2]是典型的2阶段处理框架,具备一定的通用性,但最初主要是针对搜索引擎网页的批量抓取而设计.Nokia的Disco[3]系统也采用了针对批量大数据处理而设计的框架.Microsoft的Dryad[5]则是主要面向工作流处理负载的框架,这类框架还包括Google的Dremel[4],Twitter的Storm[6],Yahoo的S4[7]等.面向图计算,Pregel[13]和开源的Giraph*http://giraph.apache.org是典型代表.针对MapReduce模型不擅长的迭代处理和交互应用,伯克利AMP Lab提出了基于RDD[8]内存数据集的迭代模型处理框架,并设计了内存大数据处理系统Spark[9].
从纵向阶段上看,各大数据处理系统自身也是围绕着框架、调度算法的升级而升级的.Hadoop自身的计算框架由原本单一的MapReduce演化出了基于DAG的更为灵活的Tez;自身的调度也从单一的全局任务调度发展到了新一代的Yarn[10],分离了JobTracker的资源管理与任务调度功能.Mesos[14]是参照操作系统内核而设计的大数据资源管理系统,其自身也是围绕着资源调度种类的增加、资源调度算法的升级而发展的,在Hadoop生态体系中,其作用类似于Yarn.
综上,现有大数据处理系统的发展无论从那个维度看,计算模型的改进、框架和算法的升级是关注点,底层平台相关技术的利用存在空白.Intel中国研究院的NativeTask[11]通过设计外挂的计算引擎模块,将部分Hadoop计算引擎内部的计算外延到Java虚拟机之外;百度公司的Hadoop的C++扩展*Hadoop C++ Extension: A Framework for Making MapReduce More Stable and Faster. http://wenku.baidu.com/view/1859f988d0d233d4b14e69c8.html,通过使用类似Pipe的协议将Map和Reduce两阶段的Java执行逻辑替换为C++编写并预编译好的二进制可执行文件,都取得了一定的本地化效果,但都未充分发挥存储结点、计算结点本地平台的潜力.
大数据文件系统是大数据处理的基石,如Google公司的GFS[15],Amazon的S3,Dynamo[16],Apache的Cassandra*http://cassandra.apache.org,Hadoop中的HDFS[17]以及基于快速网络的FDS[18]等,它们都提供类Key/Value的存储抽象和基于副本的可靠性机制,为上层的大数据应用服务.新一代内存文件系统Tachyon[19]以内存数据集为主要抽象为上层提供大数据存储服务,其中引入了Lineage[20]的抽象来实现内存数据的可靠性,大大减少了存储空间占用,提高了写入带宽,但也引入了重计算的调度等问题.同样采用Lineage抽象的还有BADFS[21],该文件系统提供了显示的描述式语言接口,使得内核能够从用户输入获得Lineage信息.由上述可知,大数据文件系统的主流聚焦于在本地系统上建立一层分布式抽象层,提供适合处理的数据模型和可靠性保障等服务,缺乏本地化相关领域的研究.
任务执行引擎需要运行时(managed runtime environment, MRE)支撑,这主要是由于运行时能够为程序运行提供灵活性和安全性.成熟运行时,如SmallTalk[22],Self[23],JVM[24]都有严格的高级语言绑定,如type-safe的检查,需要程序符合其MRE的设计.微软的CLI[25]能够支持多种语言,但对语言互操作性有严格限制,不支持非控制(unmanaged)语言的优化,且不开源.LLVM[12]是一个开源的编译器设计框架,提供通用、基于静态单一分配(static single assignment, SSA)模式的代码中间表示,同时具备系列开源前端,支持多种高级语言,后端能做多遍优化,因此是本文选型方案.
5 结论和局限性及未来工作
我们提出一种基于正交分解的大数据处理系统设计与优化方法,主张将整个系统划分为功能上互相正交的、松耦合的模块,将数据存储与任务执行下沉到具体的硬件平台去完成,大数据系统只负责最核心的资源与任务调度.进而,在此方法的指导下,我们提出了基于锁无关机制的存储底层优化策略,以及基于指令超级优化的执行引擎底层优化策略.这种优化方式与主流的面向计算模型、框架、算法的发展趋势并不矛盾,是正交、互补的关系,有效填补了技术空白.
基于上述技术,以Hadoop作为兼容和改进的对象,我们实现了原型大数据处理系统Arion,采用正交分解,将Hadoop的任务调度与存储、计算引擎拆分开,通过通信协议连接;数据存储下沉到C语言实现的锁无关大数据分布式文件系统ArionFS中;任务执行下沉到基于LLVM的本地化执行引擎.经实验证明,同等硬件配置下,Arion的性能优于Hadoop.
本技术局限在于:分解后下沉到平台的数据存储与任务执行引擎带来的加速比依赖于负载模式、代码特点及JIT引擎实现,对于数据分布均衡、处理逻辑简单、优化代码段执行频率低的任务,如何提高收益,深挖平台潜力是我们下一步工作的重点.另外,正交分解方法在Spark平台上的应用也是未来工作之一,Spark平台将调度交给Mesos、存储交给HDFS等,已然符合正交分解思想,并为后续面向平台优化做了铺垫;其计算引擎层面的优化是难点,需要针对RDD的Transformation和Action执行逻辑中间表达作超级优化,充分考虑代码特点及JIT引擎实现;存储可以直接交给ArionFS.
[1]Wang Yuanzhuo, Jin Xiaolong, Cheng Xueqi. Network big data: Present and future[J]. Chinese Journal of Computers, 2013, 36(6): 1125-1138 (in Chinese)(王元卓, 靳小龙, 程学旗. 网络大数据: 现状与展望[J]. 计算机学报, 2013, 36(6): 1125-1138)
[2]Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113
[3]Mundkur P, Tuulos V, Flatow J. Disco: A computing platform for large-scale data analytics[C] //Proc of the 10th ACM SIGPLAN Workshop on Erlang. New York: ACM, 2011: 84-89
[4]Melnik S, Gubarev A, Long J J, et al. Dremel: Interactive analysis of Web-scale datasets[J]. Proc of the VLDB Endowment, 2010, 3(1/2): 330-339
[5]Isard M, Budiu M, Yu Y, et al. Dryad: Distributed data-parallel programs from sequential building blocks[C] //ACM SIGOPS Operating Systems Review. New York: ACM, 2007: 59-72
[6]Leibiusky J, Eisbruch G, Simonassi D. Getting Started with Storm[M]. Sebastopol: O’Reilly Media, Inc, 2012
[7]Neumeyer L, Robbins B, Nair A, et al. S4: Distributed stream computing platform[C] //Proc of the 2010 IEEE Int Conf on Data Mining. Piscataway, NJ: IEEE, 2010: 170-177
[8]Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C] //Proc of the 9th USENIX Conf on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 2
[9]Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[C] //Proc of the 2nd USENIX Conf on Hot Topics in Cloud Computing. Berkeley, CA: USENIX Association, 2010: 10
[10]Vavilapalli V K, Murthy A C, Douglas C, et al. Apache Hadoop yarn: Yet another resource negotiator[C] //Proc of the 4th Annual Symp on Cloud Computing. New York: ACM, 2013
[11]Yang D, Zhong X, Yan D, et al. NativeTask: A Hadoop compatible framework for high performance[C] //Proc of IEEE Int Conf on Big Data. Piscataway, NJ: IEEE, 2013: 94-101
[12]Lattner C, Adve V. LLVM: A compilation framework for lifelong program analysis & transformation[C] //Proc of Int Symp on Code Generation and Optimization. Piscataway, NJ: IEEE, 2004: 75-86
[13]Malewicz G, Austern M H, Bik A J C, et al. Pregel: A system for large-scale graph processing[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 135-146
[14]Hindman B, Konwinski A, Zaharia M, et al. Mesos: A platform for fine-grained resource sharing in the data center[C] //Proc of Symp on Network System Design and Implementation. Berkeley, CA: USENIX Association: 2011: 22
[15]Ghemawat S, Gobioff H, Leung S T. The Google file system[C] //Proc of the 19th ACM Symp on Operating Systems Principles. New York: ACM, 2003: 29-43
[16]DeCandia G, Hastorun D, Jampani M, et al. Dynamo: Amazon’s highly available key-value store[C] //Proc of ACM SIGOPS Operating Systems Review. New York: ACM, 2007: 205-220
[17]Shvachko K, Kuang H, Radia S, et al. The Hadoop distributed file system[C] //Proc of the 26th IEEE Symp on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2010: 1-10
[18]Nightingale E B, Elson J, Fan J, et al. Flat datacenter storage[C] //Proc of the 10th USENIX Symp on Operating Systems Design and Implementation (OSDI 12). Berkeley, CA: USENIX Association. 2012: 1-15
[19]Li H, Ghodsi A, Zaharia M, et al. Tachyon: Reliable, memory speed storage for cluster computing frameworks[C] //Proc of the ACM Symp on Cloud Computing. New York: ACM, 2014: 1-15
[20]Bose R, Frew J. Lineage retrieval for scientific data processing: A survey[J]. ACM Computing Surveys, 2005, 37(1): 1-28
[21]Bent J, Thain D, Arpaci-Dusseau A C, et al. Explicit control in the batch-aware distributed file system[C] //Proc of Symp on Network System Design and Implementation. Berkeley, CA: USENIX Association, 2004: 365-378
[22]Deutsch L P, Schiffman A M. Efficient implementation of the smalltalk-80 system[C] //Proc of the 11th ACM SIGACT-SIGPLAN Symp on Principles of Programming Languages. New York: ACM, 1984: 297-302
[23]Ungar D, Smith R B. Self: The Power of Simplicity[M]. New York: ACM, 1987
[24]Lindholm T, Yellin F, Bracha G, et al. The Java Virtual Machine Specification[M]. Reading, MA: Addison-Wesley, 2014
[25]Miller J S, Ragsdale S. The Common Language Infrastructure Annotated Standard[M]. Reading, MA: Addison-Wesley, 2004
An Orthogonal Decomposition Based Design Method and Implementation for Big Data Processing System
Xiang Xiaojia1, Zhao Xiaofang1, Liu Yang1, Gong Guanjun1, and Zhang Han2
1(Institute of Computing Technology, Chinese Academy of Science, Beijing 100190)2(School of Computer Science, North China University of Technology, Beijing 100144)
Big data stimulates a revolution in data storage and processing field, resulting in the thriving of big data processing systems, such as Hadoop, Spark, etc, which build a brand new platform with platform independence, high throughput, and good scalability. On the other hand, substrate platform underpinning these systems are ignored because their designation and optimization mainly focus on the processing model and related frameworks & algorithms. We here present a new loose coupled, platform dependent big data processing system designation & optimization method which can exploit the power of underpinning platform, including OS and hardware, and get more benefit from these local infrastructures. Furthermore, based on local OS and hardware, two strategies, that is, lock-free based storage and super optimization based data processing execution engine, are proposed. Directed by the aforementioned methods and strategies, we present Arion, a modified version of vanilla Hadoop, which show us a new promising way for Hadoop optimization, meanwhile keeping its high scalability and upper layer platform independence. Our experiments prove that the prototype Arion can accelerate big data processing jobs up to 7.7%.
big data processing system; computing framework; localization; lock free; super optimization; excecution engine

Xiang Xiaojia, born in 1977. PhD, associate professor. Senior member of CCF. His main research interests include big data processing system, distributed storage, operating system, etc.

Zhao Xiaofang, born in 1965. PhD, professor, PhD supervisor. Her main research interests include computer architecture, data management, information security, etc.

Liu Yang, born in 1991. Master candidate. His main research interests include operating system, distributed system, information security, etc.

Gong Guanjun, born in 1993. Master candidate. His main research interests include operating system, network security, etc.

Zhang Han, born in 1993. Bachelor. Her main research interests include digital media, distributed storage, etc.
2015-12-09;
2016-07-19
国家自然科学基金项目(61202061,61202413);中国科学院计算技术研究所创新课题项目(20146080) This work was supported by the National Natural Science Foundation of China (61202061, 61202413) and the Innovation Program of Institute of Computing Technology, Chinese Academy of Sciences (20146080).
TP391
猜你喜欢
军民两用技术与产品(2022年2期)2022-06-01
小学科学(2022年3期)2022-04-01
施工技术(中英文)(2021年15期)2021-10-23
北京航空航天大学学报(2019年9期)2019-10-26
现代计算机(2018年30期)2018-11-20
中国建筑金属结构(2018年4期)2018-05-23
汽车文摘(2016年6期)2016-12-07
小说林(2014年5期)2014-02-28
电影新作(2014年5期)2014-02-27
杂文选刊(2013年7期)2013-02-11
