
基于互信息的粒化特征加权多标签学习k近邻算法
2017-05-13 03:50苗夺谦张志飞
计算机研究与发展 2017年5期
李 峰 苗夺谦 张志飞 张 维
(同济大学计算机科学与技术系 上海 201804)(嵌入式系统与服务计算教育部重点实验室(同济大学) 上海 201804)(tjleefeng@163.com)
基于互信息的粒化特征加权多标签学习k近邻算法
李 峰 苗夺谦 张志飞 张 维
(同济大学计算机科学与技术系 上海 201804)(嵌入式系统与服务计算教育部重点实验室(同济大学) 上海 201804)(tjleefeng@163.com)
传统基于k近邻的多标签学习算法,在寻找近邻度量样本间的距离时,对所有特征给予同等的重要度.这些算法大多采用分解策略,对单个标签独立预测,忽略了标签间的相关性.多标签学习算法的分类效果跟输入的特征有很大的关系,不同的特征含有的标签分类信息不同,故不同特征的重要度也不同.互信息是常用的度量2个变量间关联度的重要方法之一,能够有效度量特征含有标签分类的知识量.因此,根据特征含有标签分类知识量的大小,赋予相应的权重系数,提出一种基于互信息的粒化特征加权多标签学习k近邻算法(granular feature weightedk-nearest neighbors algorithm for multi-label learning, GFWML-kNN),该算法将标签空间粒化成多个标签粒,对每个标签粒计算特征的权重系数,以解决上述问题和标签组合爆炸问题.在计算特征权重时,考虑到了标签间可能的组合,把标签间的相关性融合进特征的权重系数.实验表明:相较于若干经典的多标签学习算法,所提算法GFWML-kNN整体上能取得较好的效果.
互信息;特征权重;粒化;多标签学习;k-近邻
传统机器学习以二类(binary-class)分类或者多类(multi-class)分类为主,每个样本只有一个类别标签,称作单标签学习(single-label learning).然而,现实世界中各领域都存在大量同时拥有多个标签的样本[1-3].比如,一篇新闻报道可能同时跟多个话题有关[4],如体育、娱乐、社会、经济;一张图片可能同时包含多个语义信息[5],如大海、沙滩、城市;一个基因可能同时具有多个功能[6],如翻译、转录;一个病人的病理图像可能同时展现出了多个病理特性[7],如角化过度、颗粒层消失.这些有多个标签的样本称为多标签数据.多标签学习(multi-label learning)的任务就是通过学习标签已知的多标签数据来预测标签未知的样本相关的多个标签[1-3].相较于单标签数据中样本只有唯一确定的标签,多标签数据中的样本可能同时拥有多个标签,从而导致了多标签数据的复杂多变.多标签数据的复杂性、多变性都增加了多标签学习算法预测的难度.
在面对复杂问题时,人类往往将复杂问题分解为多个简单问题,再逐个解决.机器学习领域沿用了此方法,传统机器学习中将多类分类问题拆分成多个二类分类问题.直观上,多标签学习问题也可以被拆分成多个独立的二类分类问题,每一个标签对应一个二类分类问题.但此方法破坏了标签间的相关性,而多标签数据中的标签间往往存在一定的相关性,如一部“动作”电影,同时也是一部“冒险”电影的可能性,要比它同时是一部“爱情”电影的可能性要大.因此如何充分利用多标签训练数据中标签间的相关性(label correlation)来帮助构建预测模型一直是多标签学习中的研究热点问题之一.
众所周知,k-近邻算法[8](k-nearest neighbors,kNN)是一种无参懒惰学习算法,无需通过训练来构建预测模型,待测样本的预测结果直接由其k个距离最近的训练样本来确定.kNN算法是机器学习领域最简单有效的算法之一,经常被用于分类或者回归.因此,一些基于kNN算法的扩展算法被提出用于多标签学习[9-12].像kNN算法一样,这些扩展算法也是懒惰学习算法,均需先查找样本的k个最近邻训练样本,再采用不同的后续处理方式.最近邻的选择依据样本间在特征空间上的距离,所选择的k个最近邻训练样本直接决定算法效果.在处理多标签问题时,这些算法大多采用了前述的拆分策略,每个标签单独求解,忽略了标签间的相关性.
标签组合是挖掘标签相关性的有效方式,但标签组合数跟标签数呈指数级的关系,其随着标签数的增长而急剧增加,加剧了算法的复杂度,而且多标签数据的标签空间中有的标签相关性很大,有的则几乎没有相关性.因此相关性较大的标签应该被放到同一类,分别考虑各类中的标签相关性.
像传统机器学习算法一样,多标签学习算法的分类预测效果依赖于输入的特征,而且相较于传统机器学习算法中只有一个类别,多标签学习中的有多个标签类别,特征与标签的相关性更为复杂.不同的特征对同一标签的分类有不同的重要度,同一特征对不同的标签也有着不同的重要度.有的特征对某一类标签分类很重要,对另一类标签则不是那么重要,甚至完全不相关.所以不同的特征应该根据其对标签分类的重要程度被给予相应的权重.但kNN算法在计算样本间距离时,将所有特征给予同样的重要度.不重要的特征被同等对待,会干扰近邻的选择,影响算法效果.
互信息是常用的度量2个变量关联度的方法,其能表示特征对标签分类的重要度.粒计算是解决复杂问题的有效方法,其模拟人类处理复杂问题的方式,将复杂问题化解成简单问题[13-14].因此,我们提出了一种基于互信息的粒化特征加权多标签学习k近邻算法(granular feature weightedk-nearest neighbors algorithm for multi-label learning, GFWML-kNN),该算法采用粒计算思想将标签空间粒化成多个标签粒,将相似的标签粒化到同一标签粒中,使得不同粒中的标签间的相关性最小,粒内的标签间相关性最大.这样既将复杂问题分解成为了多个简单问题,大大减少标签组合数,又最大限度地保留了标签间的相关性.对每个标签粒,根据特征包含的标签分类信息程度,对不同的特征给予不同的权重,将标签间的相关性融入特征的权重系数.对特征进行加权,寻找与待测样本标签信息更接近的近邻样本,提高算法的精度.
为了验证所提算法的有效性,本文将GFWML-kNN与标准ML-kNN算法,以及其他经典的多标签算法在多个真实世界多标签数据集上进行了实验对比,实验结果表明本文所提算法能取得较好的学习效果.
1 研究现状
多标签学习已经受到了越来越多的关注,成为机器学习领域中的一个研究热点.目前为止,一系列多标签学习算法已经被提出.这些多标签算法主要可以分为2类:问题转换方法(problem transformation method, PTM)和算法适应方法(algorithm adaption method, AAM)[1].
问题转换方法首先将多标签数据集转换成多个单标签数据集,再采用已有的单标签学习算法来处理每个标签数据.问题转换方法独立于算法,让数据去适应算法.经典的问题转换方法有BR(binary relevance)[15]方法、LP (label powerset)方法等.
BR[15]方法直接将多标签数据集中的每个标签拆分开来,形成|L|个独立的单标签数据集,|L|表示标签的数量.BR方法虽然简单,但其忽略标签间的相关性.考虑到标签的相关性,Read等人[16]提出了一种对BR方法的改进算法,链式的分类(chain classifier, CC)算法用于多标签学习.该算法同样构建|L|个二分类标签模型,但其将先预测出的标签作为后待预测标签的输入特征.CC虽然考虑到了标签间的相关性,而且算法较为简单,但算法结果依赖于标签预测的顺序,前面预测的标签误差会传递到后面的标签中,如果前面的标签误差较大,那么整体算法性能将大打折扣.因此一种集成的链式(ensembles of chain classifiers, ECC)[17]算法被提出用于解决此缺陷.PW(pairwise binary)[18]是另一种对BR改进的方法.PW任意选取2个标签进行组合,这对标签构成一个二类分类问题,通过标签已知的数据集为每个二类分类问题训练一个分类模型,这样将有|L|(|L|-1)/2个分类模型,致使PW方法计算代价过高.
LP方法则根据数据集中标签间组合的可能性,将多标签数据变成2|L|单标签数据,多标签问题变成多类分类问题.LP方法考虑到了标签间的相关性,但标签组合的爆炸性问题,极大增加了算法复杂度.因此,Tsoumakas等人[19]提出一种集成的随机标签子集(ensembles of randomk-label subsets, RAkEL)方法,其从标签集中随机选取k个标签,再研究其中可能的标签组合;Read等人[20]提出了EPS(ensembles of pruned sets)算法,用出现频次较高的标签组合来表示出现频次较低的标签组合,出现频次较低的被去除.这样既最大限度地保证了标签相关性,又降低了算法的复杂度.
算法适应方法依赖于某一具体的机器学习算法,对该具体算法进行改进使其能直接处理多标签数据,如决策树[21]、支持向量机[22]、BP神经网络[23]等算法.
Clare等人[21]利用多标签熵将传统的C4.5决策树算法用于多标签学习,称作多标签C4.5,其允许叶子节点拥有多个标签.Elisseeff等人[22]将支持向量机(support vector machine, SVM)算法应用于多标签学习中,提出了一种RankSVM算法.其对每个标签构建一个SVM预测模型,利用排序损失考虑每个样本的相关标签和不相关标签.BPMLL[23]算法将最流行的神经网络模型之一的BP神经网络的扩展成多个输出,以适应多标签学习,并提出了一种排序的多标签的误差度量函数,认为待测样本实际包含的标签应该比不包含的标签排序靠前.Yu等人[24]提出了基于粗糙集的多标签学习分类算法和标签局部关系的粗糙集多标签学习分类算法.基于邻域的思想,文献[5]提出了一种基于邻域粗糙集(neighborhood rough sets)的多标签分类算法,用于图像语义标注问题.
kNN算法无需提前训练模型,优化参数,相较于其他算法,具有算法复杂度低且分类效果较好的优势.因此Spyromitros 等人[12]对BR方法和kNN算法结合的BRkNN算法进行了扩展,提出了一种懒惰的多标签分类算法,用测试样本的k个近邻训练样本的标签近似估计它的标签.该方法提升了算法的运行效率,但其也保留了BR方法的不足,即忽略了标签间的相关性.Zhang等人[9]将kNN算法和贝叶斯理论应用于多标签学习中,提出了一种多标签懒惰学习算法(ML-kNN),通过样本的k个近邻训练样本的标签信息,用最大后验概率准则预测它的标签.ML-kNN算法因其算法简单、预测效果好,得到了广泛的关注.但ML-kNN算法对每个标签独立预测,未考虑到多个标签间的相关性.因此,文献[25]提出了一种新型多标记懒惰学习算法(IMLLA),该算法同样首先找出测试样本的近邻训练样本,再利用训练数据的分布信息和标签间的相关性来进行预测,考察了样本多个标签之间的相关性.这些算法均没有考虑特征对于标签分类的不同作用.因此本文提出一种基于互信息的粒化特征加权多标签学习k近邻算法,以利用标签间的相关性,以及考虑特征对标签分类的重要度,并且不过多增加算法复杂度.
2 基本知识
在介绍所提算法前,先简要介绍互信息和多标签学习的基本概念.
2.1 互信息
定义1. 熵[26-27]是度量随机变量不确定性的重要工具,随机变量X的熵为
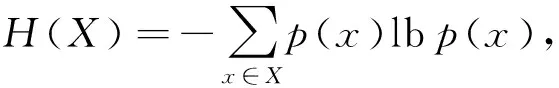
其中,p(x) 表示x的概率密度.
定义2.X和Y的联合熵为
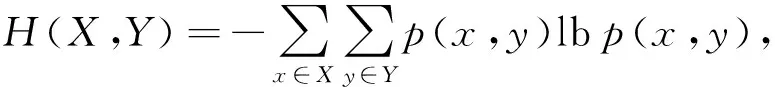
其中,p(x,y) 是x和y的联合概率密度.
定义3. 变量Y对于变量X条件熵为
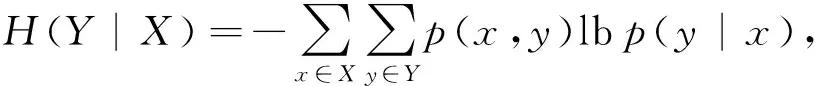
其中,p(y|x) 是条件概率密度.
性质1. 条件熵可由熵、联合熵改写为
H(Y|X)=H(X,Y)-H(X).
证明.
证毕.
定义4. 互信息能够度量2个变量间的关联程度,指出了一个变量通过另一个变量所获得的知识,对于变量X和Y的互信息计算如下:
可以看出I(X;Y)=I(Y;X).当X与Y相互独立时互信息值为0.
性质2. 互信息可以用熵和条件熵表示为
I(X;Y)=H(Y)-H(Y|X).
证明.
证毕.
2.2 多标签学习
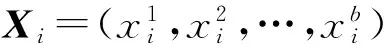
3 GFWML-kNN
针对以往基于kNN的多标签学习算法不考虑特征重要性的差异,忽略标签间的相关性以及避免标签组合爆炸问题,本文提出基于互信息的粒化特征加权多标签学习k近邻算法.该算法首先基于粒计算的思想,用平衡k均值(balancedk-means)聚类算法[27]将标签空间粒化成多个标签粒,简化标签的组合;然后,对每个标签粒,根据特征与标签粒的互信息的大小,为特征赋予相应的权重系数,权重系数包含了标签相关性的信息,为待测样本找到更贴切的近邻训练样本;最后,根据近邻训练样本的标签信息可以计算待测样本的标签后验概率值,预测出待测样本相应的标签.
3.1 标签粒化及特征加权
互信息能够有效度量2个变量间的关联性,用其度量标签对特征的依赖度.互信息值越大,说明特征含有标签分类的信息越多,该特征越重要,权重系数越高,因此特征的权重系数与其含有的标签分类信息等价.
定义5. 特征fi对整个标签空间L的重要度,即特征fi的权重系数ωi为
ωi=I(fi;L),
其中,I(fi;L)表示特征fi∈F与标签空间L的互信息.I(fi;L)由定义4可得:
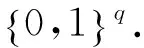
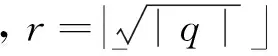
目前粒计算中主要的粒化方法有粗糙集理论、模糊集理论、聚类分析等[13-14].本文考虑聚类分析中流行的k均值(k-means)聚类算法来粒化标签空间,为了防止粒化时出现标签不平衡问题,即有的标签粒中标签数过多,不能有效减少标签组合的数量,降低算法复杂度,因此采用平衡k均值(balancedk-means)聚类算法[27],将标签均匀地分散到各个标签粒中,具体的标签粒化过程如算法1所示.
往往同一个特征对不同标签粒的重要度不同,因此需对每一个标签粒Ge,计算其对应的特征权重系数.
定义6. 对标签粒Ge,特征fi的权重系数为
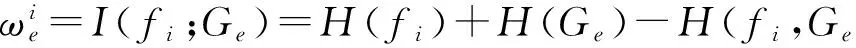
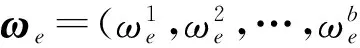
算法1. 标签粒化过程.
输入:标签空间L、训练集T={(X1,Y1),(X2,Y2),…,(Xn,Yn)}、标签粒个数r、迭代次数iter;
输出:r个标签粒.
步骤1. 对每个标签粒Gi和粒中心gi初始化,将Gi赋值为φ,从L中随机选择标签到gi.
步骤2. 将标签粒化到各个粒中:
WHILEiter>0
FORlj∈L
步骤2.1. 计算lj到每个粒中心gi在数据集T中的距离dij,令φ表示lj,将循环信号flag设为真;
步骤2.2. 对lj粒化:
WHILEflag
① 找到离φ最近的粒中心gk,将lj插入Gk中,根据距离大小对Gk中的标签进行排序;
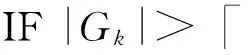
③ 将Gk中排序最后一个标签赋值给φ,并把该标签从Gk去除,把dkφ设为∞;
④ ELSE将循环信号flag设为假;
⑤ END IF
END WHILE
END FOR
重新计算各粒中心,迭代次数iter减1.
END WHILE
步骤3. 得到标签粒G1,G2,…,Gr.
3.2 近邻选择
以往的算法在寻找近邻、度量样本间的相似度和计算样本间距离时,对所有特征给予相同的权重,不考虑特征间重要度的差异,这里以欧氏距离为例,欧氏距离是kNN算法中常用的一种样本距离度量,样本Xi与Xj的距离计算如下:
而往往不同特征含有的标签分类信息不同,需将特征重要度的差异体现在距离中,计算出特征加权的距离.
定义7. 对于标签粒Ge,基于特征的权重信息ωe得到样本间特征加权的欧氏距离:
性质3. 特征加权的欧氏距离与一般的欧氏距离有关系:
De(Xi,Xj)=d(ωeXi,ωeXj).
证明.
证毕.

在标签粒Ge上,样本X得到一个与标签已知的训练样本的加权欧氏距离集De={De(X,X1),De(X,X2),…,De(X,Xn)}.对距离集De中的距离值升序排列后,第k个距离值设为阈值t,获得样本X在标签粒Ge上训练集中的k个最近邻训练样本Ne(X)={Xi|De(X,Xi)≤t}.
3.3 标签预测
根据k个近邻Ne(X),基于经典的ML-kNN算法[9],预测标签未知的测试样本X含有标签粒Ge中标签的概率值,将得到的各标签粒的结果最后组合得到测试样本X的标签概率向量P=(p1,p2,…,pq),由标签概率向量可以得到预测的标签向量Y′=(y1′,y2′,…,yq′).
算法2. 粒化特征加权的多标签k近邻算法.
输入:测试样本X、近邻数k、训练集T={(X1,Y1),(X2,Y2),…,(Xn,Yn)}、标签粒个数r、迭代次数iter、标签空间L;
输出:X的标签概率向量P、标签向量Y′.
步骤1. 根据算法1对标签空间L进行粒化,得到标签粒Ge(1≤e≤r).
步骤2. 对每个标签粒进行如下处理:
FORe=1 tor
步骤2.1. 根据式(9)得到关于标签粒Ge的特征系数ωe;
步骤2.2. 对训练样本和测试样本的特征进行加权得到ωeXi(1≤i≤n)和ωeX;
步骤2.3. 根据式(10)计算测试样本X与所有训练样本Xi的加权距离,找到X的k个近邻训练样本Ne(X);
FORlj∈Ge
步骤2.4. 根据经典ML-kNN算法[9],统计出Ne(X)中拥有标签lj的样本个数CX(lj),得到X含有标签lj的概率预测值:
END FOR
END FOR
步骤3. 将所有标签的概率预测值组合后得到X所有的标签概率:
P=(p1,p2,…,pq).
步骤4. 由标签概率得到X的预测标签向量Y′=(y1′,y2′,…,yq′),如果pj≥0.5,则yj′=1,否则yj′=0.
4 数据实验
4.1 数据集及实验设置
为了验证算法的有效性,本文选取了来自Mulan Library[29]的涵盖多个领域的5个真实世界的多标签数据集进行实验,多标签数据集对应的名称、领域、样本数量、特征维度、标签空间中标签数量、标签基数等详细信息如表1所示:
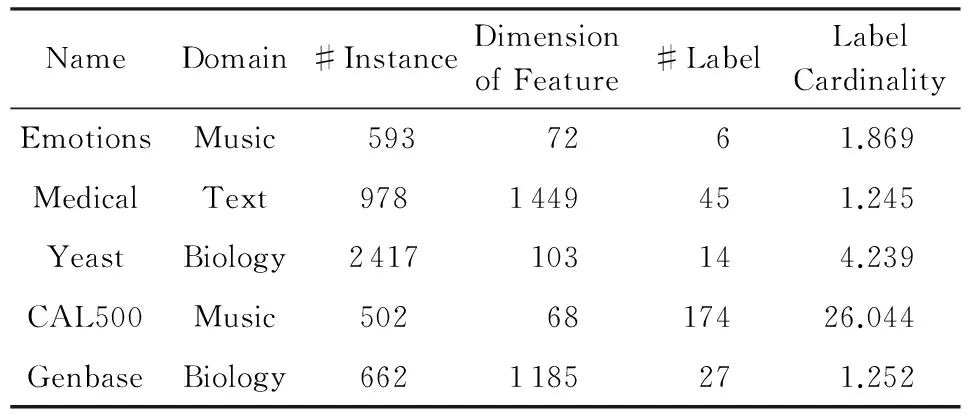
Table 1 Multi-Label Datasets Used in the Experiments表1 多标签数据集
1) Emotions数据集[30]包含了593个标注了情感的歌曲样本,每个样本由72个特征来描述,即8韵律特征和64音色特征和6个可能的情感标签表示,每个标签代表了一个基于Tellegen-Watson-Clark模型的歌曲情感聚类.
2) Medical数据集[31]包含了978个病历样本,其含有1 449个特征,每个样本的特征由诊断历史记录和观察到的症状组成,标签则是45种ICD-9-CM疾病编码.
3) Yeast数据集[22]用于描述酵母菌的基因功能分类,其包含了2 417个样本,每个样本表示一个yeast基因,每个基因对应于一个103维的特征向量,标签空间是14种可能的基因功能.
4) CAL500数据集[32]含有502首流行乐曲,以及174个风格、情绪、乐器等语义关键词,每个样本由68个特征表示.
5) Genbase数据集[33]是一个关于蛋白质功能分类的多标签数据集,由662个蛋白质样本组成,每个蛋白质由1 185个蛋白基序表示.标签为27个蛋白家族功能类别,如抗氧化酶、结构蛋白、受体等.
Medical和Genbase数据集的特征值为离散型,而其他数据集的特征值为连续型.对于离散型的特征,可以很容易计算其与标签的互信息,而连续型的特征则比较困难.因此,我们对连续型特征采用二值等距区间离散化方法.
除了经典的多标签懒惰学习算法ML-kNN[9],还将本文所提算法与其他常见的多标签学习算法RankSVM[20],BPMLL[21],BRkNN[12]进行了对比.所有的实验在Matlab2012b上完成.为了取得最佳效果,根据相应文献的建议选取最优的参数配置.ML-kNN算法中,近邻数为10、平滑因子为1;RankSVM选用了度为8的多项式核函数;BPMLL的隐藏层节点数为特征数的20%;BRkNN的近邻数为10.根据表1统计的多标签数据集的标签数,实验中本文算法GFWML-kNN在数据集Emotions,Medical,Yeast,CAL500,Genbase的标签粒数分别为2,6,3,15,5.
4.2 评价指标
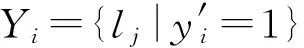
1) 汉明损失(Hamming loss,Hamloss).度量算法预测出的标签信息与实际的标签信息的平均差异值:

2) 1-错误率(one error,Onerror).计算算法预测的排序最靠前的标签实际不是测试样本的标签的比率:
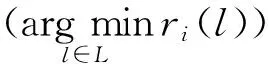
3) 覆盖率(Coverage).计算要囊括测试样本实际包含的所有标签所需最大排序距离:
4) 排序损失(ranking loss,Rankloss).评价有多少测试样本实际不包含的标签比实际包含的标签排序高:
5) 平均准确率(average precision,Avgprec).用于评价给定一个测试样本实际包含的标签,平均有多少实际包含的标签排序比其高:
前面4项评价指标的值越低说明算法效果越好,而平均准确率值越高则说明算法效果越好.
4.3 实验结果
4.3.1 近邻参数选择
首先讨论了近邻数k的选择以及验证标签空间的粒化没有对标签相关性造成过大的损失.以Emotions数据集为例,图1~5给出了Emotions数据集的5项评价指标随着近邻数k增加的变化曲线.其中,k以步长2从2增加到20.图1~5中,ML-kNN曲线表示经典的多标签懒惰学习算法;FWML-kNN曲线表示未粒化的特征加权ML-kNN算法;GFWML-kN曲线表示粒化的特征加权ML-kNN算法.
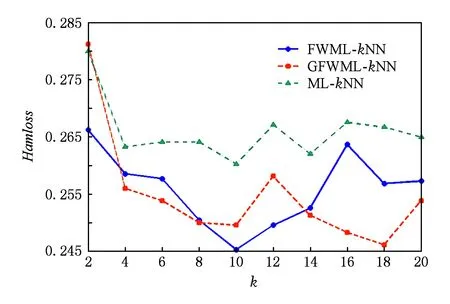
Fig. 1 Hamming loss of varying the number of nearest neighbors图1 汉明损失随着近邻数增加的变化曲线
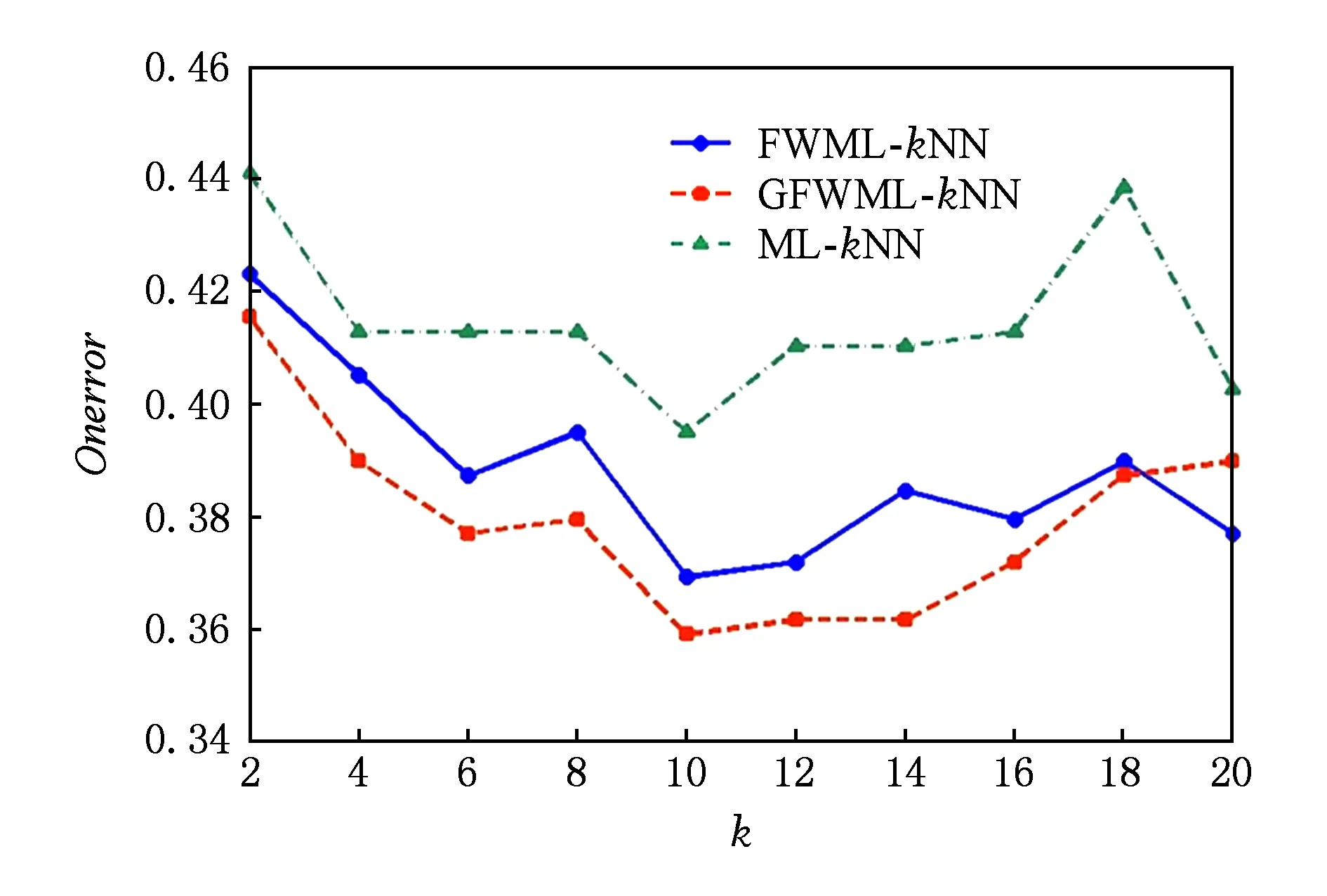
Fig. 2 One error of varying the number of nearest neighbors图2 1-错误率随着近邻数增加的变化曲线
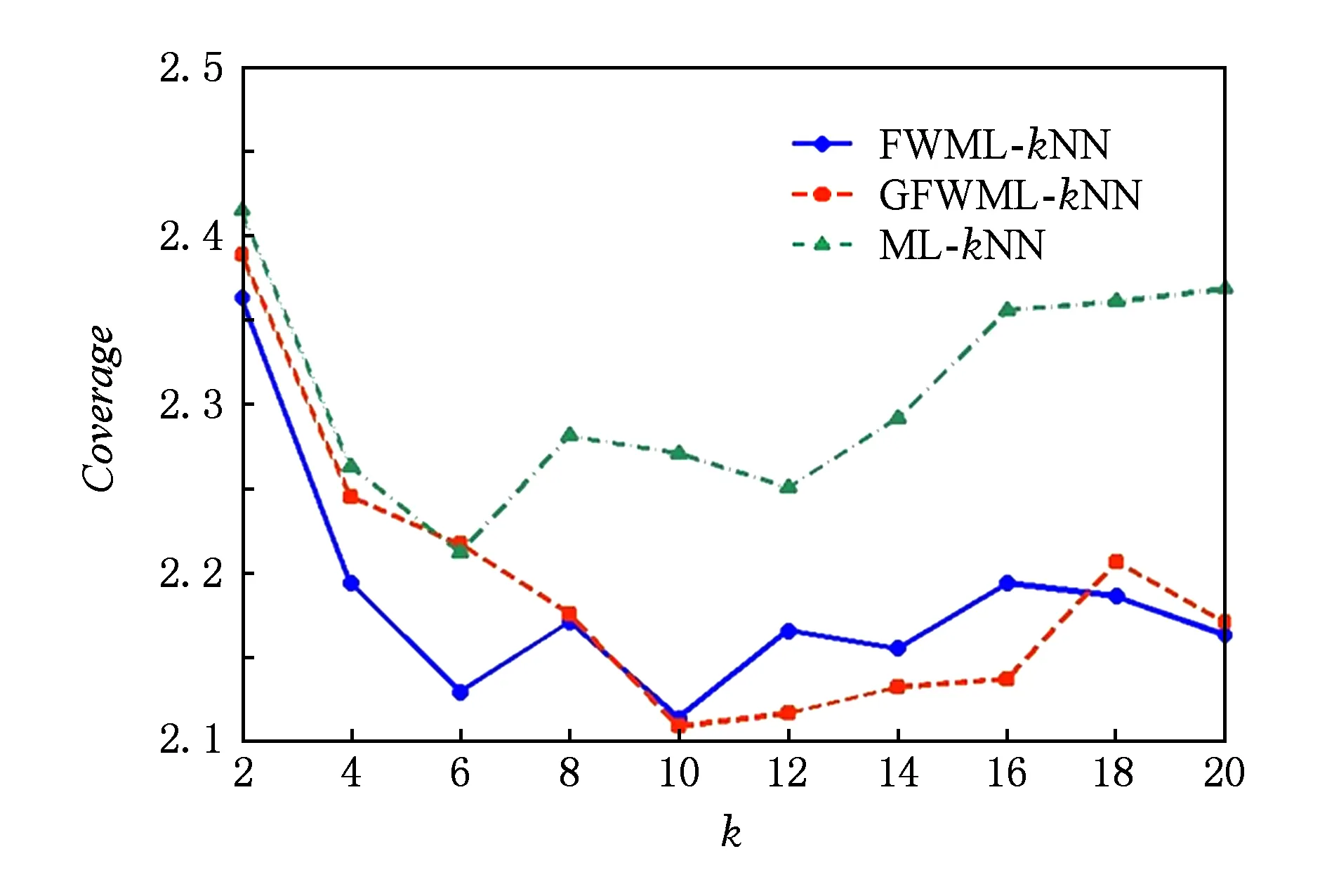
Fig. 3 Coverage of varying the number of nearest neighbors图3 覆盖率随着近邻数增加的变化曲线
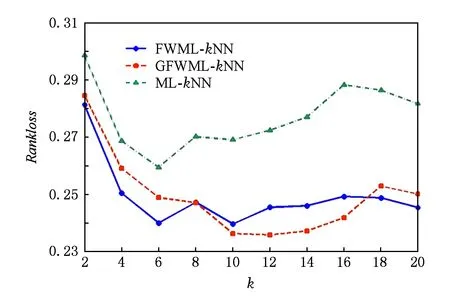
Fig. 4 Ranking loss of varying the number of nearest neighbors图4 排序损失随着近邻数增加的变化曲线
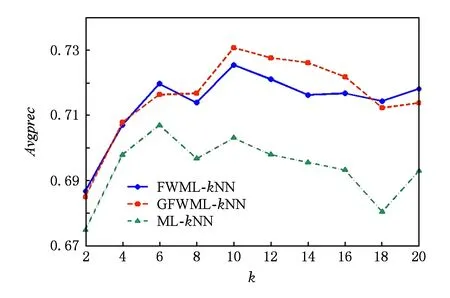
Fig. 5 Average precision of varying the number of nearest neighbors图5 平均准确率随着近邻数增加的变化曲线
在各项评价指标上,粒化和未粒化的特征加权ML-kNN以及经典的ML-kNN的性能均随着近邻数k的增加而快速提升,而后达到最优值后逐渐略微下降.其中,粒化和未粒化的特征加权ML-kNN的性能变化趋势十分接近,且在各个近邻数上基本都优于经典ML-kNN.当近邻数k=10,性能最优,因此,本文近邻数设为10.
GFWML-kNN算法取得的最优值除了在汉明损失Hamloss上比未粒化的特征加权多标签学习懒惰算法略大一点,在1-错误率Onerror、排序损失Rankloss和平均精度Avgprec上均要优于未粒化的算法,两者取得相同的覆盖率Coverage最优值.综上,GFWML-kNN算法的性能不但不差于未粒化的特征加权ML-kNN算法,反而略优,说明GFWML-kNN算法的粒化几乎保留了标签间的相关性,找到更合适的近邻,提高了算法的性能.
4.3.2 实验对比
实验采用了十折交叉验证(ten-fold cross-validation)方法,实验结果用均值±标准差表示.表2~5表示了各个多标签学习算法在多标签数据集Emotions,Medical,Yeast,CAL500,Genbase上取得的实验结果,其中各项评价指标的最优值用粗体标注,↓(↑)表示该项评价指标值越小(越大)算法效果越好.
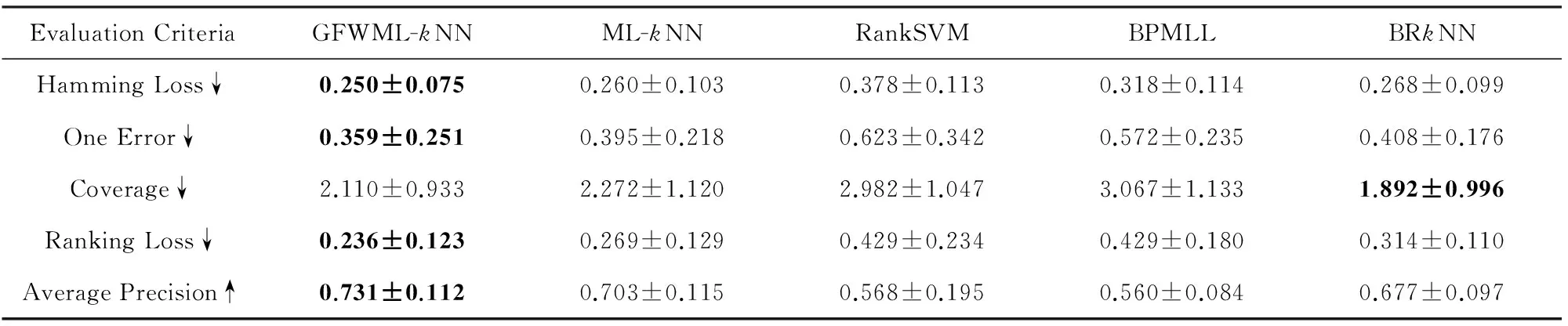
Table 2 Experimental Results Obtained by Multi-label Algorithms (Mean±Std.deviation) on the Emotions Dataset表2 Emotions数据集的实验结果(均值±标准差)
↓:The smaller the value is, the better the performance is. ↑:The larger the value is, the better the performance is.
从表2可以看出,GFWML-kNN在绝大多数评价指标上取得了较好的性能.除了在覆盖率Coverage上仅次于BRkNN,但BRkNN在其他4项评价指标上算法性能明显劣于GFWML-kNN,因此总体来说GFWML-kNN优于BRkNN.而对于其他3种对比算法ML-kNN,RankSVM,BPMLL,GFWML-kNN算法在所有评价指标上均取得了更好的性能,尤其相比于经典的多标签懒惰学习算法ML-kNN.所以在Emotions数据集上,GFWML-kNN算法的性能明显优于其他对比算法的性能.
对于Medical数据集,由表3可知,在评价指标汉明损失Hamloss、1-错误率Onerror和平均精度Avgprec上,GFWML-kNN取得最优值,排序损失Rankloss的最优值和覆盖率Coverage的最优值则分别由BPMLL和BRkNN获得,RankSVM在所有评价指标上取得最差值.GFWML-kNN算法在评价指标排序损失Rankloss上,性能略微差于BPMLL,而明显优于剩下的3种对比算法.虽然BRkNN在覆盖率Coverage表现最优,但其在其他4种评价指标上较差,特别是明显差于GFWML-kNN.此外,相较于ML-kNN算法,本文所提算法GFWML-kNN在各项评价指标上的性能均显著优于该算法.
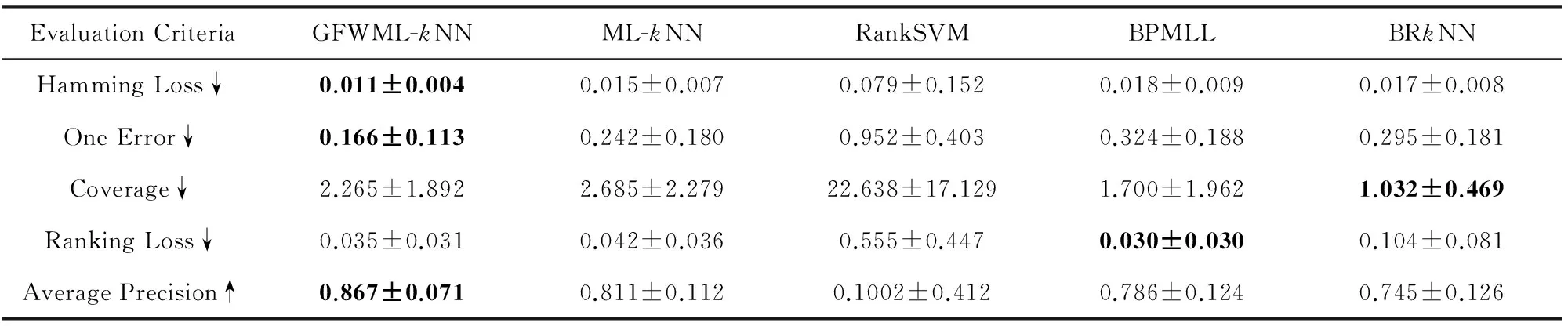
Table 3 Experimental Results Obtained by Multi-label Algorithms (Mean±Std.deviation) on the Medical Dataset表3 Medical数据集的实验结果(均值±标准差)
↓:The smaller the value is, the better the performance is. ↑:The larger the value is, the better the performance is.
如表4所示,本文所提算法GFWML-kNN在汉明损失Hamloss、排序损失Rankloss和平均精度Avgprec上表现最优,而在1-错误率Onerror上略次于RankSVM和BPMLL,但在覆盖率Coverage上优于这2种算法. 相较于GFWML-kNN,BRkNN算法依旧在覆盖率Coverage上表现较好,在剩下的评价指标表现较差.所以在Yeast数据集,GFWML-kNN算法整体上略好于其他对比算法.
↓:The smaller the value is, the better the performance is. ↑:The larger the value is, the better the performance is.
在CAL500数据集上,虽然GFWML-kNN的算法效果没有在对比的算法中取得最优值,但从表5可见,GFWML-kNN,ML-kNN,RankSVM,BPMLL在所有指标上几乎没有差异,而BRkNN虽在覆盖率Coverage上表现最优,但其也在剩下4项评价指标上表现最差,所以总体而言在CAL500数据集上前4种算法表现无异,BRkNN表现较差.特别地本文所提算法GFWML-kNN略优于ML-kNN.
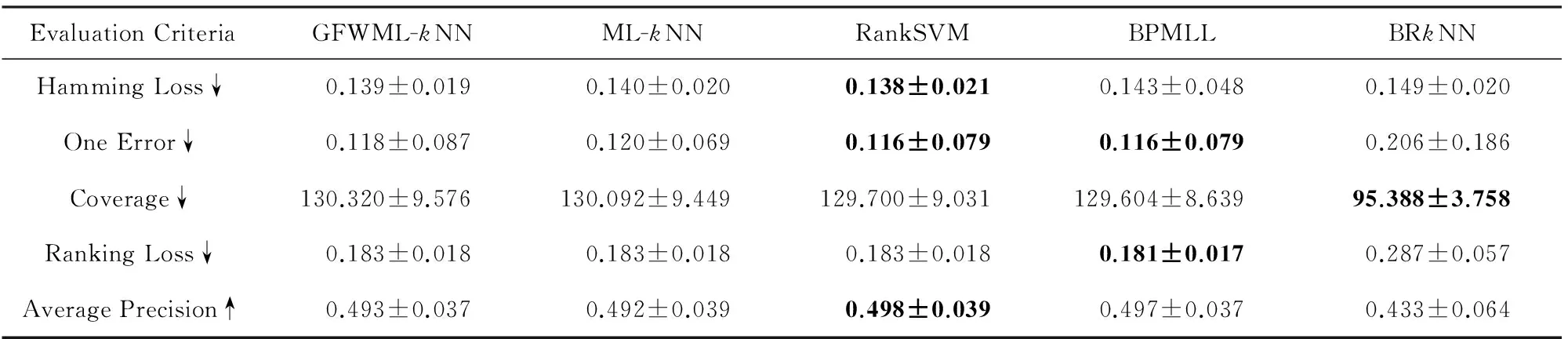
Table 5 Experimental Results Obtained by Multi-label Algorithms (Mean±Std.deviation) on the CAL500 Dataset表5 CAL500数据集的实验结果(均值±标准差)
↓:The smaller the value is, the better the performance is. ↑:The larger the value is, the better the performance is.
Genbase数据集中平均每个样本含有的标签数极少,所以除了RankSVM算法外,其他算法都在Genbase数据集上取得了很好的结果.从表6可知,BPMLL在1-错误率Onerror上取得最佳值,其预测的每个相关性最大的标签均为测试样本实际含有的标签.GFWML-kNN取得的排序损失Rankloss和平均精度Avgprec优于其它算法,1-错误率Onerror上和覆盖率Coverage上分别仅次于BPMLL和BRkNN. 各个算法取得的汉明损失Hamloss差异性较小. 虽然在该数据集上ML-kNN表现已经很优异,但GFWML-kNN除了汉明损失Hamloss外在各项指标上仍显著优于ML-kNN.因此,在Genbase数据集,GFWML-kNN整体上好于其他算法.
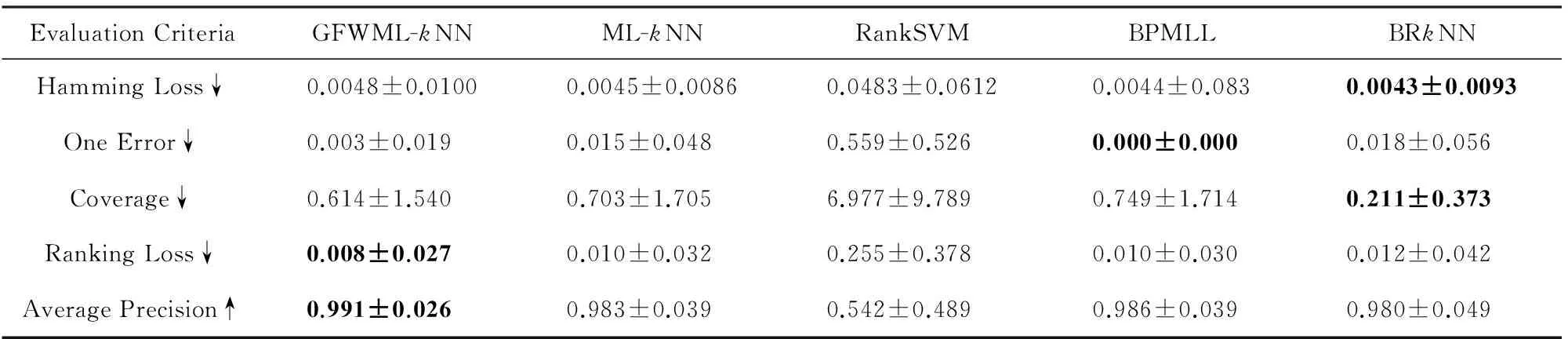
Table 6 Experimental Results Obtained by Multi-label Algorithms (Mean±Std.deviation) on the Genbase Dataset
↓:The smaller the value is, the better the performance is. ↑:The larger the value is, the better the performance is.
从整个数据集来看,所有算法中GFWML-kNN算法的整体算法效果表现突出.对比于经典的多标签懒惰学习算法ML-kNN,GFWML-kNN在所有评价指标上都好于该算法,尤其是在特征数远多于标签数的Emotions,Medical,Genbase数据集上显著优于该算法,因为特征数越多,越不相关的特征越多,特征间重要度的差异越大.对于另一种基于kNN的多标签学习算法BRkNN,本文所提算法除了评价指标覆盖率外,均明显优于该算法.这些结果与分析验证了在寻找k近邻时特征加权的有效性.
5 结 论
以往基于kNN的多标签学习算法,在寻找近邻时,往往把所有特征同等对待,而且大多将多标签学习问题分解为多个独立的二类分类问题,对每个标签单独求解,忽略了标签间的相关性.因此本文提出了一种基于互信息的粒化特征加权多标签学习k近邻算法.该算法考虑了特征对标签分类的重要度,为特征赋予相应的权重,并将标签间的相关性融入到特征的权重系数中,这样更利于寻找更相关的近邻样本,提升标签预测的准确性.而基于粒计算解决复杂问题的思想,粒化标签空间以解决标签组合爆炸性问题,而极少损失标签间的相关性.实验结果表明本文所提算法GFWML-kNN算法整体上能取得较好的预测效果,而且优于以往将所有特征同等对待的算法,验证了考虑特征重要度和标签间的相关性是必要的.但该算法对于含有大量标签的数据集处理速度较慢,寻找一个更合理的粒化方式是未来的研究工作.
[1]Tsoumakas G, Katakis I, Vlahavas I. Mining multi-label data[G] //Data Mining and Knowledge Discovery Handbook. Berlin: Springer, 2010: 667-685
[2]Tsoumakas G, Katakis I. Multi label classification: An overview[J]. International Journal of Data Warehousing and Mining, 2007, 3(3): 1-13
[3]Zhang Minling, Zhou Zhihua. A review on multi-label learning algorithms[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(8): 1819-1837
[4]Schapire R, Singer Y. BoosTexter: A boosting-based system for text categorization[J]. Machine Learning, 2000, 39(2/3): 135-168
[5]Yu Ying, Pedrycz W, Miao Duoqian. Neighborhood rough sets based multi-label classification for automatic image annotation[J]. International Journal of Approximate Reasoning, 2013, 54(9): 1373-1387
[6]Pavlidis P, Weston J, Cai J, et al. Combining microarray expression data and phylogenetic profiles to learn functional categories using support vector machines[C] //Proc of the 5th Annual Int Conf on Computational Biology. New York: ACM, 2001: 242-248
[7]Zhang Gang, Zhong Ling, Huang Yonghui. A machine learning method for histopathological image automatic annotation[J]. Journal of Computer Research and Development, 2015, 52(9): 2135-2144 (in Chinese)(张钢, 钟灵, 黄永慧. 一种病理图像自动标注的机器学习方法[J]. 计算机研究与发展, 2015, 52(9): 2135-2144)
[8]Altman N. An introduction to kernel and nearest-neighbor nonparametric regression[J]. The American Statistician, 1992, 46 (3): 175-185
[9]Zhang Minling, Zhou Zhihua. ML-KNN: A lazy learning approach to multi-label learning[J]. Pattern Recognition, 2007, 40(7): 2038-2048
[11]Brinker K, Hüllermeier E. Case-based multilabel ranking[C] //Proc of the 20th Int Joint Conf on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2007: 702-707
[12]Spyromitros E, Tsoumakas G, Vlahavas I. An empirical study of lazy multilabel classification algorithms[G] //LNCS 5138: Proc of the 5th Hellenic Conf on Artificial Intelligence. Berlin: Springer, 2008: 401-406
[13]Yao Yiyu. Interpreting concept learning in cognitive informatics and granular computing[J]. IEEE Trans on Systems, Man, and Cybernetics, Part B: Cybernetics, 2009, 39(4): 855-866
[14]Yao Yiyu, Zhao Liquan. A measurement theory view on the granularity of partitions[J]. Information Sciences, 2012, 213(23): 1-13
[15]Boutell M, Luo J, Shen X, et al. Learning multi-label scene classification[J]. Pattern Recognition, 2004, 37(9): 1757-1771
[16]Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification[G] //LNAI 5782: Proc of the 20th European Conf on Machine Learning. Berlin: Springer, 2009: 254-269
[17]Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification[J]. Machine Learning, 2011, 85(3): 335-359
[18]Hüllermeier E, Fürnkranz J, Cheng W, et al. Label ranking by learning pairwise preferences[J]. Artificial Intelligence, 2008, 172(16): 1897-1916
[19]Tsoumakas G, Katakis I, Vlahavas I. Random k-labelsets for multilabel classification[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(7): 1079-1089
[20]Read J, Pfahringer B, Holmes G. Multi-label classification using ensembles of pruned sets[C] //Proc of the 8th IEEE Int Conf on Data Mining. Piscataway, NJ: IEEE, 2008: 995-1000
[21]Clare A, King R. Knowledge discovery in multi-label phenotype data[G] //LNCS 2168: Proc of the 5th European Conf on Principles of Data Mining and Knowledge Discovery. Berlin: Springer, 2001: 42-53
[22]Elisseeff A, Weston J. A kernel method for multi-labelled classification[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2001: 681-687
[23]Zhang Minling, Zhou Zhihua. Multilabel neural networks with applications to functional genomics and text categorization[J]. IEEE Trans on Knowledge and Data Engineering, 2006, 18(10): 1338-1351
[24]Yu Ying, Pedrycz W, Miao Duoqian. Multi-label classification by exploiting label correlations[J]. Expert Systems with Applications, 2014, 41(6): 2989-3004
[25]Zhang Minling. An improved multi-label lazy learning approach[J]. Journal of Computer Research and Development, 2012, 49(11): 2271-2282 (in Chinese)(张敏灵. 一种新型多标记懒惰学习算法[J]. 计算机研究与发展, 2012, 49(11): 2271-2282)
[26]Shannon C. A mathematical theory of communication[J]. Bell System Technical Journal, 1948, 27(3): 379-423
[27]Shannon C. A mathematical theory of communication[J]. Bell System Technical Journal, 1948, 27(4): 623-666
[28]Tsoumakas G, Katakis I, Vlahavas I. Effective and efficient multi-label classification in domains with large number of labels[C] //Proc of ECML/PKDD 2008 Workshop on Mining Multidimensional Data. Berlin: Springer, 2008: 287-313
[29]Tsoumakas G, Spyromitros-Xiousfis E, Vilcek I. Mulan:a java library for multi-label learning[J]. Journal of Machine Learning Research, 2011, 12(7): 2411-2414
[30]Trohidis K, Tsoumakas G, Kalliris G, et al. Multi-label classification of music into emotions[J]. Eurasip Journal on Audio Speech & Music Processing, 2008, 2011(1): 325-330
[31]Pestian J, Brew C, Matykiewicz P, et al. A shared task involving multi-label classification of clinical free text[C] //Proc of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2007: 97-104
[32]Turnbull D, Barrington L, Torres D, et al. Semantic annotation and retrieval of music and sound effects[J]. IEEE Trans on Audio, Speech, and Language Processing, 2008,16(2): 467-476
[33]Diplaris S, Tsoumakas G, Mitkas P, et al. Protein classification with multiple algorithms[G] //LNCS 3746: Proc of the 10th Panhellenic Conf Informatics (PCI 2005). Berlin: Springer, 2005: 448-456
Mutual Information Based Granular Feature Weightedk-Nearest Neighbors Algorithm for Multi-Label Learning
Li Feng, Miao Duoqian, Zhang Zhifei, and Zhang Wei
(Department of Computer Science and Technology, Tongji University, Shanghai 201804)(Key Laboratory of Embedded Systems and Service Computing (Tongji University), Ministry of Education, Shanghai 201804)
All features contribute equally to compute the distance between any pair of instances when finding the nearest neighbors in traditionalkNN based multi-label learning algorithms. Furthermore, most of these algorithms transform the multi-label problem into a set of single-label binary problems, which ignore the label correlation. The performance of multi-label learning algorithm greatly depends on the input features, and different features contain different knowledge about the label classification, so the features should be given different importance. Mutual information is one of the widely used measures of dependency of variables, and can evaluate the knowledge contained in the feature about the label classification. Therefore, we propose a granular feature weightedk-nearest neighbors algorithm for multi-label learning based on mutual information, which gives the feature weights according to the knowledge contained in the feature. The proposed algorithm firstly granulates the label space into several label information granules to avoid the problem of label combination explosion problem, and then calculates feature weights for each label information granule, which takes label combinations into consideration to merge label correlations into feature weights. The experimental results show that the proposed algorithm can achieve better performance than other common multi-label learning algorithms.
mutual information; feature weight; granulation; multi-label learning;k-nearest neighbors

Li Feng, born in 1989. PhD candidate in Tongji University. Student member of CCF. His main research interests include multi-label learning and granular computing.

Miao Duoqian, born in 1964. Professor and PhD supervisor in Tongji University. Distinguished member of CCF. His main research interests include rough sets, granular computing, and machine learning.

Zhang Zhifei, born in 1986. PhD and lecturer in Tongji University. Member of CCF. His main research interests include natural language processing and machine learning (zhifeizhang@tongji.edu.cn).

Zhang Wei, born in 1978. PhD candidate in Tongji University. Student member of CCF. Her main research interests include rough sets and machine learning (zhangweismile@163.com).
2016-05-24;
2016-09-06
国家自然科学基金项目(61273304,61573255); 高等学校博士学科点专项科研基金项目(20130072130004); 上海市自然科学基金项目(14ZR1442600) This work was supported by the National Natural Science Foundation of China (61273304, 61573255), the Specialized Research Fund for the Doctoral Program of Higher Education of China (20130072130004), and the Natural Science Foundation of Shanghai(14ZR1442600).
苗夺谦(dqmiao@tongji.edu.cn)
TP18
猜你喜欢
农机科技推广(2022年7期)2022-08-16
中国现代中药(2021年7期)2021-09-06
河南农业科学(2020年7期)2020-07-22
广西农学报(2019年4期)2019-11-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年1期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
Coco薇(2015年11期)2015-11-09
