
知识嵌入的贝叶斯MA型模糊系统
2017-05-13 03:50顾晓清王士同
计算机研究与发展 2017年5期
顾晓清 王士同
1(江南大学数字媒体学院 江苏无锡 214122)2 (常州大学信息科学与工程学院 江苏常州 213164) (czxqgu@163.com)
知识嵌入的贝叶斯MA型模糊系统
顾晓清1,2王士同1
1(江南大学数字媒体学院 江苏无锡 214122)2(常州大学信息科学与工程学院 江苏常州 213164) (czxqgu@163.com)
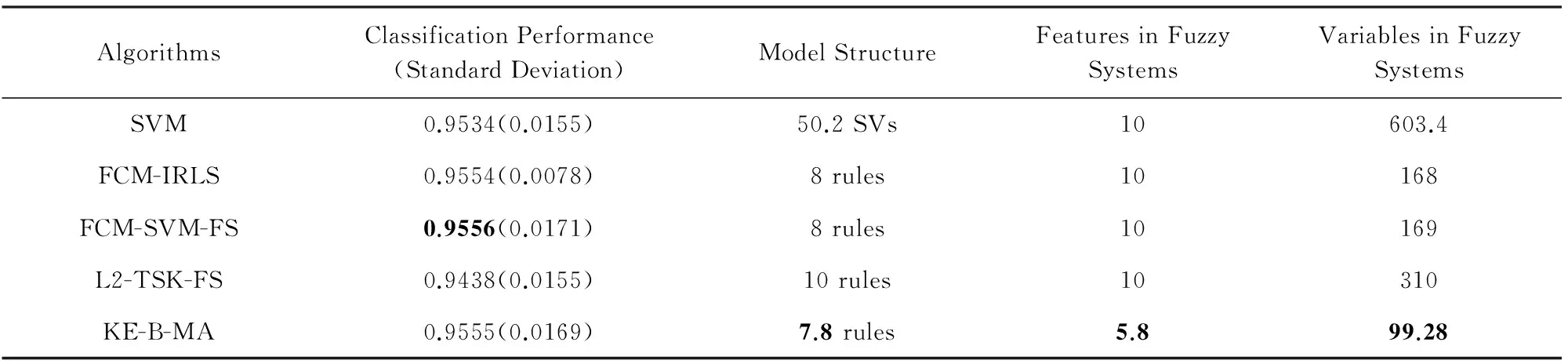
模糊系统的独特优势在于其高度的可解释性,然而传统的基于聚类的模糊系统往往需要使用输入空间的全部特征且常出现模糊集交叉的现象,系统的可解释性不高;此外,此类模糊系统对高维数据处理时还会因使用大量的特征而使规则过于复杂.针对此问题,探讨了一种知识嵌入的贝叶斯MA型模糊系统(knowledge embedded Bayesian Mamdan-Assilan type fuzzy system, KE-B-MA).首先,KE-B-MA使用DC(don’t care)方法进行知识嵌入的模糊集划分,对模糊隶属度函数中心和输入空间特征的选择进行有效指导,其获得的规则可对应于不同的特征空间.其次,KE-B-MA基于贝叶斯推理使用马尔可夫蒙特卡洛(Markov chain Monte Carlo, MCMC)方法对模糊规则的前后件参数同时学习,所得结果为全局最优解.实验结果表明:与一些经典模糊系统相比,KE-B-MA具有令人满意的分类性能且具有更强的可解释性和清晰性.
分类;贝叶斯推理;Mamdan-Assilan型模糊系统;知识嵌入;马尔可夫链蒙特卡洛方法
目前,基于规则的模糊系统已成功地应用于系统建模、模式识别和图像处理等领域[1-5].模糊系统与其他人工智能方法的主要区别在于:1)模糊系统具备不确定和模糊信息的处理能力,能够将自然语言直接转译成与人类推理机制相似的模糊规则;2)模糊系统不仅具有强大的学习能力,其构建的模糊规则还具有高度的可解释性,而这一特性是其他人工智能方法所不具备的.
广泛使用的提取模糊规则的方法主要可分为3类:
1) 通过对输入空间的固定划分或基于网格的空间划分方法来获取模糊规则[6-8],其优点是空间的模糊划分清晰度高,但在对高维数据进行训练时,会因采用大量的特征而使其规则变得过于复杂.假设使用均匀5网格的方法对输入空间的每一维进行模糊划分,对于特征数是n的数据集而言,最终提取的模糊规则数为5n.为此,进化算法和自我评价学习算法[9-11]常用于模糊规则的结构简化.
2) 使用支持向量机(support vector machine,SVM)技术[12-13],将每一个支持向量作为一条模糊规则.SVM技术遵循结构风险最小化原则,能够最大限度地减少模型的泛化误差,然而支持向量的数量通常是很大的,尤其是对于复杂的分类任务,因此这类方法设计得到的模糊规则也易出现规模较大且易冗余的情况.为此,研究者提出了一系列的删减准则用于模糊规则的约减[14].
3) 使用聚类算法,模糊规则的个数等于聚类的个数.文献[15-16]中,模糊规则的前件参数则使用自适应模糊聚类算法获得,模糊规则的后件参数则使用SVM的方法获得;文献[17]使用密度聚类对模糊系统的结构进行初始化;文献[18-20]使用经典的模糊C均值聚类(fuzzy c-means, FCM)算法来获得输入空间的模糊划分,并使用Ho-Kashyap算法得到模糊规则的后件参数;文献[21]利用FCM聚类算法确定模糊规则的前件参数后,基于极大极小概率学习理论产生了一种有分类可靠性保证的模糊分类器.虽然近几年基于聚类的模糊系统得到了一定的发展,但这类方法普遍存在2点不足:
1) 模糊空间的划分通过聚类算法获得,通常情况下不能保证所得的聚类中心,即模糊集中心具有可解释性,得到的模糊集往往存在过度的交叉或重叠现象,模糊划分的清晰性自然得不到保证.
2) 模糊规则前件对应于输入空间的所有特征,在处理高维数据时,每条规则所对应模糊集的数量大大增加,模糊规则前件则变得愈加复杂,规则的可解释性也必然大大下降.
针对上述不足,本文提出了全新的知识嵌入的贝叶斯MA型模糊系统(knowledge embedded Bayesian Mamdan-Assilan type fuzzy system, KE-B-MA).鉴于MA(Mamdan-Assilan)型模糊系统的简单性和受到广泛应用等特点,本文将其作为研究对象.首先,通过DC方法(don’t care approach)实现对模糊隶属中心和输入空间特征的选择,其获得的模糊划分物理意义明显且有效降低所构建系统的复杂性.其次,引入贝叶斯概率框架并使用马尔可夫链蒙特卡洛(Markov chain Monte Carlo, MCMC)方法构造一条马尔可夫链,同时对模糊规则的前件和后件参数进行学习,保证获得参数具有全局最优值.因而,本文所提方法能够在保证模糊规则的可解释性的同时兼顾模糊系统分类准确度.
1 相关工作
1.1 MA型模糊系统基本概念
经典模糊系统可分为3类[22-23]:Mamdan型模型、Takagi-Sugeno-Kang型模型和Generalized Fuzzy型模型.其中,Mamdan型模糊系统由于其输出的简洁性,使得构造的模糊规则后件参数具有较高的可解释性受到较多关注.MA型模糊系统的第k个模糊规则的表示为[20]
fk(x)=vk,
其中,k=1,2,…,K,每一条规则都有对应的输入向量x=(x1,x2,…,xd)T,并把输入空间的模糊子集Ak⊂d投影到输出空间的模糊集fk(x).式(1)中d是样本的特征数,K是模糊规则数,and是模糊合取操作为第i维输入在第k条模糊规则中对应的模糊子集,令μk(x)为第k条规则对应的模糊隶属度函数,若采用高斯型隶属函数,则其可以表示为
其中,参数cki和δki分别是隶属函数的中心和方差.在经过一系列的操作及去模糊化处理之后,可得MA型模糊系统的实值输出:
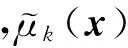
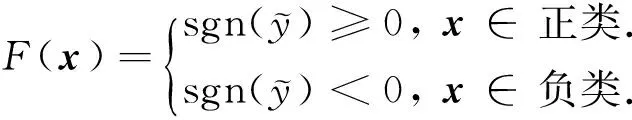
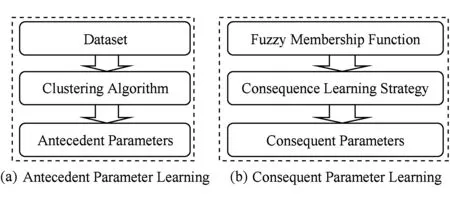
Fig. 1 The cluster based TSK fuzzy classifier’s parameter learning mechanism图1 基于聚类算法的模糊系统参数学习的示意图
1.2 基于模糊聚类和SVM技术的MA型模糊系统
设给定样本X=(x1,x2,…,xN)和对应的标签Y=(y1,y2,…,yN),其中yi∈{-1,+1},1≤i≤N.传统基于模糊聚类的模糊系统参数学习方法如图1所示,模糊系统的规则前件参数可以直接通过模糊聚类算法的学习获得.由于模糊C均值聚类FCM[24]所获得的空间划分具有模糊性,且具有实现简单和有效的优点,其被广泛应用于模糊系统规则前件参数的学习中.此时,式(2)中的隶属度函数中心ck=(ck1,ck2,…,ckd)T为聚类中心,方差δk=(δk1,δk2,…,δkd)T可计算得到:
其中,uj k为输入向量xj=(xj1,xj2,…,xjd)T隶属于第k类的隶属度,尺度参数h为一正常数.
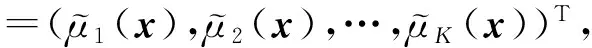
s.t.yi(VTφi+b)≥1-ξi,
ξi≥0,i=1,2,…,N.
其中,后件参数V=(v1,v2,…,vK)T,C′是正则化参数.
通过最优化理论,式(6)可转化为对偶问题:
由此可得后件参数的全局最优解:
最终,对于任意给定的样本x,MA型模糊系统的实值输出为
其中,偏移量b可通过求解式(7)获得.
值得注意的是,偏移量b可以看作是除K条模糊规则之外的第K+1条规则,其形式为
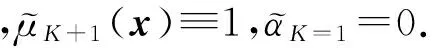
2 知识嵌入的贝叶斯MA型模糊系统
针对第1节分析的传统基于聚类的模糊系统的缺陷,本文探讨了一种知识嵌入的贝叶斯MA型模糊系统,即KE-B-MA的构建方法.KE-B-MA模糊系统的工作原理和参数学习示意图如图2所示.1)KE-B-MA使用DC方法给出系统对应的模糊隶属度函数中心和每条规则使用的输入空间特征;2)构造用于模糊规则前件和后件参数同时学习的概率模型框架;3)使用MCMC方法来估计模型的最大后验概率,得到模型参数的全局最优解.对比图1和图2可知,传统基于聚类的模糊系统前件和后件参数的学习是相对独立的,一旦模糊规则的前件参数通过聚类算法确定后,在随后的模糊规则后件参数学习过程中不能更改.然而聚类方法的本质是按照某种相似程度的度量来完成输入空间的划分,其无法考量模糊系统中输入空间和输出空间之间的联系.KE-B-MA从贝叶斯推理的角度建立输入空间和输出空间之间的联系,保证了在复杂问题中所得模糊系统的分类准确度.
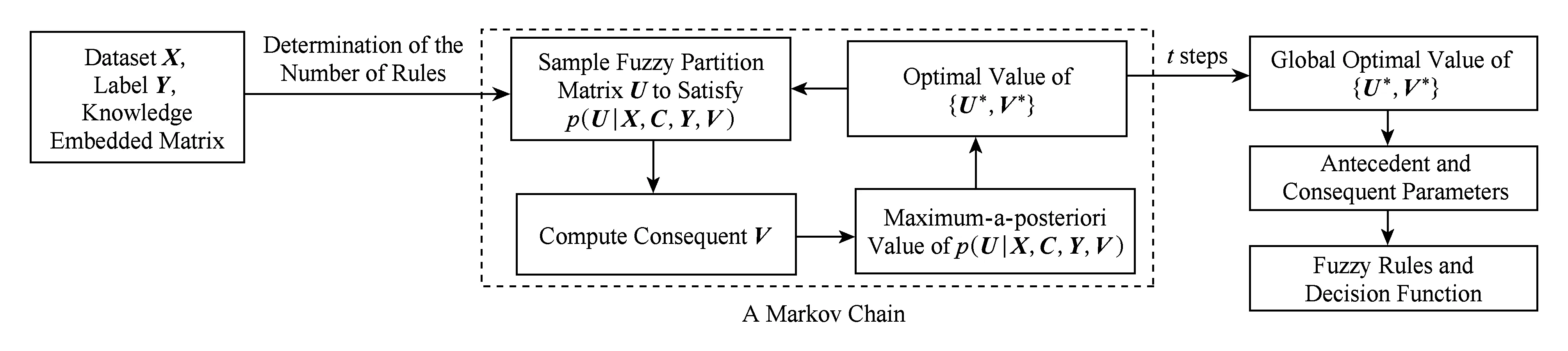
Fig. 2 System diagram of the KE-B-MA and parameter learning mechanism图2 KE-B-MA工作原理和参数学习示意图
2.1 KE-B-MA中模糊规则构建
日常生活和生产活动中通常积累有大量的专家经验,把这些有用的专家经验嵌入到模糊系统中能起到提高模糊规则可解释性的作用.如在糖尿病患者的诊断系统中,胰岛素释放曲线常作为一个特征进行考察.胰岛素释放曲线一般可分为:胰岛素分泌正常型、胰岛素分泌不足型、胰岛素分泌增多型和胰岛素释放障碍型4种.在这一特征进行模糊划分时,如果按照4种胰岛素释放类型的平均数值进行预先设定可得4个具有可解释性的模糊隶属中心.
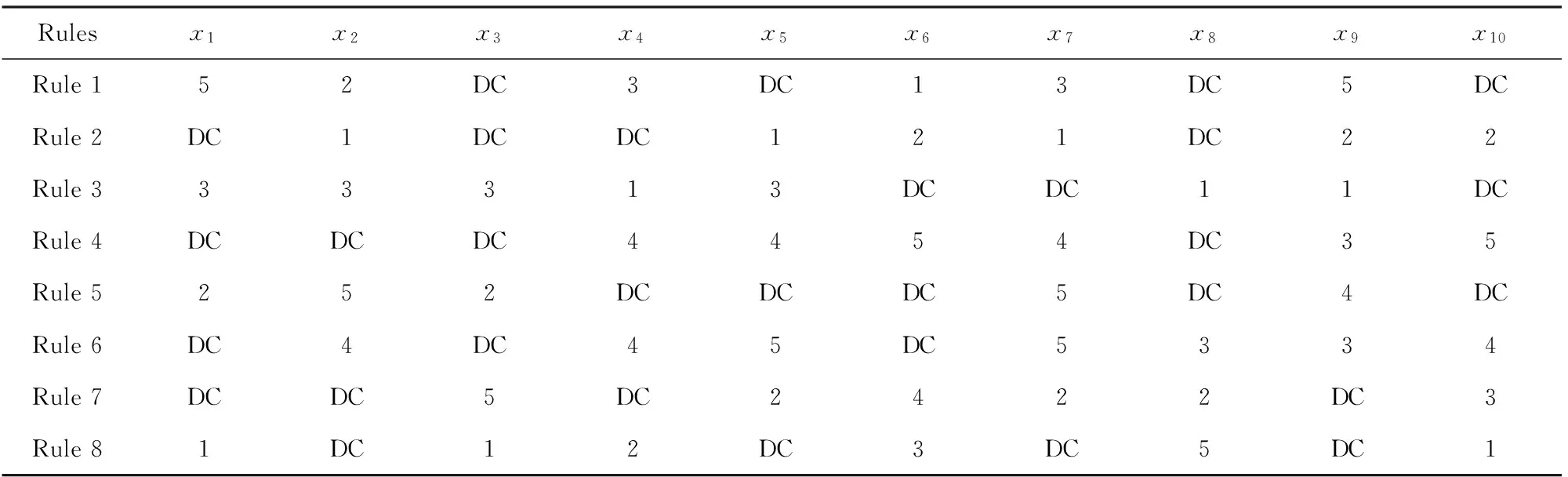
根据这一思路,KE-B-MA模糊系统使用知识嵌入的DC方法[25-26]对每条规则使用的输入空间特征和模糊隶属度函数中心进行选择.DC方法在模糊规则每一维上定义5个高斯型隶属度函数并赋予了其各自的语意标签:very low,low,medium,high,very high,分别用数字1~5表示.隶属度函数中心相应地设定为(0,0.25,0.5,0.75,1);而DC则用来表示特征在规则中不被选择.以下给出KE-B-MA模糊系统对应的模糊规则示例:表1是使用DC方法在样本维度为5的数据集上设置的知识嵌入矩阵.其中第1条规则选择的输入特征(和对应的隶属度函数中心)分别是第1维(0),第2维(0.25)和第5维(0.75),而第3维和第4维不选择;第2条规则上选择的输入特征(和对应的隶属度函数中心)分别是第1(0.25)、第3(0.5)、第4(0)和第5维(1)、第2维不选择.DC方法中的知识嵌入矩阵在实际应用中往往按照专家经验人为设定.
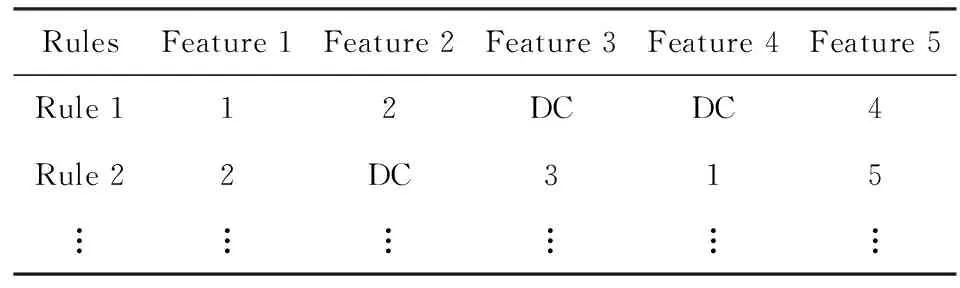
Table 1 A Knowledge Embedded Matrix in DC Approach表1 DC方法中知识嵌入矩阵示例
由于篇幅所限,以下给出第1条模糊规则的IF语句部分的格式:
ifx1is very low andx2is low andx3
is “don’t care” andx4is “don’t
care” andx5is high,
进一步,该模糊规则的if语句部分可以简洁地写为
ifx1is very low andx2is
low andx5is high,
显然,与经典MA型模糊规则相比,本文所用模糊规则具有2个特点:1)if语句部分保证模糊划分的清晰性;2)允许每条模糊规则的输入空间不同,即使用非连续的隶属度函数,这样既缩短了规则前件对应于输入向量的特征数,又可使每条规则从不同的视角进行推理,增强了模糊系统的可解释性.
2.2 KE-B-MA模糊系统构建
当使用知识嵌入的DC方法预设了模糊隶属度函数的中心C=(c1,c2,…,cK)T和各规则的输入空间特征,KE-B-MA模糊系统中待求的前件参数是模糊隶属度函数的方差δ=(δ1,δ2,…,δK)T.值得注意的是,每一条规则的方差δk与中心ck在同一输入空间下.此外,由式(2)(5)(7)可知,δk的值与模糊聚类的隶属度un k(1≤n≤N,1≤k≤K)有关,un k表示样本xn与第k个聚类中心ck的划分关系.因此,求解δ的问题就转化为求解模糊划分矩阵U的问题,加上待求的模糊规则后件参数V=(v1,v2,…,vK)T,KE-B-MA模糊系统中需同时学习的模糊规则前件和后件参数为U和V.
根据贝叶斯理论,KE-B-MA模糊系统中数据和各参数的联合似然估计可以写为
p(X,U,C,Y,V)=
p(X|U,C,Y,V)p(U|C,Y,V)p(C,V,Y),
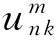
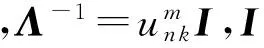
对式(13)取负对数,可得:
-lg(p(X|U,C,Y,V))=
式(14)等号右边第1项与FCM聚类的目标函数相同,用来保证在聚类中心固定的情况下得到X合理的模糊划分.假设模糊划分矩阵U的先验分布p(U|C,Y,V)只与聚类中心C有关,即p(U|C,Y,V)等价于p(U|C),同时不同样本所属的模糊隶属度之间相互独立,则先验分布p(U|C,Y,V)可以定义为

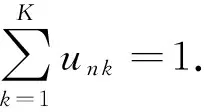
本文所提KE-B-MA假设先验分布p(C,V,Y)服从指数分布,形式为
其中,函数f(C,yn,V)的定义为
KE-B-MA假设先验分布p(Y)为常数.将式(13)(15)(17)相乘,得到KE-B-MA的数据和参数的联合分布,其形式为
通过对式(19)取对数,可得KE-B-MA目标函数:
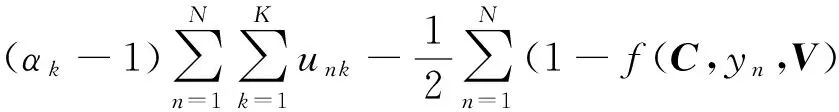
从式(20)可以看出,KE-B-MA将模糊规则前件和后件参数的学习融入到一个概率模型中,当模型的联合分布达到MAP值时,参数{U,V}可同时得到最优解.
2.3 模糊规则前件和后件参数的学习策略
为了得到参数{U,V}的全局最优解,如图2所示,本文使用蒙特卡洛(MCMC)方法[28]来求解式(19)的MAP值.具体地,本文通过MH(Metropolis-Hastings)采样算法构造一条满足一定后验分布且平稳分布的Markov链.该Markov链的第t次迭代的步骤如下:
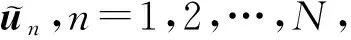
其中,参数α=(α1,α2,…,αK)决定了Dirichlet分布的形状,当αk值越接近于0,产生的un k值趋于二值化(0或1);当αk值在1附近时,产生的un k值具有模糊性;随着αk值的继续增大,产生的un k值趋向于均匀分布.实验中,由于数据分布的未知性,α参数设为α=1K.
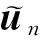
其中,
概率au的计算方法可写为
其中,函数Unif(0,1)产生一个在[0,1]范围内均匀分布的随机数.
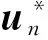
5) 计算第t次迭代后件V(t+1)和当前后件V*
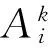
6) 更新U和V的MAP值{U*,V*}
在Markov链第t次迭代的最后,进行p(X,U(t+1),C,Y,V(t+1))与p(X,U*,C,Y,V*)值的比较,值大者成为当前新的MAP值{U*,V*},即:
通过重复上述步骤,当迭代次数足够大时,可以保证得到的参数{U*,V*}是全局收敛.
2.4 KE-B-MA算法描述和算法分析
根据2.2节利用MCMC理论构造Markov链求解{U*,V*}的叙述,本节给出KE-B-MA模糊系统学习算法.
算法1. KE-B-MA算法.
输入:训练样本X和样本标签Y、知识嵌入矩阵、模糊指数m、规则数K、正则化参数C′、隶属函数尺度参数h、Markov链最大迭代次数tmax;
输出:KE-B-MA模糊系统的模糊规则和决策函数.
步骤1. 设置iter=1;
步骤2. 设置iterationU=1;
步骤4. 根据式(22)计算接受概率au;
步骤6.iterationU=iterationU+1;
步骤7. 如果iterationU≤N,转到步骤3;
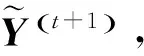
步骤9. 根据式(19)分别计算p(X,U(t+1),C,Y,V(t+1))和p(X,U*,C,Y,V*);
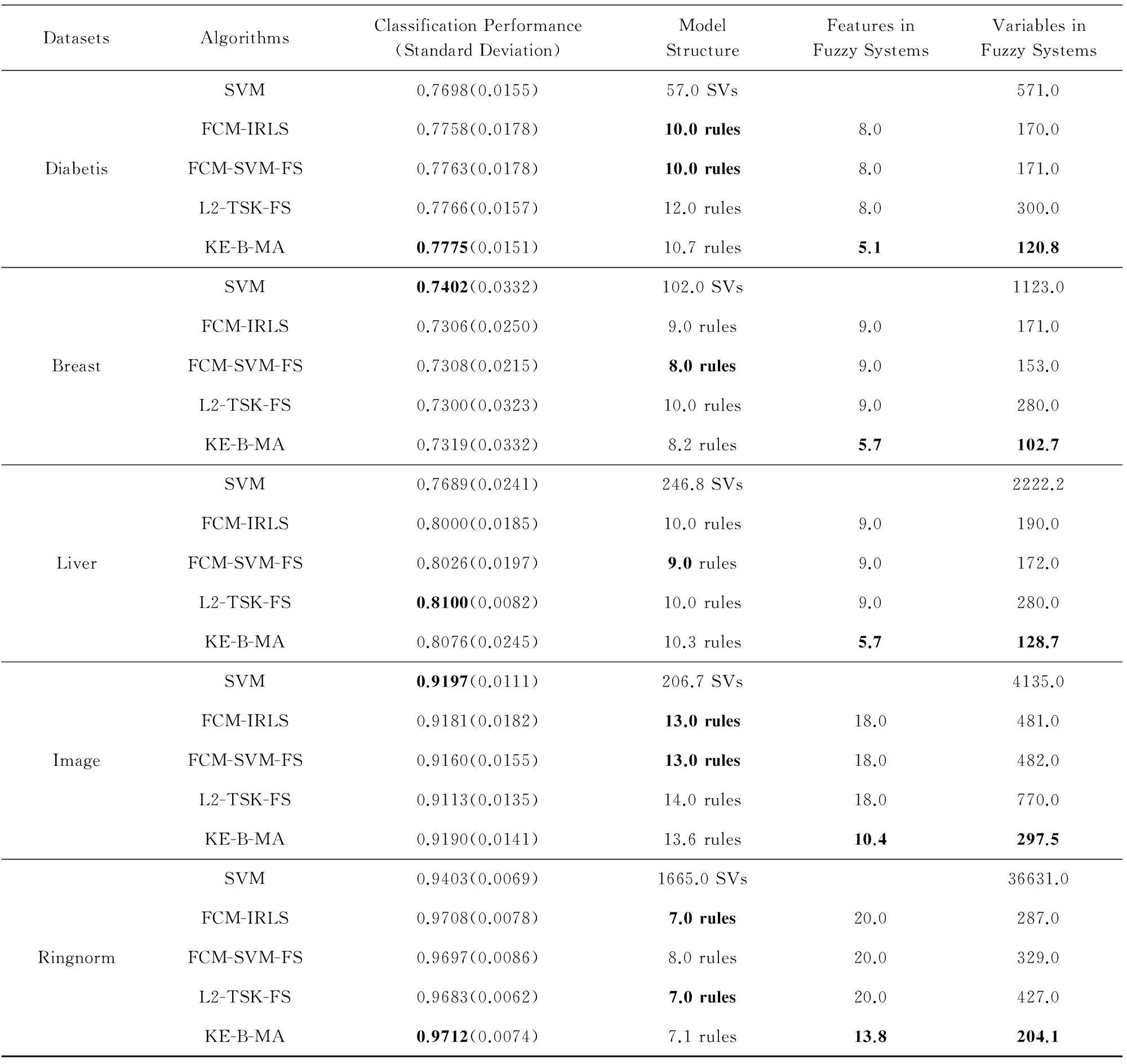
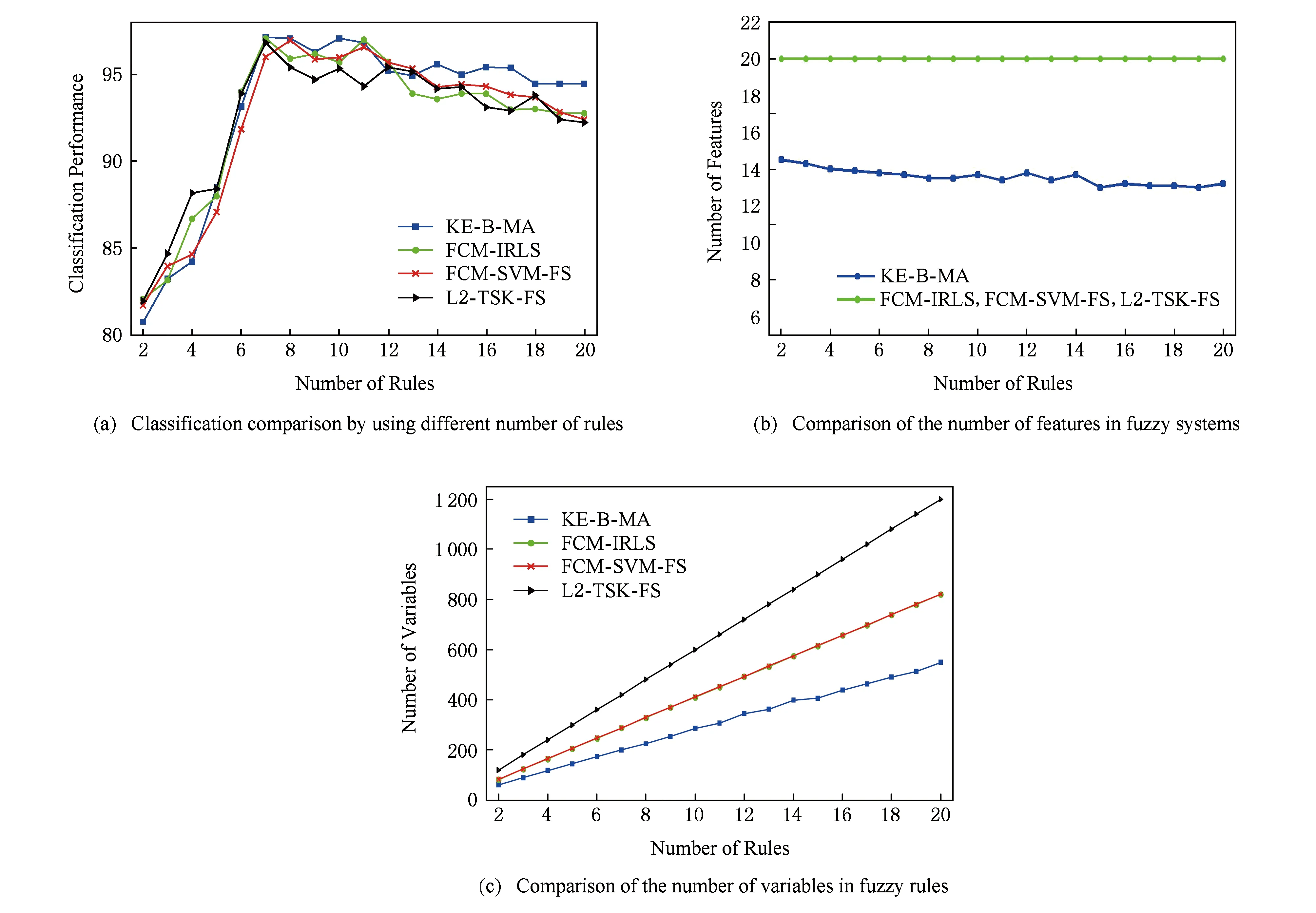
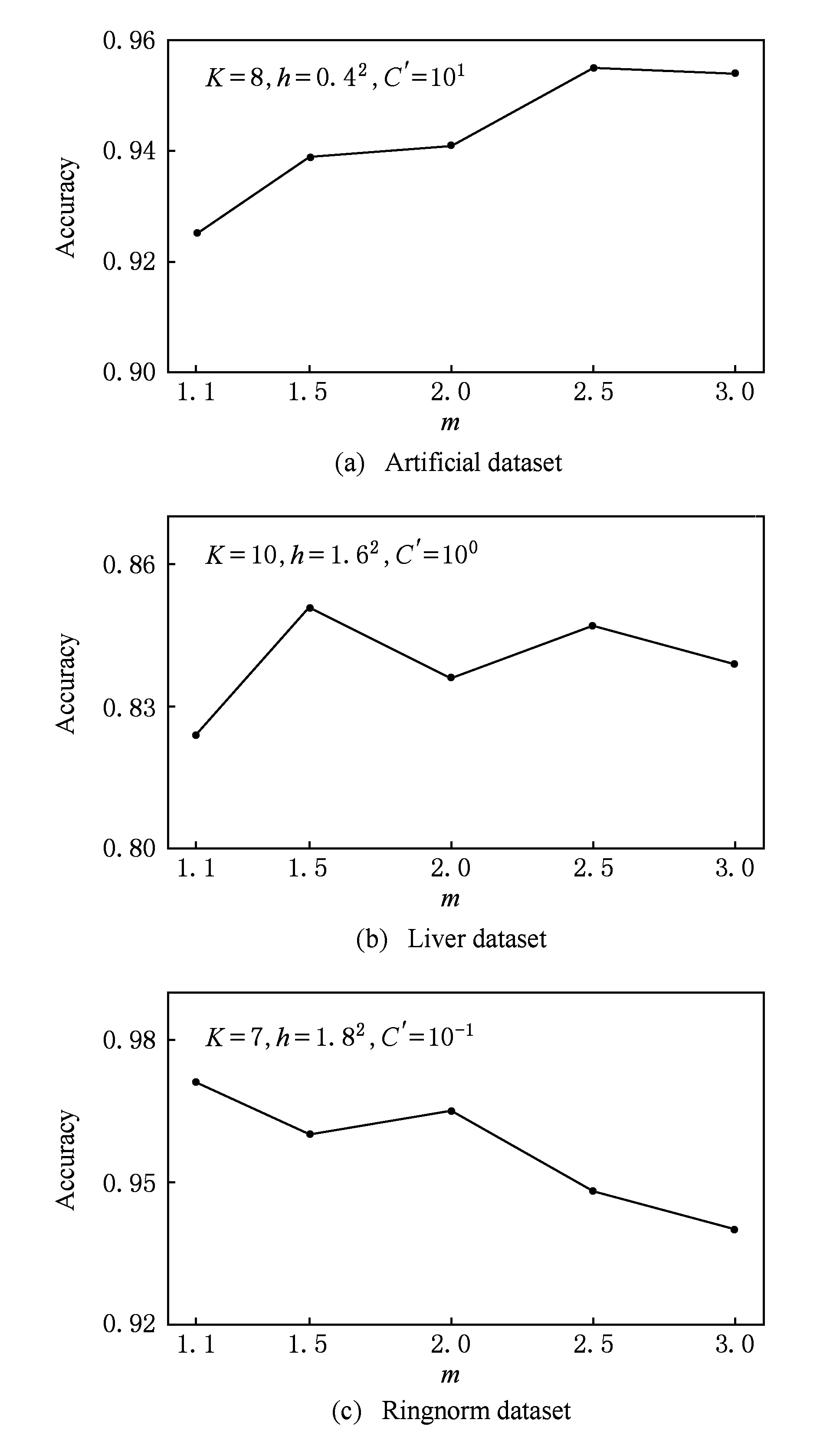
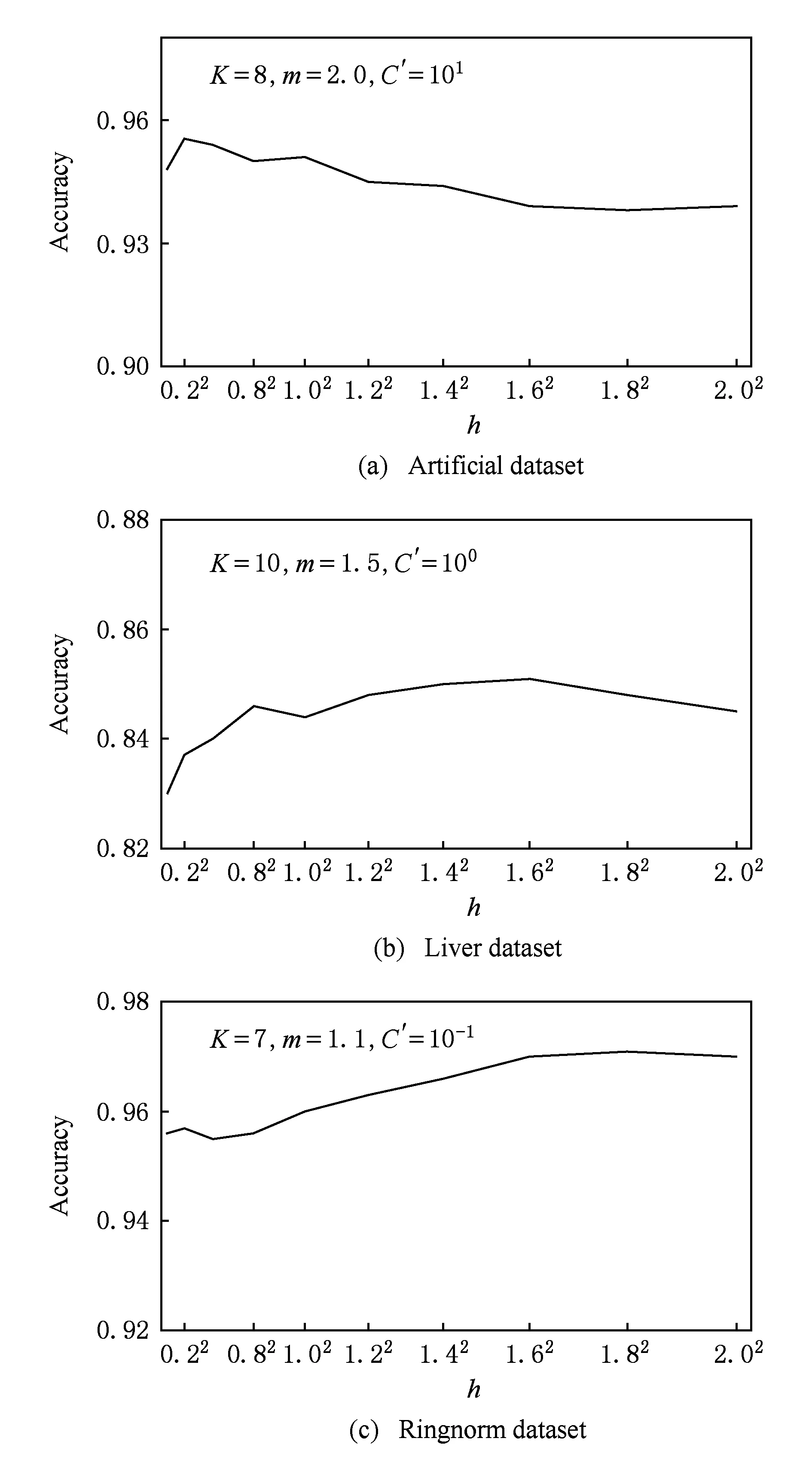
如果p(X,U(t+1),C,Y,V(t+1))>p(X,U*,C,Y,V*),那么U*=U(t+1),V*=V(t+1);
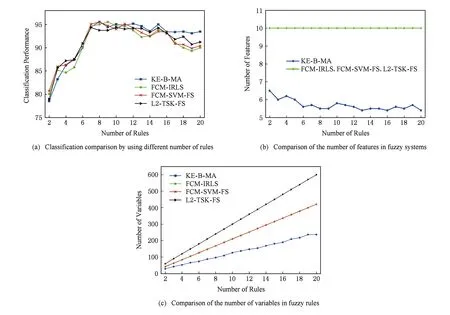
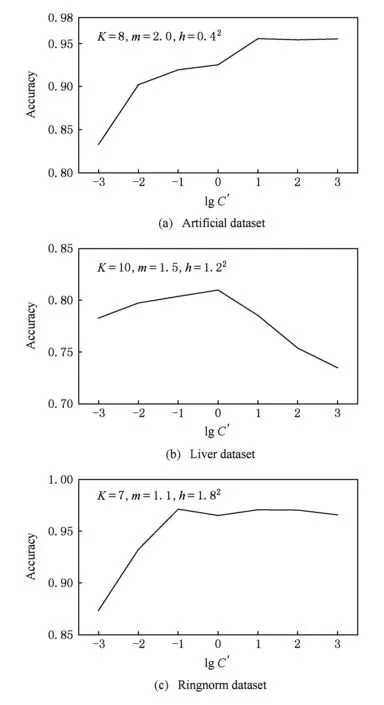
步骤10.iter=iter+1;如果iter 步骤11. 使用式(5)计算规则前件参数δ,并得到模糊规则; 步骤12. 由式(9)得到系统的决策函数. 通过对算法1的分析可知,算法1的时间复杂度主要有2部分构成:条件概率p(xn,un|C,Y,V)(式(15))和后件参数V(式(7))的计算,时间复杂度分别是O(Kdk)和O(N3),其中dk为第k条规则的输入向量的特征数.因此,算法1的时间复杂度小于等于O(tmax(NKd+KN3)).可见,算法1运行的时间效率与样本的容量和结构有关,大部分情况下数据集的维数d与样本容量N之间存在d≪N2的关系,因此,算法1执行时间复杂度近似为O(tmaxKN3),即等于求解后件参数对应的二次规划所需的时间.为了在一定程度上提高算法的执行效率,可以采用许多成熟的快速算法来提高二次规划的求解速度,例如SMO(sequential minimal optimization)[29]和parallel mixture[30]等,其执行效率在样本容量为N时分别能够达到O(N2)和O(N).本文采用SMO算法来求解后件参数. MH采样算法的全局收敛性在文献[28]中得到证明,根据随机游走的策略,无论其参数的初值如何设置,算法最终一定收敛于平稳分布.而本文提出的KE-B-MA模糊系统在采用MH采样算法的同时,引入了计算模糊规则后件参数的SVM算法,其QP解法也可保证获得结果的全局收敛性.因此,算法1得到的KE-B-MA的前件和后件参数是全局最优解. 3.1 实验设置 为了验证本文方法的有效性,本节将分别通过人工合成数据集以及UCI标准数据库数据对KE-B-MA算法进行分析与验证.有关实验数据的详细描述分别于3.2节和3.3节给出.此外,与KE-B-MA进行比较的算法包括4种典型的基于聚类的模糊系统:FCM-IRLS[20],FCM-SVM-FS[16](模糊系统前件参数学习使用FCM聚类)和L2-TSK-FS[31],以及经典分类算法SVM.在本文实验部分,各调节参数的设置采取5重交叉验证法来选取最优值,参数的详细设置如表2所示.所有算法在Matlab2010b环境下实现,SVM算法由LIBSVM软件实现,采用L1-SVM的形式. Table 2 Definition and Settings of the Related Parameters for All Algorithms 为对各算法的性能进行全面比较,实验采用4个评价指标:1)分类精度和方差;2)模糊系统的规则数和SVM的支持向量数;3)各模糊系统规则中包含的特征数;4)各算法所对应模型的变量数.SVM包含的变量数为L+L(s+1)+1,其中L表示支持向量数,s表示样本的维数;L2-TSK-FS包含的变量数为2Kd+K(d+1),K表示模糊规则数,d表示模糊规则对应输入空间的维数;FCM-SVM-FS和KE-B-MA包含的变量数为2Kd+K+1;FCM-IRLS包含的变量数为2Kd+K. 3.2 人工数据集实验 人工数据集由500个10维在[0,1]之间均匀分布的随机数x构成.每个样本对应的类标签定义为y=sgn(x1+x2+…+x10). 为了验证KE-B-MA中基于贝叶斯理论的前件后件参数同时学习策略的有效性,本节实验中5重交叉验证的每一折中知识嵌入矩阵通过随机选择样本特征和随机选择语义标签的方式获得.KE-B-MA中知识嵌入矩阵中各元素的选择原则是:模糊集应覆盖输入空间所有的特征.实验比较了KE-B-MA与其他4种对比算法的分类平均准确率和标准差、规则数、规则包含的特征数和模型包含的变量数4个指标,结果如图3所示(最佳结果用黑体标出).其中,SVs表示SVM获得的支持向量数. Table 3 Accuracy Performance Comparison of Several Algorithms on the Artificial Dataset表3 各种算法在人工数据集上的性能比较 SVs: Support vectors Fig. 3 Performance comparison between KE-B-MA,FCM-SVM-FS,FCM-IRIS and L2-TSK-FS on the artificial dataset图3 KE-B-MA,FCM-SVM-FS,FCM-IRIS,L2-TSK-FS在人工集上的性能比较 由表3和图3可以看出: 1) 本文方法与实验4种对比算法相比,在人工数据集上取得了相当的分类性能,KE-B-MA的分类准确度仅比最佳分类效果低0.01%. 2) FCM-IRLS,FCM-SVM-FS,L2-TSK-FS模糊系统采用样本的全部10个特征来构造模糊规则,而KE-B-MA构造的模糊规则通过知识嵌入矩阵只使用了5.8个特征,说明KE-B-MA虽然没有使用样本的全部特征,但通过规则前件和后件共同学习的策略能够充分考虑输入空间和输出空间之间的内在联系,保证了模糊系统的分类精确度.这一点是FCM-IRLS,FCM-SVM-FS,L2-TSK-FS不具备的. 3) 表3的最后一行比较了实验中5种算法各自模型中的变量数,显然KE-B-MA模糊系统具有绝对的优势,其模型中的变量数远小于另外4种算法. 4) 对于模糊系统而言,模糊规则的可解释性不仅与模糊规则数有关,同时也与规则在输入空间的划分清晰度有关.KE-B-MA中通过使用知识嵌入矩阵设定了语义清晰的模糊隶属度函数中心,保证了输入空间的划分清晰度,这一优点也是实验中其他3种模糊系统所不具备的. 为了对KE-B-MA所得模糊规则这一特性有更直观的了解,下面给出了实验中设定的知识嵌入矩阵和最佳分类精度时得到的模糊规则,分别如表4和图4所示. Table 4 The Knowledge Embedded Matrix Corresponding to Eight Fuzzy Rules in One Running Time on the Artificial Dataset表4 某次运行时人工集上产生的8条模糊规则对应的知识嵌入矩阵 Fig. 4 Fuzzy membership functions obtained by KE-B-MA by using the knowledge embedded matrix in table 4图4 KE-B-MA模糊系统根据表4知识嵌入矩阵得到的模糊隶属度函数 图4所示规则对应的后件参数为V=(0.9731,0.8931,1.2387,1.7321,-1.2971,-1.8662,-07582,-0.9265)T.由于篇幅所限,下面给出所得第1条模糊规则的形式: R1:ifx1is very high andx2is low andx4is medium andx6is very low andx7is medium andx9is very high,thenv1=0.9731. 3.3 UCI数据集实验 本节通过5个真实的UCI机器学习库[32]中的数据集来验证KE-B-MA的性能:Pima Indians’ Diabetis(Diabetis)数据集、Breast Cancer(Breast)数据集、Liver数据集、Image Segmentation(Image)数据集和Ringnorm数据集.Diabetis数据集共有768个数据样本,每个样本有8个特征,数据集分为糖尿病类和正常类,样本数分别为500和268.Breast共有288个数据样本,其中属于乳腺癌类样本85个,属于良性乳腺癌类样本201个,每个样本有9个特征.Liver数据集共有345个数据样本,包含肺部异常类样本145个和正常类样本200个,每个样本有6个特征.Image数据集为图像分割测试数据集,共有2 10个数据样本,含18个特征,其中正类1 320个样本,负类990个样本.Ringnorm数据集包含 7 400个样本,其特征数为20 维,正类和负类样本分别为3 364和3 736个.实验中5个UCI集的数据均归一化至[0,1]范围内.本节实验中知识矩阵的建立借助于F-score方法[33],优先选择F-score值较大的特征,并确保模糊集覆盖输入空间所有的特征.需要说明的是,实际应用中,知识嵌入矩阵常通过事先积累的专家经验获得. 表5给出了5种分类算法在UCI数据集上的实验结果.与人工数据集实验类似,实验比较了KE-B-MA与3种对比算法在规则数{2,3,…,20}范围内分类精确度、规则包含的特征数和模型包含的变量数这3个指标,结果如图5所示. Table 5 Performance Comparisons on UCI Datasets with Different Algorithms表5 各种算法在UCI数据集上的性能比较 SVs:Support vector Fig. 5 Performances comparison between KE-B-MA,FCM-SVM-FS FCM-IRIS and L2-TSK-FS on Ringnorm dataset图5 KE-B-MA,FCM-SVM-FS,FCM-IRIS,L2-TSK-FS在Ringnorm集上的性能比较 从这些实验结果,我们可以看出: 1) UCI数据集上获得的实验结果与人工数据集的实验结果是一致的.由于使用了知识嵌入矩阵实现了模糊隶属度函数中心和规则特征的选择,可以保证得到的模糊规则具有高度的可解释性,同时使用基于贝叶斯理论的前件和后件同时学习的策略,保证了所得模型参数的全局最优解,并建立起输入空间和输出空间的内在联系,保证了分类器的分类精度,且结果偏差不大,较为稳定. 2) 从图5可以看出,当设定的模糊规则数较小时(K<4),KE-B-MA的性能略逊于其他3种模糊系统,当设定的模糊规则数逐渐增大时,KE-B-MA的性能快速提升,5个UCI数据集上除了Liver数据集上分类准确度略差于FCM-IRLS,另4个UCI数据集上的分类准确度在4种模糊系统中是最优的.究其原因在于:KE-B-MA构造的每条模糊规则的输入特征不同,在规则数过小时不足以映射完整的输入空间,但是一旦模糊规则数增加到合适值,KE-B-MA能获得较之经典模糊系统更好或可比的分类性能.同时,虽然FCM-SVM-FS,FCM-IRIS,L2-TSK-FS模糊系统在规则数过小时分类性能略优于KE-B-MA,但此时的分类精度也低于其最高值,从获得优良分类效果的角度看,此时的规则数不会被最终选择.而FCM-SVM-FS,FCM-IRIS,L2-TSK-FS在UCI数据集上获得最佳分类性能时模型的变量数和规则的复杂程度远大于KE-B-MA的变量数和规则的复杂度,也再次说明了KE-B-MA得到的模型规则具有高度的可解释性. 3.4 参数敏感性实验 本文所提KE-B-MA实现需要协调的实验参数有:K,m,h,C′,其中K为模糊规则数,C′为结构化风险正则化参数,h为隶属函数尺度参数,m为模糊指数.模糊规则数K的取值与样本的分布有关,在基于聚类的模糊系统中,选择合适的模糊规则数常用2种方法: 1) 借助于Xie-Beni指数[34]、Mountain potential指数[35]等来确定,但这种方法本质上只是从聚类的角度对输入空间进行划分,没有考虑模糊系统输入空间和输出空间之间的联系,应用在模糊系统中往往效果不佳; 2) 通过手动设定的方式来确定模糊规则数,也是本文所用方法.KE-B-MA为了保证所得规则具有高度的可解释性使用知识嵌入矩阵对模糊规则的特征和隶属度函数中心进行选择,在这种情况下,通过交叉验证策略对模糊规则数K进行寻优是合适的. 本节重点评价KE-B-MA中m,h,C′这3个参数对分类精度的影响,实验使用人工集(Artificial dataset),Liver和Ringnorm数据集作为实验数据,模糊规则数分别固定为8,10,7条,另外采用固定其他参数寻优的方法,图6~8分别显示了上述3个参数所提方法的性能影响曲线. Fig. 6 Parameter m sensitivity analysis on three datasets图6 参数m的敏感性实验 Fig. 7 Parameter h sensitivity analysis on three datasets图7 参数h的敏感性实验 Fig. 8 Parameter C′ sensitivity analysis on three datasets图8 参数C′的敏感性实验 由此可得3个结论: 1) KE-B-MA中模糊指数m的作用等同于FCM聚类中的作用,m在FCM中必须设置为大于1,否则得不到模糊隶属度的解析解,但在KE-B-MA中m在理论上可以取任何值,甚至为负值.根据文献[36]对模糊指数的物理意义解释,本文设定m的调节区间是m∈{1.1,1.5,2,2.5,3}.由图6可以出,KE-B-MA的分类精度对m值较敏感.因此,通过交叉验证策略对参数m进行寻优是合理的. 2) 尺度参数h对KE-B-MA的分类性能起着相对温和的影响.从图7可以看出,在h的设定区间内,KE-B-MA在3个实验数据集上分类效果的最高值与最低值的变化幅度不超过4%.同时,正如我们熟知的,尺度参数h的设置对模糊规则的清晰性和可解释性起到了重要的影响,因此,对该参数的获取也应使用交叉验证的方法. 3) KE-B-MA中模糊规则后件的,学习基于典型的SVM模型,所有对正则化参数C′具有较强的敏感性,C′在一定范围内的不同取值明显影响所提方法的泛化性能,且C′的取值与数据集的分布有关,这也进一步说明了对C′寻优的重要性. 本文使用贝叶斯概率模型提出了一种新的MA型模糊系统,即KE-B-MA模糊系统.KE-B-MA运用DC方法实现对模糊规则的特征和隶属度函数中心进行选择,保证了模糊划分的清晰性和有效降低了所建系统的复杂性,解决了传统基于聚类的模糊系统可解释性不高,且需要数据的全部特征来构造模糊规则易造成规则繁杂的问题.KE-B-MA运用MH采样构建了一个Markov链实现模糊规则前件和后件参数的同时学习,保证了所得结果的全局最优解.这些特性是传统的基于聚类的模糊系统所不具备的.通过人工数据和真实数据集的仿真实验,结果亦表明了本文算法的分类性能较之传统方法相当,但获得的模糊规则更具可解释性.应当指出,目前本文算法仍存在一些不足之处,例如对KE-B-MA模糊系统能否有效解决大样本等问题没有进行深入探讨,当数据容量极大时,从MH采样和二次规划求解角度而言,KE-B-MA仍面临进一步提高实用性的挑战,这将作为我们下阶段的研究重点. [1]Huo Weigang, Shao Xiuli. A fuzzy associative classification method based on multi-objective evolutionary algorithm[J]. Journal of Computer Research and Development, 2011, 48(4): 567-575 (in Chinese)(霍纬纲, 邵秀丽. 一种基于多目标进化算法的模糊关联分类方法[J]. 计算机研究与发展, 2011, 48(4): 567-575) [2]Sanz J, Fernández A, Bustince H, et al. IVTURS: A linguistic fuzzy rule-based classification system based on a new interval-valued fuzzy reasoning method with tuning and rule selection[J]. IEEE Trans on Fuzzy Systems, 2013, 21 (3): 399-411 [3]Juang C F, Hsiao C M, Hsu C H. Hierarchical cluster-based multispecies particle-swarm optimization for fuzzy-system optimization[J]. IEEE Trans on Fuzzy Systems, 2010, 18(1): 14-26 [4]Alcalá R, Alcala-Fdez J, Casillas J, et al. Local identification of prototypes for genetic learning of accurate TSK fuzzy rule-based systems[J]. International Journal of Intelligent Systems, 2007, 22(9): 909-941 [5]Lughofer E, Buchtala O, Reliable all-pairs evolving fuzzy classifiers[J]. IEEE Trans on Fuzzy Systems, 2013, 21(4): 625-641 [6]Fazzolari M, Alcalá R, Nojima Y, et al. A review of the application of multiobjective evolutionary fuzzy systems: Current status and further directions[J]. IEEE Trans on Fuzzy Systems, 2013, 21(1): 45-65 [7]Ishibuchi H, Yamamoto T. Fuzzy rule selection by multi-objective genetic local search algorithms and rule evaluation measures in data mining[J]. Fuzzy Sets and Systems, 2004, 141(1): 59- 88 [8]Derrac J, Verbiest N, García S, et al. On the use of evolutionary feature selection for improving fuzzy rough set based prototype selection[J]. Soft Computing, 2013, 17(2): 223-238 [9]Alcala-Fdez J, Alcalá R, Herrera F. A fuzzy association rule-based classification model for high-dimensional problems with genetic rule selection and lateral tuning[J]. IEEE Trans on Fuzzy Systems, 2011, 19(5): 857-872 [10]Chen Yicheng, Pal N R, Chung I. An integrated mechanism for feature selection and fuzzy rule extraction for classification[J]. IEEE Trans on Fuzzy System, 2012, 20(4): 683-698 [11]Chen Yixin, Wang J Z. Support vector learning for fuzzy rule-based classification systems[J]. IEEE Trans on Fuzzy System, 2003, 11 (6): 716-728 [12]Chiang J H, Hao P Y. Support vector learning mechanism for fuzzy rule-based modeling: A new approach[J]. IEEE Trans on Fuzzy Systems, 2004, 12 (1): 1-12 [13]Juang C F, Chen G C. A TS fuzzy system learned through a support vector machine in principal component space for real-time object detection[J]. IEEE Trans on Industrial Electronics, 2012, 59(8): 3309-3320 [14]Lin C T, Yeh C M, Liang S F, et al. Support-vector-based fuzzy neural network for pattern classification[J]. IEEE Trans on Fuzzy Systems, 2006, 14 (1): 31-41 [15]Juang C F, Chiu S H, Shiu S J. Fuzzy system learned through fuzzy clustering and support vector machine for human skin color segmentation[J]. IEEE Trans on System, Man and Cybernetics-Part A: Systems and Humans, 2007, 37(6): 1077-1087 [16]Cheng W, Juang C. An incremental support vector machine-trained TS -type fuzzy system for online classification problems[J]. Fuzzy Sets and Systems, 2011(163): 24-44 [17]Pan Weimin, He Jun. Neuro-fuzzy system modeling with density-based clustering[J]. Journal of Computer Research and Development, 2010, 47(11): 1986-1992 (in Chinese)(潘维民, 何骏. 基于密度聚类的神经模糊系统建模算法[J]. 计算机研究与发展, 2010, 47(11): 1986-1992) [18]Leski J M. Anε-margin nonlinear classifier based on fuzzy if-then rules[J]. IEEE Trans on System, Man and Cybernetics, Part B: Cybernetics, 2004, 34(1): 68-76 [19]Leski J M. TSK-fuzzy modeling based onε-insensitive learning[J]. IEEE Trans on Fuzzy System, 2005, 13(2): 181-193 [20]Leski J M. Fuzzy (c+p)—means clustering and its application to a fuzzy rule-based classifier: Towards good generalization and good interpretability[J]. IEEE Trans on Fuzzy System, 2015, 23(4): 802-812 [21]Deng Zhaohong, Cao Longbing, Jiang Yizhang, et al. Minimax probability TSK fuzzy system classifier: A more transparent and highly interpretable classification model[J]. IEEE Trans on Fuzzy System, 2015, 23(4): 813-826 [22]Deng Zhaohong, Jiang Yizhang, Chung F L, et al. Knowledge-leverage based fuzzy system and its modeling[J]. IEEE Trans on Fuzzy System, 2013, 21(4): 597-609 [23]Azeem M F, Hanmandlu M, Ahmad N. Generalization of adaptive neural-fuzzy inference systems[J]. IEEE Trans on Neural Networks, 2000, 11(6): 1332-1346 [24]Bezdek J C. Pattern Recognition with Fuzzy Objective Function Algorithms[M]. Amsterdam, Netherlands: Kluwer Academic Publishers, 1981 [25]Dehzangi O, Zolghadri M, Taheri S, et al. On equivalence of FIS and ELM for interpretable rule-based knowledge representation[J]. IEEE Trans on Neural Networks and Learning Systems, 2015, 26(7): 1417-1430 [26]Lan Y, Soh Y C, Huang G B. Two-stage extreme learning machine for regression[J]. Neurocomputing, 2010, 73(16): 3028-3038 [27]Glenn T C, Zare A, Gader P D. Bayesian fuzzy clustering[J]. IEEE Trans on Fuzzy System, 2015, 23(5): 1545-1561 [28]Robert C, Casella G. Monte Carlo Statistical Methods[M]. Berlin: Springer, 2005 [29]Chang C C, Lin C J. LIBSVM: A library for support vector machines[EB/OL]. 2001 [2015-09-28]. http://www.csie.ntu.edu.tw/~cjlin/libsvm [30]Collobert R, Bengio S, Bengio Y. A parallel mixture of SVMs for very large scale problems[J]. Neural Computation, 2002, 14 (5): 1105-1114 [31]Deng Zhaohong, Choi K S, Chung F L, et al. Scalable TSK fuzzy modeling for very large datasets using minimal-enclosing-ball approximation[J]. IEEE Trans on Fuzzy Systems, 2011, 19(2): 210-226 [32]Bache K, Lichman M. UCI database[EB/OL]. 2013 [2015-09-28]. http://www.ics.uci.edu/%20mlearn/ MLRepository.html [33]Chen Y W, Lin C J. Feature Extraction: Foundations and Applications[M]. Berlin: Springer, 2007 [34]Xie Xiaoliang, Beni G. A validity measure for fuzzy clustering[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1991, 13(4): 841-846 [35]Mezquida E T, Rubio A, Sánchez-Palomares O. Evaluation of the potential index model to predict habitat suitability of forest species: The potential distribution of mountain pine (pinus uncinata) in the Iberian peninsula[J]. European Journal of Forest Research, 2010, 129(1): 133-140 [36]Pal N R, Bezdek J C. On cluster validity for the fuzzyc-means model[J]. IEEE Trans on Fuzzy Systems, 1995, 3(3): 370-379 Knowledge Embedded Bayesian MA Fuzzy System Gu Xiaoqing1,2and Wang Shitong1 1(School of Digital Media, Jiangnan University, Wuxi, Jiangsu 214122)2(School of Information Science and Engineering, Changzhou University, Changzhou, Jiangsu 213164) The most distinctive characteristic of fuzzy system is its high interpretability. But the fuzzy rules obtained by classical cluster based fuzzy systems commonly need to cover all features of input space and often overlap each other. Specially, when facing the high-dimension problem, the fuzzy rules often become more sophisticated because of too much features involved in antecedent parameters. In order to overcome these shortcomings, based on the Bayesian inference framework, knowledge embedded Bayesian Mamdan-Assilan type fuzzy system (KE-B-MA) is proposed by focusing on the Mamdan-Assilan (MA) type fuzzy system. First, the DC (don’t care) approach is incorporated into the selection of fuzzy membership centers and features of input space. Second, in order to enhance the classification performance of obtained fuzzy systems, KE-B-MA learns both antecedent and consequent parameter of fuzzy rules simultaneously by a Markov chain Monte Carlo (MCMC) method, and the obtained parameters can be guaranteed to be global optimal solutions. The experimental results on a synthetic dataset and several UCI machine datasets show that the classification accuracy of KE-B-MA is comparable to several classical fuzzy systems with distinctive ability of providing explicit knowledge in the form of interpretable fuzzy rules. Rather than being rivals, fuzziness in KE-B-MA and probability can be well incorporated. classification; Bayesian inference; Mamdan-Assilan type fuzzy system; knowledge embedded; Markov chain Monte Carlo (MCMC) method Gu Xiaoqing, born in 1981. PhD candidate and lecturer. Her main research interests include pattern recognition and machine learning. Wang Shitong, born in 1964. Professor and PhD supervisor. His main research interests include artificial intelligence, neuro-fuzzy systems, pattern recognition, and image processing. 2016-01-05; 2016-10-10 国家自然科学基金项目(61572236,61502058,61572085);江苏省自然科学基金项目(BK20160187);中央高校基本科研业务费专项资金项目(JUSRP51614A);江苏省高校自然科学基金项目(15KJB520002) This work was supported by the National Natural Science Foundation of China (61572236, 61502058, 61572085), the Natural Science Foundation of Jiangsu Province of China (BK20160187), the Fundamental Research Funds for the Central Universities (JUSRP51614A), and the Natural Science Foundation of Jiangsu Higher Education Institutions (15KJB520002). TP18; TP391.43 实验研究


4 总 结


猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
法律方法(2021年4期)2021-03-16
铁道通信信号(2019年6期)2019-10-08
文教资料(2018年30期)2018-01-15
Coco薇(2017年11期)2018-01-03
雷达学报(2017年6期)2017-03-26
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
互联网天地(2016年1期)2016-05-04
无线互联科技(2015年23期)2016-03-05
