
结合显性与隐性空间光滑的高效二维图像判别特征抽取
2017-05-13 03:43朱快快陈松灿
计算机研究与发展 2017年5期
朱快快 田 青 陈松灿
(南京航空航天大学计算机科学与技术学院 南京 210016)(zkk1992@nuaa.edu.cn)
结合显性与隐性空间光滑的高效二维图像判别特征抽取
朱快快 田 青 陈松灿
(南京航空航天大学计算机科学与技术学院 南京 210016)(zkk1992@nuaa.edu.cn)
图像具有固有的二维空间结构,空间上邻近的像素点通常具有相近的灰度值,意味着图像具有局部光滑性.为对其特征抽取,传统方法常将原始图像拉成向量,造成空间结构的破坏,由此直接基于图像的2D特征抽取法应运而生.典型的如2DLDA,2DPCA,相比向量方法,计算复杂度显著降低,但其操作针对的是图像整行(或整列),导致空间光滑度过粗.为此,空间正则化通过在向量化空间中显式地施加局部空间光滑弥补这一不足,由此获得了比2D抽取法更优的分类性能,但其遗传了向量法的高计算代价.最近,隐性空间正则化方法(implicit spatial regularization, ISR)提出利用图像划分与重组隐性地体现图像局部光滑性,而后再利用现有2D方法抽取特征,使典型双边2DLDA性能优于SSSL(一种典型的显性空间正则化方法),但是,仅隐性地光滑缺乏显式的强制约束力,其特征空间依然欠光滑,同时双边2DLDA由非凸问题获得,计算耗时却不能保证解的全局最优性.鉴于此,提出一种结合显性与隐性空间光滑的高效二维图像判别特征抽取框架(2D-CISSE).其关键步骤是预先对图像显性地全局光滑,紧接着进行ISR,既继承了ISR的隐性光滑又强化了图像局部光滑的显式约束力,不仅可直接获得全局最优投影,同时该框架具有一般性,即现有大部分图像光滑方法与2D特征抽取法均可嵌入其中.最后,通过在人脸数据集Yale,ORL,CMU PIE,AR以及手写数字数据集MNIST和USPS上的对比实验验证了2D-CISSE框架性能的优越性与计算的高效性.
空间光滑;图像欧氏距离;隐性空间正则化;特征抽取;基于矩阵模式
尽管深度学习已在图像分类[1-2]、自然语言理解[3-4]等领域取得了几乎无可比拟的进展,其成功的关键在于利用了大量的训练样本,但现实中依然存在仅有少量训练样本的分类问题,而提升此种情况下分类性能的关键之一是如何充分利用数据内在的结构信息.针对图像分类问题,则是如何充分利用图像的二维空间结构信息.传统的特征抽取方法[5-7]通常先按一定顺序将r×c的图像拉成rc维向量后用向量方法处理,导致空间结构信息缺失,影响后续学习任务的性能.因此,如何充分利用空间结构信息成为了研究关注点.
针对结构信息利用策略,Tian等人[8]将其归纳为3类,即结构嵌入的欧氏度量法、面向估计器学习的结构正则化方法和直接图像操作方法.传统的欧氏距离在用于衡量2幅图像的相似度时,包含在图像中的空间信息未能充分体现,对图像分类产生不利影响.鉴于此,Wang等人[9]将空间结构信息嵌入欧氏距离提出一种图像欧氏距离法(IMage Euclidean distance, IMED),在手写数字识别与人脸识别的实验中获得了比传统欧氏距离更优的识别效果.而Li等人[10]拓展了IMED,将其用于多角度的性别分类并获得了更高的分类精度,随后文献[11]又提出了一种自适应的图像欧氏距离度量法.这些结构嵌入的欧氏度量法本质在于通过对图像像素点施加权重显性地对图像作全局空间光滑,有效补偿了空间信息的损失,但其基于向量模式,不可避免要面对维度过高带来的高计算复杂度和小样本问题.
为尽可能保持像素点间的空间结构信息,一个自然的做法是直接对图像(或重组图像)矩阵操作.因而很多2D特征抽取法相继被提出,代表性的有Chen等人[12-16]通过对图像双线性投影所发展出的一系列分类器,例如MatMHKS[12]和MatFE+MatCD[16],并在人脸识别与手写数字识别的任务中获得比基于向量模式更优的识别性能.迄今为止,大部分基于向量子空间的方法已被成功地拓展到2D或张量的版本,如主成分分析(PCA)的2D版本2DPCA[17]和广义低秩近似矩阵(GLRAM)[18]等,线性判别分析(LDA)的2D版本单边2DLDA[19]和双边2DLDA[20]等,支持向量机的2D版本,即支持矩阵机[21](support matrix machines, SMM).与传统向量法相比,2D特征抽取法具有3点优势:
1) 直接基于图像矩阵定义的离散矩阵维度很低,这能有效缓和小样本问题,也避免了原有类内散度矩阵的奇异问题;
2) 能显著降低特征抽取的时间和空间计算复杂度;
3) 可部分利用像素点间的空间结构信息.
众多实验结果表明2D特征抽取法比其对应的1D向量法更优,但文献[22]中指出2D方法仅部分利用了图像在同一行或列的空间信息,并没有充分利用整个图像中的空间信息,其空间光滑度仍较粗.
鉴于此,有学者尝试将空间光滑正则化用于惩罚相关目标函数,从而使优化结果尽可能空间光滑[22-24].代表性方法为Cai等人[22]提出的空间光滑子空间学习模型(spatial smooth subspace learning, SSSL).在SSSL中,通过引入拉普拉斯惩罚使投影系数在空间上保持光滑.Zuo等人[23]进一步对拉普拉斯惩罚函数做高斯加权来实现多尺度图像光滑.Lotte等人[24]利用拉普拉斯惩罚对欠光滑滤波器光滑约束提出空间正则化的共同空间模式,在脑电波滤波分类实验中获得更优分类性能.通过显性地光滑图像空间的投影向量,空间正则化使向量特征抽取法获得了比2D特征抽取法更优的分类性能.但是,这种空间正则化策略依然存在2点不足:1)它遗传了原向量法固有的高计算代价;2)选取正则化参数的交叉验证耗时且参数选取依然是一个开放性问题.
在图像分类领域,随着空间信息利用策略的不断深入研究,很多综合策略相继被提出.如2013年,Gao等人[25]将结构嵌入的欧氏度量法结合到图像直接操作法中,通过将传统欧氏距离替换成IMED来实现像素点间空间关系的融合利用,提出了一种基于图像欧氏距离的2维最大局部变化(two-di-mensional maximum local variation, 2DMLV)人脸识别方法,并在人脸识别实验中获得比2DLDA,2DLPP,2DPCA等更高的分类精度.然而,2DMLV缺失了与SSSL的性能比较,且由于Kronecker积的计算导致较高的空间复杂度.2016年,Zhu等人[26]提出了一种不同于SSSL显性空间正则化的隐性空间正则化策略(implicit spatial regularization, ISR),基于SSSL的假设:局部图像区域(也称作空间窗口,如3×3)通常是光滑的,以重叠和非重叠方式将原图像划分成同大小的空间窗口,再依次将各空间窗口拉成向量作为新矩阵的列,从而重新组装成新的矩阵作为后续特征抽取的对象,具体操作如3.2节图2所示.重组的本意在于使新矩阵每列能保持自然的光滑和局部空间关系.由此结合现成的2D特征抽取法所提出的ISR+双边2DLDA(ISR-b)方法获得了优于ISR+单边2DLDA(ISR-s)和SSSL的分类精度.但其仍然存在2点不足:
1) 尽管其中的双边2DLDA达到了同类方法当前最好的结果,但其目标函数非凸,只能采用交替迭代优化算法求解,计算代价大,同时也不能保证解的全局最优性;
2) 划分重组的隐性方法尽管直觉上较好地保持了图像的局部空间光滑,但因其缺乏显性光滑的强制,其空间仍欠光滑.
为克服上述方法的不足,提出了一种结合显性与隐性空间光滑的高效二维图像判别特征抽取框架(2D-CISSE).2D-CISSE框架主要包含3个步骤,如图1所示,其关键步骤体现在步骤1中,即对原图像预先显性空间光滑,而后2个Step等同上述ISR.尽管2D-CISSE仅简单地在非重叠ISR基础上施加显性空间光滑约束,但令人惊讶的是其仅需结合单边2DLDA即可获得比ISR-b(非重叠ISR中最优)显著更优的分类性能,由此不仅大大降低了计算复杂度,同时还保证了解的全局最优性.最后利用最近邻分类器分别在人脸数据集ORL,Yale,CMU PIE,AR以及手写数字数据集MNIST和USPS上的分类实验结果显示2D-CISSE框架获得了比SSSL,2DMLV,ISR更优的分类性能和更高的计算效率.

Fig. 1 2D-CISSE framework图1 结合显性与隐性空间光滑的2D图像判别特征抽取框架
1 相关工作
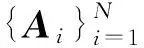
1.1 空间光滑的子空间学习模型SSSL
空间光滑的子空间学习(SSSL)[22]是一种典型的基于向量的显性空间正则化方法,其利用离散的Laplacian光滑算子对投影向量显式地约束使其局部光滑,在图嵌入框架[27]中其目标函数为
(1)
其中,a是待优化的投影向量,正则化因子0≤β≤1控制光滑度,J是一个离散的Laplacian正则化函数:
(2)
其中二维Laplacian算子的离散近似Δ∈rc×rc可以表示为
Δ=D1⊗I2+I1⊗D2,
(3)
其中,I1与I2分别是r×r和c×c的单位矩阵,⊗表示Kronecker积,D1(D2)是在图像行(列)方向一个r×r(c×c)二阶梯度光滑算子或矩阵:
(4)
其中,h1(h2)是样本矩阵在水平(竖直)方向的宽度.
1.2 二维最大局部变化法2DMLV
基于图像欧氏距离的二维最大局部变化法(two-dimensional maximum local variation, 2DMLV)[25]将包含图像的差异性与判别性信息的局部变化混合到目标函数中来降维,利用图像欧氏距离替换传统欧氏距离,从而将图像像素点间的空间关系运用到2D特征抽取法中.对于任意图像矩阵Aj∈r×c,目标是通过线性变换y=Aα得到一个低维的特征向量y∈c,α为待优化的投影向量.
首先,定义邻接关系矩阵V,当Aj是Al的k近邻或者Al是Aj的k近邻时,Vjl=1,否则Vjl=0.实际上,近邻空间的图像可能来自不同的类别,为了保持图像多样性,保证距离较大的2张图像在降维后依然保持较大的距离,可分别定义类内邻接关系矩阵Vw与类间邻接关系矩阵Vb:
(5)
(6)
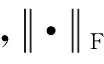
定义矩阵版本的图像欧氏距离[25]:
(7)
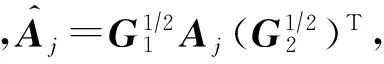
(8)
(9)
其中,p,p′=1,2,…r;q,q′=1,2,…c;σ为宽度参数,用于调整光滑度.
分别最大化类内和类间的局部方差,目标函数可以定义为
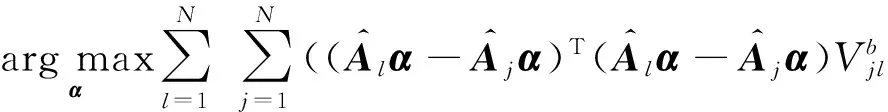
(10)
之后可利用线性和将其转换为单目标的优化问题,可以通过特征分解求出优化目标.
2 2D-CISSE框架
针对结合显性与隐性的空间光滑的二维图像判别特征抽取框架(2D-CISSE)所包含如图1所示的3个步骤(Step1~Step3),本节将分别对其详细地展开介绍.
2.1 原始图像显式光滑
2.1.1 全局图像欧氏距离光滑
图像欧氏距离(IMED)[9]巧妙地将像素点间的空间关系嵌入欧氏距离成为有效的图像相似性度量.
定义1[9]. 图像欧氏距离IMED.假设有2幅图像Aj∈r×c,Al∈r×c,其距离可表示为
(11)
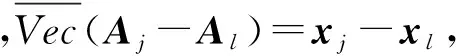
(12)
ii=(p-1)c+q,
jj=(p′-1)c+q′,
p,p′=1,2,…,r,q,q′=1,2,…,c.
由于矩阵G维度过高,通常计算困难,幸运的是能利用简单变换将其改写为
G=G1⊗G2,
(13)
对称矩阵G1∈r×r与G2∈c×c同式(8)(9).利用式(13),有如下定理:
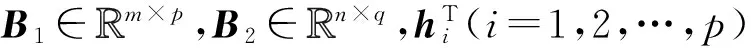
根据定理1可变换得到图像欧氏距离的矩阵版本如1.2节式(7)所示.因此即得图像欧氏距离对原始图像的光滑操作:
(14)
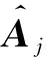
算法1. 全局图像欧氏距离光滑算法GIMED.
① 分别利用式(8)(9)计算G1,G2;
② fori=1 toNdo*对每个图像矩阵*
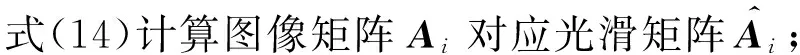
④ end for
2.1.2 局部图像欧氏距离光滑
除了对图像矩阵全局空间光滑,本文将IMED结合到第2阶段的图像矩阵划分重组(详见3.2节)之中,提出局部图像欧氏距离光滑算法(LIMED).
假设有2个原始图像Aj∈r×c,Al∈r×c,选择尺寸为m×n的空间窗口,利用如图2方式将其划分重组为
其中,K=(rc)(mn).
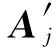
(15)
用式(7)中矩阵图像欧氏距离替换传统欧氏距离:
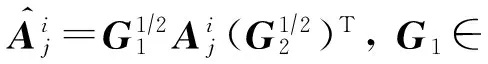
(16)
对于每个原始图像矩阵Aj,式(16)即为对其每一个空间窗口进行空间光滑操作,称为局部图像欧氏距离光滑算法LIMED.
2.1.3 双边滤波光滑
Tomasi等人[29]提出的双边滤波(bilateral filter, BLF)在处理相邻像素点的灰度值时,兼顾了几何空间上的临近关系和灰度值上的相似性,对两者非线性组合,自适应滤波后得到光滑图像,优点在于图像光滑的同时模糊的边缘信息能够得以保持.这里将其用作原图像全局光滑.
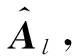
(17)
其中,Si,j表示以空间坐标(i,j)为中心点大小为(2M+1)×(2M+1)的邻域(或窗口),M为滤波器的半宽,M值越大,平滑作用越强,实验中取M=5.式(17)实际就是对中心像素点邻域内像素点灰度值的加权平均,w(p,q)为空间坐标(i,j)处的加权系数,由2部分因子的乘积组成:
w(p,q)=ws(p,q)wr(p,q),
(18)
其中,空间临邻近度因子ws(p,q)与灰度值相似度因子wr(p,q)分别表示为
(19)
(20)
其中,参数σs与σr分别控制空间邻近度因子与灰度值相似度因子的衰减程度.
双边滤波光滑算法详细过程如下.
算法2. 双边滤波光滑算法BLF.
① fori=1 toNdo*每个训练图像样本*
② for (p,q)=(1,1) to (r,c) do*对每个像素点*
③ 利用式(19)(20)计算(p,q)处的ws,wr;
⑤ end for
⑥ end for
2.2 图像划分重组
图像重组技术在人脸识别中已有广泛应用,如我们此前的工作MatPCA与MatFLDA[30]将向量模式重组为相应矩阵后再利用2DPCA与2DLDA特征抽取.SSSL[22]中分析了2D特征抽取方法只能整行或整列利用空间信息.实际上图像整行(或列)并不光滑,故这些2D嵌入函数的空间光滑度仍较粗.以此为动机的隐式正则化[19]将原始图像划分重组以体现列向量的光滑度,隐式地利用图像空间结构信息.
本文借鉴了ISR[19]的非重叠的划分策略,如图2所示,将给定的大小为r×c的光滑图像划分为K个相同尺寸(m×n)的空间窗口,K=(rc)(mn),依次将每个空间窗口拉成向量从而组成维度为mn×K的新矩阵.直观上,通过划分重组,新矩阵的列(相应空间窗口)通常是光滑的,隐含的局部空间关系得以高度充分地保留.
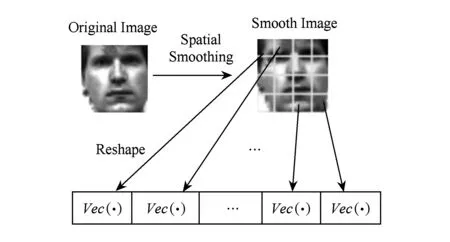
Fig. 2 An illustration of smoothed image reshaping in non-overlapping way图2 光滑图像的非重叠重组图示
2.3 单边2DLDA特征抽取
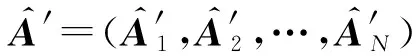
(21)
本文采用基于线性判别分析(LDA)的2D版本,单边2DLDA抽取特征.LDA通过最小化类内散度的同时最大化类间散度以将不同类别尽可能分开,在图嵌入框架中定义LDA准则,权重矩阵W′为
(22)
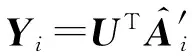
(23)
通过简单的公式变换,式(23)重写为
(24)
投影矩阵V的优化可通过解决下式(25)的特征分解问题求得,具体算法参考算法3中Step3.
(25)
2.4 分 类
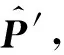
(26)
算法3. 2D-CISSE.
输出: 投影矩阵V.
Step1. 原始图像空间光滑.
① ifchoice=GIMED,执行算法1;
② 转到Step2;
③ end if
④ ifchoice=BLF,执行算法2;
⑤ 转到Step2;
⑥ end if
Step2. 划分重组.
① fori=1 toNdo*对每张图像*
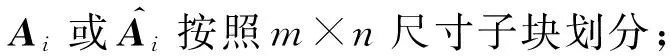
③ ifchoice=LIMED;*若选择LIMED算法*
④ forj=1 toKdo*K=rcmn*
⑤ 用式(16) 对每个空间窗口空间光滑;
⑥ end for
⑦ end if
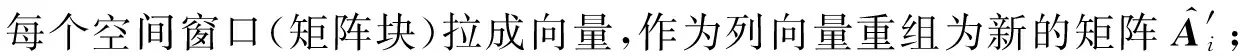
⑨ end for
Step3. 单边2DLDA.
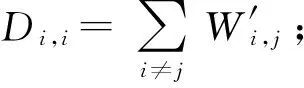
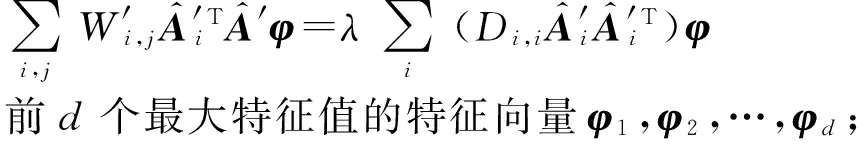
③V←(φ1,φ2,…,φd).
算法3分别将全局图像欧氏距离光滑算法GIMED、局部图像欧氏距离光滑算法LIMED和双边滤波算法BLF嵌入2D-CISSE框架中,得到3种算法:GIMED-ISR-S,LIMED-ISR-S,BLF-ISR-S.
2.5 算法复杂度分析
假设有N个训练样本,每个图像样本维度为r×c,空间窗口大小为m×n.本文利用的GIMED,LIMED,BLF三个光滑算法的计算复杂度分别为O(Nrc(r+c)),O(Nrc(m+n)),O(NrcM2),其中M为BLF的窗口半宽.本文2D-CISSE框架中图像划分重组与特征抽取2个步骤的计算复杂度同ISR-s,均为O((r3c3)(m3n3)),而ISR-b是由非凸问题获得,若其交替迭代优化选取的迭代次数为Ite,则其计算时间复杂度为O((m3n3+(r3c3)(m3n3))×Ite),SSSL与2DMLV的计算时间复杂度分别为O(r3c3)和O(N2rc+r3c3).因此可以发现:尽管需要付出Step1中对原始图像空间光滑的计算代价,但2D-CISSE框架在整体上依然具有最低的计算复杂度.
3 实 验
为验证2D-CISSE框架在现实数据集上的分类性能,将利用其所提出的GIMED-ISR-S,LIMED-ISR-S,BLF-ISR-S三个算法分别在4个人脸数据集(Yale,ORL,CMU PIE,AR)、3个手写数字数据集(MNIST350,MNIST2k2k,USPS)上与SSSL、非重叠ISR+双边2DLDA(简记为ISR-b)、非重叠ISR+单边2DLDA(简记为ISR-s)和2DMLV四个代表性的空间信息利用算法进行比较.表1为本文所用7个数据集的详细介绍.
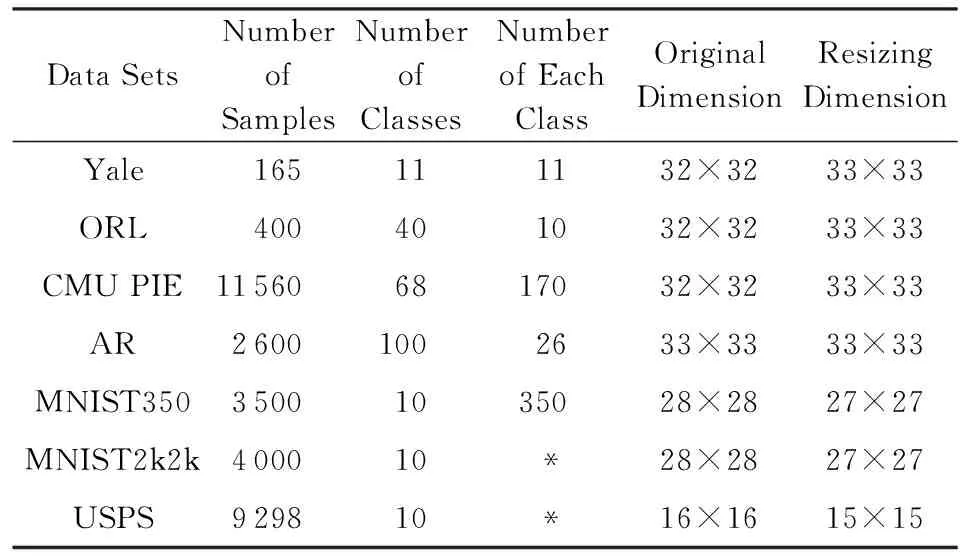
Table 1 Introduction of Datasets表1 数据集介绍
Note:“*” means each class has different numbers.
SSSL与2DMLV均采用5折(5-fold)交叉验证选取参数.本文算法和ISR在图像划分重组时均将空间窗口大小设为3×3(文献[26]中验证为最优),为了对图像完整地非重叠划分,利用近邻差值法将一些数据集的维度进行了调整,如表1所示.本文的BLF-ISR-S算法通过5折交叉验证获得不同训练样本量的参数σr与σs,基于图像欧氏距离的GIMED与LIMED的参数σ对训练样本数目弱敏感,因此每个数据集交叉验证获得的σ可运用于对其不同的训练划分.实验中,每个训练集均是从完整数据集随机采样获得.

Fig. 3 Sample images from Yale, ORL and CMU PIE datasets图3 来自Yale, ORL, CMU PIE数据集的样本图像
3.1 人脸数据集
表2为在图3所示的人脸数据集Yale,CMU PIE,ORL上的实验结果,表2中结果为20次随机采样训练的均值与标准差.可以发现:1)本文的3种算法均优于ISR-s,意味着对原始图像的光滑策略(Step1)确实提升了分类性能;2)2种全局光滑算法GIMED-ISR-S与BLF-ISR-S均获得比ISR-b,ISR-s,SSSL,2DMLV更优的分类性能;3)局部光滑策略LIMED-ISR-S的分类性能比起2种全局策略稍低,但在大部分训练集中能得到不低于4种对比算法的分类与稳定性能.
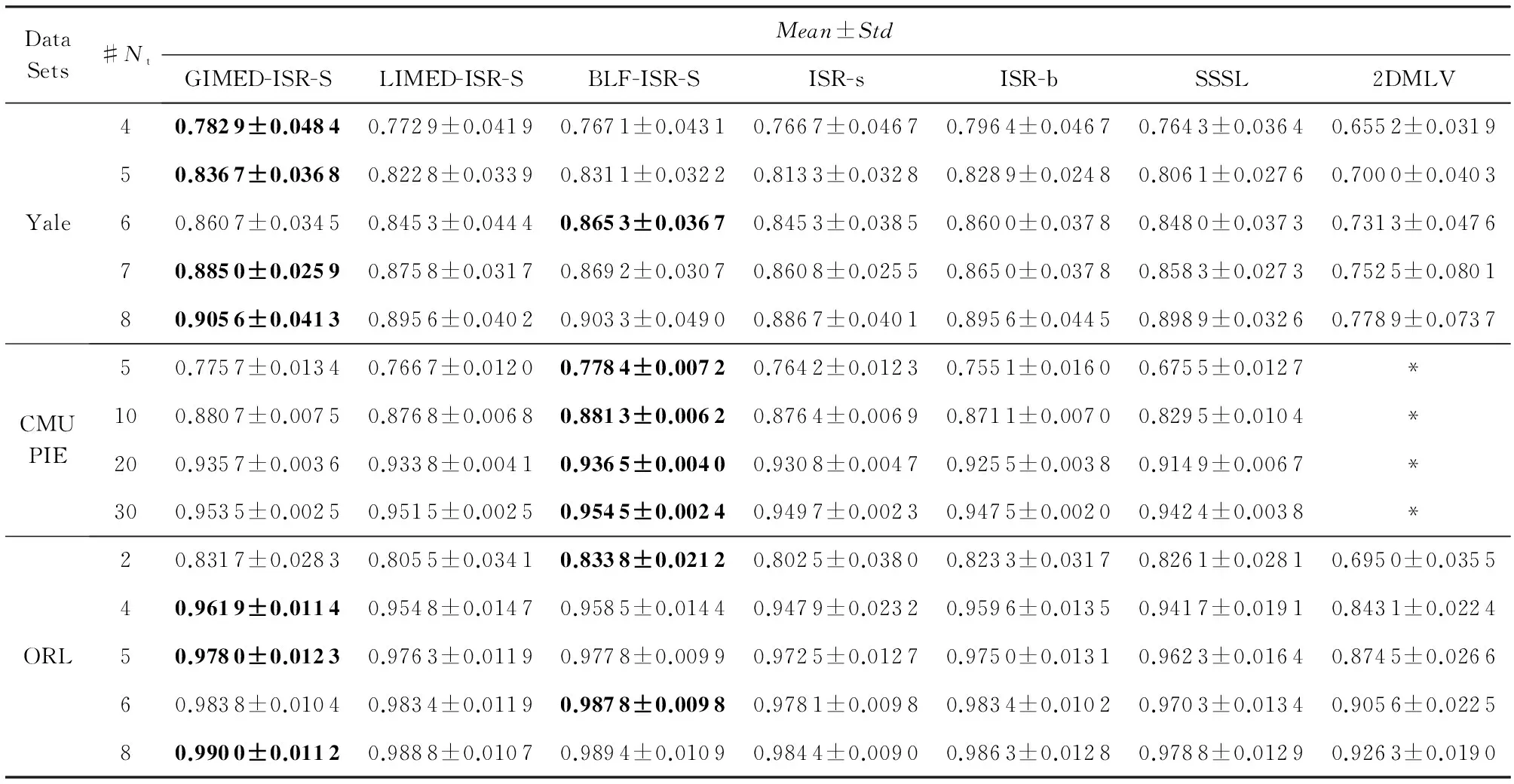
Table 2 Recognition Accuracy on Yale, CMU PIE, ORL Datasets表2 在Yale,CMU PIE,ORL数据集上分类识别率
Notes: The best performance in each line has been bolded;“#Nt”means number of samples for training in each class;“*”means out of memory (similarly hereinafter).
图4是AR人脸数据集,用于检测分类算法在有遮挡人脸集上的性能.图5中50次随机采样实验的结果显示:1)本文框架下3个算法均获得比ISR-b等方法更优的性能;2)局部光滑的LIMED-ISR-S所有训练划分中获得最优分类性能.

Fig. 4 Sample images from AR dataset图4 AR数据集的样本图像
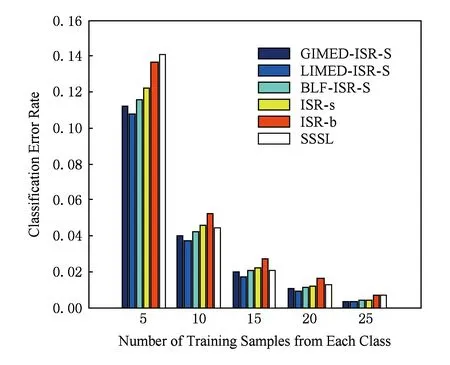
Fig. 5 Error rate (err) comparison on AR dataset图5 AR数据集上的错误率比较
3.2 手写字母数据集
手写数字数据集MNIST中常用的MNIST2k2k含有2000训练样本与2000测试样本,包含手写数字0~9共10个类别,一些图像样本如图6所示.为便于划分训练样本,本文从MNIST中每类随机抽取350个样本组成数据集MNIST350,并对其50次随机采样训练.如图7所示的USPS数据集将前7 291个样本作为训练集,余下用于测试.表3的实验结果表明:1)GIMED-ISR-S与BLF-ISR-S均能获得比ISR与SSSL更优的分类性能,且识别率比ISR-b分别提高10和15个百分点,前者在USPS数据集获得最优,后者在MNIST350与MNIST2k2k上获得最优识别率和最高的稳定性;2)LIMED-ISR-S稳定地优于ISR方法,略低于SSSL.

Fig. 6 Sample images from MNIST图6 MNIST数据集的图像示例

Fig. 7 Sample images from USPS图7 USPS数据集的图像示例
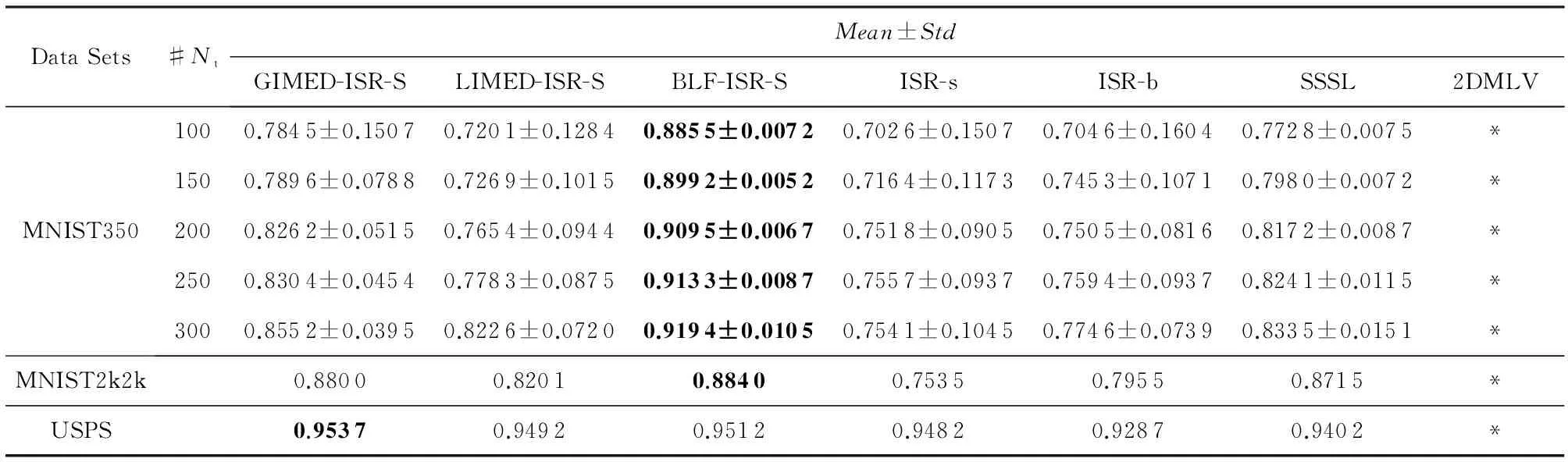
Table 3 Recognition Accuracy on MNIST350, MNIST2k2k, USPS Datasets表3 在MNIST350,MNIST2k2k,USPS数据集上分类识别率
Notes: The best performance in each line has been bolded;“#Nt”means number of samples for training in each class;“*”means out of memory (similarly hereinafter).
3.3 实验结果分析
上述一系列实验结果表明:1)无论GIMED -ISR-S,BLF-ISR-S还是LIMED-ISR-S在7个数据集上的分类识别率大部分优于ISR-s,ISR-b,SSSL,2DMLV.其中,GIMED-ISR-S与BLF-ISR-S在所有数据集中均显著优于其他方法,这表明本文的框架在隐性利用局部空间信息的同时对图像显性全局光滑能够更加充分且有效地利用图像的空间结构信息,提升分类性能.2)LIMED-ISR-S在7个数据集中的4个数据集上性能优于对比方法,在有遮挡人脸数据集AR上的分类性能显著最优,故在Step1采用局部光滑的策略相比全局光滑策略对一般图像分类性能提升较弱,但对于有遮挡的图像分类提升效果显著.
4 结 论
本文兼顾考虑图像空间结构信息的充分利用和计算代价的降低,提出了1种结合显性与隐性空间光滑的高效二维图像判别特征抽取框架(2D-CISSE).在2D-CISSE中,仅需简单地在ISR策略上融合原图像的显性光滑,图像的局部光滑性得到了充分保持和学习利用,结果仅需结合单边2DLDA即可获得比ISR结合双边2DLDA显著更优的性能.由3种图像光滑策略嵌入该框架得到的3个算法在标准数据集的实验结果验证了本文框架的有效性和性能的优越性,同时也体现了其一般适应性.相比其他方法,2D-CISSE具有3点优势:1)与SSSL相比,本文的框架是基于图像的2D方法,性能优于SSSL的同时降低了计算复杂度;2)与2DMLV相比,2D-CISSE不局限于图像欧氏距离单一光滑,其双重空间光滑使得空间信息得以更充分地利用,性能显著更优,其次,2DMLV的计算空间复杂度依赖于样本数量,2D-CISSE则避免了其训练样本数量较大导致的超出内存问题;3)与非重叠ISR相比,2D-CISSE使单边2DLDA即可获得比ISR+双边2DLDA更好的分类性能,计算复杂度得到显著降低.尽管2D-CISSE需要在Step1中付出图像空间光滑的计算代价,但这种代价相对于整体计算复杂度的降低很小.在对光滑图像划分重组后,并非每个空间窗口都能对分类起判别作用.因此,下一步工作一是重组矩阵的稀疏化,二是设计判别准则筛选空间窗口.
[1]Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C] //Proc of the Advances in Neural Information Processing Systems 25. Cambridge, MA: MIT Press, 2012: 1097-1105
[2]Sun Yi, Wang Xiaogang, Tang Xiaoou. Deeply learned face representations are sparse, selective, and robust[C] //Proc of the 28th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 2892-2900
[3]Dahl G E, Yu Dong, Deng Li, et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. IEEE Trans on Audio, Speech, and Language Processing, 2012, 20(1): 30-42
[4]Collobert R, Weston J. A unified architecture for natural language processing: Deep neural networks with multitask learning[C] //Proc of the 25th Int Conf on Machine Learning. New York: ACM, 2008: 160-167
[5]Belhumeur P N, Hespanha J P, Kriegman D J. Eigenfaces vs fisherfaces: Recognition using class specific linear projection[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1997, 19(7): 711-720
[6]Turk M, Pentland A. Eigenfaces for recognition[J]. Journal of Cognitive Neuroscience, 1991, 3(1): 71-86
[7]Murase H, Nayar S K. Visual learning and recognition of 3-D objects from appearance[J]. International Journal of Computer Vision, 1995, 14(1): 5-24
[8]Tian Qing, Chen Songcan, Tan Xiaoyang. Comparative study among three strategies of incorporating spatial structures to ordinal image regression[J]. Neurocomputing, 2014, 136: 152-161
[9]Wang Liwei, Zhang Yan, Feng Jufu. On the Euclidean distance of images[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1334-1339
[10]Li Jing, Lu Baoliang. A framework for multi-view gender classification[C] //Proc of ICONIP’07. Berlin: Springer, 2008: 973-982
[11]Li Jing, Lu Baoliang. An adaptive image Euclidean distance[J]. Pattern Recognition, 2009, 42(3): 349-357
[12]Chen Songcan, Wang Zhe, Tian Yongjun. Matrix-pattern-oriented Ho-Kashyap classifier with regularization learning[J]. Pattern Recognition, 2007, 40(5): 1533-1543
[13]Wang Zhe, Chen Songcan. New least squares support vector machines based on matrix patterns[J]. Neural Processing Letters, 2007, 26(1): 41-56
[14]Tian Yongjun, Chen Songcan. Matrix-pattern-oriented Ho-Kashyap classifier with regularization learning[J]. Journal of Computer Research and Development, 2005, 42(9): 1628-1632 (in Chinese)(田永军, 陈松灿. 面向矩阵模式的正则化Ho-Kashyap算法[J]. 计算机研究与发展, 2005, 42(9): 1628-1632)
[15]Wang Zhe, Zhu Changming, Gao Daqi, et al. Three-fold structured classifier design based on matrix pattern[J]. Pattern Recognition, 2013, 46(6): 1532-1555
[16]Wang Zhe, Chen Songcan, Liu Jun, et al. Pattern representation in feature extraction and classifier design: Matrix versus vector[J]. IEEE Trans on Neural Networks, 2008, 19(5): 758-769
[17]Yang Jian, Zhang D, Frangi AF, et al. Two-dimensional PCA: A new approach to appearance-based face representation and recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2004, 26(1): 131-137
[18]Ye Jieping. Generalized low rank approximations of matrices[J]. Machine Learning, 2005, 61(1/2/3): 167-191
[19]Li Ming, Yuan Baozong. 2D-LDA: A statistical linear discriminant analysis for image matrix[J]. Pattern Recognition Letters, 2005, 26(5): 527-532
[20]Ye Jieping, Janardan R, Li Qi. Two-dimensional linear discriminant analysis[C] //Proc of the Advances in Neural Information Processing Systems 17. Cambridge, MA: MIT Press, 2004: 1569-1576
[21]Luo Luo, Xie Yubo, Zhang Zhihua, et al. Support matrix machines[C] //Proc of the 32nd Int Conf on Machine Learning. New York: ACM, 2015: 938-947
[22]Cai Deng, He Xiaofei, Hu Yuxiao, et al. Learning a spatially smooth subspace for face recognition[C] //Proc of the 20th IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 1-7
[23]Zuo Wangmeng, Liu Lei, Wang Kuanquan, et al. Spatially Smooth Subspace Face Recognition Using LOG and DOG Penalties[M]. Berlin: Springer, 2009: 439-448
[24]Lotte F, Guan C. Spatially regularized common spatial patterns for EEG classification[C] //Proc of the 20th Int Conf on Pattern Recognition. 2010. Piscataway, NJ: IEEE, 2010: 3712-3715
[25]Gao Quanxue, Gao Feifei, Zhang Hailin, et al. Two-dimensional maximum local variation based on image Euclidean distance for face recognition[J]. IEEE Trans on Image Processing, 2013, 22(10): 3807-3817
[26]Zhu Yulian, Chen Songcan, Tian Qing. Spatial regularization in subspace learning for face recognition: Implicit vs. explicit[J]. Neurocomputing, 2016, 173: 1554-1564
[27]Yan Shuicheng, Xu Dong, Zhang Benyu, et al. Graph embedding and extensions: A general framework for dimensionality reduction[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2007, 29(1): 40-51
[28]Franklin J N. Matrix Theory[M]. New York: Dover, 2000
[29]Tomasi C, Manduchi R. Bilateral filtering for gray and color images [C] //Proc of the 6th Int Conf on Computer Vision. Piscataway, NJ: IEEE, 1998: 839-846
[30]Chen Songcan, Zhu Yulian, Zhang Daoqiang, et al. Feature extraction approaches based on matrix pattern: MatPCA and MatFLDA[J]. Pattern Recognition Letters, 2005, 26(8): 1157-1167
A Fast Discriminant Feature Extraction Framework Combining Implicit Spatial Smoothness with Explicit One for Two-Dimensional Image
Zhu Kuaikuai, Tian Qing, and Chen Songcan
(College of Computer Science & Technology, Nanjing University of Aeronautics & Astronautics, Nanjing 210016)
Images have two-dimensional inherent spatial structures, and the pixels spatially close to each other have similar gray values, which means images are locally spatially smooth. To extract features, traditional methods usually convert an original image into a vector, resulting in the destruction of spatial structure. Thus 2D image-based feature extraction methods emerge, typically, such as 2DLDA and 2DPCA, which reduce time complexity significantly. However,2D-based methods manipulate on the whole raw (or column) of an image, leading to spatially under-smoothing. To overcome such shortcomings, spatial regularization is proposed by explicitly imposing a Laplacian penalty to constrain the projection coefficients to be spatially smooth and has achieved better performance than 2D-based methods, but sharing the genetic high computing cost with 1D methods. Implicit spatial regularization (ISR) constrains spatial smoothness within each local image region by dividing and reshaping image and then executing 2D-based feature extraction methods, resulting in a performance improvement of the typical bi-side 2DLDA over SSSL (a typical ESR method). However, ISR obtains the spatial smooth implicitly but has lack of explicit spatial constraints such that the feature space obtained by ISR is still not smooth enough. The optimization criteria of bi-side 2DLDA are not jointly convex simultaneously, resulting in high computing cost and globally optimal solution cannot be guaranteed. Inspired by statements above, we introduce a novel linear discriminant model called fast discriminant feature extraction framework combining implicit spatial smoothness with explicit one for two-dimensional image recognition (2D-CISSE). The key step of 2D-CISSE is to preprocess spatial smooth for images, then ISR is executed. 2D-CISSE not only retains spatial smooth explicitly, but also reinforces the explicit spatial constraints. Not only can it achieve globally optimal solution, but it also have generality, i.e. any out-of-shelf image smoothing methods and 2D-based feature extraction methods can be embedded into our framework. Finally, experimental results on four face datasets (Yale, ORL, CMU PIE and AR) and handwritten digit datasets (MNIST and USPS) demonstrate the effectiveness and superiority of our 2D-CISSE.
spatial smooth; image Euclidean distance; implicit spatial regularization(ISR); feature extraction; matrix-based pattern

Zhu Kuaikuai, born in 1992. Master candidate. His main research interests include machine learning and pattern recognition.

Tian Qing, born in 1984. PhD candidate. Student member of CCF. His main research interests include machine learning and pattern recognition.

Chen Songcan, born in 1962. Professor and PhD supervisor. Senior member of CCF. His main research interests include pattern recognition, machine learning and neural networks.
2016-03-11;
2016-05-05
国家自然科学基金项目(61472186);高等学校博士学科点专项科研基金项目(20133218110032) This work was supported by the National Natural Science Foundation of China (61472186) and the Specialized Research Fund for the Doctoral Program of Higher Education (20133218110032).
陈松灿(s.chen@nuaa.edu.cn)
TP391.41; TP751
猜你喜欢
数学年刊A辑(中文版)(2022年3期)2023-01-05
新高考·高一数学(2022年3期)2022-04-28
电讯技术(2022年3期)2022-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
高中生学习·高三版(2016年9期)2016-05-14
火控雷达技术(2016年3期)2016-02-06
新高考·高二数学(2015年11期)2015-12-23
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
