
Action Recognition with Temporal Scale-Invariant Deep Learning Framework
2017-05-08 01:46:52HuafengChenJunChenRuiminHuChenChenZhongyuanWang
China Communications 2017年2期
Huafeng Chen , Jun Chen , Ruimin Hu *, Chen Chen, Zhongyuan Wang
1 State Key Laboratory of Software Engineering, Wuhan University, Wuhan 430072, China
2 National Engineering Research Center for Multimedia Software, Computer School of Wuhan University, Wuhan 430072, China
3 Center for Research in Computer Vision, University of Central Florida, Orlando, FL 32816, USA
* The corresponding author, email: hrm@whu.edu.cn
I. INTRODUCTION
Human action recognition aims to enable computer automatically recognize human action in video through related features. Visual features extracted from videos are crucial for dealing with these issues and designing effective action recognition systems [1-8]. Traditional action features can be divided into two categories: hand-crafted features and deep-learned features.
The hand-crafted features are artificially designed based on the statistical properties of the frame pixels in video. Laptev [9] developed space-time interest points (STIP) by extending image Harris detector to video and integrated the HOG/HOF descriptors to represent local spatio-temporal features of STIP[10]. Scovanner et al. [11] proposed a 3D version of scale-invariant feature transform(3D-SIFT) descriptor. Willems et al. [12] extended the SURF descriptor of image to video domain by computing weighted sums of uniformly sampled responses of spatiotemporal Haar wavelets. Klaser et al. [13] designed a 3D version of HOG descriptor (HOG3D) for video action recognition. Yeffet and Wolf [14]proposed Local Trinary Patterns for videos as the extension of Local Binary Patterns (LBP).Wang et al. [15] introduced motion boundary histograms in Dense Trajectories (DT) to suppress camera motions, and further proposed a camera motion estimation method in [16]to explicitly rectify the image to remove the camera motion. Benefited from double camera motion inhibition, the iDT in [16] performs the best in action recognition accuracy among the hand-crafted features. However, the shortcoming of hand-crafted descriptors is that they are not optimized for visual representation and lack discriminative capacity for action recognition [17].
Encouraged by the success of CNNs in image classification [18], researchers have exploited the deep-learned features for video action recognition. Taylor et al. [19] proposed convGRBM algorithm to unsupervised learn spatio-temporal features by using Gated Restricted Boltzmann Machine (GRBM). Ji et al. [20] extended 2D CNN to 3D CNN for action recognition. They put gray maps, gradient maps and optical flow maps of raw video frames into multi-channel CNNs. Karpathy et al. [21] introduced several CNN architectures based on stacked RGB images for video classification. Simonyan and Zisserman [22]designed the two-stream architecture which exploits two CNNs to model static appearance and motion variation of action respectively.Based on two-stream CNNs and iDT, Wang et al. [17] designed Trajectory-pooled Deep-Convolutional (TDD) descriptors which enjoy the merits of CNNs and trajectory based method.While the deep-learned features with CNN architecture distinctly improve the accuracy of action recognition compared to hand-crafted features, they are not able to model the longterm temporal structure among frames in a video.
Recently, Ng et al. [23] utilized the recurrent Long Short Term Memory (LSTM) architecture to capture temporal structure of consecutive frames. Donahue et al. [24] proposed a temporal LSTM structure similar to [23].Wu et al. [25] fed the spatial CNN feature and the motion CNN feature [22] into two sets of LSTM networks for modeling long-term temporal clues. They also employ a regularized feature fusion network to fuse the video-level features. Srivastava et al. [35] learned the unsupervised deep action representations based on a composite LSTM model. Generally, the LSTM-based frameworks model temporal clues among video frames and gain the stateof-the-art performances by integrating deep learning architecture of CNN and LSTM.
Nevertheless, current LSTM-based methods sample keyframes by serial [23,24] or fixed number [25] sampling strategies, which cannot cope with the change of action speed.Actions have great differences in execution time. Taking the UCF101 dataset [26] for example, the frame numbers of different action sequences vary from 200 to more than 400.An action consists of a number of sub-actions in order. For example, the action of “clean and jerk” can be divided into four sub-actions:clean the weight to the chest, squat, jerk, and keep standing. The videos in the same action class have an equal number of sub-actions while they have different frame numbers. The temporal scales of sub-actions in an action can change, therefor affecting the action speed.The traditional serial (or fixed number) keyframe sampling strategy is mechanically and is not robust to the temporal scale variation of sub-action in an action video.
To this end, in this paper we propose a novel temporal scale-invariant deep learning framework for action recognition, as shown in Figure 1. The motivation is, instead of using serial or fixed number sampling, we extract keyframes of sub-action clips in an action video to represent the sub-actions. As shown in Figure 1, wefirstly split a video into multiple sub-action clips. A keyframe is sampled from every sub-action clip to represent the sub-action since the frames in each sub-action are similar in appearance while the frames from different sub-actions have significant differences. Based on the keyframe and its adjacent frames, we calculate optical flow maps.We put the keyframe and the corresponding optical flows into CNN [22] architecture separately, and fuse the two-stream CNN features.The fused features of sampled frames in every clip are served as the input of the LSTM framework. The outputs of the sequence-based LSTM are combined as thefinal predictions.
The contributions of this paper are summarized as follows:
1) We find sub-action based keyframe sampling is temporal scale-invariant to action speed and is better for action recognition than serial or fixed number sampling.
2) We propose a sub-action segmentation method based on recent Deepbit feature [29],and evaluate the effect of keyframe location in the sub-action on the action recognition accuracy.
3) We introduce convolutional fusion in LSTM framework for action recognition.
The rest of this paper is organized as follows. In Section II, we present the proposed temporal scale-invariant deep learning framework in detail. We conduct the experiments on UCF101 [26] and HMDB51 [27] action recognition databases in Section III. Finally, we conclude this paper in Section IV.
II. PROPOSED APPROACH
In this section, we start with the presentation of temporal sub-action clustering and keyframe sampling, then introduce the training/testing method of the spatial and motion CNN.Based on fused descriptors of spatial and motion CNN features, we describe the long-term LSTM-based temporal modeling framework and video-level prediction scores combination methods.
2.1 Sub-action clustering
Formally, given a video sequenceis the frame index of the video), sub-actions group thevideo frames intosequential segments:

We expect a sub-action in a video to have enough motion information that can express a part of action and at the same time it should not be too long that includes irrelevant motions. Fig. 2 illustrates the process of sub-action clustering. Specifically, we create a binary code for each frame based on Deepbit feature[29]. We select 32-bit length for the binary codes since it is the optimal length for image matching [29]. These binary codes should have similar hamming distance for similar points in the CNN feature space. By moving across the frames, we pick the frames that their binary codes are different from their previous frames as the start of the next clip.By repeating the cycle, a video is divided into several segmentations.
Affected by the variation of camera angle and other factors, the numberof the segmented clips of a video may be more or less than practical sub-actions amount of m. Whenwe merge part of small segmentations to draw near to the sub-actions. We start the merging process from the shortest clip based on the assumption that the long segments can better represent the sub-actions than the small clips in a video. The shortest clip is merged into its adjacent clip which has more frames.The process of merging ends when the number of segments is equal to the number of sub-actions. If(rarely happens in experiments), we split part of long segmentations to draw near to the sub-actions. The longest clip is divided into two equal parts, and the split process ends when the number of segments is equal to the number of sub-actions.
2.2 Keyframe sampling
A keyframe sampled from sub-action clip can effectively describe a stage in the evolution of the action [28]. Also, using a keyframe representing a sub-action is able to adapt to the variation of sub-action speed. Theoretically,we can sample the keyframe at any location in the sub-action clip

where α is the parameter of step size. We’ll evaluate the effect of α on action recognition accuracy in Section 3.2.
2.3 Feature extracting
We follow the two-stream architecture [22]and extract the spatial and the short-term motion features from the sampled keyframes. For training/testing CNN model, we select VGG-16 model instead of VGG-M-2048 model as the former significantly improved action recognition accuracy than the latter [27, 28].
In order to learn robust features from CNNs, we adopt three data augmentation strategies [32]. Firstly, we randomly crop a 224×224 patch from keyframe. Secondly, the cropped patches are horizontally flipped by random. Finally, we use a scale jittering strategy to help CNN to learn robust features [31].We crop a patch on three scales (1, 0.875, and 0.75), which yield the scaled patches of size 224×224, 196×196, and 168×168. The scaled patches are then resized to 224×224. In testing phase, we disuse the data augmentation strategy and just crop one 224×224 patch from the center of testing frame.

Fig.2 Deepbit feature based sub-action clustering
Spatial CNN is pre-trained on ImageNet dataset [33] and then the model parameters arefinely tuned on action recognition datasets. In the process of spatial CNN training, the learning rate is set to 10-3, decreases to its 1/10 every 4K iterations, and stops at 10K iterations[31]. We set 0.9 drop out ratios for the two fully connected layer of the spatial CNN.
For training the temporal CNN, we use optical flow stacking with L=10 frames [22] for learning the short-term motion features around keyframe. We pre-compute the optical flow of images by using the GPU implementation of[34] from the OpenCV toolbox. The horizontal and vertical components of the optical flow are linearly scaled to a [0, 255] range just like two channel images. The training procedure of temporal CNN is similar to spatial CNN while the input data is a 224×224×20 sub-volume.The learning rate initiated from 10-3, decreases to its 1/10 every 10K iterations, and stops at 30K iterations [31]. We set 0.9 and 0.8 drop out ratios for the fully connected layer of the temporal CNN.
2.4 Feature fusing
In this section, we consider fusing the two stream CNNs to establish the correspondence among the channel responses at the same pixel position. As an example, we consider discriminating between the actions of opening the door and closing the door. The two actions are identical in appearance and only opposite in motion direction. When a hand moves at some spatial location in the video, the temporal CNN can recognize that motion (opening or closing), and the spatial CNN can recognize the hand location and their combination can discriminate the two actions.
For feature fusing using in the LSTM framework, the experimental results in [24]have shown that the sum fusion at thefirst full connect (FC) layer perform better than at the last FC layer. Wu et al. [25] also adopt thefirst FC layer as the feature fusion layer. Recently,Feichtenhofer et al. [30] have verified that the convolutional (Conv) fusion method perform well than traditional method of sum fusion at FC layer [22] under CNN based action recognition. In this paper, we introduce the Conv fusion method for the LSTM based action recognition framework, and compare it to the traditional sum fusion method.

We briefly introduce the concatenation fusion as it is the basis of the Conv fusion[30]. The concatenation fusion functioncombines the two feature maps at the same spatial locations h,w across the feature channels d:

T h e C o n v f u s i o n f u n c t i o nfirstly combines the two feature maps at the same spatial locations h,w across the feature channels d as (4) and then convolves the combined data [30] with a batch offilters

where the filter has the dimension ofand the number of output channels is
2.5 Sequence modeling
The sequential keyframes of an action video represents the temporal evolution of the action.We select the LSTM framework for modeling this action evolution. The LSTM is a kind of Recurrent Neural Networks (RNN) with controllable memory units and is efficient in many long-term sequential modeling tasks without suffering from the vanishing and exploding gradients problem in traditional RNNs. Usually, LSTM recursively maps the input represen-tations at the current time step to output labels via a sequence of hidden statesand thus the learning process of LSTM should be in a sequential manner (as shown in Fig.1).
As a neural network, the LSTM model can easily go deep by stacking the hidden states from a layer l-1 as inputs of the next layer l. Considering a framework of K layers, the fused feature vectorof the keyframe in the j-th sub-action segment is fed into the first layer of the LSTM framework together with the hidden statein the same layer obtained from last time step to produce an updated, which will then be used as inputs of the following layer.
Following [25], we adopt two-layered LSTM framework for temporal modeling (as shown in Fig.1). The upper layer of the LSTM has 1,024 hidden units and the bottom layer has 512 hidden units. The network weights are learnt using a parallel implementation of the method of back propagation through time(BPTT). The mini-batch size is set to 10. Additionally, the learning rate and momentum are set to 10-4and 0.9 respectively. The training is stopped at 150K iterations. The outputs of the LSTM model form the prediction score set
In order to combine LSTM frame-level prediction scores into a single video-level prediction, Ng et al. [23] have evaluated four approaches: 1) returning the prediction at the last time step, 2) max-pooling the predictions over time, 3) summing the predictions over time and return the max, 4) linearly weighting the predictions over time by 0…1 then sum and return the max. The difference of the accuracy for the four methods was less than 1%, and weighted predictions always resulted in the best performance, supporting the idea that the LSTM’s hidden states become progressively more informed as a function of the number of frames. Wu et al. [25] proposed the first method and returning the prediction at the last time step. The video-level prediction method in [24] is similar to the third approach, but it averaged the sum scores. In this paper, we follow [23] and select the weighted predictions method for video-level prediction. The final prediction score is defined as

where m is the sub-action number of an action.
III. EXPERIMENTS AND RESULTS
In this section, we show the action recognition performance of the proposed method. Wefirstly introduce the datasets for evaluating our proposed approach. Then we analyze the effects of parameterandon action recognition accuracy. Thirdly, the keyframe sampling strategies are discussed. We also compare the convolutional fusion with the traditional sum fusion under LSTM framework. Finally, the proposed method is compared with the stateof-the-art methods.
3.1 Datasets and parameter settings
We evaluate the proposed approach on two popular action recognition datasets: UCF101[26] and HMDB51 [27]. The datasets are the two largest datasets for action recognition, and extremely challenging for researchers [35-41].
The UCF101 dataset contains 101 action classes and there are at least 100 video clips for each class. The whole dataset contains 13,320 video clips. Following the evaluation scheme of the THUMOS14 challenge and adopt the three training/testing splits for evaluation. Results are measured by classification accuracy on each split and we report the mean accuracy over the three splits.
The HMDB51 dataset is a large collection of realistic videos from movies and web videos. The dataset is composed of 6,766 video clips from 51 action categories, with each category containing at least 100 clips. Our experiments follow the evaluation scheme in [27]and use three different training/testing splits.Each action class has 70 clips for training and 30 clips for testing in every split. We select the average accuracy over three splits as thefinal recognition performance. Since UCF101 is larger than HMDB51, we use the UCF101 dataset to train two-stream CNNs initially, and transfer this learned model for two-stream feature extraction on the HMDB51 dataset.
3.2 Parameter analysis

Fig.3 Influence of sub-action number m on recognition accuracy on UCF101(split1)

Fig.4 Influence of sampling parameter α on recognition accuracy on UCF101(split1)
We first analyze the influence of sub-action number m on the recognition accuracy. The experiments are carried out on the first split(split1) of UCF101. The sampling parameterisfixed at 1 which ensures the frame is sampled from the middle position of a sub-action segment. The spatial and motion features are fused by Conv fusion at the RELU5_3 layer.The experiment results are presented in Fig.3.We observe that the recognition accuracies rise rapidly when the parametervaries from 2 to 6, and reach to peak whenis 7. Therefore,wefixat 7 in the following experiments.
We then discus in fluence of sampling step size α on the recognition accuracy. The experiments are also conducted on thefirst split(split1) of UCF101. From the experimental results (shown in Fig.4), we observe that the recognition accuracies reach to peak when α=1, which shows the keyframe sampled from middle of the sub-action segment (α=1) is the most representative image for the sub-action.More interestingly, the curve of recognition accuracies is nearly symmetric, the symmetry axis is located at α=1. Thus, we use α=1 in the following experiments.
3.3 CNN feature fusion evaluation
In this section, we compare the Convolutional fusion with the sum fusion. Summing the spatial and the motion CNN features at FC6 layer is adopted by the traditional LSTM based framework in [21, 22]. In this paper we select the Conv fusion at RELU5_3 layer by following [30]. The comparison results between the two methods are reported the average accuracy over all three splits of UCF101 (as shown in Table I). The recognition accuracy based on Conv fusion method is 93.7%, improved 1.4% compared to the accuracy based on the sum fusion. Moreover, fusing the features at RELU5_3 layer saves almost half of the training/testing parameters (149.6M) than at FC6 layer (252.1M) because the parameters in FC6 layer account for more than 70% of the total parameters of CNN framework.
3.4 Sampling strategy evaluation
To evaluate the effectiveness of the proposed
sub-action based frame sampling strategy,we compare it with the traditional sampling strategies: serial sampling and fixed number sampling. For serial sampling, we follow the sampling method in [24] and extract 16 frame clips with a stride of 8 frames from each video and average across clips. For fixed number sampling, we sample a fixed number of 25 frames for the deep learning framework by following the sampling method in [19, 22].The results are reported the average accuracy over all three splits of UCF101 and HMDB51 in Table II. For UCF101 dataset, according to Table II, we can learn that the recognition accuracy of our method is 93.7% which is 1.9%higher than that of fixed number sampling approach, and 2.4% higher than that of serial sampling method. On HMDB51 dataset, the average improvement of the proposed method over the second best method is 3.5%. In general, the proposed temporal scale-invariant deep learning framework obviously improves the action recognition accuracy.
3.5 Comparison with the state-ofthe-art
Finally, we compare our method with the state-of-the-art over all three splits on UCF101 and HMDB51. As shown in Table III, our temporal scale-invariant deep learning framework produces the highest performance on the two datasets. Both on the UCF101 and HMDB51 dataset, many works with competitive results are based on two-stream CNN feature. Compared with the result of the original Conv fusion method in [30] (92.5%, 65.4%), our framework (93.7%, 69.5%) is better with the additional LSTM framework to explore the temporal clues among the keyframes in video.The recent LSTM-based works [20, 21] adopted different LSTM neural networks, so the results are not directly comparable. Our deep learning framework is similar to [25], but our results improved 2.4% compared to [25].
IV. CONCLUSIONS
In this paper, we have proposed a novel tem-poral scale-invariant deep learning framework for action recognition. The main idea is sampling keyframes from every sub-action sequence in an action video for representing the sub-action and thus learning the deep sequential feature from the action related keyframes.We also introduced the Conv fusion method to characterize the pixel-level correlation between the spatial and motion CNN features. The proposed method can significantly improve the accuracy of action recognition.Experimental results on two public benchmark databases have demonstrated its superiority over the state-of-the-art methods.

Table I CNN feature fusion evaluation on UCF101
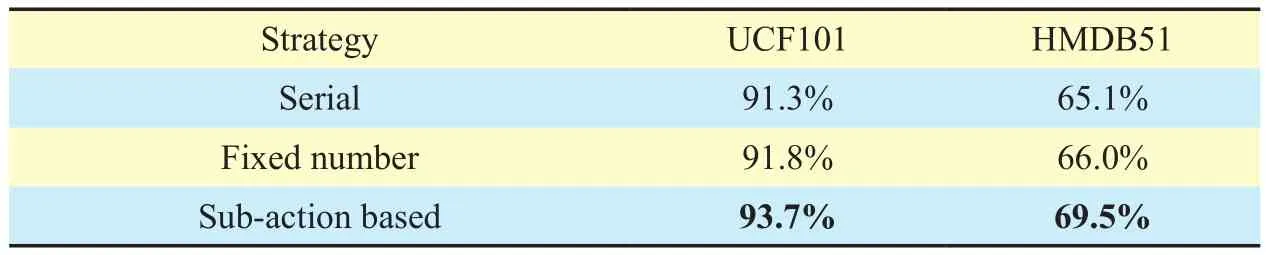
Table II Sampling strategy evaluation on UCF101 and HMDB51

Table III Comparison with state-of-the-art results on UCF101 and HMDB51
ACKNOWLEDGEMENTS
This work was supported in part by the National High Technology Research and Development Program of China (863 Pro-gram) (2015AA016306), the National Nature Science Foundation of China (61231015),the Technology Research Program of Ministry of Public Security (2016JSYJA12),the Shenzhen Basic Research Projects(JCYJ20150422150029090), and the Applied Basic Research Program of Wuhan City(2016010101010025).
[1] P Afsar, P Cortez, H Santos, “Automatic visual detection of human behavior: a review from 2000 to 2014”,Expert Systems with Applications,vol. 42, no. 20, pp. 6935-6956, 2015.
[2] D Weinland, R Ronfard, E Boyer, “A survey of vision- based methods for action representation, segmentation and recognition”,Computer Vision and Image Understanding, vol. 115, no. 2,pp. 224-241, 2011.
[3] Y Shan, Z Zhang, K Huang, “Visual human action recognition: history, status and prospects”,Journal of Computer Research and Development,no. 1, pp. 93-112, 2016.
[4] C Chen, Z Gan, “Action recognition from a different view”,China Communications, vol. 10, no.12, pp. 139-148, 2013.
[5] W Song, N.N Liu, G.S Yang, et al, “A novel human action recognition algorithm based on decision level multi-feature fusion”,China Communications, vol. 12, no. 2, pp. 93-102, 2015.
[6] C Chen, R Jafari, N Kehtarnavaz, “Fusion of depth, skeleton, and inertial data for human action recognition”,Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 2712-2716, 2016.
[7] C Chen, R Jafari, N Kehtarnavaz, “Action recognition from depth sequences using depth motion maps-based local binary patterns”Proceedings of the IEEE Winter Conference on Applications of Computer Vision, pp. 1092-1099,2015.
[8] C Chen, R Jafari, N Kehtarnavaz, “UTD-MHAD:A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor”,Proceedings of IEEE International Conference on Image Processing, pp. 168-172,2015.
[9] I Laptev, “On space-time interest points”,International Journal of Computer Vision, vol. 64, no.2-3, pp. 107-123, 2005.
[10] I Laptev, M Marszalek, C Schmid, et al, “Learning realistic human actions from movies”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-8, 2008.
[11] P Scovanner, S Ali, M Shah, “A 3-dimensional sift descriptor and its application to action recognition”,Proceedings of the 15th internationalconference on Multimedia, pp. 357-360, 2007.
[12] G Willems, T Tuytelaars, G.L Van, “An efficient dense and scale-invariant spatio-temporal interest point detector”,Proceedings of the 10th European Conference on Computer Vision, pp.650-663, 2008.
[13] A Klaser, M Marszałek, C Schmid, “A spatio-temporal descriptor based on 3d-gradients”,Proceedings of the 19th British Machine Vision Conference, pp. 271-210, 2008.
[14] L Yeffet, L Wolf, “Local trinary patterns for human action recognition”,Proceedings of IEEE 12th International Conference on Computer Vision,pp. 492-497, 2009.
[15] H Wang, A Kläser, C Schmid, et al, “Dense trajectories and motion boundary descriptors for action recognition”,International Journal of Computer Vision, vol. 103, no. 1, pp. 60-79,2013.
[16] H Wang, D Oneata, J Verbeek, et al, “A robust and efficient video representation for action recognition”,International Journal of Computer Vision, pp. 1-20, 2015.
[17] L Wang, Y Qiao, X Tang, “Action recognition with trajectory-pooled deep-convolutional descriptors”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp.4305-4314, 2015.
[18] O Russakovsky, J Deng, H Su, et al, “ImageNet large scale visual recognition challenge”,International Journal of Computer Vision, vol. 115,no. 3, pp. 211-252, 2015.
[19] G.W Taylor, R Fergus, Y Lecun, et al, “Convolutional learning of spatio-temporal features”,Proceedings of European conference on computer vision, pp. 140-153, 2010.
[20] S Ji, W Xu, M Yang, et al, “3D convolutional neural networks for human action recognition”,IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 1, pp. 221-231, 2013.
[21] A Karpathy, G Toderici, S Shetty, et al, “Largescale video classification with convolutional neural networks”,Proceedings of IEEE conference on Computer Vision and Pattern Recognition,pp. 1725-1732, 2014.
[22] K Simonyan, A Zisserman, “Two-stream convolutional networks for action recognition in videos”,Proceedings of Advances in Neural Information Processing Systems, pp. 568-576, 2014.
[23] J.Y Ng, H Matthew, S Vijayanarasimhan, et al,“Beyond short snippets: deep networks for video classification”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 4694-4702, 2015.
[24] J Donahue, H.L Anne, S Guadarrama, et al,“Long-term recurrent convolutional networks for visual recognition and description”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 2625-2634, 2015.
[25] Z Wu, X Wang, Y Jiang, et al, “Modeling spa-tial-temporal clues in a hybrid deep learning framework for video classification”,Proceedings of the 23rd Annual ACM Conference on Multimedia Conference, pp. 461-470, 2015.
[26] K Soomro, A.R Zamir, M Shah, “UCF101: A dataset of 101 human actions classes from videos in the wild”,arXiv preprint, 2012.
[27] H Kuehne, H Jhuang, E Garrote, et al, “HMDB: a large video database for human motion recognition”,Proceedings of International Conference on Computer Vision, pp. 2556-2563, 2011.
[28] M Ravanbakhsh, H Mousavi, M Rastegari, et al,“Action recognition with image based cnn features”,arXiv preprint, 2015.
[29] K Lin, J Lu, C.S Chen, et al, “Learning compact binary descriptors with unsupervised deep neural networks”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[30] C Feichtenhofer, A Pinz, A Zisserman, “Convolutional two-stream network fusion for video action recognition”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[31] L Wang, Y Xiong, Z Wang, et al, “Towards good practices for very deep two-stream convnets”,arXiv preprint, 2015.
[32] B Zhang, L Wang, Z Wang, et al, “Real-time action recognition with enhanced motion vector cnns”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[33] K Chat field, K Simonyan, A Vedaldi, et al, “Return of the devil in the details: delving deep into convolutional nets”,arXiv preprint, 2014.
[34] T Brox, A Bruhn, N Papenberg, et al, “High accuracy optical flow estimation based on a theory for warping”,Proceedings of European conference on computer vision, pp. 25-36, 2004.
[35] N Srivastava, E Mansimov, R Salakhudinov, “Unsupervised learning of video representations using lstms”,Proceedings of the 32nd International Conference on Machine Learning, pp.843-852, 2015.
[36] W Zhu, J Hu, G Sun, et al, “A key volume mining deep framework for action recognition”,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[37] H Bilen, B Fernando, E Gavves, et al, “Dynamic image networks for action recognition”,Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, 2016.
[38] B Fernando, P Anderson, M Hutter, et al, “Discriminative hierarchical rank pooling for activity recognition”,Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, 2016.
[39] X Wang, A Farhadi, A Gupta, “Actions - transformations”,Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, 2016.
[40] J Jiang, R Hu, Z Wang, Z Han, and J Ma, “Facial image hallucination through coupled-Layer neighbor embedding”,IEEE Transactions on Circuits and Systems for Video Technology, vol. 26,no.9, pp. 1674-1684, 2016.
[41] Z Wang, R Hu, C Liang, et al. “Zero-shot person re-identification via cross-view consistency”,IEEE Transactions on Multimedia, vol. 18, no. 2,pp. 260-272, 2016.

- China Communications的其它文章
- High-Performance Beamformer and Low-Complexity Detector for DF-Based Full-Duplex MIMO Relaying Networks
- An Open IoT Framework Based on Microservices Architecture
- Open Access Strategy in Cloud Computing-Based Heterogenous Networks Constrained by Wireless Fronthaul
- Distributed Document Clustering Analysis Based on a Hybrid Method
- RGB Based Multiple Share Creation in Visual Cryptography with Aid of Elliptic Curve Cryptography
- Orchestrating Network Functions in Software-Defined Networks