
Distributed Document Clustering Analysis Based on a Hybrid Method
2017-05-08 01:46:47JudithJayakumari
China Communications 2017年2期
J.E. Judith, J. Jayakumari
Noorul Islam Centre for Higher Education, Kumaracoil, India.
I. INTRODUCTION
An era powered by the constant progress in Information Technology ventures on multitudes of opportunities on data analysis, information retrieval and transaction processing as the size of information repositories keep on expanding each day. This is due to enormous growth in the volume of information available on the internet, such as Digital Libraries, Reuters, Social Medias, etc. There is a dramatic increase in the volume and scope of data which forms huge corpus or databases.
Clustering or unsupervised learning is one of the most important fields of machine learning which splits the data into groups of similar objects helping in extraction or summarization of new information. It is used in a variety of fields such as statistics, pattern recognition and data mining. This research focuses on the application of clustering on data mining. Clustering is one of the major areas in data mining that has a vital role in answering to the challenges of every IT industry.
Data mining is a procedure to discover patterns from large datasets. Text mining is a sub- field of data mining that analyses a large collection of document datasets. The prime challenge incurred in thisfield is the amount of electronic text documents available which when increases exponentially makes room for effective methods to handle these documents.Also it is infeasible to centralize all the documents from multiple sites to a centralized location for processing. Nowadays these document datasets are increasing tremendously which often referred to as Big Data. The problems of analysis on these datasets are referred to as a curse of dimensionality since they are often highly dimensional.
Distributed computing plays a major role in data mining due to these reasons. Distributed Data Mining (DDM) has evolved as a hot research area to solve these issues [29]. The use of machine learning in distributed environments for processing massive volumes of data is a recent research area. It is one of the important and emerging areas of research due to the challenges associated with the problem of extracting unknown information from very large centralized real-world databases.
Document clustering has been investigated for use in a number of different areas of text mining and information retrieval. It is regarded as a major technology for intelligent unsupervised categorization of content [3] in text form of any kind; e.g. news articles, web pages, learning objects, electronic books, even textual metadata. Document clustering groups similar documents to form a coherent cluster while documents that are different are separated into different clusters [6]. The quality of document clustering in both centralized and decentralized environments can be improved by using an advanced clustering framework.
Most of the conventional document clustering methods is designed for central execution[4] which maintains a single large repository of documents where clustering analysis is performed. They require clustering to be performed on a dedicated node, and are not suitable for deployment over large scale distributed networks [21]. These methods are based on the assumption that the data is memory resident, which makes them unable to cope with the increasing complexity of distributed algorithms. So there is an eminent need for mining knowledge from distributed resources [4]. Therefore, specialized algorithms for distributed clustering have to be developed[1], [8]. Distributed clustering algorithms are needed to overcome the challenges in distributed document clustering.
In order to support data intensive distributed applications [13], an open source implementation based on Hadoop is used for processing of large datasets. MapReduce is a functional programming model [7] for distributed processing over several machines. The important idea behind MapReduce framework is to map the datasets into a group of <key,value> pairs, and then reduce all pairs with the same key [10]. A map function is performed by each machine which takes a part of the input and maps it to <key, value> pairs [28].This is then send to a machine which applies the reduce function. The reduce function combines the result for further processing. The outputs from the reduce function are then fed into the appropriate map function to begin the next round of processing.
In this proposed work, a hybrid PSOKMeans (PKMeans) distributed document clustering method is formulated for better speedup and accuracy of document clustering.Along with these conceptual and algorithmic changes there is also a need to use any of the emerging frameworks for distributed analysis and storage. Today’s enterprises use Big Data infrastructure for analytical engineered applications [18]. One of the evolving technologies is the MapReduce methodology and its open source implementation is Hadoop. This proposed method of document clustering is based on MapReduce methodology which improves the performance of document clustering and enables handling of large document dataset.
Section 2 highlights related work in the area of MapReduce based distributed document clustering using PSO. Section 3 describes the proposed methodology, the experimental setup and the document sets used for analysis. Result analysis and discussions are done at Section 4. The paper concludes at Section 5.
II. RELATED WORKS
A brief review on the MapReduce based distributed document clustering is described in this section. Andrew W. McNabb et al. (2007)proposed [2] a method for optimizing large volume of data by parallelizing PSO algorithm in order to optimize individual function evaluations. The results indicate that with more particles than the number of processors, the performance of the MapReduce system is improved. The system is not able to handle the dynamic changes in particles. Ibrahim Aljarah and Simone A. Ludwig (2012) proposed [9] a Parallel Particle Swarm Optimization Clustering Algorithm based on MapReduce Methodology. The author used synthetic and real data sets for evaluation. The experimental results reveal that scalability and speedup increases with increasing data set size while maintaining the clustering quality. An efficient DBSCAN algorithm based on MapReduce was proposed[22] by Yaobin et al. This algorithm solved the problems of existing parallel DBSCAN algorithms. The algorithms scalability and efficiency is improved by fully parallelized implementation and removing any sequential processing bottleneck. Z. Weizhong et al. introduced [23] a parallel K-means algorithm clustering algorithm based on MapReduce.The Map function calculates the centroids as the weighted average of each individual cluster points; and the Reduce function calculates a new centroid for each data point based on the distance calculations. The final centroids are determined using MapReduce iterative refinement technique.
Ping et al. in [17] proposed an algorithm for document clustering using the MapReduce based on K-means algorithm. MapReduce is used to read the document collection and to calculate the term frequency and inverse document frequency. The performance of the algorithm is improved for clustering text documents with improved accuracy. Another K-means clustering algorithm using MapReduce was suggested by Li et al. in [15].This algorithm merges the K-means algorithm with ensemble learning method bagging. Outlier problem is solved using this algorithm and is efficient for large data. S. Nair et al. proposed a modification of self-organizing map(SOM) clustering using Hadoop MapReduce to improve its performance. Experiments were conducted with large real data sets which show an improvement in efficiency. S. Papadimitriou et al. proposed [19] a MapReduce framework to solve co-clustering problems. Usage of MapReduce for co-clustering provides good solution and can scale well for large data sets.Yang et al. in [11] proposed a big data clustering method based on the MapReduce framework. Parallel clustering is done based on ant colony approach. Data analysis is improved by using ant colony clustering with MapReduce.The proposed algorithm showed acceptable accuracy with good improved efficiency.
The proposed method is a hybrid algorithm based on MapReduce framework. This method utilizes optimization approach to generate optimal centroids for clustering. The global search ability of PSO algorithm improves the performance of the proposed method.
III. PROPOSED APPROACH
3.1 Overview of the Process
The different steps followed in this methodology are,
1. Choosing a document dataset to perform analysis. A variety of document datasets are publicly available and used for text mining research.
2. Document preprocessing is done to reduce the number of attributes. The input text documents are transformed in to a set of terms that can be included in the vector model.
3. Document vector representation is performed to represent the documents in a vector form by determining the term weight.Term weight is an entry in the Document Term Matrix (DTM) which is determined based on MapReduce methodology.
4. These document vectors are clustered using a hybrid PSO KMeans clustering algorithm based on MapReduce methodology(MR-PKMeans).
The overview of the process is shown in fig.1.
3.2 Document vector representation based on mapreduce
The pre-processed documents are represented as a vector using vector space model. Documents have to be transformed from full text version to a document vector [24] which describes the content of the document. Let D={d1, d2…..dn} be a set of documents and let T ={t1, t2,…..tm} be the set of distinct terms occurring in D. Each document is represented on a Document-Term Matrix (DTM). Each entry in the document-term matrix is the term weight.Terms that appear frequently in a small number of documents but rarely in other documents, tend to be more relevant and specific for that group of documents. These terms are useful for finding similar documents. To capture these terms and reflect their importance tf*idf weighting scheme is used. For each index terms, the term frequency (tf) in each document and the inverse document frequency (idf) are calculated to determine the term weight based on Equation 3.1,
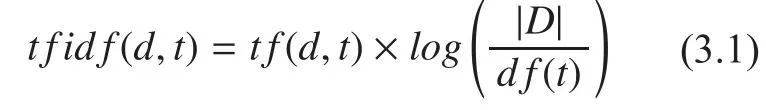
where df(t) is the number of documents in which term t appears.
Map and Reduce function
The input to the Map function includes the document dataset stored in HDFS. The document dataset is split and <key, value> pairs are generated for each individual text documents in the dataset. The key is the doc ID and the value is the terms in the document <docID,term>. The Map function determines the term frequency of each term in the document. The list of terms frequency of each term in the document collection are given as input to reduce function which combines the term frequency to form a Document Term Matrix. Document term matrix is normalized by including the inverse document frequency along with the term frequency for each entry in the matrix as determined in Equation 3.1. The pseudo code for DTM construction based on MapReduce is shown in fig.2.
3.3 Proposed enhanced mapreduce based distributed document clustering method
A multidimensional document vector space is modeled as a problem space in this proposed document clustering method. Each term in the document datasets represent one dimension of the problem space. This enhanced model as proposed includes two modules MR-PSO module, MR-KMeans module. Multiple MapReduce jobs are chained together to improve the quality and accuracy of clusters with reduction in execution time.

Fig.1 Overview of the process

Fig.2 Pseudo code for document vector representation based on MapReduce
3.3.1 MR-PSO module
PSO is an iterative global search method.According to PSO each particles location in the multidimensional problem space represents a solution for the problem. A number of candidate clustering solutions for document collection are considered as a swarm.A different problem solution is generated when the location of the particle changes. The problem solution moves through the search space by following the best particles [12]. It moves through the search space looking for a personal best position. The velocity of each particle determines the convergence to an optimal solution. The inertia weight, particle personal experience and global experience will influence the movement of each particle in the problem space. A fitness value [14] is assigned by the objective function to each particle which has to be optimized based on the position. Thefitness function is defined according to the property of the problem where it is applied. The quality of clustering solution depends on the fitness function defined. It represents the average distance between document vector and cluster centroids. Thefitness evaluation is based on the following Equation 3.2.

Where d(ti, nj) is the distance between document nijand the cluster centroid ti.,Piis the document number, Ncis the cluster number.The velocity and position of new particle are updated based on the following equations,
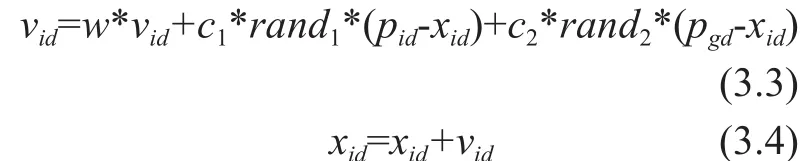
Where vidis the velocity and xidis the position of the particle w represents the inertia weight pidis the personal best position where the particle experience the best fitness value and pgdis the global best position where the particle experience a global fitness value c1and c2denotes the acceleration coefficient,rand1and rand2are random values [25] with the values between (0, 1).The personal, global best positions and velocity of each particle are updated based on Equations 3.3 and Equations 3.4., where the two major operations are performed in this module; such asfitness evaluation and particle centroids updates. PSO module for generating optimal centroids for clustering is summarized as follows,
For each particle
Initialize each particle with k numbers of document vectors from document collection as cluster centroid vectors
END
LOOP
For each particle
Assign each document vector to the closest centroid vectors.
Calculate fitness value based on equation 3.1
If the fitness value is better than the previous personal best fitness value (pBest) set current value as the new pBest.
Update the particle position and velocity according equations 3.3 and 3.4
respectively to generate the next solution.END
While maximum number of iterations is reached
Choose the particle with the best fitness value of all the particles as the global best(gBest) fitness value. gBest value gives the optimal cluster centroids.
Map and Reduce function
The input to the Map function includes the tf-idf representation of documents stored in HDFS. Map function splits the documents and<key, value> pairs are generated for each individual text document in the dataset. In thefirst module the MapReduce job is used for generating optimal centroids using PSO. The map function evaluates thefitness of each particle in the swarm. All the information about the particle such as particleID, Cluster vector(C),Velocity vector(V), Personal Best Value(PB),Global Best Value(GB) are determined.
The particleID represents the key and the corresponding content as the value. The col-lection of <key, value> pairs contained in files is referred to as blocks. The pseudo code for the map and reduce function is given below. The particle swarm is retrieved from the distributed storage. For each particleID the map function extracts centroids vectors and calculates the average distance between centroids vector and document vector. It returns a new fitness value based on global best values to the reduce function. The reduce function aggregates the values with the same key and updates the particle position and velocity. The reduce function emits the global best centroids as the optimal centroids to be stored in HDFS for the next module. The pseudo code for the determination optimal centroids is summarized in Fig.3.3.
3.3.2 MR-KMeans module
For the first iteration the clustering process gets the optimal initial cluster centroids from PSO and for the other iteration it gets cluster centroids from the last MapReduce output.The clustering process works according to the MapReduce program for similarity calculation,assignment of document to clusters and recalculation of new cluster centroids. KMeans algorithm repeats its iteration until it meets the convergence criterion which is the maximum iteration. The similarity measurement is based on Jaccard similarity which compares the sum weight of shared terms to the sum weight of terms that are present in either of two documents but are not the shared terms,

Where taand tbare n-dimensional term vectors over the term set. The recalculation of new cluster centroids as the mean of the document vectors in that cluster is determined using the following equation 3.6,

Where njis the number of document vectors with in cluster Qjand djis the document vector that belong to cluster Qj.
The description of KMeans clustering method for generating document clusters are summarized as follows,
o Retrieve the cluster centroids vector from PSO module.
o Determine the cluster similarity using Jaccard similarity given in equation 3.5 and assign each document vector to the cluster centroids which has maximum similarity

Fig.3 Pseudo code for the determination of optimal centroids based on MapReduce
o Recalculate the cluster centroids using equation 3.6 as the mean of the document vectors in the cluster.
Map and Reduce function
The input to the Map function includes two parts, the input document dataset stored in HDFS and the centroids got from PSO or from the last iteration are stored in centers directory in HDFS. First the input document dataset is split as a series of <key, value> pairs in each node where key is the docID and value is the content of the document. At each Mapper calculate the similarity between each document vector and the cluster centroids using Jaccard coefficient and assign the document vector to the cluster centroids with the maximum similarity. This is repeated for all the document vectors. A list of <key, value> pairs with centroidID as the key and cluster contents as value is given to reduce function. The reduce function updates the centroids by finding the sum of all the document vectors with the same key. The new centroidID and the cluster contents are stored in HDFS to be used for the next round of MapReduce job. The pseudo code for the MapReduce job to perform K-Means clustering using optimal centroids is given in Fig.4.

Fig.4 Pseudo code for proposed hybrid method for document clustering based on MapReduce
3.4 Experimental setup
The distributed environment is set up using Hadoop cluster environment to evaluate the performance of the proposed clustering algorithm. Hadoop version used is 0.20.2. Each node of the cluster consists of Intel i7 CPU 3GHz, 1TB of local hard disk storage reserved for HDFS [26] and 8GB for main memory.All nodes are connected by standard gigabit Ethernet network on a flat network topology.Table 4.1 shows the con figuration of Hadoop cluster. Parallel jobs are submitted on the parallel environment like Hadoop (MapReduce).Hadoop is run in a pseudo distributed mode where each Hadoop daemon runs as a separate process.
3.4.1 Document datasets
The Reuters Corpus is a benchmark document dataset [6] contains newspaper articles and have been widely used for evaluating clustering algorithms. It covers a wide range of international topics including business and finance,lifestyle, politics, sports etc. They are categorized into different categories such as topic,industry, region etc. which consume 3,804MB corpus size.
Reuters Corpus Volume 1(RCV1) introduced by Lewis et al. consists of about 800000 documents in XML format for text categorization research [27]. They were collected over Reuter’s newswire during 1-year period. The documents contained in this corpus were sent over the Reuters newswire and is available at[27].Table 3.2 summarizes the characteristics of the dataset,
3.4.2. Document dataset preparation
In order to represent the documents the docu-ment datasets are preprocessed using common procedures like stemming using default porters algorithm[16], stopword removal, pruning,removal of punctuations, whitespaces, numbers and conversion to lowercase letters. Each of the extracted terms represents a dimension of the feature space. In this work the feature weighting scheme used is a combination of term frequency and document frequency known as term frequency-inverse document frequency (tf-idf) as in equation 4.1. It is based on the idea that terms that appear frequently in a small number of documents but rarely in other documents, tend to be more relevant and specific for that group of documents.
IV. PERFORMANCE ANALYSIS AND DISCUSSION
There are a variety evaluation metrics in order to evaluate the performance of the proposed clustering algorithm. The accuracy of the proposed clustering algorithm is determined using SSE (Sum of Squared Error) and performance is analyzed with respect to execution time.
4.1 Analysis of clustering accuracy
Clustering accuracy is determined using internal similarity criteria SSE for choosing appropriate cluster solution at which SSE slows down dramatically. It measures the intra-cluster (within) similarity of documents with in a cluster.
Within cluster sum of squares (within-SSE)error as given in eqn.7 is used to determine cohesion.

The between cluster sum of squares is used to determine cluster separation and is described as,

Where |Si| is the size of cluster i. The total SSE = within-SSE + BSS. To determine the impact of particle swarm optimization algorithm (PSO) on the accuracy of clusters and in order to make a fair comparison of accuracy ahighly recommended PSO setting [20] is used for analysis. The initial swarm size considered was 100 particles, inertia weight, w = 0.72 and acceleration coefficient, c1&c2is 1.7. Let k be the number of clusters to be generated. For the given dataset the algorithm is executed for a range of k. The MR-KMeans algorithm is repeated with random initial centroids and the mean value of purity is recorded. Similarly the proposed hybrid algorithm with PSO generat-ed centroids is executed on the dataset.

Table 3.1 Experimental environment

Table 3.2 Characteristics of dataset for evaluation

Table 3.3 Initial feature space dimensions using terms after preprocessing
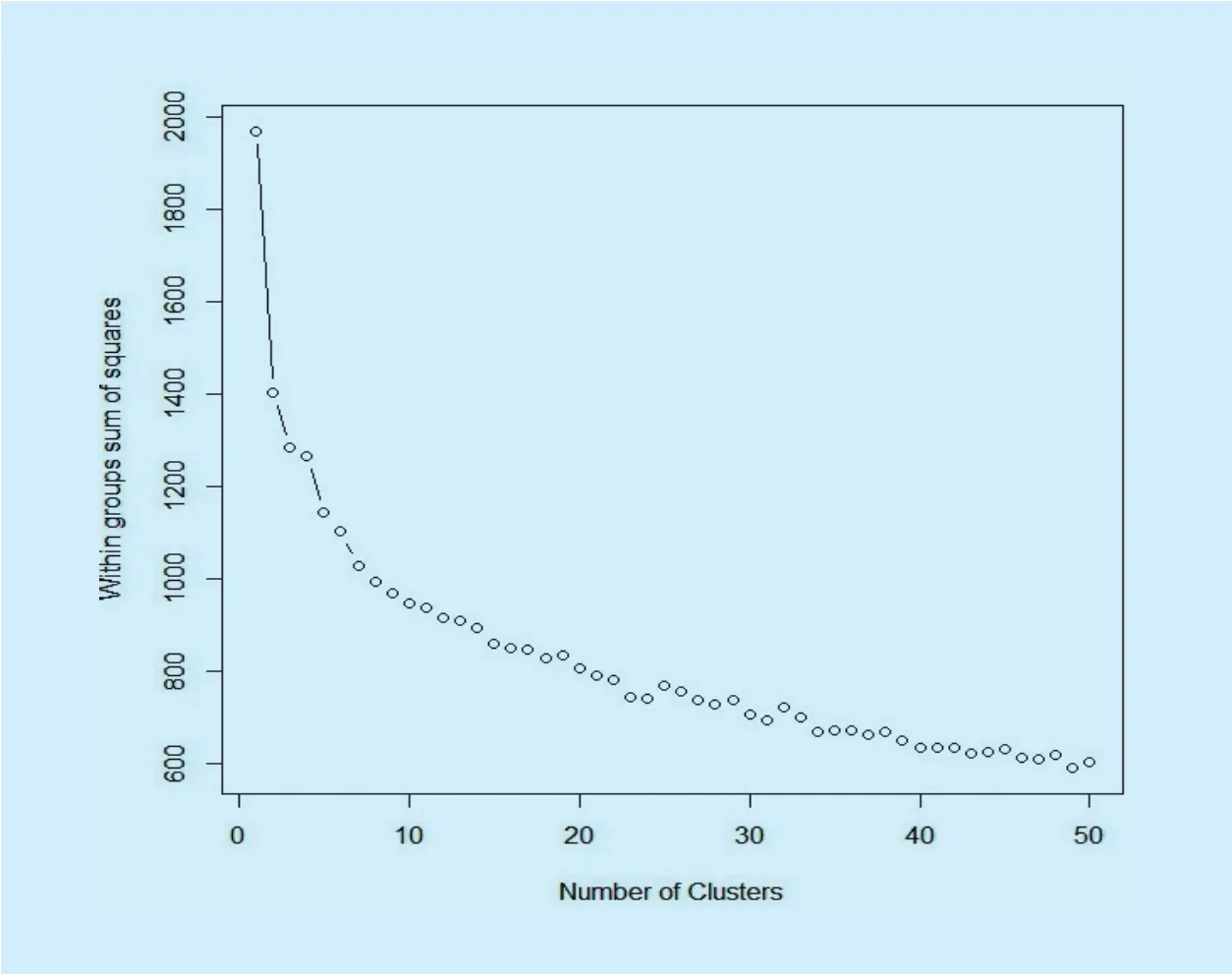
Fig.5 SSE for 50 clusters
Results show that clustering solutions greater than 30 do not have substantial impact on the total SSE. Clustering solution generated is more optimal or stable due to proper initial cluster centroids provided using particle swarm optimization algorithm. Fig 5 describes the SSE for 50 clusters. Results show that clusters achieve reduction in sum of square error by 81% for the generation of 50 cluster solutions.
Fig. 6 shows the performance comparison of the algorithms considering accuracy. Results show that the accuracy of the centralized version of the hybrid method is 77% for the generation of 50 clusters. Results for the comparison of accuracy using the internal index for both centralized and the proposed distributed method shows a comparable performance improvement for the distributed hybrid algorithm with increase in the number of clusters.

Fig.6 Comparison of accuracy
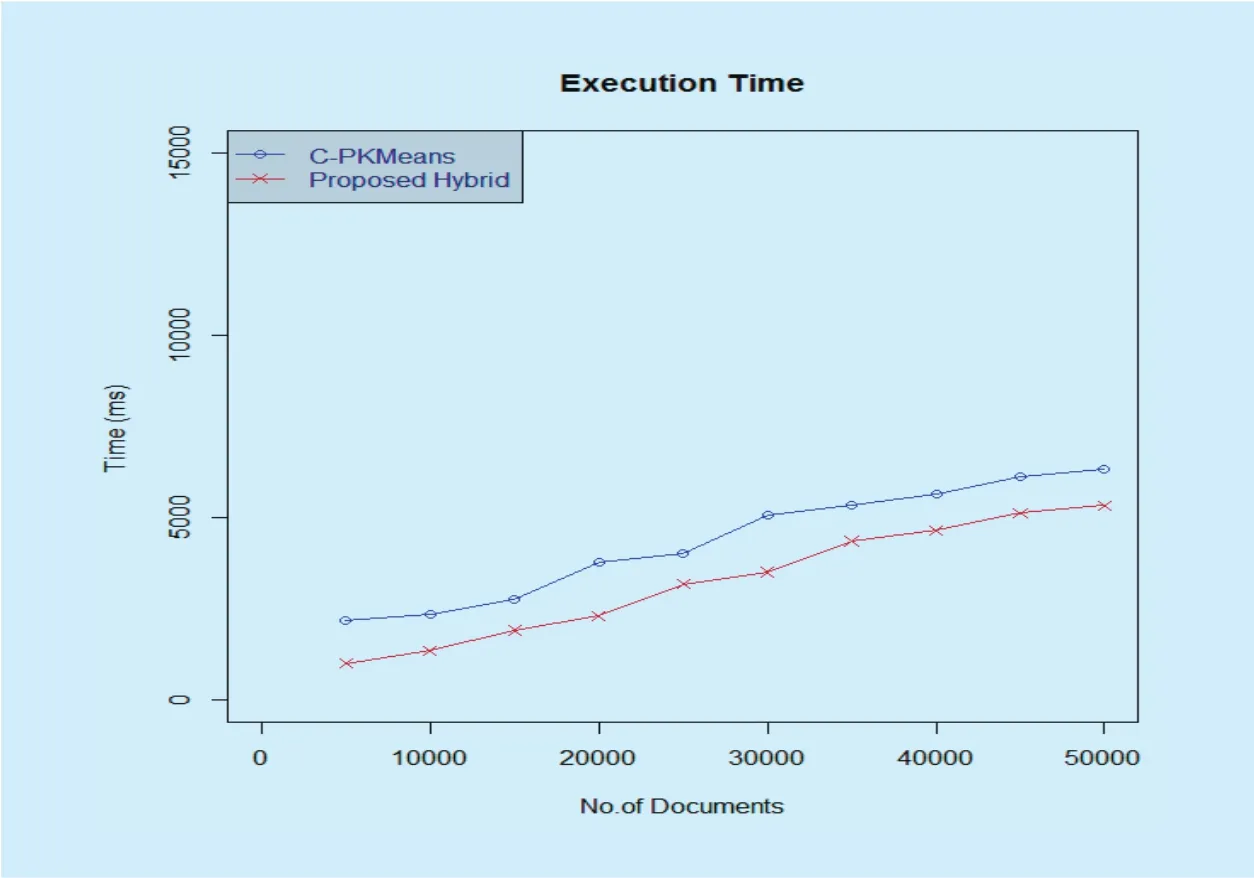
Fig.7 Comparison of execution time
4.2 Analysis of execution time
In order to analyze the execution time of proposed hybrid method, the number of documents in the test data set is increased and the execution time is plotted against the number of documents. The experiment is repeated to get the mean value of execution time for the given number of documents. Results show that for relatively small number of documents the performance of proposed MapReduce hybrid algorithm is only comparable with that of centralized version of the hybrid algorithm. There is a tremendous improvement in the speedup of the system with increase in the number of documents. Fig.7 shows that the execution time for the proposed method decreases with increase in the number of documents.
Table 3.4 and Fig.8 shows the comparison in execution time for different datasets when considering the number of Hadoop nodes. It can be seen from the graph that there is a tremendous reduction in execution time for the proposed Hybrid clustering on different datasets compared to centralized K-Means clustering method and distributed MR-KMeans. The execution time is measured in seconds(s).
The execution time of MR-KMeans and proposed hybrid method is only comparable. PSO algorithm normally requires large number of iterations to converge but in the proposed distributed method the maximum number of iterations of MR-PSO is limited to 25. The optimal centroids are generated within that iteration. The computational requirement required by PSO is reduced since it is implemented using distributed hardware such as HDFS (Hadoop Distributed File System) in Hadoop.
4.3 Performance comparison with existing centralized clustering algorithms
The performance of the efficient hybrid distributed document clustering method is compared with the performance of existing methods on a centralized node. All the centralized existing methods of clustering utilize Euclidean distance as the similarity measure to determine the closeness between the document vectors.
4.3.1 Analysis of clustering accuracy
The standard centralized K-Means algorithm converges within 50 iterations to a stable clustering result, but PSO requires more iteration to converge. For comparison purpose,KMeans and PSO are limited to 50 iterations for document clustering. PSO is able to assign documents to appropriate cluster based on thefitness value of document [44]. Thefitness of a particle is determined based on the average distance between document and cluster centroids. If the average distance is smaller thefitness of the document is greater. The average accuracy of clusters for the document dataset, Reuters and RCV1 is 70% and 65% for centralized KMeans clustering algorithm and 73% and 68% for centralized PSO clustering method. The KPSO clustering method adopts 25 iterations for KMeans to converge and PSO is allowed 25 iterations to generate an optimal solution. Experimental results show that KPSO clustering method is able to assign documents to clusters with the average accuracy value for the all the 50 clusters of Reuters and RCV1 to 81% and 79% respectively. The comparision of clustering quality with exiting centried clustering method is shown in fig.9.
The proposed hybrid distributed document clustering method based on MapReduce methodology provides a tremendous increase in the clustering accuracy.
4.3.2 Analysis of execution time
Table 3.6 describes the comparison of the execution time of the proposed MapReduce based Hybrid method with the existing centralized methods. It demonstrates that the distributed Hybrid method shows significant improvement in execution time compared to other centralized existing clustering methods. The corresponding graph is given in Fig.10 whichdescribes the execution time analysis of the proposed hybrid method with other existing centralized clustering methods.

Table 3.4 Comparison of execution time of proposed hybrid method

Table 3.5 Comparison of clustering accuracy with existing centralized methods

Table 3.6 Comparison of execution time with existing centralized methods

Fig.8 Comparison of execution time of proposed MapReduce based (MR-PKMeans)clustering method with other clustering methods

Fig.9 Comparison of clustering quality with existing centralized clustering method
From Fig.10 it can be seen that there is a tremendous reduction in execution time for the proposed Hybrid method compared to centralized clustering algorithms. The proposed Hybrid method determines optimized related document clusters with improved speedup.

Fig.10 Comparison of execution time with existing centralized clustering methods
V. CONCLUSION AND FUTURE WORK
In this paper, design and implementation of a hybrid PSO KMeans clustering (MR-PKMeans) algorithm using MapReduce framework was proposed. The PKMeans clustering algorithm is an effective method for document clustering; however, it takes a long time to process large data sets. Therefore, MR-PKMeans was proposed to overcome the inefficiency of PKMeans for big data sets. The proposed method can efficiently be parallelized with MapReduce to process very large data sets. In MR-PKMeans the clustering task that is formulated by KMeans algorithm utilizes the best centroids generated by PSO. The global search ability of optimization algorithm generates results with good accuracy and reduced execution time. Future work is to apply MR-PKMeans in real application domains.
[1] Aboutbl Amal Elsayed and Elsayed Mohamed Nour, “A Novel Parallel Algorithms for Clustering Documents Based on the Hierarchical Agglomerative Approach”,Int’l Journal of Computer Science & Information Technology, vol.3, issue 2, pp.152, Apr.2011.
[2] Andrew W. McNabb, Christopher K. Monson,and Kevin D. Seppi, “Parallel PSO Using MapReduce”,IEEE Congress on Evolutionary Computation (CEC 2007), pp.7-14, 2007.
[3] Anna Huang, “Similarity Measures for Text Document Clustering”,Proceedings of the New Zealand Computer Science Research Student Conference,pp. 49-56, 2008.
[4] B.A. Shboul and S.H. Myaeng. “Initializing K-Means using Genetic Algorithms”,World Academy of Science, Engineering and Technology,vol.54,2009
[5] Cui X., & Potok T. E., “Document Clustering Analysis Based on Hybrid PSO + Kmeans Algorithm”,Journal of Computer Sciences,Special Issue, pp. 27-33, 2005.
[6] D.D. Lewis, Reuters-21578 text categorization test collection distribution 1.0http://www.research.att.com /lewis,1999.
[7] E. Alina, I. Sungjin, and M. Benjamin, “Fast clustering using MapReduce,” inProceedings of KDD’11. NY, USA: ACM, pp. 681–689, 2011.
[8] Eshref Januzaj, Hans-Peter Krigel and Martin Pfei fle,” Towards Eff ective and Effi cient Distributed Clustering”,Workshop on Clustering Large Data Sets, Melbourne, 2003.
[9] Ibrahim Aljarah and Simone A. Ludwig, “Parallel Particle Swarm Optimization Clustering Algorithm based on MapReduce Methodology”,Fourth World Congress on Nature and Biologically Inspired Computing (NaBIC), pp. 105-111,2012.
[10] J. Wan, W. Yu, and X. Xu, “Design and implementation of distributed document clustering based on MapReduce”,Proceedings of the 2nd symposium on International Computer Science and Computational Technology, pp.278–280,2009.
[11] J. Yang and X. Li, “MapReduce based method for big data semantic clustering,” inProceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, SMC’13. Washington, DC, USA: IEEE Computer Society, pp.2814–2819, 2013.
[12] J.J. Li, X. Yang, Y.M. Ju and S.T. Wu, “Survey of PSO clustering algorithms”,Application Research of Computers,vol. 26, no.12, Dec.2009.
[13] Kathleen Ericsson and Shrideep Pallickara, “On the performance of high dimensional data clustering and classification algorithms”,Future Generation Computer Systems,June 2012
[14] Kennedy, J., Eberhart, R.C., “Particle swarm optimization”,IEEE International Conference on Neural Networks, pp. 1942–1948,1995.
[15] L. Guang, W. Gong-Qing, H. Xue-Gang, Z. Jing,L. Lian, and W. Xindong, “K-means clustering with bagging and mapreduce,” inProceedings of the 2011 44th Hawaii International Conference on System Sciences. Washington, DC, USA: IEEE Computer Society, pp. 1–8, 2011.
[16] M.F. Porter, “An algorithm for suffix stripping”,Program electronic library and information systems, vol. 14, Issue 3, pp.130 – 137, 1980.
[17] Ping hou, Jingsheng Lei, Wenjun Ye, “Large-Scale Data Sets Clustering Based on MapReduce and Hadoop”,Journal of Computational Information Systems,vol.7, no.16, pp. 5956-5963,2011.
[18] S. Nair and J. Mehta, “Clustering with apache Hadoop,”Proceedings of the International Conference, Workshop on Emerging Trends in Technology, ICWET’11. New York,NY, USA: ACM, pp.505–509, 2011.
[19] S.Papadimitriou and J.Sun,“Disco.Distributed co-clustering with MapReduce:Acasestudy towards petabyte-scale end-to-end mining”,Proceeding of the eighth IEEE International Conference on Data Mining,pp.512-521,2008.
[20] Shi,Y.H and R.C.Eberhart, “Parameter selection in particle swarm optimization”,The 7thAnnual Conf.EvolutionaryProgramming.SanDiego.C.A,1998.
[21] SouptikDatta, K. Bhaduri, Chris Giannella, Ran Wolff and Hillol Kargupta, “Distributed Data Mining in Peer-to-Peer Networks”,IEEE Internet Computing,vol.10, no.4, August 2006, pp.18-26.[22] Y. He, H. Tan, W. Luo, S. Feng, and J. Fan,“Mr-dbscan:a scalable Mapreduce-based dbscan algorithm for heavily skewed data,”Frontiers of Computer Science, vol. 8, no. 1,pp.83–99, 2014.
[23] Z. Weizhong, M. Huifang, and H. Qing, “Parallel kmeans clustering based on mapreduce,”Proceedings of the CloudCom’09. Berlin, Heidelberg:Springer-Verlag, pp. 674–679, 2009.
[24] Patil Y. K., Nandedkar V. S., HADOOP: A New Approach for Document Clustering,Int’l. J. Adv.Res. in IT and Engg.,pp. 1 – 8, 2014.
[25] Nailah Al-Madi, Ibrahim Aljarah and Simone A.Ludwig, Parallel Glowworm Swarm Optimization Clustering Algorithm based on MapReduce,IEEE Symposium on Swarm Intelligence, pp. 1 –8,2014.
[26] C.L. Philip Chen, Chun-Yang Zhang, Data-intensive applications, challenges, techniques and technologies: A survey on Big Data,Information Sciences, 2014.
[27] Lewis D. D., Y. Yang, T. Rose, and F. Li. RCV1: A new benchmark collection for text categorization research,Journal of Machine Learning Research, pp. 361 – 397, 2004.
[28] Dawen Xia, Binfeng Wang, Yantao Li, Zhuobo Rong, and Zili Zhang, An Efficient MapReduce-Based Parallel Clustering Algorithm for Distributed Traffic Subarea Division,Discrete Dynamics in Nature and Society,2015.
[29] Cui, Yajun, et al. “Parallel Spectral Clustering Algorithm Based on Hadoop.”arXiv preprint arXiv:1506.00227,2015.

- China Communications的其它文章
- High-Performance Beamformer and Low-Complexity Detector for DF-Based Full-Duplex MIMO Relaying Networks
- Action Recognition with Temporal Scale-Invariant Deep Learning Framework
- An Open IoT Framework Based on Microservices Architecture
- Open Access Strategy in Cloud Computing-Based Heterogenous Networks Constrained by Wireless Fronthaul
- RGB Based Multiple Share Creation in Visual Cryptography with Aid of Elliptic Curve Cryptography
- Orchestrating Network Functions in Software-Defined Networks