
数据挖掘在教学评价中的应用研究
2017-04-27 09:45万梅芬
电脑知识与技术 2016年29期
万梅芬

摘要:高等教育的发展以及教育质量的高低,与教学评价有着密切的联系。但是这些十分重要的数据在实际的教学管理过程中并没有被充分的利用。该文主要阐述的是在教学领域中引人数据挖掘,并對一系列的教学数据进行分析从中提取出,从而促进教学管理服务的进一步提高。
关键词:数据挖掘;教学评价
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)29-0012-02
虽然高等院校经过多年的教学实践已经积累了很多教学管理的数据,但是对这些数据的利用还只是停留在分析表面信息的阶段,而且教师的评优评先也是以此为依据的。然而实际上,有很多重要的信息都隐藏在这些数据中。所以,怎样深入的利用这些数据,并将其转化为可以为学校管理者提供决策支持的信息,是目前教学领域中急需解决的问题。
1数据挖掘概述
人们通常数据挖掘(Data Mining)称为数据的开采,以全新的角度将相关的技术领域紧密结合是其建立的主要基础,而在这其中则主要包含了数据库技术、知识发现技术(KDD技术)、数据统计技术等。将相关的数据通过数据库进行搜索,同时对搜索出的数据进行深入的挖掘分析后,对其中利用价值以及具备潜在利用价值的进行存储,这样对数据进行挖掘以及高级处理就是数据挖掘主要的工作原理。而数据挖掘则可以从以下两个方面进行详细的解释:首先,在浅层次上。在进行数据挖掘时可以充分的利用数据库管理系统的数据查询功能、数据探索功能以及数据报表功能等,进相关数据分析的结合使用,其中通常会应用多维数据分析法和数据统计分析法,进行联机数据分析的处理,从而获得所需要的相关参考数据。其次在深层次上。其主要的目的是将在数据库中隐蔽性极强的数据探索出来。在针对高校数据的挖掘和索取时应用这一方法,不但可以将更加全面的参考数据提供给人们,同时也实现了对相关数据的科学合理的应用。
2数据挖掘方法
2.1传统统计分析方法
传统的统计分析方法主要有:判别分析、回归分析、聚类分析、探索分析以及支持量分析等几方面的数据分析。而先由用户提供所需要假设的相关数据,而后再通过系统对相关的参数进行数据验证,就是传统的统计分析的主要原理。而且传统的统计分析方法自身存在的弊端也相对较多,比如相关的数据必须经过验证之后才能进行使用,而且为了确保数据探索时的真实性,需要用户不断地进行操作。而在广泛应用的统计学理论中,支撑矢量机(SVM)就是人们探索出的新型的学习方法,其主要是以风险相对较小的计算学习理论结构为基础的,其目的是为了推动学习机的广泛应用能力。
2.2机器学习方法
归纳学习法、以范例为推理基础的方法以及贝叶斯网络方法等是机器学习方法最常用的三种方法。以范例为推理基础的方法其主要的原理就是利用实验的方式对已经制定的问题进行解答。就目前的情况而言,将范例推理和最近邻原理相结合是我国机器学习法研究和探索的主要方向。另外,一多关联规则为基础的分类算法也是效率相对较高且适应功能较强的机器学习法。
2.3数据库方法
数据库方法主要有以可视化多维数据分析为基础的方法、OLAP方法以及面向属性的归纳方法等三种方法。
3数据挖掘在教学评价中的应用
按照一定的教学规范标准和教学目标,对学院教育学的相关情况进行系统的检测与考核是教学评价的主要依据,同时根据教学效果和教学目标实现的程度,对其进行相应的改进。
3.1数据准备
数据准备包括数据选择和数据预处理。1)数据选择。确定最终的任务对象并根据相关用户的需要,提取原始数据库的数据形成实际的目标数据就是数据选择的最终目的。一般情况下教师的工号、职称、学历、年龄以及教龄等基本信息都是从院校的教务系统中提取的,相关数据提取完成之后再提取最终的评价数据。2)数据预处理。去除噪声、缺失值以及删除一些无效的数据就是数据处理的主要内容。比如,如果学生对教师评价时出现了极端的0分或者100分的话,就必须对这些数据进行相应的处理。此外,如果因为学生的学号或者班级号等内容出现了缺失,而造成的缺失值可以对其予以忽略;一旦造成最终评价结果的缺失,那么就必须对相关的数据及时的进行处理。
3.2数据挖掘
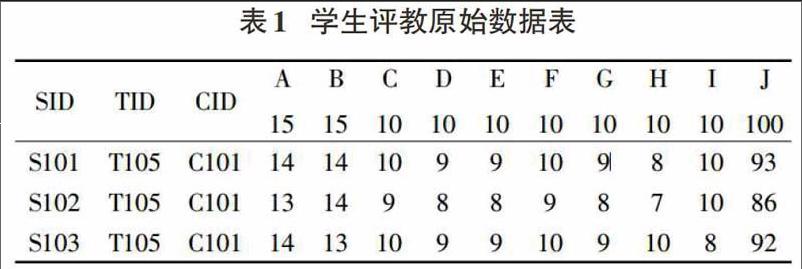
将已经获得的所有的数据进行挖掘就是我们所说的数据挖掘。1)内部挖掘。当前,学生评价是高校教学评价体系的主体,其主要是针对教师水平、教学内容、教学态度以及教学模式进行评价,经过对学生评价数据中的相关指标进行挖掘分析,就可以将其在的关键指标明确。2)内部与外部特征之间的关联规则挖掘。通过采用关联规则,实现了对学生评价数据和教师基本信息的掌握,而对高校教师的教学效果、教师的学历、年龄以及支撑等数据之间关系的研究,可以将挖掘过程主要分为以下三步:第一,数据准备。通过随机抽取某高校的500份学生评教数据,并将职称、年龄以及评教分数等相关的数据信息调入数据库。一般情况下评定分数以及年龄都属于数值型数据,而职称则为文本型数据,那么就可以将这些数据先转换为布尔型,然后再进行相关数据的离散处理,并对评定分数和年龄进行分组,例如将年龄分为M1[24,29],M2[30,39],M3[40,49],M4[50,60]四组;评定分数分为N1[90,100],N2[80,89],N3[60,79],N4[0,59]四组;将职称的级别分为G1初级,G2中级,G3副高,G4t高。从而实现了在数据准备的阶段就奠定了以上三者之间的关系基础。第二,关联规则挖掘。如果所获得的评定分数为[90,100],那么就证明其课堂效果相对较好,同过挖掘技术以及关联规则算法的应用,可以及时的发现并掌握教师课堂效果的基本信息。第三,模式评估,就是对关联规则信息进行初步的挖掘。例如表1是某高校应用B/S结构,经过对原始的数据片段进行网上评教,得出实际的数据,表2是教师基本情况。
其中SID是学生编号,TID是教师编号,CID是课程编号,--I是各种评教指标,J是总评,数字代表对应的分数。这里以表1中的B列指标为例,建立关联函数。
按照上面所讲述的关联函数的相关内容,就可以很容易的计算出教师学生评教的平均分数为89,而这项指标的平均分数为10,总分数应该为15,而对其中影响较大关键因素的百分比必须至少达到a=9%,则x=10/89=11%,b=15/89=17%,X0=<9%,11%>,X=<0,17%>代入关联函数,得f(x)=0.48>0,这样也就进一步证明了这项指标对教学评价所带来的影响。然后,将相关的重要因素与教师的基本信息进行关联。同时将职称、年龄以及评教分数存入相应的数据库,并将其转化为布尔型-引。通过对相关数据库的搜索,发现在所有的数据中一共有5条大鱼或者等于90的评定分数,如果将其最小支持度设定为5%,那么其最小的可信度就是18%,经过这样的数据挖掘,可以看出实际年龄M2[30,39]所取得的评定分数为Nl[90,100]的可能性是36%,支持度是9%”,“职称为G2中级,评定分数为N1[90,100]的可能性是27%,支持度是10%”初步结果。最后再利用相关的模式评估,通过进一步挖掘发现31-49岁年龄段的教师其课堂教学的经验十分的丰富,而且其所获得的支持度和可信度也相对较高,这些都为高校的管理部门提供了重要的决策支持,对于可续合理的安排和调配师资资源为学生服务具有极大的帮助。
4结束语
在高校教学评价中充分利用数据挖掘,有效地促进了高校获取有用信息能力的提升。本文主要是以学评教信息和教师的基本信息为基础,详细地阐述了如何挖掘内部与外部关联性知识的办法。目的是为了促进数据挖掘在教学领域的进一步应用,并为以后的继续研究奠定基础,同时也将挖掘方法计算机化作为了今后研究的重点。
猜你喜欢
科教导刊(2023年2期)2023-02-23
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
电力与能源(2017年6期)2017-05-14
读者(2017年5期)2017-02-15
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
信息通信技术(2015年6期)2015-12-26
大庆师范学院学报(2015年3期)2015-12-24
河南教育·基教版(2015年5期)2015-06-05
