
融合深度及边界信息的图像目标识别
2017-04-24 10:24:59原彧鑫周向东
计算机应用与软件 2017年4期
原彧鑫 周向东
(复旦大学计算机科学技术学院 上海 200433)
融合深度及边界信息的图像目标识别
原彧鑫 周向东
(复旦大学计算机科学技术学院 上海 200433)
为精确定位候选目标,提高目标识别效果,提出一种融合图像边界信息和深度信息的目标识别方法,该方法可以产生数量更少、定位更准确的图像候选目标。然后提取深度学习特征,通过支持向量机分类模型,实现目标识别。在两个常用数据集上进行对比实验显示,与Baseline和选择性搜索等方法相比,该方法显著地提高了目标识别的性能。
目标识别 区域融合 深度信息 深度学习 支持向量机
0 引 言
目标识别技术在安全监控、人机交互、医学、国防及公共安全领域具有十分重要的应用价值和发展前景。图像目标识别,旨在从二维图像或视频中精准地定位目标对象的位置,并自动赋予类别标签。
目标识别的过程主要包括提取候选目标和对目标进行分类。其中,如何准确地定位目标物体是目标识别技术的重要组成部分。基于梯度方向直方图(HOG)的行人检测[1]以及基于形变部件模型(DPM)[2]的目标检测都采用了滑动窗口检测方式,其本质是通过穷举检索提取候选集。但滑动窗口方法产生的候选目标集过大,影响目标识别的效率和性能。特别是目前最受关注的深度学习特征的提取往往具有较大的时间开销,因此,利用深度特征的目标识别更进一步要求目标候选区域的选取更加精简、准确。
“选择性搜索”[3]缩减了候选目标集的大小,取得了较好的目标定位效果,但目标区域的选取依然不够准确,会产生较多的错误检测。为此,文献[4]首先通过一次粗糙的分割得到候选目标集,然后对这些候选集上的检测结果使用监督下降方法进行一次自上而下的搜索,进而获得更准确的目标定位;而文献[5]使用贝叶斯优化调整选择性搜索方法得到的候选集的位置,得到更准确的候选集。然而,上述方法仍然是根据图像外观特征,对原始候选集进行位置调整,忽略了图像是3D世界的二维投影等问题。图像蕴含的3D信息,可以帮助我们进行更加准确的目标定位与识别。
本文在发掘图像蕴含的3D信息的基础上提出了一种新目标识别方法,即首先基于“超像素”融合的思想,根据图像边界信息和深度信息以及传统的颜色、纹理特征,对“超像素”进行更准确的融合,产生候选目标集。为了避免或消除图像的“过分割”状态,本文方法利用颜色、纹理特征进行二次融合。然后,提取深度特征并训练支持向量机分类模型。在PASCAL VOC及ImageNet数据集上的实验结果表明,本文方法产生的候选目标数量远少于选择性搜索方法,而且获得了更好的目标定位效果,在整体上较为明显地提升了目标识别的性能。
1 相关工作
在图像中直接搜索目标物体的方法是穷举搜索。虽然穷举搜索可以很好地找到目标的位置,但随着图像数量及图像分辨率地提升,其候选窗口的数量将成倍地增加,如此一来穷举搜索的计算代价十分巨大并且非常低效。因此,如果能过滤掉一些无用的候选区域,不但能提升识别速度,而且对分类准确率也会产生积极的影响。
因此,早期的目标识别研究采用规则网格、固定尺寸和固定长宽比的滑动窗口来减少搜索空间,但候选集的质量会差很多。为此,文献[6]提出用多尺度扫描窗口对图像进行搜索,提出候选目标,但该方法搜索空间依然很大。
虽然滑动窗口效果较好,但其计算量大、速度慢,并且没有考虑图像本身所包含的信息。因此,根据图像的信息,将图像分割成有意义的若干个连通区域,各个区域有其独特的性质,然后从中提取出感兴趣的目标区域,这就是基于图像分割进行目标提取的基本思路。但是,如何定义图像区域间的边界却是一个十分复杂的问题。通常的算法[7-10]都是依赖于图像的亮度、灰度、颜色、纹理等特征的相似性将图像像素聚类成多个区域,各个区域内部有其特定的一致性,区域之间却存在着一定的差异性。例如,文献[10]提出的一种基于图表示的图像分割方法,使用RGB颜色的距离来衡量两点的相似性,并建立了一个自适应阈值的算法来确定相邻区域是否合并。该算法实现简单,速度较快,但是容易产生过分割,所以一般不直接将其作为分割结果,而需进一步处理。
基于分割的目标提取方法,使用图像自身的特征、结构来指导分割过程,尽可能地将目标区域分割出来,但分割结果往往表现为过分割或欠分割,无法对应到真实的目标区域,造成分割不够精确。受到从细节到整体的分割方式的启发,文献[3]综合了分割与穷举检索的思想,提出了选择性搜索的方法。该方法大幅降低候选目标数量,提高了程序效率:先利用文献[10]提出的分割算法生成初始的候选目标区域位置;同时结合穷举检索,将初始分割得到的目标区域不断融合,尽可能地获得候选目标的位置。而且,该方法与目标类别无关,仅与图像自身有关。
2 融合3D信息的图像目标识别
在图像目标提取方法中,选择性搜索方法速度快、效果较好,近几年在目标识别领域被广泛应用。但是,实际图像中的物体是3D世界中的实体的投影,仅仅通过颜色、尺寸、纹理等图像外观特征往往难以很好地划分目标区域。因此,本文提出利用3D信息,如通过引入边界及深度信息,在区域融合时,使区域的优先融合更符合目标的真实情况,产生更高质量的候选目标集。本文进行目标识别的流程如图1所示。
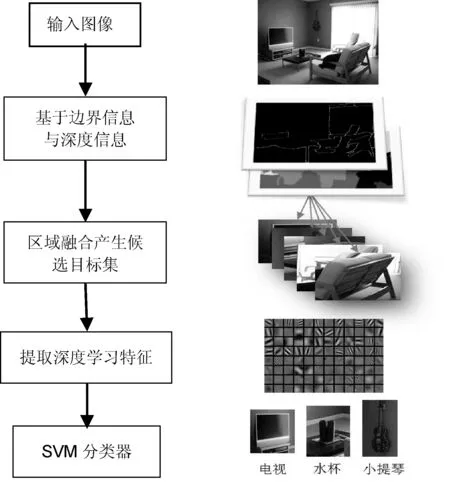
图1 本文目标识别流程图
2.1 目标提取
现实世界映射到图像平面时产生的一个重要结果就是物体之间的遮挡边界:当物体遮挡住位于它后面的物体时,两物体之间产生的分界线。其本质上是由三维信息中的深度信息造成的,即物体的深度不一致造成的。因此边界特征与深度信息对于图像目标识别与场景理解都是十分重要的。
2.1.1 图像3D信息
1) 边界信息
一般情况下,图像中较长的平滑边界很可能是物体之间的边界。所以,图像的边界本身就包含很多的信息。
(1) 边界长度,这里是相对长度,与边界分隔的两个区域中周长较短的区域进行比较:
Bl=L/min(Ci,Cj)
(1)
其中,L为边界长度,Ci、Cj分别为该边界两边区域的周长。该特征描述了边界与区域之间包围的程度。
(2) 边界方向,即边界两端点之间夹角。
(3) 边界平滑度,其本质上就是计算边界曲线的平滑度,计算公式如下:
(2)
其中, (x1,x2)、(y1,y2)为边界端点坐标。
(4) 边界连续性,计算与其相邻边界夹角的最小值。
此外,还使用了文献[11]提出的平均边界概率值作为边界特征的一部分。这些信息组合在一起,构成图像中一条边的边界特征。
2) 深度信息
通过深度信息可以更好地判断两个相邻区域是否属于一个物体,例如,如果可以确定相邻区域在深度上差距较大,则这个边界更有可能是真正的边界。虽然仅仅从单幅图像中,无法得到图像的绝对深度信息,但通过很多算法可以估算出图像的相对深度。
T-junction被广泛用于基于图像的深度恢复技术中,T-junction是由三条边界组成的“T”型节点,是三条边界和其对应的三个区域交界的点。如图2 所示。
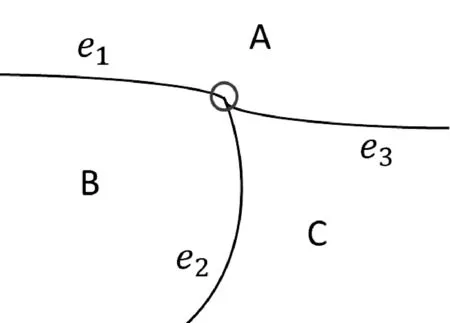
图2 T-junction示意图
T-junction描述了相邻物体边界线之间的相交关系。一个理想的T-junction就是一个标准的“T”字形,即有两条边界构成180度夹角,标志着这两条边之间的区域在最前面,另两个区域在后面(如图2中A区域,由边e1和e3所构成的夹角接近180度,表明A区域在B区域和C区域的前面)。
结合其他特征,获得相邻区域的前景/背景标签后,可以确定边界的方向(确定准则:边界左侧为前景)[12]。这样在T-junction中,若其为物体的边界,则其方向不可能是任意的,至少有一个出junction的方向及一个进junction的方向,否则作为物体的边界,就会出现矛盾。
2.1.2 融合3D信息的候选目标定位
根据边界特征、深度信息以及区域的颜色、纹理等外观特征,本文采用文献[12]的条件随机场模型,使得边界和外观标签[13]取得一致性,公式如下:
(3)
这里φj表示junction因子,γe表示外观因子;Nj表示junction数目,Ne表示图中边的数目。对于无效的junctions(如:没有边界出junction),给其较大的惩罚;同样对于属于不同外观类别的两个区域,边界却属于“虚边界”的(即要将两个不同外观类别的区域融合的)给予其较大的惩罚。
这样可以确定初始分割中真正的边界,将“虚边界”去除,即区域融合。直至所有的边界都是真正边界后,图像分割完成,获得图像初始候选目标集。
在经过上述基于边界信息与深度信息的融合之后,得到区域目标候选集。但此时依然存在“过分割”的情况,如图3所示。

图3 融合边界与深度信息的图像分割情况
这时为了获得更好的候选目标,本文采用颜色、纹理这两种外观特征作为区域相似性评价标准,进行区域融合,获得更加准确的候选目标集。
相对于RGB颜色空间,HSV空间更接近于人类对颜色的主观认识,所以本文采用HSV颜色空间对图像颜色特征进行描述。纹理特征方面,本文选取局部二值模式(LBP)作为纹理特征,该特征具有旋转不变性和灰度不变性等显著的优点,并且计算简便高效,能够有效地描述图像局部纹理。
在获得各个区域的颜色及纹理特征直方图后,先将特征向量进行L1归一化,然后使用χ2距离:
(4)
计算相邻区域的颜色直方图及纹理直方图的距离。则相邻区域ri和rj的相似度计算公式为:
(5)
这样,在上一步候选集的基础上,每次将最相似的两个区域合并,形成一个新的候选目标区域,不停地融合,直至整幅图像融合成一个区域为止。
2.2 特征提取与目标分类
本文通过Caffe[14]框架提取图像的深度学习特征作为候选目标图像的描述符,使用SVM模型进行分类任务。
Caffe是一个深度学习的开发框架,具有轻便性、易用性和速度快的优势。深度学习可以逐层提取图像的特征,通过组合低层特征形成更加抽象的高层特征,语义从低到高,对图像的扭曲、偏移、缩放等形变更加适应。近年来,深度学习发展迅猛,在图像的各个领域都取得了不错的成绩,为图像特征描述提供了新的思路。
SVM是一种监督学习模型,被广泛地应用于机器学习分类和回归任务中。SVM的决策函数来源于线性分类模型的决策函数:
f(x)=(ωTx+b)≥1
(6)
带有松弛变量的软间隔SVM模型目标函数为:
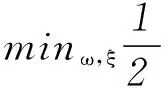
(7)
s.t.
yi(ωTxi+b)≥1-ξ,ξi≥0 i=1,2,…,n
(8)
3 实验及分析
3.1 实验数据集
3.1.1PASCALVOC
PASCALVOC数据集是计算机视觉分类、识别和检测的一个基准测试,提供了标准图像注释数据集。该数据集要求研究者仅通过图像内容将其分类并识别目标物体。
本实验从PASCALVOC2007数据集中随机抽取了aeroplane、bird、bottle、car、cow、dog、motorbike、sheep、sofa、train等10个类共1 161幅图像作为实验数据集一。其中训练图像583幅,测试图像578幅。
3.1.2ImageNet
ImageNet是目前世界上最大的图像识别数据库,是根据词汇层次结构组织的图像数据库。词汇网中的每个有意义的概念可能被多个单词或词组表述,即“同义词集合”。在ImageNet数据集中,每个“同义词集合”通过多幅图像来对其进行描述,其中,每幅图像都是经过筛选及人工标注的。
本实验从ImageNet数据集中随机抽取了10个类别图像:antelope、bus、cucumber、guitar、lion、monkey、winebottle、hairdryer、refrigerator、Mushroom等10个类共2 091幅图像作为本实验数据集二,其中训练图像1 046幅,测试图像1 045幅。
3.2 实验结果
目标检测不但要求正确识别出物体的类别,而且需要较好地定位目标的位置。PASCALVOC定义目标定位的标准是重合度(Overlap),要求候选目标区域与真实目标之间要有最大重合度,公式如下:
(9)
即候选目标Bp与groundtruthBgt的重合区域与两者全部区域的面积之比。PASCALVOC评价标准要求只有当目标区域Bp与groundtruth的重合率超过50%时,才能认为是正确的检测。
本文利用F1综合评价目标分类的效果,公式为:
F1=2PR/(P+R)
(10)
其中,P是准确率(precision),R是召回率(recall)。
表1与表2分别比较了本文方法与采用滑动窗口的基准(Baseline)方法、选择性搜索[3]方法在两个数据集上的分类结果(三种方法均使用deepfeature特征和SVM分类器)。

表1 数据集一F1
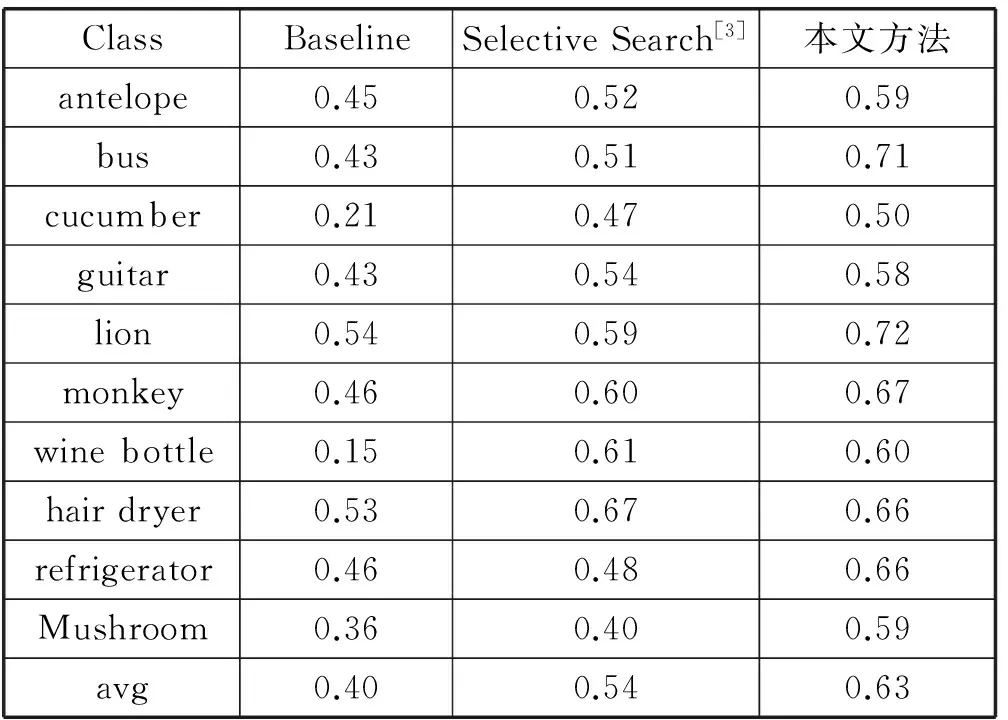
表2 数据集二F1
3.3 实验分析
通过实验结果对比,本文方法相比于选择性搜索在目标识别的效果上有很大提高。在数据集一中,Baseline的平均F1为0.29,选择性搜索方法为0.44,而本文的方法达到0.51,并且大部分类别的识别效果都好于Baseline与选择性搜索方法。在数据集二上也得到了一样的结果(Baseline为0.40,选择性搜索方法为0.54,而本文方法为0.63)。本文方法可以取得更好的分类效果,根本原因在于,本文方法可以更准确地定位目标。如图4中所示,本文方法的定位效果更加准确,尤其在对白马的目标定位。

图4 实验效果图1
因为初始分割方法[10]只根据颜色特征将图像分为上百块“超像素”,而选择性搜索只根据外观特征进行融合,这样很容易将属于白马的区域与旁边栏杆的白色区域先行融合,对后续的融合产生连锁影响,造成目标定位不准确。相比于选择性搜索,本文加入深度信息与边界信息,使区域的融合更加符合物体在三维空间上的定义,而不仅仅是外观上的相似性,进而获得更加准确的目标定位,改善了最后分类的效果。更多实验效果如图5所示。

图5 实验效果图2
4 结 语
针对目标识别中的目标提取过程,本文通过融入深度信息与边界特征,获得了更加准确的候选目标集,最后利用图像的深度学习特征训练SVM模型对候选目标进行分类。通过在PASCAL VOC和ImageNet数据集上的实验验证了本文方法的效果。下一步将研究如何避免或解决边界错误定义产生的问题。
[1] Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//Computer Vision and Pattern Recognition,2005 IEEE Computer Society Conference on.IEEE,2005:886-893.
[2] Felzenszwalb P F,Girshick R B,McAllester D,et al.Object detection with discriminatively trained part-based models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(9):1627-1645.
[3] Uijlings J R R,Sande K E A V D,Gevers T,et al.Selective search for object recognition[J].International Journal of Computer Vision,2013,104(2):154-171.
[4] Long C,Wang X,Hua G,et al.Accurate object detection with location relaxation and regionlets re-localization[C]//12th Asian Conference on Computer Vision.Springer International Publishing,2014:260-275.
[5] Zhang Y,Sohn K,Villegas R,et al.Improving object detection with deep convolutional networks via Bayesian optimization and structured prediction[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,2015:249-258.
[6] Viola P,Jones M J.Robust real-time face detection[J].International Journal of Computer Vision,2004,57(2):137-154.
[7] Shi J,Malik J.Normalized cuts and image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(8):888-905.
[8] Martin D,Fowlkes C,Tal D,et al.A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Computer Vision,2001 8th IEEE International Conference on.IEEE,2001:416-423.
[9] Ren X,Malik J.Learning a classification model for segmentation[C]//Computer Vision,2003 9th IEEE International Conference on.IEEE,2003:10-17.
[10] Felzenszwalb P F,Huttenlocher D P.Efficient graph-based image segmentation[J].International Journal of Computer Vision,2004,59(2):167-181.
[11] Martin D,Fowlkes C,Malik J.Learning to find brightness and texture boundaries in natural images[C]//Advances in Neural Information Processing Systems,2002.
[12] Hoiem D,Stein A N,Efros A A,et al.Recovering occlusion boundaries from a single image[C]//Computer Vision,2007.ICCV 2007.IEEE 11th International Conference on.IEEE,2007:1-8.
[13] Hoiem D,Efros A A,Hebert M.Recovering surface layout from an image[J].International Journal of Computer Vision,2007,75(1):151-172.
[14] Donahue J,Jia Y,Vinyals O,et al.DeCAF:A deep convolutional activation feature for generic visual recognition[J].Computer Science,2013,50(1):815-830.
OBJECT RECOGNITION COMBINED WITH DEPTH AND BOUNDARY INFORMATION
Yuan Yuxin Zhou Xiangdong
(SchoolofComputerScienceandTechnology,FudanUniversity,Shanghai200433,China)
In order to locate the candidate object accurately and improve the target recognition effect, an object recognition method combined with depth and boundary information is proposed. The proposed method can generate less but better object candidates with more accurate location. Then the depth learning feature is extracted, and the SVM classification model is used to realize the target recognition. Experimental results on two common data sets show that compared with Baseline and selective search, this method improves the performance of object recognition significantly.
Object recognition Region merge Depth information Deep learning SVM
2016-03-18。国家自然科学基金项目(61370157)。原彧鑫,硕士生,主研领域:计算机视觉。周向东,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.04.031
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
证券法律评论(2018年0期)2018-08-31 02:33:08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
外语学刊(2014年6期)2014-04-18 09:11:49
