
用说话人相似度i-vector的非负值矩阵分解说话人聚类
2017-04-24 10:38:25哈尔肯别克木哈西达瓦伊德木草
计算机应用与软件 2017年4期
哈尔肯别克·木哈西 钟 珞 达瓦·伊德木草
1(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)2(新疆大学多语言技术重点实验室 新疆 乌鲁木齐 830046)
用说话人相似度i-vector的非负值矩阵分解说话人聚类
哈尔肯别克·木哈西1钟 珞1达瓦·伊德木草2
1(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)2(新疆大学多语言技术重点实验室 新疆 乌鲁木齐 830046)
基于贝叶斯或者全贝叶斯准则的说话人自动聚类或者识别方法,主要采取重复换算全发话语音段的相似量度,再组合相似性较大的语音片段实现说话人的聚类。这种方法中如果发话语音片段数越多,组合计算时间就越长,系统实时性变差,而且各说话人模型用GMM方法建立,发话语音时间短暂时GMM的信赖性降低,最终影响说话人聚类精度。针对上述问题,提出引用i-vector说话人相似度的非负值矩阵分解的高精度快速说话人聚类方法。
说话人分割及聚类 非负值矩阵分解i-vectorGMM电话语音
0 引 言
随着信息技术和存储技术的发展,音频数据量呈现爆炸式增长。面对如此海量数据,人们迫切希望能准确快速搜索到需要的信息,因而对相关语音技术的需求也与日俱增。会议讲演(语音)的有声记录,或者为国家安全、社会稳定、犯罪嫌疑人追踪控制、身份确认以及加强反腐力度等目的,录制保留的多人长时间说话语音数据媒体规模逐年增多[1]。在这种大规模音频文件中自动提取(谁在说话、什么时间说话、说了什么等)不同发话人,不同时间及不同内容的话语信息需要进行自动分析分割,并进行数字化整理,作为有声数据资源管理。多说话人识别技术的目的是在上述某种音频文件中分割出或者分类出不同的说话人技术。和传统的说话人识别技术相比,多说话人识别技术不仅能够分割出不同的说话者,而且还能判断每个说话人发话时间及内容。它是说话人识别技术的一种延伸。
针对基于贝叶斯信息准则(BIC)的说话人分割算法[2-3]对语音信号的分布估计较粗糙的缺点,以及高斯混合模型GMM说话人模型在发话时间短暂时信赖性底等问题,提出基于非负值矩阵分解NMF(Non-negative Matrix Factorization)的、引用i-vector说话人相关性模型组合方法的、高精度快速分割或聚类说话人方案。该方案主要利用i-vector说话人向量间的距离,计算相似量度,生成说话人相似矩阵,将K均值算法的聚类结果作为NMF的初始因子矩阵,并对超图的邻接矩阵进行NMF,获得基矩阵和系数矩阵;最后根据系数矩阵获得最终的聚类结果。由于抽出i-vector作为知识事先利用大量的实验数据,因此相比于GMM,i-vector方法不受发话语音短暂的影响。另外由于i-vector方法很难受到声道的影响、可以作为有效的说话人特征量使用[4-5]。
1 说话人识别研究工作现状
2014年,在说话人识别(也称声纹识别)领域的国际顶级会SpeakerOdyssey2014专家学者报告讨论表明,i-vector已是说话人识别的主流技术,成为其他算法的参照标准。洪青阳介绍了国内把i-vector说话人识别技术率先应用到公安部声纹识别行业中大幅度提高了系统识别的效率情况报告[6]。栗志意等学者报告了系统融合以及对未知数据的聚类和自适应提升性能的有效方法[7]。Tawara等学者提出的狄利克雷分布过程混合模型全贝叶斯准则的说话人自动聚类或者识别的新尝试也受到了研究人员的关注[8]。
2 基于非负值矩阵分解方法的说话人聚类
2.1 非负值矩阵分解
NMF法是把非负值矩阵V分解为基底矩阵W和系数矩阵H的方法。即:
V≅WH
(1)
式中W、H分别通过Kullback-Leibler[9]信息量(简称K-L信息量)D(q‖p)获取。它表示对于真分布q推测出分布p,距离q的偏离程度。如果这两个分布是一致的,那么偏离程度为0。要确定W和H,可以假设:当推测分布设为WH,而真分布设为V时,K-L信息量由式(2)定义:
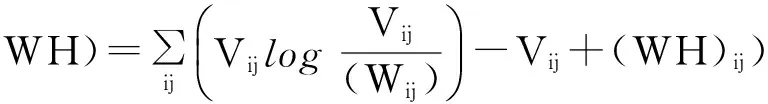
(2)
再经过式(3)和式(4)的更换,可以获得式(2)的最小化方程,即:
(3)
(4)
其中,Vij、Hij、Wij分别表示矩阵V、W及H的第i行j列元素。
2.2 说话人聚类方法
基于NMF法的说话人聚类是分解发话语音片段间的相似量度U×U矩阵V而实现的[10]。这里U为语音片段总数。如图1所示,相似矩阵(similarity)可以分解成基底矩阵W(basis)和系数矩阵H(activation)的乘积。其中矩阵W为R×U类的基底矩阵,其各列表示各说话人;矩阵H也是R×U矩阵,其行表示对于各语音片段对应的说话人比重;R为类数。按照说话人的不同,首先从矩阵H中选出比重较大的语音片段,然后将相同说话人的语音片段聚类在一起,实现说话人聚类。
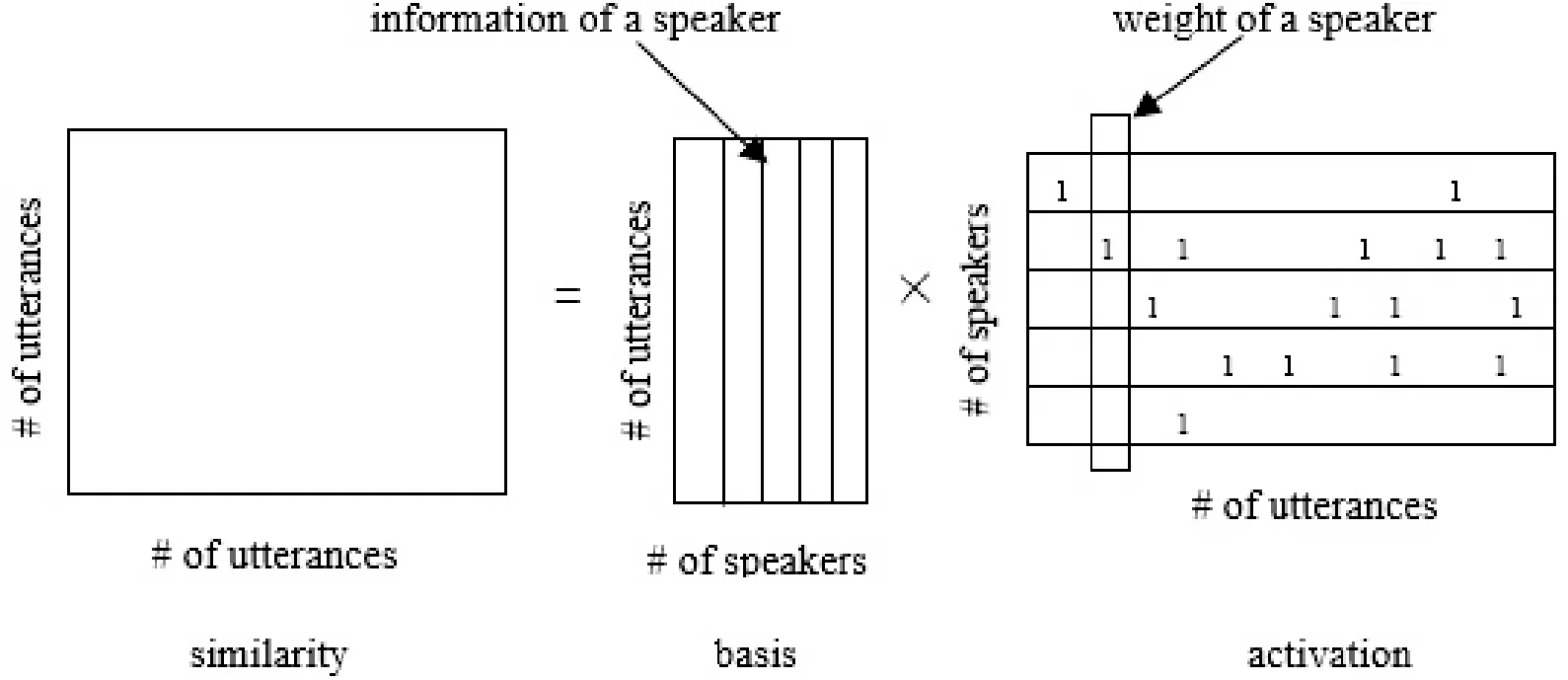
图1 NMF方法说话人聚类示意图
3 说话人建模
在本节讨论说话人建模以及通过说话人模型算出说话人间的相似量度方法。也就是,在多说话人语音流文件中生成各发话语音片段所表现的说话人模型,计算语音片段间的相似量度。本节讨论常见基于GMM的说话人模型的交叉似然比CLR(CrossLikelihoodRatio) 距离的建模聚类方法和利用i-vector说话人模型余弦算相似量度建模聚类方法。
3.1 基于GMM的说话人建模
对于各发话语音片段,经优化学习法建GMM说话人模型。GMM的概率密度p(x|λ)由下式算出:
(5)
(6)
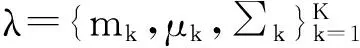
3.2 基于CLR方法的说话人相似量度计算
CLR方法可以通过两个GMM参数的对数似然密度比算出。因为GMM两个似然密度相近时CLR取值为零。因此,CLR可以作为说话人间的距离尺度。基于NMF的聚类方法是利用相似度矩阵法,可以取CLR的倒数变换算出相似量度。第i个和第j个语音片段的CLR可以通过下式算出,即:
(7)
(8)
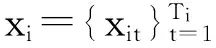
3.3 基于i-vector的说话人相似度计算
常见UBM(Universalbackgroundmodel)方法[12]对于不特定说话人全部特征空间概率模型,利用多说话人在不同内容的话语,在不同说话环境以及不同实验条件下收集整理的大量语音数据学习GMM混合参数建模。而i-vector法是对于上述语音流按语音片段从UBM获取话语依存UBM超级向量、再通过维数压缩的方法获得向量,既称为i-vector。这种话语依存GMMm(u)超级向量可以表示为:
m(u)=m+Tw(u)
(9)
式(9)中,w(u)代表i-vector。m(u),m分别表示话语依存GMM和UBM超级向量、而T为部分空间映射矩阵。一般对i-vector实施FLDA分解(Fisherlineardiscriminantanalysis)法消除参数声道影响。
3.4 基于余弦相似量度的说话人相似度计算
两个向量间的相似性常用余弦相似量度尺度测量[13]。因此,该文中两个语音片段i-vector间的相似性通过余弦相似量度获取。因为余弦尺度取值范围在-1到+1之内,而NMF(非负值矩阵)只能取正数。所以,本研究中对于余弦相似量度向量进行下式变换,再实施NMF法。即:
(10)
4 多说话人聚类实验
针对NMF方法的说话人聚类实验,为便于比较,本文分别利用常见GMM方法和i-vector生成相似量度矩阵,通过两种实验进行讨论。
4.1 实验条件及数据
本次多说话人聚类实验选用新疆大学多语言信息技术重点实验室开发的100个人电话语音录用数据,从中选用50个发话人数据[14-16]。其中,男女性分别为25人,每人在不同时间段发话5次、每次发话语音片段长度5~10秒时间不等。特征量为12维的MFCC参数,帧长25ms,周期10ms。GMM用混合数设定8。
4.2 实验评估方法
本次试验结果的评估,我们采用各语音片段追加说话人标签,取标签平均聚类纯度ACP(averageclusterpurity)及平均说话人纯度ASP(averagespeakerpurity)的几何K均值进行评估。
假设ST为实际发话人数,S为说话人类数,nij为发话人j在全发话语音中分配到第i个说话人类的发话语音数,nj为发话人j的全发话数,ni为分配到说话人i类的发话数,U表示发话总数时,类纯度pi和说话人纯度qj分别由式(11)算出,即:
(11)
类纯度表示,对各类分配到的发话语音中属于同一个说话人的比例,而说话人纯度表示,每个发话人所发话语音中属于同一个类的发话语音比例。这样,平均类纯度VACP及平均说话人纯度VASP分别表示为:
(12)
因此,ACP和ASP的几何K均值设定为:
(13)
4.3 实验结果
本次试验结果如图2所示。
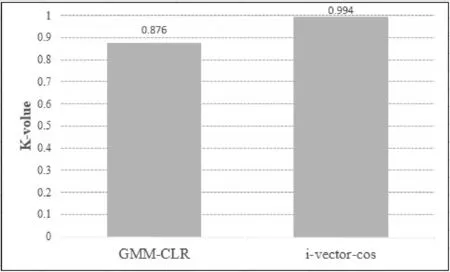
图2 GMM-CLR及-vector-COS相似度获取说话人聚类的比较
从图2可以看出,用i-vector-COS余弦相似量度生成相似矩阵所获得的实验效果明显好于用CLR方法生成相似矩阵的效果。为了便于比较,图3中显示了上述实验中追加标签的10个说话人在不同实验过程中聚类效果。

图3 GMM-CLR及提按方法说话人聚类结果演示
从演示结果可以观察到,各语音片段在不同类中分配聚类实况。其中每个矩形图表示各说话人发话语音片段,横坐标代表各发话语音片段聚类的正确说话人标签,而纵坐标代表推测出的说话人标签。从图3可以观察到,在GMM-CLR试验中,同一个说话人发话语音片段被分配到多个类中,而采用i-vector-Cos聚类试验中同一个说话人的发话语音基本上被正确地分配到同一个类中。因此,可以肯定本文提出的NMF算法及i-vector组合方法运行高效,并且获得了比其他常见的聚类集成算法更加优越的结果。
5 结 语
针对小规模语音实验数据,对基于NMF(非负值矩阵分解)方法的说话人聚类中导入i-vector说话人相似度模型,实现短暂发话语音能够获取高速并高精度的说话人聚类方法。并探讨了常见基于CLR相似量度矩阵算法说话人聚类与基于i-vector相似量度矩阵的说话人聚类方法,再利用K均值法对系统性能进行了比较评估。实验结果显示,i-vector说话人相似矩阵模型及NMF算法组合方法不仅可以获得高精度说话人聚类效果,而且对于数据变动也具有较强鲁棒性。
进一步扩大实验人数以及实验数据环境,确认提出方法对于无限说话人分割及聚类的推测效果是后期研究工作重点。
[1]NishidaM,IshigawaY,YamamotoS.SpeakerDiarizationBasedonNon-negativeMatrixFactorizationinMulti-partyConversations[J].SLP,2011,85(7):1-6.
[2] 伊·达瓦,吾守尔·斯拉木,匂坂芳典.LPC及F0参数组合基于GMM电话语音说话人识别[J].中文信息学报,2011,25(4):105-109.
[3]KanagasundaramA,VogtR,DeanD,etal.i-vectorbasedspeakerrecognitiononshortutterances[C]//12thAnnualConferenceoftheInternationalSpeechCommunicationAssociation(ISCA),2011:2341-2344.
[4]GeigerJ,WallhoffF,RigollG.GMM-UBMbasedopen-setonlinespeakerdiarization[C]//11thAnnualConferenceoftheInternationalSpeechCommunicationAssociation(ISCA),2010:2330-2333.
[5] 伊·达瓦,匂坂芳典,中村哲.语料资源缺乏的连续语音识别方法的研究[J].自动化学报,2010,36(4):550-557.
[6]JessenM.Currentdevelopmentsinforensicspeakeridentification[C]//Odyssey2010:TheSpeakerandLanguageRecognitionWorkshop,2010:378-394.
[7] 栗志意,张卫强,何亮,等.基于总体变化子空间自适应的i-vector说话人识别系统研究[J].自动化学报,2014,40(8):1836-1840.
[8]TawaraN,WatanabeS,OgawaT,etal.SpeakerClusteringBasedonUtterance-OrientedDirichletProcessMixtureModel[C]//12thAnnualConferenceoftheInternationalSpeechCommunicationAssociation(ISCA),2011:2905-2908.
[9]WatanabeS,MochihashiD,HoriT,etal.Gibbissamplingbasedmulti-scalemixturemodelforspeakerclustering[C]//Proceedingsofthe2011IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP),2011:4524-4527.
[10] 达瓦·伊德木草,木合亚提·尼亚孜别克,吾守尔·斯拉木.语音技术在少数民族语言的应用研究[J].新疆大学学报(自然科学版),2014,31(1):88-96.
[11]MurtazaM,BSharifM,RazaM,etal.FaceRecognitionUsingAdaptiveMarginFisher’sCriterionandLinearDiscriminantAnalysis(AMFC-LDA)[J].TheInternationalArabJournalofInformationTechnology,2014,11(2):149-158.
[12] Dehak N,Kenny P J,Dehak R,et al.Front-End Factor Analysis for Speaker Verification[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(4):788-798.
[13] Ye J.Cosine similarity measures for intuitionistic fuzzy sets and their applications[J].Mathematical and Computer Modelling,2011,53(1/2):91-97.
[14] 武晓敏,达瓦·伊德木草,吾守尔·斯拉木.自然预料缺乏的民族语言连续语音识别[J].计算机工程,2012,38(12):129-131,135.
[15] 李晓阳,伊·达瓦,吾守尔·斯拉木,等.基于GMM-UBM/SVM的维吾尔语电话语音监控系统[J].计算机应用与软件,2012,29(1):46-48,77.
[16] Yidemucao D,Zhao Z,Silamu W.Sound scene clustering without prior knowledge[C]//2012 Chinese Conference on Pattern Recognition (CCPR),2012:613-621.
A SPEAKER CLUSTERING METHOD BASED ON NON-NEGATIVE MATRIX FACTORIZATION AND I-VECTOR OF SPEAKER SIMILARITY
Harhenbek Muhaxov1Zhong Lou1Dawa Idomucao2
1(SchoolofComputerScienceandTechnology,WuhanUniversityofTechnology,Wuhan430070,Hubei,China)2(KeyLaboratoryofXinjiangMulti-LanguageTechnology,XinjiangUnivrsity,Urumqi830046,Xingjiang,China)
Based on Bayesian or full Bayesian criterion, the speaker clustering or recognition method is mainly used to repeat the similarity measure of the whole utterance segment, and then combine the similar utterance segment to realize speaker clustering. In this method, if the number of utterance segment is increased, the combined computation time is longer and the system real-time property is worse. Moreover, the speaker model is established by GMM. The reliability of GMM is reduced when the speech time is short, which affects the accuracy of speaker clustering. Aiming at the above problems, this paper proposes a high-accuracy fast speaker clustering method based on non-negative matrix factorization and i-vectorofspeakersimilarity.
Speaker segmentation and clustering Non-negative matrix factorization I-vector GMM Telephone speech
2016-03-01。国家自然科学基金项目(61163030)。哈尔肯别克·木哈西,博士生,主研领域:语音信号处理。钟珞,教授。达瓦·伊德木草,教授。
TP
ADOI:10.3969/j.issn.1000-386x.2017.04.028
猜你喜欢
香格里拉(2019年4期)2019-11-20 09:30:58
中成药(2018年2期)2018-05-09 07:20:05
卫拉特研究(2017年0期)2017-12-07 00:35:50
中学数学杂志(高中版)(2016年6期)2017-03-01 18:53:58
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:40
职业技术(2015年8期)2016-01-05 12:16:46
中国修辞(2015年0期)2015-02-01 07:07:26
物理教学探讨(2014年4期)2014-09-17 17:04:36
云南中医学院学报(2014年3期)2014-07-31 18:58:01
语言与翻译(2014年1期)2014-07-10 13:06:12
