
基于源码模式挖掘的软件辅助开发技术研究
2017-04-21 00:44:12沈莉莉
电子科技 2017年4期
付 鹏,沈莉莉
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于源码模式挖掘的软件辅助开发技术研究
付 鹏,沈莉莉
(上海理工大学 光电信息与计算机工程学院,上海 200093)
由于软件代码的复杂性,对于不了解框架的新手,很难利用开源社区中的代码来开发软件。因此,利用数据挖掘技术挖掘现有代码中的编程模式成为研究热点。文中介绍了频繁项挖掘Apriori算法,并提出了基于源码模式的软件辅助开发方法。它能够根据用户输入的关键字来智能匹配类库中的特定父类,挖掘基于此父类的编程模式,给出优先要重写的方法以及关联规则。实验结果表明,新手可以利用这些编码建议,快速学习一个新的框架,提高开发效率。
源码;数据挖掘;编程模式;软件辅助开发
如今开源社区受到越来越多人的关注,人们可以轻松从网络上获取各种软件源代码,软件重用[1]是软件工程的一个热点研究方向,它可以为开发新手带来很多好处,例如提高工作效率、减小开发成本、获取更好的产品质量以及更快的投入市场。但新手很难理解基于同一种框架而编写的代码,首要的问题是不知道编写第一行代码。
框架作为目前软件开发的一个重要组成部分,扮演着重要角色,然而对框架不了解的新手,要重用框架并不容易。框架本来就是为了灵活性而设计的,因此引入了很多抽象类,这使理解框架变的更加复杂。而且,开发者单单理解一个类无法使用框架,还需要理解框架的整体架构。尽管如此,目前还是有很多方法来解决这个问题,但存在一些弊端。例如,一些框架教程以及相应的API[2]文档,可以帮助开发人员学习框架,但框架开发人员编写文档的水平参差不齐,有些框架开发者编写的文档质量不高;另外有的框架版本已更新,但文档并没有及时更新。文献[3]提出了一种挖掘用户类库的重用模式的方法,可以根据用户选择的应用,挖掘其中的类库重用模式,这样在使用特定框架时,只需已知其他开发者如何使用框架,就能以同样的方式使用框架,这对构建应用有一定的帮助,但用户首先需要挑选那些使用框架与其一致的应用,此方法挖掘出来的关联规则[4- 6],对于框架初学者来说,要理解这些关联规则并应用到自己的应用中难度较大。文献[7]提出了一种帮助开发人员理解框架的方法,这种方法可以在用户实例化一个对象之后,挖掘现有代码库,按照置信度给出下一步应该进行操作的提示,这样用户在编写代码的时候就有了一定的参考,但初学者并不知道首先要实例化哪个对象。针对上述问题,文中提出了一种新的辅助开发方法CodeMining,它根据现有框架源码库,挖掘其中的编程模式,为不了解框架的新手提供编码建议,辅助开发。
1 Apriori算法
基本概念:规则A->B在事务集D中成立。
(1)支持度:P(A∩B),既A发生时B也发生的概率;
(2)置信度:P(B|A),即在A发生的事件中同时发生B的概率P(AB)/P(A)。
例如购物篮[8]分析:泡面⟹火腿肠
例:[支持度:2%,置信度:50%]
支持度2%:意味着2%顾客同时购买泡面和火腿肠。
置信度50%:意味着购买泡面的顾客50%也购买火腿肠;
(3)如果事件A中包含k个元素,那么称这个事件A为k项集事件A满足最小支持度阈值的事件为频繁k项集;
(4)同时满足最小支持度阈值和最小置信度阈值的规则称为强规则。
Apriori算法[9-10]的主要作用是寻找所有支持度不小于最小支持度(minsup)的项集。项集的支持度是指包含该项集的事务所占所有事务的比例。频繁项集[11-12]就是指满足给定的最小支持度的项集。该算法会对数据集进行多次遍历:第一次遍历,对所有单项集的支持度进行计数并确定频繁项;在后续的每次遍历中,利用上一次遍历所得频繁项集作为种子项集,产生新的潜在频繁项集(即候选项集),接下来就是对候选项集的支持度进行计数,在本次遍历结束时统计满足最小支持度的候选项集,则本次遍历对应的频繁项集就确定了,这些频繁项集又作为下一趟遍历的种子。重复此遍历过程,直到再不能发现新的频繁项集,算法结束。
其中,Apriori算法有两个核心步骤:(1)连接步:假设Apriori算法对事务集中的项按字典顺序排序,前面所说的由种子项集生成新的频繁K项集就是通过保证事务集中不同项前K-1项相同,而第K项不同,则认为这两项是可连接的;(2)剪枝步:如果一个项集是非频繁的,那么其所有超集也是非频繁的,所以它的所有超集就没有必要再进行搜索了,就是把那些不满足minsup的项集从生成的新的频繁K项集中删除。
下面介绍Apriori算法的实现,算法1给出了Apriori算法伪代码。Apriori假设事务或项集里的各项已经预先按词典序进行排列。项集里项的数量被称为项集的大小,大小为k的项集被称为k项集。用Fk表示大小为k的频繁项集的集合,用Ck表示相应候选项集的集合,Fk和Ck都包含一个存储支持度的字段。第一次遍历只对每个单项的出现次数计数并确定频繁1-项集。随后的遍历包含两个阶段,第一阶段调用Apriori-gen函数从第k-1次遍历产生的频繁项集Fk-1中获得Ck;第二阶段扫描事务集D,用函数Subset对Ck中每个候选项集的支持度进行计数,将不满足最小支持度的项集从候选项集中删除。
算法1 Apriori算法
∥频繁1项集
F1= {frequent 1-itemsets};
for(k=2;Fk-1≠□) do begin
∥新的候选
Ck=apriori-gen(Fk-1);
∥扫描D,对候选项集进行统计计数foreach transactiont∈Ddo begin
Ct=subset(Ck,t);
foreach candidate c∈ do begin
c.count++;
end
Fk= {c∈Ck∣c.count≥minsup}
end
returnFk=最大频繁项集;
Apriori算法通过剪枝来减少候选集大小来获得良好的性能。然而,在频繁项集很多或者最小支持度很低的情况下,算法必然产生数量庞大的候选项集,并且需要反复扫描事务集D来检查数量庞大的候选项集,代价仍然较高,但是它作为经典的数据挖掘[13-14]算法,简单实用,能够解决文中的问题。
2 基于源码的模式挖掘
本文主要研究Jenkins插件,利用Apriori算法挖掘其中的编程模式,生成编码建议给用户。生成的编码建议主要分为两个部分:一是在用户选择了一个父类之后,优先要重写的方法频繁项;二是这些重写方法之间的关联规则,例如:类A要重写父类方法a(·)和方法b(·)之后,还要重写方法c(·)的概率,此处的概率即置信度。

图1 本文工作概述
如图1所示,本文主要工作包括以下4个阶段:第一阶段:预处理阶段,把相关有用的信息保存到数据库中,减少后期代码频繁项挖掘[15]的时间开销;第二阶段:挖掘Jenkins插件类库中类与类之间的继承关系,生成树形结构图;第三阶段:根据用户输入关键字智能匹配树形结构中对应节点;第四阶段:从上一步匹配的节点为切入点,挖掘代码中需要重写的方法,为用户提示要优先重写的方法,以及关联规则和对应的置信度。
第一阶段:把插件的插件名、子类名、继承的父类名以及子类中重写的method等信息存储到数据库中,方便后面挖掘插件重用的父类信息。另外还要把继承Jenkins类库父类的子类的类名进行分词,便于通过关键字进行节点匹配;
第二阶段:为了从这些代码中挖掘出相应的父类继承关系树形结构图,通过分析Jenkins插件中继承Jenkins类库中父类的代码,它们的import信息都是以import hudson开头,或包含husdon的,先解析插件源码中的import信息。但是并不是所有的import信息都是有用的信息,有些类不是插件继承的父类,这部分类要剔除掉;还有些类虽然被插件中的子类继承了,但是只有一个插件继承过,这种父类也要剔除掉,因为挖掘频繁项至少要有两个事务,只有一个插件继承的父类,事务集中只有一个事务。例如图2中所示的import信息,org.jvnet.hudson.t- est.HudsonTestCase类HudsonTestCase是Jenkins插件类库中的一个父类,用户在写插件的时候可以直接继承父类。这些代码中的import信息就是要利用的信息,在这个阶段的主要任务是生成Jenkins插件中类似的类与类之间的继承结构关系图,为下一个阶段中匹配对应节点做准备;

图2 源码import信息
第三阶段:这个阶段就是为了获取用户想要了解的信息,然后有针对性的挖掘,并返回给用户有价值的信息。首先用户输入最能代表他想实现功能的关键字,CodeMining根据用户的输入的关键字智能匹配相应的节点,并给出评分,分数越高,代表关联性越大,用户可以很轻松的做出自己的选择,作为编写代码的切入点;
第四阶段:这个阶段就是利用Apriori算法进行频繁项挖掘,也是本文所提方法最重要的一个部分。编写一个类继承Jenkins插件中的一个父类,需要重写一些方法,这里所说的频繁项就是这些要优先重写的方法,设置不同的支持度和置信度参数值,会返回不同的频繁项结果,同时给出相应的关联规则和对应的置信度。用户可以有针对性的参考这些规则,在没有任何经验的情况下开始编写Jenkins插件的第一行代码。
3 实验结果与分析
为评价本文方法,挖掘了从Github[16]上下载的1 523个Jenkins插件的代码信息,为了减少挖掘时间,从1 523个插件代码中随机挑选了500个插件,这些代码均采用Java语言编写。本文试验环境为:操作系统: Windows 7 64位专业版、CPU:Intel(R)Core(TM)i3-2330 M @ 2.20 GHz、内存8 GB。
为展现本文所提方法的效果,列举了一个以James为开发者的应用案例,分析挖掘出来的频繁项集以及关联规则,以验证本文提出的方法的可行性。
例1 HudsonTestCase
James想写一个关于Hudson的测试用例,他并不知道应该继承哪一个类,以及从哪里入手开始写代码,于是他输入了关键字hudson, CodeMining开始搜索之前预处理阶段存储在数据库中的数据,返回如表1数据,代码运行的时间为0.143 s。

表1 基于关键字CodeMining返回的父类列表
Count为关键字在所有继承此父类的子类名中出现的次数,Frequency为此关键字在类名分词结果中所占比例,Score为关键字匹配的得分,得分最高者为最匹配的那个父类。
于是James就编写一个类文件来继承这个父类,在CodeMining中选择HudsonTestCase这个父类,设置频繁项挖掘的一些参数,例如:支持度、置信度。CodeMining就可以进行频繁项挖掘,这里分别将支持度设置为2、3和4,置信度都设置为0.5,挖掘出的频繁K项集K的最大值Kmax、Kmax项集对应的支持度、关联规则数量以及运行时间如表2所示。

表2 置信度为0.5不同支持度下的实验结果
如表2所示,支持度设置过低的话,会挖掘出很多关联规则,James可有侧重性的选择其中有价值的信息来使用,另外本文实验运行时间很短得益于预处理阶段将有用的数据存储在数据库中。本文限于篇幅,仅分析当支持度为4时的实验结果。当支持度设置为4,置信度设置为0.5时,返回的频繁项集如图3所示,关联规则如图4所示。实验结果简单明了,如@Before:setup在单元测试[17]里很常见,原因是为了方便演示,但对于那些不常见的关联规则,CodeMining也可以像挖掘那些熟悉的关联规则一样,将其挖掘出来。

图3 支持度为4的频繁项集
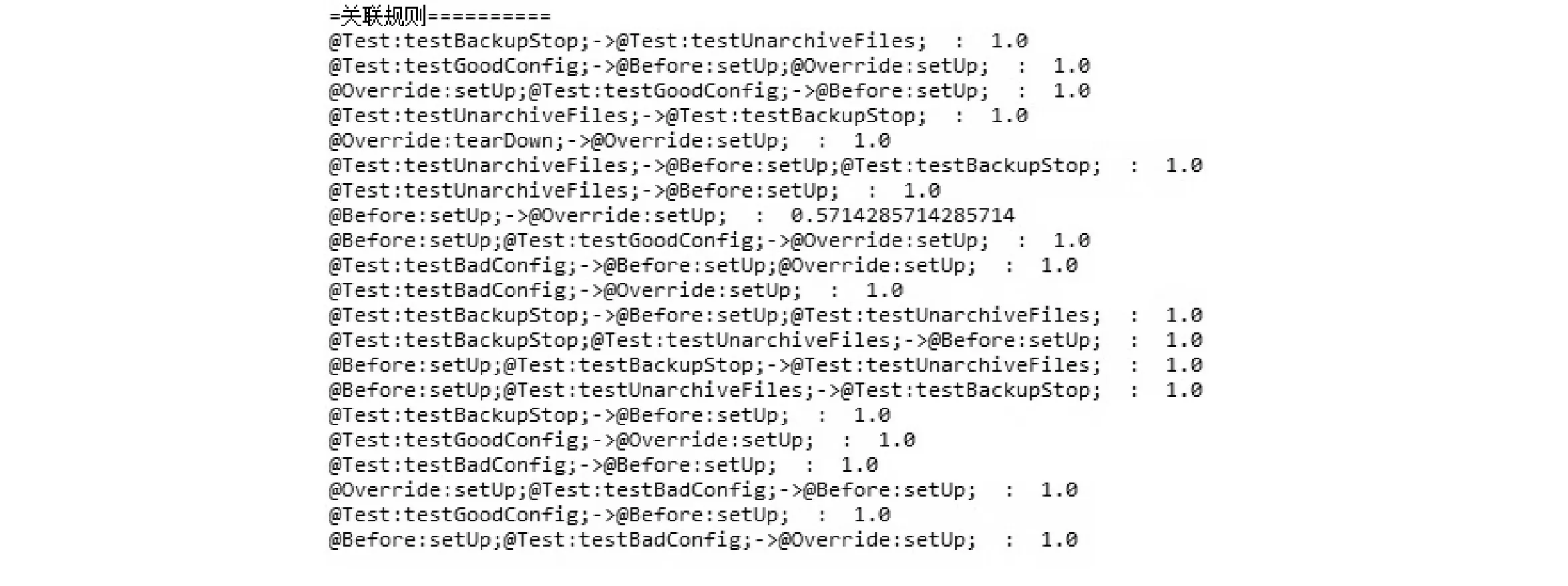
图4 支持度为4的关联规则
图3和图4中@Override:setup表示要重写setUp方法,@Before:setUp表示注解为@Before的setUp方法。
图3中频繁1项集@Override:setup在62个插件中出现了,出现次数最多,James会优先重写这个方法,而@Before:
setUp这个方法在21个插件中出现了,James已知这个方法也是要优先重写的方法,但并不像@Override:setup这个方法那么重要,有时也可以不重写这个方法。图3中2项集@Before:setUp; @Override:setup在12个插件中出现了,James会猜想这两个方法应该是存在某种关联,即重写了第一个方法,有较大概率要重写第二个方法。频繁3项集的支持度为6,说明在6个插件中这3个方法都同时出现了,James重写了3项集中任意一个方法时其他两个方法就是优先重写的方法。
图4中由@Before:setup-> @Override: setup的置信度为0.571,这也验证了由图3得出的猜想,在重写了@Before:setup这个方法后,是有很大概率要重写@Override:setUp这个方法的。从图4还可以发现由@Before:setUp;@Test:
testBadConfig;->@Override:setUp;置信度为1.0,由@Before:setUp;@Test: testGoodConfig;->@Override:setUp;置信度也为1.0,James重写了@Before: setUp方法之后,只要也重写了@Test: testBadConfig这个测试或者@Test: testGoodConfig这个测试,他就有100%的概率还要再重写@Override: setUp这个方法。
通过James的案例分析,验证了可以通过文中提出的CodeMining方法,根据挖掘出来的频繁项以及关联规则,快速的学习框架的开发,写出软件开发的第一行代码。
4 结束语
本文提出了一种挖掘源码模式的辅助开发方法,通过实验证明,可以挖掘出代码中的编程模式,并有效辅助新手进行软件开发。但本文挖掘出的是粗粒度编程模式,没有进一步深入到方法中去挖掘相关的编程模式,也没有挖掘代码中一些其他有用的信息。下一步工作是进一步挖掘代码方法中的具体内容,挖掘出更细粒度的编程模式,并加入更多维度。
[1] 王少锋,何志均,王克宏.软件重用技术研究[J].计算机工程与设计,2000,21(5):10-14.
[2] Robillard M P,Chhetri Y B. Recommendi -ng reference API documentation [J]. Empirical Software Engineering,2015,20(6):1558-1586.
[3] Michail A.Data mining library reuse patterns in user-selected applications[C]. Hangzhou:Automated Software Engineering,14th IEEE International Conference,2000.
[4] 赵洪英,蔡乐才,李先杰.关联规则挖掘的Apriori算法综述[J].四川理工学院学报:自然科学版,2011,24(1):66-70.
[5] 崔贯勋,李梁,王柯柯,等.关联规则挖掘中Apriori研究与改进[J].计算机应用,2010,30(11):2952-2955.
[6] 刘华婷,郭仁祥,姜浩.关联规则挖掘Apriori算法的研究与改进[J].计算机应用与软件,2009,26(1):146-149.
[7] Bruch M, Schäfer T, Mezini M. FrUiT: IDE support for framework understanding[C]. Portland, Oregon, USA:OOPSLA Workshop on Eclipse Technology Exchange, ETX 2006.
[8] 吴信东,Vipin Kumar.数据挖掘十大算法[M].北京:清华大学出版社,2013.
[9] Jiang C, Coenen F,Zito M.Frequent sub -graph mining on edge weighted graphs[M].Berlin:Springer Berlin Heidelberg,2010.
[10] 陆丽娜,陈亚萍,魏恒义,等.挖掘关联规则中的Apriori算法的研究[J].小型微型计算机系统,2000,21(9):940-943.
[11] 颜跃进,李舟军,陈火旺.基于FP-Tree有效挖掘最大频繁项集[J].软件学报,2005,16(2):215-222.
[12] 高宏宾,潘谷,黄义明.基于频繁项集特性的Apriori算法的改进[J].计算机工程与设计,2007,28(10):2273-2275.
[13] 贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007,24(1):10-13.
[14] 刘红岩,陈剑,陈国青.数据挖掘中的数据分类算法综述[J].清华大学学报:自然科学版,2002,42(6):727-730.
[15] 祝然威,王鹏,刘马金.基于计数的数据流频繁项挖掘算法[J].计算机研究与发展,2011,48(10):1803-1811.
[16] 张智,郑卉,蒋依伶,等.使用Github实现高效的团队协作开发[J].电脑知识与技术,2015,11(7):206-208.
[17] 白凯,崔冬华.基于JUnit自动化单元测试的研究[J].计算机与数字工程,2010,38(2):52-54.
Based on the Source Code Pattern Mining Software Assist Development Technology Research
FU Peng,SHEN Lili
(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology, Shanghai 200093,China)
With the explosive growth of the open source community software code, software reuse is being more and more attention. Because of the complexity of the software code. To the novice that do not understand the framework, it is difficult to use the code from the open source community to develop software. As a result, using data mining technology to dig programming patterns from the existing code become a research hotspot. This paper mainly introduces the frequent items mining Apriori algorithm, and put forward the based on the source code pattern mining software assist development method. It can be based on user input keywords to intelligent matching to the super class, mining programming patterns based on the super class, give the methods that priority to override as well as the association rules. The experimental results show that the novice can use these coding suggestions, fast learning a new framework and improve the development efficiency.
source code; data mining; programming patterns; software assist development
2016- 05- 30
沈莉莉(1992-),女,硕士研究生。研究方向:数据挖掘。
10.16180/j.cnki.issn1007-7820.2017.04.035
TP312
A
1007-7820(2017)04-140-05
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
电子制作(2019年22期)2020-01-14 03:16:34
计算机应用(2018年5期)2018-07-25 07:41:26
黑龙江工程学院学报(2015年5期)2015-12-04 01:39:38
轴承(2015年2期)2015-07-25 03:51:04
智能建筑电气技术(2015年1期)2015-03-01 03:07:55
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电讯技术(2011年11期)2011-04-02 14:00:37
网络安全与数据管理(2010年1期)2010-05-18 07:28:54
