
SPSS在理论语言学方向的应用初探
2017-04-17 09:20迟晓旭
文教资料 2016年34期
关键词:实证研究
迟晓旭
摘 要: 近年来,SPSS统计软件逐步应用于语言学及应用语言学各个领域,并取得了丰硕的研究成果,但在理论语言学方向却较少涉及。本文收集了“动物类”表人词语共416例,利用SPSS对其进行统计分析,对该软件在理论语言学方向的应用进行了初步的探索。
关键词: SPSS 理论语言学 软件应用 实证研究
一、概述
SPSS(Statistical Package for the Social Science)全名为社会科学统计软件包,是一种利用计算机进行统计分析和数据处理的工具性软件。凭借其成熟的统计理论、强大的统计功能以及友好的操作界面,一经问世,就受到科研工作者们的青睐,迅速应用于科研、医疗、通讯等多个领域。
20世纪以来,语言学的发展呈现出百花齐放百家争鸣的态势,理论的极大丰富凸显了实证研究的紧迫性,这种以数据为基础的定量研究方法逐渐成为一股潮流,逐步应用于语言学及应用语言学研究的各个领域。这为语言学的研究开拓了一條新路,国内研究人员也利用该软件在语言研究的各个方面进行了尝试。
章柏成(2008)利用SPSS对学生的成绩、智商、策略运用等方面进行了相关性考察。倪传斌(2009)利用独立样本T检验考察了不同性别的外语磨蚀程度。王佳琳、侯煜冠(2012)对哈尔滨方言合口呼零声母各音节的v型发音进行了卡方检验,以探寻音节结构间的差异性。谢展飞、吴佩娜(2015)应用双因素方差分析探讨了人工耳蜗的植入对受试者听力的影响。项梦冰(2015)利用聚类分析对方言间的相似度进行了考察。
根据前人的研究成果,可以发现:SPSS软件工具已经开始同语言学各方向进行结合,但主要应用于方言学、心理语言学、社会语言学、第一语言与第二语言习得等方向。而在理论语言学方向上,这种真正意义的定量分析却运用得很少,少数一些应用,也多是利用标准化测试的方法。本文收集了一些真实语料,利用SPSS软件及其统计原理,对该语料进行统计分析,对理论语言学方向的应用做初步探索。
二、理论语言学应用初探
在新兴的网络新词语中,有一类包含动物语素用以表人的名词或动词,如:大虾、菜鸟等。现从《汉语新词语词典》(2005-2010)、《新华新词语词典》(2003)、《新词语大词典》(1978-2002)、《汉语新词语》系列书籍(2007-2013)等四部词典中抽取该类新词语,除去存疑和重复,共计159例,通过人工标注,对其语义褒贬倾向进行初步判断。另有从《现代汉语词典(第六版)》中收集的同类新词语227例,通过相同的方式对语料进行处理,作为其对比语料。将全部416个词语导入SPSS软件中,并对其意象、褒贬倾向、来源三个部分进行赋值,具体赋值结果如下:
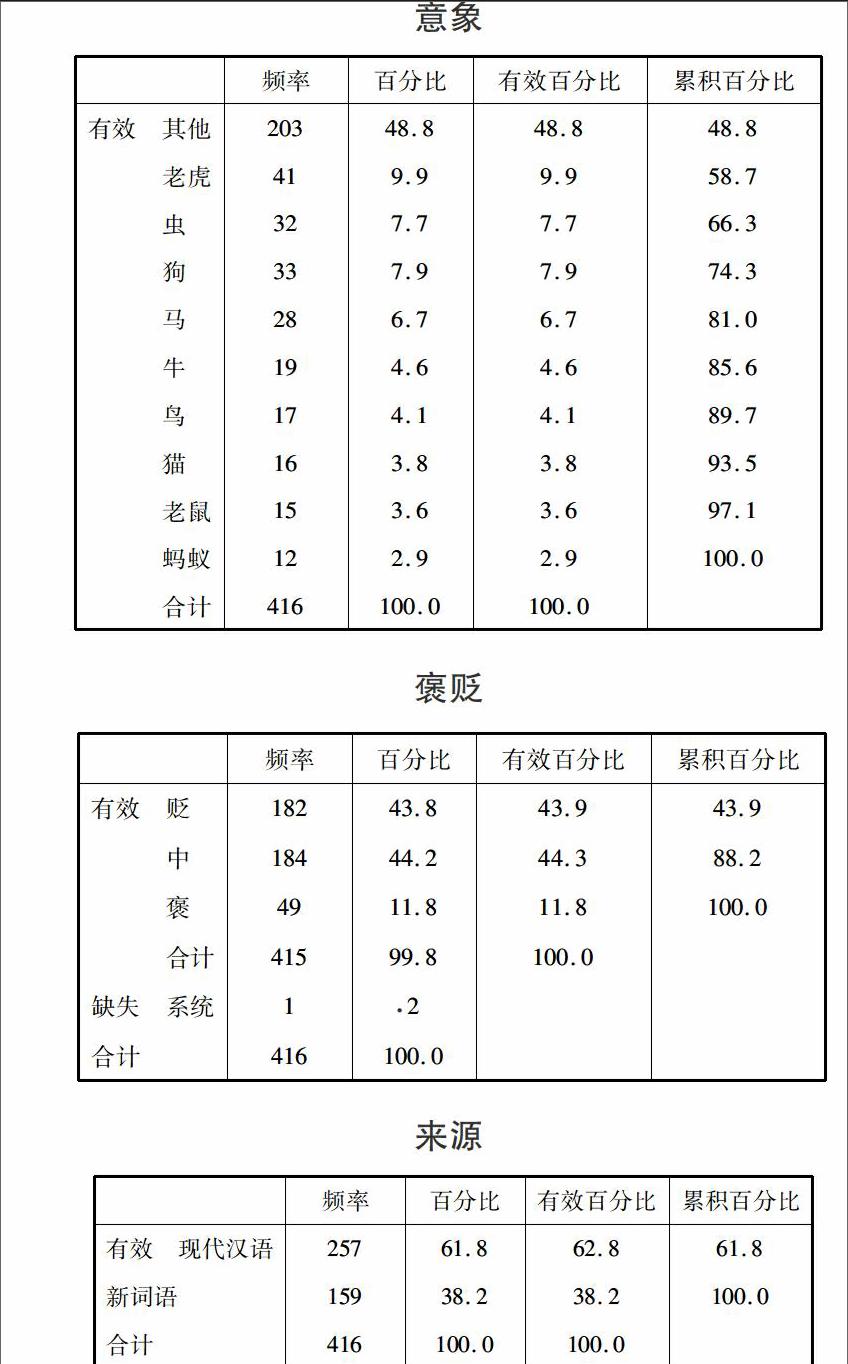
第一、意象。这里的意象指狭义的意象,即词语中表示人的动物形象。如“菜鸟”的意象就是“鸟”。由于“动物类”表人词语意象颇多,足有84个,而大部分的意象仅出现一次。因此,本文仅对出现频次超过10的意象进行赋值,其余意象统一归为一类。赋值结果为:“老虎=1”;“虫=2”;“狗=3”;“马=4”;“牛=5”;“鸟=6”;“猫=7”;“老鼠=8”;“蚂蚁=9”;“其他=0”。度量标准设置为“名义(N)”。
第二、褒贬。词语的意义通常可分为概念义和色彩义。需要说明的是,褒义、贬义作为感情色彩义本不应当进行赋值及运算操作,然而因为感情色彩具有一定的对称性及偏向性,所以在此将其量化为可运算数据。赋值结果为:“褒=1”;“中=0”;“贬=-1”。度量标准设置为“度量(S)”。
第三、来源。词语的来源有二,其一为新词语,主要是从四部新词语词典中收集而来;其二为《现代汉语词典(第六版)》中的词语。现对其进行赋值:“现代汉语=1”;“新词语=2”。度量标准设置为“名义(N)”。
在进行初步的语料处理后,本文将基于SPSS软件,对这些语料进行统计分析,进而探索SPSS在理论语言学方向的应用。
(一)描述统计
描述统计是统计分析的第一步。利用抽样或其他手段采集到数据后,仅凭肉眼观察有时无法发现观察对象的基本特征,而语言研究中,这种数据的无序性尤为明显,因此,在进行数据分析之前,可利用描述统计的频率表观察现有数据的分布状况。
以动物类表人词语为例。本文对现有416个词语进行频率统计,得到结果如下:
意象
褒贬
来源
根据以上图表,可以明显看出,虎、虫、狗等意象使用频率较高,词语的褒贬义也趋近于贬义,褒义较少。另外,也可以绘制饼图更为直观地观察其分布比例。
(二)参数假设检验
参数假设检验是应用的较为广泛的一种科学的统计方法,其原理为:事先对总体的参数或分布进行假设,再通过样本信息判断该假设是否合理。在目前语言学各方向的研究中,应用得较多的参数假设检验是T检验和卡方检验。利用该原理,我们可以通过样本信息对某种语言现象进行假设并验证,进而得出结论。
1.T检验
T检验是对均值差异性的检验,其最大的优点在于可以使用样本标准差代替总体标准差,从而解决了实际问题中总体标准差多数不可知的问题。SPSS中的T检验主要有三类,其中,单样本T检验和配对样本T检验由于其检验要求较高,并不适用于理论语言学方向,因此,本文只讨论独立样本T检验在理论语言学方向的应用。
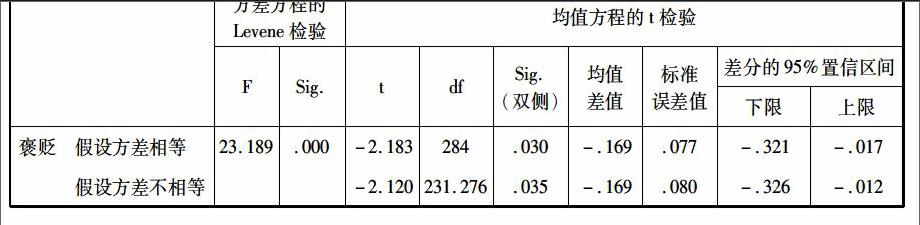
独立样本T检验旨在比较两样本均数的差别。现将动物类表人新词语159例作为样本一;《现汉》收录的同类词语227例作为样本二。由于独立样本T检验要求两样本具有完全的独立性,而两样本有所交叉,因此本文对实验数据进行修正,将《现代汉语词典(第六版)》中的语料进行删减处理,只保留1919年前的熟语部分。修正后的样本二收录词语共128例。
利用现有的两样本,对动物类表人词语的褒贬义做对比考察。其中检验变量为词义的褒贬,分组变量为词语的来源,组别分为两组,一组是新词语,一组为现代汉语。通过独立样本T检验,得到结果如下:
独立样本检验
检验结果:新词语褒贬均值为-0.26,熟语部分褒贬均值为-0.43。二者方差不齐,因此P=0.035<0.05,实验结果较为显著,说明二者确实存在一定的历时差异。即:动物类表人新词语的语义偏向从偏贬义而逐渐趋于中性。
虽然修正后的样本独立性得到相对保证,但是仍存在一些问题:其一,删减后的词语主要保留1919年之前的熟语,无法概括当时词语的全貌;其二,影响褒贬偏向的重要因素不止有时间上的差异,更重要的是意象的差别。因此将所有意象共同考察显然并不合适。对于第二个问题,将在稍后的方差分析部分进行完善。
通过以上研究可以发现,独立样本T检验在语言学上的实用性相对较高,尤其对于关键因素不同的两样本来说,独立样本T检验是十分适用的检验方式。
2.卡方检验
卡方检验是对无序分类变量的统计推断,其优点在于,可以对两个或多个分类变量进行关联度分析,其应用的广泛程度可以和T检验相媲美。卡方检验共有五种功能,但是,除了两样本卡方检验外,其他检验方式,对样本的要求较高,多数情况并不适用于理论语言学的研究。因此,本文只讨论两样本卡方检验的具体应用。
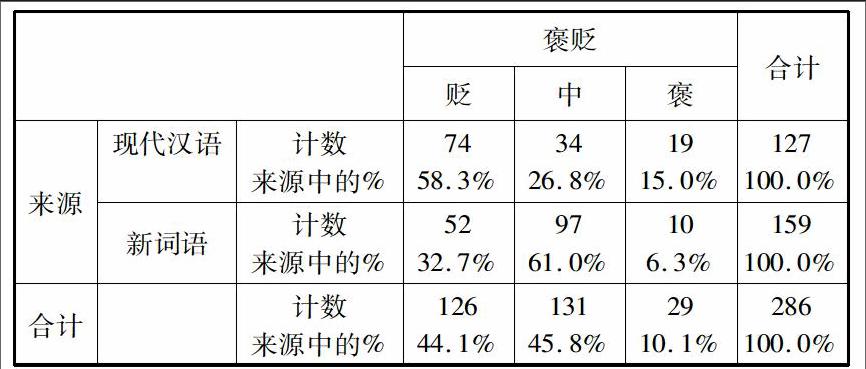
两样本卡方检验是单样本卡方检验的扩展,用于比较两个或多个样本所在总体的另一个分类变量的发生率/构成比是否相同。现有修正后的动物类表人词语,共计287例,其来源包括1978年以来的新词语以及1919年前的熟语。现希望考察不同时间来源的词语,其褒贬偏向的分布率是否相同。经过两样本卡方检验后,得到关于来源情况与褒贬取向的交叉制表如下:
来源*褒贬交叉制表
样本数据的差异很明显,源自现代汉语熟语部分的词语贬义取向约占58%,而新词语中的褒贬取向则偏向于中性,约占61%。而后,对该差异是否有统计学意义进行进一步的验证,得到卡方检验结果表如下:
卡方检验
a.0单元格(0.0%)的期望计数少于5。最小期望计数为12.88。
通过以上检验,几种卡方量P值均小于0.05,因此该差异具有统计学意义,即:词语的褒贬向分布确实存在历时差异,同先前独立样本T检验的结果存在一致性,当然,在差异的显著性上,两检验结果存在差别。通过该例,我们可以明显看出,双样本卡方检验在语言学研究中也具有一定的实用性。
(三)方差分析
T检验可以解决单样本、两样本的均数比较问题,而方差分析则是用于解决多个样本的均数比较问题。面对真实世界的复杂情况,方差分析显然有其独到的作用。SPSS中的方差分析共有三类。其中,多元方差分析的前提是假定几个因变量同等重要,在面对复杂的语言现象时,这种方法显然不可取。因此,本文仅讨论单因素方差分析、多因素方差分析在理论语言学方向的应用。
1.单因素方差分析
现有未修正的动物类表人词语,共计416例,其中,常见意象共有9种,其感情色彩义分别为褒、贬、中三类。现希望考察意象對于词语的感情色彩义的影响。通过单因素方差分析,得到结果如下:
单因素方差分析
褒贬
经过检验,P=0.000<0.05,这说明意象对于感情色彩义的影响极为显著。
虽然在方差分析前的Levene方差齐性检验中,结果显示P=0.000<0.05,方差不齐,且输出的Welch统计量显示,该统计量接近于F分布。但是,根据前人的研究,方差分析对于正态性和方差齐性的要求是稳健的,即:当正态性得不到满足或存在轻微的方差不齐时,只会对结果造成轻微的影响。因此,虽然该例并不典型,但结果依然具有可参考性。
另外,单因素方差分析,还可以进行均数间的两两比较,以确定究竟是哪些组之间存在差异。但本次的实验语料对于这种方法并不适用,在此不过多赘述。
2.多因素方差分析
多因素方差分析模型多用于考察多个因素对因变量的影响,在面对复杂多变的现实情况时,该模型具有独到之处。
现有修正后的动物类表人词语词表,共计287例。现希望考察词语意象及来源时间两者对词语褒贬偏向的影响。通过初步拟合模型,得到结果如下:
主体间效应的检验
因变量:褒贬
a.R方=.257(调整R方=.204)
经检验,校正模型P=0.000<0.05,说明在所有影响因素中,至少有一种对词语的褒贬偏向造成影响。而其后的数据显示,词语的来源时间对词语的褒贬并没有显著影响,而意象对于词语的褒贬偏向有显著影响,并且,二者的交互作用对词义的褒贬倾向也有显著影响。
为了进一步考察影响因素对词汇褒贬语义倾向的影响,本文在原有基础上,对主体间效应进行两两比较,得到结果如下:
褒贬
Student-Newman-Keulsa,b,c
已显示同类子集中的组均值?莓
基于观测到的均值?莓
误差项为均值方(错误)=.341
a.使用调和均值样本大小=15.078
b.组大小不相等?莓将使用组大小的调
和均值?莓不保证Ⅰ型误差级别?莓
c.Alpha=.05?莓
根据该图表可以发现,两种来源的动物类表人词语,意象之间均存在差异性,这说明,意象对于词汇褒贬语义倾向确实存在显著影响。另外,来源时间的两个子集之间差异并不十分显著,这说明,来源时间对于词语的褒贬意象不存在显著影响,但是由于个别意象的影响,使得其来源时间与意象存在交互作用,这才对词语的褒贬义产生了一定的影响。这也解释了为什么在考察来源时间对词汇褒贬语义偏向的影响时,方差分析同独立样本T检验、卡方检验的结果存在差异。
三、小结
在理论语言学方向,SPSS最主要的应用是:描述统计、独立样本T检验、两样本卡方检验、单因素方差分析及多因素方差分析。其他分析工具虽然存在一定的应用价值,但其因为检验条件、检验数据的限制,或是研究目的的要求,无法很好地应用到语言研究中。
通过以上分析可以发现,这种将统计运用到语言研究的方法,具有明显的优势:其一,语言统计方法可以将本不可量化的语言现象量化,并通过科学的方法进行检验,为理论研究提供较好的数据支持;其二,该方法能够观察到一些简单思辨观察不到的现象,在样本量不大的时候,也可以通过科学的方法进行实验并验证。
但这种基于统计学原理的方法在进行理论语言学分析时,也存在明显的问题:其一,几种统计方法的先决条件均为正态性和连续变量,而很多数据并不符合这两项先决条件,样本量不够大时,检验结果或有偏颇;其二,理论语言学的实证研究多采用语料库的方法,数据资料较少,在应用统计的过程中,如何合理地量化数据,是一个应用难点;其三,在进行语料的收集与處理中,数据主观性强且没有合理的验证方式也是一个重要的问题。
因此,在实际运用过程中,我们既应该合理利用工具,用科学的方法对语料进行量化,以增强研究的科学性,又要考虑到数据的可用性,工具使用的合理性,切忌误用、滥用统计工具,以求最大限度地科学化使用统计工具,保证研究的科学性。
参考文献:
[1]杨端和.语言研究应用SPSS软件实例大全[M].中国社会科学出版社:2004.
[2]张文彤,邝春伟.SPSS统计分析基础教程[M].高等教育出版社:2011.
[3]张文彤,邝春伟.SPSS统计分析高级教程[M].高等教育出版社:2013.
[4]严振松.谈语言学和应用语言学中的定量型研究方法[J].解放军外国语学院学报,2001,24(5):4-6.
[5]倪传斌.外语磨蚀的性别差异[J].外语与外语教学,2009,(4):1-5.
[6]章柏成.SPSS在外语教育实证研究中的应用[J].重庆交通大学学报(社科版),2008,8(1):128-131.
[7]黄利花.SPSS统计方法及其适用性分析[J].延安职业技术学院学报,2014,28(4):83-91.
[8]谢展飞,吴佩娜.双模式对人工耳蜗低频段电极不全植入者的言语识别影响[J].临床耳鼻咽喉头外颈外科杂志,2015,29(11):980-983.
[9]王佳琳、侯煜冠.哈尔滨话合口呼零声母[υ]化的社会语言学研究[J].学术交流,2012(10):157-162.
[10]项梦冰.聚类分析在汉语方言研究中的运用[J].语文研究,2015(4):7-14.
